SOC for beginners. Задачи SOC: контроль защищенности
Продолжаем цикл наших статей о центрах мониторинга кибератак для начинающих. В прошлой статье мы говорили о Security Monitoring, инструментах SIEM и Use Case.
Термин Security Operations Center у многих ассоциируется исключительно с мониторингом инцидентов. Многим сервис-провайдерам это, в принципе, на руку, поэтому мало кто говорит о том, что мониторинг имеет ряд серьезных ограничения в плане защиты от кибератак.
В этой статье мы на примерах продемонстрируем слабые места мониторинга инцидентов ИБ, расскажем, что с этим делать, и в конце, как обычно, дадим несколько практических рекомендаций на тему того, как провести аудит защищенности инфраструктуры своими силами.

«Уязвимость» Security Monitoring
В чем и сильная, и слабая сторона Security Monitoring? В том, что в первую очередь он оперирует событиями безопасности. Это либо события и срабатывания правил средств защиты информации, либо логи и журнальные файлы: операционной системы, базы данных, прикладного ПО.
При этом есть большое количество ситуаций, при которых либо в логах активность явным образом не фиксируется, либо поток событий или возможности систем не позволяют эффективно организовать процесс мониторинга.
Давайте рассмотрим на примерах.
1. Эксплуатация уязвимостей систем
Рассмотрим достаточно типовую ситуацию: есть существенно защищенный периметр, отдельно выделенный сегмент DMZ и достаточно слабо сегментированная офисная сеть компьютеров. И вот, в этой сети у нас появляется «новый » хост. Принадлежит ли эта машина инсайдеру, или это ноутбук рядового сотрудника, зараженный при помощи социальной инженерии, не столь важно. Злоумышленник начинает точечно заниматься эксплуатацией уязвимости RCE на операционных системах серверов и рабочих станций, доступных ему в рамках сегмента.
Каким образом можно зафиксировать такую проблему? Отсутствие сегментации сети оставляет нас без надежд на детект от сетевых средств защиты, будь то IPS или другие системы. В логах самой операционной системы эксплуатация RCE уязвимости не несет никакого специального кода, и поэтому нет никакой возможности отличить её от обычной попытки аутентификации в ОС. Так или иначе, в логах будет запуск системного процесса svchost.exe от системного пользователя.
Единственной нашей надеждой остаются IDS-модули средств защиты хоста, но, как показывает наша практика, наличие работающего и регулярно обновляемого IDS на всех хостах инфраструктуры — большая редкость.
Вот как выглядит процесс эксплуатации «наболевшей» уязвимости EternalBlue SMB Remote Windows Kernel Pool Corruption (устраняемой обновлением безопасности MS17–010). Обратите внимание, что отсутствие любого из приведенных в примере трех источников не даст нам полной картины и возможности понять, была атака или нет.
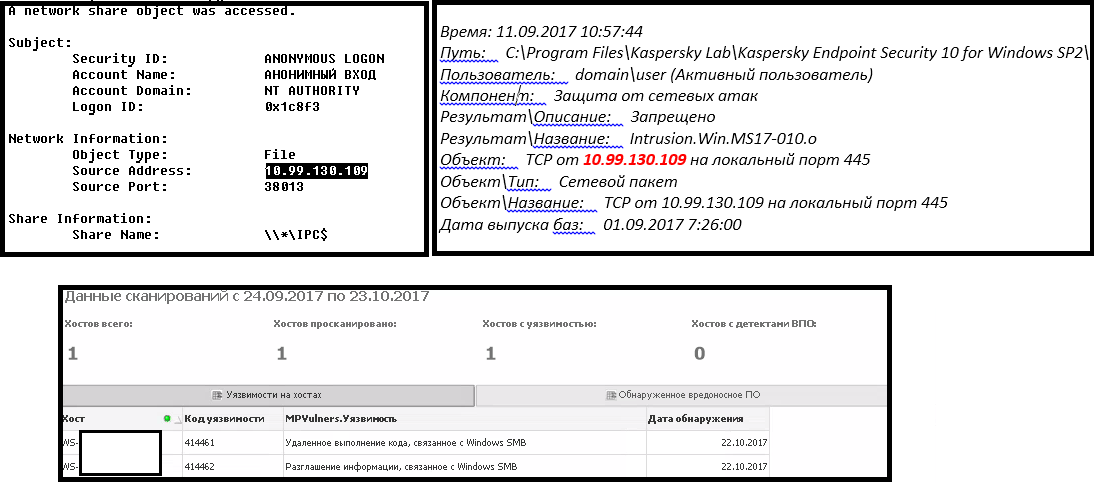
В итоге можно надеяться на чудо, а можно начать строить процесс управления уязвимостями и попытаться локализовать проблему еще до ее проявления.
По этой проблеме есть достаточно большое количество специализированных материалов, поэтому заострять внимание на ней не будем. Обозначим лишь несколько тезисов.
«Выиграть гонку» с уязвимостями и построить инфраструктуру с актуальными обновлениями безопасности — задача, практически не реализуемая в крупном корпоративном клиенте. Количество уязвимостей из года в год растет, причем большинство из них среднего и высокого уровня критичности (согласно системе оценки CVSS v2).
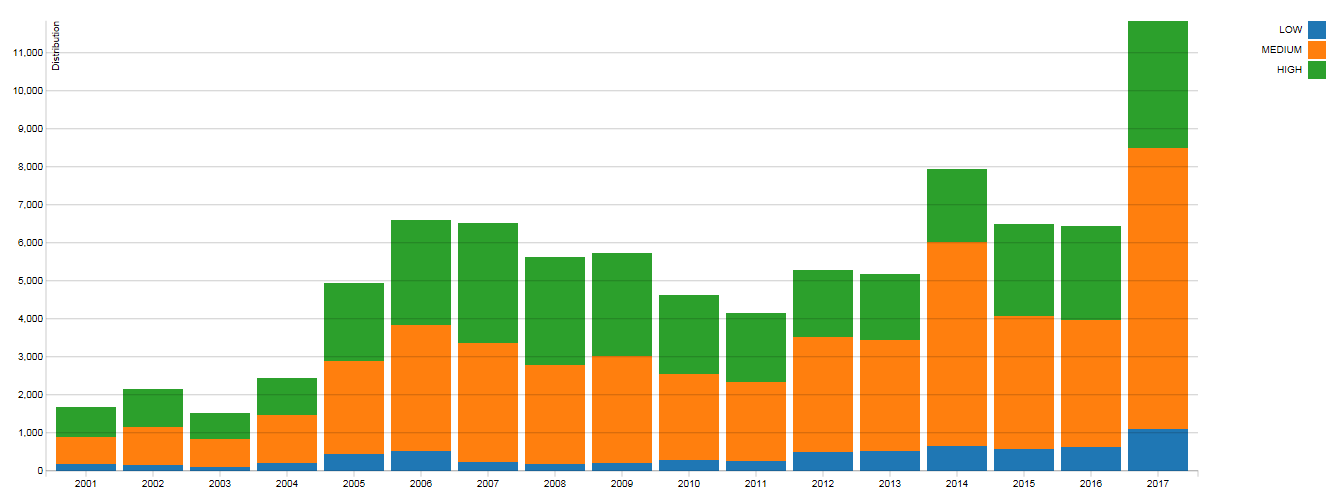
Распределение количества уязвимостей по годам в разрезе их критичности (ссылка на источник).
При рассмотрении и составлении карты устранения уязвимостей необходимо не только придерживаться принципа Парето (т.е. выбирать только самую критичную часть для устранения), но и очень тщательно работать с компенсирующими мерами — с достижимостью уязвимости за счет настроек средств защиты, анализом возможных векторов реализации и т.д.
Но это не единственная задача, оставшаяся за скоупом возможностей мониторинга.
2. Профилирование прямого доступа в Интернет
Периодически в глазах службы безопасности SIEM превращается в могучий инструмент, который в состоянии оперировать любыми событиями или потоками данных. В таком случае может возникнуть, например, следующая задача: в рамках компании есть некоторое согласованное количество маршрутов разрешенного прямого доступа в Интернет в обход прокси-серверов. И в целях контроля работы сетевых специалистов перед SIEM ставится задача: контролировать все несогласованные ранее открытия прямых доступов путем анализа сессий из корпоративной сети.
Казалось бы, задача простая и логичная. Но есть несколько ограничений:
- В средней компании количество ACL-правил, разрешающих прямой доступ в Интернет, по разным причинам (ограничение работы прокси, специализированное ПО и т.д.) составляет несколько сотен. Создать профиль такой характеристики в SIEM не сложно, но тут мы сталкиваемся с второй проблемой.
- Эти правила постоянно, на ежедневной основе, меняются. Как исчезают текущие тестовые системы, так и появляются новые, часть доступов открывается в целях тестирования или регламентных работ. В итоге это ежедневно создает такой огромный поток инцидентов, что его сложно обрабатывать.
- Стоит отметить, что и само такое правило при всей видимой простоте является очень «тяжеловесным» для классической корреляции в SIEM. В первую очередь это связано с огромным потоком событий, проходящим через межсетевой экран в сторону Интернета.
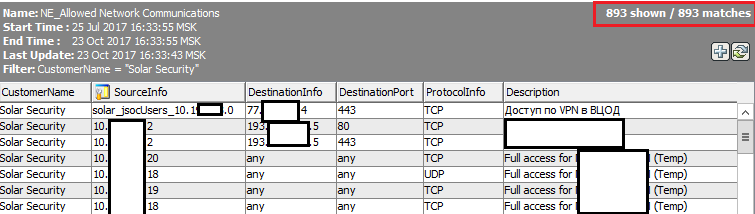

В итоге данный вопрос в первую очередь касается управления конфигурациями и контроля изменений. И, несмотря на теоретическую возможность решения этой задачи с помощью мониторинга, многократно эффективнее оперировать специализированными средствами и уже в SIEM мониторить работоспособность процесса.
Совокупно же эти примеры приводят нас к более глобальной задаче: SOC должен детально понимать инфраструктуру компании, ее уязвимости и процессы в «широком смысле» и принимать решение о том, как наиболее эффективно мониторить данную инфраструктуру и как максимально быстро узнавать о том, что в ней что-то изменилось — то есть в каждый момент времени объективно оценивать фактическую защищенность инфраструктуры от атаки.
Контроль защищенности — задачи и технологии
На наш взгляд, в тематику контроля защищенности попадают следующие задачи:
- Определение периметра и сервисов компании, доступных из сети Интернет.
- Анализ уязвимостей внешнего периметра и внутренней инфраструктуры.
- Анализ конфигураций критичного сетевого и инфраструктурного оборудования.
- Анализ политик безопасности серверов и АРМ.
- Оценка эффективности политик, внедренных на средствах защиты, с точки зрения полноты и функционала.
- Выявление уязвимостей в программном коде используемого прикладного ПО.
- И в идеале — анализ ключевых бизнес-процессов на предмет процессных уязвимостей, которые могут повлечь за собой финансовые потери.
Для каждой из обозначенных задач есть свой инструментарий:
- сканеры безопасности;
- системы firewall management, эффективно управляющие сетевым оборудованием;
- системы контроля целостности;
- системы управления конфигурациями;
- системы анализа кода;
- ручные проверки общей защищенности с помощью тестов на проникновение.
Но одним из самых важных и одновременно самых недооцененных ресурсов безопасности является его язык и коммуникация. Из нашей практики работы в клиентах, при выстроенном человеческом общении с ИТ и прикладниками даже за разговором в курилке можно узнать о грядущих или случившихся изменениях гораздо больше, чем в процессе длительного технического анализа настроек (что, тем не менее, не отменяет важности данного процесса).
Мониторинг и контроль защищенности => Мониторинг + контроль защищенности
Одним из важных преимуществ параллельного запуска процессов мониторинга и контроля защищенности в SOC является возможность «переопылять» один процесс информацией из другого, тем самым повышая общую безопасность. Разберем на примере, как это работает.
Мониторинг как инструмент выявления новых хостов и активов
Если в компании не построен процесс инвентаризации активов или ИТ не делится его результатами, появление новой системы с критичным функционалом или критичными данными может пройти мимо информационной безопасности. Но ситуация существенно меняется, когда существует процесс мониторинга.
В 99% случаев вновь появившийся хост в обязательном порядке «проявит» себя:
- Попытается получить доступ в Интернет напрямую или через прокси.
- Попробует обратиться к контроллеру домена.
- Проведет попытку обращения к DNS.
Если эти источники подключены к мониторингу, то c помощью достаточно несложного отчета или сценария можно выявлять такие «шпионские» хосты.
Пример: события аутентификации в ОС Windows с фильтрами по известным именам хостов. Как правило, в компании есть критерии именования хостов, за которые можно зацепиться.
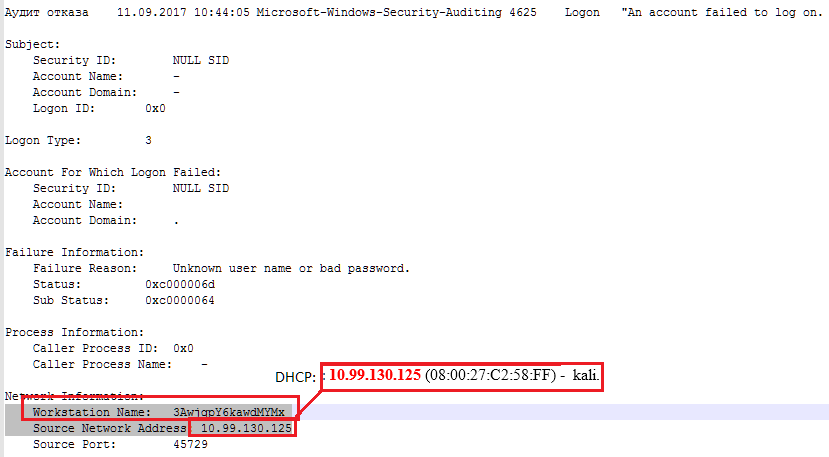
И, уже владея информацией о том, что появились новые сущности в сети компании, вполне можно разобраться в их задачах, легитимности или учесть их в общей модели угроз.
И наоборот, если невозможно закрыть какую-то процессную или технологическую уязвимость навсегда, в качестве компенсирующей меры можно разработать дополнительные сигнатуры и сценарии, контролирующие эксплуатацию данной уязвимости.
В качестве примера можно привести процесс наладки и обслуживания технологического оборудования на заводе (или, например, ГРЭС — другими словами, практически на любом производстве). Для работы с таким оборудованием, как правило, привлекаются инженеры от производителя, и зачастую это иностранные специалисты, для которых нужно каким-то образом организовать удаленный доступ до площадки. Довольно часто из-за ограничений существующей архитектуры сети и технологических сегментов удаленный доступ открывается напрямую из Интернета (по RDP, SSH) до терминальных серверов, с которых уже осуществляется наладка оборудования посредством специализированного ПО. И по-другому организовать этот доступ просто нет возможности. Да, можно открывать доступ по заявке и в строго определенное технологическое окно, ограничить адреса, с которых будут разрешены подключения к терминальному серверу, но все же остается риск перехвата RDP/SSH сессии, эксплуатации уязвимостей ОС из сети Интернет, проникновения в технологическую сеть через АРМ инженера-наладчика, заражения бэкдором данного терминального сервера и т.п.
Так как «закрыть» данную процессную уязвимость нет возможности, в качестве компенсирующей меры можно предложить усиленный мониторинг данных терминальных серверов и активности на них, а именно:
- Контролировать любую активность (в т.ч. сетевую активность в ОС в ППО) вне согласованных технологических окон.
- Запрофилировать сетевую активность, а также собрать профиль аутентификации на данных терминальных серверах, чтобы видеть отклонения от обычного процесса в части новых подключений, аутентификации с неразрешенных адресов или учеток.
- Выявлять ранее не известные/не запрофилированные процессы, установку служб и нового ПО.
- Контролировать изменения критичных системных директорий и веток реестра.
- Выявлять подозрительные и вредоносные объекты посредством АВПО, коррелируя их с активностью на хосте в окрестностях его запуска.
- Контролировать внешние подключения, включая неуспешные попытки доступа к хосту извне.
- Выявлять события изменения настроек хостового межсетевого экрана, а также изменения ACL на сетевом файерволле, который разграничивает доступ к данному терминальному серверу и от него.
- Контролировать создание локальных учетных записей, повышение привилегий у существующих и т.д.
Эти меры хоть и не позволят предотвратить факт взлома или нелегитимных действий в рамках рассмотренного процесса, но помогут вовремя выявить их и отреагировать.
Контроль защищенности — с чего начать
Мы предлагаем начать подход к задачам контроля защищенности со следующих действий:
- Провести целостную инвентаризацию периметра — способы и каналы выхода в Интернет, используемые внешние адреса, системы, доступные из Интернета, сервисы и протоколы. Даже на этом шаге зачастую удается зафиксировать некоторое количество забытых уязвимых сервисов и административных портов, открытых из сети Интернет.
Например, для внешнего периметра можно провести инвентаризационное сканирование и результаты добавить в SIEM. В данном случае сразу будет понятно, что и как фиксируется в логах, и, сравнив результаты с выводом сканера, останется просто заполнить описания.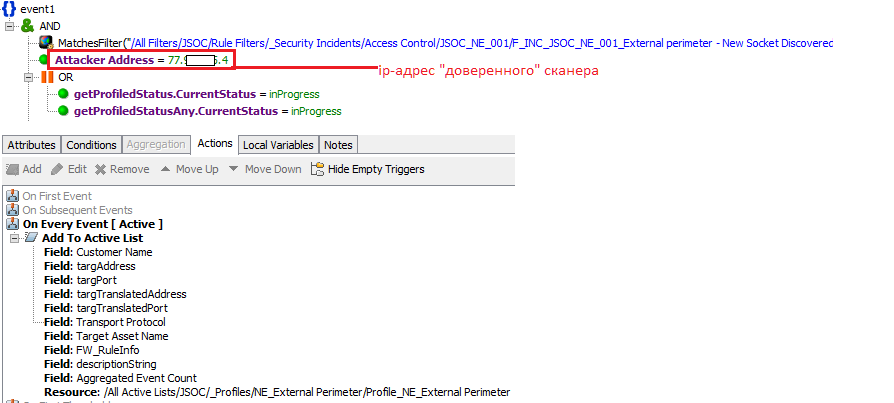
- Оценить общее состояние базовых средств защиты (антивирус, FW, Proxy) с точки зрения ширины их покрытия: охватывают ли они всю инфраструктуру, актуальны ли используемые политики и сигнатуры и т.д.
- В «крупную клетку» нарисовать сетевую инфраструктуру компании — разделение по подсетям в функциональном смысле, наличие сегментации, возможности по мониторингу взаимодействий и отделению одного сегмента от другого.
Например, мы в первую очередь пытаемся выделить следующие сегменты сети:
- DMZ.
- Внешняя адресация.
- Гостевой Wifi и иные сети, в которых есть хосты, не контролируемые средствами защиты компании.
- Локальный VPN-пул адресов.
- Отдельные закрытые сегменты (у нас это, например, сегмент АРМ'ов Solar JSOC, банк-клиент и сегмент для тестирования малвари).
- Провести сканирование и периметра, и внутренней инфраструктуры на уязвимости, посмотреть на общее состояние, выделить наиболее критичные проблемы, которые необходимо или закрыть, или поставить на мониторинг.
- Поставить на регулярный контроль и актуализацию указанные срезы информации. Как вариант, для начала можно сосредоточиться на отчетах. И, постепенно анализируя информацию и улучшая процесс, приходить к алертам.
Даже этот не очень трудоемкий срез информации позволит сделать первый подход к пониманию фактической защищенности своей инфраструктуры. Ну, а далее дорогу осилит идущий… или ждите наших следующих статей :)
