SNA Hackathon 2019
В феврале-марте 2019 года проходил конкурс по ранжированию ленты социальной сети SNA Hackathon 2019, в котором наша команда заняла первое место. В статье я расскажу про организацию конкурса, методах, которые мы попробовали, и настройках catboost для обучения на больших данных.

SNA Hackathon
Хакатон под таким названием проводится уже в третий раз. Организован он социальной сетью ok.ru, соответственно задача и данные имеют непосредственное отношение к этой соцсети.
SNA (social network analysis) в данном случае правильнее понимать не как анализ социального графа, а скорее как анализ социальной сети.
- В 2014 году задачей было спрогнозировать количество лайков, которые наберет пост.
- В 2016 году — задача ВВЗ (возможно вы знакомы), более приближенная к анализу социального графа.
- В 2019 году — ранжирование ленты пользователя по вероятности, что пользователь лайкнет пост.
Не могу сказать про 2014 год, но в 2016 и 2019 годах, кроме способностей к анализу данных, также требовались навыки работы с большими данными. Думаю, что именно объединение задач машинного обучения и обработки больших данных меня привлекло на эти конкурсы, а опыт в этих областях помог одержать победу.
mlbootcamp
В 2019 году конкурс был организован на платформе https://mlbootcamp.ru.
Конкурс начался в онлайн режиме 7 февраля и состоял из 3 задач. Все желающие могли зарегистрироваться на сайте, скачать baseline и загрузить свою машину на несколько часов. По окончании онлайн этапа 15 марта топ-15 каждого конкура были приглашены в офис Mail.ru на офлайн этап, который проходил с 30 марта по 1 апреля.
В исходных данных предоставлены идентификаторы пользователей (userId) и идентификаторы постов (objectId). Если пользователю показывали пост, то в данных есть строчка, содержащая userId, objectId, реакции пользователя на этот пост (feedback) и набор различных признаков или ссылок на картинки и тексты.
| userId | objectId | ownerId | feedback | images |
|---|---|---|---|---|
| 3555 | 22 | 5677 | [liked, clicked] | [hash1] |
| 12842 | 55 | 32144 | [disliked] | [hash2, hash3] |
| 13145 | 35 | 5677 | [clicked, reshared] | [hash2] |
Тестовый набор данных содержит аналогичную структуру, но отсутствует поле feedback. Задачей является предсказать наличие реакции 'liked' в поле feedback.
Файл сабмита имеет следующую структуру:
| userId | SortedList[objectId] |
|---|---|
| 123 | 78,13,54,22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Метрика — средний ROC AUC по пользователям.
Более подробное описание данных можно найти на сайте совернования. Также там можно скачать данные, включая тесты и картинки.
Онлайн этап
На онлайн этапе задача была разбита на 3 части
Офлайн этап
На офлайн этапе данные включали все признаки, при этом тексты и изображения были разреженные. Строк в датасете, которых и без того было много, стало в 1,5 раза больше.
Так как на работе занимаюсь cv, я начал свой путь в этом конкурсе с задачи «Изображения». Данные, которые были предоставлены, — это userId, objectId, ownerId (группа в которой опубликован пост), timestamps создания и показа поста и, конечно, изображение к этому посту.
После генерации нескольких фич, основанных на timestamp, следующей идеей было взять предпоследний слой предобученной на imagenet нейронки и отправить эти эмбеддинги в бустинг.
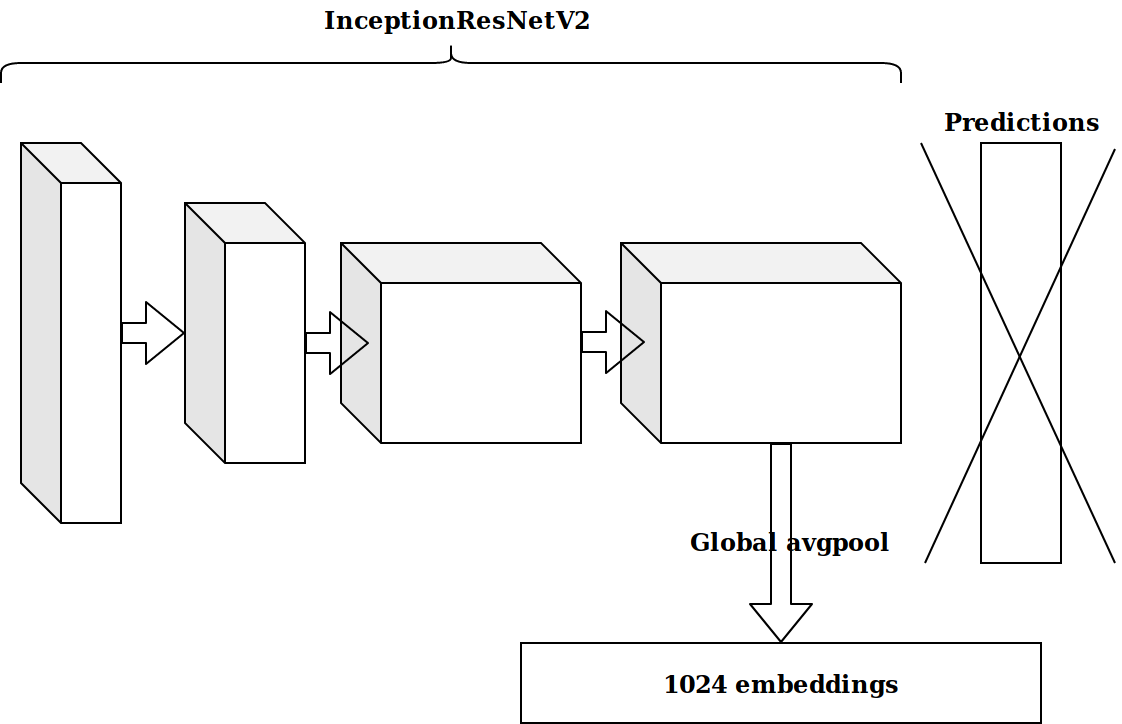
Результаты получились не впечатляющие. Эмбеддинги с нейронки imagenet нерелевантны, подумал я, надо запилить свой автоэнкодер.
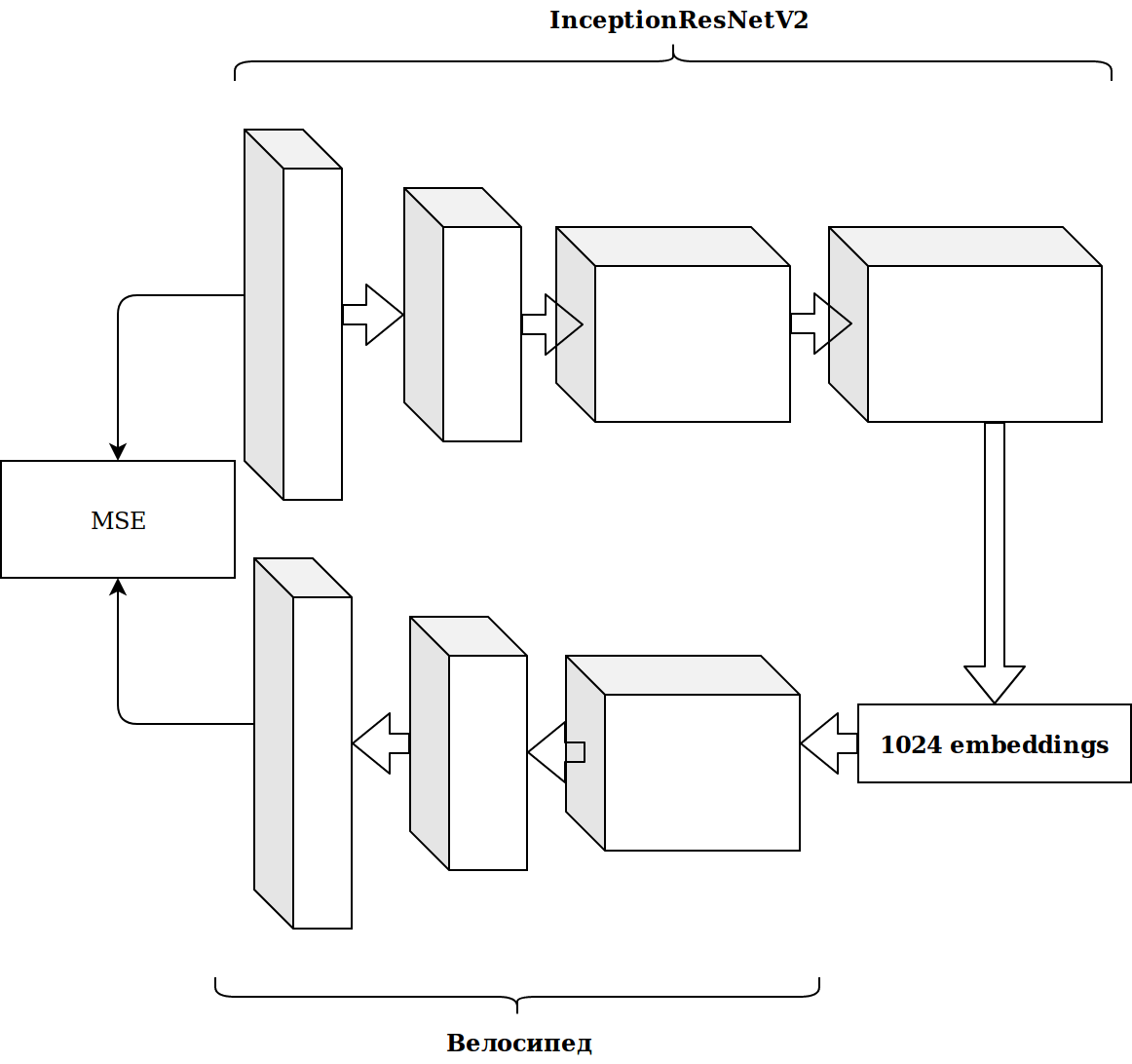
Это заняло немало времени, а результат не улучшился.
Генерация фич
Работа с изображениями занимает много времени, и я решил заняться чем-то более простым.
Как сразу видно, в датасете есть несколько категориальных признаков, и чтобы сильно не заморачиваться, я просто взял catboost. Решение было отличное, без каких-либо настроек я сразу попал на первую строчку лидерборда.
Данных достаточно много и выложены они в формате parquet, поэтому я, недолго думая, взял scala и начал писать всё на spark.
Простейшие фичи, которые дали больше прироста, чем эмбеддинги изображений:
- сколько раз встречался objectId, userId и ownerId в данных (должно коррелировать с популярностью);
- сколько постов userId видел у ownerId (должно коррелировать с интересом пользователя к группе);
- сколько уникальных userId смотрели посты у ownerId (отражает размер аудитории группы).
Из timestamps можно было получить время суток, в которое пользователь смотрел ленту (утро/день/вечер/ночь). Совместив эти категории, можно продолжать генерировать фичи:
- сколько раз userId заходил вечером;
- в какое время чаще показывают этот пост (objectId) и так далее.
Всё это постепенно улучшало метрику. Но размер обучающего датасета около 20М записей, поэтому добавление фич сильно замедляло обучение.
Я пересмотрел подход к использованию данных. Хотя данные и являются time-dependent, явных утечек информации «в будущем» я не видел, тем не менее на всякий случай разбил так:
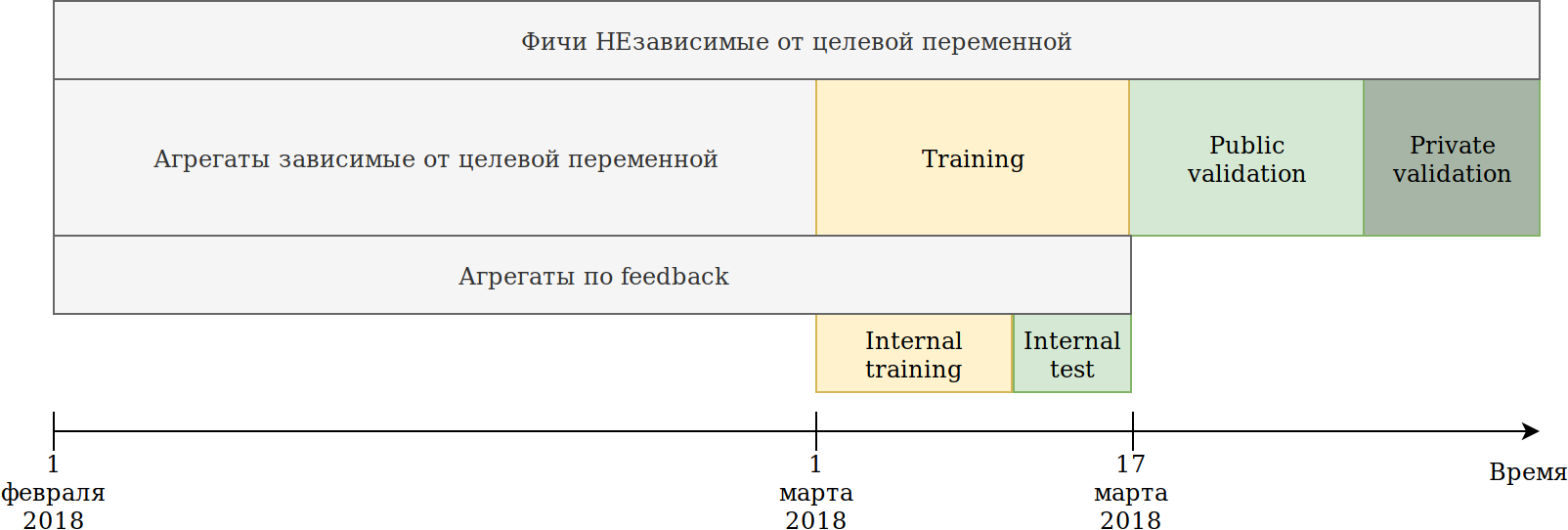
Предоставленный нам обучающий набор (февраль и 2 недели марта) разбил на 2 части.
На данных последних N дней обучал модель. Агрегации, которые описал выше, строил на всех данных, включая тест. При этом появились данные, на которых можно строить различные энкодинги целевой переменной. Самый простой подход заключается в том, чтобы переиспользовать код, который уже создает новые фичи, и просто подать ему данные, на которых не будет производится обучение и target = 1.
Таким образом, получились подобные фичи:
- Сколько раз userId видел пост в группе ownerId;
- Сколько раз userId лайкнул пост группе ownerId;
- Процент постов которые userId лайкнул у ownerId.
То есть получился mean target encoding на части датасета по различным комбинациям категориальных признаков. В принципе, catboost тоже строит target encoding и с этой точки зрения выгоды никакой, но, например, стало возможным посчитать количество уникальных пользователей, которые лайкали посты в этой группе. В тоже время, достигнута основная цель — мой датасет уменьшился в несколько раз, и можно было продолжать генерацию фич.
В то время как catboost может строить энкодинг только по реакции liked, в feedback есть другие реакции: reshared, disliked, unliked, clicked, ignored, энкодинги по которым можно сделать руками. Я пересчитывал всевозможные агрегаты и отсеивал фичи с низкой важностью, чтобы не раздувать датасет.
К тому времени я был на первом месте с большим отрывом. Смущало только то, что эмбеддинги изображений почти не давали прироста. Пришла идея отдать всё на откуп catboost. Кластеризуем изображения Kmeans и получаем новую категориальную фичу imageCat.
Вот некоторые классы после ручной фильтрации и мерджинга кластеров, полученных от KMeans.

На основе imageCat генерируем:
- Новые категориальные фичи:
- Какую imageCat чаще всего смотрел userId;
- Какую imageCat чаще всего показывает ownerId;
- Какую imageCat чаще всего лайкал userId;
- Различные счетчики:
- Сколько уникальных imageCat смотрел userId;
- Около 15 подобных фич плюс target encoding как описано выше.
Тексты
Результаты в конкурсе изображений меня устраивали и я решил попробовать себя в текстах. Раньше я много не работал с текстами и, по глупости, убил день на tf-idf и svd. Потом увидел baseline с doc2vec, который делает как раз то, что мне нужно. Немного настроив параметры doc2vec, получил эмбеддинги текстов.
А дальше просто переиспользовал код для изображений, в котором заменил эмбеддинги изображений эмбеддингами текстов. В результате попал на 2 место в конкурсе текстов.
Коллаборативная система
Оставался один конкурс, в который я ещё не «потыкал палкой», а судя по AUC на лидерборде, результаты именно этого конкурса сильнее всего должны были повлиять на офлайн этапе.
Я взял все признаки, которые были в исходных данных, выбрал категориальные и рассчитал те же агрегаты, что и для изображений, кроме фич по самим изображениям. Просто засунув это в catboost, я попал на 2 место.
Одно первое и два вторых места меня радовали, но было понимание того, что ничего особенного я не сделал, а значит можно ожидать потери позиций.
Задача конкурса — ранжирование постов в рамках пользователя, а я всё это время решал задачу классификации, то есть оптимизировал не ту метрику.
Приведу простой пример:
| userId | objectId | prediction | ground truth |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
Делаем небольшую перестановку
| userId | objectId | prediction | ground truth |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
Получаем следующие результаты:
| Модель | AUC | User1 AUC | User2 AUC | mean AUC |
|---|---|---|---|---|
| Вариант 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Вариант 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Как видно, улучшение метрики общего AUC не означает улучшения метрики среднего AUC в рамках пользователя.
Catboost умеет оптимизировать метрики ранжирования из коробки. Я почитал про ранжирующие метрики, истории успеха при использовании catboost и поставил обучаться YetiRankPairwise на ночь. Результат получился не впечатляющим. Решив что я недообучился, я поменял функцию ошибки на QueryRMSE, которая, судя по документации catboost, быстрее сходится. В итоге получил те же результаты, что и при обучении на классификацию, но ансамбли этих двух моделей давали хороший прирост, который вывел меня на первые места во всех трех конкурсах.
За 5 минут до закрытия онлайн этапа в конкурсе «Коллаборативнае системы» Сергей Шальнов подвинул меня на второе место. Дальнейший путь мы проходили вместе.
Победа в онлайн этапе нам гарантировала по видеокарте RTX 2080 TI, но главный приз в 300 000 рублей и, скорее даже, финальное первое место заставили нас поработать эти 2 недели.
Как оказалось, Сергей тоже использовал catboost. Мы обменялись идеями и фичами, и я узнал про доклад Анны Вероники Дорогуш в котором были ответы на многие мои вопросы, и даже на те, которые у меня к тому времени ещё не появились.
Просмотр доклада привел меня к мысли, что надо вернуть все параметры в дефолтное значение, а настройкой заниматься очень аккуратно и только после фиксации набора признаков. Теперь одно обучение занимало около 15 часов, но удалось одной моделью получить скор лучше, чем получался в ансамбле с ранжированием.
Генерация фич
В конкурсе «Коллаборативные системы» большое количество признаков оцениваются как важные для модели. Например, auditweights_spark_svd — самый важный признак, при этом нет информации о том, что он означает. Я подумал, что стоит посчитать различные агрегаты, основываясь на важных признаках. Например, средний auditweights_spark_svd по пользователю, по группе, по объекту. То же самое можно посчитать по данным, на которых не производится обучение и target = 1, то есть средний auditweights_spark_svd по пользователю по объектам, которые он лайкал. Важных признаков, помимо auditweights_spark_svd, было несколько. Вот некоторые из них:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
Например, среднее значение auditweightsCtrGender по userId оказалось важной фичей, так же, как и среднее значение userOwnerCounterCreateLikes по userId+ownerId. Это уже должно было заставить задуматься о том, что надо разбираться со смыслом полей.
Также важными фичами были auditweightsLikesCount и auditweightsShowsCount. Разделив одно на другое, получилась ещё более важная фича.
Утечки данных
Конкурс и продакшн модели — это очень разные задачи. При подготовке данных очень сложно учесть все детали и не передать какую то нетривиальную информацию о целевой переменной на тесте. Если мы создаем продакшн решение, то постараемся избежать использования утечек данных при обучении модели. Но если мы хотим выиграть конкурс, то утечки данных — это самые хорошие фичи.
Изучив данные, можно заметить, что по objectId значения auditweightsLikesCount и auditweightsShowsCount меняются, а значит отношение максимальных значений этих признаков значительно лучше отразит конверсию поста, чем отношение в момент показа.
Первая утечка, которую мы нашли,- это auditweightsLikesCountMax/auditweightsShowsCountMax.
А что если посмотреть на данные внимательнее? Отсортируем по дате показа и получим:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | target (is liked) |
|---|---|---|---|---|
| 1 | 1 | 12 | 3 | наверное, нет |
| 1 | 2 | 15 | 3 | наверное, да |
| 1 | 3 | 16 | 4 |
Удивительно было, когда я нашел первый такой пример и оказалось, что мое предсказание не сбылось. Но, учитывая тот факт, что максимальные значения этих признаков в рамках объекта давали прирост, мы не поленились и решили найти auditweightsShowsCountNext и auditweightsLikesCountNext, то есть значения в следующий момент времени. Добавив фичу
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) мы сделали резкий прыжок по скору.
Аналогичные утечки можно было использовать, если найти следующие значения для userOwnerCounterCreateLikes в рамках userId+ownerId и, например, auditweightsCtrGender в рамках objectId+userGender. Мы нашли 6 подобных полей с утечками и максимально вытащили из них информацию.
К тому моменту мы выжали максимум информации из коллаборативных признаков, но не возвращались к конкурсам изображений и текстов. Появилась отличная идея проверить:, а сколько же дают непосредственно фичи по изображениям или текстам в соответствующих конкурсах?
В конкурсах по изображениям и текстам не было утечек, но к тому времени я вернул дефолтные параметры catboost, причесал код и добавил несколько фич. Итого получилось:
| Решение | скор |
|---|---|
| Максимум с изображениями | 0.6411 |
| Максимум без изображений | 0.6297 |
| Результат второго места | 0.6295 |
| Решение | скор |
|---|---|
| Максимум с текстами | 0.666 |
| Максимум без текстов | 0.660 |
| Результат второго места | 0.656 |
| Решение | скор |
|---|---|
| Максимум в коллаборативных | 0.745 |
| Результат второго места | 0.723 |
Стало очевидно, что из текстов и изображений вряд ли удастся выжать много, и мы, попробовав пару самых интересных идей, бросили с ними работать.
Дальнейшая генерация признаков в коллаборативных системах не давала прироста, и мы занялись ранжированием. На онлайн этапе ансамбль классификации и ранжирования давал мне небольшой прирост, как оказалось потому, что я недообучал классификацию. Ни одна из функций ошибок, включая YetiRanlPairwise даже близко не давала того результата, который давал LogLoss (0,745 против 0,725). Оставалась надежда на QueryCrossEntropy, которую не удавалось запустить.
На офлайн этапе структура данных осталась прежней, но были небольшие изменения:
- идентификаторы userId, objectId, ownerId были перерандомизированы;
- несколько признаков убрали и несколько переименовали;
- данных стало примерно в 1,5 раза больше.
Помимо перечисленых сложностей был один большой плюс: на команду выделяли большой сервер с RTX 2080TI. Я долго наслаждался htop.
Идея была одна — просто воспроизвести то, что уже есть. Потратив пару часов на настройку окружения на сервере, мы постепенно начали проверять, что результаты воспроизводятся. Основная проблема, с которой мы столкнулись, — это увеличение объема данных. Мы решили немного уменьшить нагрузку и установили параметр catboost ctr_complexity=1. Это немного понижает скор, но моя модель начала работать, результат был хороший — 0,733. Сергей, в отличии от меня, не разбивал данные на 2 части и обучался на всех данных, хотя это и давало лучший результат на онлайн этапе, на офлайн этапе сложностей оказалось много. Если брать все фичи, которые мы нагенерили, и «в лоб» пытаться засунуть в catboost, то ничего не получилось бы и на онлайн этапе. Сергей делал оптимизацию типов, например, преобразование типов float64 в float32. В этой статье можно найти информацию по оптимизации памяти в pandas. В итоге Сергей обучился на CPU на всех данных и получилось около 0,735.
Этих результатов было достаточно для победы, но мы скрывали свой настоящий скор и не могли быть уверенными, что другие команды не делают то же самое.
Тюнинг catboost
Наше решение полностью воспроизвелось, фичи текстовых данных и изображений мы добавили, поэтому оставалось только тюнить параметры catboost. Сергей обучился на CPU с небольшим количеством итераций, а я обучился на с ctr_complexity=1. Оставался один день, и если просто добавить итераций или увеличить ctr_complexity, то можно было к утру получить ещё более хороший скор, и весь день гулять.
На офлайн этапе скоры можно было очень легко скрывать, просто выбирая не самое лучшее решение на сайте. Мы ожидали резкие изменения в лидерборде в последние минуты до закрытия сабмитов и решили не останавливаться.
Из видео Анны я узнал, что для улучшения качества модели лучше всего подбирать следующие параметры:
- learning_rate — Дефолтное значение рассчитывается на основании размера датасета. Увеличение learning_rate требует увеличения количества итераций.
- l2_leaf_reg — Коэффициент регуляризации, дефолтное значение 3, выбирать желательно от 2 до 30. Уменьшение значения ведет к увеличению оверфита.
- bagging_temperature — добавляет рандомизацию весам объектов в выборке. Дефолтное значение 1, при котором веса выбираются из экспоненциального распределения. Уменьшение значения ведет к увеличению оверфита.
- random_strength — Влияет на выбор сплитов на конкретной итерации. Чем выше random_strength, тем выше шанс у сплита с низкой важностью быть выбранным. На каждой следующей итерации рандомность понижается. Уменьшение значения ведет к увеличению оверфита.
Другие параметры значительно меньше влияют на конечный результат, поэтому я не пытался их подбирать. Одна итерация обучения на моем датасете на GPU с ctr_complexity=1 занимала 20 минут, а подобранные параметры на уменьшенном датасете немного отличались от оптимальных на полном датасете. В итоге я сделал около 30 итераций на 10% данных, а потом ещё около 10 итераций на всех данных. Получилось примерно следующее:
- learning_rate я увеличил на 40% от дефолтного;
- l2_leaf_reg оставил прежней;
- bagging_temperature и random_strength уменьшил до 0,8.
Можно сделать вывод, что с дефолтными параметрами модель недообучалась.
Я был очень удивлен, когда увидел результат на лидерборде:
| Модель | модель 1 | модель 2 | модель 3 | ансамбль |
|---|---|---|---|---|
| Без тюнинга | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| С тюнингом | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
Я сделал для себя вывод, что если не нужно быстрое применение модели, то подбор параметров лучше заменить ансамблем нескольких моделей на неоптимизированных параметрах.
Сергей занимался оптимизацией размера датасета для запуска его на GPU. Самый простой вариант — это отрезать часть данных, но это можно сделать несколькими способами:
- постепенно убирать самые старые данные (начало февраля), пока датасет не начнет помещаться в память;
- убрать фичи с самой низкой важностью;
- убрать userId, по которым есть только одна запись;
- оставить только userId, которые есть в тесте.
А в конечном итоге — сделать ансамбль из всех вариантов.
Последний ансамбль
К позднему вечеру последнего дня мы выложили ансамбль наших моделей, который давал 0,742. На ночь я запустил свою модель с ctr_complexity=2 и вместо 30 минут она обучалась 5 часов. Только в 4 утра она досчиталась, и я сделал последний ансамбль, который на публичном лидерборде дал 0,7433.
За счет разных подходов к решению задачи, наши предсказания не сильно коррелировали, что дало хороший прирост в ансамбле. Для получения хорошего ансамбля лучше использовать сырые предсказания модели predict (prediction_type='RawFormulaVal') и установить scale_pos_weight=neg_count/pos_count.
На сайте можно увидеть финальные результаты на приватном лидерборде.
Другие решения
Многие команды следовали канонам алгоритмов рекомендательных систем. Я, не будучи экспертом в этой области, не могу их оценить, но запомнилось 2 интересных решения.
- Решение Николая Анохина. Николай, являясь сотрудником Mail.ru, не претендовал на призы, поэтому ставил перед собой целью не получение максимального скора, а получение легко масштабируемого решения.
- Решение команды, получившей приз жюри, основанное на этой статье от facebook, позволило очень хорошо кластеризовать изображения без ручной работы.
Что больше всего отложилось в памяти:
- Если в данных есть категориальные фичи, и вы знаете как правильно делать target encoding, все равно лучше попробовать catboost.
- Если вы участвуете в конкурсе, не стоит тратить время на подбор параметров, кроме learning_rate и iterations. Более быстрое решение — сделать ансамбль нескольких моделей.
- Бустинги умеют обучаться на GPU. Catboost умеет очень быстро обучаться на GPU, но кушает много памяти.
- Во время разработки и проверки идей лучше установить небольшой rsm~=0.2 (CPU only) и ctr_complexity=1.
- В отличии от других команд, ансамбль наших моделей дал большой прирост. Мы обменивались только идеями и писали на разных языках. У нас был разный подход к разбиению данных и, думаю, у каждого были свои баги.
- Непонятно почему оптимизация ранжирования давала результат хуже, чем оптимизация классификации.
- Я получил небольшой опыт работы с текстами и понимание, как делаются рекомендательные системы.

Спасибо организаторам за полученные эмоции, знания и призы.
