Сколько места в куче занимают 100 миллионов строк в Java?
Чтобы оценить масштаб бедствия, мы решили провести простой эксперимент — создать 100 миллионов пустых строк в Яве и посмотреть, сколько придётся заплатить за них оперативной памяти.
Внимание: В конце статьи приведён опрос. Будет интересно, если вы попробуете ответить на него до прочтения статьи, для самоконтроля.
Правилом хорошего тона при проведении любых замеров считается опубликовать версию виртуальной машины и параметры запуска теста:
> java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
Сжатие указателей включено (читай: размер кучи меньше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:+UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
Сжатие указателей выключено (читай: размер кучи больше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:-UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
Исходный код самого теста:
package ru.habrahabr.experiment;
import org.apache.commons.lang3.time.StopWatch;
import java.util.ArrayList;
import java.util.List;
public class HundredMillionEmptyStringsExperiment {
public static void main(String[] args) throws InterruptedException {
List lines = new ArrayList<>();
StopWatch sw = new StopWatch();
sw.start();
for (int i = 0; i < 100_000_000L; i++) {
lines.add(new String(new char[0]));
}
sw.stop();
System.out.println("Created 100M empty strings: " + sw.getTime() + " millis");
// чтобы не сохранять лишнего и было проще анализировать снимок кучи
System.gc();
// защита от оптимизаций
while (true) {
System.out.println("Line count: " + lines.size());
Thread.sleep(10000);
}
}
}
Процесс
Ищем идентификатор процесса с помощью утилиты jps и делаем снимок кучи (heap dump) с помощью jmap:
> jps
12777 HundredMillionEmptyStringsExperiment
> jmap -dump:format=b,file=HundredMillionEmptyStringsExperiment.bin 12777
Dumping heap to E:\jdump\HundredMillionEmptyStringsExperiment.bin ...
Heap dump file created
Анализируем снимок кучи, используя Eclipse Memory Analyzer (MAT):
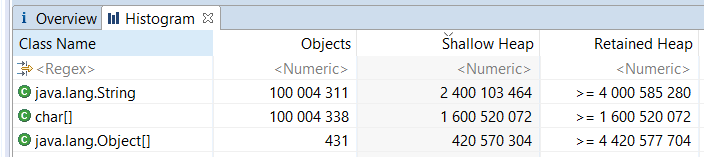

Для второго теста с выключенным сжатием указателей снимки не приводим, но мы честно провели эксперимент и просим поверить на слово (оптимально: воспроизвести тест и убедиться самим).
Выводы
- 2.4 Гб занимает обвязка объектов класса String + указатели на массивы символов.
- 1.6 Гб занимает обвязка массивов символов.
- 400 Мб занимают указатели на строки.
Если вы работаете с размером кучи больше 32Гб (сжатие указателей выключено), то указатели будут стоить ещё дороже. Соответственно будут такие результаты:
- 3.2 Гб занимает обвязка объектов класса String + указатели на массивы символов.
- 2.4 Гб занимает обвязка массивов символов.
- 800 Мб занимают указатели на строки.
Итого, за каждую строку вы дополнительно к размеру массива символов платите 44 байта (64 байта без сжатия указателей). Если средняя длина строк составляет 15 символов, то получается почти 5 байт на каждый символ. Запретительно дорого, если речь идёт о домашнем железе.
Как бороться
К сожалению в Яве не существует встроенных механизмов, чтобы напрямую сократить потребление памяти при работе со строками. Существуют две основные стратегии для экономии ресурсов:
- Для большого количества дублирующихся строк можно использовать интернирование (string interning). Суть механизма такая: поскольку строки в Яве неизменяемые, то можно хранить их в отдельном пуле и при повторе ссылаться на существующий объект вместо создания новой строки. Такой подход не бесплатен — он стоит и памяти и процессорного времени для хранения структуры пула и поиска в нём.
- Если, как в нашем случае, строки уникальные — не остаётся ничего другого как использовать различные алгоритмические трюки. Мини-анонс: как мы работаем с сотней миллионов биграмм (читай: слово + слово или 15 символов) в наших задачах расскажем в самое ближайшее время.
В заключение
Решение любой проблемы начинается с оценки её масштабов. Теперь вы эти масштабы знаете и можете учитывать накладные расходы при работе с большим количеством строк в своих проектах.
Комментарии (2)
 doom369
doom369
15 октября 2016 в 15:50 (комментарий был изменён)
0↑
↓
К сожалению в Яве не существует встроенных механизмов, чтобы напрямую сократить потребление памяти при работе со строками
Существуют. Вы можете работать с массивом байт вместо класса String. Как, например, это делают в проекте Netty (смотреть класс AsciiString). Так же в Java 9 на подходе JEP 254.15 октября 2016 в 16:07 (комментарий был изменён)
0↑
↓
Не согласен.1) Массив байт даёт выигрыш в 1 байт на символ (из пяти!). Просто по той причине, что если вы хотите использовать .hashCode и .equals, вам придётся положить массив в объект-контейнер, который будет отвечать за хэширование и сравнение.
2) Это ни разу не встроенный механизм, а свой велосипед.
3) JEP 254 — это хотя бы намёк на то, что разработчики знают о существовании проблемы. Но это опять же экономия в 1 байт для строк с латиницей. Для национальных языков выигрыш отсутствует.Основной расход памяти здесь не на сами символы (в тесте их просто нет), а на дорогущие обвязки объектов и неспособность Java хранить объектные поля рядом с самим экземпляром. Есть подстольные решения для последнего, но это ещё более велосипед.
