Сколько кода на C++ нужно написать для разбора HTTP-заголовка Authorization с помощью easy_parser из RESTinio?
Мы продолжаем развивать бесплатный и открытый встраиваемый в С++ приложения HTTP-сервер RESTinio. В реализации RESTinio активно используются C++ные шаблоны, о чем мы здесь регулярно рассказываем (недавний пример).
Одной из точек приложения C++ной шаблонной магии стал easy_parser, небольшая реализация нисходящего рекурсивного парсера на базе PEG. Easy_parser был добавлен в RESTinio в прошлом году для того, чтобы упростить работу с HTTP-заголовками.
Мы уже немного обсуждали easy_parser-е в предыдущей статье. А сегодня хочется показать как же easy_parser применяется при разработке RESTinio. На примере разбора содержимого HTTP-заголовка Authorization. Попробуем, так сказать, заглянуть в потроха RESTinio.
Структура заголовка Authorization определена в RFC7235 следующим образом:
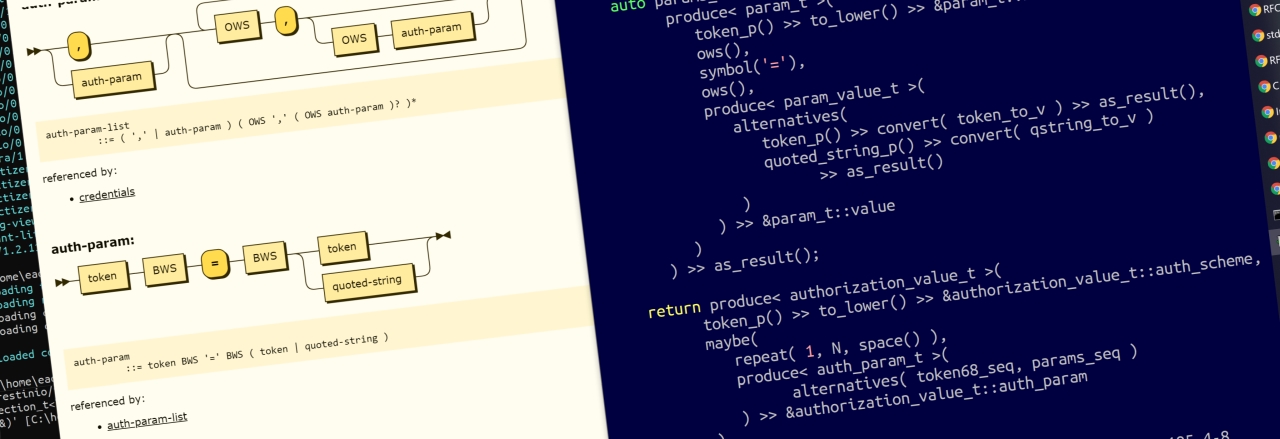
authorization-field = "Authorization" ":" OWS credentials
credentials = auth-scheme [ 1*SP ( token68 / [ #auth-param ] ) ]
auth-scheme = token
auth-param = token BWS "=" BWS ( token / quoted-string )
token68 = 1*( ALPHA / DIGIT / "-" / "." / "_" / "~" / "+" / "/" ) *"="Т.е. значение заголовка Authorization должно включать в себя обязательное название схемы аутентификации и опциональные параметры для этой схемы.
Если параметры для схемы аутентификации заданы, то они могут быть представлены либо специальным значением token68 (некая строка, закодированная в base64), либо списком параметров в виде «имя=значение».
Что требуется получить в итоге?
Особенностью easy_parser является то, что он производит нужные пользователю значения в процессе разбора и результатом разбора является либо объект с полученными в результате разбора данными, либо код ошибки.
Поэтому прежде чем мы перейдем к рассмотрению правил разбора, нужно посмотреть на типы для объектов, которые должны получиться в итоге разбора:
struct authorization_value_t
{
enum class value_form_t { token, quoted_string };
struct param_value_t
{
std::string value;
value_form_t form;
};
struct param_t
{
std::string name;
param_value_t value;
};
using param_container_t = std::vector< param_t >;
struct token68_t
{
std::string value;
};
using auth_param_t = variant_t< token68_t, param_container_t >;
std::string auth_scheme;
auth_param_t auth_param;
};Результатом разбора должен стать экземпляр структуры authorization_value_t с двумя полями: auth_scheme и auth_params. При этом auth_params — это либо значение типа token68_t, либо список параметров, каждый из которых представлен структурой param_t.
Разбор значения Authorization
Главный producer
Итак, у нас есть структура, экземпляр которой мы хотим получить. Осталось написать несколько (или чуть больше) строчек, в которых и будет указано, из чего и как этот экземпляр будет строится:
auto make_parser()
{
... // Самое интересное здесь, но скрыто до поры, до времени.
return produce< authorization_value_t >(
token_p() >> to_lower() >> &authorization_value_t::auth_scheme,
maybe(
repeat( 1, N, space() ),
produce< auth_param_t >(
alternatives( token68_seq, params_seq )
) >> &authorization_value_t::auth_param
)
);
}Функция make_parser создает и возвращает объект-продюсер, который отвечает за парсинг и формирование объекта типа authorization_value_t. Этот объект формируется вызовом шаблонной функции produce, параметризуемой типом результирующего значения. А аргументами для produce являются правила грамматики, сформулированные посредством C++ного DSL.
В данном случае правила тривиальны:
- мы ожидаем token (в смысле RFC7230). Значение этого token-а должно быть преобразовано в нижний регистр и сохранено в поле
auth_schemeструктурыauthorization_value_t; - далее следует опциональная часть, которая может присутствовать, а может и отсутствовать, поэтому она описывается внутри
maybe; - опциональная часть начинается с одного или нескольких пробелов;
- за пробелами следует либо token68, либо последовательность параметров. Что бы это не было, это идет в поле
auth_paramструктурыauthorization_value_tв виде экземпляраauth_param_t.
В общем-то пока все просто. И я бы даже сказал, что очевидно, если привыкнуть к easy_parser и его DSL.
Однако, эта простота возникает из-за того, что пока мы не видели, что же такое token68_seq и params_seq в представленном коде. Так что давайте устраним это упущение и попробуем узнать, насколько глубока кроличья нора ;)
Что же такое token68_seq?
Идентификатор token68_seq в коде выше — это всего лишь локальная переменная, которая определяется внутри make_parser следующим образом:
auto token68_seq = sequence(
token68_p() >> as_result(),
not_clause( any_symbol_p() >> skip() ) );Здесь говорится о том, что token68_seq — это цепочка правил. Первое правило ожидает наличие token68 и, если таковой встретится, то его значение возвращается в качестве результата.
А вот дальше идет специальное правило, которое говорит, что во входном потоке после извлечения token68 ничего больше не должно остаться. Это правило использует такую особенность PEG, как not-predicate. Not-pedicate задает выражение, которое должно оказаться ложным, чтобы правило сработало. И при этом символы из входного потока, которые были использованы для проверки not-predicate, автоматически возвращаются обратно во входной поток.
Это специальное правило было использовано здесь потому, что по RFC7617 выходит, что если встретился token68, то он должен быть единственным значением. Поэтому мы дополнительно проверили, что после разбора token68 во входном потоке ничего не осталось. Если же осталось, то следует попробовать другие альтернативные варианты.
В разговоре о token68_seq осталось показать, что такое token68_p и что за ним скрывается. А скрывается вот что:
struct is_token68_char_predicate_t
: protected hfp_impl::is_alphanum_predicate_t
{
using base_type_t = hfp_impl::is_alphanum_predicate_t;
bool operator()( const char actual ) const noexcept
{
return base_type_t::operator()(actual)
|| '-' == actual
|| '.' == actual
|| '_' == actual
|| '~' == actual
|| '+' == actual
|| '/' == actual
;
}
};
inline auto token68_symbol_p()
{
return restinio::easy_parser::impl::symbol_producer_template_t<
is_token68_char_predicate_t >{};
}
inline auto token68_p()
{
return produce< token68_t >(
produce< std::string >(
repeat( 1, N, token68_symbol_p() >> to_container() ),
repeat( 0, N, symbol_p('=') >> to_container() )
) >> &token68_t::value
);
}Кода много, но повышенное внимание к себе может потребовать разве что код функции token68_p. А вот тип is_token68_char_predicate_t и функция token68_symbol_p — это вынужденная рутина. Дело в том, что в easy_parser есть ряд готовых продюсеров для символов, попадающих в какие-то категории, например: digit_p, space_p, hexdigit_p, alpha_symbol_p, alphanum_symbol_p и т.д. Но вот такого продюсера, который бы извлекал из входного потока символы, которые могут встречаться именно в token68, не было. Поэтому и пришлось сделать is_token68_char_predicate_t плюс token68_symbol_p специально для этих целей.
Внутри же token68_p правила разбора значение token68 описывается чуть ли один-в-один как в грамматике: сперва от одного и более символов из множества token68, затем ноль или более символов =. И каждый извлеченный символ должен попасть в результирующее значение.
Что такое params_seq?
Вот мы и подобрались к наиболее зубодробительному фрагменту, в котором определяется params_seq. Для того, чтобы вся картинка была перед глазами, я приведу еще раз код make_parser, но уже полностью:
auto make_parser()
{
auto token_to_v = []( std::string v ) -> param_value_t {
return { std::move(v), value_form_t::token };
};
auto qstring_to_v = []( std::string v ) -> param_value_t {
return { std::move(v), value_form_t::quoted_string };
};
auto token68_seq = sequence(
token68_p() >> as_result(),
not_clause( any_symbol_p() >> skip() ) );
// Список параметров вида name=value может быть пустым.
auto params_seq = maybe_empty_comma_separated_list_p< param_container_t >(
produce< param_t >(
token_p() >> to_lower() >> ¶m_t::name,
ows(),
symbol('='),
ows(),
produce< param_value_t >(
alternatives(
token_p() >> convert( token_to_v ) >> as_result(),
quoted_string_p() >> convert( qstring_to_v )
>> as_result()
)
) >> ¶m_t::value
)
) >> as_result();
return produce< authorization_value_t >(
token_p() >> to_lower() >> &authorization_value_t::auth_scheme,
maybe(
repeat( 1, N, space() ),
produce< auth_param_t >(
alternatives( token68_seq, params_seq )
) >> &authorization_value_t::auth_param
)
);
}Начать можно с самого простого, с двух вспомогательных lambda-функций token_to_v и qstring_to_v. Они используются для того, чтобы взять значение типа std::string и породить новое значение типа param_value_t, в котором будет зафиксирована исходная форма значения параметра: был ли параметр представлен в виде token или же в виде quoted-string.
Эти вспомогательные лямбда-функции нужны потому, что при разборе правил для параметров в виде name=value из входного потока будут извлекаться экземпляры std::string, тогда как в итоге нам требуется иметь значение param_value_t, где кроме std::string будет еще и дополнительный флажок.
Ну, а теперь пришло время самого params_seq:
auto params_seq = maybe_empty_comma_separated_list_p< param_container_t >(
...
) >> as_result();Переменная params_seq хранит продюсера, который производит объект типа param_container_t. Это контейнер, который может быть пустым.
Функция maybe_empty_comma_separated_list_p является частью easy_parser-а и она реализует разбор списков, которые в RFC для HTTP описываются посредством правил вида #auth-param, где # раскрывается как:
[ ( "," / auth-param ) *( OWS "," [ OWS auth-param ] ) ]Так что при определении продюсера params_seq нам уже не нужно бодаться с разбором запятых, необязательных пробелов и их повторений. Можно сосредоточится именно на правилах для auth-param. А правило, в общем-то, вполне себе прямолинейное:
produce< param_t >(
token_p() >> to_lower() >> ¶m_t::name,
ows(),
symbol('='),
ows(),
produce< param_value_t >(
alternatives(
token_p() >> convert( token_to_v ) >> as_result(),
quoted_string_p() >> convert( qstring_to_v )
>> as_result()
)
) >> ¶m_t::value
)Здесь говорится, что мы будем пытаться формировать объекты типа param_t, для чего требуется выполнение следующих правил:
- сперва должен идти token, значение которого приводится к нижнему регистру и сохраняется в
param_t::name; - затем может идти ноль или более необязательных пробелов (функция
owsреализует понятиеOWS(т.е. optional whitespace) из RFC7230); - затем должен идти символ
=; - затем может идти ноль или более необязательных пробелов;
- затем мы ждем значение параметра (т.е. должны произвести объект типа
param_value_t), которое может возникнуть в результате одной из альтернатив: либо token, либо quoted-string. Если token, то берется его значение, пропускается через трансформаторtoken_to_v(который мы рассмотрели выше) и сохраняется результирующее значение трансформатора. Если же quoted-string, то мы делаем тоже самое, но с помощью трансформатораqstring_to_v; - полученный экземпляр
param_value_tсохраняется вparam_t::value.
Вот, собственно, и все.
В заключении хочется ответить на вопрос «А зачем и о чем была написана эта статья?» Точнее дать несколько ответов на этот вопрос.
Мы не упоролись плюсовыми шаблонами
Первый ответ, наименее очевидный, состоит в том, что мы хотим рассказывать не только о том, что RESTinio делает, но и как он это делает. В частности, о технических решениях, применяемых в реализации RESTinio.
Думаю, что эта информация несколько повышает степень доверия к нашей разработке. Ведь одно дело, когда человек заглядывает в исходники RESTinio, видит там шаблонную магию и думает, что это просто потому, что авторы упоролись шаблонами и пытаются проверить C++ные компиляторы на прочность. Совсем другое дело, когда принятые нами решения объяснены и аргументированы.
Сам по себе easy_parser появился в RESTinio не просто так, а как результат попытки добавить в RESTinio средства работы с HTTP-заголовками.
Заголовков этих много, какие-то простые по своей структуре, какие-то не очень. И нам нужно было либо писать парсинг каждого заголовка вручную (что трудоемко и чревато ошибками, поэтому невыгодно), либо найти способ упростить себе работу за счет использования какого-то парсера на основе формальных грамматик.
Использование парсера на базе грамматик выглядело как наиболее подходящее решение, но вот вариант затащить в проект какой-то генератор парсеров (вроде bison, coco/r, ragel и пр.) рассматривался как нежелательный. RESTinio является header-only библиотекой (хоть и требует линковки к libhttp-parser). А использовать для разработки кросс-платформенной header-only библиотеки внешние генераторы кода выглядит так себе идеей. Кроме того, смущал вот какой момент: допустим, мы сгенерируем код для разбора каких-то штатных заголовков и этот код попадет в состав RESTinio, но что делать пользователю, которому захочется разобрать какой-нибудь нестандартный заголовок (или стандартный, но поддержки которого еще нет в RESTinio)? Писать разбор вручную или осваивать ragel или coco/r? Ну так себе выбор, как по мне.
Поэтому было решено сделать свой парсер, с описанием грамматик посредством C++ного DSL. Свой парсер потому, что затаскивать в RESTinio в качестве зависимости что-то из Boost-а или какой-нибудь PEGTL не хотелось, т.к. зависимости получались бы ну очень уж тяжелые. Кроме того, сторонние реализации парсеров (Boost.Spirit и PEGTL) используют исключения для информирования об ошибках, а также применяют не очень удобную для наших целей схему коллбэков для извлечения разобранных значений. И если с коллбэками еще можно было бы жить, то вот исключения показались show stopper-ом. Поэтому и возник easy_parser.
Cтатья продемонстрировала как выглядит добавление поддержки HTTP-заголовка в RESTinio с помощью easy_parser-а. Это может показаться чрезмерным усложнением.
Но…
На практике, после освоения easy_parser, написать показанный выше код не сложно. Это занимает совсем немного времени. Гораздо больше уходит на то, чтобы a) вкурить соответствующую часть RFC, b) понять, во что именно должно трансформироваться разобранное значение, какие структуры потребуются для хранения результата разбора, c) покрыть написанный парсер тестами и d) задокументировать это все. Так что, бывает, что общая работа по реализации поддержки какого-то не самого простого заголовка занимает 4–6 часов, из которых написание связанного с easy_parser-ом кода — это всего 15–20 минут.
Так что, хоть у easy_parser-а в RESTinio есть свои особенность и недостатки, все-таки его создание и использование в RESTinio пока что выглядит оправданным.
RESTinio живет и развивается
Второй же ответ на вопрос «А зачем и о чем была написана эта статья?» как раз тривиальный и очевидный: хотелось в очередной раз напомнить, что проект живет и развивается. Можно взять, попробовать, а потом поделиться с нами своими ощущениями: что понравилось, что не понравилось, чего не хватило, что сделано не так, как хотелось бы… Ко всем конструктивным замечаниям и предложениям мы прислушиваемся (думаю, что некоторые читатели смогут это подтвердить).
