Сказ о том, как мы Tarantool Kubernetes Operator писали
Kubernetes — это быстроразвивающийся opensource проект, позволяющий управлять контейнерами Linux как единой системой. Мы с лёгкостью можем запускать сложные системы, используя при этом yaml-конфигурации. Для управления системой применяются декларативные ресурсы. Иерархическая система ресурсов позволяет создавать большие системы с минимумом конфигов. Именно поэтому всё больше и больше людей переносит свою инфраструктуру внутрь Kubernetes, причём не только stateless-, но и statefull-приложения. Так зачем отказывать себе в удобстве и не использовать Tarantool внутри Kubernetes?
Привет, меня зовут Костя, и сегодня я расскажу про то, с чем мы столкнулись при разработке Tarantool Kubernetes Operator, Enterprise для Kubernetes / Openshift. Кому интересно — добро пожаловать под кат.

Tarantool — это эффективная платформа для in-memory вычислений и создания высоконагруженных приложений, сочетающая в себе базу данных и сервер приложений. Как база данных она обладает рядом уникальных характеристик — высокой эффективностью утилизации железа, гибкой схемой данных, поддержкой как in-memory, так и дискового хранилища, возможностью расширения за счёт использования языка Lua. Как сервер приложений платформа позволяет переместить код приложения максимально близко к данным, достигая при этом минимального времени отклика и максимальной пропускной способности.
Экосистема Tarantool постоянно расширяется, и сейчас уже содержит множество коннекторов для популярных языков программирования (Golang, Python, Java и др.), модулей расширения, позволяющих собирать ваши приложения из некоторых блоков (vshard, queue и др.), фреймворков, ускоряющих разработку (Cartridge, Luatest).
Сейчас хотелось бы остановиться на приложениях, разработанных на фреймворке Тarantool Cartridge, предназначенном для разработки сложных распределённых систем. Он позволяет сфокусироваться на написании бизнес-логики вместо решения инфраструктурных проблем.
Основные возможности Tarantool Cartridge:
автоматизированное оркестрирование кластера Tarantool;
расширение функциональности приложения с помощью новых ролей;
шаблон приложения для разработки и развёртывания;
встроенное автоматическое шардирование;
интеграция с тестовым фреймворком Luatest;
управление кластером с помощью WebUI и API;
инструменты упаковки и деплоя.
В основе каждого кластерного приложения на Cartridge лежат роли — Lua-модули, в которых описывается бизнес-логика приложения. Например, это могут быть модули, которые занимаются хранением данных, предоставляют HTTP API или кэшируют данные из Oracle. Роль назначается на набор инстансов, объединённых репликацией (репликасет), и включается на каждом из них. У разных репликасетов может быть различный набор ролей.
Подробнее про Cartridge можно почитать в отдельных статьях:
В Cartridge есть кластерная конфигурация, которая хранится на каждом узле кластера. Там описывается топология, также туда можно добавить конфигурацию, которой будет пользоваться ваша роль. Такую конфигурацию можно изменять в рантайме и влиять на поведение роли.
Но работать с фреймворком удобно, когда инстансов не так много. Если же вам нужно более 100 инстансов, то могут возникнуть эксплуатационные трудности, связанные с настройкой и обновлением больших кластеров. И тут мы вспоминаем про Kubernetes, призванный решить массу эксплуатационных проблем. Возникает вопрос:, а что если мы хотим использовать все плюсы k8s, и с помощью его возможностей упростить процесс развёртывания и поддержки Tarantool Cartridge? Ответом и является Tarantool Kubernetes Operator.
Немного про kubernetes операторы
Kubernetes оператор — это программа, позволяющая управлять приложениями внутри kubernetes. Операторы это часть основного reconciliation цикла, целью которого является приблизить текущее состояние кластера к описанному в ресурсах. Грубо говоря, это некий менеджер, который помогает решить часто возникающие ситуации в автоматическом режиме. Оператор призван помочь людям, которые не знакомы с особенностями конкретного приложения, развернуть и эксплаутировать это приложение в кластере куба.
Как работает оператор?
Оператор следит за изменениями в ресурсах за которыми он наблюдает и реагирует на них. Чаще всего для операторов вводят так называемые Custom resourse definition (CRD), в которых описывается какой-либо ресурс.
На примере Tarantool Kubernetes Operator рассмотрим следующую ситуацию. Оператор при установке через helm заводит две CRD — Cluster и Role.
Пример описания кластера:
apiVersion: tarantool.io/v1alpha1
kind: Cluster
metadata:
name: tarantool-cluster
spec:
roles:
- name: router
- name: storage
... Пример описания роли:
apiVersion: tarantool.io/v1alpha1
kind: Role
metadata:
name: router
spec:
replicasets: 1
vshard:
clusterRoles:
- failover-coordinator
- app.roles.router
replicasetTemplate:
replicas: 2
podTemplate:
spec:
containers:
- name: cartridge
image: "tarantool/tarantool-operator-examples-kv:0.0.4"
...Во время работы для каждого репликасета оператор создаёт Statefulset, так как именно этот ресурс позволяет работать Volume и Persistent volume claim (PVC, шаблон, по которому будут создаваться Persistent volume для подов). В итоге получается такая иерархия ресурсов в Kubernetes:
Cluster — основной ресурс, содержащий общекластерные настройки, такие как Cluster-wide config, настройки Failover;
Role — в текущем контексте это именно ресурс Kubernetes, содержащий описание шаблона для репликасетов, а также информацию о назначенных ролях Cartridge, количество репликасетов с такими настройками и инстансов Tarantool внутри каждого репликасета.
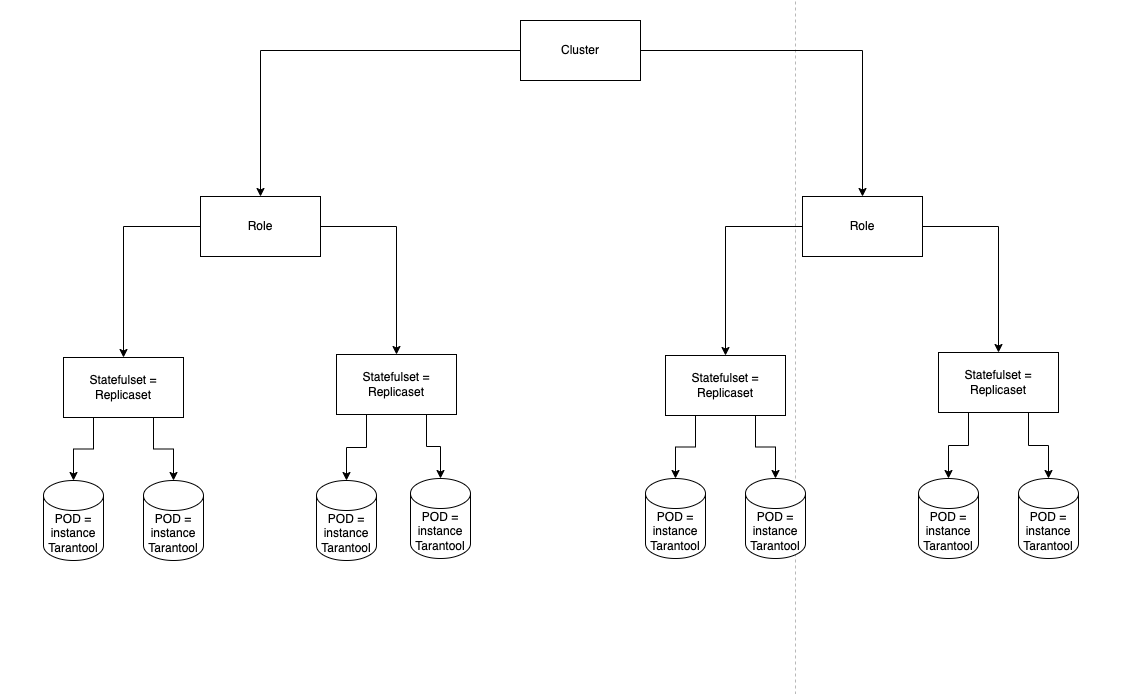 Иерархия ресурсов в Kubernetes
Иерархия ресурсов в Kubernetes
Оператор работает на основе Operator SDK (https://sdk.operatorframework.io/) и содержит два основных контроллера: Cluster и Role.
Каждый контроллер реализует интерфейс Reconciler и подписывается на изменения конкретных ресурсов. В коде это выглядит следующим образом:
func (r *RoleReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&Role{}).
Watches(&source.Kind{Type: &appsV1.StatefulSet{}}, &handler.EnqueueRequestForOwner{
IsController: true,
OwnerType: &Role{},
}).
Watches(&source.Kind{Type: &coreV1.Pod{}}, &handler.EnqueueRequestForOwner{
IsController: true,
OwnerType: &Role{},
}).
Complete(r)
}При изменении ресурса, на который подписан контроллер, будет вызван метод Reconcile. Контроллер сравнивает конфигурацию ресурса и актуальное состояние кластера, а затем исправляет разницу.
Рассмотрим на примере Сluster-контроллера:
func (r *ClusterReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
clusterContext := reconcilers.MakeReconciler(ctx, r.Reconciler)
return clusterContext.RunCluster(ctx,
reconcilers.GetObjectFromRequest(req),
reconcilers.CheckDeletion,
reconcilers.CheckFinalizer,
reconcilers.SetupRolesOwnershipStep,
reconcilers.SyncClusterWideServiceStep,
reconcilers.WaitForRolesPhase(RoleReady),
reconcilers.GetLeader,
reconcilers.CreateTopologyClient,
reconcilers.Bootstrap,
reconcilers.SetupFailover,
reconcilers.ApplyCartridgeConfig)
}При написании контроллера нужно учитывать, что порядок обработки событий всегда случаен, и нельзя полагаться на то, что, например, при изменении ресурса роли сначала вызовется Reconcile у контроллера роли, а потом — у контроллера кластера, или наоборот.
Теперь, понимая, как работает оператор, рассмотрим основные фичи Tarantool Kubernetes Operator Enterprise. Оператор сейчас умеет:
развернуть кластер Cartridge;
изменить настройки Failover;
производить Rolling update;
масштабировать кластер в обе стороны — как по количеству репликасетов, так и по репликам внутри каждого репликасета;
управлять параметрами приложения;
менять Persistent volume без потери данных и простоя в обход ограничений Kybernetes (в Kubernetes запрещено менять Persistent volume без пересоздания ресурса).
Теперь перейдём к трудностям, с которыми мы столкнулись при написании оператора.
Разделяй и властвуй
Разработка enterprise-версии оператора началась с переосмысления community, где для описания кластера использовались три CRD:
Первым шагом стала смена CRD:
Role;
Cluster.
Наша ошибка заключалась в том, что мы сделали один контроллер, который полностью отвечает за работу с кластером, и это привело к серьёзным проблемам при расширении функциональности оператора. Код метода Reconcile стал очень быстро расти, каждый этап порождал минимум 5—10 строк кода.
Пример метода для контроллера кластера до рефакторинга:
func (r *ClusterReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := ctrlLog.FromContext(ctx)
log.Info("Reconcile cluster")
cluster, err := r.GetCluster(ctx, req.NamespacedName.Namespace, req.NamespacedName.Name)
if err != nil {
if !apiErrors.IsNotFound(err) {
log.Error(err, "Unable to retrieve cluster")
return reconcile.Result(
ctx,
reconcile.WithError(
errors.Wrap(err, "unable to retrieve cluster for reconcile"),
10*time.Second,
),
)
}
return reconcile.Result(ctx)
}
...
return reconcile.Result(
ctx,
reconcile.WithClusterPhaseUpdate(r.Status(), cluster, ClusterReady),
)
}Решить эту проблему удалось разделением логики на несколько контроллеров — Cluster и Role.
Теперь Cluster занимается только общекластерными настройками — Failover и настройкой приложения.
В свою очередь Role контролер занимается созданием Statefulset — создает поверх них репликасеты, а также настройки конкретных инстансов.
Но на этом мы не остановились… В методах Reconcile множество шагов похожи в обоих контроллерах: получение текущего объекта, удаление, создание объекта для работы с топологией Tarantool и др. В результате мы пришли, как мне кажется, к достаточно элегантному решению: теперь метод Reconcile собирается из шагов, и код стал выглядеть гораздо нагляднее и читабельнее.
func (r *ClusterReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
clusterContext := reconcilers.MakeReconciler(ctx, r.Reconciler)
return clusterContext.RunCluster(ctx,
reconcilers.GetObjectFromRequest(req),
reconcilers.CheckDeletion,
reconcilers.CheckFinalizer,
reconcilers.SetupRolesOwnershipStep,
reconcilers.SyncClusterWideServiceStep,
reconcilers.WaitForRolesPhase(RoleReady),
reconcilers.GetLeader,
reconcilers.CreateTopologyClient,
reconcilers.Bootstrap,
reconcilers.SetupFailover,
reconcilers.ApplyCartridgeConfig)
}Кроме того, он имеет приятный бонус: теперь можно иметь общую кодовую базу для enterprise- и community-версии оператора. Данная модульность позволяет разрабатывать оператор модулями, которые можно подключать в нужной версии.
P.S. Да-да, скоро будет переработка community-версии оператора, и там мы сможем более подробно рассказать, как работает оператор.
Rolling update
Как было сказано выше, репликасеты представляются в Kubernetes при помощи стандартного ресурса Statefulset, который уже имеет две стратегии обновления приложений:
OnDelete — поды внутри Statefulset не будут обновлены автоматически;
RollingUpdate — стратегия, когда поды обновляются по отдельности.
Стратегия RollingUpdate не подходит для приложений, где поды не равноправные, как в Tarantool. В одном репликасете инстансы могут выполнять две роли:
мастер — инстанс, с которого можно как читать данные, так и записывать новые;
реплика — инстанс, имеющий права только на чтение (так называемый режим ReadOnly).
Поскольку при RollingUpdate Kubernetes не знает, в каком поде сейчас находится мастер, он может начать обновление именно с мастера, что приведёт к недоступности части приложения для записи. Выходом из ситуации стало написание собственных стратегий обновлений:
OnDelete — стратегия повторяет одноимённую стратегию Statefulset;
ClusterPartitionUpdate — используется для инстансов без данных. Схож с обычной стратегией обновления, поскольку как такового мастера нет (отсутствуют данные);
SwitchMasterUpdate — используется для инстансов с данными. Работает внутри одного репликасета по следующему алгоритму:
обновляем все реплики;
переключаем мастера на новые инстансы;
обновляем предыдущего мастера.
Тут может возникнуть вопрос: как в «базе данных» появляются инстансы без данных? Здесь главное не забывать, что Tarantool — это база данных и сервер приложений в одном флаконе! Дело в том, что для работы шардирования необходим отдельный инстанс (или инстансы), выступающий в роли роутера. По сути, роутер — это регулировщик, который говорит, куда нужно идти за необходимыми данными.

Чаще всего нет смысла объединять роутеры в репликасеты, поэтому стратегия ClusterPartitionUpdate работает поверх всех репликасетов, а не внутри конкретного Statefulset.
Подобные стратегии в коде работают достаточно просто:
проверяем условия обновления;
при необходимости производим какие-либо действия (например, переключаем мастера внутри репликации);
удаляем под;
ждём, пока Statefulset/Deployment-контроллер создаст новые поды с новым образом;
повторяем пункты, пока не обновим все необходимые поды.
Решаем проблемы с сетями
При разработке иногда возникают ситуации, когда оператору для работы необходим доступ ко всем подам внутри сети Kubernetes. Во время нормальной работы оператора внутри Kubernetes это не является проблемой, но, а что если вы хотите отлаживать свой код вне Kubernetes?
Одним из возможных решений может стать поднятие VPN внутри Kubernetes. Именно так мы и поступили, когда только начинали разрабатывать Tarantool Kubernetes Operator, потому что для настройки Cartridge-кластера использовалось graphql api. Но такое решение дополнительно нагружает компьютер разработчика.
Другое решение не подойдет для любого приложения, но замечательно подошло при работе с Tarantool: избавиться от запросов по сети и перейти на использование pod exec внутри контейнера с приложением. Текущая версия оператора использует именно этот подход для настройки Tarantool, тем более что в экосистеме Tarantool есть консольная утилита Tarantoolctl, позволяющая подключаться к работающему инстансу через control-сокет и выполнять настройку кластера через Lua-код.
Данный подход позволил нам решить ещё одну проблему. В Cartridge можно включить авторизацию, что раньше добавляло трудностей при использовании http-подключения. Поскольку при подключении через сокет мы имеем максимальные права доступа, то для оператора вопрос с авторизацией решён.
Именование Statefulset во время смены PVC
Иногда при работе с Statefulset хочется изменять размер Persistent volume claim, но в Kubernetes у Statefulset раздел с PVC является неизменяемым. Поскольку мы работаем с базой данных, то данных становится больше, и в какой-то момент придётся увеличивать размер дисков.
Поэтому появилась фича, позволяющая пользователю менять PVC у роли. Тут возникает проблема с именами подов: одновременно в Kubernetes не могут работать два пода с одинаковым названием. Изначально имя пода строилось по правилу:
создаём новый Statefulset с новым PVC;
создаём для него новый Replicaset с нужным весом;
устанавливаем вес репликации в 0 у старого Replicaset;
ждём, пока у нового Replicaset не останется данных;
если лидер топологии находится в старом Replicaset, то меняем его;
удаляем старый Replicaset и все его инстансы.
Как можно заметить, старое правило именования Statefulset и подов нам не подходит. Было принято решение изменить правило именования на
Тестирование оператора
Оператор, как и любое другое ПО, необходимо тестировать. В нашем случае мы имеем два вида тестов: Unit и E2E. Для тестирования обычно используют кода генерацию моков (например, с помощью golang/mock). Нам этот вариант не понравился, поэтому мы решили использовать модуль mock из библиотеки testify, позволяющий замокать интерфейсы функций с помощью рефлексии, которые непосредственно настраивают Tarantool.
Если интересно, то есть статья, где приводятся сравнения testify/mock и golang/mock: GoMock vs. Testify: Mocking frameworks for Go
Для создания фейкового кластера Kubernetes мы использовали библиотеку от разработчиков Kubernetes: «sigs.k8s.io/controller-runtime/pkg/client/fake».
Сейчас Unit-тесты работают по примерно такой схеме:
создаём фейковую топологию и клиент кластера Kubernetes;
вызываем метод Reconcile;
проверяем, что нужные методы топологии были вызваны и ресурсы изменены правильно.
Таким образом, тесты выглядят так:
BeforeEach(func() {
cartridge = helpers.NewCartridge(namespace, clusterName).
WithRouterRole(2, 1).
WithStorageRole(2, 3).
Finalized()
fakeTopologyService = new(mocks.FakeCartridgeTopology)
fakeTopologyService.
On("BootstrapVshard", mock.Anything).
Return(nil)
fakeTopologyService.
On("GetFailoverParams", mock.Anything).
Return(&topology.FailoverParams{Mode: "disabled"}, nil)
fakeTopologyService.
On("GetConfig", mock.Anything).
Return(map[string]interface{}{}, nil)
})Сам тест пишется примерно по следующей схеме:
cartridge.WithAllRolesReady().WithAllPodsReady()
fakeClient := cartridge.BuildFakeClient()
resourcesManager := resources.NewManager(fakeClient, scheme.Scheme)
clusterReconciler := &ClusterReconciler{...}
_, err := clusterReconciler.Reconcile(...)
Expect(err).NotTo(HaveOccurred(), "an error during reconcile")
err = fakeClient.Get(ctx, types.NamespacedName{Namespace: namespace, Name: clusterName}, cartridge.Cluster)
Expect(err).NotTo(HaveOccurred(), "cluster gone")
Expect(cartridge.Cluster.Status.Bootstrapped).To(BeTrue(), "cluster not bootstrapped")Что касается E2E-тестов, то для их реализации был использован E2E-framework, что позволило нам проверять полностью helm chart оператора, а также тестировать его на разных версиях Kubernetes при помощи KinD. Из-за особенностей тестов в Kubernetes мы вынуждены ждать, пока будут созданы различные поды, следовательно, время работы всех тестов очень быстро растёт. E2E-framework помог нам решить эту проблему, так как он поддерживает параллельный запуск тест-кейсов, что позволило сократить время работы с 30 до 8 минут.
Итог
Это всё, что я хотел вам рассказать. Ниже несколько полезных ссылок по теме.
