Сканирование 300 раз в секунду: как мы решали проблему в SAP ERP
Недавно решая проблему заказчика — крупного ритейлера, мы значительно ускорили работу одного из процессов, реализованных в SAP ERP. Периодически задания по загрузке цен работали ооооооооооооооооооооооооооочень медленно, причем задержка составляла не каких-нибудь 10 минут, а могла доходить до нескольких часов.
Для сравнения приводим два скрина. На первом отображено нормальное время выполнения задачи:
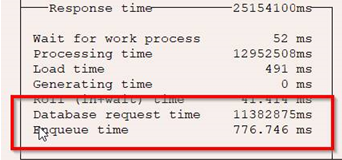
А на этом — время, затраченное в момент возникновения проблемы:
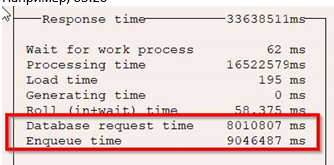
В результате критически важные для бизнеса данные — информация об ценах на товары — не успевали подгружаться в единственно возможное с точки зрения времени окно — к утру следующего дня.
Ситуация осложнялась еще некоторыми факторами:
· В силу бизнес-процессов, стартовать процесс загрузки цен можно только глубокой ночью;
· Проблема проявляется только время от времени;
· Многопоточность бизнес-процесса, связанного с проблемой;
· Отсутствие возможности искусственно воспроизвести расчет, который зависел от множества параметров.
С такими вводными мы приступили к поиску решения.
Шаг первый — что в системе?
Анализ проблемы в SAP всегда начинается с наиболее нагруженной части системы — базы данных. Мы стали искать «тяжелые» запросы в ней во время возникновения проблемы, но зафиксировать их нам не удалось. Более того, нагрузка на БД никак не коррелировала с замедлением загрузки цен. Следовательно, проблема кроется где-то на уровне сервера приложений, предположили мы.
Производительность приложения анализировали стандартно — с помощью транзакции st03n. В топе нагрузки мы заметили программу SAPLSENA — это косвенно говорило о том, что проблема находится где-то на уровне сервера блокировок.

Спустились на уровень работы операционной системы и увидели красивую полочку по CPU, которая коррелировала с проблемами в работе заданий:
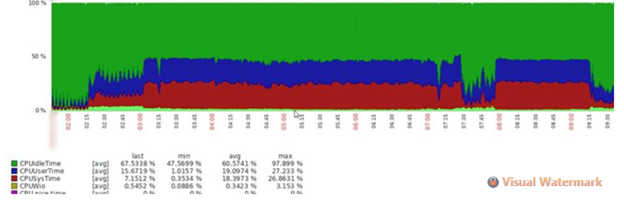
ENQ-сервер полностью утилизировал одно ядро. Логичное решение — это увеличение количества тредов enqserver для повышения производительности, что мы и сделали. Описание изменяемого параметра:
enque/server/threadcount | The number of I/O threads. Normally you do not need to change this parameter. It may be useful to change it for increasing system performance, but this should only be done with support from SAP or your hardware provider. Experience up to now shows that a value higher than 4 has never resulted in an increase in throughput. |
Для этого добавили ядер на виртуалку, и количество потоков enqserver выросло до двух. При синтетической нагрузке (кстати, ее можно генерить в sm12) получили ожидаемые 200% утилизации CPU:

Однако под продуктивной нагрузкой ничего не изменилось. У нас по-прежнему утилизировалось одно ядро. Параллелизм не отрабатывал.
Шаг второй — трассировка enqserver
На этом этапе анализ проблемы состоял из двух частей: включение логирования и разбор полученного лога. Для этого у SAP есть инструмент Enqueue Log Analyzer (Note 2763999 — How to analyze enqueue log with enqueue log analyzer).
Для включения логирования enqserver с помощью enqt необходимо выполнить следующие шаги:
1. enqt pf=<профиль инстанции ASCS> 81 1
2. воспроизвести проблему
3. enqt pf=<профиль инстанции ASCS> 81 0
Результат работы утилиты — появление файла ENQLOG99 в рабочей директории.
Так как запись debug логов дело затратное, то для снижения нагрузки на систему и уменьшения количество генерируемых логов мы скорректировали подход, включая трассировку на несколько секунд раз в 10 минут. Для этого написали скрипт и запланировали трассировку каждые 10 минут в надежде поймать проблему.
Результаты собранных данных и работу Log Analyzer можно увидеть ниже. Программа сама выделила желтым подозрительные данные:

Хотя первопричину на тот момент мы еще не нашли, в нашем паззле появилась еще одна деталь: при высокой и постоянной утилизации ядер происходило значительное снижение (Throughput) пропускной способности. То есть сильно нагруженный enqserver утилизировал CPU, но при этом обрабатывал меньше блокировок. Предположили, что это баг. Обновили ядро, но ситуация не изменилась.
Идем в код
Первоначальная диагностика помогла выдвинуть предположение о локализации проблемы, но не приблизила нас к ее решению. Поэтому пошли вглубь — в код. На этом этапе нам сильно повезло: мы поймали проблему утром, проанализировали ее и получили тайминги работы программы, обращавшейся к ENQ-серверу.
Скриншот в момент возникновения проблемы выглядел так:

Сразу смутила SAPLSENA, которая работала 1 000 секунд, что подозрительно много. Тем не менее полученные результаты были недостаточными. Мы не понимали, какую блокировку запрашивал конкретно этот пользователь. Отягчающим обстоятельством стала и невозможность моделировать проблему из-за работы с боевыми данными. Оставалось только запускать трассировку программы через st12/st05 и надеяться, что размера трассировки хватит, и проблема повторится.
Просто так ждать не стали и написали агрегатор количества блокировок по объекту и пользователям. На скриншоте ниже приведен размер таблицы блокировок в записях.

В этом месте нашли топ-пользователя по количеству блокировок. Посмотрели количество блокировок по пользователю:

Ниже посмотрели агрегацию по объекту блокирования:

Дальнейший анализ показал прямую зависимость между возникновением проблемы со стороны пользователя и количеством блокировок на таблицы MARC и MBEW. С точки зрения функциональных специалистов подобное совпадение не вызывает подозрений — эти блокировки нужны. Но тогда почему так медленно работает ENQ-сервер? Еще раз вернулись к CPU-утилизации. Теперь явно прослеживалась четкая зависимость между проблемой и нагрузкой на CPU.

Дальше мы посмотрели количество блокируемых объектов по пользователю:

На этом этапе возникло подозрение, что всё-таки происходит какая-то внутренняя блокировка в ENQ-сервере. Ведь по графику CPU утилизировалось только одно ядро, хотя в параметрах стояла утилизация четырех. Мы предположили, что проблема возникала из-за внутреннего цикла или еще какой-то нагрузки, снижающей отзывчивость к некоторым запросам. Судя по данным, тормозили только обращения к MARC и MBEW, остальные блокировки обрабатывались корректно. Помимо этого, логировалось и время обработки метода. Дальнейший лог сервера блокировок показывал: один и тот же метод (см. скрины ниже) в первом случае обрабатывал намного меньше записей и тратил на это намного меньше времени.
До проблемного задания:

Во время проблемного задания:

Красным мы выделили время операции в мс.
Зафиксировали промежуточные итоги проделанной работы:
1) Одно фоновое задание выставляло кучу блокировок на MARC и MBEW.
2) Второе задание сканировало эти объекты полностью по 300 раз в секунду.
3) Массовые параллельные задания пытались обратиться к MARC и MBEW, но вставали в очередь из-за второго задания и тормозили.
Для подтверждения гипотезы с многократным обрабатыванием блокировок решили отключить второе задание. Иииии — бинго! Это помогло снять все симптомы.
Детальная трассировка второго задания по стеку вызовов продемонстрировала следующую картину:
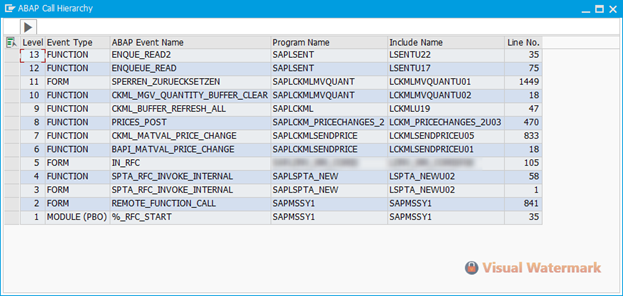
Стали искать по именам программ ноты, связанные с проблемами производительности ENQ. Нашли Note 2991565 (High load on lock server) и выставили значение в настроечную таблицу:

После применения этой настройки задания стали отрабатывать штатно — проблема решена!
