Сканер установленных перехватчиков в памяти процесса

В статье будет рассмотрен один из методов поиска изменений в памяти процесса, на основе построения полной карты уязвимых к перехвату адресов. Рассмотрена работа со списками загрузчика, ручным разбором таблиц импорта/отложенного импорта/экспорта/TLS загруженных файлов, c обработкой форварда функций и ApiSet редиректов.
Будет показана методика доступа в 64 битное адресное пространство чужого процесса из 32 битного кода через статически сформированный ассемблерный шлюз, так и подход с применением автоматически генерируемого гейта.
Будет дано много комментариев «почему» применяется тот или иной подход, а также описание различных проблемных ситуаций, основанных в том числе как на собственном опыте, так и на разборе кода системного загрузчика, поэтому будет интересна и подготовленным специалистам.
0. В качестве вступления
Думаю, практически у ста процентов читающих данную статью в компании есть служба технической поддержки, и я думаю что не ошибусь если как минимум половина из вас писала для своей службы техподдержки вспомогательные утилиты, наподобие сборщиков системной информации, которые помогают делать общие выводы о состоянии компьютера пользователя и окружении вашего софта, запущенного на этом компьютере.
У наших технарей тоже есть такой инструмент и мне приходится периодически его расширять под новые изменяющиеся требования, добавляя те или иные ситуации, которые необходимо прогнать на машине пользователя чтобы выяснить, корректно ли работает та или иная часть софта на данной конкретной машине.
Где-то полгода назад у нас появилась очередная идея, есть очень много разноплановых ошибок которые достаточно проблематично покрыть тестами, но по результатам накопленного методом проб и ошибок опыта было выяснено что большая часть из них происходит по причине вмешательства стороннего софта в тело нашего процесса. Это могут быть как антивирусы, так и всякие DLP, а то и вовсе зловреды, которые лезут к нам в процесс, перехватывают некоторые критичные для выполнения API на себя и в обработчиках перехваченных функций ломают полностью логику исполнения кода.
Поэтому было принято решение контролировать такое вмешательство через одну из утилит, которой пользуется наша служба техподдержки, и на основе её работы быстро выяснять — кто именно, куда конкретно влез и главное, что именно он там поломал.
Собственно идея достаточно простая и она будет развитием моей предыдущей статьи «Карта памяти процесса». Суть её заключается в следующем: чтобы провернуть такой трюк, нужно уметь самостоятельно рассчитывать все критические адреса в теле удаленного процесса, знать, что должно находится по этим адресам и в автоматическом режиме просто пробежаться по ним и проверить, есть ли изменения или нет.
Правда при общей простоте идеи реализация получилось достаточно трудоемкая.
Самая большая проблема при этом была в том что утилита 32 битная, а софт, работающий у пользователя может быть как 32 бита, так и 64 (второе более вероятно), поэтому для работы с 64 битным процессом пришлось писать соответствующую обвязку.
И то я бы не сказал, что это решение в финале получилось полным, т.к. мне стало в какой-то момент времени лень обрабатывать одну из ситуаций, к решению которой я хотел подключить таблицы контекста активации процесса, (правда в них, как оказалось, нет нужной мне информации) поэтому там я выкрутился простым трюком, о котором расскажу чуть позже.
Короче в итоге получилось такое, как бы это назвать… антивирусный сканер на минималках :)
В этой статье я пройдусь по всем этапам построения такого сканера с нуля, постаравшись подробно описать каждый шаг чтобы было не только понимание что именно тут происходит, а чтобы вы (при желании, конечно) могли бы реализовать свой вариант такого сканера, даже не пользуясь моими наработками.
Для каждого из этапов будет свой код, который будет расширятся от главы к главе, обрастая функционалом, а в самом конце я дам ссылку на финальную реализацию данного фреймворка, который использую сам у себя в инструментарии (если вдруг кто захочет просто воспользоваться готовым решением подключив его к себе в проект).
1. Таблица экспорта
Для начала разберем принцип получения экспортируемых исполняемым файлом (или библиотекой) адресов функций, читая эту информацию напрямую из образа на жестком диске. Вся эта информация хранится в таблице экспорта, поэтому с неё и начнем.
Данная таблица применяется в случае динамической линовки функций посредством LoadLibrary + GetProcAddress, а также для заполнения таблиц импорта и отложенного импорта загружаемых библиотек в случае статической компоновки (на этом пока не акцентируйте внимание).
Я не буду сильно углубляться по формату РЕ файла, благо на эту тему есть огромное количество статей (ссылки будут в конце статьи), поэтому описывать буду только интересующие для текущей задачи моменты. А текущей задачей будет получить от таблицы экспорта два адреса по каждой экспортируемой функции.
- Первый это RAW и VA адрес, по которому размещен код тела функции.
- А второй — RAW и VA адрес, в котором лежит RVA указатель на первый адрес.
Именно эти адреса потребуются при анализе памяти так как, когда осуществляется перехват функции, меняются данные либо по первому адресу (методом HotPatch или через трамплин, копированием части кода в другую область и размещением вместо него перехода на перехватчик), либо по второму, заставляя функцию GetProcAddress возвращать вместо адреса функции адрес перехватчика.
Да, сразу же оговорюсь, в данной статье будут применяться три термина относительно адресации:
- RAW адрес — смещение от начала файла на диске (всегда 4 байта).
- RVA адрес (relative virtual address), это относительный адрес в том виде, в котором он записан в исполняемом файле (всегда 4 байта). Как правило он указывается относительно ImageBase записанном в РЕ заголовке файла, либо относительно hInstance файла в памяти приложения, но бывают и другие варианты, я буду их указывать, когда потребуется.
- VA адрес — реальный адрес в адресном пространстве процесса. Т.к. нам нужно работать и с 32 битами и с 64, то он хранится в виде 8-байтного ULONG_PTR64 (UInt64), но содержит в зависимости от битности процесса либо 32 битный указатель, либо 64 битный. VA адрес (как правило) рассчитывается исходя из базы загрузки файла IMAGE_OPTIONAL_HEADERхх.ImageBase и прибавления к ней RVA адреса, но могут быть и исключения (например структуры ApiSet таблиц, которые рассмотрим немного позже, содержат RVA адреса относительно своего заголовка, а не ImageBase.
Выход на таблицу импорта происходит посредством чтения трех структур, которые всегда присутствуют в начале любого РЕ файла.
- Чтением структуры IMAGE_DOS_HEADER, с которой начинается исполняемый файл
- Переходом на смещение IMAGE_DOS_HEADER._lfanew, указывающий на начало PE заголовка
- Проверкой наличия четырехбайтной сигнатуры IMAGE_NT_SIGNATURE и чтением идущей за ней структуры IMAGE_FILE_HEADER.
- Из этой структуры будут интересны два поля. NumberOfSections и Machine. В зависимости от значения второго нужно прочитать идущую следом:
- либо структуру IMAGE_OPTIONAL_HEADER32 в случае если IMAGE_FILE_HEADER.Machine = IMAGE_FILE_MACHINE_I386
- либо структуру IMAGE_OPTIONAL_HEADER64 в случае если IMAGE_FILE_HEADER.Machine = IMAGE_FILE_MACHINE_AMD64
Вот примерно так, как на картинке:

Различия структур IMAGE_OPTIONAL_HEADER друг от друга заключается в размере полей.
32 битная содержит 4 байтные DWORD, а 64 битная восьмибайтные ULONGLONG.
Последним полем IMAGE_OPTIONAL_HEADERхх содержит массив IMAGE_DATA_DIRECTORY (всего 16 элементов). Вот именно он и будет интересен, а если конкретнее, то самый первый его элемент, обозначающийся индексом IMAGE_DIRECTORY_ENTRY_EXPORT.
Но, прежде чем начать работу с этим массивом, необходимо прочитать и запомнить данные о секциях исполняемого файла. Их количество записано в поле IMAGE_FILE_HEADER.NumberOfSections, и представляют они из себя массив структур IMAGE_SECTION_HEADER которые идут сразу после IMAGE_OPTIONAL_HEADERхх.
Структура IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT], это всего два поля:
- VirtualAddress (DWORD) — RVA адрес директории
- Size (DWORD) — её размер
А структура, описывающая секцию (IMAGE_SECTION_HEADER) предоставляет следующий набор полей (перечислены только требуемые для текущей задачи):
- VirtualAddress (DWORD) — RVA адрес секции
- VirtualSize (DWORD) — её размер в адресном пространстве процесса
- PointerToRawData (DWORD) — RAW адрес секции
- SizeOfRawData (DWORD) — размер RAW данных в файле
Так вот, если создать пустое консольное приложение и выполнить над ним описанные выше шаги, то на руках будет структура с (примерно) такими параметрами:
IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress = 0×103000
IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_EXPORT].Size = 0×96
В данном случае я говорю про Delphi 10.4, которая создает исполняемые файлы с тремя экспортируемыми функциями:
dbkFCallWrapperAddr, _dbk_fcall_wrapper и TMethodImplementationIntercept
Чтобы прочитать содержимое таблицы экспорта из файла на диске, полученный RVA адрес 0×103000 не подходит и нужно его пересчитать в RAW и вот именно тут пригодится информация из массива IMAGE_SECTION_HEADER, который содержит данные для преобразования из одного типа указателя в другой.
Для этого потребуется новый класс TRawPEImage. Этапы чтения структур заголовка (LoadFromImage + LoadNtHeader) и секций (LoadSections) я пропущу, отмечу только один нюанс.
Так как подразумевается работа с 64 битным кодом из 32 битного приложения, то поле FNtHeader в данном классе имеет тип TImageNtHeaders64 и при чтении 32 битного заголовка происходит этап конвертации 32 битного опционального заголовка в 64. Это сделано только для удобства работы.
Начну сразу с реализации утилитарных функций. Первые две функции выглядит так:
function TRawPEImage.RvaToVa(RvaAddr: DWORD): ULONG_PTR64;
begin
Result := FImageBase + RvaAddr;
end;
function TRawPEImage.VaToRva(VaAddr: ULONG_PTR64): DWORD;
begin
Result := VaAddr - FImageBase;
end;
Собственно это и есть все преобразование из RVA адресации в VA и наоборот.
Для преобразования из RVA адреса в RAW потребуется три вспомогательных функции:
function TRawPEImage.AlignDown(Value, Align: DWORD): DWORD;
begin
Result := Value and not DWORD(Align - 1);
end;
function TRawPEImage.AlignUp(Value, Align: DWORD): DWORD;
begin
if Value = 0 then Exit(0);
Result := AlignDown(Value - 1, Align) + Align;
end;
Эти две функции отвечают за выравнивание, а третья отвечает за поиск секции, к которой принадлежит RVA адрес:
function TRawPEImage.GetSectionData(RvaAddr: DWORD;
var Data: TSectionData): Boolean;
var
I, NumberOfSections: Integer;
SizeOfRawData, VirtualSize: DWORD;
begin
Result := False;
NumberOfSections := Length(FSections);
for I := 0 to NumberOfSections - 1 do
begin
if FSections[I].SizeOfRawData = 0 then
Continue;
if FSections[I].PointerToRawData = 0 then
Continue;
Data.StartRVA := FSections[I].VirtualAddress;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
Data.StartRVA := AlignDown(Data.StartRVA, FNtHeader.OptionalHeader.SectionAlignment);
SizeOfRawData := FSections[I].SizeOfRawData;
VirtualSize := FSections[I].Misc.VirtualSize;
// если виртуальный размер секции не указан, то берем его из размера данных
// (см. LdrpSnapIAT или RelocateLoaderSections)
// к которому уже применяется SectionAlignment
if VirtualSize = 0 then
VirtualSize := SizeOfRawData;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
begin
SizeOfRawData := AlignUp(SizeOfRawData, FNtHeader.OptionalHeader.FileAlignment);
VirtualSize := AlignUp(VirtualSize, FNtHeader.OptionalHeader.SectionAlignment);
end;
Data.Size := Min(SizeOfRawData, VirtualSize);
if (RvaAddr >= Data.StartRVA) and (RvaAddr < Data.StartRVA + Data.Size) then
begin
Data.Index := I;
Result := True;
Break;
end;
end;
end;
В ней происходит перебор секций, и первым этапом идет пропуск секций с нулевым размером или отсутствующими данными.
Вторым этапом вычисляется нижняя граница секции (её начало) на основе VirtualAddress с округлением вниз на значение SectionAlignment.
Третьим — верхняя граница (её конец) на основе сначала Misc.VirtualSize с округлением вверх на значение SectionAlignment, а потом SizeOfRawData с округлением вверх на значение FileAlignment.
Важный нюанс, Misc.VirtualSize может быть равен нулю и это штатное значение, в таком случае в качестве конечного адреса секции берется значение из SizeOfRawData к которому также применяется округление вверх, но уже на значение SectionAlignment.
Реальный размер секции в адресном пространстве равен меньшему из двух рассчитанных значений.
Последний этап, это проверка — попадает ли переданный RVA адрес в диапазон адресов секций.
После того как номер секции, к которой принадлежит RVA адрес определен, необходимо произвести его конвертацию посредством следующей функции:
function TRawPEImage.RvaToRaw(RvaAddr: DWORD): DWORD;
var
NumberOfSections: Integer;
SectionData: TSectionData;
SizeOfImage: DWORD;
PointerToRawData: DWORD;
begin
Result := 0;
// ... граничные проверки вырезаны
if GetSectionData(RvaAddr, SectionData) then
begin
PointerToRawData := FSections[SectionData.Index].PointerToRawData;
if FNtHeader.OptionalHeader.SectionAlignment >= DEFAULT_SECTION_ALIGNMENT then
PointerToRawData := AlignDown(PointerToRawData, DEFAULT_FILE_ALIGNMENT);
Inc(PointerToRawData, RvaAddr - SectionData.StartRVA);
if PointerToRawData < FSizeOfFileImage then
Result := PointerToRawData;
end;
end;
В ней сначала происходит проверка редких ситуаций, когда RVA адрес принадлежит заголовкам файла и второй случай, когда в файле вообще нет секций (случаи граничные, поэтому рассматривать не буду).
После чего происходит сама конвертация, из конвертируемого RVA адреса вычитается RVA адрес начала секции и к результату прибавляется PointerToRawData, указывающий на смещение секции относительно начала файла. Результатом будет RAW адрес, опираясь на который можно прочитать данные из образа файла на диске.
Осталось написать еще одну утилитарную функцию, она пригодится для работы с адресами директорий, которые TRawPEImage хранит уже преобразованными в VA.
function TRawPEImage.VaToRaw(VaAddr: ULONG_PTR64): DWORD;
begin
Result := RvaToRaw(VaToRva(VaAddr));
end;
Если проверить этот код на 'ntdll.dll' то в случае Win11 из 32 битного процесса (при этом будет подгружена библиотека из SysWOW64) данные будут такие:
- RVA адрес директории экспорта = 0×110360 (VA при этом равен 0×77A60360)
- Принадлежит директории '.text', которая начинается с RVA 0×1000, размером 0×122800 байт, PointerToRawData = 0×400.
- Значит в реальном файле RAW адрес директории экспорта должен быть равен: 0×110360 — 0×1000 + 0×400 = 0×10F760
Можно для самопроверки открыть эту библиотеку в HEX редакторе и сравнить с тем, что находится по VA адресу таблицы экспорта в процессе.

Скриншот показал, что данные совпали, значит RAW адрес получен правильно и пришло время читать саму таблицу экспорта напрямую из файла.
В качестве реципиента я взял маленькую библиотеку для работы с ACE архивами, так как в ней более наглядно можно увидеть для чего предназначен каждый список таблицы экспорта. Итак, таблица экспорта функций начинается со структуры IMAGE_EXPORT_DIRECTORY, которую нужно прочитать самым первым шагом.
function TRawPEImage.LoadExport(Raw: TStream): Boolean;
var
I, Index: Integer;
LastOffset: Int64;
ImageExportDirectory: TImageExportDirectory;
FunctionsAddr, NamesAddr: array of DWORD;
Ordinals: array of Word;
ExportChunk: TExportChunk;
begin
Result := False;
LastOffset := VaToRaw(ExportDirectory.VirtualAddress);
if LastOffset = 0 then Exit;
Raw.Position := LastOffset;
Raw.ReadBuffer(ImageExportDirectory, SizeOf(TImageExportDirectory));
if ImageExportDirectory.NumberOfFunctions = 0 then Exit;
// читаем префикс для перенаправления через ApiSet,
// он не обязательно будет равен имени библиотеки
// например:
// kernel.appcore.dll -> appcore.dll
// gds32.dll -> fbclient.dll
Raw.Position := RvaToRaw(ImageExportDirectory.Name);
if Raw.Position = 0 then
Exit;
FOriginalName := ReadString(Raw);
// читаем масив Rva адресов функций
SetLength(FunctionsAddr, ImageExportDirectory.NumberOfFunctions);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfFunctions);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(FunctionsAddr[0], ImageExportDirectory.NumberOfFunctions shl 2);
Вначале идет проверка, получилось ли преобразовать VA адрес директории в RAW (т.е. результат работы VaToRaw). Таких проверок будет по коду много, и чуть позже я покажу в каком случае эти проверки могут сработать.
Особо отмечу — все адреса из структуры IMAGE_EXPORT_DIRECTORY представлены в виде RVA, т.е. для работы с ними всегда требуется преобразование, либо в RAW если читаем из файла, либо в VA если читаем из памяти!
Следующим шагом идет проверка количества экспортируемых функций, так как наличие директории экспорта еще не означает что в ней есть данные.
Далее читается имя библиотеки. Сейчас оно не интересно, но будет использоваться в следующих главах.
Ну и последним подготовительным шагом читается массив адресов экспортируемых функций. Это список DWORD, содержащий RVA адреса экспортируемых функций.
Вот так выглядит таблица экспорта для библиотеки UNACEV2.DLL
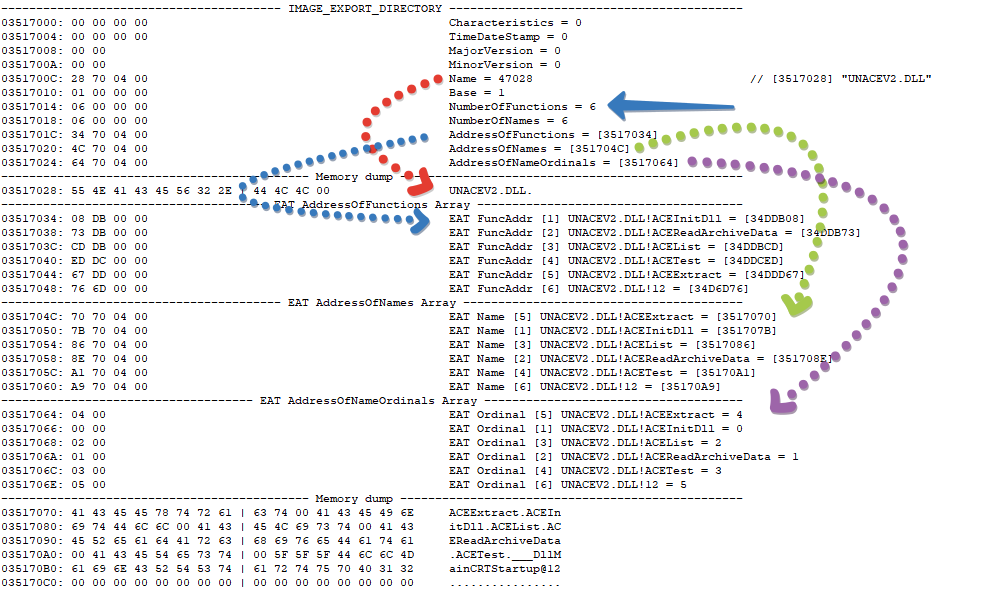
Вначале идет структура IMAGE_EXPORT_DIRECTORY и стрелками я показал на какие данные ссылаются её поля. Самое важное поля в ней это NumberOfFunctions + AddressOfFunctions.
Остальные поля со стрелками NumberOfNames + AddressOfNames + AddressOfNameOrdinals могут быть равны нулю, но NumberOfFunctions + AddressOfFunctions обязательно должны присутствовать, т.к. именно они дают возможность получить доступ к экспортируемым функциям хотя бы по их ORDINAL значению (т.е. по индексу экспортируемой функции, а не по имени).
Итак, синяя стрелка показывает на список экспортируемых функций. Первая запись:
03517034: 08 DB 00 00 EAT FuncAddr [1] UNACEV2.DLL!ACEInitDll = [34DDB08]- 03517034- это адрес в котором хранится RVA значение экспортируемой функции ACEInitDll
- 08 DB 00 00- это 4 байта которые и являются RVA адресом функции. Если преобразовать их в DWORD это будет означать 0×0000DB08 (числа хранятся в памяти в little-endian формате, т.е. обратно их привычному представлению).
- EAT FuncAddr [1] — это комментарий к экспортируемой функции поясняющий тип адреса и в скобках содержащий ORDINAL экспортируемой функции. Замечу — Ordinal это не порядковый номер, это именно индекс функции, который получается сложением IMAGE_EXPORT_DIRECTORY.Base и порядкового номера функции в таблице адресов. При загрузке функции по ординалу применяется вызов GetProcAddress (dll, MAKEINTRESOURCE (ordinal)). В текущей библиотеке он равен единице, а вот в ntdll например он равен восьми.
- UNACEV2.DLL! ACEInitDll = [34DDB08] — сама экспортируемая функция, а в скобках содержится её VA адрес, который вернет GetProcAddress (VA = RVA + ImageBase)
Из четвертого пункта можно понять, что так как RVA равен 0xDB08, а VA адрес равен 0×34DDB08 то Instance библиотеки (адрес, по которому она загружена) равен 0×034D0000
Если посмотреть на первый список, то можно заметить, что все ординалы функций (в первых квадратных скобках) идут по порядку от единицы до шести. Это условие всегда будет соблюдаться, дело в том, что это (как правило) тот порядок, в котором они объявлены в коде библиотеки. Вот как они идут в коде, так обычно и прописываются в списке экспорта (это можно наглядно увидеть по их RVA или VA значениям, которые идут на увеличение, правда это не всегда так).
Более интересны два другие списка, в частности список, на который указывает параметр AddressOfNames. Это список имен функций в количестве IMAGE_EXPORT_DIRECTORY.NumberOfNames объявленных строго в отсортированном порядке (обязательное условие), именно по этим именам идет поиск функции в случае вызова GetProcAddress, а сортировка нужна для ускорения поиска. При этом — имя функции это такой-же RVA указатель на буфер с именем (строго на Ansi буфер).
Строго говоря отсортированный список имен функций практически всегда не будет соответствовать их декларации из первого (AddressOfFunctions) списка, поэтому для соответствия какое имя какому адресу соответствует, существует третий список — AddressOfNameOrdinals. Это список двухбайтовых WORD, в количестве IMAGE_EXPORT_DIRECTORY.NumberOfNames каждый из которых соответствует (по индексу) такому же имени функции и содержащий индекс от нуля в самом первом списке AddressOfFunctions.
Можно проверить это утверждение опираясь на картинку выше:
1. имя самой первой функции из списка AddressOfNames:
0351704C: 70 70 04 00 EAT Name [5] UNACEV2.DLL! ACEExtract = [3517070]
2. соответствующий ей ординал индекс из списка AddressOfNameOrdinals
03517064: 04 00 EAT Ordinal [5] UNACEV2.DLL! ACEExtract = 4
3. индекс равен четырем. Это реальный индекс от нуля в самом первом списке RVA адресов функций. Четвертая запись из списка AddressOfFunctions:
03517044: 67 DD 00 00 FuncAddr [5] UNACEV2.DLL! ACEExtract = [34DDD67]
4. Ну, а ORDINAL индекс этой функции равен индексу в списке + база, т.е. пяти.
Хитрый момент — индекс всего два байта!
Именно из-за этого ограничения ни у кого не получится сделать библиотеку, экспортирующую больше 65535 функций (я знаю людей, которые пробовали).
Вот примерно такой-же алгоритм и необходимо написать:
// Важный момент!
// Библиотека может вообще не иметь функций экспортируемых по имени,
// только по ординалам. Пример такой библиотеки: mfperfhelper.dll
// Поэтому нужно делать проверку на их наличие
if ImageExportDirectory.NumberOfNames > 0 then
begin
// читаем массив Rva адресов имен функций
SetLength(NamesAddr, ImageExportDirectory.NumberOfNames);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfNames);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(NamesAddr[0], ImageExportDirectory.NumberOfNames shl 2);
// читаем массив ординалов - индексов через которые имена функций
// связываются с массивом адресов
SetLength(Ordinals, ImageExportDirectory.NumberOfNames);
Raw.Position := RvaToRaw(ImageExportDirectory.AddressOfNameOrdinals);
if Raw.Position = 0 then
Exit;
Raw.ReadBuffer(Ordinals[0], ImageExportDirectory.NumberOfNames shl 1);
// сначала обрабатываем функции экспортируемые по имени
for I := 0 to ImageExportDirectory.NumberOfNames - 1 do
begin
Raw.Position := RvaToRaw(NamesAddr[I]);
if Raw.Position = 0 then Continue;
// два параметра по которым будем искать фактические данные функции
ExportChunk.FuncName := ReadString(Raw);
ExportChunk.Ordinal := Ordinals[I];
// VA адрес в котором должен лежать Rva линк на адрес функции
// именно его изменяют при перехвате функции методом патча
// таблицы экспорта.
ExportChunk.ExportTableVA := RvaToVa(
ImageExportDirectory.AddressOfFunctions + ExportChunk.Ordinal shl 2);
// Смещение в RAW файле по которому лежит Rva линк
ExportChunk.ExportTableRaw := VaToRaw(ExportChunk.ExportTableVA);
// Само RVA значение которое будут подменять
ExportChunk.FuncAddrRVA := FunctionsAddr[ExportChunk.Ordinal];
// VA адрес функции, именно по этому адресу (как правило) устанавливают
// перехватчик методом сплайсинга или хотпатча через трамплин
ExportChunk.FuncAddrVA := RvaToVa(ExportChunk.FuncAddrRVA);
// Raw адрес функции в образе бинарника с которым будет идти проверка
// на измененные инструкции
ExportChunk.FuncAddrRaw := RvaToRaw(ExportChunk.FuncAddrRVA);
// вставляем признак что функция обработана
FunctionsAddr[ExportChunk.Ordinal] := 0;
// переводим в NameOrdinal который прописан в таблице импорта
Inc(ExportChunk.Ordinal, ImageExportDirectory.Base);
// добавляем в общий список для анализа снаружи
Index := FExport.Add(ExportChunk);
// vcl270.bpl спокойно декларирует 4 одинаковых функции
// вот эти '@$xp$39System@%TArray__1$p17System@TMetaClass%'
// с ординалами 7341, 7384, 7411, 7222
// поэтому придется в массиве имен запоминать только самую первую
// ибо линковаться они могут только через ординалы
// upd: а они даже не линкуются, а являются дженериками с линком на класс
// а в таблице экспорта полученном через Symbols присутствует только одна
// с ординалом 7384
FExportIndex.TryAdd(ExportChunk.FuncName, Index);
// индекс для поиска по ординалу
// (если тут упадет с дубликатом, значит что-то не верно зачитано)
FExportOrdinalIndex.Add(ExportChunk.Ordinal, Index);
end;
end;
Что здесь происходит:
Самым первым шагом идет проверка, а есть ли вообще список имен? Если есть, то происходят все те же самые действия, про которые я рассказал выше и заполняется структура, в которой будет хранится информация по каждой экспортируемой функции. Её пока не рассматриваю, она пригодится гораздо позже, для кода анализатора.
Единственно что упомяну, это то, что именно на этом этапе рассчитывается реальный VA адрес каждой функции на основе Instance библиотеки переданного в конструкторе класса, и хранится он в ExportChunk.FuncAddrVA, а также адрес поля в таблице экспорта, в котором этот адрес записан в памяти процесса, это ExportChunk.ExportTableVA.
Оба этих адреса будет контролировать анализатор на следующих этапах, т.к. изменением значения, на которое указывает ExportTableVA осуществляется установка перехватчика через правку таблицы экспорта, а правкой данных, которые указывает FuncAddrVA осуществляется установка перехватчика прямой правкой кода функции (не важно каким именно способом, через HotPatch или трамплин или вообще модификация поведения функции посредством изменения её кода целиком).
Для ускорения работы с классом помимо списка экспорта FExport используются два словаря.
- Словарь имен функций FExportIndex
- Словарь ординалов функций FExportOrdinalIndex
Это уже чисто организационные моменты, тут я их показал для демонстрации одного момента.
Дело в том, что по правилам дубликатов в списке имен экспорта быть не должно, но как видно по комментарию к коду, Delphi вполне допускает такие дубликаты, правда момент заключается в том, что эти имена не принадлежат функциям как таковым, а указывают на некие публичные структуры. Такое встречается и в штатных библиотеках, например экспортируемая из ntdll RtlNtdllName фактически функцией не является, т.к. является просто указателем на строку.
Впрочем, такие ситуации будут рассмотрены немного позже, когда буду расширять код класса, а сейчас остался последний шаг.
Данные по функциям экспортирующихся по имени загружены, но есть очень много библиотек экспортирующих часть функций только по ординалам (без имени), поэтому третьим шагом нужно обработать оставшиеся функции, опираясь на значение FunctionsAddr[Index], которое обнуляется для обработанных ранее функций (или изначально было равно нулю из-за пропуска в списке ординалов).
Кстати, по поводу списка адресов. Данный список может идти с разрывами, т.е. если простым языком, некоторые функции экспортируемые по ординалу могут отсутствовать. Тогда вместо RVA такой функции будет записан ноль, вот как в случае экспорта библиотеки cabinet.dll

Именно на такие пропуски и идет закладка, когда я упомянул что нужно проверять значение FunctionsAddr[Index]. Итак — последний шаг:
// обработка функций экспортирующихся по индексу
for I := 0 to ImageExportDirectory.NumberOfFunctions - 1 do
if FunctionsAddr[I] <> 0 then
begin
// здесь все тоже самое за исключение что у функции нет имени
// и её подгрузка осуществляется по её ординалу, который рассчитывается
// от базы директории экспорта
ExportChunk.FuncAddrRVA := FunctionsAddr[I];
ExportChunk.Ordinal := ImageExportDirectory.Base + DWORD(I);
ExportChunk.FuncName := EmptyStr;
// сами значения рассчитываются как есть, без пересчета в ординал
ExportChunk.ExportTableVA := RvaToVa(
ImageExportDirectory.AddressOfFunctions + DWORD(I shl 2));
ExportChunk.FuncAddrVA := RvaToVa(ExportChunk.FuncAddrRVA);
ExportChunk.FuncAddrRaw := RvaToRaw(ExportChunk.FuncAddrRVA);
// добавляем в общий список для анализа снаружи
Index := FExport.Add(ExportChunk);
// имени нет, поэтому добавляем только в индекс ординалов
FExportOrdinalIndex.Add(ExportChunk.Ordinal, Index);
end;
По чтению таблицы экспорта всё, точнее это конечно же только первый этап, но для демонстрации корректности работы класса будет рассмотрен небольшой тестовый пример.
var
Raw: TRawPEImage;
hLib: THandle;
ExportFunc: TExportChunk;
begin
hLib := GetModuleHandle('ntdll.dll');
Raw := TRawPEImage.Create('c:\windows\system32\ntdll.dll', ULONG64(hLib));
try
for ExportFunc in Raw.ExportList do
if ExportFunc.FuncAddrVA <> ULONG64(GetProcAddress(hLib, PChar(ExportFunc.FuncName))) then
Writeln(ExportFunc.FuncName, ' wrong addr: ', ExportFunc.FuncAddrVA);
finally
Raw.Free;
end;
end.
В данном примере загружается ntdll.dll и идет проверка рассчитанного адреса каждой экспортируемой функции с его реальным значением, полученным через вызов GetProcAddress.
Если все сделано правильно, то результатом выполнения будет только одна строчка
Export count: 2469
Полученный в результате код достаточен, чтобы перейти к следующему этапу, его можно забрать для самостоятельного изучения по этой ссылке.
Правда если меня сейчас читают люди, полностью понимающие то, что происходит в этой главе, пока не начинайте возмущаться что выполнены не все необходимые шаги по полноценной загрузке таблицы экспорта. Я про это в курсе, но на данном этапе они пока что не нужны — все будет, но чуть позже.
2. Работа со списками загрузчика
Встает вопрос — как получить список загруженных файлов (библиотек) в удаленное адресное пространство процесса.
Вообще, конечно, технически есть вполне себе штатный способ, через вызов EnumProcessModulesEx, но с ним есть нюанс — он не покажет данные по 64 битным модулям, будучи вызван из 32 битного процесса.
В этом можно убедиться вот таким кодом:
function EnumProcessModulesEx(hProcess: THandle; lphModule: PHandle;
cb: DWORD; var lpcbNeeded: DWORD; dwFilterFlag: DWORD): BOOL; stdcall;
external 'psapi.dll';
procedure TestEnumSelfModules;
const
LIST_MODULES_ALL = 3;
var
Buff: array of THandle;
Needed: DWORD;
I: Integer;
FileName: array[0..MAX_PATH] of Char;
begin
EnumProcessModulesEx(GetCurrentProcess, nil, 0, Needed, LIST_MODULES_ALL);
SetLength(Buff, Needed shr 2);
if EnumProcessModulesEx(GetCurrentProcess, @Buff[0], Needed, Needed, LIST_MODULES_ALL) then
begin
for I := 0 to Integer(Needed) - 1 do
if Buff[I] <> 0 then
begin
FillChar(FileName, MAX_PATH, 0);
GetModuleFileNameEx(GetCurrentProcess, Buff[I], @FileName[1], MAX_PATH);
Writeln(I, ': ', IntToHex(Buff[I], 1), ' ', string(PChar(@FileName[1])));
end;
end;
end;
Слева то что он выведет, а справа реальная ситуация. Отображены только 32 битные модули, загруженные из папки C:\Windows\SysWOW64\ причем из-за работающего редиректа, этот факт прячется и пути к библиотекам показываются как C:\Windows\System32\ хотя это на самом деле не так.
Такое ограничение вполне себе понятно, дело в том, что он возвращает список инстансов, а инстанс это адрес загрузки библиотеки, т.е. указатель по сути, который для 32 бит может держать только 4 байта и не сможет вместить в себя полный 64 битный адрес.
Давайте сразу же уточню один момент.
В 64 битной ОС НЕ СУШЕСТВУЕТ 32 битных процессов! Все процессы, без исключения, являются 64 битными, и когда стартует 32 битное приложение, сначала инициализируется 64 битный процесс, в который загружаются библиотеки WOW64 подсистемы и только потом в него загружаются 32 битные образы, которые работают с ОС не напрямую, а через WOW64 подсистему, конвертирующую все 32 битные вызовы API в их 64 битные аналоги.
Именно поэтому:
- В 32 битном процессе постоянно присутствуют загруженные 64 битные библиотеки
- Флаг IMAGE_FILE_LARGE_ADDRESS_AWARE выставленный в РЕ заголовке предоставляет доступ ко всем 4 гигабайтам памяти, а не к трем, как это будет на 32 битной OS при включенном PAE (Physical Address Extension) и флаге /3GB в boot.ini
Так как анализатору нужны все данные, то получать список загруженных модулей придется самостоятельно, через списки загрузчика.
Для это нужно произвести небольшую подготовку.
В модуле RawScanner.Types я декларирую три новых структуры TModuleData, UNICODE_STRING32 и UNICODE_STRING64, и создаю новый модуль RawScanner.Wow64. Он будет содержать все необходимое для работы с 64 битными процессами, а именно обертки над следующими функциями:
- IsWow64Process — для детекта работы WOW64 подсистемы
- Wow64DisableWow64FsRedirection + Wow64RevertWow64FsRedirection — для отключения и включения редиректа библиотек из System32 в SysWOW64
- NtWow64QueryInformationProcess64 — аналог функции NtQueryInformationProcess для работы с 64 битными процессами.
- NtWow64ReadVirtualMemory64 — для чтения памяти удаленного процесса по 64 битным указателям, недоступным при вызове ReadProcessMemory
Так же в модуль RawScanner.Utils добавляю функцию ReadRemoteMemory, в которой будет автоматически приниматься решение какой из вызовов использовать для чтения удаленной памяти.
Структура TModuleData и список TModuleList будут хранить информацию по загруженным модулям и использоваться на следующих этапах.
Итак, где хранятся все данные о загруженных библиотеках? Их формирует загрузчик для каждого процесса (причем в двух экземплярах если процесс 32 битный). Представляет из себя двунаправленный список, доступ к которому нужно получить из блока окружения процесса, который сам по себе также представляет структуру, одним из полей которой является поле PPEB_LDR_DATA→Ldr.
Чтобы получить данные из списков загрузчика, нужно сначала научится правильно прочесть адрес начала этих списков.
Может быть четыре разных ситуации:
- Мы 32 битное приложение, которое будет читать данные из 64 битного
- Мы 64 битное приложение, которое будет читать данные из 32 битного
- Мы приложение, которое будет читать данные из процесса такой-же битности (т.е. два разных случая под разную битность).
Для каждого из перечисленных вариантов применяется свой подход, распишу по шагам.
Шаг первый, открываем процесс и проверяем его битность:
var
hProcess: THandle;
IsWow64Mode: LongBool;
begin
hProcess := OpenProcess(
PROCESS_QUERY_INFORMATION or PROCESS_VM_READ,
False, GetCurrentProcessId);
Wow64Support.IsWow64Process(hProcess, IsWow64Mode);
Флаг IsWow64Mode будет сигнализировать о том, что удаленный процесс работает под WOW64 подсистемой.
Следующим шагом потребуется декларация структуры блока окружения процесса (полная структура не нужна, достаточно будет только до поля загрузчика):
TPEB = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: THandle;
ImageBaseAddress: PVOID;
LoaderData: PVOID; // именно это поле нас и интересует
end;
После чего потребуются еще две декларации её-же только строго соответствующие битности списка загрузчика, из которого будет производится чтение.
Еще раз заострю внимание, у 32 битного процесса на 64 битной ОС таких списков будет два, соответственно блоков окружения процесса, через которые происходит выход на список также будет два, для 64 бит и 32-битный для WOW64!
TPEB32 = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: ULONG;
ImageBaseAddress: ULONG;
LoaderData: ULONG;
end;
TPEB64 = record
InheritedAddressSpace: BOOLEAN;
ReadImageFileExecOptions: BOOLEAN;
BeingDebugged: BOOLEAN;
BitField: BOOLEAN;
Mutant: ULONG_PTR64;
ImageBaseAddress: ULONG_PTR64;
LoaderData: ULONG_PTR64;
end;
Загрузка данных будет достаточно тривиальная, посредством вызова NtQueryInformationProcess с флагом ProcessBasicInformation получаем информацию о процессе, в которой, помимо прочего будет поле PROCESS_BASIC_INFORMATION.PebBaseAddress, содержащее адрес блока окружения процесса.
Вот из него и будут читаться нужные данные.
function ReadNativePeb(hProcess: THandle; out APeb: TPEB64): Boolean;
const
ProcessBasicInformation = 0;
var
PBI: PROCESS_BASIC_INFORMATION;
dwReturnLength: Cardinal;
NativePeb: TPEB;
begin
Result := NtQueryInformationProcess(hProcess,
ProcessBasicInformation, @PBI, SizeOf(PBI), @dwReturnLength) = 0;
if not Result then
Exit;
Result := ReadRemoteMemory(hProcess, ULONG_PTR64(PBI.PebBaseAddress),
@NativePeb, SizeOf(TPEB));
if Result then
{$IFDEF WIN32}
APeb := Convert32PebTo64(TPEB32(NativePeb));
{$ELSE}
APeb := TPEB64(NativePeb);
{$ENDIF}
end;
Данная функция всегда возвращает 64 битный PEB, это сделано только для удобства работы с этой структурой. Если читается 32 битный PEB, то результат преобразуется в 64 битный аналог вызовом Convert32PebTo64.
Но она покрывает только два случая из четырех вышеперечисленных.
- При чтении 32 битного PEB из 32 битного процесса (при этом мы сами находимся в 32 битной сборке)
- При чтении 64 битного PEB из 64 битного процесса (при этом мы сами находимся в 64 битной сборке)
Показываю остальные варианты:
function Read64PebFrom32Bit(hProcess: THandle; out APeb: TPEB64): Boolean;
const
ProcessB
