Системы хранения данных: как выбирать?!
 Проект любой сложности, как ни крути, сталкивается с задачей хранения данных. Таким хранилищем могут быть разные системы: Block storage, File storage, Object storage и Key-value storage. В любом вменяемом проекте перед покупкой того или иного storage-решения проводятся тесты для проверки определённых параметров в определённых условиях. Вспомнив, сколько хороших, сделанных правильно растущими руками проектов прокололись на том, что забыли про масштабируемость, мы решили разобраться: Какие характеристики Block storage и File storage нужно учитывать, если хотите, чтобы при росте проекта система хранения выросла вслед за ним
Почему отказоустойчивость на software уровне надежнее и дешевле, чем на hardware уровне
Как правильно проводить тестирование, чтобы сравнивать «яблоки с яблоками»
Как получить на порядок больше/меньше IOPS, поменяв всего один параметр
В процессе тестирования мы применяли RAID–системы и распределенную систему хранения данных Parallels Cloud Storage (PStorage). PStorage входит в продукт Parallels Cloud Server.Начнем с того, что определим основные характеристики, на которые нужно обратить внимание при выборе системы хранения. Они же будут определять структуру поста.
Проект любой сложности, как ни крути, сталкивается с задачей хранения данных. Таким хранилищем могут быть разные системы: Block storage, File storage, Object storage и Key-value storage. В любом вменяемом проекте перед покупкой того или иного storage-решения проводятся тесты для проверки определённых параметров в определённых условиях. Вспомнив, сколько хороших, сделанных правильно растущими руками проектов прокололись на том, что забыли про масштабируемость, мы решили разобраться: Какие характеристики Block storage и File storage нужно учитывать, если хотите, чтобы при росте проекта система хранения выросла вслед за ним
Почему отказоустойчивость на software уровне надежнее и дешевле, чем на hardware уровне
Как правильно проводить тестирование, чтобы сравнивать «яблоки с яблоками»
Как получить на порядок больше/меньше IOPS, поменяв всего один параметр
В процессе тестирования мы применяли RAID–системы и распределенную систему хранения данных Parallels Cloud Storage (PStorage). PStorage входит в продукт Parallels Cloud Server.Начнем с того, что определим основные характеристики, на которые нужно обратить внимание при выборе системы хранения. Они же будут определять структуру поста.
Отказоустойчивость Скорость восстановления данных Производительность, соответствующая вашим запросам. Консистентность данных ОтказоустойчивостьСамая важное свойство системы хранения данных — это то, что система призвана СОХРАНЯТЬ данные без каких-либо компромиссов, то есть обеспечивать максимальную доступность и ни в коем случае не потерять даже малой их части. Почему-то очень многие задумываются о производительности, цене, но мало внимания уделяют надежности хранения данных.Для обеспечения отказоустойчивости в случае сбоя существует одна-единственная техника — резервирование. Вопрос в том, на каком уровне применяется резервирование. С некоторым грубым упрощением, можно сказать, что уровня два: Hardware и Software.
 Резервирование на уровне Hardware давно зарекомендовало себя в Enterprise-системах. SAN/NAS коробки имеют двойное резервирование всех модулей (два, а то и три блока питания, пара плат «мозгов») и сохраняют данные одновременно на нескольких дисках внутри одной коробки. Лично я метафорически представляю это себе как очень безопасную кружку: максимально надежную для сохранения жидкости внутри, с толстыми стенками и обязательно с двумя ручками на случай, если одна из них сломается.
Резервирование на уровне Hardware давно зарекомендовало себя в Enterprise-системах. SAN/NAS коробки имеют двойное резервирование всех модулей (два, а то и три блока питания, пара плат «мозгов») и сохраняют данные одновременно на нескольких дисках внутри одной коробки. Лично я метафорически представляю это себе как очень безопасную кружку: максимально надежную для сохранения жидкости внутри, с толстыми стенками и обязательно с двумя ручками на случай, если одна из них сломается.
 Резервирование на уровне Software только начинает проникать в Enterprise-системы, но с каждым годом отъедает все больший и больший кусок у HW решений. Принцип тут прост. Такие системы не полагаются на надежность железа. Они считают, что оно априори ненадежно, и решают задачи резервирования на уровне ПО, создавая копии (реплики) данных и храня их на физически разном железе. Продолжая аналогию с чашками, это — когда есть несколько совершенно обычных чашек, и ты разлил чай в обе, вдруг одна разобьется.
Резервирование на уровне Software только начинает проникать в Enterprise-системы, но с каждым годом отъедает все больший и больший кусок у HW решений. Принцип тут прост. Такие системы не полагаются на надежность железа. Они считают, что оно априори ненадежно, и решают задачи резервирования на уровне ПО, создавая копии (реплики) данных и храня их на физически разном железе. Продолжая аналогию с чашками, это — когда есть несколько совершенно обычных чашек, и ты разлил чай в обе, вдруг одна разобьется.
Таким образом, SW решения не требуют дорогостоящего оборудования, как правило, более выгодны, но при этом обеспечивают ровно такую же отказоустойчивость, хотя и на другом уровне. Их также легче оптимизировать, например, разносить данные на разные сайты, выполнять балансировку, менять уровень отказоустойчивости, линейно масштабировать при росте кластера.
Расскажу, как решается вопрос резервирования на примере Parallels Cloud Storage (PStorage). PStorage не имеет привязки к какому-либо вендору железа и способен работать на совершенно обычных машинах, вплоть до настольных PC. Мы не доверяем железу, поэтому архитектура PStorage рассчитана на потерю любого физического сервера целиком (а не только отдельного диска). Все данные в Parallels Cloud Storage хранятся в нескольких копиях (репликах). При этом PStorage никогда не хранит более одной копии на физическом сервере/стойке/комнате (как захотите). Мы рекомендуем хранить 3 копии данных, чтобы быть защищенным от одновременного сбоя сразу двух серверов/стоек.
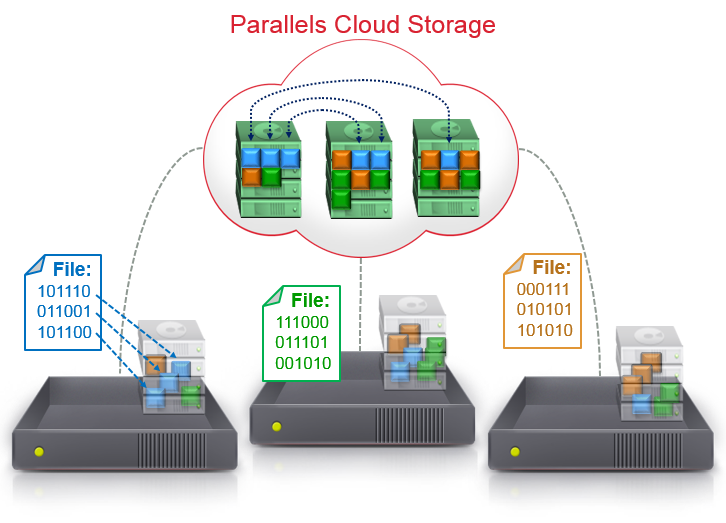 Комментарий: на рисунке показан пример кластера, хранящего данные в двух копиях.
Комментарий: на рисунке показан пример кластера, хранящего данные в двух копиях.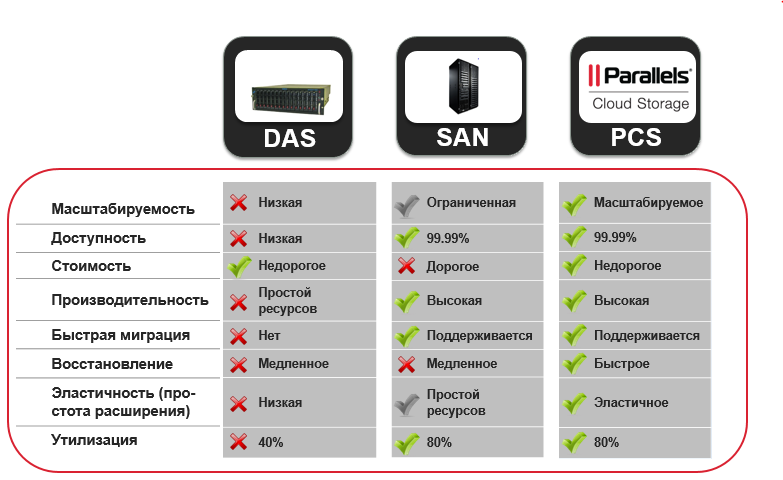
Скорость восстановления данных Что происходит, если один из дисков выходит из строя? Для начала рассмотрим обычный HW RAID1 (mirror) из двух дисков. В случае выпадения одного диска, RAID продолжает работать с оставшимся, ожидая момента замены сломавшегося диска. Т.е. в это время RAID уязвим: оставшийся диск хранит единственную копию данных. У одного из наших клиентов был случай, когда в их дата-центре проводили ремонт и пилили металл. Стружки летели прямо на работающие сервера, и в течение нескольких часов диски в них стали вылетать один за другим. Тогда система была организована на обычных RAID, и в результате провайдер потерял часть данных.
Сколько времени система находится в уязвимом состоянии — зависит от времени восстановления. Эту зависимость описывает следующая формула:
MTTDL ~= 1 / T^2 * С, где T — это время восстановления, а the mean time to data loss (MTTDL) — среднее время наработки до потери данных, С — некий коэффициент.
Итак, чем быстрее система восстановит необходимое количество копий данных, тем меньше вероятность потерять данные. Здесь мы даже опустим тот факт, что для начала процесса восстановления HW RAID администратору нужно заменить дохлый диск на новый, а на это тоже нужно время, особенно если диск нужно заказывать.Для RAID1 время восстановления — это время, за которое RAID контроллер перельет данные с рабочего диска на новый. Как легко догадаться, скорость копирования будет равна скорости чтения/записи HDD, то есть примерно 100 MB/s, если RAID контроллер совершенно не нагружен. А если в это время RAID котроллер грузят извне, то скорость будет в несколько раз ниже. Вдумчивый читатель проведет аналогичные расчёты для RAID10, RAID5, RAID6 и придет к выводу, что любой HW RAID восстанавливается со скоростью не выше скорости одного диска.
SAN/NAS системы почти всегда используют аналогичный обычному RAID подход. Они группируют диски и собирают из них RAID. Собственно, скорость восстановления такая же.
На Software уровне гораздо больше возможностей для оптимизации. Например, в PStorage данные распределяются по всему кластеру и по всем дискам кластера, и в случае выхода из строя одного из дисков репликация начинается автоматически. Здесь не нужно ждать, когда администратор заменит диск. Кроме того, в репликации участвуют все диски кластера, поэтому скорость восстановления данных намного выше. Мы записывали данные в кластер, отключали один сервер из кластера и замеряли время, за которое кластер восстановит недостающее количество реплик. На графике результат для кластера из 7/14/21 физической ноды с двумя SATA дисками по 1TB. Кластер собран на 1GB сети.
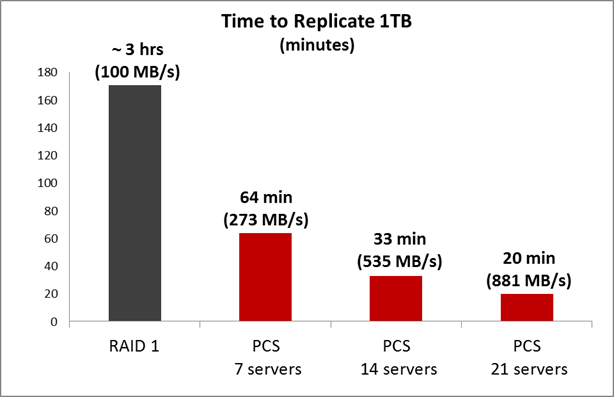
Если использовать 10Gbit сеть, то скорость будет еще выше.
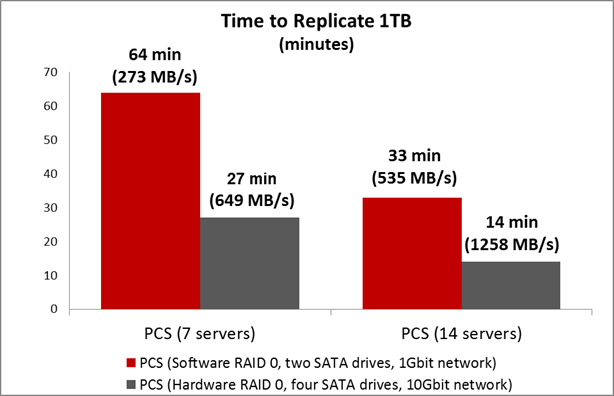
Комментарий: Здесь нет ошибки в том, что на 1Gbit сети скорость восстановления кластера из 21 сервера — почти гигабайт в секунду. Дело в том, что данные, сохранённые в Parallels Cloud Storage, распределены по дискам кластера (некий stripe в масштабе кластера), таким образом, мы получаем возможность параллельно производить копирование данных с разных дисков на разные. То есть нет единой точки владения данными, которая могла бы быть узким местом теста.
Полный сценарий теста можно найти в этом документе, при желании вы сможете его повторить самостоятельно.
Как правильно тестировать производительность — советы Основываясь на нашем опыте тестирования систем хранения данных, я бы выделил основные правила: Надо «определиться с хотелками». Что именно хочется получить от системы и сколько. Наши клиенты в большинстве случаев используют Parallels Cloud Storage для построения кластера высокой доступности для виртуальных машин и контейнеров. То есть каждая из машин кластера одновременно предоставляет и storage, и исполняет виртуальные машины. Таким образом, в кластере не требуется выделенной внешней «хранилки данных». В терминах производительности это значит, что кластер получает нагрузку от каждого сервера. Поэтому в примере мы будем всегда нагружать кластер параллельно со всех физических серверов кластера. Не нужно использование хорошо сжимаемые шаблоны данных. Многие HDDs/SSDs диски, системы хранения данных, а также виртуальные машины иногда имеют специальные Low-level оптимизации для обработки нулевых-данных. В таких ситуациях легко заметить, что запись нулей на диск происходит несколько быстрее, чем запись случайных данных. Типичным примером такой ошибки служит всем известный тест: dd if=/dev/zero of=/dev/sda size=1M Лучше использовать случайные данные при тестировании. При этом генерация этих данных не должна влиять на сам тест. Т.е. лучше сгенерировать случайные данные заранее, например в файл. В противном случае тест упрется в генерацию данных, как в следующем примере: dd if=/dev/random of=/dev/sda size=1M Учитывайте расстояние между компонентами, разнесенными друг от друга. Естественно, что коммуникация между распределёнными компонентами может содержать задержки. Стоит помнить об этом возможном узком месте при нагрузках. Особенно сетевых задержках и пропускной способности сети. Отведите не меньше минуты на проведение теста. Время теста должно быть продолжительным. Проводите один тест несколько раз, чтобы сгладить отклонения. Используйте большой объем данных для нагрузки (working set). Working set — это очень важный параметр, так как он сильно влияет на производительность. Именно он может изменить результат тестирования в десятки раз. Например, с RAID контроллером Adaptec 71605, random I/O на 512M файле показывает 100K iops, а на 2GB файле — всего 3К IOPS. Разница в производительности в 30 раз обусловлена RAID-кешем (попаданием и не попаданием в кеш в зависимости от объема нагрузки). Если вы собираетесь работать с данными больше, чем объем кэша вашей системы хранения (в данном примере 512M), то используйте именно такие объемы. Для виртуальных машин мы используем 16GB. И конечно, всегда сравнивайте только «яблоки с яблоками». Необходимо сравнивать системы с одинаковой отказоустойчивостью на одинаковом железе. Например, нельзя сравнивать RAID0 c PStorage, так как PStorage обеспечивает отказоустойчивость при вылете дисков/серверов, а RAID0 нет. Правильно в этом случае будет сравнивать RAID1/6/10 c PStorage. Ниже приведу результаты тестирования по описанной методологии. Мы сравниваем производительность локального RAID1 («host RAID 1») с кластером PStorage («PCS»). Те самые «яблоки с яблоками». Следует обратить внимание, что необходимо сравнивать системы с одинаковым уровнем избыточности. PStorage в этих тестах хранил информацию в двух копиях (replicas=2) вместо рекомендованных трех, чтобы уровень отказоустойчивости быть одинаковый для обоих систем. Иначе сравнение было бы нечестным: PStorage (replicas=3) позволяет потерять 2 любых диска/сервера одновременно, когда RAID1 из 2 дисков — всего 1. Мы используем одинаковое железо для всех тестов: 1,10,21 одинаковых физических серверов с двумя 1TB SATA дисками, 1Gbit сетью, core i5 CPU, 16GB RAM. Если кластер состоит из 21 сервера, то его производительность сравнивается с суммарной производительностью 21 локального RAID. Нагрузка производилась в 16 потоков на каждой физической ноде одновременно. Каждая нода имела working set в 16GB, то есть, например, для RANDOM 4K теста в целом на кластере нагрузчики случайно ходили по 336GB данным. Время нагрузки — 1 минута, каждый тест проводился 3 раза.Колонки «PCS+SSD» показывают производительность того же кластера, но с SSD-кешированием. PStorage имеет встроенную возможность использовать локальные SSD для write-журналирования, read-кеширования, что позволяет в несколько раз превзойти производительность локальных вращающихся дисков. Также SSD диски могут быть использованы для создания отдельного слоя (tier) с большей производительностью.
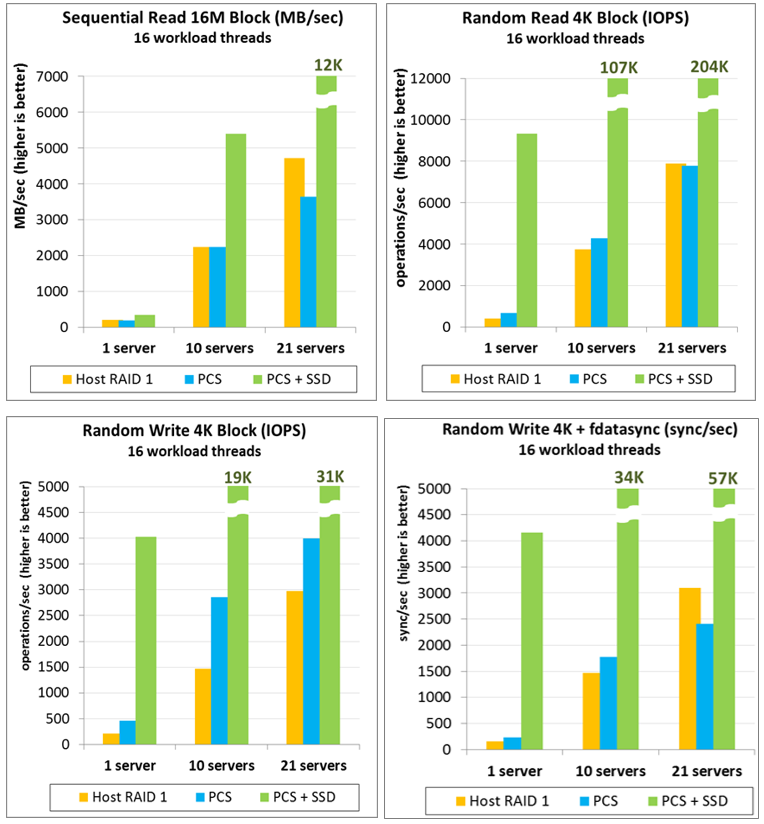
Выводы Коротко резюмирую: Выбирая тип резервирования, склоняемся к «уровню ПО». Software уровень предоставляет больше возможностей для оптимизации и позволяет снизить требования к железу и удешевить систему в целом. Тесты проводим на определенных условиях (см. наши советы) Обращаем внимание на скорость восстановления — очень важный параметр, который при недостаточной эффективности может попросту погубить часть бизнеса. Также вы можете протестировать и наше собственное решение, тем более что мы даем это сделать бесплатно. По крайней мере, на наших собственных тестах Parallels Cloud Storage показывает наибольшую скорость восстановления данных в случае потери диска (больше, чем в RAID системах, включая SAN) и производительность как минимум не хуже локального RAID, а с SSD-кешированием — и выше.О консистентности данных мы планируем поговорить подробнее в отдельном посте.
Как попробовать Parallels Cloud Storage Официальная страничка продукта тут. Чтобы бесплатно попробовать, заполните анкету.Также PStorage доступен для проекта OpenVZ.Почитать о том, как PCS работает в FastVPS можно в этом посте.Что показывают ваши тесты, плюсы-минусы — можем подробно обсудить в комментариях.
