Синтетическое генерирование данных (SMOTE)

Привет, Хабр!
В далеком 2002 году, когда многие из нас еще тусовались на IRC и мечтали о широкополосном интернете, Нитеш Чавла и его команда представили миру SMOTE. Этот алгоритм решал больную проблему — несбалансированность классов в обучающих данных.
Почему несбалансированные данные — это большая проблема? К примеру у нас есть набор данных, где один класс значительно преобладает над другим. В такой ситуации наша ml моделька может просто «забить» на малочисленный класс, сосредоточившись на многочисленных классах. Это приводит к ситуации, когда модель хорошо работает на общем уровне, но плохо распознаёт важные исключения или редкие случаи.
SMOTE не просто дублирует минорные классы, как это делает простой oversampling, он создает новые, синтетические примеры, которые помогают модели лучше понять и обобщить характеристики минорных классов.
Про библиотеку SMOTE в питоне
Устанавливаем imbalanced-learn, которая включает в себя SMOTE.
pip install imbalanced-learnИмпорт выглядит так:
from imblearn.over_sampling import SMOTESMOTE инициализируется с рядом параметров, которые позволяют настроить процесс генерации синтетических данных:
smote = SMOTE(
sampling_strategy='auto', # Стратегия выборки. 'auto' означает увеличение меньшего класса до размера большинственного.
random_state=None, # Зерно для генератора случайных чисел.
k_neighbors=5, # Количество ближайших соседей для создания синтетических примеров.
n_jobs=1 # Количество ядер для параллельной работы. -1 означает использование всех доступных ядер.
)Для применения SMOTE к вашим данным, вам нужно вызвать метод fit_resample:
X_resampled, y_resampled = smote.fit_resample(X, y)X и y — это ваши исходные данные и метки соответственно. X_resampled и y_resampled — это новые данные и метки после применения SMOTE.
Параметры smote:
sampling_strategy: определяет соотношение числа примеров в меньшинственном классе после ресэмплинга к числу примеров в многочисленном классе. Значения могут быть различными: от доли (между 0 и 1) до 'auto', которое уравнивает количество примеров в классах.
random_state: зерно для генератора случайных чисел.
k_neighbors: количество ближайших соседей, используемых для создания синтетических примеров.
n_jobs: количество ядер для параллельной работы.
SMOTE также может быть скомбинирован с другими методами ресэмплинга для достижения еще более сбалансированных и разнообразных данных. Например, вы можете сочетать его с случайным андерсэмплингом многочисленного класса:
from imblearn.pipeline import make_pipeline
from imblearn.under_sampling import RandomUnderSampler
pipeline = make_pipeline(
RandomUnderSampler(), # Сначала применяем андерсэмплинг
SMOTE() # Затем применяем SMOTE
)
X_resampled, y_resampled = pipeline.fit_resample(X, y)Как работает SMOTE?
Выбор образца
Когда мы говорим о выборе образца, мы имеем в виду выбор конкретного примера из малочисленного класса, который будет использоваться для генерации новых синтетических данных. Это делается для того, чтобы улучшить баланс между классами в нашем наборе данных.
Если выбрать не тот образец, который не является репрезентативным для малочисленного класса, сгенерированные данные могут ввести модель в заблуждение.
Обычно образец выбирается случайным образом из малочисленного класса. Это делается для того, чтобы обеспечить разнообразие и предотвратить смещение в сторону какой-либо конкретной области пространства признаков. Однако, в некоторых случаях, выбор может быть и целенаправленным, основанным на определенных критериях, например, близости к границе решения.
Нахождение k ближайших соседей
После того как мы выбрали наш образец из малочисленного класса, следующий шаг — найти его k ближайших соседей.
Идея здесь проста: мы хотим создать новые данные, которые будут похожи на уже существующие, но при этом добавят немного разнообразия. Ближайшие соседи дают нам именно это — они похожи на наш выбранный образец, но каждый из них добавляет свою уникальность в микс.
Количество соседей k обычно выбирается экспериментально. Часто используют 5, но это число может варьироваться в зависимости от размера и природы ваших данных. Тут надо найти баланс: слишком маленькое k может привести к недостаточному разнообразию, а слишком большое — к потере специфики малочисленного класса.
import numpy as np
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
# создаем рандом набор данных
np.random.seed(0)
majority_class = np.random.rand(50, 2) + 1 # многочисленный класс
minority_class = np.random.rand(10, 2) # малочисленный класс
# чуз образца из меньшинственного класса
sample_index = np.random.randint(0, len(minority_class))
sample = minority_class[sample_index]
# колво соседей
k = 5
# NearestNeighbors для нахождения k ближайших соседей
neighbors = NearestNeighbors(n_neighbors=k).fit(minority_class)
distances, indices = neighbors.kneighbors([sample])
# визуализируем
plt.figure(figsize=(10, 6))
plt.scatter(majority_class[:, 0], majority_class[:, 1], label='Большинственный класс', alpha=0.6)
plt.scatter(minority_class[:, 0], minority_class[:, 1], label='Меньшинственный класс', alpha=0.6)
plt.scatter(sample[0], sample[1], label='Выбранный образец', c='red', edgecolor='black', s=100) # Увеличенный размер для видимости
plt.scatter(minority_class[indices][0][:, 0], minority_class[indices][0][:, 1], label='k ближайших соседей', c='green', edgecolor='black')
plt.title('k ближайших соседей для выбранного образца')
plt.legend()
plt.show()
# для сокращения текста в графике здесь многочисленный класс - большнитсвенный, а малочисленный - меньшинственный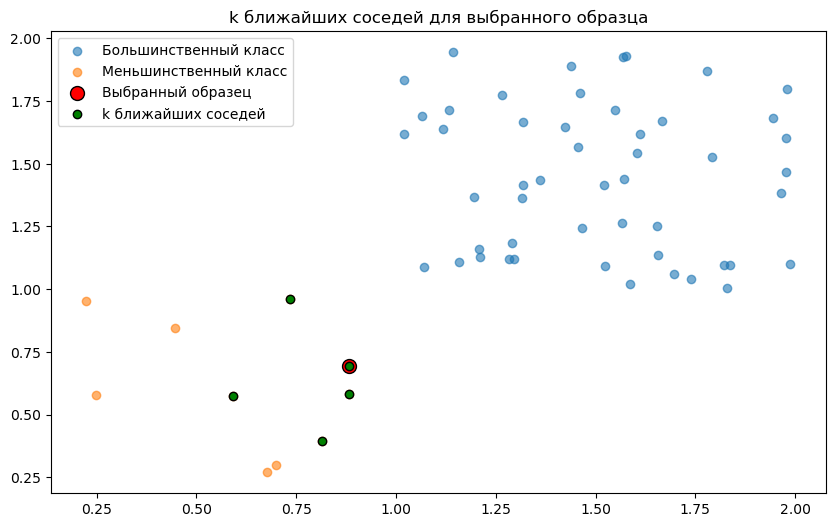
Создание синтетических примеров
На этом этапе у нас уже есть выбранный образец из малочисленного класса и его k ближайших соседей. Теперь наша задача — создать новые, синтетические данные, которые помогут сбалансировать классы.
Процесс создания синтетических примеров в SMOTE довольно прост. Мы берем наш выбранный образец и одного из его соседей, выбранного случайным образом. Затем мы интерполируем между этими двумя точками, чтобы создать новый образец. Это означает, что новый образец будет где-то между ними в пространстве признаков, наследуя характеристики обоих.
Интерполяция между образцами позволяет нам создавать новые данные, которые сохраняют общие характеристики малочисленного класса, но при этом добавляют немного разнообразия.
Создадим синтетические примеры:
import numpy as np
from sklearn.neighbors import NearestNeighbors
# Предполагаем, что у нас уже есть данные и выбранный образец
# majority_class и minority_class определены на предыдущем шаге
# sample - выбранный образец из малочисленного класса
# indices - индексы k ближайших соседей выбранного образца
def create_synthetic_points(sample, neighbors, n_synthetic):
synthetic_points = []
for _ in range(n_synthetic):
# выбираем случ. соседа
neighbor = neighbors[np.random.randint(0, len(neighbors))]
# генерируем случайное числое
fraction = np.random.rand()
# синт. пример
synthetic_point = sample + (neighbor - sample) * fraction
synthetic_points.append(synthetic_point)
return np.array(synthetic_points)
# колво синтетических примеров для создания
n_synthetic = 10
# k ближайших соседей из предыдущего шага
neighbors = minority_class[indices][0]
synthetic_samples = create_synthetic_points(sample, neighbors, n_synthetic)
print("Синтетические примеры:\n", synthetic_samples)Результат:
Синтетические примеры:
[[0.78736418 0.86618803]
[0.88173536 0.69253159]
[0.87892276 0.69770717]
[0.88173536 0.69253159]
[0.88146431 0.64482733]
[0.86819877 0.71744085]
[0.88138652 0.63113722]
[0.6010335 0.57598517]
[0.88173536 0.69253159]
[0.82787235 0.7916472 ]]Интеграция синтетических данных в обучающий набор
Созданные синтетические примеры затем добавляются к исходному набору данных.
Вариации SMOTE
Borderline-SMOTE
Borderline-SMOTE фокусируется на образцах, которые находятся на границе между классами. Идея здесь в том, что эти образцы часто являются наиболее трудными для классификации и, следовательно, наиболее важными для обучения модели.
Сначала идентифицируются граничные образцы малочисленного класса. Это те, которые имеют много соседей из многочисленного класса. Затем SMOTE применяется только к этим граничным образцам, увеличивая их количество и тем самым усиливая границу решения вокруг них.
Можно реализовать так:
from imblearn.over_sampling import BorderlineSMOTE
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
# создаем рандом енабор данных
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
# разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
sm = BorderlineSMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X_train, y_train)
clf = SVC(gamma='auto')
clf.fit(X_res, y_res)
# оцениваем модель
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
plt.scatter(X_res[y_res == 0][:, 0], X_res[y_res == 0][:, 1], label='Класс 0', alpha=0.5)
plt.scatter(X_res[y_res == 1][:, 0], X_res[y_res == 1][:, 1], label='Класс 1', alpha=0.5)
plt.title('Borderline-SMOTE')
plt.legend()
plt.show() precision recall f1-score support
0 1.00 0.96 0.98 26
1 1.00 1.00 1.00 224
accuracy 1.00 250
macro avg 1.00 0.98 0.99 250
weighted avg 1.00 1.00 1.00 250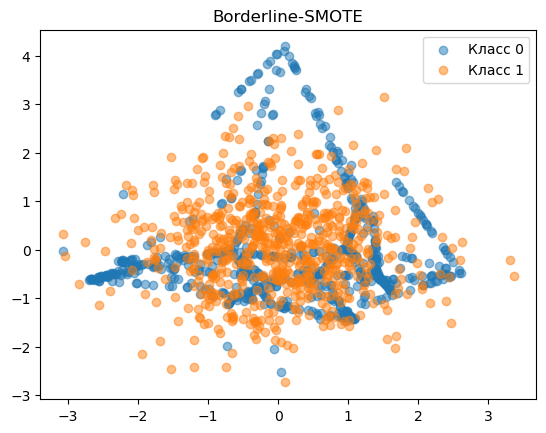
SVM-SMOTE
SVM-SMOTE использует машину опорных векторов (SVM) для определения образцов, которые будут усилены. SVM хорошо известен своей способностью находить оптимальные границы решения между классами.
По началу мы обучаем SVM-классификатор. Затем образцы, которые находятся ближе всего к границе решения (опорные векторы), используются для генерации новых синтетических данных.
Адаптивный SMOTE (ADASYN)
ADASYN сосредотачивается на образцах, для которых классификация является наиболее сложной, и генерирует больше синтетических данных для этих образцов. Количество синтетических данных для каждого образца определяется на основе количества соседей из другого класса — чем больше соседей из другого класса, тем больше синтетических данных будет сгенерировано.
SMOTE с Undersampling
Undersampling — это техника уменьшения количества образцов в многочисленном классе. Когда мы комбинируем это с SMOTE, мы одновременно увеличиваем количество образцов в меньшинственном классе и уменьшаем количество образцов в большинственном классе.
Сначала применяем SMOTE для увеличения количества образцов малочисленного класса. Затем применяем undersampling к многочисленному классу, чтобы уменьшить его размер до более сбалансированного уровня:
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import Pipeline
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# cочетаем smote и андресемпл
pipeline = Pipeline([
('smote', SMOTE(random_state=42)),
('under', RandomUnderSampler(random_state=42))
])
X_resampled, y_resampled = pipeline.fit_resample(X_train, y_train)
classifier = RandomForestClassifier(random_state=42)
classifier.fit(X_resampled, y_resampled)
y_pred = classifier.predict(X_test)
print(classification_report(y_test, y_pred))Когда SMOTE может ухудшить результаты
В данных с высокой размерностью расстояния между точками становятся менее различимыми. Это означает, что концепция ближайшего соседа теряет свою четкость, и SMOTE может создавать синтетические образцы, которые не являются репрезентативными для малочисленного класса.
Если в данных много шума, SMOTE может усилить этот шум, создавая синтетические образцы на основе аномальных или ошибочных точек данных.
В некоторых случаях распределение малочисленного класса может быть слишком сложным или разрозненным. SMOTE в таких ситуациях может создать синтетические образцы, которые не отражают реальное распределение класса.
SMOTE предполагает, что данные являются числовыми и непрерывными. Если ваши данные содержат категориальные признаки, SMOTE может неправильно интерполировать между этими точками, создавая бессмысленные синтетические образцы.
SMOTE — это хороший инструмент для работы с данными.
Keep coding, keep improving, и до новых встреч на Хабре.
Не забывайте заглядывать в наш каталог курсов.
