Мониторинг Apache Airflow. Оценка «прожорливости» тасок
Всем привет! Случались ли у вас ситуации, когда количество DAG«ов в вашем Airflow переваливает за 800 и увеличивается на 10–20 DAG«ов в неделю? Согласен, звучит страшно, чувствуешь себя тем героем из Subway Surfers… А теперь представьте, что эта платформа является единой точкой входа для всех аналитиков из различных команд и DAG«и пишут более 50 различных специалистов. Подкосились ноги, холодный пот и желание уйти из IT?
Не спешите паниковать, под катом я расскажу о том, как контролировать потребление ресурсов DAG«ов Airflow для предупреждения неоптимально написанных DAG«ов и борьбы с ними.
Меня зовут Давид Хоперия, я Data Engineer в департаменте данных Ozon.Fintech и моим основным инструментом является Apache Airflow, поэтому настало время углубиться в детали его работы.
Немного вводных
Apache Airflow в Ozon.Fintech стал де-факто «народным» инструментом для аналитики благодаря компонентному подходу. Наша команда реализовала широкий набор кастомных операторов и сенсоров, который позволяет аналитикам создавать DAG«и практически под любую задачу. Однако у данного подхода есть серьезный минус — оптимизация.
Ни для кого не секрет, что бизнес всегда был заинтересован в скорейшей разработке новых аналитических продуктов, особенно это касается быстроразвивающихся компаний. Аналитикам в такой ситуации необходимо быстро разрабатывать решения, даже если пострадает их оптимальность с точки зрения потребления ресурсов. Такой процесс забирает драгоценные ресурсы сервера Airflow, которых у него и так не много.
Ограниченность ресурсов Airflow вызвана не жадностью, а понимаем, что инструмент оркестрации — не то же самое, что и ETL-инструмент, а это значит, что хранить и обрабатывать на нем большие объемы данных неправильно.
Грамотный мониторинг помог бы решить главную проблему, которую вручную из-за количества DAG«ов решать затруднительно — определить самые неоптимальные task«и и обратить на них внимание аналитиков.
Входные ограничения
Думаю, для тех, кто работает с Airflow или по крайней мере интересуется популярными open-source решениями, не является секретом, что с версии 2.7.3 у Airflow появилась поддержка Open Telemetry. Про этот стандарт можно почитать отдельно в статье @Color «OpenTelemetry на практике» или на официальном сайте, однако стоит объяснить почему мы не стали использовать его в своей работе.
На самом деле причины две:
Работа с Airflow версии 2.2.5 и неготовность обновлять восемь сотен DAG«ов в начале года;
Сомнения в стабильности решения от Airflow.
И если второй пункт может вызвать вопросы и является субъективным недоверием ко всему новому и свежему, то по первому пункту стоит пояснить.
Каждая версия Airflow приносит сюрпризы — то, что работало раньше, может сломаться. Поэтому обновиться сразу с версии 2.2.5 до 2.7.3 не получится, нужно накатывать версию за версией.
Task Airflow с точки зрения операционной системы
Определив направление деятельности, а именно мониторинг потребления ресурсов task«ами, предлагаю последовательно начать разбираться, что лежит внутри любимого многими «воздушного потока» на примере его работы с Celery.
Для простоты восприятия начать стоит с конца, то есть с task«и. Когда мы говорим о task«e Airflow, в голову сразу приходит оператор, класс, который содержит в себе некоторые инструкции и выполняет определенную работу. На самом же деле, task«a Airflow — это, в первую очередь, процесс, а значит наша задача сводится к мониторингу ресурсов, потребляемых конкретным процессом.
Как оценить потребление ресурсов конкретным процессом? Легко! В Python существует модуль psutil, который поможет нам с этим. Для этого нам необходимо знать идентификатор процесса и использовать встроенные методы. Попробуем написать достаточно простую функцию мониторинга интересующего нас процесса:
def monitor_process(process_id: int, metrics: Dict[str, Value]) -> None:
"""
Monitor a tracked process's consumption metrics.
This function measures CPU and memory resource consumption and writes it
to shared memory variables if it is greater than it was.
The measurement interval is 1 second.
Args:
process_id (int): The tracked process ID.
metrics (Dict[str, Value]): A dictionary containing consumption metrics.
Returns:
None
Raises:
None
"""
import psutil
import time
print('Monitoring process ID: ', os.getpid())
# Define process start datetime
process_start_dt = datetime.now()
print('Monitoring process started at: ', process_start_dt)
# Get tracked process
tracked_process = psutil.Process(process_id)
# Monitor the process while it is active and has not timed out
while tracked_process.is_running():
with tracked_process.oneshot():
metrics['cpu_threads_cnt'].value = max(
metrics['cpu_threads_cnt'].value,
tracked_process.num_threads()
)
metrics['cpu_times_sec'].value = max(
metrics['cpu_times_sec'].value,
sum(tracked_process.cpu_times()[:2])
)
metrics['cpu_utilization_percent'].value = max(
metrics['cpu_utilization_percent'].value,
tracked_process.cpu_percent()
)
metrics['memory_rss_b'].value = max(
metrics['memory_rss_b'].value,
tracked_process.memory_info()[0]
)
metrics['memory_vms_b'].value = max(
metrics['memory_vms_b'].value,
tracked_process.memory_info()[1]
)
metrics['memory_rss_percent'].value = max(
metrics['memory_rss_percent'].value,
tracked_process.memory_percent('rss')
)
metrics['memory_vms_percent'].value = max(
metrics['memory_vms_percent'].value,
tracked_process.memory_percent('vms')
)
# Wait 1 second before next metrics gathering
time.sleep(1)Что ж, функция действительно получилась простой и состоящей всего лишь из:
Определения процесса с помощью его идентификатора;
Запуска цикла, пока «подопытный» процесс активен;
Сбора метрик и сохранения максимального значения с периодичностью в 1 секунду.
Забегая вперед, скажем, что для мониторинга процесса необходим еще один daemon-процесс, который будет следить за своих «хозяином». И именно эта функция и будет тем самым процессом мониторинга, создать который мы стремимся.
Внутренний мир Airflow
И вот мы подошли к самой интересной и сложной части — созданию daemon-процесса для каждой task«и. Первое, что приходит в голову для создания процесса — это модуль multiprocessing, но все не так просто…
Если вы попробуете выполнить код, указанный ниже, то получите ошибку, указывающую на то, что у daemon-процесса не может быть дочерних процессов.
from multiprocessing import Process
# Define main process ID
main_process_id = os.getpid()
print('Main process id: ', main_process_id)
# Define monitoring process
monitoring_process = Process(
target=monitor_process,
args=(main_process_id, consumption_metrics),
daemon=True
)
print('Monitoring process defined.')
# Start monitoring process
monitoring_process.start()После стадии отрицания приходит стадия принятия, и эта ситуация не исключение. Значит, нам необходимо осознать ошибку и отправить в глубины Airflow + Celery.
Вы же не думали, что Airflow выполняет task«и с помощью одного процесса? Конечно нет, существует целая цепочка взаимосвязанных между собой процессов, отвечающих за выполнение наших task«ов. Познакомимся с ними поближе, на картинке ниже изображена Sequence диаграмма в нотации UML. Предлагаю внимательно ее изучить, а после я попытаюсь ее понятно прокомментировать.
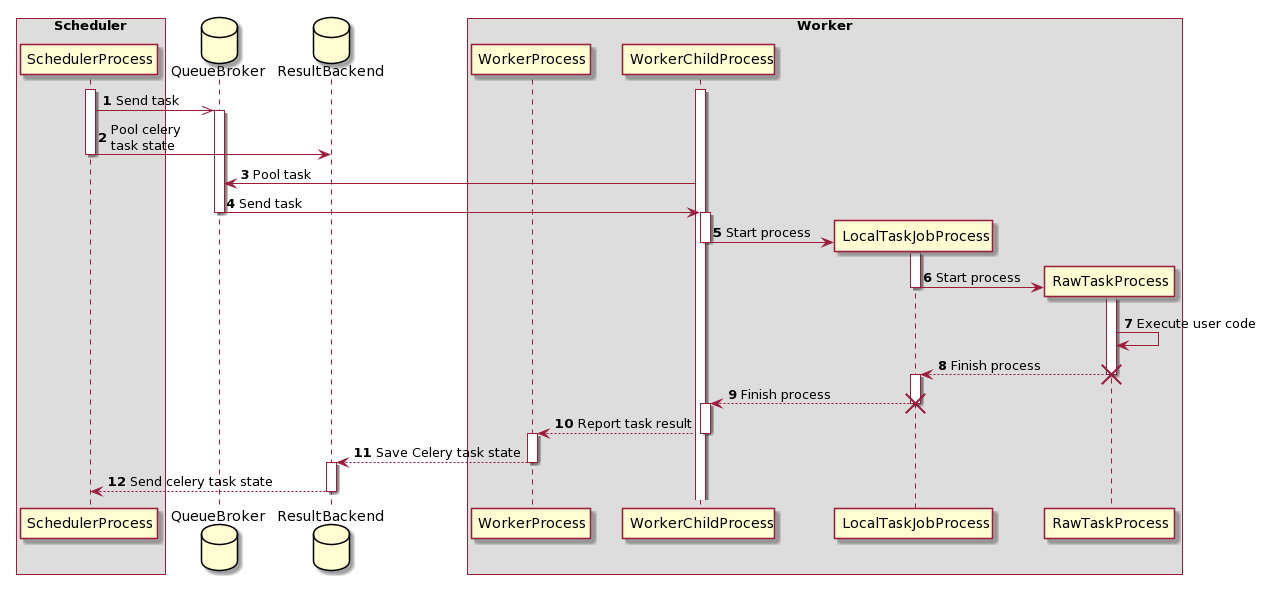
Итак, на данной схеме мы видим следующий процесс:
SchedulerProcess, о существовании которого многие знали, а кто-то догадывался, следит за расписание и, если время выполнения конкретной task«и настало помещает ее в QueueBroker, закидывая таким образом ее в очередь (статус в интерфейсе queued), параллельно с этим SchedulerProcess начинает регулярно опрашивать ResultBackend о статусе работы этой task«и, чтобы мы видели ее актуальное состояние в интерфейсе;
QueueBroker, в свою очередь, когда ему становится известно о задаче, отправляет информацию о ней одному конкретному WorkerProcess;
Получив информацию о задаче, WorkerProcess назначает конкретную задачу на WorkerChildProcess; **4) WorkerChildProcess выполняет необходимые функции обработки task«и и создает новый процесс — LocalTaskJobProcess.
LocalTaskJobProcess с помощью TaskRunner запускет RawTaskProcess, при этом начиная мониторить его выполнение;
RawTaskProcess — непосредственно выполняет программный код и возвращает статус.
RawTaskProcess и LocalTaskJobProcess останавливаются, когда RawTaskProcess завершает выполнение программного кода;
WorkerChildProcess уведомляет главный процесс — WorkerProcess о завершении задачи;
WorkerProcess сохраняет информацию о состоянии в ResultBackend.
Таким образом, мы видим, что выполнение одной таски — работа 4 процессов внутри worker«a. Однако для точности изменений мониторить нам необходим RawTaskProcess, так как остальные процессы выступают в роли контролирующих элементов и большую часть времени находятся в ожидании.
На картинке ниже представлен лог выполнения одной task«и:
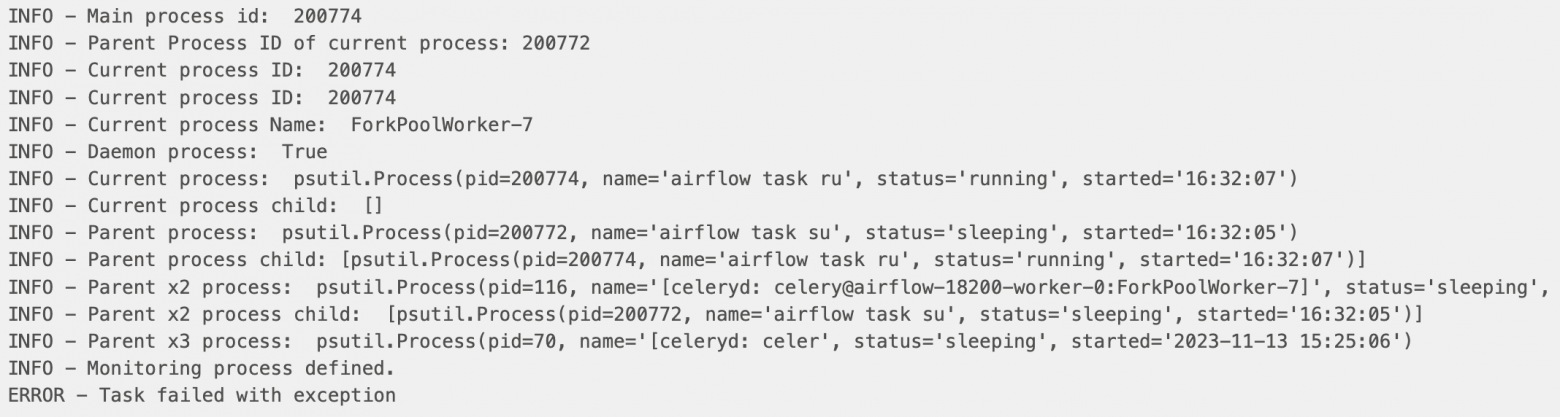
На самом деле, нам не составляет труда получить информацию обо всех 4 процессах в рамках данного worker«a и task«и, однако все процессы, кроме RawTaskProcess находятся в состоянии sleeping и ждут окончания выполнения программного кода, а значит в процессе мониторинга нас не интересуют.
Теперь, когда мы знаем как устроена работа Airflow с task«ами изнутри, нам необходимо понять, действительно ли RawTaskProcess является daemon-процессом и что со всем этим делать…
Загадочный форк
Потратив не один час своей жизни на то, чтобы понять почему модуль multiprocessing определяет интересующий нас процесс как daemon, **я с отчаянием начал листать GitHub проекта Airflow в поисках хотя бы какой-то информации, но эта проблема казалась нерешаемой. Однако, когда надежда начала пропадать и все мысли были о неудаче я наткнулся на обсуждение похожей проблемы, но для задачи многопроцессорной обработки данных.
Оказалось, что проблема решается с использованием специального форка модуля multiprocessing, который был создан разработчиками Celery для устранения подобных проблем. Спасителя звали billiard (https://pypi.org/project/billiard/).
Данный форк используется внутри Celery для организации процессов, о которых мы говорили выше, поэтому проблем с его установкой и настройкой возникнуть не могло, он уже был готов. Оставалось лишь заменить упоминание одного модуля на другой.
После простых манипуляций проблема с определение RawTaskProcess, как daemon-процесс исчезла и оставалось лишь решить, как применить данное решение на все существующие кастомные операторы.
Декор дело тонкое
Для тех, кто хотя бы раз в жизни писал кастомные операторы, в этом разделе я не расскажу ничего нового, но данная информация обязана дополнить весь вышеописанный опыт.
Итак, логика работы кастомного оператора реализуется через наследование базового оператора и настройки методов init и execute.
class CustomOperator(BaseOperator):
def __init__(self,
attr_1: str,
attr_2: str,
**kwargs) -> NoReturn:
super().__init__(**kwargs)
self.attr_1 = attr_1
self.attr_2= attr_2
def execute(self, context):
print('Hello, world!')В данном случае нас интересует метод execute, так как именно его вызов создает RawTaskProcess.
Наиболее очевидным и простым решением представляется использование декоратора, который можно было бы «навесить» на методы execute всех кастомных классов.
Так и сделаем! Используя функцию, описанную для мониторинга процесса напишем несложный декоратор.
def add_task_monitoring(decorated_function: Callable) -> Callable:
"""
Add monitor functionality to the custom operator's execute method.
Args:
decorated_function (Callable): The function to be monitored.
Returns:
wrapper (Callable): The decorated function with monitoring functionality
Raises:
None
"""
@wraps(decorated_function)
def wrapper(*args, **kwargs):
"""Wrap decorated function in order to enhance monitoring capabilities"""
from utils.etl_utils import ConnectionManager
from utils.read_sql import read_sql
from pathlib import Path
# Define main process ID
main_process_id = os.getpid()
print('Main process id: ', main_process_id)
# Define shared memory metrics
consumption_metrics = {
'cpu_threads_cnt': Value('i', 0),
'cpu_times_sec': Value('d', 0.0),
'cpu_utilization_percent': Value('d', 0.0),
'memory_rss_b': Value('i', 0),
'memory_vms_b': Value('i', 0),
'memory_rss_percent': Value('d', 0.0),
'memory_vms_percent': Value('d', 0.0)
}
# Define monitoring process
monitoring_process = Process(
target=monitor_process,
args=(main_process_id, consumption_metrics),
daemon=True
)
print('Monitoring process defined.')
# Define task start as default
task_start_dt = datetime(year=1980, month=1, day=1)
try:
# Start monitoring process
monitoring_process.start()
print('Monitoring process started.')
# Write fact task start dt
task_start_dt = datetime.utcnow()
# Start decorated funtion in main process
result = decorated_function(*args, **kwargs)
return result
finally:
# Write fact task end dt
task_end_dt = datetime.utcnow()
# Terminate monitoring process
monitoring_process.terminate()
print('Sent terminate signal to monitoring process.')
# Wait until the process terminated
monitoring_process.join()
print('Monitoring process terminated.')
# Release terminated process resources
monitoring_process.close()
print('Monitoring process resources released.')
# Calculate task duration in seconds
task_duration_sec = (task_end_dt - task_start_dt).total_seconds()
# Write consumption_metrics to Houston
conn = ConnectionManager.get_pg_client('pg_client')
cur = conn.cursor()
cur.execute(
read_sql(
str(Path(__file__).parent / 'sql' /
'insert_airflow_task_resource_consumption.sql')
),
(
kwargs['context']['dag'].dag_id,
kwargs['context']['ds'],
kwargs['context']['dag'].tags,
kwargs['context']['ti'].task_id,
task_start_dt,
task_end_dt,
task_duration_sec,
consumption_metrics['cpu_threads_cnt'].value,
consumption_metrics['cpu_times_sec'].value,
consumption_metrics['cpu_utilization_percent'].value,
consumption_metrics['memory_rss_b'].value,
consumption_metrics['memory_vms_b'].value,
consumption_metrics['memory_rss_percent'].value,
consumption_metrics['memory_vms_percent'].value
)
)
conn.commit()
print('Monitoring result successfully sent to Houston.')
return wrapperНаш декоратор оборачивает функцию execute кастомного оператора, чтобы запустить daemon-процесс мониторинга, который через shared memory передает пиковые значения потребления в наш основной процесс. По завершению процесса результаты работы task«и записываются в таблицу PostgreSQL.
Таким образом, «навесив» наш декоратор на нужный метод класса получаем универсальный мониторинг потребления ресурсов внутри Airflow.
class CustomOperator(BaseOperator):
def __init__(self,
attr_1: str,
attr_2: str,
**kwargs) -> NoReturn:
super().__init__(**kwargs)
self.attr_1 = attr_1
self.attr_2= attr_2
@add_task_monitoring
def execute(self, context):
print('Hello, world!')Подведем итоги
Информация о потребляемых ресурсах является одной из ключевых для обеспечения стабильности любого сервиса и Apache Airflow не является исключением.
Внедрение данного мониторинга позволило:
подсветить task«и, нуждающиеся в нашем внимании с разной степенью критичности
сохранить показатели потребления CPU и RAM в прежних рамках, несмотря на увеличение количества DAG«ов.
Помимо этого, косвенным результатом, о котором изначально никто не думал, стало углубление знаний по работе с Airflow и внедрение best-practices среди команд аналитики. Действительно, качество написания DAG«ов с каждым месяцем растет, в том числе благодаря обучениям, которые мы проводим для аналитиков, на основании выявленных проблем.
Подумаем о будущем
В наших планах продолжить развивать мониторинг ресурсов Airflow, в том числе с движением в сторону автоматизации, внедрения реактивного мониторинга, формирования ежедневных сводок о работе DAG«ов в копоративный месенджер и многое другое. Впереди огромное полотно для творчества и разработки и мы не собираемся останаливаться на одной статье.
И так как этот проект жив, нам важная ваша обратная связь. Сталкивались ли вы с похожими проблема и как их решали? Пишите комментарии, задавайте вопросы и критикуйте автора. Делиться своими мнениями и кейсами, сделаем сообщество Airflow открытым и развивающимся вместе!
Спасибо за прочтение статьи!
