Семейство тестов хи-квадрат: что у них под капотом и какие выбрать для сравнения воронок
Всем привет, меня зовут Вячеслав Зотов, я аналитик в студии Whalekit. В этом тексте я расскажу про статистические тесты и сравнение воронок, а также мы попробуем разобраться, что объединяет χ²-тесты, какова область их применения и подробно исследуем применимость χ²-тестов к анализу воронок. И все это с примерами на Python.
Тест χ² — очень полезный аналитический инструмент, который тем не менее часто вызывает у аналитиков недопонимание и путаницу. Прежде всего это происходит из-за того, что существует целое семейство тестов χ², имеющих разные области применения. Дополнительную путаницу создает то, что тесты χ² часто рекомендуют применять для анализа продуктовых и маркетинговых воронок, а это обычно приводит к ошибочному использованию тестов.

1. χ²-распределение
Начнем с импорта библиотек:
import warnings
warnings.filterwarnings('ignore')
import os
import math
import random
import re
import pandas as pd
import numpy as np
import scipy.stats as stats
from matplotlib import pyplot as plt
import matplotlib.ticker as mtick
import seaborn as sns
from matplotlib import cm
import matplotlib.colorsРаспределение χ² возникает при возведении в квадрат нормально распределенной случайной величины:
np.random.seed(1234)
size = 10000 # размеры случайных переменных
loc = 0
scale = 1
result = pd.DataFrame([[0] * size], index = ['chi2_1']).T
plt.figure(figsize = (15, 5))
# перебираем значения степеней свободы k
for k in range(2, 22, 3):
# создаем фрейм результатов
current_result = pd.DataFrame([[0] * size], index = [1]).T
# генерируем нужное количество нормально распределенных переменных, находим сумму их квадратов
for i in range(1, k + 1): current_result[i] = pd.Series(np.random.normal(loc = loc, scale = scale, size = size))
# находим сумму квадратов
current_result['chi2'] = (current_result * current_result).sum(axis = 1)
sns.kdeplot(current_result['chi2'], label = 'k = {}'.format(k))
plt.legend(title = 'Степени свободы'), plt.ylabel('$f_k(x)$'), plt.xlabel('$x$'), plt.title('Распределения $\chi_k^2$')
plt.show()
2. χ²-тесты
Существует три χ²-теста.
Тест на гомогенность (test of homogeneity, он же goodness of fit) — непараметрический, одновыборочный тест, который проверяет соответствие наблюдаемого распределения категориальной случайной величины некоторому эталонному распределению. В Python реализован функцией
scipy.stats.chisquare.Тест на независимость (он же test of independence/association) — непараметрический, одновыборочный тест, который проверяет наличие связи между двумя категориальными переменными. В Python реализован функцией
scipy.stats.chi2_contingency.Тест для дисперсии — параметрический (параметр — дисперсия), одновыборочный тест, который проверяет равенство дисперсии непрерывной случайной величины заданному порогу. В Python для него нет готовой функции.
Первые два теста используют критерий согласия Пирсона (КСП), который имеет распределение χ². Третий тест никак не относится к первым двум за исключением того, что статистика, которую он использует, также имеет распределение χ² (об этом ниже).
Критерий согласия Пирсона рассчитывается по формуле:

Здесь:
Таким образом, КСП — это разница между наблюдаемым и ожидаемым значением, возведенная в квадрат (нам важно не направление отличий, а только факт их наличия) и нормированная с помощью деления на ожидаемое значение (чтобы слишком быстро не росла).
Если мы сравниваем набор наблюдаемых значений с набором эталонов, то формула КСП приобретает вид:

В том случае, когда O и E имеют нормальное распределение, КСП имеет распределение χ².
Получается, что мы можем провести статистический тест с гипотезами:
H0: между наблюдаемым распределение и эталонным распределением нет различий;
H1: между наблюдаемым распределение и эталонным распределением есть различия.
Если различий нет, то КСП будет стремиться к нулю. В противном случае она окажется за пределами интервала наиболее вероятных значений:
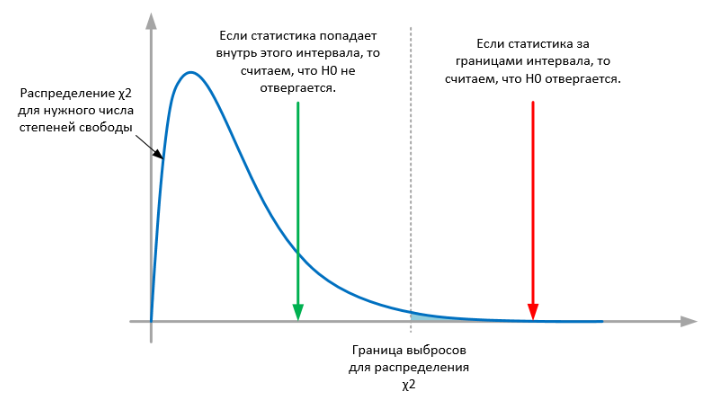
Тесты с КСП, таким образом, непараметрические (поскольку не оценивают никакие из параметров распределений) и односторонние (так как статистика всегда положительная за счет возведения в квадрат — вот некоторые рассуждения на этот счет). Поскольку тест непараметрический, мы можем напрямую сравнивать полученную статистику с эталонным распределением (без применения несмещенных оценок как в z— и t-тестах).
Остался маленький нюанс — O и E должны иметь нормальное распределение. При работе с категориальными переменными это достигается за счет нормальной аппроксимации биномиального распределения (вот обсуждение по теме).
2.1 χ²-тест на гомогенность (homogeneity, goodness of fit)
Предположим, что у нас есть таблица реально наблюдаемых вероятностей появления наблюдений в группах (Observed) и ожидаемых вероятностей появления (Expected):
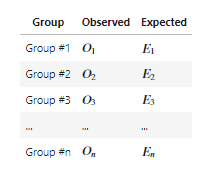
Тогда гипотезы для теста goodness of fit можно представить таким образом:
H0: O₁ = O₂ = O₃ = … = Oₙ (то есть наблюдение может относиться с равной вероятностью к каждой из групп);
H1: Хотя бы одна из вероятностей Oᵢ не равна остальным.
или таким:
H0: O₁ = E₁, O₂ = E₂, O₃ = E₃, …, Oₙ = Eₙ (то есть вероятности соответствуют ожидаемому распределению);
H1: хотя бы в одном случае Oᵢ не равна Eᵢ (то есть вероятности не соответствуют ожидаемому распределению).
Пример расчета статистики (источник):
Для полученную статистики можно рассчитать p-value для распределения χ² при числе степеней свободы d = (n-1) = 4:
1 - stats.chi2.cdf(52.75, 4)9.612521889579284e-11
Сравнив его с уровнем значимости α = 0.05, можно сделать вывод о том, что нулевая гипотеза отвергается и конфеты распределены по вкусам неравномерно.
Еще примеры расчета: один и второй.
Напишем функцию для проведения теста:
def diy_chisquare(observed, expected):
# рассчитываем статистику
k = len(observed) # число степеней свободы
statistic = (((observed - expected)**2)/expected).sum() # КСП
# рассчитываем p-value
p_value = 1 - stats.chi2.cdf(statistic, k - 1) # вероятность получить значение выше или равное статистике
return k - 1, statistic, p_valueСравним ее результат со встроенным методом, используя предыдущий пример:
# задаем исходные данные
np.random.seed(1234)
data = np.array([180, 250, 120, 225, 225])
expected = np.array([200, 200, 200, 200, 200])
# результат самодельного теста
display(diy_chisquare(data, expected))
# результат встроенного теста
from scipy.stats import chisquare
chisquare(data, expected)(4, 52.75, 9.612521889579284e-11)
Power_divergenceResult(statistic=52.75, pvalue=9.612518035368181e-11)
Результаты полностью совпадают.
Интереса ради исследуем вопрос о том, как размер выборки влияет на то, будет ли распределение КСП соответствовать распределению χ². Зададим функцию проведения эксперимента:
def generate_max_likelihood_distro(size, num_samples, sample_size, k_range, ax, ax2, ax3, title):
ks_results = []
for line_i, k in enumerate(k_range): # перебираем степени свободы (количество классов, на которые разбиваются наблюдения)
data = pd.Series(np.random.choice(k, size, p = [1 / k] * k)) # не генерируем равномерно распределенный массив групп наблюдений
max_likelihood = []
for i in range(num_samples):
observed = data.sample(sample_size, replace = True).value_counts() # считаем, сколько раз появилось каждое из значений
expected = sample_size/k # ожидаемое число значений
max_likelihood += [[i,
k - 1,
(((observed - expected)**2)/expected).sum() # максимальное правдоподобие
]]
max_likelihood = pd.DataFrame(max_likelihood, columns = ['Sample #', 'Degrees of freedom', 'Max likelyhood distribution'])
# строим графики распределений
sns.kdeplot(max_likelihood['Max likelyhood distribution'], label = 'k = {}'.format(k), ax = ax)
ax.legend(title = 'Степени свободы'), ax.set_ylabel('$f_k(x)$'), ax.set_xlabel('$x$'), ax.set_title(title)
# строим qq-графики
stats.probplot(max_likelihood['Max likelyhood distribution'],
dist = stats.chi2, sparams = (k - 1), # chi2 с числом степеней свободы k-1
plot = ax2, fit = False)
line_index = (line_i + 1) * 2
(ax2.get_lines()[line_index - 2].set_color(ax.get_lines()[line_i].get_color()),
ax2.get_lines()[line_index - 2].set_label('k = {}'.format(k)),
ax2.get_lines()[line_index - 2].set_markersize(3),
ax2.get_lines()[line_index - 2].set_alpha(0.5)
)
ax2.get_lines()[line_index - 1].set_color('lightgrey'), ax2.get_lines()[line_index - 1].set_linestyle(':')
ax2.set_title('Соответствие распределению $\chi^2$'), ax2.legend(title = 'Степени свободы')
# проводим КС-тест
ks_stat, ks_p = stats.kstest(max_likelihood['Max likelyhood distribution'], 'chi2', args = (k - 1, ))
ks_results.append([k, ks_stat, ks_p])
ks_results = pd.DataFrame(ks_results, columns = ['k', 'statistic', 'p']).set_index('k')
ks_results[['p']].plot(ax = ax3, xticks = ks_results.index, label = '$p$-value')
ax3.axhline(0.05 / len(k_range), color = 'red', linestyle = ':', label = 'alpha = {:.2f}'.format(0.05 / len(k_range))) # с коррекцией Бонферрони
ax3.set_ylabel('$p$-value'), ax3.set_xlabel('$k$ (степени свободы)'), ax3.set_title('Результаты КС-теста'), ax3.legend()Исследуем влияние размера выборки на соответствие статистики распределению χ²:
np.random.seed(12345)
size = 100000 # размер «генеральной совокупности» — исходной большой выборки
num_samples = 1000
sample_size = 100
plt.figure(figsize = (25, 12))
sample_sizes = [10, 50, 100, 500, 1000, 2000]
for i, sample_size in enumerate(sample_sizes):
generate_max_likelihood_distro(size, num_samples, sample_size,
range(2, 22, 3),
title = 'Размер выборки $n = {}$'.format(sample_size),
ax = plt.subplot(3, len(sample_sizes), i + 1),
ax2 = plt.subplot(3, len(sample_sizes), len(sample_sizes) + i + 1),
ax3 = plt.subplot(3, len(sample_sizes), len(sample_sizes) * 2 + i + 1),
)
plt.tight_layout()
Наблюдения и выводы:
при увеличении размера выборки результат становится менее шумным;
сами распределения весьма похожи на χ²;
QQ-plot показывает, что распределение статистики становится близко к χ² даже для малых k, когда размер выборки превышает 100 наблюдений;
тест Колмогорова-Смирнова также показывает, что с ростом размера выборок статистика уверенно приближается к χ².
Мы показали эмпирически, что КСП действительно имеет распределение χ².
2.2 χ²-тест на независимость
Тест χ²-тест на независимость (test of independence/association) отличается от предыдущего теста постановкой гипотез:
Допустим, у нас есть таблица сопряженности (из примера). Таблица сопряженности описывает наблюдаемые (observed) результаты:
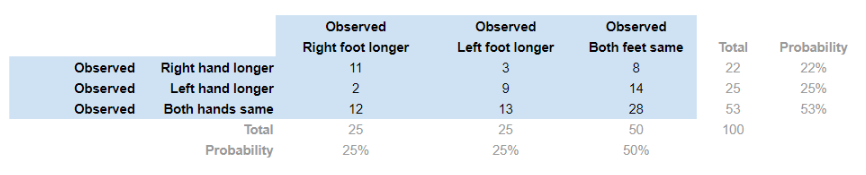
Согласно теореме умножения вероятностей, в том случае, когда две случайные величины A и B независимы, вероятность получить совместное событие равна P (AB) = P (A) ⋅ P (B). Таким образом, наши ожидаемые (expected) величины можно рассчитать по формуле умножения вероятностей и свести в таблицу:
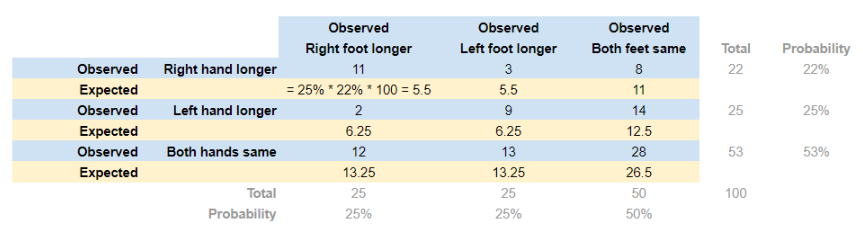
Используя эту таблицу, мы можем рассчитать статистику по формуле:


Готовую статистику можно подставить в CDF для распределения χ² и получить p-value.
Напишем функцию для расчетов:
def diy_chi2_contingency(contingency_table):
# общее число наблюдений
total = contingency_table.sum().sum()
# суммы по строкам и столбцам
col_probs = contingency_table.sum(axis = 0).values
row_probs = contingency_table.sum(axis = 1).values
# превращаем их в вероятности
col_probs = col_probs / total
row_probs = row_probs / total
# рассчитываем ожидаемые значения
expected = np.array([col_probs]).T @ np.array([row_probs]) # перемножаем вектор-столбец вероятностей в рядах на вектор-стороку вероятностей в столбцах
expected = expected.T
expected = expected * total
# рассчитываем статистику
statistic = ((contingency_table.values - expected)**2)/expected
statistic = statistic.sum()
# определяем число степеней свободы
dof = (contingency_table.shape[0] - 1) * (contingency_table.shape[1] - 1)
# рассчитываем p-value
p_value = 1 - stats.chi2.cdf(statistic, dof) # вероятность получить значение выше или равное критерию МП
return dof, statistic, p_value
contingency_table = pd.DataFrame([[11, 3, 8], [2, 9, 14], [12, 13, 28]])
diy_chi2_contingency(contingency_table)(4, 11.942092624356777, 0.01778711460986071)
Сравним результат со встроенной функцией:
from scipy.stats import chi2_contingency
chi2_contingency(contingency_table)[0:3](11.942092624356777, 0.0177871146098607, 4)
Результаты полностью идентичны.
2.3 χ²-тест для дисперсии
Третий вид χ²-теста не имеет никакой связи с предыдущими за исключением того, что его статистика

также имеет распределение:

Вот доказательство. Здесь S — это наблюдаемое выборочное СКО, а σ — ожидаемое СКО.
Пример расчета статистики тут.
В Python нет встроенной функции, но можно ее написать: пример.
Тест χ² для дисперсии не используется для сравнения выборок. Для этого служит F-тест (очень чувствителен к требованию нормальности данных), а для ненормальных данных — тесты Левена или Бартлетта (оба есть в Python).
Нас, как практиков, конечно же, прежде всего интересует вопрос — можно ли использовать этот тест для ненормально распределенных данных (потому что на практике мы практически никогда не работаем с нормальными распределениями).
Для этого сравним распределение статистики для нормально распределенных и экспоненциально распределенных данных. Кроме того, оценим влияние размера выборки на результат:
np.random.seed(1234)
size = 100000 # размер «генеральной совокупности» — исходной большой выборки
num_samples = 1000
sample_size = 1000
std_threshold = 1.1
data_norm = pd.Series(np.random.normal(0, std_threshold, size))
data_exp = pd.Series(np.random.exponential(std_threshold, size))
plt.figure(figsize = (25, 5))
sample_sizes = [10, 30, 50, 100, 500, 1000]
for i, sample_size in enumerate(sample_sizes):
statistics = []
for j in range(num_samples):
statistics += [[j,
(sample_size - 1) * data_norm.sample(sample_size, replace = True).var() / (std_threshold ** 2), # статистика для нормально распределенных данных
(sample_size - 1) * data_exp.sample(sample_size, replace = True).var() / (std_threshold ** 2) # статистика для жкспоненциально распределенных данных
]]
statistics = pd.DataFrame(statistics, columns = ['Sample #', 'Statistic (normal data)', 'Statistic (exponential data)'])
# строим графики распределений
ax = plt.subplot(1, len(sample_sizes), i + 1)
sns.kdeplot(statistics['Statistic (normal data)'], label = 'Нормально распределенные данные', color = 'orange', linestyle = ':', ax = ax)
sns.kdeplot(statistics['Statistic (exponential data)'], label = 'Экспоненциально распределенные данные', color = 'orange', ax = ax)
sns.kdeplot(pd.Series(np.random.chisquare(sample_size - 1, size)), color = 'blue', label = 'Эталонное распределение $\chi^2$', ax = ax)
plt.title('Размер выборки: {}'.format(sample_size)), plt.xlabel('Статистика'), plt.ylabel('Частота')
if i == 0: plt.legend()
plt.tight_layout()
Наблюдения:

распределение статистики для экспоненциально распределенных данных отличается от эталонного распределения. Более того, различие, похоже, растет с ростом размера выборки.
Вывод: промысловой ценности не имеет.
3. Связь между z-тестом и χ²-тестом (и тестом Фишера)
Довольно часто встречаются попытки использовать χ²-тест вместо z-теста для пропорций. Также можно встретить утверждения о том, что z-тест эквивалентен χ²-тесту для ситуации с двумя классами. Имеется в виду эквивалентность результатов между:
двухвыборочным z-тестом для пропорций;
тестом χ² на независимость данных (test of independence) в ситуации, когда таблица сопряженности имеет размерность 2×2.
Пример: допустим, у нас есть результаты бинарного эксперимента:
np.random.seed(1234)
size = 1000
p = 0.4
data = pd.Series(np.random.choice(2, size, p = [1 - p, p]))Эти результаты можно представить в виде таблицы сопряженности, если добавить к ним ожидаемые значения:
contingency_table = pd.DataFrame([data.value_counts().values, [500, 500]], index = ['Observed', 'Expected'])
contingency_table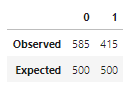
Результат χ²-теста на независимость:
from scipy.stats import chi2_contingency
chi2_statistic, p_value, dof, exp = chi2_contingency(contingency_table, correction = False) # отключаем коррекцию (с ней результат чуть-чуть отличается)
chi2_statistic, p_value(14.555161038503186, 0.00013611529553341273)
Результат двухвыборочного z-теста для пропорций:
from statsmodels.stats.proportion import proportions_ztest
z_statistic, p_value = proportions_ztest(contingency_table[0], contingency_table.sum(axis = 1), alternative = 'two-sided')
z_statistic, p_value(3.815122676730484, 0.00013611529553341327)
p-value полностью совпадают. Более того, z-статистика равна квадратному корню из χ²-статистики:
z_statistic, math.sqrt(chi2_statistic)(3.815122676730484, 3.8151226767304856)
Демонстрация математической эквивалентности: тут и тут.
Нужно отметить, что тест на гомогенность не эквивалентен z-тесту:
from scipy.stats import chisquare
chi2_statistic, p_value = chisquare(contingency_table.loc['Observed'], f_exp = contingency_table.loc['Expected']) # тестируем наблюдаемые величины на равновероятность
chi2_statistic, p_value(28.9, 7.62129129638297e-08)
Тест Фишера часто рекомендуют применять вместо χ²-теста для таблиц сопряженности размером 2×2 в тех случаях, когда частоты очень малы (ячейки таблицы сопряженности имеют значения <= 5). Если тест Фишера до какой-то степени эквивалентен χ²-тесту, то он должен быть эквивалентен и z-тесту для пропорций. Действительно, p-value довольно похожи:
from scipy.stats import fisher_exact
fisher_exact(contingency_table, alternative = 'two-sided')(1.4096385542168675, 0.00016169735747221216)
4. Размер выборки для χ²-теста
Утверждается, что размер выборки должен быть такой, чтобы:
каждая из ячеек таблицы сопряженности была больше 5 (если нет, то это легко исправляется умножением таблицы на нужный множитель);
общий размер сэмпла был не более 500, так как увеличение размера сэмпла вызывает рост статистики и вероятности ложноположительных результатов.
Проверим это на практическом примере.
Возьмем таблицу сопряженности, при которой тест подтверждает нулевую гипотезу (это слегка модифицированная таблица ожидаемых значений из одного из предыдущих примеров) и будем последовательно увеличивать размер выборки:
# тестовые данные
test_table = pd.DataFrame([[6, 5.5, 11], [6.25, 7, 12.5], [13.25, 13.25, 26.5]])
# последовательно увеличиваем количество наблюдений
result = []
for mult in range(1, 100, 1):
current = test_table * mult
statistic_ind, p_ind, _, _ = chi2_contingency(current) # тест по увеличиваемой таблице
result += [[current.sum().sum(), p_ind, statistic_ind]]
result = pd.DataFrame(result, columns = ['sample_size', 'p-value', 'statistic']).set_index('sample_size')
# график p-value
ax = result['p-value'].plot(figsize = (10, 5), color = 'red', grid = True)
plt.ylabel('p-value'), plt.xlabel('Размер выборки')
# график статистики
ax2 = ax.twinx()
result['statistic'].plot(ax = ax2, color = 'blue', label = 'Статистика')
# собираем легенду
lines, labels = ax.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines + lines2, labels + labels2, loc = 1, title = 'Параметры')
plt.ylabel('Статистика'), plt.title('Влияние размера выборки на результаты теста $\chi^2$');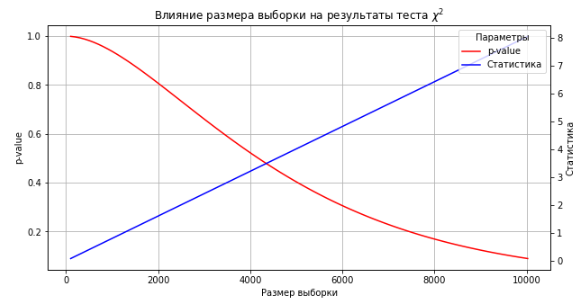
Видно, что с ростом размера выборки статистика растет линейно, при этом p-value стремится к 0 и рано или поздно тест покажет статистически значимые отличия при исходных пропорциях.
Таким образом, размер выборки желательно брать достаточно малый (видимо, 500 — хорошая практическая граница).
5. Применение χ²-тестов для анализа множественных пропорций
Довольно часто встречаются утверждения, что χ²-тест можно применять для сравнения множественных пропорций. Например, при сравнении нескольких воронок (скажем, в процессе A/B-тестирования) предлагается вместо серии последовательных z-тестов для пропорций применять тест χ². В этом разделе мы посмотрим, какие из χ²-тестов применимы для задачи анализа воронок.
Сразу можно сказать, что для анализа воронок неприменим тест χ² для дисперсии.
Чтобы разобраться с оставшимися двумя видами тестов χ², представим, что нам нужно проанализировать результаты А/B теста, в котором тестировались два вида воронок — воронка контрольной группы (A) и воронка тестовой группы (B).
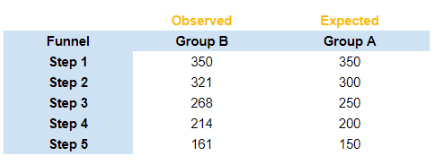
Теоретически, χ²-тест на гомогенность можно применить, если рассматривать воронку контрольной группы как набор ожидаемых значений (expected), а воронку тестовой группы — как набор наблюдаемых значений (observed). Тогда тест покажет наличие статистически значимого отличия между observed и expected.
Аналогично χ²-тест на независимость можно применять для анализа любого числа воронок, если рассматривать все эти воронки как таблицу сопряженности. В этом случае тест покажет, зависит ли переменная «шаги воронки» от переменной «группа теста» или нет.

Но, кажется, здесь возникает нюанс. Дело в том, что логика обоих видов χ²-теста предполагает, что на их вход подаются таблицы сопряженности. Таблицу сопряженности, прежде всего, характеризует то, что в ней каждый объект наблюдений может попадать в одну единственную категорию. Это условия, очевидно, не выполняется для таблиц воронок, так как каждый объект наблюдений (в случае с воронками — это пользователь) может выполнить несколько шагов воронки и оказаться сразу в нескольких категориях.
Чтобы превратить таблицу воронок в таблицу сопряженности, нужно провести простую трансформацию — посчитать, сколько пользователей ушло из воронки на каждом из шагов. Таким образом, для каждого пользователя в таблице остается одно единственное наблюдение. Например, таблица сопряженности для таблицы из двух воронок из примера выше будет иметь вид:
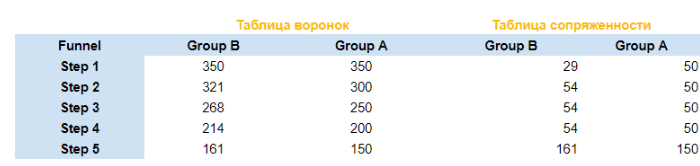
В этом примере мы полагаем, что пользователь не может перепрыгивать через шаги воронок, поэтому число отвалившихся пользователей для каждого шага равно разности уникальных пользователей на двух соседних шагах.
Есть ли какое-либо отличие в результатах, получаемых при подстановке в χ²-тесты таблиц воронок и таблиц сопряженности? Действительно, довольно легко подобрать пример, для которого тест, проведенный на данных таблицы сопряженности, даст правильный результат, а тест проведенный на таблице воронок — неправильный. К примеру, возьмем воронки из примера выше.

У них есть явные отличия, но χ²-тест для гомогенности, выполненный на таблице воронок показывает отсутствие отличий, а тот же тест, выполненный по таблице сопряженности, показывает, что отличия есть:

Казалось бы, все просто — трансформируем таблицы воронок в таблицы сопряженности, подаем их в χ²-тесты и получаем правильный результат. Но где гарантия, что получившийся выше результат не случаен, и в особенности, что результаты тестов никак не зависят от формы воронок. Давайте это проверим.
5.1 Зависимость результатов χ²-тестов от формы воронок
Сначала протестируем, как от формы воронок зависит вероятность ошибки первого рода (вероятность обнаружить отличия там, где их нет). Для этого проведем серию экспериментов:
создадим набор воронок, состоящих из трех шагов. Каждая воронка будет описываться парой чисел — вероятностью конвертироваться из первого во второй шаг и вероятностью конверсии из второго шага в третий. То есть воронка 100 → 50 → 25 будет описываться парой чисел [0.5, 0.5];
для каждой из созданных воронок построим N пар выборок;
для каждой из пар выборок проведем 5 тестов:
χ²-тест на гомогенность по таблице воронок;
χ²-тест на гомогенность по таблице сопряженности;
χ²-тест на независимость по таблице воронок;
χ²-тест на независимость по таблице сопряженности;
z-тест, сравнивающий доли пользователей, достигших последнего шага воронок.
Начнем с функции построения воронок:
# строим воронки, из которых будем делать сэмплирование
# pop_size — количество пользователей, которые участвуют в каждой воронке
# coeffs — массив процентных значений отличий воронок для тестирования ошибок второго рода
# rel — параметр, управляющий тем, какая воронка будет получена — абсолютная (доля рассчитывается от первого шага воронки) или относительная (доля рассчитывается от предыдущего шага)
def generate_funnel_log(pop_size, coeffs, rel = False, random_state = 12345):
# задаем начальный шаг
result = pd.DataFrame([[0, 1]] * pop_size, columns = ['step', 'user_id'])
result['user_id'] = result['user_id'].apply(lambda x: ''.join(random.choice('abcdefghij1234567890') for i in range(10)))
# на каждом шаге берем только нужный процент пользователей, достигших прошлого шага
for step, step_coeff in enumerate(coeffs):
current = result.query('step == @step')
# если относительная воронка, то число уников на этом шаге считаем как % от предыдущего, если абсолютная, то от всей популяции
current_pop = pop_size
if rel: current_pop = current['user_id'].nunique()
current = current.sample(int(np.ceil(current_pop * step_coeff)), random_state = random_state)
current['step'] = step + 1
result = result.append(current)
return resultС помощью этой функции сконструируем воронки разной формы:
# конструируем разные формы воронок
# steps — на сколько шагов будут разбиты относительные шаги воронок
# pop_size — количество пользователей, которые участвуют в каждой воронке
# differences — массив процентных значений отличий воронок для тестирования ошибок второго рода
# file_name — файл, в который будут записаны результаты генерации лога (при определенных условиях его генерация может занимать существенное время)
def generate_funnel_set(steps, pop_size, differences = [], file_name = None):
result = pd.DataFrame()
funnel_num = 0
# проверяем ранее сгенерированный файл лога воронки
if file_name is not None:
try:
return pd.read_csv(file_name)
except:
print(f'{file_name} не существует.')
# добавляем 1 к списку различий, чтобы сгенерировать исходную воронку
differences = [1] + differences
for first_step_prob in np.linspace(0, 1, num = steps):
for second_step_prob in np.linspace(0, 1, num = steps):
# отсекаем ситуации, когда воронка плоская
if first_step_prob == 0 or second_step_prob == 0: continue
funnel_coeffs = [first_step_prob, second_step_prob]
# генерируем набор воронок, имеющих отличия от исходной воронки
# здесь же генерируется и она сама с diff = 1
for i, diff in enumerate(differences):
current_funnel = generate_funnel_log(pop_size, [x * diff for x in funnel_coeffs], rel = True)
# номер воронки для быстрого к ней обращения
current_funnel['funnel_num'] = funnel_num
current_funnel['funnel_diff_num'] = i
# параметры воронки
current_funnel['first_step_prob'] = first_step_prob
current_funnel['second_step_prob'] = second_step_prob
current_funnel['diff'] = diff
result = result.append(current_funnel)
funnel_num += 1
# сохраняем воронку в файл
if file_name is not None:
result.to_csv(file_name)
return result
# набор воронок
log = generate_funnel_set(steps = 25, pop_size = 10000, differences = [], file_name = 'sample_log.csv')
display(log.query('funnel_num == 10')[['first_step_prob', 'second_step_prob']].drop_duplicates())
report = log.query('funnel_num == 10').groupby('step').agg({'user_id': 'nunique'})
report['perc'] = report['user_id'] / report.loc[0, 'user_id']
display(report)
Построим некоторые из полученных воронок и посмотрим, на какие классы мы можем их разделить:
# выбираем 5 произвольных воронок
sample_funnels = log['funnel_num'].drop_duplicates().sample(5, random_state = 1234567)
# строим их
report = log.query('funnel_num in @sample_funnels')
report['funnel_name'] = report.apply(lambda x: f"№{x['funnel_num']}. Отн. конверсия {x['first_step_prob']:.2%} -> {x['second_step_prob']:.2%}", axis = 1)
report = report.pivot_table(index = 'step', columns = 'funnel_name', values = 'user_id', aggfunc = 'nunique')
report = report.div(report.loc[0], axis = 1)
# выводим графики
ax = report.plot(figsize = (15, 7), grid = True)
ax.yaxis.set_major_formatter(mtick.PercentFormatter(1))
ax.set_xticks(report.index)
plt.xlabel('Шаг воронки'), plt.ylabel('Абсолютная вероятность конверсии'), plt.legend(title = 'Воронки')
plt.title('Различные классы воронок');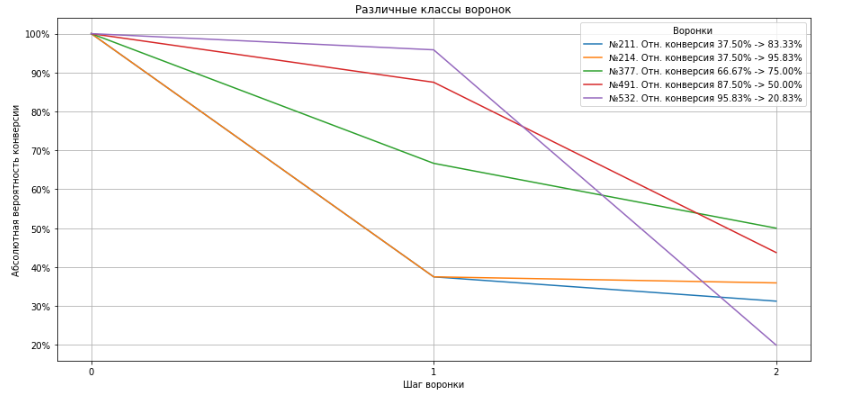
Видно, что воронки, в сущности, делятся на три класса:
воронки с немедленным падением — те, у которых на первом шаге наблюдается падение на более, чем 50% от нулевого. В этом случае конверсия во второй шаг не важна. На графике к этой категории относятся воронки №211 и №214;
воронки с умеренным угасанием — те, у которых падение на первом шаге составляет не более 50% от нулевого, а на втором шаге — не более, чем 50% от первого. Например, этим критериям соответствует воронка №377;
воронки с быстрым угасанием на втором шаге. На картинке выше это воронки №491 и №532.
Если мы построим график, у которого по оси X отложена вероятность конверсии из шага 0 в шаг 1, а по оси Y — вероятность конверсии из шага 1 в шаг 2, то воронки расположатся на нем вот так:
report = log.query('funnel_num in @sample_funnels')
plot_data = report[['funnel_num', 'first_step_prob', 'second_step_prob']].drop_duplicates()
x, y, t = plot_data['first_step_prob'].values, plot_data['second_step_prob'].values, plot_data['funnel_num'].values
ax = plt.axes()
plt.scatter(x, y)
plt.xlim((0, 1)), plt.ylim((0, 1))
# границы типов воронок
ax.axvline(0.5, linestyle = '-.', color = 'red')
ax.hlines(y = 0.5, xmin = 0.5, xmax = 1, linestyle = '-.', color = 'red')
ax.text(0.07, 0.9, 'Быстрое', fontsize = 15, color = 'red')
ax.text(0.55, 0.9, 'Умеренное', fontsize = 15, color = 'red')
ax.text(0.55, 0.3, 'Быстрое\n2-й шаг', fontsize = 15, color = 'red');
for i, txt in enumerate(t):
ax.annotate(txt, (x[i] + 0.03, y[i]))
plt.xlabel('Вероятность конверсии в первый шаг'), plt.ylabel('Вероятность конверсии во второй шаг');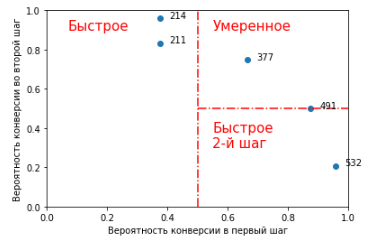
Если мы проведем для каждой воронки серию тестов, то мы сможем построить график вероятности, на котором будет показан шанс допустить ошибку первого рода. Он будет выглядеть примерно так:

Здесь зеленым цветом обозначены области с умеренной вероятностью допустить ошибку, а оттенки красного показывают области с высокими вероятностями ошибок.
Подготовим набор воронок, которые будут использоваться при тестировании:
# генерирует набор воронок, в котором будут не только исходные воронки, но и отличающиеся от них на 75%, 50% и 25%
funnel_log = generate_funnel_set(steps = 25, pop_size = 2000, differences = [0.9, 0.8, 0.7], file_name = 'funnel_log.csv')
display(funnel_log.query('funnel_num == 10')[['diff', 'first_step_prob', 'second_step_prob']].drop_duplicates())
Зададим функции для проведения экспериментов:
run_experimentполучает на вход данные воронок, получает из них выборки нужного размера, формирует таблицы воронок и сопряженности, а также проводит по ним статистические тесты;run_error_experimentsперебирает наборы воронок для тестирования и для каждого набора вызывает функциюrun_experiment. Помимо этого,run_error_experimentsотображает графики результатов.
# для каждого сочетания воронок проводим серию экспериментов
# funnel_log — лог с данными воронок
# sample_size — размер выборок, формируемых в каждом из экспериментов
# number_of_experiments — число экспериментов для каждой из воронок
# alpha — уровень значимости
# test_func — функция, описывающая набор статистических тестов, которые проводятся в каждом из экспериментов
# result_column_names — словарь человеко-читаемых названий колонок с результатами экспериментов
# compare_func — функция, служащая для сравнения p-value в каждом из экспериментов с уровнем значимости
def run_experiment(funnel_log, sample_size, number_of_experiments, alpha, test_func, compare_func):
result = []
errors = 0
# проводим эксперименты
for i in range(number_of_experiments):
# составляем выборки из всех групп
funnel = pd.DataFrame()
for j, group in enumerate(funnel_log['group'].unique()):
test_users = funnel_log.query('group == @group')['user_id'].drop_duplicates().sample(sample_size, random_state = i + j)
current_funnel = funnel_log.query('group == @group and user_id in @test_users')
funnel = funnel.append(current_funnel)
# формируем таблицу воронок
funnel = funnel.pivot_table(index = 'step', columns = 'group', values = 'user_id', aggfunc = 'nunique').fillna(0)
# игнорируются ситуации, когда из-за малого размера выборки воронка состоит только из первого шага
if funnel.shape[0] == 1:
errors += 1
continue
# формируем таблицу сопряженности
for col in funnel.columns:
funnel[f'cont_{col}'] = funnel[col] - funnel[col].shift(-1)
# заполняем пропуски в последнем ряду оставшимися пользователями
funnel_cols = [x for x in funnel.columns if 'cont' not in str(x)]
cont_cols = [x for x in funnel.columns if 'cont' in str(x)]
funnel.loc[funnel.index.max(), cont_cols] = funnel.loc[funnel.index.max(), funnel_cols].values
# если в таблице сопряженности попадаются нули, то пропускаем такие ситуации
if (funnel[cont_cols] == 0).max().max():
errors += 1
continue
# проводим тесты
result += [test_func(funnel)]
result = pd.DataFrame(result)
result = result.apply(compare_func, args = [alpha], axis = 1)
return list(result.mean().values), errors
# funnel_log — лог с данными воронок
# diffs — набор воронок, которые сравниваются с эталонной. Например, если diff = [0.7], то c эталонной воронкой будет сравниваться воронка, имеющая 30% отличие от эталонной
# sample_size — размер выборок, формируемых в каждом из экспериментов
# number_of_experiments — число экспериментов для каждой из воронок
# alpha — уровень значимости
# test_func — функция, описывающая набор статистических тестов, которые проводятся в каждом из экспериментов
# result_column_names — словарь человеко-читаемых названий колонок с результатами экспериментов
# compare_func — функция, служащая для сравнения p-value в каждом из экспериментов с уровнем значимости
# levels — линии уровня на карте ошибок
# color_map — цвета для отображения уровней ошибок
# filename_template — шаблон имени файлов, в которые будут записаны результаты экспериментов
def run_error_experiments(funnel_log, diffs, sample_size, number_of_experiments, alpha, test_func, result_column_names, compare_func, levels, color_map, suptitle, filename_template):
# проверяем наличие более ранних расчетов
existing_result_files = [f for f in os.listdir('.') if re.match(filename_template, f)]
if len(existing_result_files) > 0:
# если результаты более ранних расчетов найдены, то просто читаем их
result = pd.read_csv(filename_template + '_result.csv')
errors = pd.read_csv(filename_template + '_errors.csv')
else:
# если нет — считаем все заново
result = []
errors = []
for funnel_num in funnel_log['funnel_num'].unique():
# A-воронка
current_funnel_log = funnel_log.query('funnel_num == @funnel_num and diff == 1')
current_funnel_log['group'] = 0
# последовательно формируем B-воронки с разной степенью отличия от исходной
for i, diff in enumerate(diffs):
current_funnel_log_another = funnel_log.query('funnel_num == @funnel_num and diff == @diff')
current_funnel_log_another['group'] = i + 1
current_funnel_log = current_funnel_log.append(current_funnel_log_another)
# для каждой пары проводим эксперимент
current_exp_results, current_exp_errors = run_experiment(current_funnel_log,
sample_size = sample_size,
number_of_experiments = number_of_experiments,
alpha = alpha,
test_func = test_func,
compare_func = compare_func
)
# собираем результаты в единый массив
result += [[funnel_num, current_funnel_log['first_step_prob'].max(), current_funnel_log['second_step_prob'].max()] + current_exp_results]
errors += [[funnel_num, current_funnel_log['first_step_prob'].max(), current_funnel_log['second_step_prob'].max(), current_exp_errors]]
result = pd.DataFrame(result, columns = ['funnel_num', 'first_step_prob', 'second_step_prob'] + list(result_column_names.keys()))
errors = pd.DataFrame(errors, columns = ['funnel_num', 'first_step_prob', 'second_step_prob', 'errors'])
# сохраняем результаты расчетов в файлы
result.to_csv(filename_template + '_result.csv', index = False)
errors.to_csv(filename_template + '_errors.csv', index = False)
# визуализация
plt.figure(figsize = (30, 7))
def show_contour(data, x_col, y_col, z_col, levels, ax, title):
z = data.pivot_table(index = y_col, columns = x_col, values = z_col, aggfunc = 'max')
x, y = z.columns, z.index.values
# закраска областей
ax.contourf(x, y, z, le
