Семантическая сегментация на основе архитектуры U-Net и определение расстояния между объектами

Всем привет!
Возвращаясь к бытовому применению нейронных сетей, изначально была идея усовершенствовать модель детекции свободного парковочного места из предыдущей моей статьи (Определение свободного парковочного места с помощью Computer Vision), сделать возможность сегментации дороги, тротуара и исключать из парковочных мест, автомобили, которые стоят на газоне (было несколько гневных комментариев на этот счёт).
Однако в процессе размышлений, я решил сделать отдельную модель сематической сегментации, причем написать вручную нейросеть и обучить на своих данных. Суть модели заключается в следующем:
Модель на базе U-Net архитектуры сегментирует различные объекты (кот, стул, стол, тарелка с котлетами итд) и при сближении двух объектов сегментации (кот — тарелка) модель сигнализирует об этом с помощью телеграмм бота.
Отлично, задача поставлена, теперь реализация!
#Библиотеки
import os
import glob
import cv2
import pandas as pd
import numpy as np
import requests
import tensorflow as tf
from skimage import measure
from skimage.io import imread, imsave, imshow
from skimage.transform import resize
from skimage.morphology import dilation, disk
from skimage.draw import polygon, polygon_perimeter
from livelossplot.tf_keras import PlotLossesCallbackПервое, что мне нужно для обучения модели с нуля — это размеченная база данных. Я сделал более 40 постановочных фотографий и разметил их с помощью сервиса Supervisely.

Это не единственный сервис для разметки изображений (есть например, очень интересный CVAT). Триальной версии Supervisely как раз хватает, чтобы разметить в один день порядка 50 фотографий на 6–8 классов. Сервис очень удобный, есть множество различных инструментов для качественной разметки.
Спустя час увлекательной (не очень) работы над разметкой, вот что у меня получилось:

Размеченное изображение (7 классов + 1 фон)
Старался как мог, не судите строго :)
Итак, база данных готова, сформируем наш датасет и поделим на train и test (классика). В общем итоге, после аугментации, получается более 2000 изображений, из них 1800 пойдут в train выборку, остальное в test.
#Размер train выборки
train_size = 1800
#Делим на train и test
train_dataset = dataset.take(train_size).cache()
test_dataset = dataset.skip(train_size).take(len(dataset) - train_size).cache()
train_dataset = train_dataset.batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
Что видит модель после аугментации
Далее сформируем архитектуру нейронной сети. Я выбрал классическую U-Net архитектуру, которая отлично показала себя на решении вопросов семантической сегментации.

Классическая U-Net архитектура
Я специально не делал никаких блоков-функций нейросети, чтобы любой желающий смог последовательно посмотреть архитектуру. Получилось примерно следующее:

Моя версия U-Net
По сути U-Net состоит из двух частей: энкодер и декодер. Мы подаем на вход трехканальное изображение размером в нашем случае 256×256 и далее делаем downsampling, на каждом уровне мы выделяем карту признаков различных объектов (формы, размеры, цвета итд).
def unet_model(image_size, output_classes):
#Входной слой
input_layer = tf.keras.layers.Input(shape=image_size + (3,))
conv_1 = tf.keras.layers.Conv2D(64, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2, padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(input_layer)
#Сворачиваем
conv_1_1 = tf.keras.layers.Conv2D(128, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(conv_1)
batch_norm_1 = tf.keras.layers.BatchNormalization()(conv_1_1)
#2
conv_2 = tf.keras.layers.Conv2D(256, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_norm_1)
batch_norm_2 = tf.keras.layers.BatchNormalization()(conv_2)
#3
conv_3 = tf.keras.layers.Conv2D(512, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_norm_2)
batch_norm_3 = tf.keras.layers.BatchNormalization()(conv_3)
#4
conv_4 = tf.keras.layers.Conv2D(512, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_norm_3)
batch_norm_4 = tf.keras.layers.BatchNormalization()(conv_4)
#5
conv_5 = tf.keras.layers.Conv2D(512, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_norm_4)
batch_norm_5 = tf.keras.layers.BatchNormalization()(conv_5)
#6
conv_6 = tf.keras.layers.Conv2D(512, 4,
activation=tf.keras.layers.LeakyReLU(),
strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_norm_5)После чего делаем upsampling и конкатенируем с картами признаков из первого этапа.
#Разворачиваем
#1
up_1 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(512, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(conv_6), conv_5])
batch_up_1 = tf.keras.layers.BatchNormalization()(up_1)
#Добавим Dropout от переобучения
batch_up_1 = tf.keras.layers.Dropout(0.25)(batch_up_1)
#2
up_2 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(512, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_up_1), conv_4])
batch_up_2 = tf.keras.layers.BatchNormalization()(up_2)
batch_up_2 = tf.keras.layers.Dropout(0.25)(batch_up_2)
#3
up_3 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(512, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_up_2), conv_3])
batch_up_3 = tf.keras.layers.BatchNormalization()(up_3)
batch_up_3 = tf.keras.layers.Dropout(0.25)(batch_up_3)
#4
up_4 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(256, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_up_3), conv_2])
batch_up_4 = tf.keras.layers.BatchNormalization()(up_4)
#5
up_5 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(128, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_up_4), conv_1_1])
batch_up_5 = tf.keras.layers.BatchNormalization()(up_5)
#6
up_6 = tf.keras.layers.Concatenate()([tf.keras.layers.Conv2DTranspose(64, 4, activation='relu', strides=2,
padding='same',
kernel_initializer='glorot_normal',
use_bias=False)(batch_up_5), conv_1])
batch_up_6 = tf.keras.layers.BatchNormalization()(up_6)
#Выходной слой
output_layer = tf.keras.layers.Conv2DTranspose(output_classes, 4, activation='sigmoid', strides=2,
padding='same',
kernel_initializer='glorot_normal')(batch_up_6)
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
return modelВ качестве loss воспользуемся смесью из бинарной кроссэнтропии и DICE (DICE хорошо работает с сегментацией, а бинарная кроссэнтропия обеспечивает хорошую сходимость).
# Binary crossentropy + 0.25 * DICE
def dice_bce_loss(y_pred, y_true):
total_loss = 0.25 * dice_loss(y_pred, y_true) + tf.keras.losses.binary_crossentropy(y_pred, y_true)
return total_lossПримерно разобравшись в принципе выбранной нейронной сети, приступим к обучению модели. Привожу примеры работы модели после обучения 5, 10, 25 эпох.

5 эпох

10 эпох

25 эпох
Видно, что 5 эпох — модель не дообучена, 25 эпох — модель переобучена. В итоге решено было остановиться на модели обученной на 10 эпохах с dropout.

Процесс обучения на 10 эпохах, после 8 эпохи модель выходит на плато
Статичные объекты (такие как столешница, тарелка) разные по цвету и форме, модель распознает отлично, но в случае если на рыжую столешницу попадает сегмент рыжего кота, модель начинает путаться, скорее всего при другом расположении объектов модель также бы путала классы объектов. Дополнительное обучение на более качественной базе данных решило бы эту проблему, но для нашей бытовой исследовательской работы хватит полученного результата.
Итак, первая часть работы готова. Теперь у нас есть модель, которая сегментирует в кадре следующие классы: столешницу, ножки стола, стул, ножки стула, кота, тарелку с котлетами, фон.
Дальше сделаем небольшую фичу по измерению расстояния между объектами классов.

Евклидово расстояние
Тут всё просто, берем точку посередине объекта тарелки и крайнюю точку контура маски кота и смотрим на расстояние между двумя точками. Как считать расстояния между двумя точками, я думаю, никому рассказывать не надо (расскажу, с помощью расчёта Euclid distance).
def distance_between_p(p1, p2):
dis = ((p2[0] - p1[0]) ** 2 + (p2[1] - p1[1]) ** 2) ** 0.5
return disДелаем несколько «уровней» срабатывания: кот на столе, кот мордой в котлетах (это настраиваемый параметр и зависит от конкретной ситуации). Вот что видит наша модель в технической части:

Сегментация и расчёт расстояния между объектами
Здесь возникают сложности связанные с плохой сегментацией. Могут возникать объекты в кадре которые модель определяет как ещё одного кота. Кусок рыжей стены в углу кадра (или часть стола), и расчёт расстояния будет уже до этого неверно сегментированного объекта.

Ошибки плохой сегментации
В нашем случае можно воспользоваться одним из разработанных костылей, например, таким: модель будет реагировать на резкое изменение расстояния между двумя объектами (если расстояние между тарелкой и котом было 100 и резко увеличился в 5 раз, то будем считать это плохой сегментацией).
Но на самом деле, необходимо вернуться на первый этап разработки и дообучить модель на более качественных данных.
Добавим моё любимое: После каждого «уровня» безопасности будет приходить сообщение в телеграмм :)
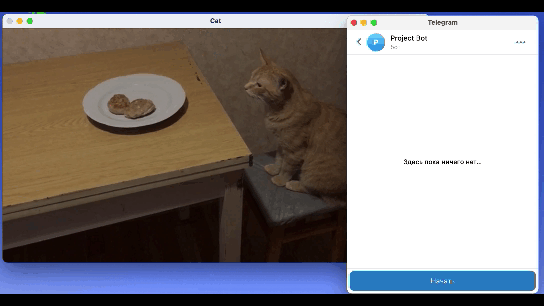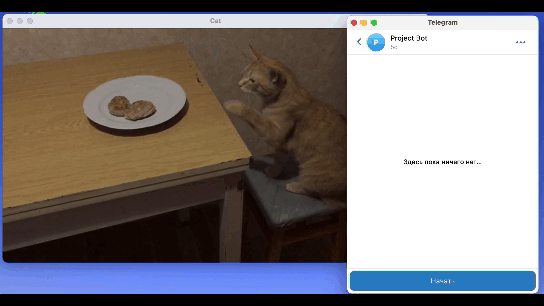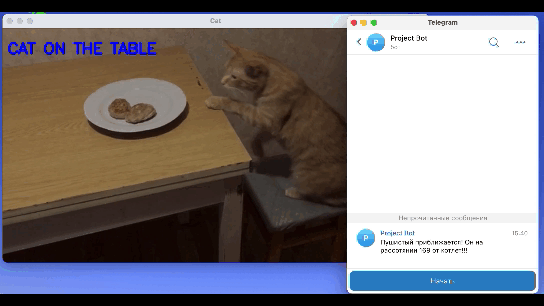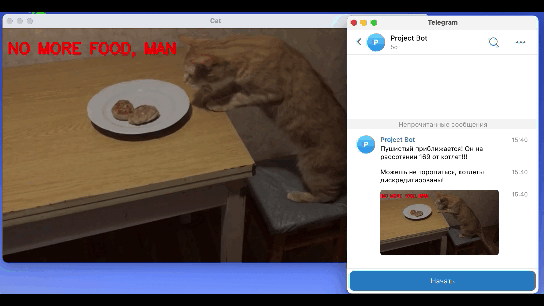
Финальный результат работы модели
Собственно говоря, у меня всё. По итогу имеется модель, которая детектирует кота в кадре и реагирует на его приближение к специально заранее обозначенным (и сегментируемым) объектам. В целом довольно простая задача, сложности могут возникнуть в качестве размеченной базы данных и в подборе правильных настроек модели. Такая примитивная модель может решать серьезные задачи, такие как, поедание котом цветов в комнате, серьезность заключается даже не в сохранении цветов, а в спасении шерстяного от ядовитых растений (Алоэ смертельно вредны для котиков, но присутствуют много у кого), поставив дома веб-камеру и разметив квартиру, можно доверить программе следить за пушистым в ваше отсутствие. Можно прикрутить много различных функций.
Основная цель этой статьи — познакомить всех желающих с базовой моделью семантической сегментации на U-Net архитектуре. Полный код можете найти на моей страничке на GitHub (https://github.com/Mazepov/Cat_Segmentation)
На этом у меня всё. Впереди ждут ещё много интересных проектов из моей головы (и не только) на основе нейронных сетей!
P.S. Кота в итоге покормили, не переживайте:)
