Schema Registry с Protobuf в Kafka — зачем оно надо?
Всем привет. Меня зовут Нина Пакшина, я разработчик в отделе Разработки и управления цифровыми продуктами и часть операционной команды в сервисе доставки продуктов «Лента Онлайн». Наш стек PHP + Python + Go.
Недавно я столкнулась с довольно тривиальной задачей: нужно было асинхронно получать большое количество данных из другого сервиса. В качестве инструмента обмена данными совместно с командой TMS, которая отвечает за управление работой сборщиков и курьеров, было решено использовать брокер сообщений Kafka.
Также, между различными продуктовыми командами нашего сервиса существовала договоренность использовать Kafka вместе с Schema Registry и Protobuf в качестве формата сообщений.
Со стороны нашей команды мы впервые реализовали такую связку, поэтому в этой статье хочу поделиться своим опытом написания продюсера и консьюмера с использованием Schema Registry на Go, а также рассказать о подводных камнях, с которыми вы можете столкнуться.
Что такое Schema Registry?
Если очень упростить — Schema Registry (далее SR) — это отдельный от Kafka компонент, который является сервисным слоем для метаданных Kafka сообщений.
На рисунке 1 — схема работы SR из официальной документации от Confluentic.
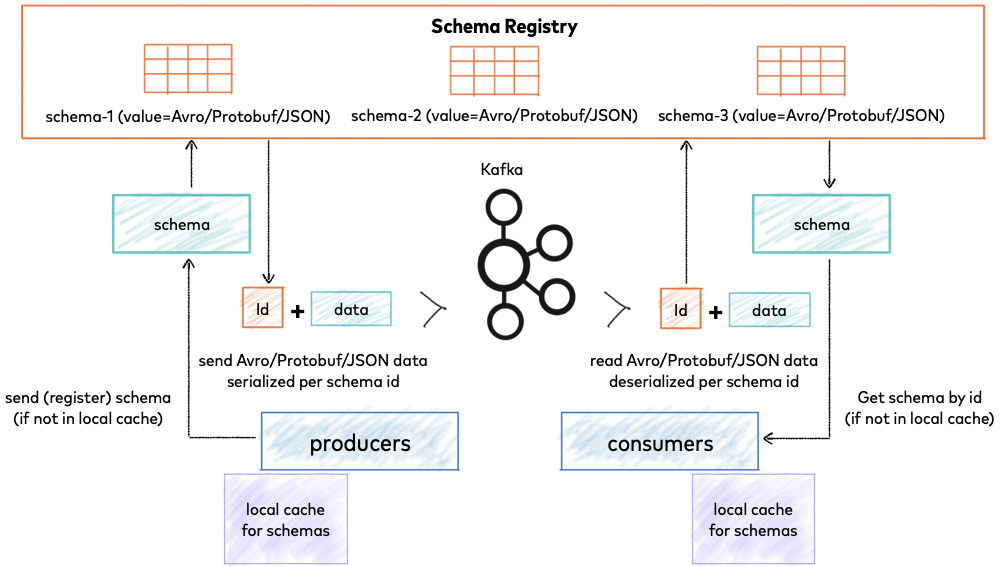 Рис 1. Как работает Schema Registry
Рис 1. Как работает Schema Registry
SR, по сути является прослойкой между Kafka и клиентским продюсером/консьюмером, а главная задача клиента и сервера SR — поддерживать совместимость между различными версиями сообщений и валидировать их согласно заданной схемы.
SR хранит в себе не только текущую схему, но и всю историю изменений, работает с форматами сообщений Avro, Json Schema или Protocol buffers, а также следит за обратной совместимостью передаваемых сообщений.
SR имеет свой RESTfull интерфейс, который предоставляет доступ ко всем действиям над схемами сообщений (создание, чтение, удаление и тд).
Как работает SR?
На примере связки Kafka + Schema Registry + Protobuf, рассмотрим в упрощенной схеме как работает SR (с остальными форматами сообщений все похоже, но есть свои нюансы):
В репозитории продюсера Kafka создается, сохраняется и компилируется на нужный язык в объект‑структуру DTO схема Protobuf.proto;
При отправке сообщения, если схема еще не была зарегистрирована в SR, клиент SR регистрирует ее и дает ей id версии. Если схема уже была зарегистрирована, то используется существующий id;
Сообщение определенным образом, используя id схемы, сериализуется и отправляется в брокер Kafka;
Репозиторий консьюмера не хранит в себе исходную схему Protobuf.proto, а имеет только скомпилированную на нужный язык объект‑структуру DTO;
Консьюмер получает сериализованное сообщение из Kafka. Затем по id версии схемы получает схему из SR и десериализует сообщение в DTO.
Пишем примеры на Go
Я не буду рассказывать, как поднимать и настраивать связку Kafka + Schema Registry. Для локального тестирования вы можете использовать уже готовый docker‑compose файл и запустить систему у себя в докере.
Для работы нам понадобится брокер Kafka и сервер Schema Registry с известными нам адресами, которые обозначим как kafkaURL и srURL соответственно.
Для работы с SR на языке Go было несколько вариантов:
Написать клиент SR самостоятельно, учитывая все нюансы взаимодействия;
Использовать нативный клиент от Confluent, который называется confluent‑kafka‑go.
Нативный клиент от Confluent есть не для всех языков, а только для C/C++, Python, Golang, Java,.NET.
Поэтому, так как мне повезло, я решила пойти более простым путем и использовать готовый клиент, тем более что для него существует достаточно подробная документация и несколько рабочих примеров.
Шаг 1: продюсер
Напишем SR продюсер SRProducer, который позволит регистрировать схему в SR для формата сообщений Protobuf и отправлять сообщения в Kafka.
Полный код SR продюсера можно посмотреть здесь.
// SRProducer интерфейс, реализующий методы продюсера SR
type SRProducer interface {
ProduceMessage(msg proto.Message, topic string) (int64, error)
Close()
}
type srProducer struct {
producer *kafka.Producer
serializer serde.Serializer
}
// NewProducer возвращает продюсер SR для работы с kafka и schema registry
func NewProducer(kafkaURL, srURL string) (SRProducer, error) {
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": kafkaURL})
if err != nil {
return nil, err
}
c, err := schemaregistry.NewClient(schemaregistry.NewConfig(srURL))
if err != nil {
return nil, err
}
s, err := protobuf.NewSerializer(c, serde.ValueSerde, protobuf.NewSerializerConfig())
if err != nil {
return nil, err
}
return &srProducer{
producer: p,
serializer: s,
}, nil
}NewProducer возвращает SR продюсер, который реализует интерфейс SRProducer.
Для работы нашего продюсера необходимо подключить:
Обратите внимание, что при создании сериализатора protobuf.NewSerializer(...) передается параметр serde.ValueSerde. Запомним это место и чуть дальше обсудим, что он значит.
SR продюсер SRProducer реализует два метода: ProduceMessage, который регистрирует схему и отправляет данные в Kafka, а также Close для закрытия соединений.
const (
nullOffset = -1
)
// ProduceMessage отправляет сообщение proto.Message в определенный топик
func (p *srProducer) ProduceMessage(msg proto.Message, topic string) (int64, error) {
kafkaChan := make(chan kafka.Event)
defer close(kafkaChan)
payload, err := p.serializer.Serialize(topic, msg)
if err != nil {
return nullOffset, err
}
if err = p.producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic},
Value: payload,
}, kafkaChan); err != nil {
return nullOffset, err
}
e := <-kafkaChan
switch ev := e.(type) {
case *kafka.Message:
return int64(ev.TopicPartition.Offset), nil
case kafka.Error:
return nullOffset, err
}
return nullOffset, nil
}
// Close закрывает соединение с schema registry и kafka
func (p *srProducer) Close() {
p.serializer.Close()
p.producer.Close()
}Метод ProduceMessage отправляет сообщения типа proto.Message в Kafka. Перед отправкой сообщение сериализуется.
Затем, с помощью метода p.producer.Produce продюсера Kafka мы отправляем сериализованное сообщение в брокер. Отчет об отправке сообщения приходит в канал kafka.Event.
Для информативности наш метод ProduceMessage будет возвращать offset записанного сообщения и ошибку, если она возникла.
В качестве сообщения Protobuf будем передавать следующее сообщение test.v1.proto со схемой:
syntax = "proto3";
option go_package = "./pkg/test.v1";
package test.v1;
message TestMessage {
int32 Value = 1;
}Важно указать директиву package в.proto файле, особенно в разрезе работы с несколькими версиями одного контракта. Go не cкомпилирует код, если в одном пакете используется две версии контрактов с одинаковыми или отсутствующим package.
Сгенерировать из.proto файла go код можно с помощью команды (он будет сгенерирован в папку pkg/test.v1):
protoc --go_out=. proto/test.v1.protoДля генерации кода используется утилита protoc.
Также обратите внимание, что для генерации кода в go необходима опция go_package, которая определяет путь импорта пакета c сгенерированным кодом.
Если в контракте она отсутствует, можно использовать M флаг для указания пути импорта пакета (сгенерированный код будет также лежать в pkg/test.v1):
protoc --go_out=. --proto_path=proto --go_opt=Mtest.v1.proto=./pkg/test.v1 proto/test.v1.protoСообщение TestMessage будем отправлять в топик «topic.v1» Kafka. Полный код примера для функции main здесь:
const (
topic = "topic.v1"
)
func main() {
kafkaURL := os.Getenv("KAFKA_URL")
schemaRegistryURL := os.Getenv("SCHEMA_REGISTRY_URL")
producer, err := kafka.NewProducer(kafkaURL, schemaRegistryURL)
defer producer.Close()
if err != nil {
log.Fatalf("error with producer: %v", err)
}
testMSG := test.TestMessage{Value: 42}
offset, err := producer.ProduceMessage(&testMSG, topic)
if err != nil {
log.Fatalf("error with produce message: %v", err)
}
fmt.Println(offset)
}Если мы запустим код, не забыв указать в переменных окружения KafkaURL и SchemaRegistryURL под именами KAFKA_URL и SCHEMA_REGISTRY_URL, то мы получим из Kafka сдвиг offset для нашего сообщения, который равен 0. Все работает!
Но погодите, что значит все работает? Загрузилась ли схема? Что вообще произошло?
Если вы помните, SR предоставляет REST API для работы со схемами, поэтому, мы можем сделать запрос на получение всех существующих схем ({{schema-registry-url}} — адрес нашего сервера SR):
GET {{schema-registry-url}}/schemas/В ответ мы получим:
[
{
"subject": "topic.v1-value",
"version": 1,
"id": 1,
"schemaType": "PROTOBUF",
"schema": "syntax = \"proto3\";\npackage test.v1;\n\noption go_package = \"./pkg/test.v1\";\n\nmessage TestMessage {\n int32 Value = 1;\n}\n"
}
]В поле schema мы видим исходный файл.proto в текстовом виде.
Как схема попала в SR, если мы ничего вручную не создавали и не вызывали никаких POST?
Дело в том, по умолчанию у сериализатора SR включена опция AutoRegisterSchemas, которая автоматически регистрирует схемы при сериализации сообщений (исходник).
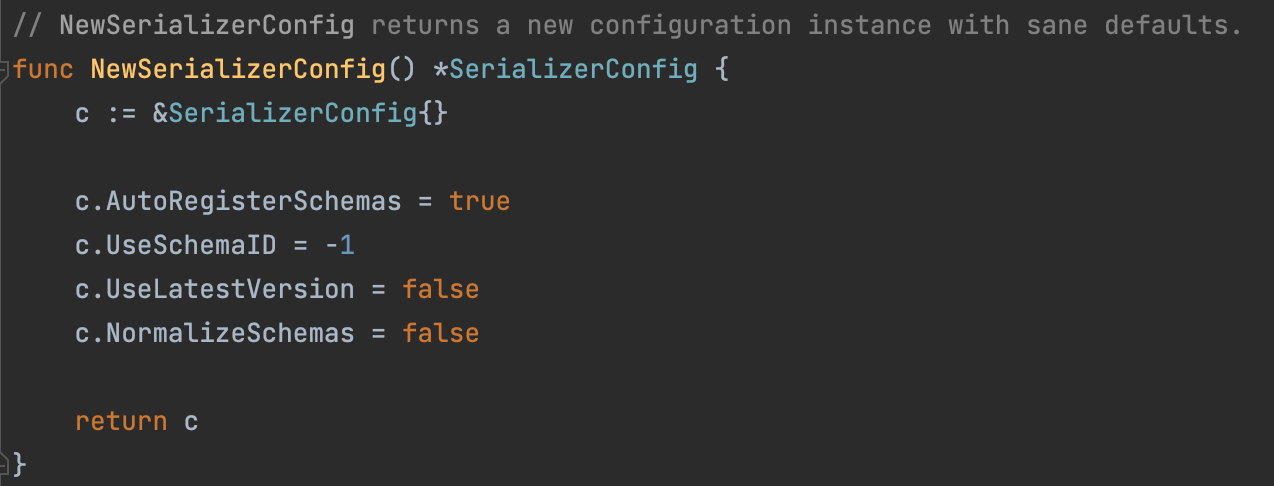 Рис 2. Конфиг сериализатора SR по умолчанию в schemaregistry/serde/config.go
Рис 2. Конфиг сериализатора SR по умолчанию в schemaregistry/serde/config.go
Схема автоматически регистрируется при вызове метода p.serializer.Serialize, и если она не существовала, ей присваивается новый id.
Так как мы отправили сообщение в первый раз, наша схема автоматически зарегистрировалась с id = 1, version = 1 и типом PROTOBUF.
Единственное, что сразу вызывает вопрос — это поле subject, в котором значение topic.v1-value, несмотря на то, что в брокере Kafka мы назвали топик topic.v1. Откуда появился постфикс -value?
SR регистрирует схему в своем реестре в пространстве имен subject. В рамках одного пространства имен производится проверка на совместимость схем. Все версии схемы привязаны к одному пространству имен. Когда схема меняется, она все так же привязана к исходному пространству имен, но у нее меняется id и версия схемы.
В SR задано несколько стратегий для определения пространства имен. По умолчанию используется TopicRecordNameStrategy. Здесь в качестве базы используется имя используемого топика в Kafka.
А постфикс определяется параметром, который мы передавали в сериализатор, и в нашем случае это serde.ValueSerde. Именно он определяет какой постфикс будет на конце топика: serde.ValueSerde для -value (есть также параметр serde.KeySerde, который соответствует постфиксу -key)
Стратегия названия пространства имен может быть отлична от TopicRecordNameStrategy. Например, еще существует RecordNameStrategy, когда пространство имен схемы определяется названием сообщения в схеме Protobuf. Такой механизм нужен, если в рамках одного топика Kafka передается несколько разных типов сообщений Protobuf, и для них также нужно валидировать схемы.
Но имейте в виду, что для клиента Go в confluent‑kafka‑go реализована только TopicRecordNameStrategy.
В поле «schema» мы видим наш исходный.proto файл: syntax = "proto3";\npackage test.v1;\n\noption go_package = "./pkg/test.v1";\n\nmessage TestMessage {\n int32 Value = 1;\n}\n
Как SR узнает, откуда его брать? Что будет если мы в коде перенесем этот файл в другое место или удалим? Продюсер не сможет отправить сообщение?
Оказывается, для того, чтобы отправить сообщение, сериализатору не нужен исходный файл.proto. Все данные о схеме Protobuf он восстанавливает из proto.Message. Вся магия происходит в методе toProtobufSchema.
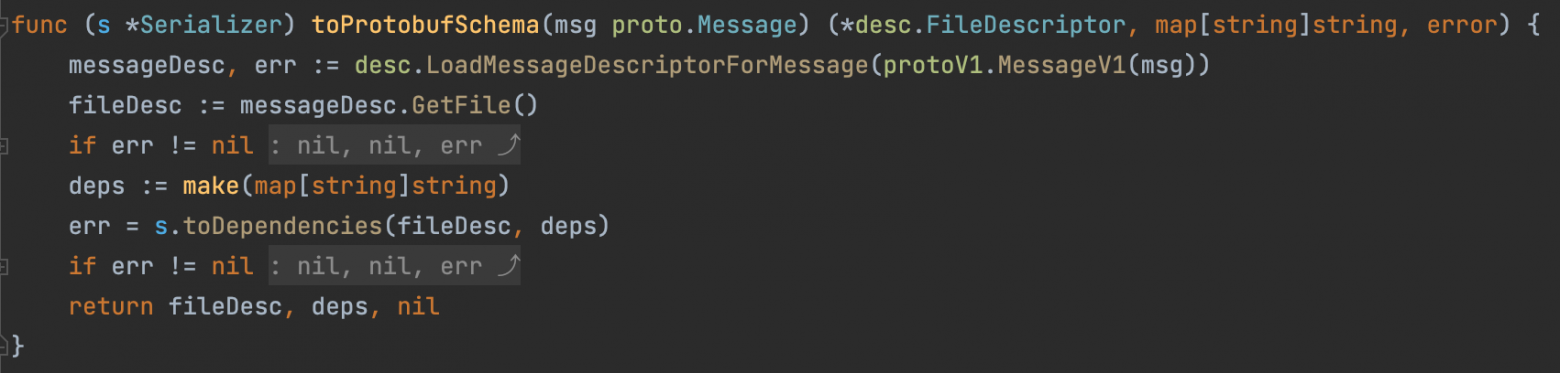 Рис 3. Генерация исходной схемы .proto из proto.Message
Рис 3. Генерация исходной схемы .proto из proto.Message
Шаг 2: Консьюмер SR
На предыдущем шаге мы с помощью SR продюсера отправили сообщение в брокер Kafka. Сейчас напишем SR консьюмер, который получит это сообщение из Kafka.
NewConsumer возвращает новый SR консьюмер, который реализует интерфейс SRConsumer. Для работы нам необходимо создать:
консьюмер Kafka
kafka.NewConsumer(...)клиент SR
schemaregistry.NewClient(...)десериализатор Protobuf
protobuf.NewDeserializer(...)
Полный код SR консьюмера здесь.
const (
consumerGroupID = "test-consumer"
defaultSessionTimeout = 6000
noTimeout = -1
)
// SRConsumer интерфейс, реализующий методы SR консьюмера
type SRConsumer interface {
Run(messageType protoreflect.MessageType, topic string) error
Close()
}
type srConsumer struct {
consumer *kafka.Consumer
deserializer *protobuf.Deserializer
}
// NewConsumer возвращает новый SR консьюмер для работы с Kafka и SR
func NewConsumer(kafkaURL, srURL string) (SRConsumer, error) {
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": kafkaURL,
"group.id": consumerGroupID,
"session.timeout.ms": defaultSessionTimeout,
"enable.auto.commit": false,
})
if err != nil {
return nil, err
}
sr, err := schemaregistry.NewClient(schemaregistry.NewConfig(srURL))
if err != nil {
return nil, err
}
d, err := protobuf.NewDeserializer(sr, serde.ValueSerde, protobuf.NewDeserializerConfig())
if err != nil {
return nil, err
}
return &srConsumer{
consumer: c,
deserializer: d,
}, nil
}Интерфейс SRConsumer содержит методы:
Run— для запуска консьюмера SR, который позволяет читать сообщения из Kafka, сопоставлять их со схемой из SR и десериализовать в сообщение proto.Message;Close— для завершения работы клиентов.
Метод Run запускает SR консьюмер. Перед чтением сообщений из Kafka происходит два важных события:
c.consumer.SubscribeTopics(...)подписывает консьюмер Kafka на нужный топик.c.deserializer.ProtoRegistry.RegisterMessage(...)регистрирует дескриптор типаprotoreflect.MessageTypeсообщения, в которое мы будем десериализовать байты из Kafka.
// Run запускает SR консьюмер
func (c *srConsumer) Run(messageType protoreflect.MessageType, topic string) error {
if err := c.consumer.SubscribeTopics([]string{topic}, nil); err != nil {
return err
}
if err := c.deserializer.ProtoRegistry.RegisterMessage(messageType); err != nil {
return err
}
for {
kafkaMsg, err := c.consumer.ReadMessage(noTimeout)
if err != nil {
return err
}
msg, err := c.deserializer.Deserialize(topic, kafkaMsg.Value)
if err != nil {
return err
}
c.handleMessage(msg, int64(kafkaMsg.TopicPartition.Offset))
if _, err = c.consumer.CommitMessage(kafkaMsg); err != nil {
return err
}
}
}
func (c *srConsumer) handleMessage(message interface{}, offset int64) {
fmt.Printf("message %v with offset %d\n", message, offset)
}Организовать работу консьюмера SR можно с помощью пула воркеров (worker pool), но в нашем случае напишем более простой пример, используя метод Poll() (ReadMessage — оболочка над функцией Poll), который опрашивает определенный топик с заданным таймаутом. В нашем случае таймаут noTimeout = -1, то есть равен бесконечности.
В поле msgKafka.Value хранится сериализованное сообщение в виде массива байтов []byte, полученное из Kafka.
Для того, чтобы это сообщение десериализовать в нужную структуру DTO, используется метод десериализатора c.deserializer.Deserialize(...).
Десериализованное сообщение msg отправляется в обработчик c.handleMessage(...), где обрабатывается нужным нам образом.
Напишем программу для вызова SR консьюмера (полный код здесь).
const (
topic = "topic.v1"
)
func main() {
kafkaURL := os.Getenv("KAFKA_URL")
schemaRegistryURL := os.Getenv("SCHEMA_REGISTRY_URL")
consumer, err := kafka.NewConsumer(kafkaURL, schemaRegistryURL)
defer consumer.Close()
if err != nil {
log.Fatal(err)
}
messageType := (&test.TestMessage{}).ProtoReflect().Type()
if err := consumer.Run(messageType, topic); err != nil {
log.Fatal(err)
}
}Если мы запустим наш консьюмер, сообщение из топика успешно десериализуется:
message Value:42 with offset 0Таким образом, мы прочитали сообщение из нужного нам топика и десериализовали его в DTO.
Шаг 3: Обновляем контракты
Наше приложение растет, расширяется и требует доработки контракта между консьюмерами и продюсером.
Например, мы хотим добавить новое поле Message в наш контракт:
syntax = "proto3";
option go_package = "./pkg/test.v1";
package test.v1;
message TestMessage {
int32 Value = 1;
string Message = 2;
}Теперь продюсер отправляет сообщение в новом формате:
test.TestMessage{Value: 42, Message: "test"}Если мы сделаем снова запрос на получение всех схем в SR, мы получим две версии наших схем, с id = 1 и новую с id = 2:
[
{
"subject": "topic.v1-value",
"version": 1,
"id": 1,
"schemaType": "PROTOBUF",
"schema": "syntax = \"proto3\";\npackage test.v1;\n\noption go_package = \"./pkg.test.v1\";\n\nmessage TestMessage {\n int32 Value = 1;\n}\n"
},
{
"subject": "topic.v1-value",
"version": 2,
"id": 2,
"schemaType": "PROTOBUF",
"schema": "syntax = \"proto3\";\npackage test.v1;\n\noption go_package = \"./pkg/test.v1\";\n\nmessage TestMessage {\n int32 Value = 1;\n string Message = 2;\n}\n"
}
]Если мы запустим наш консьюмер, не обновляя предоставленный DTO новым полем, сообщение из топика с новым контрактом беспрепятственно сериализуется в старую версию DTO. Таким образом, совместимость между продюсером и консьюмером не нарушится.
Попробуем доработать контракт следующим образом: вместо добавления поля изменим его тип. Поле Value стало типом string.
syntax = "proto3";
option go_package = "./pkg/test.v1";
package test.v1;
message TestMessage {
string Value = 1;
string Message = 2;
}Продюсер будет отправлять следующее сообщение:
testMsg := test.TestMessage{Value: "42", Message: "test"}И при попытке отправить его в Kafka, наш SR консьюмер вернет ошибку:
schema registry request failed error code: 409: Schema being registered is incompatible with an earlier schema for subject "topic.v1-value"Данная ошибка означает, что новая схема не отвечает правилам совместимости с предыдущими схемами и она ломает работу консьюмеров, которые используют предыдущие версии схем.
У SR есть разные уровни совместимости. По умолчанию используется уровень совместимости BACKWARD, то есть обратный уровень совместимости.
Например, если мы добавили новое поле или удалили прежнее при уровне совместимости BACKWARD схема пройдет валидацию.
А если, например, у существующего поля вы изменили тип данных, то обратная совместимость не будет соблюдена и сохранить новую версию схемы не получится.
То есть, в текущем топике эта схема не будет сохранена и нужно будет создавать другой топик. (В таком случае, необходимо создавать новый топик версии 2).
Подробнее об уровнях совместимости здесь.
Подводные камни работы со Schema Registry
Как видите, при работе с готовыми библиотеками Schema Registry от Confluent все довольно просто. Но, как я уже говорила, готовый клиент для SR есть не для всех языков, а только для C/C++, Python, go, Java, .NET.
И самое интересное начинается, когда необходимо написать продюсер или консьюмер на языке, для которого нет нативной библиотеки.
В нашем проекте, мы столкнулись с тем, что необходимо было написать продюсер на языке PHP, который был бы совместим с работой SR. Поэтому рассмотрим на примере продюсера, что он должен делать, чтобы иметь совместимость с SR:
Зарегистрировать схему в сервере Schema Registry.
Сериализовать сообщение из DTO в набор байтов.
Отправить его в нужный топик Kafka.
С третьим пунктом все понятно и просто. Поэтому рассмотрим первые два.
Зарегистрировать схему в schema registry
Достаточно создать клиент REST API для SR и помощью метода POST создать и зарегистрировать схему в нужном пространстве имен: пример в документации
Здесь важно помнить, что пространство имен не совпадает с названием топика в брокере Kafka. Мы уже говорили про пространства имен ранее и если вы в консьюмере используете параметр serde.ValueSerde при сериализации, то топику topic.v1 в брокере Kafka в SR будет соответствовать пространство имен topic.v1-value.
Сериализация сообщения
Мы не можем просто так взять и сериализовать наш DTO в массив байтов и отправить его в нужный топик. Все сломается, потому что при сериализации сообщения используется специальный протокол и специальный способ кодирования.
Вот так в общем формате выглядит формат сообщений.
Для формата Protobuf используется такой формат сообщений:
Байты | Название | Описание |
0 | Magic Byte | Равен 0 для текущей версии |
1–4 | Schema ID | ID схемы в SR, используя ID схемы и имя топика всегда однозначно можно определить нужную схему. |
5…N | Message Indexes | Указывает на индекс сообщения в Protobuf. В самом частом случае, если используется первое сообщение из схемы Protobuf, Message Index будет равен 0 |
N… | Data | Сериализованное сообщение |
Message Indexes — один из самых неочевидных моментов. Изначально — это массив чисел, который точно определяет расположение сообщения Protobuf в структуре.proto.
Например, у нас есть схема с множеством вложенных сообщений:
package test.package;
message MessageA {
message Message B {
message Message C {
...
}
}
message Message D {
...
}
message Message E {
message Message F {
...
}
message Message G {
...
}
...
}
...
}
message MessageH {
message MessageI {
...
}
}Если мы захотим отправить сообщение Message G, то его расположение в схеме будет кодироваться индексами [0, 2, 1]: оно вложено в сообщение A на уровне 0, вложено в сообщение E на уровне 2 и занимает 1 уровень внутри сообщения E.
Далее этот индекс кодируется с помощью variable‑length zig‑zag encoding (зигзагообразное кодирование переменной длины), которое также используется в Google Protocol Buffers, и получается нужный нам Message Indexes. Подробнее об данном алгоритме кодирования можно почитать здесь и здесь.
Но в самом распространенном случае, если используется первое и единственное сообщение из Protobuf схемы, то Message Indexes будет равен 0.
Для тех, кто хочет углубиться в то, как вычисляется Message Indexes, можно посмотреть исходный код на примере Go здесь.
Оставшиеся байты Data представляют сериализованное в массив байтов с помощью функции proto.Marshal(...) сообщение.
Весь процесс сериализации сообщений на примере Go в исходнике можно посмотреть здесь.
Выводы
Выводы, которые я сделала для себя, погрузившись в дивный мир SR:
SR позволяет поддерживать совместимость в рамках одного контракта, гарантируя то, что все версии схемы будут иметь обратную совместимость и при дальнейшей разработке ничего не сломается. А если контракт ломается, значит пора переходить на новую версию контракта;
SR содержит всю историю изменений контракта;
По сравнению с использованием JSON вместе с Kafka, SR + Protobuf очень сильно упрощает жизнь разработчику в плане работы с DTO. Последнюю актуальную версию исходника схемы.proto можно даже не просить у своего коллеги, а скачать с помощью обычного REST API клиента из Schema Registry;
Нет необходимости создавать общий репозиторий со всеми контрактами и следить за его обновлением. Исходный файл.proto хранится на сервере SR;
SR — это лишняя сущность, за которой надо следить. Хорошо работает с клиентами из коробки, но может испортить жизнь нескольким командам, если придется писать свой собственный клиент;
Документация для SR очень подробная, но из‑за этого сложная для восприятия. Огромный плюс в том, что есть готовые примеры, а исходный код открыт для изучения;
В сети по данной теме очень мало обучающих видео, статей и вопросов в Stackoverflow. Но зато прямо сейчас стало на одну статью больше.
