Сборка мусора в JavaScript
Каждый из нас, хотя бы раз, слышал о сборке мусора. Мы знаем, что где-то там работает сборщик мусора, убирая за нами ненужные объекты. Но сколько из нас знают, как он устроен под капотом?
В этой статье мы заглянем под капот этого процесса, поймем, как работает память, и изучим алгоритм сборки мусора.
Поехали убираться!
Мы будем рассматривать только V8
За основу мы возьмем браузерный движок V8(именно на нем мы будем рассматривать как работает алгоритм сборки мусора), сделаем мы это по нескольким причинам:
Во-первых, если мы заглянем на Википедию, то увидим, что только Google Chrome занимает 65.76% рынка среди всех браузеров. Кроме того, существует еще довольно много Chromium based браузеров (Opera, Vivaldi, Brave). В связи с этим получаем, что большую часть рынка занимает V8.
Во-вторых, в интернете о V8 есть большое количество материала. Разработчики достаточно часто публикуют свои статьи о новых и старых фичах движка в блог, поэтому достоверной и валидной информации гораздо больше.
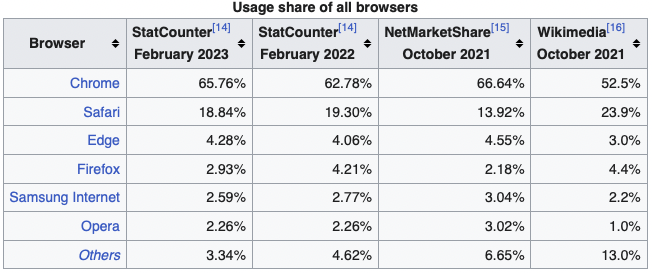
V8 доминирует.
Про память в V8
Сначала давайте кратко посмотрим, какие структуры данных используются для хранения наших данных и как они выглядят. Это поможет нам лучше понять, с чем работает сборщик мусора.
Для хранения данных у нас есть 2 структуры данных — Стек и Куча.
Стек — это структура данных, которая подчиняется принципу LIFO (Last In, First Out), т.е. последний пришёл — первый ушёл. V8 использует стек для управления контекстами выполнения функций. Когда функция вызывается, контекст выполнения этой функции помещается на вершину стека, он в свою очередь содержит информацию о состоянии функции, ее локальных переменных, параметрах и значении this. Когда функция выполняется, её переменные и параметры хранятся в стеке.
Что хранится на стеке?
Примитивные типы данных, такие как Number, String, Boolean, undefined, null и symbol, обычно хранятся прямо в стеке, поскольку они имеют фиксированный размер. Также на стеке хранятся ссылки на объекты/массивы в куче.
Однако существуют исключения, например, вещественные числа — heapNumber, которые могут хранится в куче, а на стеке будет только ссылка на значение в куче. Также это может происходить и с String, Boolean, undefined, null более подробно об этом можно почитать вот в этой прекрасной статье — тык.
Куча — это область памяти, используемая для хранения переменных с динамическим размером, например обьектов/массивов/сетов и тд.
Что хранится на куче?
Как мы уже выяснили ранее, здесь могут хранится некоторые примитивы, а также массивы и объекты, и вообще все, что не имеет фиксированного размера.
Важно учитывать, что куча делиться на определенные сегменты (это будет важно в дальнейшем при рассмотрении алгоритмов сборки мусора):
New Space (молодое поколение) — Этот сегмент кучи предназначен для размещения большинства вновь созданных объектов. Он имеет небольшой размер, но его объекты часто собираются сборщиком мусора, так как многие объекты умирают молодыми, также он разделяется на две области From Space и To Space (об этом подробнее мы поговорим далее).
Old Space (старое поколение) — Этот сегмент кучи предназначен для размещения объектов, которые пережили несколько сборок мусора в New Space. Так как объекты здесь реже удаляются, сборка мусора здесь происходит реже и обычно занимает больше времени.
Large Object Space — Этот сегмент кучи предназначен для размещения больших объектов, размеры которых превышают предельно допустимый размер для размещения в New Space.
Code Object Space — Этот сегмент кучи предназначен для размещения объектов кода, содержащих JIT-инструкции. Это единственное пространство с исполняемой памятью (хотя коды могут быть размещены в пространстве больших объектов, и они тоже будут являться исполняемыми).
Кстати, объекты, которые создаются в куче, можно посмотреть с помощью Chrome Devtools в Heap Snapshot:
// Chrome Dev Tools -> Memory -> Heap Snapshot
function testTypes() {
this.array = ['42', '4242', '424242'];
this.object = {
'42': '42',
'4242': '4242',
};
this.set = new Set(['42', '4242']);
}
const types = new testTypes();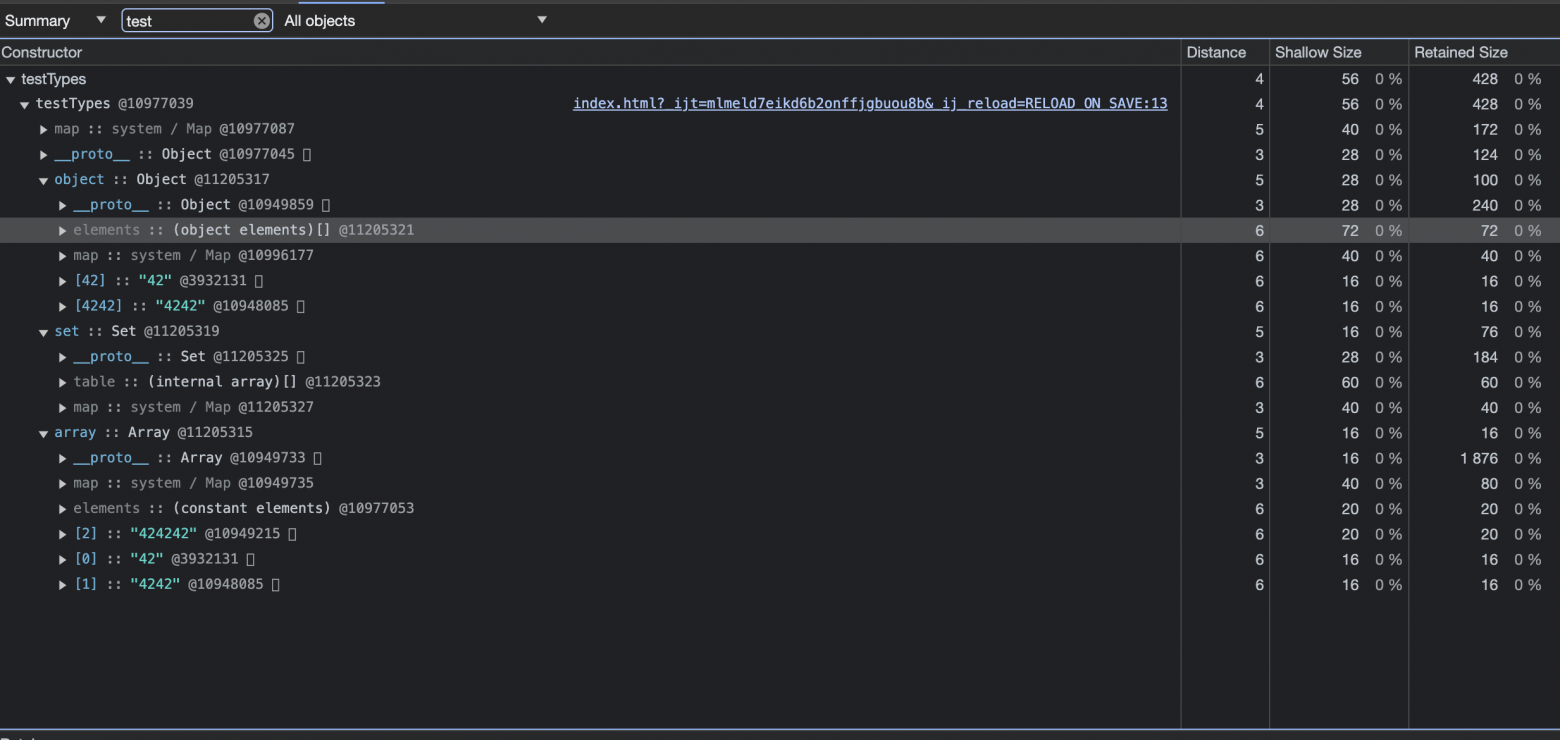
Heap Snapshot
Жизненный цикл памяти
В контексте управления памятью, термины «allocate», «use» и «release» относятся к классическим этапам работы с памятью. Они описывают процесс выделения памяти для хранения данных, использования этой памяти и освобождения памяти, чтобы она могла быть переиспользована. Давайте более подробно разберём каждый из этих этапов:
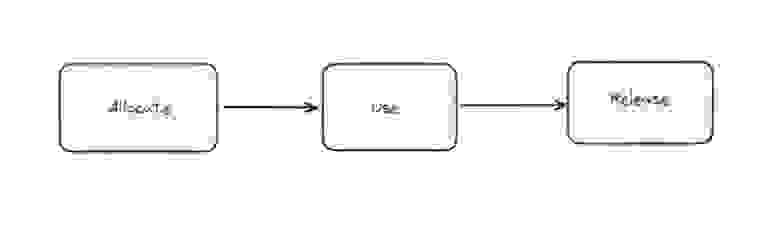
Memory lifecycle
Allocate — запрос на выделение памяти из доступного пула ресурсов для использования в программе. В JS нет возможности явно выделять памяти с помощью каких-либо инструментов, в JS это делает движок, который выделяет необходимое количество памяти.
Use — использование памяти. В данной фазе переменные присваиваются значениям, объекты заполняются данными, массивы заполняются элементами и т.д. Если коротко, то это просто различные манипуляции с памятью.
Release — освобождение памяти — это процесс, в котором ранее выделенная память возвращается системе для повторного использования. В среде JavaScript освобождение памяти управляется автоматически через процесс сборки мусора (Garbage Collection, GC). Сборщик мусора периодически находит объекты, которые больше не доступны в контексте выполнения программы, и автоматически освобождает связанную с ними память.
Теорию по памяти мы освежили, можем переходить к сборке мусора.
Сборка мусора
Зачем вообще собирать мусор ?
Сборщики нужны для того, чтобы у нас не заканчивалась память после того, как мы открыли несколько вкладок в браузере (соответственно, в каждой вкладке под приложение выделяется память). Они помогают эффективно использовать ресурсы компьютера и не занимать память ненужными для работы объектами.
Какие задачи есть у любого сборщика мусора ?
Поиск живых объектов и мертвых объектов (мусора).
Повторно использовать память занятую мертвыми объектами (мусором).
Опционально, может дефрагментировать память, чтобы было удобнее аллоцировать память под новые объекты.
Мы поняли, что собирать нужно и примерно понимаем алгоритм по которому мы хотим его собирать, переходим к самому интересному.
Что такое мусор ?

Мем чтобы расслабить мозг
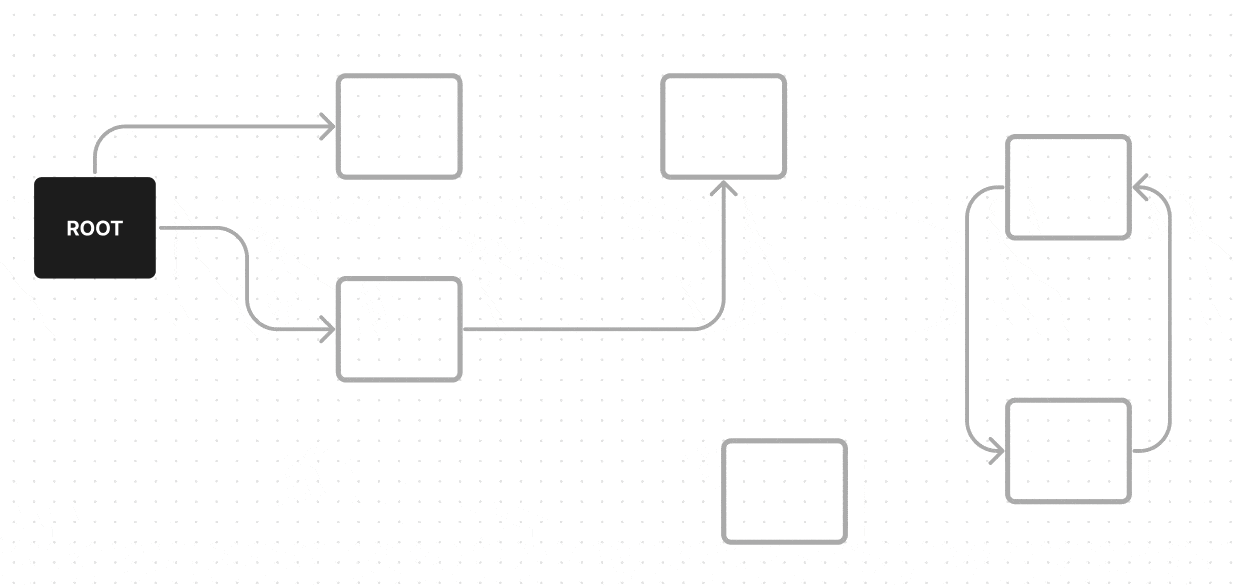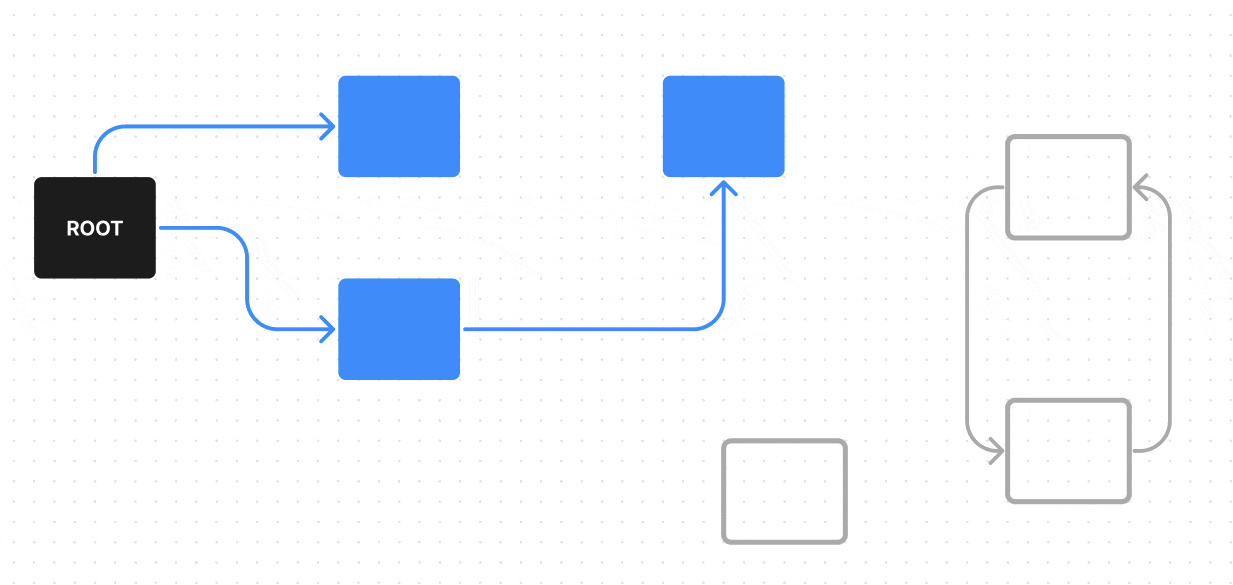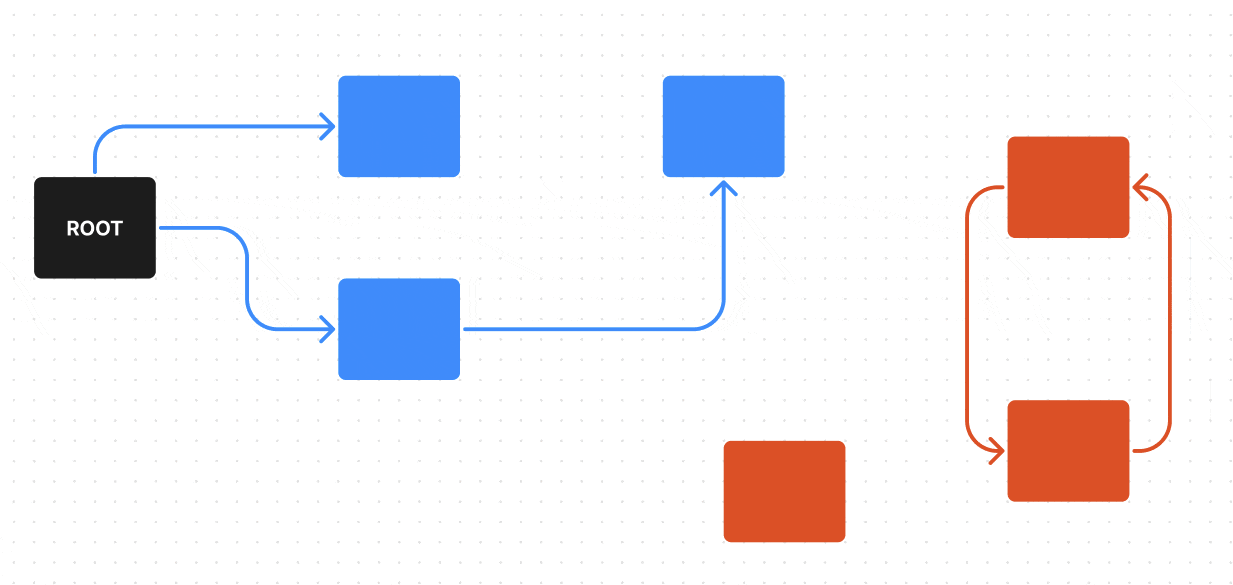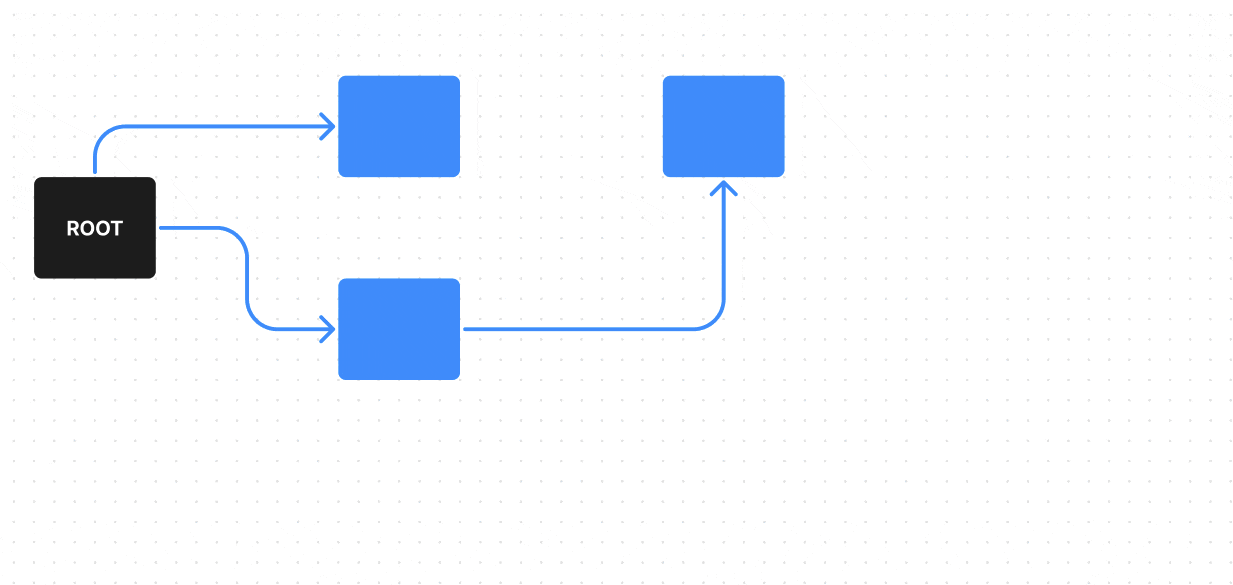
Мусором считаются объекты, которые недостижимы из корневых объектов по ссылкам (ребрам). Это можно рассматривать как обход графа: мы начинаем от корневых объектов (узлов), проходим по всем ссылкам (ребрам) до всех возможных объектов (узлов), а те объекты, до которых мы не смогли дойти и будут считаться мусором.
Множество корневых объектов — это объекты, которые являются глобальными переменными, локальными переменными в стеке вызовов или другими активными ссылками, которые напрямую доступны выполняющемуся коду (window, Promise, Microtask, Macrotask и тд.).
N.B. мусор собирается только в куче.
Чтобы стало понятнее, что такое мусор, давайте рассмотрим пример:
В нем у нас есть ROOT — один из корневых объектов, от него мы можем пройти по всем возможным ребрам (ссылкам) к объектам, до которых можно из него дойти (на гифке они красятся в синий), эти объекты достижимы — поэтому они не будут считаться мусором, а вот объекты, которые недостижимы из ROOT по ребрам (ссылкам) — будут считаться мусором (на гифке они красятся в красный).
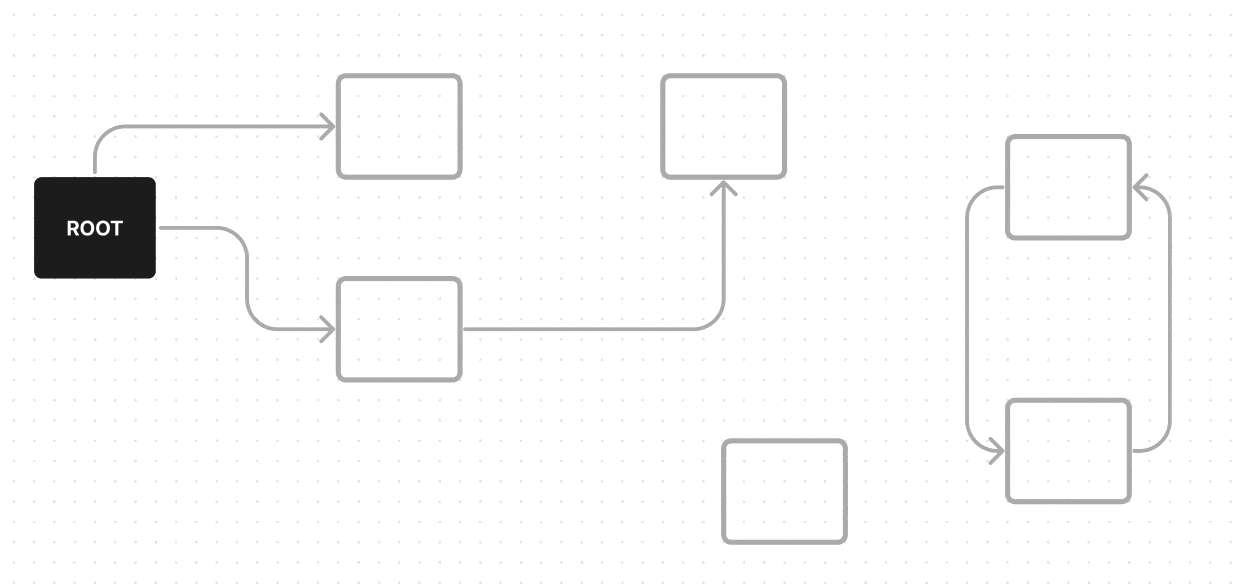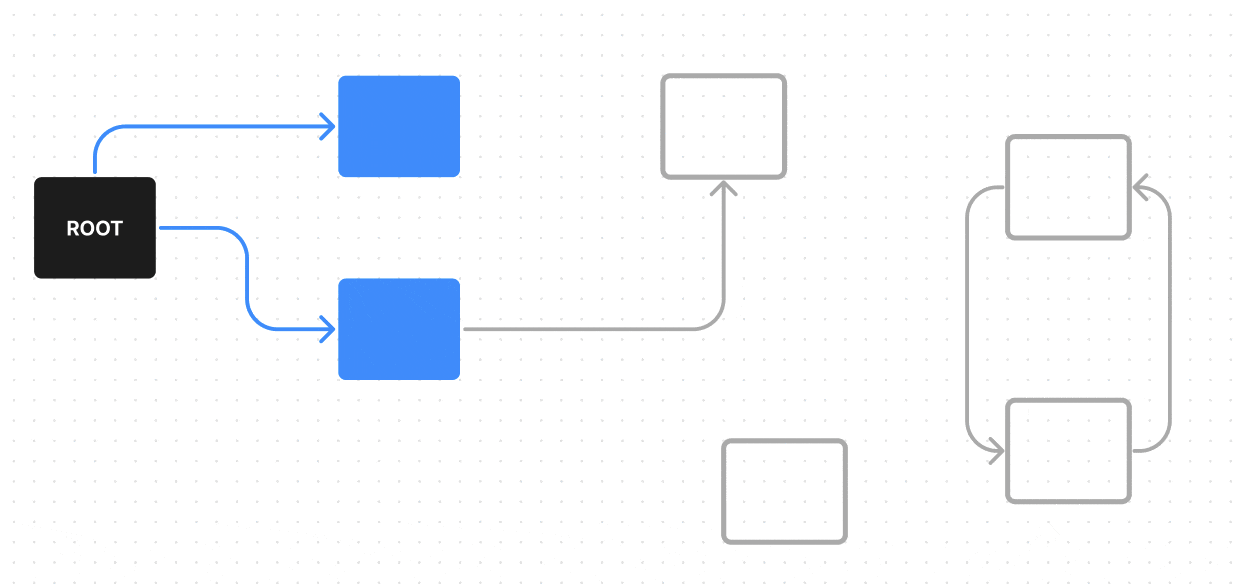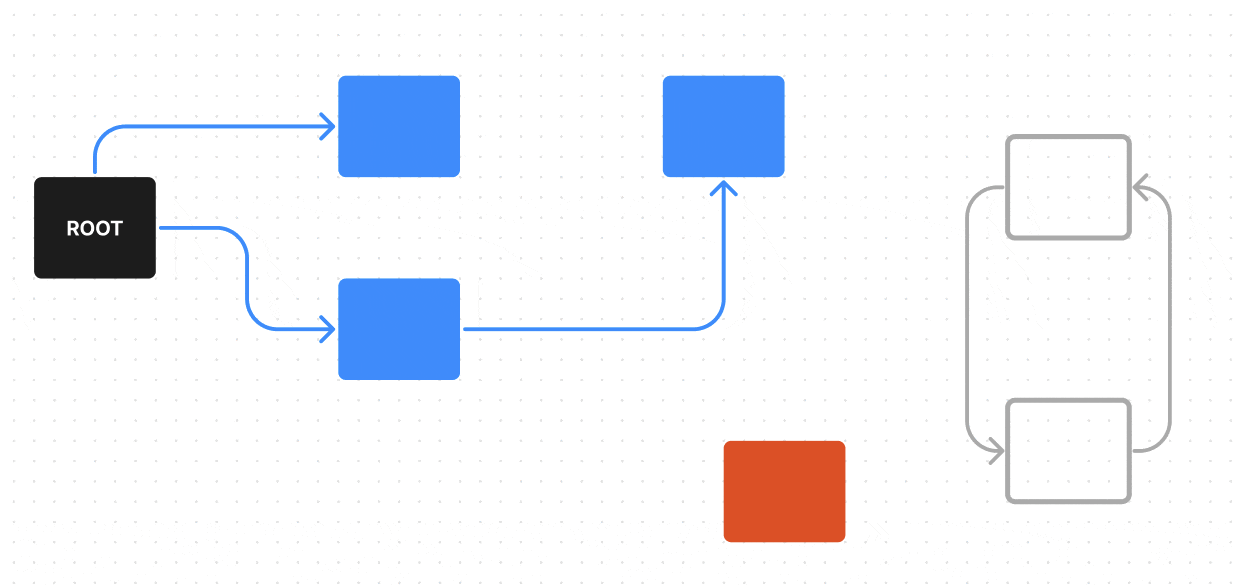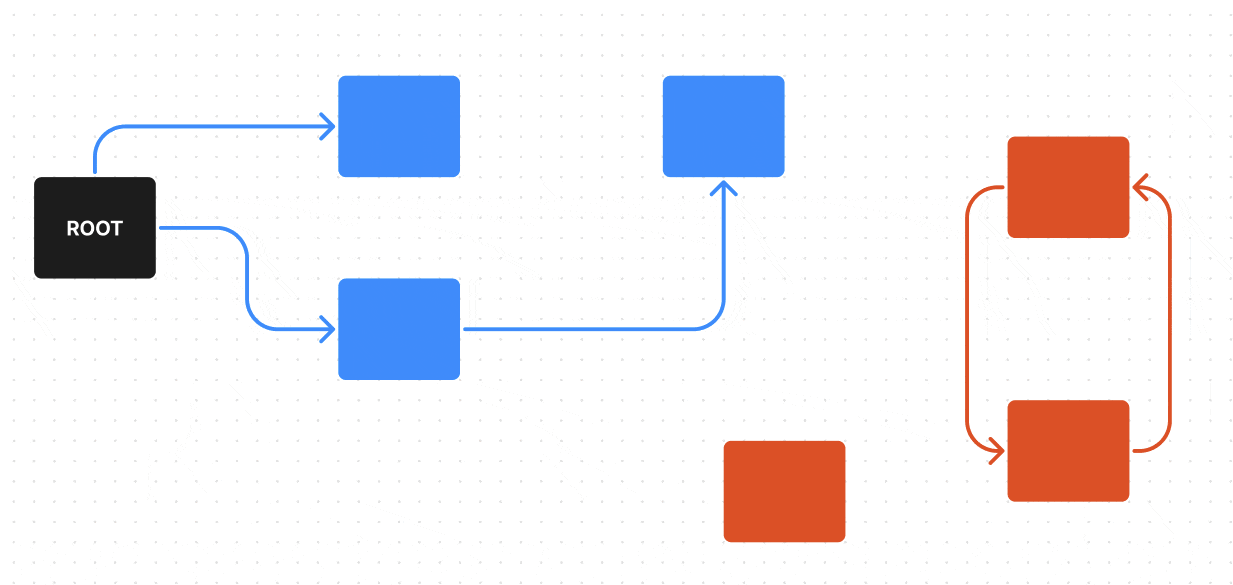
Поиск живых обьектов
Так отлично, мы поняли что такое мусор, теперь давайте разбираться как его собирать.
В V8 есть два сборщика мусора:
Minor GC (scavenge algorithm) — собирает мусор в New Space кучи.
Major GC (mark-sweep-compact algorithm) — сборщик мусора, который собирает мусор из всей кучи.
Тут напрашивается вопрос: зачем нам два сборщика, и почему мы не можем собирать одним сборщиком мусора весь мусор ?
Мы спокойно можем делать сборку одним сборщиком мусора, но разработчики нашли способ делать это эффективнее.
В терминологии сборки мусора существует понятие «Гипотеза Поколений», согласно которой большинство объектов умирают молодыми. Проще говоря, большинство объектов после выделения довольно быстро становятся мусором, а вот объекты, которые переживают несколько сборок GC, уже маловероятно будут мусором.
Именно поэтому V8 использует два сборщика мусора: один, который хорошо справляется с обработкой объектов, которые умирают молодыми, а другой хорошо подходит для сборки старых объектов.
Minor GC (Scavenge)
Этот алгоритм используется в Minor GC фазе, он работает только с New Space разделом кучи, который разделяется еще на две довольно малые области памяти From Space и To Space (в сумме ~16 МБ, как минимум так было в 2017, об этом писали разработчики в своем блоге).
Алгоритм сборки мусора в нем следующий:
Когда From Space заполняется, Minor GC начинается. Алгоритм перебирает все объекты в From Space, проверяя их на доступность.
Живые объекты, на которые ещё есть ссылки, помечаются и копируются в To Space. Объекты, на которые нет ссылок, не копируются и, таким образом, удаляются.
После того как все живые объекты перемещены из From Space в To Space, роли областей меняются. From space становится новым To Space (и очищается для последующего использования), а старый To Space становится From Space.
Так как живые объекты были перемещены, необходимо обновить все ссылки на эти объекты, чтобы они указывали на новые адреса в to space, происходит обновление ссылок.
Если объект переживает 2 Minor GC сборки, то он перемещается в Old Space и будет собираться с помощью Major GC.
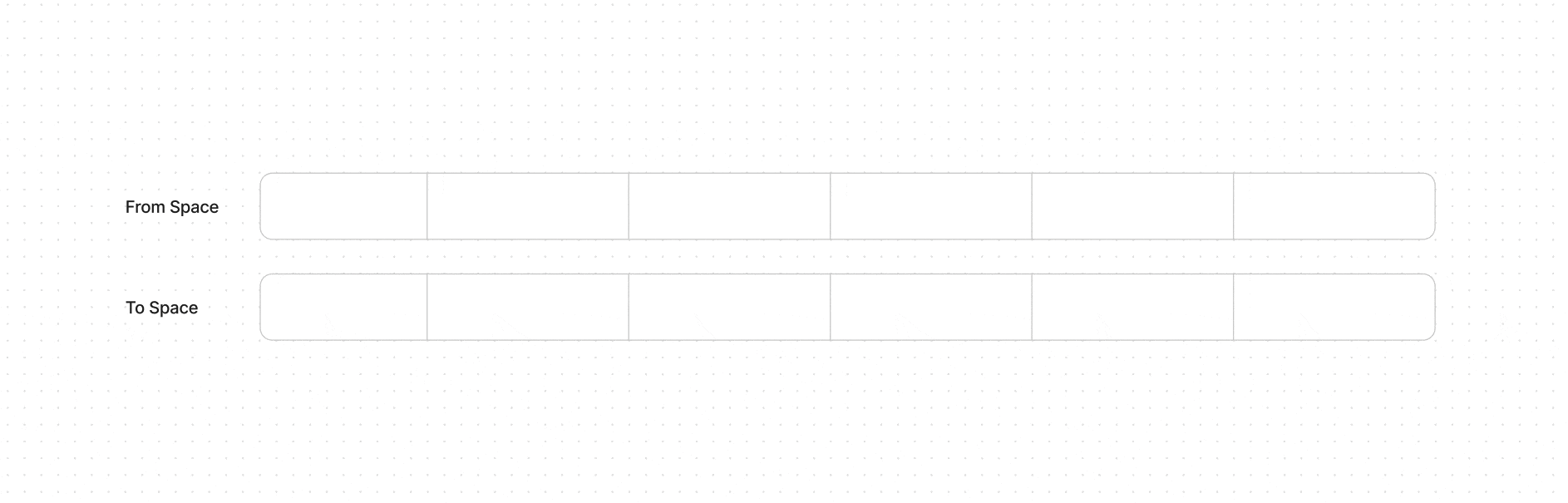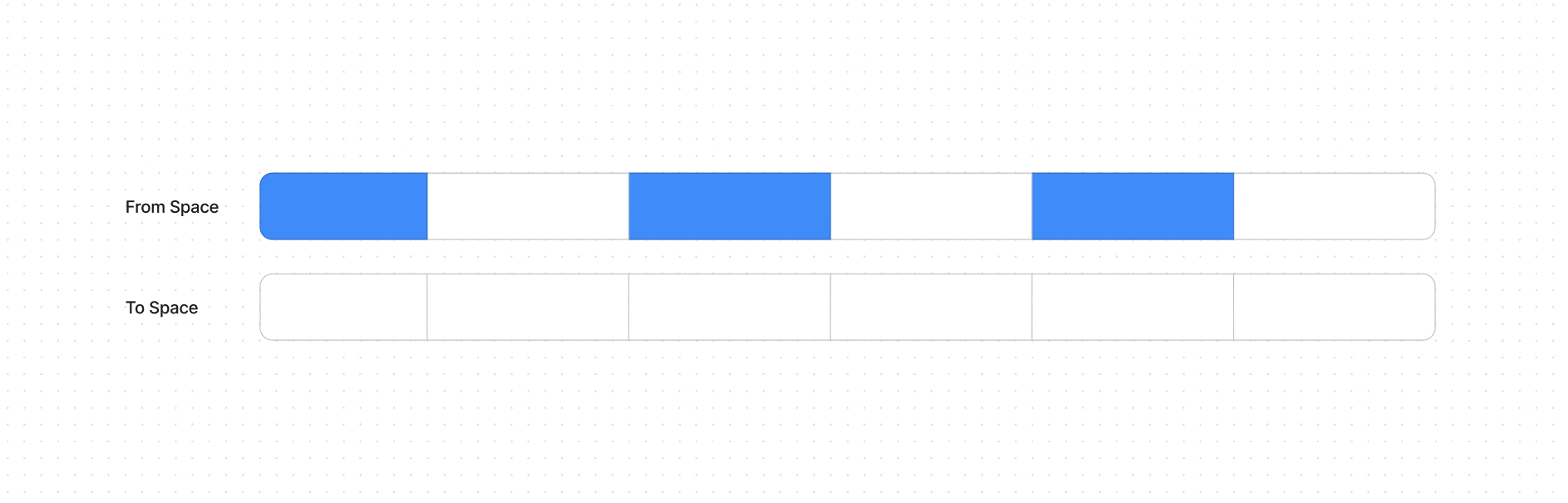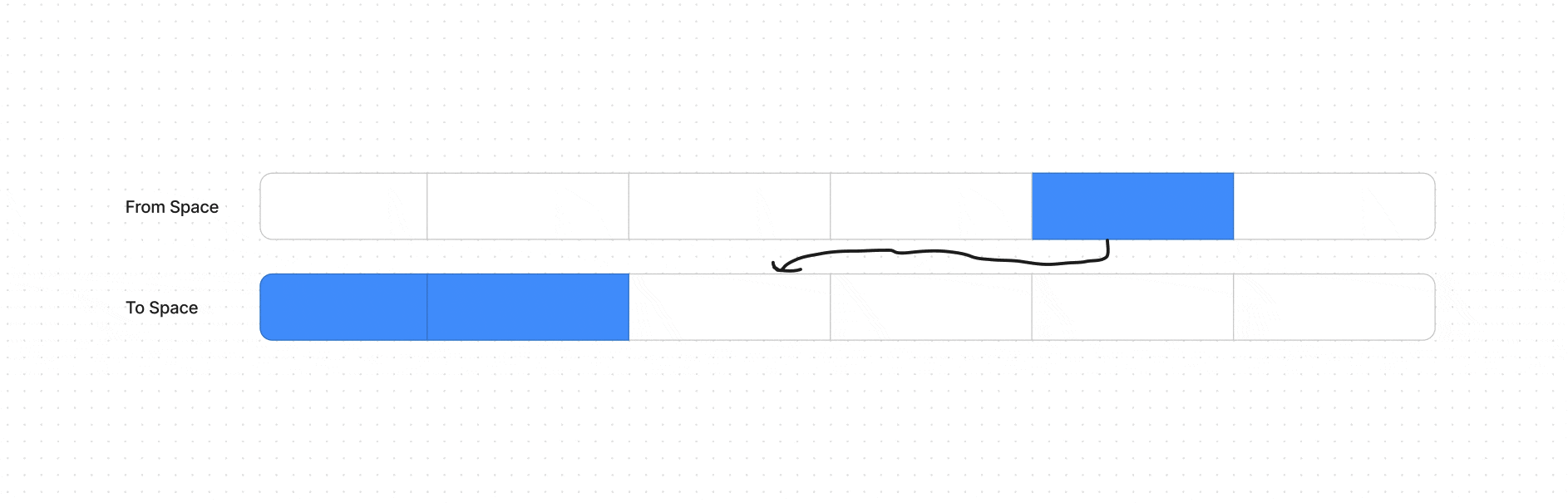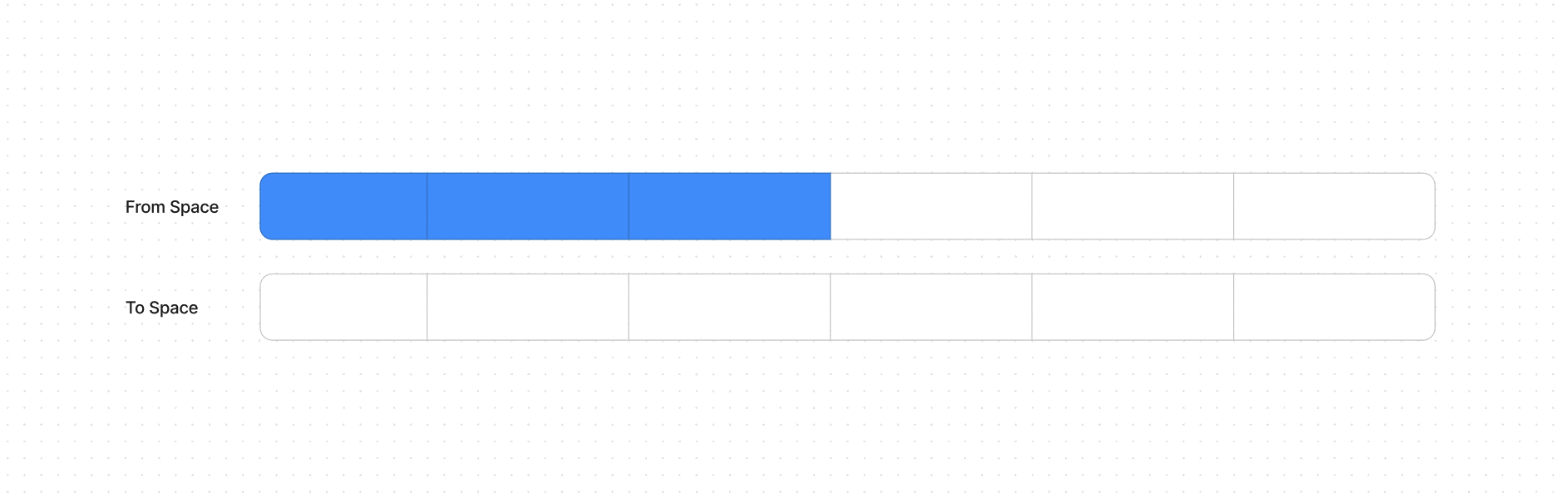
Как условно выглядит алгоритм сборки на ячейках памяти
Плюсы:
Minor GC удаляет объекты за короткий промежуток времени, что уменьшает задержки, связанные с сборкой мусора.
Алгоритм относительно простой и хорошо работает для большинства сценариев, когда много объектов быстро становятся ненужными.
При копировании память дефрагментируется.
Минусы:
Требует, чтобы половина памяти молодого поколения была выделена под To Space, что неэффективно, так как эта память большую часть времени не используется.
Процесс копирования трудозатратный по времени и по памяти.
Когда этот сборщик мусора работает ?
Параллельный подход — это когда основной поток и вспомогательные потоки выполняют примерно равный объем работы одновременно.
Плюсы такого подхода:
1.Быстрота, за счет разделения вычислений.Минусы такого подхода:
1. Это stop-the-world операция, то есть операция останавливающая основной поток.
2. Могут возникать гонки чтения/записи, нужна синхронизация операций.
Сборка мусора в New Space использует параллельный подход для распределения работы между основным и вспомогательными потоками:
Каждый поток получает множество указателей, по которым он проходится и перемещает живые объекты в To Space.
После перемещения объекта в To Space потокам необходимо синхронизироваться через атомарные read/write/compare/swap операции, чтобы избежать ситуации, когда два разных потока, пытаюсь произвести манипуляцию над одним и тем же объектом.
После синхронизации, поток, который переместил объект в To Space, потом возвращается и оставляет указатель (который указывает на область памяти в To Space), чтобы другие потоки, могли также обращаться к этому объекту по верному адресу.

Главный поток и два вспомогательных поток собирают мусор на определенных наборах указателей
Major GC
Здесь мы поговорим про Mark And Sweep и его модификацию Mark Sweep and Compact. Эти алгоритмы используются для Old Space раздела кучи, они выполняются, когда размер живых объектов в Old Space превышает эвристический предел памяти для выделенных объектов.
Mark And Sweep
Алгоритм используется как основной сборщик мусора в Old Space, в случае, если нет проблем с фрагментацией памяти.
Алгоритм выглядит следующим образом:
Сборщик мусора строит множество корневых объектов.
Фаза пометки (Mark Phase) — сборщик мусора итеративно обходит все объекты, достижимые из множества корневых объектов и помечает их (живые объекты).
Фаза очистки (Sweep Phase) — сборщик проходит по куче и удаляет все не помеченные объекты, так как они считаются недоступными и больше не нужны.
Mark and Sweep demo

Как условно выглядит алгоритм сборки на ячейках памяти
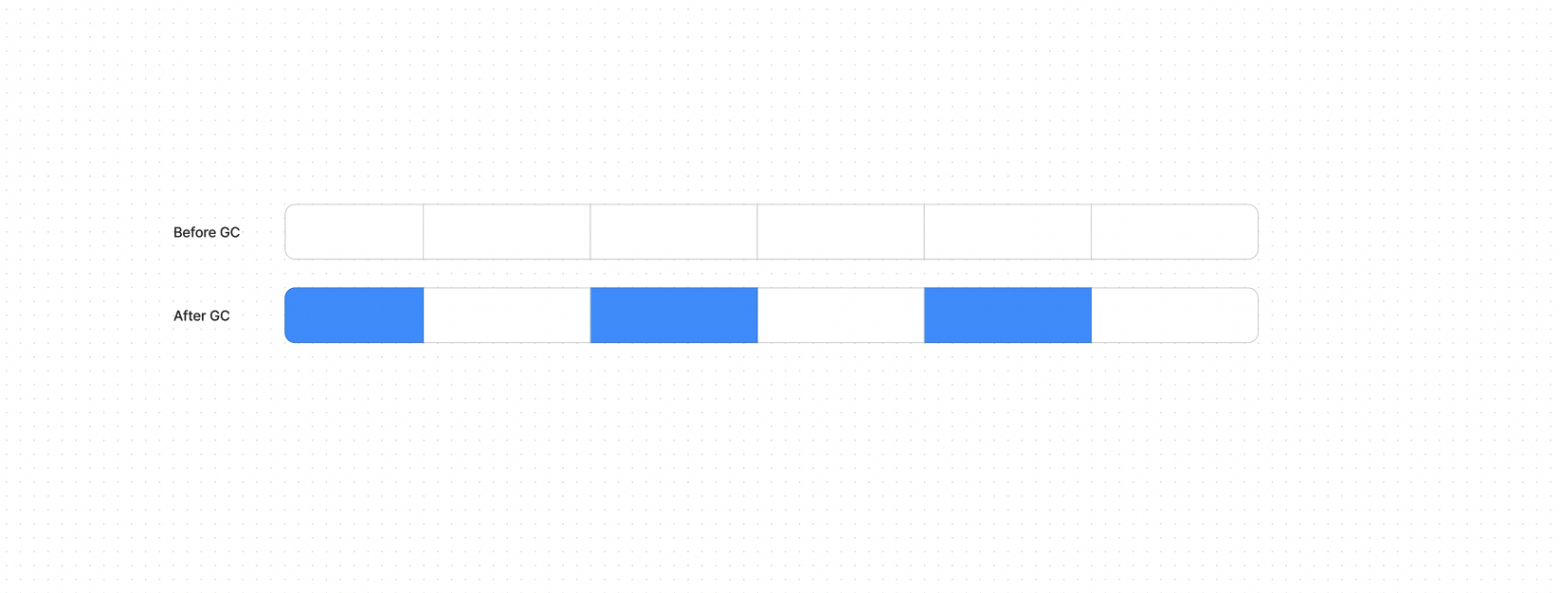
Условный рисунок памяти до (во всех ячейках были какие-то данные) и после Mark and Sweep (остались в 3)
Плюсы:
Алгоритм очень простой в реализации и в понимании.
Может собирать любые недостижимые объекты, не зависимо от того, как они связаны между собой.
Не перемещает объекты.
Минусы:
Так как объекты не перемещаются, память получается фрагментированной, из-за этого, в дальнейшем, может быть сложно выделять большие блоки памяти.
Довольно медленный, так как для поиска живых объектов и мусора, нужно обходить весь граф объектов.
Если большинство объектов не окажутся мусором, то продолжительность сборки мусора сильно увеличиться.
Mark, Sweep and Compact
Это модификация прошлого алгоритма, он применяется, если присутствует проблема фрагментации памяти. Он работает точно также, как и прошлый, только после выполнения всех этапов прошлого еще происходит уплотнение памяти.
Сборщик мусора строит множество корневых объектов.
Фаза пометки (Mark Phase) — сборщик мусора итеративно обходит все объекты, достижимые из множества корневых объектов и помечает их (живые объекты).
Фаза очистки (Sweep Phase) — сборщик проходит по куче и удаляет все не помеченные объекты, так как они считаются недоступными и больше не нужны.
Фаза уплотнения (Compact Phase) — сборщик перемещает все живые объекты в смежные участки памяти. Это решает проблему фрагментации, так как после уплотнения все свободное пространство оказывается в одном блоке, что полезно для выделения больших объектов.
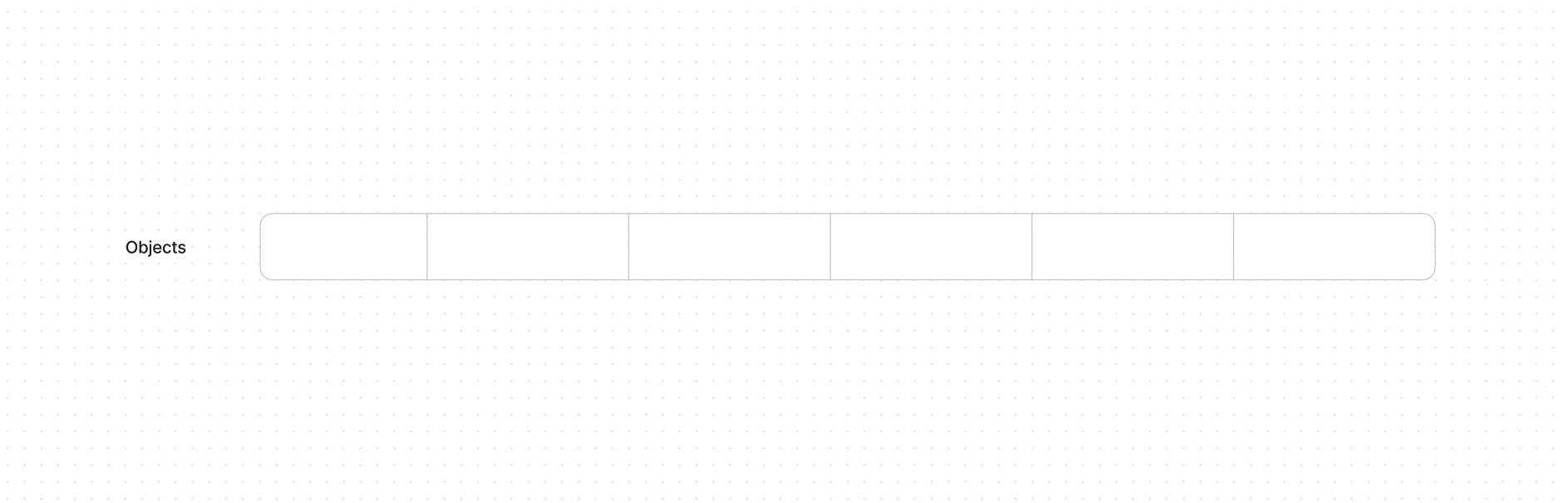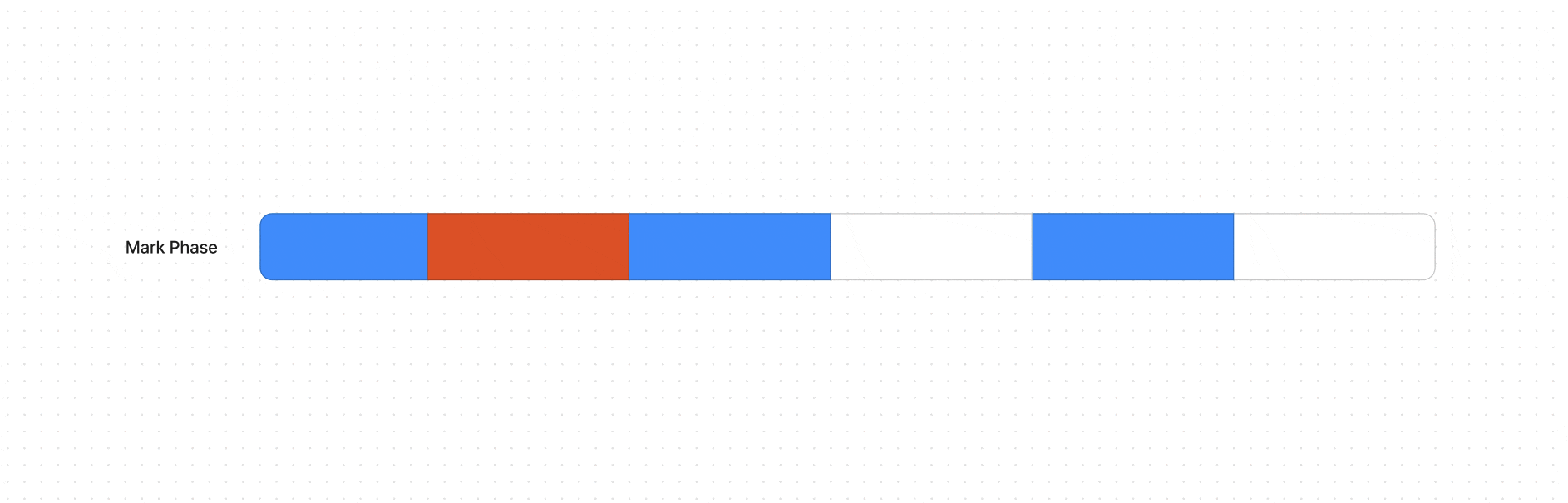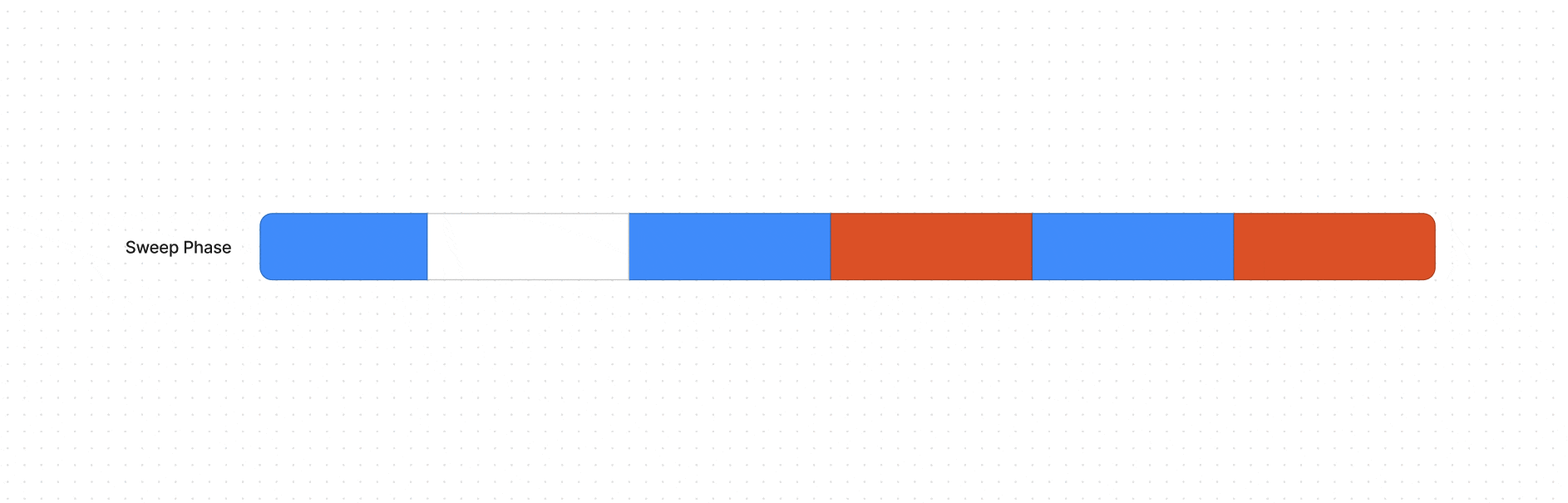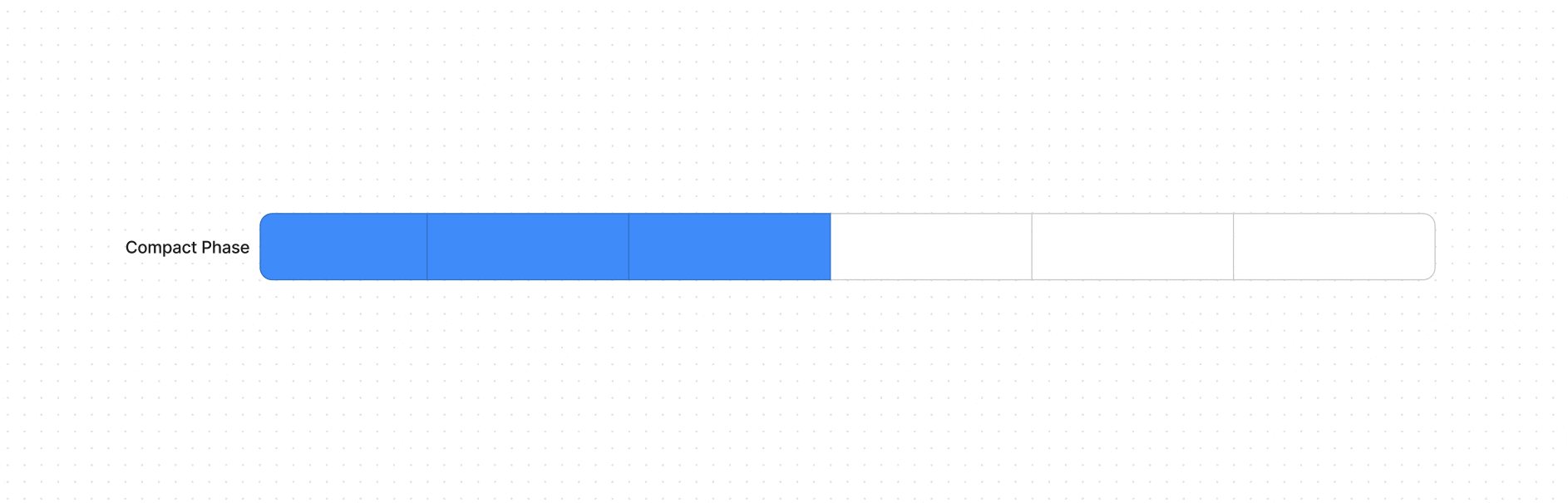
Как условно выглядит алгоритм сборки на ячейках памяти
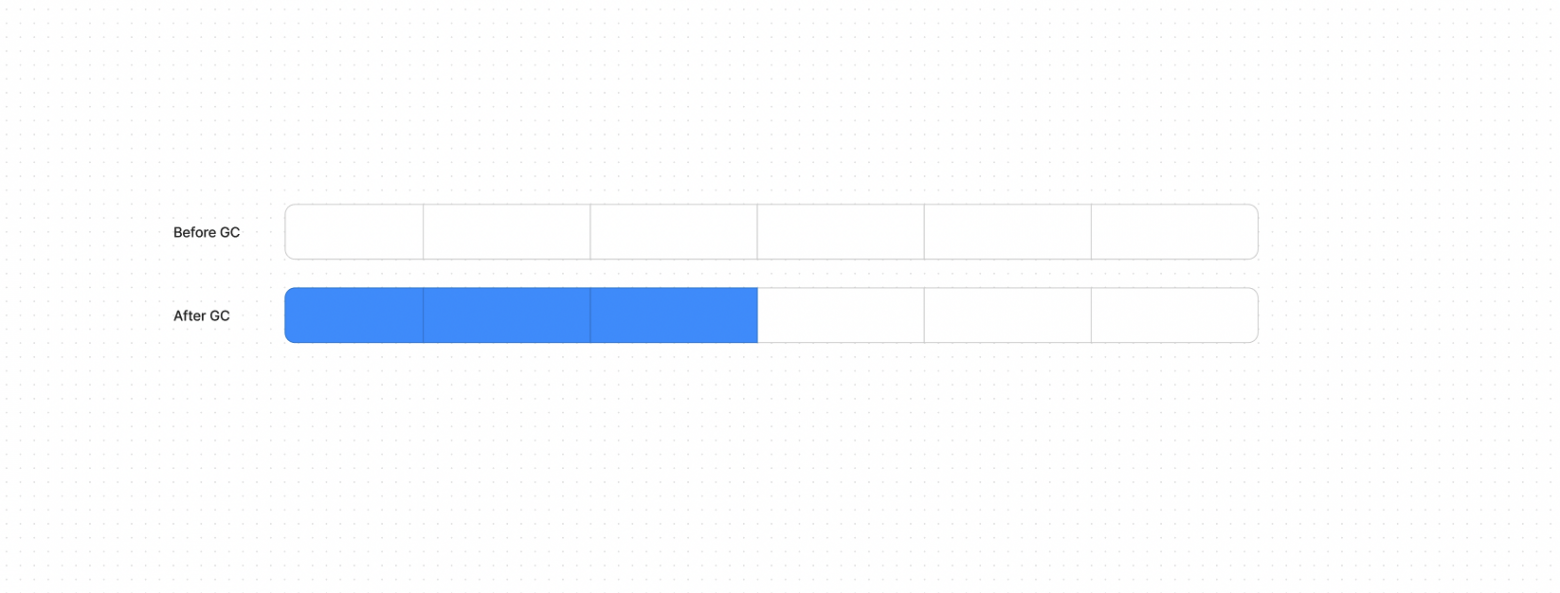
Условный рисунок памяти до (во всех ячейках были какие-то данные) и после Mark and Compact (остались в 3)
Плюсы:
Не фрагментирует память, в отличии от Mark and Sweep.
Так как память дефрагментирована, то просто выделять память для новых объектов.
Минусы:
Довольно медленный, так как для поиска живых объектов и мусора, нужно обходить весь граф объектов.
Если большинство объектов не окажутся мусором, то продолжительность сборки мусора сильно увеличиться.
Перемещает объекты, а это дорого и медленно.
Сложно реализуется, так как нужно двигать объекты, менять указатели и тд.
Когда эти сборщики мусора работают ?
Конкурентный подход — это когда основной поток может исполнять JS код, а вспомогательные потоки в это время выполняют операции полностью в фоновом режиме.
Плюсы такого подхода:
1.Основной поток не блокируется, когда выполняются операции в фоновых потоках.Минусы такого подхода:
1. Так как все это время JS код исполняется, значения в куче могут меняться, что может делать работу фоновых потоков бесполезной.
2. Могут возникать гонки чтения/записи, нужна синхронизация операций.
Когда куча приближается к эвристическому пределу памяти для выделенных объектов в Old Space, запускаются конкурентные задачи маркировки. Каждому фоновому потоку дается набор указателей, по которым он проходится и помечает живые объекты (Mark Phase), при этом основной поток продолжает выполнять JS код.
После завершения конкурентной маркировки фоновыми потоками, основной поток выполняет этап завершения маркировки. На этом этапе основной поток блокируется. Теперь потоки работают в параллельном режиме. Основной поток еще раз сканирует корневые объекты, проверяя, что все живые объекты помечены, а затем вместе с вспомогательными потоками запускает сжатие (Compact Phase) и обновление указателей, также в этот момент запускаются задачи очистки (Sweep Phase).

Mark, Sweep And Compact
Вы можете сами посмотреть, когда срабатывают и сколько занимают этапы Minor GC и Major GC, с помощью Chrome Dev Tools → Perfomance → Поставить галочку Memory (чтобы сделать снепшот памяти) → Сделать Snapshot → Найти GC в Call Tree
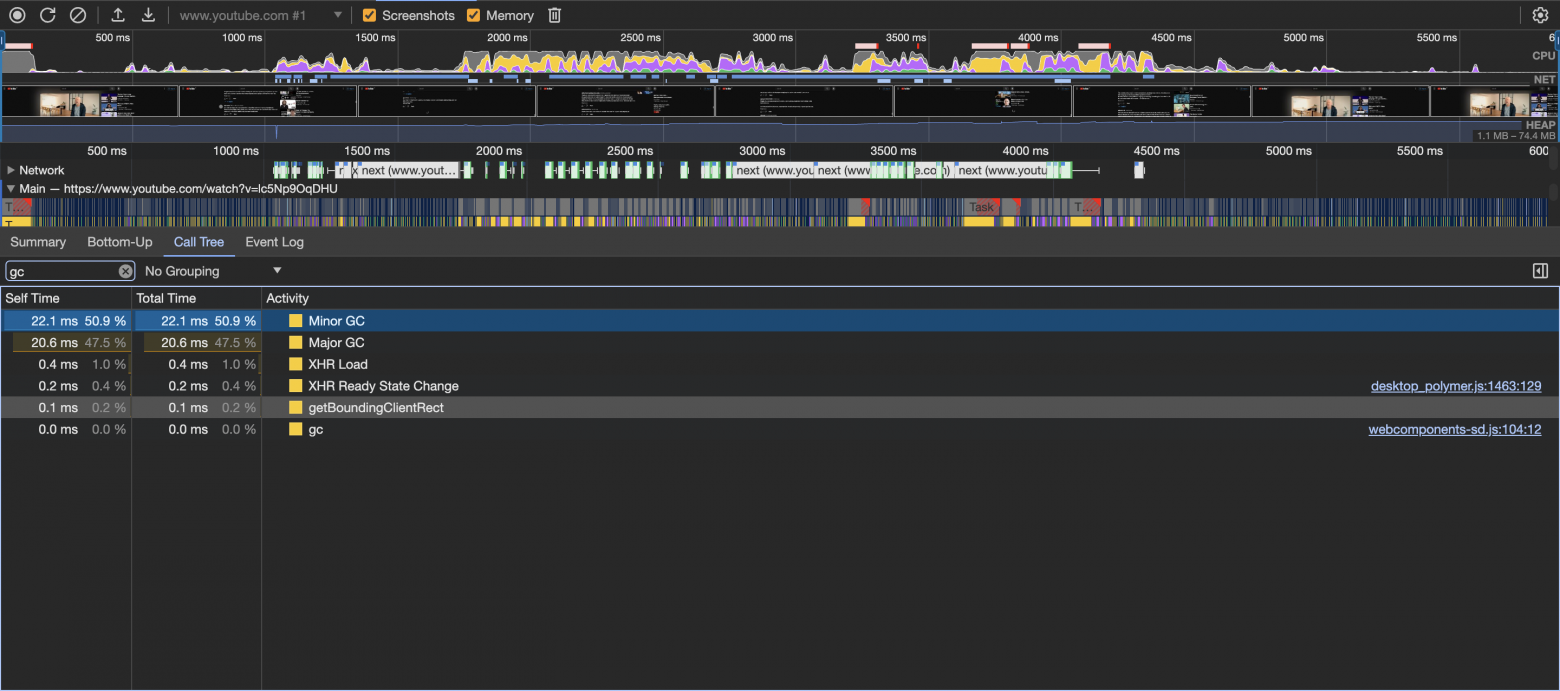
Как выглядит snapshot памяти
Итого
В этой статье мы кратко познакомились с устройством памяти в V8, поговорили о том как работает сборка поколениями, познакомились с алгоритмами сборки мусора и их особенностями, а самое главное мы стали чуть лучше понимать, как внутри устроен инструмент, которым мы пользуемся.
Если статья показалась вам интересной, то у меня есть Телеграм Канал, где я пишу про новые технологии во фронте, делюсь хорошими книжками и интересными статьями других авторов.
