Самообучающийся трекер объектов: как отслеживать цель в изменчивых условиях сцены

Специалисты по компьютерному зрению не один десяток лет бьются над трекингом объектов. Они перепробовали многое: от старой-доброй оценки движения оптическим потоком до сетей-трансформеров.
Есть один подход к трекингу, широко известный на западе, но о котором мало пишут по-русски: Incremental Visual Tracker (IVT). Это трекер объектов на основе модифицированного метода главных компонент: он самообучается на ходу и адаптируется к изменчивым условиям.
Давайте исследуем физиологию этого трекера, чем он интересен и где его можно применить -, а затем изучим проблемы его реализации и нюансы использования. Под катом ссылка на репозиторий и много математики.
Всем, кто интересуется исключительно реализацией, предъявляю C++-код. Есть также прототип на Python. Лицензии нету, делать можно что угодно.
О трекинге вкратце
Трекинг — это задача отслеживания объекта в сцене. Решается она путем предсказания местоположения объекта на последующем кадре с учетом динамики его движения. Трекинг применяется во многих задачах видеоаналитики среди которых наиболее выделяются подсчет посетителей, анализ поведения (например, животных на ферме или мышей в лабиринте), анализ траектории авто для вычисления средней скорости, отслеживание лица для определения лучшего кадра, подходящего для идентификации. Всего сценариев использования, естественно, гораздо больше.
Для интересующихся данной темой рекомендую подробную статью с примерами.
IVT трекер относится к классу так называемых appearance-based трекеров. Идея appearance-based подхода состоит в том, чтобы создать или обучить признаковое описание целевого объекта на начальном кадре и отслеживать его перемещение с помощью этого описания на последующих кадрах. Например, мы можем представить объект цветовой гистограммой и в дальнейшем искать регион с наиболее похожим цветовым распределением. Или обучить нейросеть представлять объект вектором эмбеддингов в евклидовом пространстве с тем свойством, что похожие объекты в этом пространстве будут находиться рядом, в то время как непохожие объекты далеко. Это был намек на DeepSORT. Альтернативный подход к трекингу, неформально — detection-based, не предполагает использования «внешнего вида» объекта и основывается исключительно на отслеживании его координат. Преимущество же кодирования «внешнего вида» объекта заключается в том, что эта информация вкупе с координатами объекта улучшает качество трекинга. Визуально разницу между detection-моделью и appearance-моделью можно увидеть на видео ниже.
 Видео 1. На видео слева пример работы трекера SORT: зеленая рамка соответствует детектору YOLO, который выдает сработку раз в 3 кадра, красная рамка соответствует оценке фильтром Калмана между детекциями. На правом видео пример трекера IVT: красная рамка соответствует оценке на основе appearance-модели, без всякой детекции.
Видео 1. На видео слева пример работы трекера SORT: зеленая рамка соответствует детектору YOLO, который выдает сработку раз в 3 кадра, красная рамка соответствует оценке фильтром Калмана между детекциями. На правом видео пример трекера IVT: красная рамка соответствует оценке на основе appearance-модели, без всякой детекции.
Далее мы рассмотрим все составляющие IVT трекера, сперва по отдельности, затем соединив все вместе.
Компактное представление объекта
Вместо того, чтобы работать с изображением объекта напрямую, как с набором независимых пикселей, разумнее описать его неким набором признаков, характеризующих этот объект. Так мы уменьшим размерность оставив только самую релевантную информацию об объекте. В качестве признакового описания объекта может быть использовано не только цветовое распределение, пример которого был приведен выше, но и его контур, текстура или более абстрактные признаки, такие как вектор эмбеддингов или базис главных компонент.
Мы будем представлять объект в (под)пространстве малой размерности — собственном базисе. Он же базис главных компонент, он же eigenbasis. Этот базис содержит бóльшую часть всей релевантной информации об объекте несмотря на то, что его размерность гораздо ниже исходной. Моделировать этот базис мы будем с помощью метода главных компонент (principal component analysis) используя первые  изображений объекта на
изображений объекта на  начальных кадрах.
начальных кадрах.
Кратко напомню, что суть метода главных компонент состоит в том, чтобы найти для исходных данных такую систему координатных осей (главных компонент), которая давала бы наибольшую дисперсию расстояний между проекциями на эту систему. Проецируя исходный вектор данных  на новую систему мы получаем новый вектор
на новую систему мы получаем новый вектор  , который мы можем урезать вплоть до
, который мы можем урезать вплоть до  , где
, где  оставшихся значений соответствуют осям наибольшей дисперсии.
оставшихся значений соответствуют осям наибольшей дисперсии.
На рисунках ниже приведены примеры уменьшения размерности.
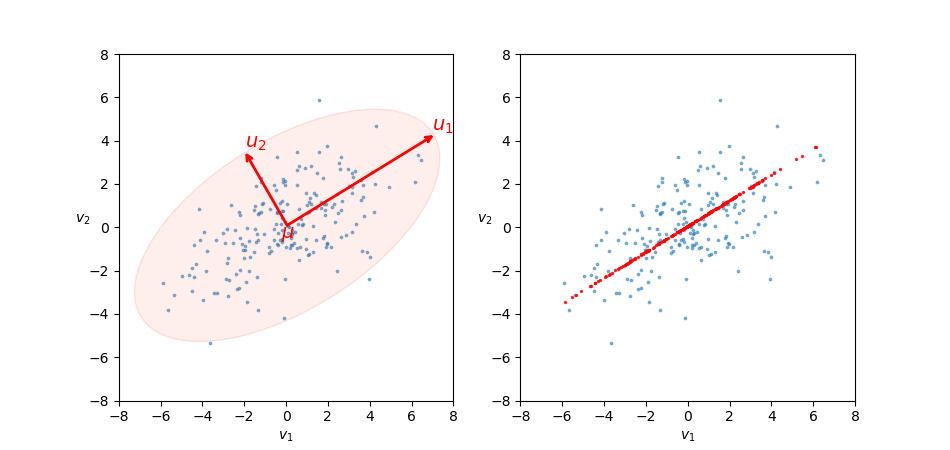 Рис. 1. Визуализация уменьшения размерности.
Рис. 1. Визуализация уменьшения размерности.
Рис. 1. Визуализация уменьшения размерности в двумерном пространстве. Исходные данные представляют собой массив векторов  , каждый из которых изображается точкой на графике с координатами
, каждый из которых изображается точкой на графике с координатами  . Рисунок слева иллюстрирует новую ортогональную систему координат
. Рисунок слева иллюстрирует новую ортогональную систему координат  с центром в
с центром в  . Рисунок справа иллюстрирует проекцию исходных данных (красные точки) на систему, состоящую только из первой главной компоненты
. Рисунок справа иллюстрирует проекцию исходных данных (красные точки) на систему, состоящую только из первой главной компоненты  . Так как разброс проекций для оси
. Так как разброс проекций для оси  заметно меньше разброса оси
заметно меньше разброса оси  , мы можем отсечь вторую ось, пожертвовать некоторой информацией, сохранив при этом основную. Таким образом проекция
, мы можем отсечь вторую ось, пожертвовать некоторой информацией, сохранив при этом основную. Таким образом проекция  представляется одним числом и мы сократили размерность с 2 до 1.
представляется одним числом и мы сократили размерность с 2 до 1.
 Рис. 2. Красивая анимация поиска оси с наибольшей дисперсией. Источник https://builtin.com/data-science/step-step-explanation-principal-component-analysis.
Рис. 2. Красивая анимация поиска оси с наибольшей дисперсией. Источник https://builtin.com/data-science/step-step-explanation-principal-component-analysis.
Весь аппарат, проиллюстрированный на рисунках 1 и 2 для двумерного случая будет также справедлив для пространства любой размерности. Так как исходными данными в нашем случае является одноканальное изображение объекта  или
или  , вырезанное из оригинального кадра, то мы будем считать, что проекция
, вырезанное из оригинального кадра, то мы будем считать, что проекция  на базис
на базис  , где
, где  , представляет собой вектор признаков
, представляет собой вектор признаков  этого объекта. В программной реализации, о которой будет рассказано ниже, будут использованы первые 16 главных компонент при исходной длине вектора 32×32=1024. Согласимся, что оперировать матрицами
этого объекта. В программной реализации, о которой будет рассказано ниже, будут использованы первые 16 главных компонент при исходной длине вектора 32×32=1024. Согласимся, что оперировать матрицами  гораздо выгоднее чем матрицами
гораздо выгоднее чем матрицами  . На рисунке ниже визуально представлены первые четыре главные компоненты для изображений велосипеда.
. На рисунке ниже визуально представлены первые четыре главные компоненты для изображений велосипеда.
 Рис. 3. Визуализация первых главных компонент для пятидесяти изображений велосипеда. Слева-направо: оригинальный кадр, среднее по последним пятидесяти кадрам, главные компоненты с первой по четвертую.
Рис. 3. Визуализация первых главных компонент для пятидесяти изображений велосипеда. Слева-направо: оригинальный кадр, среднее по последним пятидесяти кадрам, главные компоненты с первой по четвертую.
Ранее мы говорили, что appearance-based подход предполагает отслеживание объекта на последующих кадрах с помощью признакового описания объекта. Каким же образом признаковое описание в пространстве главных компонент может быть использовано нами для отслеживания объекта? Механизм для этого прост — мы должны найти участок кадра  , который лучше всего проецируется на базис
, который лучше всего проецируется на базис  . Что значит «лучше всего»?
. Что значит «лучше всего»?
Если рассматривать собственный базис через вероятностный подход, то мы можем определить вероятность того, что объект принадлежит данному базису. Эта вероятность обратно пропорциональна расстоянию от спроецированного объекта до центра базиса  . В следующих разделах будет показано, что все чуть сложнее, но для текущего пояснения этого будет достаточно. Очевидно, что объекты, принадлежащие базису будут располагаться близко к центру, в то время как иные объекты будут находиться далеко. Представьте, что на рисунке 1 мы пытаемся спроецировать точку
. В следующих разделах будет показано, что все чуть сложнее, но для текущего пояснения этого будет достаточно. Очевидно, что объекты, принадлежащие базису будут располагаться близко к центру, в то время как иные объекты будут находиться далеко. Представьте, что на рисунке 1 мы пытаемся спроецировать точку  на главную ось
на главную ось  . Понятно, что проекция будет находиться далеко от центра
. Понятно, что проекция будет находиться далеко от центра  , значит маловероятно, что точка принадлежит базису. Теперь предположим, что мы хотим найти участок кадра, в котором находится объект. Для этого я должен найти участок кадра, который лучше всего проецируется на базис объекта
, значит маловероятно, что точка принадлежит базису. Теперь предположим, что мы хотим найти участок кадра, в котором находится объект. Для этого я должен найти участок кадра, который лучше всего проецируется на базис объекта  ; иными словами, расстояние от которого до базиса
; иными словами, расстояние от которого до базиса  минимально.
минимально.
Чтобы лучше понять, как это будет выглядеть, попробуем представить проекцию на базис в качестве корреляционной функции  , принимающую на вход участок изображения, окно, фиксированного размера и возвращающую степень принадлежности этого участка базису
, принимающую на вход участок изображения, окно, фиксированного размера и возвращающую степень принадлежности этого участка базису  . Теперь заставим функцию
. Теперь заставим функцию  пробежать все изображение, сдвигая наше окно по горизонтали и вертикали. Тогда результатом работы будет новое изображение, в каждой точке
пробежать все изображение, сдвигая наше окно по горизонтали и вертикали. Тогда результатом работы будет новое изображение, в каждой точке  которого будет записано расстояние от участка с центром в
которого будет записано расстояние от участка с центром в  до базиса.
до базиса.
 Рис. 4. Слева оригинальный кадр. Справа результат прогона корреляционной функции по оригинальному кадру. Для удобства визуализации кадр нормирован от 0 до 255, где 255 — наиболее близкое к базису окно. Базис главных компонент обучен на изображениях манекена, стоящего в центре, поэтому корреляционная функция ожидаемо выдала наибольшее значение точке, в которой этот манекен находится.
Рис. 4. Слева оригинальный кадр. Справа результат прогона корреляционной функции по оригинальному кадру. Для удобства визуализации кадр нормирован от 0 до 255, где 255 — наиболее близкое к базису окно. Базис главных компонент обучен на изображениях манекена, стоящего в центре, поэтому корреляционная функция ожидаемо выдала наибольшее значение точке, в которой этот манекен находится.
Задача трекинга в общем виде сложна и подвержена многим ошибкам связанных как с факторами окружения, так и с поведением самого объекта. К первым относятся изменение освещения, движение камеры и всевозможные перекрытия цели другими объектами. Ко вторым относятся изменение позиции и очертания объекта. Для того, чтобы устранить влияние этих факторов или минимизировать их последствия наше признаковое описание (базис главных компонент) не должно быть постоянным, а должно уметь адаптироваться к изменениям. И IVT трекер умеет это делать.
 Видео 2. Левое видео: потеря трека на 275 кадре из-за константного базиса. Правое видео: успешное отслеживание авто до конца с помощью инкрементного обучения базиса.
Видео 2. Левое видео: потеря трека на 275 кадре из-за константного базиса. Правое видео: успешное отслеживание авто до конца с помощью инкрементного обучения базиса.
Трюк с адаптацией базиса является ключевой особенностью трекера, что, в свое время, позволило ему выделиться среди других трекеров. Основной вклад авторов данного трекера состоит в том, что они разработали эффективную процедуру обновления базиса главных компонент по мере накопления изменений в кадре. Эту процедуру они назвали Incremental PCA. Таким образом, вместо однократного обучения базиса в начале трекинга мы способны периодически обновлять этот базис по мере движения.
Инкрементное обучение — эффективное обновление базиса главных компонент
Здесь и в дальнейшем будут использованы только основные математические выкладки, необходимые для понимания происходящего. Все, кто интересуются теорией и доказательствами, могут ознакомиться с ними в оригинальной статье [1].
Задача обновления базиса описывается следующим образом. Дана матрица собственных векторов  и диагональная матрица собственных значений
и диагональная матрица собственных значений  , обученных на первичных изображениях объекта
, обученных на первичных изображениях объекта  . Требуется обучить новый набор
. Требуется обучить новый набор  и
и  на первичных изображениях объекта плюс новых
на первичных изображениях объекта плюс новых  входных изображениях
входных изображениях  .
.
Тривиальное решение с переобучением базиса при каждом поступлении новых данных или даже при при поступлении новых  данных выглядит неразумно, так как с увеличением количества данных растет размер выделяемой для них оперативной памяти и время вычисления.
данных выглядит неразумно, так как с увеличением количества данных растет размер выделяемой для них оперативной памяти и время вычисления.
Предлагаемый авторами метод инкрементного обучения/обновления собственного базиса, основанный на последовательном Методе Карунена-Лоэва (Sequential Karhunen-Loeve) [4], умеет обновлять базис используя только последние  наблюдений, не уничтожая влияние предыдущих наблюдений, следовательно время вычисления всегда постоянно. Сложность данного решения составляет
наблюдений, не уничтожая влияние предыдущих наблюдений, следовательно время вычисления всегда постоянно. Сложность данного решения составляет  , где
, где  — размерность входа, в то время как сложность тривиального решения составляет
— размерность входа, в то время как сложность тривиального решения составляет  . Кроме этого, авторы вводят в уравнения обновления коэффициент затухания (forgetting factor), снижающий влияние более старых данных на новый базис, уделяя больше внимания более новым данным. Полное описание алгоритма с формулами для вычисления приведено в статье. На видео 2 представлен пример обновления среднего и собственного базиса.
. Кроме этого, авторы вводят в уравнения обновления коэффициент затухания (forgetting factor), снижающий влияние более старых данных на новый базис, уделяя больше внимания более новым данным. Полное описание алгоритма с формулами для вычисления приведено в статье. На видео 2 представлен пример обновления среднего и собственного базиса.
Итак, мы поняли, что целевой объект будет представляться через базис главных компонент и что это базис будет периодически обновляться для того, чтобы адаптироваться к изменениям. Перейдем теперь к формальной постановки задачи.
Формальная постановка задачи трекинга
Мы будем рассматривать задачу трекинга в рамках стохастического марковского процесса, лежащего в основе движения объекта. Будем считать, что мы владеем априорным знанием того, где находится объект в начальном кадре. Это априорное знание можно получить с помощью нейросетевого детектора. В процессе движения мы наблюдаем данные  из которых мы можем вывести апостериорное знание о новом местоположении объекта.
из которых мы можем вывести апостериорное знание о новом местоположении объекта.
Положение объекта в момент времени  будет рассматриваться как скрытое состояние
будет рассматриваться как скрытое состояние  . Это состояние может быть задано многими способами в зависимости от фигуры объекта. Для сохранения общности будем предполагать, что объект заключен в четырехугольную рамку. Тогда состояние
. Это состояние может быть задано многими способами в зависимости от фигуры объекта. Для сохранения общности будем предполагать, что объект заключен в четырехугольную рамку. Тогда состояние  представляет собой аффинное преобразование
представляет собой аффинное преобразование  для четырехугольника, где параметры в скобках означают координаты центра рамки, угол поворота, масштаб, соотношение сторон и наклон соответственно.
для четырехугольника, где параметры в скобках означают координаты центра рамки, угол поворота, масштаб, соотношение сторон и наклон соответственно.
Наблюдаемой величиной  будет являться изображение объекта с камеры.
будет являться изображение объекта с камеры.
Графическая модель марковского процесса проиллюстрирована ниже.
 Рис. 5. Графическое представление скрытой марковской модели.
Рис. 5. Графическое представление скрытой марковской модели.
Итак, нам дано начальное положение объекта  . Мы получили наблюдение
. Мы получили наблюдение  . Требуется предсказать новое местоположение объекта
. Требуется предсказать новое местоположение объекта  в момент времени
в момент времени  . На языке теории вероятностей это выражается как
. На языке теории вероятностей это выражается как  — вероятность
— вероятность  при условии
при условии  и
и  . Применяя теорему Байеса находим
. Применяя теорему Байеса находим

Опуская лишние зависимости (пользуясь марковским свойством) и отсекая нормировочный коэффициент получаем

что искомая вероятность пропорциональна произведению двух множителей. Первый множитель это модель движения или «где будет находиться объект в момент времени  , при условии, что в момент времени
, при условии, что в момент времени  объект находился в
объект находился в  . Второй множитель это модель наблюдения или «насколько правдоподобно было бы наблюдение
. Второй множитель это модель наблюдения или «насколько правдоподобно было бы наблюдение  , если бы в момент времени
, если бы в момент времени  объект находился в
объект находился в  . В следующих разделах мы рассмотрим эти множители подробнее.
. В следующих разделах мы рассмотрим эти множители подробнее.
Теперь мы обладаем знанием о местоположении объекта в момент времени  . Сделаем один шаг вперед к
. Сделаем один шаг вперед к  и пронаблюдаем
и пронаблюдаем  . Как теперь нам найти местоположение объекта на новом шаге? На самом деле все очевидно. Вспоминаем, что для определения текущего положения нам достаточно знать предыдущее положение объекта и текущее наблюдение. Но мы уже знаем предыдущее местоположение объекта, мы вывели его на шаге
. Как теперь нам найти местоположение объекта на новом шаге? На самом деле все очевидно. Вспоминаем, что для определения текущего положения нам достаточно знать предыдущее положение объекта и текущее наблюдение. Но мы уже знаем предыдущее местоположение объекта, мы вывели его на шаге  , поэтому все, что нужно сделать, это подставить его в формулу в качестве предыдущего наблюдения, то есть
, поэтому все, что нужно сделать, это подставить его в формулу в качестве предыдущего наблюдения, то есть  .
.
Все готово к тому, чтобы записать общую рекурсивную формулу для произвольного шага 

Можно заметить, насколько элегантно в краткой формуле записывается решение нашей задачи. По сути, в выражении  содержатся (хоть и в проинтегрированном виде) все предыдущие знания о перемещении объекта (оно соответствует верхней горизонтальной стрелочке в графической модели на рисунке 5). На самом деле байесовский вывод возникает естественным образом для моделей последовательной обработки данных, каковой является и наша марковская модель, из-за способности обновлять апостериорное знание по мере поступления новой информации.
содержатся (хоть и в проинтегрированном виде) все предыдущие знания о перемещении объекта (оно соответствует верхней горизонтальной стрелочке в графической модели на рисунке 5). На самом деле байесовский вывод возникает естественным образом для моделей последовательной обработки данных, каковой является и наша марковская модель, из-за способности обновлять апостериорное знание по мере поступления новой информации.
Модель движения (dynamical model)
 Источник http://www.anuncommonlab.com/articles/how-kalman-filters-work/.
Источник http://www.anuncommonlab.com/articles/how-kalman-filters-work/.
Модель движения задает закон, которому подчиняется движение объекта, то есть переход  от состояния
от состояния  к состоянию
к состоянию  . Он определяется заранее на основе неких теоретических сведений об объекте. Это может быть, например, линейная модель или дифференциальное уравнение произвольного порядка. Так как в этой статье мы рассматриваем отслеживание произвольного объекта, динамика которого нам неизвестна, то в качестве модели движения мы возьмем случайное перемещение объекта в любом из направлений — Броуновское движение. Мы можем записать это движение в виде многомерного нормального распределения
. Он определяется заранее на основе неких теоретических сведений об объекте. Это может быть, например, линейная модель или дифференциальное уравнение произвольного порядка. Так как в этой статье мы рассматриваем отслеживание произвольного объекта, динамика которого нам неизвестна, то в качестве модели движения мы возьмем случайное перемещение объекта в любом из направлений — Броуновское движение. Мы можем записать это движение в виде многомерного нормального распределения  , где
, где  — диагональная ковариационная матрица, каждый элемент которой на главной диагонали равен дисперсии одного из параметров, то есть
— диагональная ковариационная матрица, каждый элемент которой на главной диагонали равен дисперсии одного из параметров, то есть  . Иными словами, каждый параметр
. Иными словами, каждый параметр  распределен нормально вокруг своего центра
распределен нормально вокруг своего центра  (предыдущего параметра) со среднеквадратичным отклонением
(предыдущего параметра) со среднеквадратичным отклонением  .
.
Геометрически, переход от предыдущего состояния в следующий будет образовывать облако четырехугольников вокруг предыдущего состояния. Новое местоположение объекта, согласно нашей модели, должно оказаться в одном из четырехугольников. В каком именно — решит модель наблюдения.
 Рис. 6. Разброс состояний вокруг предыдущего состояния (красный прямоугольник). Каждый синий четырехугольник это гипотеза о местонахождении объекта.
Рис. 6. Разброс состояний вокруг предыдущего состояния (красный прямоугольник). Каждый синий четырехугольник это гипотеза о местонахождении объекта.
Модель наблюдения (observation model)
Каждое новое наблюдение  вносит некую информацию, на основе которой мы можем делать вывод о местонахождении объекта. Для того, чтобы включить эту информацию в модель мы должны задать связь между наблюдением и состоянием
вносит некую информацию, на основе которой мы можем делать вывод о местонахождении объекта. Для того, чтобы включить эту информацию в модель мы должны задать связь между наблюдением и состоянием  . Это и есть модель наблюдения. В байесовской интерпретации модель наблюдения задается распределением
. Это и есть модель наблюдения. В байесовской интерпретации модель наблюдения задается распределением  — правдоподобием того, что находясь в позиции
— правдоподобием того, что находясь в позиции  , мы пронаблюдаем
, мы пронаблюдаем  . Так как для наблюдаемого объекта мы моделируем базис
. Так как для наблюдаемого объекта мы моделируем базис  с центром
с центром  , то мы предполагаем, что наблюдение
, то мы предполагаем, что наблюдение  получено из этого базиса. В этом случае распределение
получено из этого базиса. В этом случае распределение  имеет следующий смысл: насколько вероятно получить
имеет следующий смысл: насколько вероятно получить  из пространства
из пространства  нашего объекта. Эта вероятность обратно пропорциональна расстоянию
нашего объекта. Эта вероятность обратно пропорциональна расстоянию  от наблюдения
от наблюдения  до центра
до центра  . Это расстояние можно разложить на два: расстояние
. Это расстояние можно разложить на два: расстояние  от наблюдения
от наблюдения  до пространства и расстояние
до пространства и расстояние  внутри самого пространства от спроецированного
внутри самого пространства от спроецированного  до центра. Но для наших целей достаточно будет посчитать только расстояние, пропорциональное
до центра. Но для наших целей достаточно будет посчитать только расстояние, пропорциональное  :
:

В этом выражении  есть просто исходное изображение объекта за вычетом среднего. Слагаемое
есть просто исходное изображение объекта за вычетом среднего. Слагаемое  есть реконструкция исходного изображения, то есть проекция изображения на базис и обратно. Визуально посмотреть на что похожа реконструкция можно на рисунке 4 в рамке под названием recon. Видно, что исходное изображение несколько искажено, из-за потери некоторой составляющей при проецировании, но основной образ сохранен. Тогда разность
есть реконструкция исходного изображения, то есть проекция изображения на базис и обратно. Визуально посмотреть на что похожа реконструкция можно на рисунке 4 в рамке под названием recon. Видно, что исходное изображение несколько искажено, из-за потери некоторой составляющей при проецировании, но основной образ сохранен. Тогда разность  , называемая также вектором невязки, есть просто разница между исходным изображением и его реконструкцией, а
, называемая также вектором невязки, есть просто разница между исходным изображением и его реконструкцией, а  -норма вектора невязки выражает количество информации, которую мы не можем восстановить. Ясно, что чем больше расстояние
-норма вектора невязки выражает количество информации, которую мы не можем восстановить. Ясно, что чем больше расстояние  , тем ниже вероятность
, тем ниже вероятность  и тем хуже будет качество восстановленного изображения.
и тем хуже будет качество восстановленного изображения.
Наглядно расстояния  и
и  изображены на рисунке ниже.
изображены на рисунке ниже.
 Рис. 7. Расстояния до базиса и внутри базиса.
Рис. 7. Расстояния до базиса и внутри базиса.
Рис. 7. Расстояние, пропорциональное  . Для наглядности базис главных компонент
. Для наглядности базис главных компонент  представлен на плоскости. Мысленно расширяем базис до
представлен на плоскости. Мысленно расширяем базис до  .
.
Полезной находкой авторов оказалось использование робастной функции  вместо
вместо  -нормы
-нормы  для минимизации влияния шумовых пикселей на оценку вероятности
для минимизации влияния шумовых пикселей на оценку вероятности  . Действительно, если целевой объект имеет круглую форму и, при этом, заключен в прямоугольную рамку, то краевые пиксели внутри рамки, выходящие за периметр круга, будут явно помехой. Смысл параметра
. Действительно, если целевой объект имеет круглую форму и, при этом, заключен в прямоугольную рамку, то краевые пиксели внутри рамки, выходящие за периметр круга, будут явно помехой. Смысл параметра  в том, что он задает критическую область, после которой влияние шумов на модель наблюдения начинает уменьшаться [2].
в том, что он задает критическую область, после которой влияние шумов на модель наблюдения начинает уменьшаться [2].
Сэмплирование — как вычислить произвольное распределение
Единственное, на чем мы пока не заостряли внимания, это на том, какую форму должно иметь распределение  . Поначалу это распределение приближали обычным гауссианом предполагая, что существует только одна наиболее вероятная точка, в которой должен находиться объект. Предсказание местоположения таким образом сводилось к оценке параметров движения фильтром Калмана. Однако, несмотря на то, что это удобное средство моделирования, на практике оно не всегда адекватно описывает процесс. Из-за наличия сложного фона и непредсказуемой динамики движения объекта было бы правильнее выдвигать сразу несколько гипотез о том, где может находиться объект и принимать наиболее вероятную из них. Поэтому мы будем считать, что распределение
. Поначалу это распределение приближали обычным гауссианом предполагая, что существует только одна наиболее вероятная точка, в которой должен находиться объект. Предсказание местоположения таким образом сводилось к оценке параметров движения фильтром Калмана. Однако, несмотря на то, что это удобное средство моделирования, на практике оно не всегда адекватно описывает процесс. Из-за наличия сложного фона и непредсказуемой динамики движения объекта было бы правильнее выдвигать сразу несколько гипотез о том, где может находиться объект и принимать наиболее вероятную из них. Поэтому мы будем считать, что распределение  имеет несколько вершин.
имеет несколько вершин.
 Рис. 8. Апостериорное распространение для x-координаты по дискретным отсчетам t. Видно, что в начале модель уверена в положении объекта (лицо человека в красной рамке), но по мере движения начинают образовываться несколько гипотез. Например, на отметке t=20 на левом графике видно три вершины. Самая левая вершина соответствует цели, вершина посередине соответствует похожему человеку справа от цели и правая вершина соответствует человеку в синей жилетке справа. Так как человек справа находится далеко от цели, то модель справедливо дает ему наименьший вес полагая, что цель не сможет так резко сдвинуться вправо.
Рис. 8. Апостериорное распространение для x-координаты по дискретным отсчетам t. Видно, что в начале модель уверена в положении объекта (лицо человека в красной рамке), но по мере движения начинают образовываться несколько гипотез. Например, на отметке t=20 на левом графике видно три вершины. Самая левая вершина соответствует цели, вершина посередине соответствует похожему человеку справа от цели и правая вершина соответствует человеку в синей жилетке справа. Так как человек справа находится далеко от цели, то модель справедливо дает ему наименьший вес полагая, что цель не сможет так резко сдвинуться вправо.
Поскольку теперь распределение  имеет произвольную форму, отличную от гауссиана, мы теряем возможность вычислить его аналитически. Поэтому мы применим технику фильтра частиц (particle filter), позволяющую оценить параметры искомого произвольного распределения. Можно считать, что это обобщение фильтра Калмана на случай негауссовских процессов. Под частицей понимается элемент
имеет произвольную форму, отличную от гауссиана, мы теряем возможность вычислить его аналитически. Поэтому мы применим технику фильтра частиц (particle filter), позволяющую оценить параметры искомого произвольного распределения. Можно считать, что это обобщение фильтра Калмана на случай негауссовских процессов. Под частицей понимается элемент  из выборочной совокупности
из выборочной совокупности  распределения
распределения  с весом, пропорциональным вероятности получить эту частицу из распределения. На рисунке 8 частицей является каждая темно-синяя точка на левом графике. Если устремить количество частиц в бесконечность, то «рваный» график будет становиться более гладким, а в пределе станет непрерывным. Заметно, что частица с наибольшим весом соответствует наиболее вероятному местоположению объекта. Для генерации и распространения частиц во времени мы воспользуемся алгоритмом сэмплирования CONDENSATION [3].
с весом, пропорциональным вероятности получить эту частицу из распределения. На рисунке 8 частицей является каждая темно-синяя точка на левом графике. Если устремить количество частиц в бесконечность, то «рваный» график будет становиться более гладким, а в пределе станет непрерывным. Заметно, что частица с наибольшим весом соответствует наиболее вероятному местоположению объекта. Для генерации и распространения частиц во времени мы воспользуемся алгоритмом сэмплирования CONDENSATION [3].
Алгоритм CONDENSATION использует технику сэмплирования с учетом динамики движения объекта для генерации выборки из  частиц подчиняемых распределению
частиц подчиняемых распределению  . Данный алгоритм итеративный. Это значит, что получив выборку из апостериорного распределения
. Данный алгоритм итеративный. Это значит, что получив выборку из апостериорного распределения  мы можем распространить эту выборку для вычисления нового апостериорного распределения на следующем шаге
мы можем распространить эту выборку для вычисления нового апостериорного распределения на следующем шаге  используя предыдущее распределение в качестве априорного. Этап распространения при этом переживают только частицы с наибольшим весом, в то время как маловероятные частицы отсеиваются. Вычислительная сложность алгоритма оценивается как
используя предыдущее распределение в качестве априорного. Этап распространения при этом переживают только частицы с наибольшим весом, в то время как маловероятные частицы отсеиваются. Вычислительная сложность алгоритма оценивается как  .
.
Упрощенно, схему CONDENSATION можно представить в следующем виде:
Генерируем случайную выборку
 из распределения
из распределения  .
.Каждому элементу выборки присваиваем вес
 , равный
, равный  .
.Нормализу
