Самодельный стратостат. Сезон 2022. Vostok-5

Вот мы и вернулись! С «небольшим» опозданием, но нам есть чем оправдаться ;) В прошлом году мы строили и запускали самодельные стратостаты с целью привезти видео в 4k с высоты 30+ километров. В этом году мы, наконец-то, достигли всех поставленных целей и привезли бескомпромисный результат. Получилось опять «длинно», но я сокращал как мог. Будет много фоток, пару видео и даже гифки.
Вступление
Так как я считаю, что «просветительскую» часть миссии мы закрыли в прошлом сезоне, опубликовав, фактически, пошаговую инструкцию по созданию таких зондов из ничего, то теперь я буду опускать большинство деталей. Это позволит не раздувать и без того не маленький текст, и сосредоточиться на более веселом — на видосах :) Тем более что теперь там точно есть на что посмотреть. Чуть подробней чем «никак» я опишу лишь критически важные для миссии места.
Если появятся вопросы, даже если ответы на них есть в других статьях (смотрите у меня в профиле) — задавайте в коментариях. Я отвечаю на все и всё что знаю. Начнём.
Список оборудования и компонентов
Буду краток:
Всё остальное — без изменений. Тот же RPI 4b с SenseHAT и GPS HAT, SPOT Trace (почему снова он — объясню ниже) и павербанки что и в прошлый раз. Теперь о каждом новом пункте немного подробней.
Трекер
Как вы могли заметить по списку оборудования, у нас кое-что добавилось в полезной нагрузке. А именно новый, автономный поисковый трекер! Это очень важный момент, на котором хотелось бы заострить внимание, так как это может быть полезно для ваших запусков (в своей первой статье про Самодельный стратостат я объяснил важность этого компонента).
Итак, наш любимый SPOT Trace, служивший нам верой и правдой весь прошлый сезон, начал немного хворать. Нет, он продолжал присылать координаты, но делать это стал как-то неуверенно и недолго. Батареи садились примерно за неделю (да, мы их меняли и не раз — не помогло). Это всё еще очень хороший показатель автономности и новый трекер его не перебивает. Но… захотелось подстраховаться. Таким образом мы выторговали на просторах интернета б\у трекер отечественного бренда — «Азимут IRIDIUM/GSM».
Мы купили у официального поставщика именно б\у трекер, списанный и снятый с какого-то самолета. Он нам обошелся в 32500 рублей.
Он имеет на борту 2 канала связи для передачи координат: спутниковую сеть IRIDIUM и мобильную сеть GSM. GSM используется когда доступна, в противном случае переходит на спутник. Такое поведение нам очень нравится.
Проблема этого трекера в малой автономности. Заряда встроенного аккумулятора, согласно официальной инструкции, хватает на «десятки часов». Вроде достаточно, но сильно меньше чем у SPOT. С другой стороны, этот недостаток покрывается лучшим охватом и более уверенной связью IRIDIUM. Напомню, что автономность SPOT нас спасала в условиях плохого сигнала (использует спутниковую инфраструктуру Globalstar), когда трекер молчал несколько дней и только потом прорезался сигнал. Что ж, если с сетью все ок, то «десятков часов» нам хватает с запасом.
Тем не менее в этот запуск мы решили не рисковать настолько и положили в коробку оба трекера ¯\_(ツ)/¯
Фото этого чуда и его комплектация: 

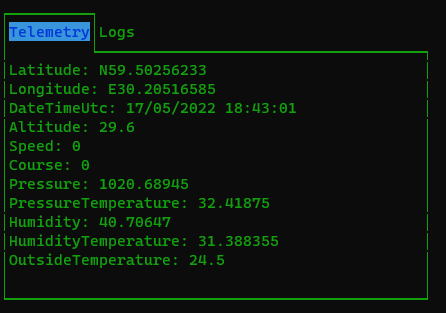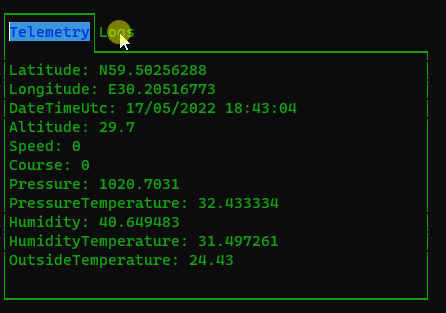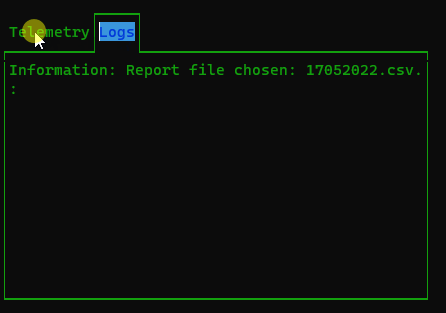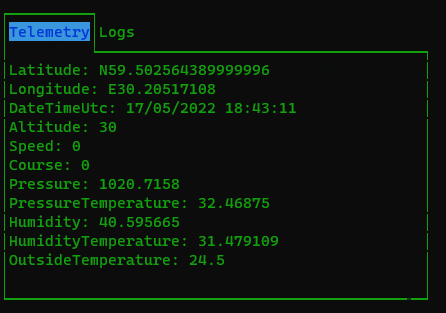
Следить за его положением вы можете на сайте flyrf.ru. Вверху надо включить отображение АОН/БАС и в поиске ввести наш ID: VSTK0160
Должны увидеть что-то вроде:
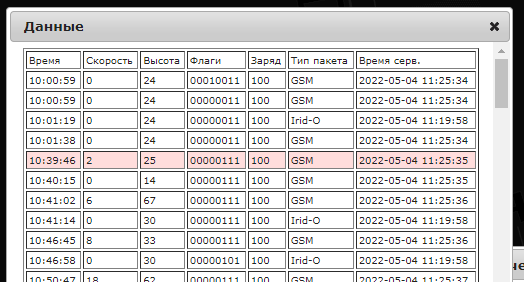
В истории видно, каким каналом был отправлен трек (поле: Тип пакета):
Ну, а дальше разберетесь по кнопкам.
Небольшое отступление про возможности конфигурации этого устройства. Механика схожа со SPOT Trace: есть десктопная программа, ставите, конфигурируете. Это приложение предоставляет поставщик трекера, через него же (поставщика) идет оплата подписки. Напрямую Iridium (именно их сеть используется как канал передачи данных) платить нельзя — только через посредников (и это не нововведение — это всегда так было, насколько я знаю). На странице поставщика есть тарифная сетка. В опции конфигурации углубляться не буду, иначе этот текст никогда не закончится. Скажу лишь, что мы поставили интервал треков в 300 сек в состоянии движения и 3600 сек в покое. С целью экономии батареи.
Таким образом, у нас на борту появилось уже 3 приемника и 2 передатчика координат. Интерференция может насоздавать проблем в таком случае. В документации SPOT есть рекомендация: располагать трекер не ближе 30 см от других приёмопередатчиков. Легко сказать, но как это сделать в малюсенькой коробке зонда?
Никак.
Можно конечно поиграться с проводами/выносными мачтами, привязать трекер к стропам/фалу и т.д., но не забываем про температуру и как к ней относятся элементы питания! Есть риск, что снаружи аккумуляторы замерзнут еще на подъеме. Да, они потом отмерзнут и возможно включатся снова. Возможно. Ситуация спорная, так что мы решили тупо протестить — включали трекеры рядом друг с другом, носили их по городу в одной сумке и т.п. Результаты нам понравились — оба трекера работали как обычно. Так что было принято решение все же разместить их внутри короба и обеспечить штатным обогревом.
Вот, как они расположились внутри короба:

Камера
Второе важное изменение — мы поменяли камеру. Прошлая GoPro 7 Black нас устраивала всем, кроме угла обзора. Очень хотелось посмотреть еще и на шар в полете. Мы даже разрабатывали вариант с 2-я камерами — одна на шар, вторая на горизонт. Но 2 камеры это двойной вес и двойное питание (что опять же — новая масса). Так что мы решили проблему кардинально — приобрели камеру с обзором 360 градусов! А конкретно Insta360 One X2. Да-да, теперь наши видосы можно смотреть в VR очках. Даже в таких картонных, я лично в таких и смотрю :) Эффект погружения — присутствует.
Теперь эту камеру надо как-то разместить на коробе. Так, чтобы не потерять в полете, чтобы она не перегрелась и чтобы ничто не мешало обзору.
Родился такой план:

Основание немного утоплено в пенопласт (из-за этого пришлось наложить второй слой крышки — чтобы не нарушать термоизоляцию внутренностей) и зафиксировано термоклеем. Основное пятно нагрева у этой камеры в зоне объективов, так что не перегреется. Прямой вид на горизонт, а так же на следующее дополнение нашей конструкции.
Дисплей
Здесь я, в основном, затрону «железную» часть вопроса и зачем нам вообще понадобился дисплей.
Итак, если вы помните, в прошлом сезоне у нас было 2 источника телеметрии: RPI с GPS HAT + набор сенсоров и GoPro 7. Данные с GoPro позволяли нам легко синхронизировать видео с показаниями RPI (чтобы сделать наложение телеметрии на видео). Это было нам необходимо, так как камера не обладает всеми необходимыми нам датчиками (температур, давления и т.п.). В новой камере такой роскоши нет. Чтобы иметь в метаданных видео показания GPS — нужно использовать специальный отдельный модуль для этой камеры (ну и купить его, соответственно). Питание для этого модуля тоже нужно отдельное. Мда, тут на славу потрудился маркетолог. Нуштош…
Можно было пойти и по пути покупки этого модуля, но мы решили сделать чуть более надежно (и более популярно в среде запускателей подобных зондов) — добавить в кадр показания самого RPI (тем более что этот GPS Smart Remote для камеры имеет всем хорошо знакомое ограничение в 10 км по высоте). Это все так же дополнительная масса и увеличенное энергопотребление, но добавлять новых батарей нам не потребовалось — питания подсистемы телеметрии хватало с запасом и на дисплей.
Плюсом мы исключали полностью необходимость синхронизации телеметрии и видео. А обзор камеры позволял внедрить следующий сценарий использования: в нужный момент останавливаем видео при просмотре и поворачиваем обзор на дисплей. С прошлой камерой такого бы «не прокатило».
Вот этот дисплей мы выбрали. Не очень большой, не очень маленький, с хорошей яркостью (как я тогда думал, но об этом посмотрите видео), подключается к порту DSI, не требует внешнего питания и есть тач. Зачем тач и почему он не пригодился, я расскажу в разделе про программирование.
Забавный момент: в комплекте идет шлейф длиной 5 см для подключения к RPI. При нашей компоновке этого маловато и мы решили купить что-то длиннее. Забавно тут то, что во всей стране именно эти 15pin FFC шлейфы занесены в красную книгу. Мы с большим трудом нашли последние 10 штук на складе одного магазина и забрали сразу все (цена за штуку там была что-то около 32р). Альтернатива — заказ из Китая. Там они есть, но долго ждать. В итоге у нас появилось десять 15-сантиметровых шлейфов. Должно хватить.
Корпус для него распечатали на 3D-принтере. Я до сих пор не уверен — было ли это хорошее решение, но наш конструктор настоял (основание — возможно долгое пребывание в неблагоприятной среде), а я не возразил. Как по мне, так можно было просто залить там все герметиком, ну да ладно.
Больше изменений «внутри» нет. Посмотрим, что поменялось снаружи.
Общая конструкция
Основное отличие — мы заменили гелий на водород. Да, нас несколько раз убеждали, что это — ключ к успеху, хоть и не очень ясно к какому. Но кто мы такие, чтобы отказываться? Когда мне говорят что-то в интернете — я верю!
Из плюсов водорода перед гелием:
- он в 3 раза дешевле
- его надо в 2 раза меньше (мы закачали половину стандартного 40л баллона)
Из минусов:
- всем пришлось бросить курить
- его нельзя перевозить в салоне\багажнике авто — нашли газель
В остальном, принципиально ничего не изменилось аж с самого первого запуска. Так что за подробностями прошу в первую статью. Скажу лишь, что в этот раз мы снова использовали латексный шар L-2000 (масса 2000 г). Заменили парашют на «побольше» и новый. А в остальном — все так же.

Софт
Без лишних деталей — тот же репозиторий, тот же проект.
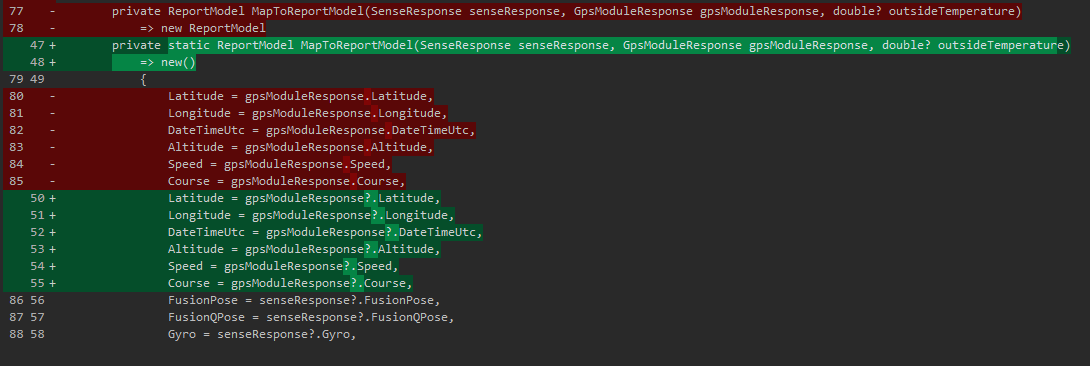
Пофиксили баг, обнаруженный в прошлый раз. Проявлялся он в том, что при потере сигнала GPS — мы теряли и все остальные данные. Звучит странно, но изначально логика была такова: время из GPS — наша точка синхронизации всех остальных данных. Без времени — мы не сможем понять за какой этап работы те или иные данные. Это было ошибочное утверждение. На самом деле время нам нужно лишь единожды — когда мы создаем файл лога (в качестве имени используется дата из GPS). Дальше данные собираются и пишутся раз в секунду по таймеру. Таймер — и есть наш источник синхронизации!
Ну, а технически там просто была NullReferenceException при пустых данных GPS, которую я игнорировал, потому что потому (выше описал). Пофиксилось это всё простым Nullable Check:
Бонусом мы мигрировали все проекты на .NET 6 и дописали немного unit-тестов. И, видимо, мало дописали, т.к. при анализе телеметрии с этого запуска, мы обнаружили новый баг¯\_(ツ)/¯
Теперь у нас при «перезапуске» GPS (а в этот раз это случалось часто) дублировался заголовок CSV. Что ж… Это не потеря данных, а лишь небольшой мусор, который легко убирается при анализе. Это мы обязательно пофиксим к следующему запуску.
Теперь о более масштабном. LCD дисплей помните? Он нам нужен был, чтобы избежать необходимости наложения телеметрии на видео в постобработке. Ок, давайте выводить на него телеметрию тогда.
В интернете мне сказали, что сейчас модно микросервисы. Вот вам микросервисы на минималках для RPI: проект по сбору телеметрии практически не подвергся изменениям, добавился новый проект RpiProbeLogger.TerminalGui, который суть есть — вывод данных в терминал.
Чтобы все это работало — надо эти две сущности как-то соединить. Отложите свои кафки обратно в стол — они нам не пригодятся. Для коммуникации была выбрана ZeroMQ. Основное отличие — отсутствие Message Broker-а. В данном случае, гарантированная доставка сообщений играет против нас. Дело в том, что дисплей должен отображать данные в реальном времени. Зачем нам очередь сообщений (из брокера), если эти «исторические» сообщения не будут отображать текущее состояние дел? Брокер хорошо, когда эти данные надо куда-то сохранить. А ZeroMQ отлично подходит для парадигмы выстрелил и забыл. К тому же, отсутствие брокера (что само по себе уже минус сущность) — делает этот метод гораздо более «легковесным».
Итак, ZeroMQ использует TCP порты для приёмопередачи (так что возможна коммуникация как внутри одного процесса, так и межпроцессная). У меня родился low-level интерфейс:
public interface IBusReporter
{
public Task Send(T model);
public void BindPort(uint port);
} BindPort занимает нужный нам порт, а Send отправляет «что-то» в канал.
Вот полная реализация:
public class BusReporter : IBusReporter, IDisposable
{
private readonly PublisherSocket _publisherSocket;
public BusReporter(PublisherSocket publisherSocket) => _publisherSocket = publisherSocket;
public void BindPort(uint port) => _publisherSocket.Bind($"tcp://*:{port}");
public void Dispose() => _publisherSocket.Dispose();
public async Task Send(T model)
{
var jsonModel = JsonSerializer.Serialize(model);
var sendTask = Task.Run(() => SendMessage(jsonModel));
return await sendTask;
}
private bool SendMessage(string jsonModel) =>
_publisherSocket
.TrySendFrame(TimeSpan.FromSeconds(1), jsonModel);
} Да, библиотека NetMQ не содержит асинхронной версии Send..., так что обертки вам придется накрутить самим. Хотя это не единственный способ отправить что-то в канал, и в документации вы можете подыскать что-то более подходящее для ваших нужд. Нас устраивает и синхронный TrySendFrame.
Далее нам надо прикрутить эту отправку к текущей подсистеме сохранения данных в файл. И желательно не трогая эту самую подсистему. Первое, что пришло в голову, это нелюбимый мной паттерн «Декоратор». Декорировать, понятное дело, будем интерфейс IReportService. Появилась еще одна его реализация TelemetryReporter. Полный листинг приводить тут не буду (лучше посмотрите репозиторий), тут лишь интересующий нас больше всего метод:
public async Task WriteReport(SenseResponse senseResponse, GpsModuleResponse gpsModuleResponse, OutsideTemperatureResponse outsideTemperatureResponse)
{
var result = await _decoratee.WriteReport(senseResponse, gpsModuleResponse, outsideTemperatureResponse);
if (!_busPortReady) return result;
await SendTelemetry(result);
return result;
} По классике: сначала вызываем декорируемую реализацию, потом пробуем отправить результат в ZeroMQ через IBusReporter.
Ну и теперь надо встроить этот декоратор в механизм разрешения зависимостей (заинжектить в DI):
private static void AddReportingServices(IServiceCollection services)
{
services.TryAddTransient();
services.TryAddTransient();
services.AddTransient();
services.AddTransient()
.Decorate();
services.AddSingleton();
services.AddTransient();
} Единственное, что здесь изменилось — добавился вызов метода Decorate. Все! Теперь при запросе IReportService из DI — этот DI будет оборачивать реализацию в наш декоратор. Больше никаких изменений в этом проекте можно не делать.
.NET в любой версии не содержит метода расширенияDecorate(и очень похоже, что никогда и не будет содержать). Этот метод из известной библиотекиScrutor
Можно не делать, но я еще немного сделал для понижения у себя уровня стресса — добавил кастомный ILogger утилизирующий ZeroMQ, но на отличном от TelemetryReporter порту. Я подумал: ну, а чо, пусть еще и ошибки на дисплей выводит? Реализация ILogger позволила мне добавить эту функциональность не трогая бизнес-логику (логгер то там так и так используется).
public class BusLogger : ILogger
{
private readonly IBusReporter _busReporter;
public BusLogger(IBusReporter busReporter) => _busReporter = busReporter;
public IDisposable BeginScope(TState state) => default;
public bool IsEnabled(LogLevel logLevel) => true;
public void Log(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func formatter)
{
if (!IsEnabled(logLevel)) return;
try
{
_busReporter.Send(
new LogEntry(
logLevel,
formatter(state, exception),
exception?.Message,
exception?.StackTrace))
.GetAwaiter().GetResult();
}
catch { }
}
} Полная реализация экосистемы логгеров в дотнете требует еще пары верхнеуровневых имплементаций, но тут я их приводить не буду. Если будете гуглить, то в любом случае на них нарветесь. Ну или посмотрите в моем репозитории.
ZeroMQ поддерживает «топики», но имя топика это фактически часть сообщения на том же порту, просто в отдельном кадре. Это может создавать состояние гонки (race condition) при чтении. Так что я решил просто разделить по портам телеметрию и логи, и не использовать топики совсем.
Хорошо, отправлять мы отправляем. Теперь давайте получим. Это еще проще (прыгаем в проект RpiProbeLogger.TerminalGui):
public abstract class BaseReceiver where T : struct
{
protected readonly IDirector _director;
protected readonly SubscriberSocket _subscriber = new();
protected BaseReceiver(IDirector director)
{
_director = director;
}
protected virtual void ReceiverLoop()
{
while (true)
{
var msg = _subscriber.ReceiveFrameString();
T model = JsonSerializer.Deserialize(msg);
_director.Refresh(model);
}
}
} Базовый класс «получателя». Просто в бесконечном цикле ждем сообщения из канала. Т.к. канала у нас 2 (логи и телеметрия), то и наследника у этого класса 2: TelemetryReceiverHostedService и LogsReceiverHostedService. Как можно догадаться, эти классы так же реализуют IHostedService и работают параллельно в экосистеме IHost. Вот весь Program.cs этого проекта:
class Program
{
private static IHost _host;
private static IConfiguration Configuration;
static void Main(string[] args)
{
_host = new HostBuilder()
.ConfigureAppConfiguration((context, builder) => {
builder.AddJsonFile("settings.json", true);
builder.AddEnvironmentVariables();
Configuration = builder.Build();
})
.ConfigureServices((hostContext, services) =>
{
services.AddHostedService();
services.AddHostedService();
services.AddSingleton, TelemetryDirector>();
services.AddSingleton, LogDirector>();
services.AddSingleton(provider => provider.GetService());
services.AddSingleton();
services.AddSingleton(provider => provider.GetService());
services.AddSingleton();
services.Configure(Configuration.GetSection("TelemetryReceiverSettings"));
services.Configure(Configuration.GetSection("LogsReceiverSettings"));
services.AddSingleton();
})
.Build();
var telemetryDirector = _host.Services.GetRequiredService>();
var logDirector = _host.Services.GetRequiredService>();
telemetryDirector.OnRefresh += UiRefresh;
logDirector.OnRefresh += UiRefresh;
Application.Init();
Application.Run(_host.Services.GetRequiredService());
}
private static void UiRefresh(object? sender, EventArgs e) => Application.DoEvents();
} Хорошо, данные мы получили. Давайте теперь их красиво выводить в терминал. Вы уже могли заметить выше какие-то MainWindow, View, etc. Это результат использования библиотеки Gui.cs. Она хорошо справляется с рисованием вьюшек в консоли, а так же умеет обрабатывать пользовательский ввод (мышка, клавиатура).
Единственная неприятность, которая у меня возникла — именно на RPI эта библиотека не обрабатывает события мыши. Я даже завел авторам Issue на гитхабе, где, после недолгих разбирательств, пометили это как баг.
Я, разумеется, не планировал таскать мышку к зонду, но помните — у дисплея есть тач? План был таков: в случае обнаружения оперативной командой каких-то «не тех» данных на экране телеметрии — они пальцем тыкают на вкладку с логами и говорят мне что там. Но… не срослось и я просто забил на эту фичу, посоветовав ребятам прихватить с собой в поле usb-клавиатуру (стрелками можно переключать вкладки).
Библиотека содержит демо-проект и очень хорошо документирована, так что я не буду тут приводить свои куски кода. Просто покажу, что получилось:
Если кратко: есть корневой уровень — Application.Top. Это должен быть наследник TopLevel (мой MainWindow), которому в зависимостях передается коллекция View (Telemetry и Logs). MainWindow создает TabView и добавляет табы из этой коллекции. Ладно, 1 кусок приведу (а то объясняю как питекантроп):
public MainWindow(IHost host, IEnumerable views) : base()
{
_host = host;
Loaded += MainWindow_Loaded;
Closing += MainWindow_Closing;
foreach (var view in views)
_tabView.AddTab(new TabView.Tab(view.Id?.ToString(), view), false);
_tabView.SelectedTab = _tabView.Tabs.First();
Add(_tabView);
} Следую заповедям IoC, каждая View сама отвечает за свое содержимое: рисует нужные элементы, получает данные, обновляет (из того же BaseReceiver) их и т.д.
Пожалуй остановимся на этом. Если есть вопросы — давайте в комменты или в репу (。_。)
CI/CD
Вы когда-нибудь деплоили что-то через связку TeamViewer + SSH? Я — да. И мне не понравилось. В первых версиях я использовал PowerShell-скрипт с использованием sftp и еще каких-то велосипедов и это все работало приемлемо до тех пор, пока целевой RPI находился в моей сети. С течением времени меня и этот RPI разнесло на тысячи километров, а дома у меня появился другой RPI (для домашних нужд), который сыграл роль тестового окружения.
А раз такие пляски, то давайте быстренько накидаем пайплайны для какой-нибудь CI\CD платформы с двумя окружениями: тест (Home) и прод (Vostok). Я конечно возьму Azure DevOps, лишь потому, что он мне ближе по роду деятельности. Это не играет принципиальной роли. Это будет сборка и доставка с использованием агентов, так как безагентная доставка усложняется конфигурацией сети целевого RPI — он не имеет статичного и\или белого IP и он скрыт за всякими NAT-ами, да и вообще не имеет статичной конфигурации (сеть постоянно меняется). Соответственно, агент нам нужен на «той» стороне.
Для начала вам надо создать окружения (Home и Vostok), скачать и установить агента под ARM архитектуру. Идем в Pipelines -> Environments -> New Environment. Тип окружения: Virtual Machine. Тут он вам предложит выбрать тип операционной системы, лишь для того, чтобы сгенерировать скрипт для установки агента. Он вам не нужен, потому что при выборе Linux — он генерит ссылку на x86–64 агента. А у нас ARM.

Так что просто создайте окружение и идите сразу в Project Settings -> Agent Pools -> Default -> New Agent. Тут уже можно явно выбрать ARM-агента:
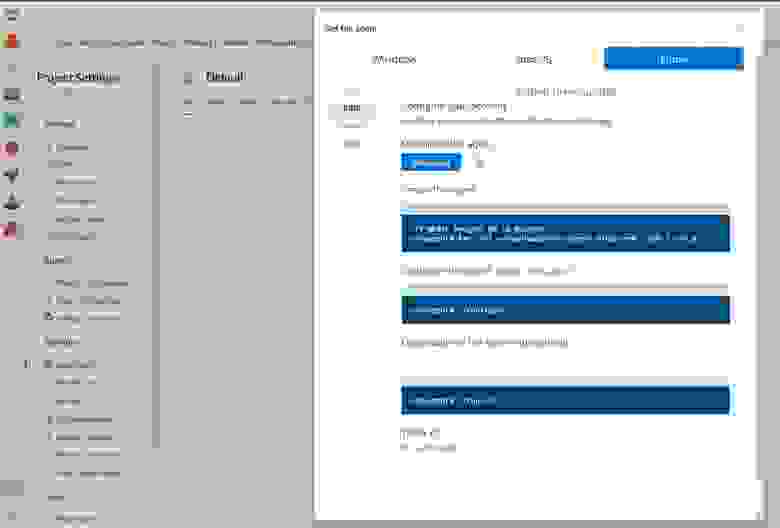
Этот шаг нужен, только чтобы получить ссылку на нужный архив с агентом, на самом деле ссылку вы можете найти и на MSDN, но тут мне показалось проще.
Скачать агента на RPI вы можете просто wget-ом. Далее выполните шаги, указанные в окне добавления агента и всё. Повторите для всех ваших окружений. На этом шаге проблем возникнуть не должно.
Проблема возникнет с «бесплатностью» этой затеи. Дело в том, что раньше Microsoft раздавали по 10 бесплатных parallel jobs по умолчанию. С каких-то пор этот аттракцион прикрыли и их стало… »0» ¯\_(ツ)/¯
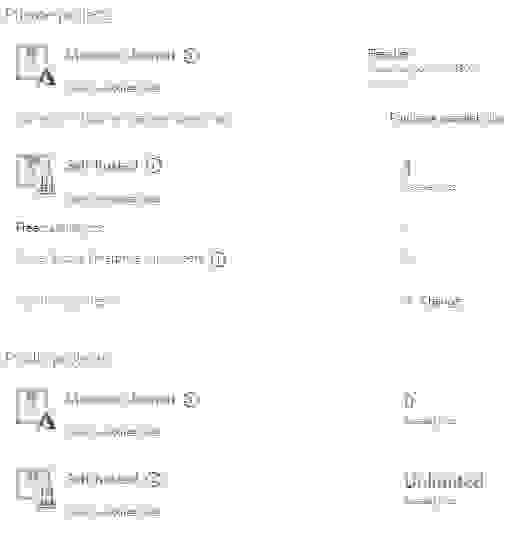
Даже для публичных проектов.
Не стоит путать parallel jobs и agents. Да, агенты тоже могут билдить ваши приложения, но хотелось бы билдить независимо от цели доставки, в облаке. А уже на целевые окружения доставлять готовые бинарники. Вот для билдов нам нужны эти Microsoft-hosted parallel jobs
Не отчаиваемся и идем сюда, видим там такое:
Public project: 10 free Microsoft-hosted parallel jobs that can run for up to 360 minutes (6 hours) each time, with no overall time limit per month. Contact us to get your free tier limits increased.
Контактируем с ними, заполняя форму и ждем. Народ в интернетах пишет, что реагируют они в течении 3-х рабочих дней. У меня всё случилось через сутки:
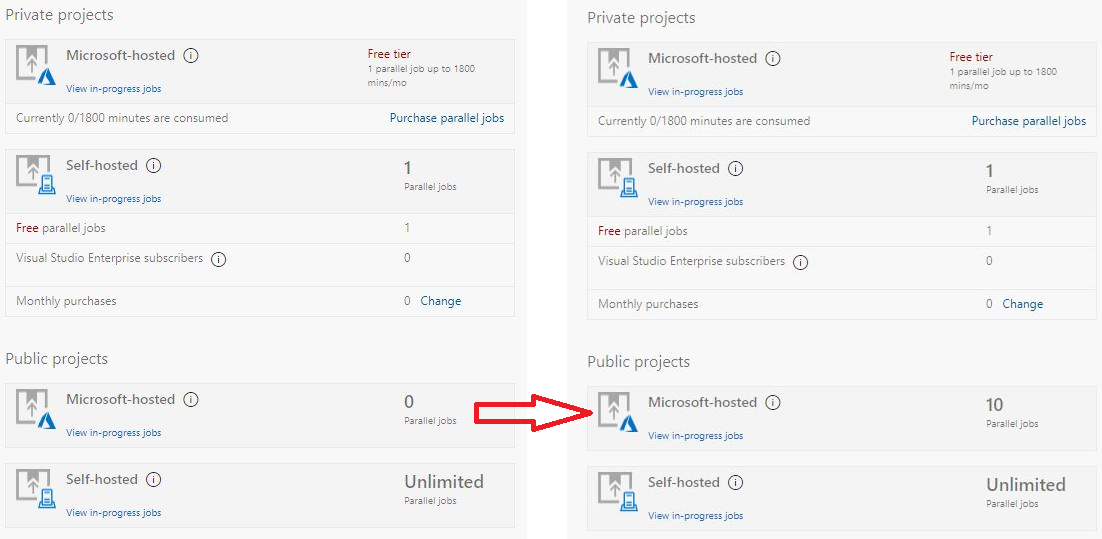
Это полностью закрывает все наши потребности. Теперь мы имеем 2 окружения (Home и Vostok), агенты на них и доступные в облаке 10 параллельных джобов для наших билдов.
Далее нам предстоит переквалифицироваться в yaml-программистов и создать, собственно, пайплайн. Чтобы поберечь ваши нервы, я приведу здесь, как пример, лишь один — для
name: $(SourceBranchName)$(Rev:.r)
trigger:
paths:
exclude:
- ReverseSsh
variables:
- name: projectName
value: RpiProbeLogger.TerminalGui
readonly: true
parameters:
- name: sdkVersion
displayName: '.NET version'
type: string
default: net6.0
values:
- net5.0
- net6.0
- name: buildConfiguration
default: Release
displayName: 'Build configuration'
type: string
values:
- Release
- Debug
- name: targetRuntime
default: linux-arm
displayName: 'Target runtime'
type: string
values:
- linux-arm
- win10-x64
- osx.12-x64
stages:
- stage: BuildAndTest
displayName: 'Build and test'
jobs:
- job: BuildAndTest
displayName: 'Build and test'
pool:
vmImage: 'ubuntu-latest'
steps:
- task: DotNetCoreCLI@2
displayName: 'Build'
inputs:
command: 'publish'
publishWebProjects: false
projects: '${{ variables.projectName }}/${{ variables.projectName }}.csproj'
arguments: '--self-contained -r ${{ parameters.targetRuntime }} -f ${{ parameters.sdkVersion }} -c ${{ parameters.buildConfiguration }}'
zipAfterPublish: false
modifyOutputPath: false
- publish: ${{ variables.projectName }}/bin/${{ parameters.buildConfiguration }}/${{ parameters.sdkVersion }}/${{ parameters.targetRuntime }}/publish
displayName: 'Publish artifacts'
artifact: ${{ variables.projectName }}
- stage: DeployTerminalGuiHome
displayName: 'Deploy Home'
jobs:
- deployment: TerminalGuiHome
environment:
name: Home
resourceType: VirtualMachine
variables:
- name: TerminalGuiAtStartup
value: false
workspace:
clean: all
condition: in(variables['Build.Reason'], 'IndividualCI', 'Manual')
strategy:
runOnce:
preDeploy:
steps:
- script: sudo pkill -f ${{ variables.projectName }}
displayName: 'Kill running GUI process'
deploy:
steps:
- task: CopyFiles@2
displayName: 'Copy files'
inputs:
SourceFolder: '$(Pipeline.Workspace)/${{ variables.projectName }}'
Contents: '**'
TargetFolder: '$(HOME)/${{ variables.projectName }}'
CleanTargetFolder: true
- script: chmod +x $(HOME)/${{ variables.projectName }}/${{ variables.projectName }}
displayName: 'Make executable'
- stage: DeployTerminalGuiVostok
displayName: 'Deploy Vostok'
dependsOn: DeployTerminalGuiHome
jobs:
- deployment: TerminalGuiVostok
environment:
name: Vostok
resourceType: VirtualMachine
variables:
- name: TerminalGuiAtStartup
value: false
workspace:
clean: all
condition: and(startsWith(variables['Build.SourceBranch'], 'refs/heads/release-'), in(variables['Build.Reason'], 'IndividualCI', 'Manual'))
strategy:
runOnce:
preDeploy:
steps:
- script: sudo pkill -f ${{ variables.projectName }}
displayName: 'Kill running GUI process'
deploy:
steps:
- task: CopyFiles@2
displayName: 'Copy files'
inputs:
SourceFolder: '$(Pipeline.Workspace)/${{ variables.projectName }}'
Contents: '**'
TargetFolder: '$(HOME)/${{ variables.projectName }}'
CleanTargetFolder: true
- script: chmod +x $(HOME)/${{ variables.projectName }}/${{ variables.projectName }}
displayName: 'Make executable'
- script: if grep ${{ variables.projectName }} $(HOME)/.bashrc; then echo "##vso[task.setvariable variable=TerminalGuiAtStartup]true"; fi
displayName: 'Check if GUI run at startup'
- script: echo $(HOME)/${{ variables.projectName }}/${{ variables.projectName }} >> $(HOME)/.bashrc
displayName: 'Add GUI at startup'
condition: eq(variables['TerminalGuiAtStartup'], 'false')
on:
success:
steps:
- script: sudo shutdown -r +1
displayName: 'System reboot in 1 minute'В triggers -> paths -> exclude видно подозрительное. Но к нему мы вернемся позже. Сейчас основная структура в двух словах:
- Есть параметры которые можно задавать перед выполнением пайплайна на UI. Возможно с ними я переборщил и их можно опустить.
- Есть
Stages. Это самые высокоуровневые юниты пайплайна. Тут у насBuildAndTest,DeployTerminalGuiHomeиDeployTerminalGuiVostok. Между последними 2-я установлена зависимость через свойствоdependsOn— деплоить на прод, только после деплоя на тест. Там еще, по хорошему, можно добавить условиеisSuccess, но я его забыл\забил. - Далее у нас идет деление каждого Stage на
Jobs. Те самые, которые мы выторговали у Microsoft, и которые могут быть распараллелины. Но у меня везде по одной джобе, так что параллелить нечего. в Azure Pipelines есть 2 типа джобов:build jobsиdeployment jobs. Они немного (сильно) разные по структуре и свойствам. Deployment jobs дают вам некоторую свободу выбора стратегии деплоймента (Canary, Rolling, GreenBlue, etc) и триггерыpreDeploy,on success,on fail, etc. Триггеры полезны если вы хотите делать zero-downtime и\или откатиться при неудачном деплое. - Ну и наконец
Steps— это просто шаги, которые выполняются по очереди в каждой джобе. Могут быть shell-скрипты или какие-то таски из marketplace. Я использую разное.
Итого:
- Билдим, запускаем тесты
- Деплоим домой
- Если до этого «ок» — деплоим на прод
Всего у меня в репозитории сейчас 3 пайплайна: RpiProbeLogger, RpiProbeLogger.TerminalGui и ReverseSsh. Последний выглядит странно, но он прикольный.
ReverseSsh
Когда агент коннектится к серверам Azure и выполняет какую-то работу — это конечно прикольно, но так не подебажишь. Вот бы наш Vostok коннектился ко мне? Установить соединение от меня к Vostok не получается — я объяснял почему. Но моя домашняя сеть — это моя домашняя сеть. Она мне полностью подконтрольна (во всяком случае приятно так думать). Значит мы можем настроить все что надо у себя дома, а именно: белый и статичный IP (или использовать DynDNS и аналоги), включить перенаправление портов (Port Forwarding) на своем любимом роутере. А дальше дело за малым — используя стандартные возможности клиента ssh — установить со мной соединение. В данном случае я устанавливал соединение с моим домашним RPI, т.к. он всегда онлайн, в отличие от моего ноута.
Делается это так: ssh -tt -i /home/user/.ssh/id_rsa -R 43022:localhost:22 pi@myhome.router.com
Я подставил фейковые значения в параметры для наглядности. Давайте и покажу реальное содержимое файла ReverseSsh\Scripts\reverse_ssh.sh:
ssh -tt -i #{ReverseSshKeyLocation}# -R #{ReverseSshLocalPort}#:localhost:#{ReverseSshServerPort}# #{ReverseSshUsername}#@#{ReverseSshServerAddress}#У меня эти значения хранятся в Azure DevOps и подставляются на этапе выполнения (информация чувствительная и хранить ее в репозитории — это моветон).
Итак:
ReverseSshKeyLocation — путь до приватного ключа на RPI
ReverseSshLocalPort — порт, который будет открыт на целевой машине (моем домашнем RPI). К нему мы, в дальнейшем, и будем коннектиться
ReverseSshServerPort — порт на который мы будем устанавливать соединение до моего домашнего RPI. Именно этот порт и надо добавить в правила Port Forwarding. У сисадминов бытует мнение, что для ssh всегда надо выбирать нестандартный порт (отличный от 22), т.к. это спасает от обнаружения массовым сканированием. Я не сисадмин, но имейте в виду — этот порт будет торчать наружу из вашей домашней сети.
ReverseSshUsername — пользователь на целевой (домашней) RPI
ReverseSshServerAddress — адрес\доменное имя домашней сети
Если все подставить\настроить правильно, выполнить команду выше, затем зайти на домашний RPI (или туда, куда вы разворачивали обратный тоннель) и попробовать соединиться по ssh с портом 43022, то должны увидеть нечто такое:

Ура, мы внутри продакшеновского RPI:3
Осталось немного полирнуть — сделать так, чтобы он теперь сам, без моих манипуляций, соединялся со мной, когда это возможно. Тут нам снова поможет подсистема сервисов\демонов (простите я всегда путаюсь в этой терминологии) systemctl. Я уже в первой статье создавал такой сервис — тот, который запускает наш логгер RpiProbeLogger. Тут механика та же, нам потребуется .service-файл:
[Unit]
Description=Reverse SSH Tunnel
After=network-online.target
Wants=network-online.target
[Service]
User=pi
WorkingDirectory=#{ReverseSshUserHomeDirectory}#
ExecStartPre=/bin/bash -c 'until host example.com; do sleep 1; done'
ExecStart=/bin/bash #{ReverseSshScriptPath}#
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
Type=exec
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=VostokSsh
[Install]
WantedBy=multi-user.targetСтоит обратить внимание на свойства After, Wants — их значения указывают, что ExecStart надо выполнить только после установления соединения с какой-либо сетью. Несмотря на, вроде бы, явные требования к сети, тут потребовался небольшой лайфхак из интернетов. По не известной мне причине, сеть появляется раньше, чем подсистема DNS (наверно это ожидаемое поведение, но я такого не знал). Так что наш ssh просто не может зарезолвить доменное имя моей сети сразу же после появления связи. Из-за этого появилось свойство ExecStartPre. С помощью него мы можем отложить выполнение основной задачи, пока не зарезолвим имя проверочного хоста (example.com).
Установку и настройку всего этого хозяйства можете посмотреть в пайплайне ReverseSsh\azure-pipelines.ReverseSsh.yml
Технически, имея такой тоннель, необходимость в Azure стремится к нулю. Но исторически у меня сложился именно такой порядок реализаций, так что вот. Более подробно про reverse ssh можете посмотреть, например, тут.
Теперь, если хотите, можете хоть с телефона наблюдать:

Разумеется, это работает до тех пор, пока RPI имеет хоть какое-то соединение с интернетом.
Ладно, вроде на этом хардкор заканчивается, давайте в более гуманитарное русло.
Подготовка к запуску
Да, тут мы поели «варенья»… Я не буду тут описывать те же вещи, что в каждой прошлой статье (про построение прогноза маршрута, выбора точки запуска и т.д.), опишу подробно лишь одну, так как она имеет критическое значение.
Полетный план
Тот красивый и удобный сайт (new.ivprf.ru), который я рекламировал в прошлом сезоне — закрылся, так до конца и не открывшись. Это очень печальная новость, потому что теперь придется составлять планы «руками» и отправлять их по электронной почте (спасибо, что не факс, хотя на заре наших запусков была и такая история). Но, как оказалось — не все так страшно. Мы это делаем не первый раз и уже имеем шаблон для планов шаров-зондов:
(SHR-ZZZZZ
-ZZZZ1200
-K0300M3000
-DEP/5850N03325E DOF/220604 OPR/ИВАНОВ ИВАН ИВАНОВИЧ +79001234567 mymail@mail.ru
TYP/SHAR RMK/ОБОЛОЧКА 300 ДЛЯ ЗОНДИРОВАНИЯ АТМОСФЕРЫ SID/VSTK0160)Это абсолютно полный полетный план шара-зонда. Именно в таком виде он отправляется в теле письма на почту зональному центру ОрВД.
Как понять какой у вас зональный центр и куда писать смотрите в Самодельный стратостат. Полётный план и ОрВД или на сайте ОВД. В нашем случае это был СПБ ЗЦ с адресом spbzc@sz.gkovd.ru
Давайте разберем его по косточкам, чтобы вы могли легко адаптировать его под себя.
(SHR-ZZZZZОткрывающая к
