Самая сложная задача в Computer Vision
Среди всего многообразия задач Computer Vision есть одна, которая стоит особняком. К ней обычно стараются лишний раз не притрагиваться. И, если не дай бог работает, — не ворошить.
У неё нет общего решения. Практически для каждого применения существующие алгоритмы надо тюнинговать, переобучать, или судорожно копаться в куче матриц и дебрях логики.
Статья о том как делать трекинг. Где он используется, какие есть разновидности. Как сделать стабильное решение.
Что можно трекать
Трекингом называют задачу сопровождения объектов. От детекции задача отличается тем что нам не только надо задетиктировать объект в первом кадре, но и понять где он находится в следующем.
Что можно трекать?
- Людей
- Животных
- Машины и прочую технику
Конечно, можно трекать что угодно (точки на пальцах, или на лице), но 99% задач из перечисленных категорий.
Разберем в каких задачах это используется на практике для каждой категории.
Люди
Трекинг людей нужен чаще всего.
Самая стандартная задача на которой больше всего решений — трекинг людей на улице. Для этого даже большой челлендж есть (даже не один):

Где применяется трекинг на улице/в толпе? Всякие системы безопасности/защиты периметра. Иногда чтобы отслеживать кого-то.
Не сказать что существует готовое общее решение работающее всегда. Почему? В такой толпе даже человек неправильно всё разметит:

Другая задача, на мой взгляд самая востребованная, и не такая маргинальная — подсчёт числа посетителей торговых точек, аналитика по торговому залу. Короче статистика для бизнеса. На хабре было несколько статей на эту тему, например эта. Сюда же можно отнести задачи плана подсчёт входящих/выходящих людей в транспорте.

Примерно те же подходы используются при трекинге на предприятиях. Это очень важно для детектирования ситуаций плана «вход в закрытую зону» (пример с Хабра). Но может работать и для задач уровня «помыл ли руки перед подходом к разделочному столу». Тут важнее не статистика, а качество решения.

Отдельная задача — трекинг в домах. Она достаточно редко встречается, но на мой взгляд сложнее любой из вышеперечисленных из-за сложности установок камер. Яркий пример фирмы которая ей занимается — CherryLabs.
Животные
Глобально, трекинг животных в 95% нужен только на фермах. В природе делают скорее детекцию, чтобы посчитать статистику. А на ферме очень полезно знать какая корова не отдоилась и куда она пошла. Как ни странно, но таких фирм очень много. Вот несколько которые решают эти задачи — Cows.ai, Cattle-Care. Но, как водиться, таких не мало.

(Видео с сайта первых)
Можно трекать овец. Можно свиней.
А можно… Рыбок! (картинка от google, но есть много разных фирм, например Aquabyte)

Машины и прочая техника
Машины и прочие самолёты обычно трекать очень просто. Они ездят по практически идеальным траекториям, что сильно упрощает работу алгоритма. Прочую технику зачастую трекают военные, и это редко встречается на практике.
А машины трекать нужно и в системах умного города, и в системах выписывания штрафов, и в всяких системах сопровождения гонок.

Есть несколько базовых алгоритмов, которые будут лежать в основе любого построения трека, и бесчисленное число комбинаций между ними:
- Детекция объектов в кадре. Не важно что тут используется. Главное чтобы детекция выдавала положение объекта. Это может быть YOLO, SSD, или любой из десятков более новых алгоритмов.
- Алгоритм распознавания объекта в кадре. Так называемая задача ReIndentification. Это может быть:
- Распознавание человека по телу
- Распознавание человека по лицу
- Распознавание типа автомобиля
- и.т.д, и.т.п.
- Алгоритмы сопоставления объектов по физическим параметрам. Это может быть сопоставление по IoU (пересечение выделенного прямоугольника), сопоставление по скелету (насколько они похожи), сопоставление по положению на полу/на земле/на дороге. и.т.д.
- Алгоритм межкадрового трекинга. Эта часть самая загадочная.
- Сюда входит много алгоритмов оптического трекинга, оптического потока, и.т.д…
Когда человек решает задачу трекинга, то он использует все перечисленные алгоритмы. Какие-то подсознательно, какие-то сознательно.
Но для любого алгоритмиста это ад и кошмар. Как найти взаимоотношения между алгоритмами, как понять что происходит, как всё это собрать.
Сейчас эти взаимосвязи пытаются обучать, или закладывать напрямую в алгоритм. Но всё слишком нестабильно. Классикой является алгоритм трекинга, который завязывает наборы детекций и матриц перехода в трек с учётом пропусков и появлением новых объектов. Обычно это различные фильтры Калмана, или нейронки.
Что важно отметить при переходе к алгоритмам трекинга
95% качества при трекенге, как впрочем и у любой задачи ComputerVision — установка камеры.
Сравните:


Где проще посчитать людей?
Но помните, установка камеры сверху — зачастую усложняет создание системы. Ни Yolo ни SSD, ни стандартные ReID алгоритмы — не будут работать по таким объектам. Потребуется полномасштабное переобучение (ниже приведу пример).
Детекция объектов в кадре
Про детекцию есть много постов на Хабре. Есть сети которые показывают более высокое качество. Есть сети которые показывают более высокую скорость. Зачастую скорость может быть завязана на железо. На одной железке быстро — на второй — медленно.
Если вы не разбираетесь что вам надо, то на июнь 2020 хорошим вариантом является YOLOv4, обеспечивающая баланс качества/производительности. Для максимальной скорости можно посмотреть в сторону YOLOv3- tiny или в сторону быстрых версий EfficientDet.
(Ещё мутный YOLOv5 появился за время написания статьи, но там какая-то хрень).
Но в ряде случаев эти решения могут не быть оптимальными.
Ниже мы будем рассматривать ряд решений где детектор объединен с другими алгоритмами, там, зачастую, будут использованы предопределенные сети, которые сложно будет перенести…
Для трекинга детекция — это основа. Какие бы крутые у вас не были следующие алгоритмы — без детекции трекинг не будет работать.
Прямым следствием является то, что детектор скорее всего придётся преобучать по вашему датасету.
Обычно детекторы учатся на каких-нибудь универсальных датасетах (например Microsoft COCO):

Там мало людей которые плохо видны, скорее всего нет камеры похожей на вашу (ИК, широкий угол). Нет ваших условий освещения, и многое другое.
Переобучение детектора по датасету из используемых условий может уменьшить число ошибок в 2–3 раза. Лично я видел примеры где и в 10–20 уменьшало (процентов с 60–70 точности до 98–99).
Отдельным моментом стоит отметить что в ситуациях когда люди/животные/машины в нестандартных ракурсах — переобучать придётся всегда. Вот пара примеров как работает непереобученный Yolo v4:


Несколько мест где можно взять готовые нейронки для детекции:
Я не буду подробно заостряться на этой теме, про детекцию безумно много статей.
Person ReIndentification
Предположим вы мельком в толпе увидели эффектную блондинку в красном платье. Выходите из толпы, и внезапно блондинка тоже вышла.

Вы не видели как она вышла из толпы. Вы не видели её последние 30 секунд. Но вы же знаете, что это она.
Тут работает именно алгоритм распознавания по телу.
В ML существуют алгоритмы для создания хэш-кода, который потом можно использовать для определения человека через какое-то время.
Особенно после разрыва трека.
Существует несколько крупных датасетов для обучения таких алгоритмов. Самые известные:
- Market-1501
- CUHK03
- MARS
- DukeMTMC
- iLIDS-VID
Большая часть датасетов собрана каким-то таким образом:

Ставится несколько камер, и отмечаются одни и те же люди которые проходят между ними. Некоторые датасеты собирают с одной и той же камеры.
Есть множество способов обучить такие нейронки, если вам это интересно, то вот тут есть хорошая подборка с исходниками.
В качестве примера я приведу старый способ, который был популярен года 4 назад, и очень простой. Сейчас пользуются его вариациями (на картинке именно такой пример).

У нейронной сети создаётся бутылочное горлышко, из небольшого числа нейронов. А на выходе нейронной сети будет число нейронов по числу людей в датасете. Сеть научится распознавать людей, но параллельно научится описывать их в качестве небольшого вектора.
Так просто никто уже не делает. При обучении последних версий ReID используется и hard negative mining, и различные хитрые аугментации и трюки с подрезанием, и фокальные потери, и многое-много другое.
Всё бы хорошо, но у ReID алгоритмов есть слишком много проблем. Даже по датасетам которые идеально под них заточены (улица, одинаковые условия освещения, почти одинаковое время съемки, отсутствие пёстрого фона, нет больших пересечений людей, нет заслонений объектами переднего фона, человек целиком в кадре, и.т.д., и.т.п.), даже у самых последних моделей точность будет на уровне 95–98%
На практике такие сети очень сложно использовать: «Предположим у вас завод где все ходят в одинаковой униформе»…
Так что данный класс сетей надо использовать в очень ограниченных задачах, или при очень аккуратном контроле, иначе он не привнесёт точности в ваш алгоритм.
Ниже мы рассмотрим как алгоритмы ReID используются в сетях трекинга и иногда ощутимо повышают результат.
ReID по одежде
Одна из вариаций ReID — распознавание по одежде:
- Пример сорсов
- Пример алгоритма
- Пример алгоритма
По сути тот же вектор что и выше, только который можно контролировать глазом. По опыту работает хуже обычного ReID, но в некоторых ситуациях может давать более стабильную работу.

Например, если у вас люди носят три типа формы — можете обучить по ним!
ReID по лицу
Отдельно стоит упомянуть про возможность трекинга по лицу. Если с вашей камеры видно лицо, да ещё и в разумном качестве — бинго! Вы можете сделать хорошую систему трекинга.
Про распознавание по лицам можно почитать например тут — 1, 2.
По практике скажу только одно. Не видел ни одной системы трекинга где лица были бы видны всегда и хорошо. Скорее это был один из дополнительных факторов, который изредка помогал что-то пофиксить, либо давал привязку трека к человеку.
Про точность распознавания лиц и их применимость я писал длинную статью.
Пусть будет ещё картиночка про олдфажеский TripletLoss для обучения лиц, который уже не используется:

ReID не на людях
Алгоритм реиндентификации очень удобен для трекинга. Хотите посмотреть где он работает на животных? Например тут:
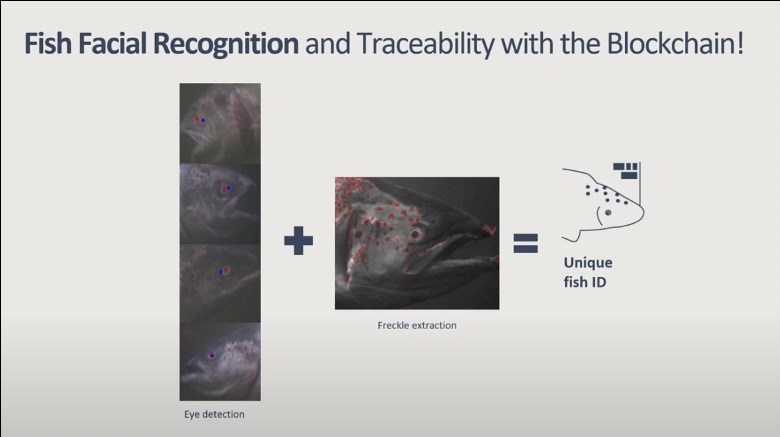
Для некоторых рыб можно вообще обучить аналог лицевого ReID, с достаточно высокой точностью. Вот тут рассказано подробнее — 1, 2
Очень хорошо ReID работает на коровах. Каждая корова по шкуре уникальна: 1, 2
И, как я слышал, ReID не очень работает на животных где окрас одинаков, например овцы или свиньи.
Прочие ReID
Какие-то аналоги ReID можно использовать для трекинга автомобилей (например распознавание марки автомобиля). Можно обучить ReID для трекинга людей по головам.
Но так как ReID обычно обучать муторно — достаточно редко вижу его использование для трекинга вне случаев описанных выше (не для трекинга применений масса!).
Алгоритмы сопоставления объектов по физическим параметрам
Как мы говорили выше — ReID это лишь набор параметров объекта, которые мы выделяем нейронной сетью. Но не стоит забывать, что у ведомого объекта может быть множество параметров, которые сложно выделить нейронной сетью, но просто использовать для трекинга.
Например:
- Размеры выделенной области (bbox) объекта. Чем более похожи объекты в соседних кадрах по размеру — тем с большей вероятностью это один объект.
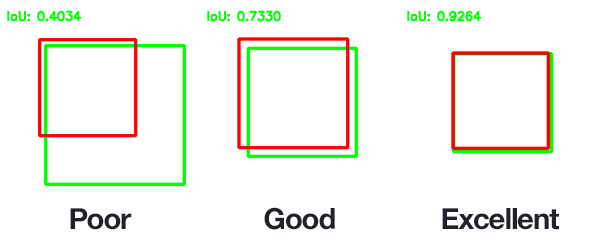
- Положение центра масс. Чем ближе центр масс к планируемой траектории — тем с большей вероятностью это один и тот же объект.
- Скорость передвижения объекта в прошлых кадрах. Чем больше скорость и ускорение соответствуют какому-то объекту, тем с большей вероятностью это одно и то же.
- Координаты проекции на землю. Можно вычислить если знать как висит камера. Для установок камер вертикально сверху — совпадает с позапрошлым пунктом. Хорошо работает при трекинге машин.

- Близость позы. ReID алгоритмы работают в длительном окне времени, не учитывая позу человека, стараясь отвязаться от неё. Но если сэтап имеет достаточно высокую скорость обработки, то наоборот, можно привязывать соседние детекции по позе человека.
- Наверняка есть что-то что я ещё забыл. Но оно сильно реже на практике.
Оптический трекер
Ну вот мы и пришли. К могучем, огромному, бесполезному оптическому трекингу!
По этой теме фанатеют многие. Смысл этого класса алгоритмов очень простой.
Пусть в первом кадре у нас есть заданное положение объекта. Нужно найти его в следующем.
И не важно какой объект: человек, машина, точка на руке, вертолёт или падающий лист.
Задача достаточно простая и древняя. Для неё существует множество подходов. Начинающихся ещё с OpticalFlow задачи:

(найти для каждой точки кадра порождающую её точку с прошлого кадра).
А потом пошло поехало:
И многое, многое другое.
Любой новичок, который хочет решить задачу трекинга — с загорающимися глазами подскакивает, и говорит «Да, я хочу использовать это!».
Обычно после этого он натыкается на примеры из Эндриана Розеброка:
И использует их в продакшне… (видел минимум в двух фирмах)
Но нет… Не надо так. «Каждый раз когда вы берёте пример с pyimagesearch и несёте его в прод — вы делаете грустным ещё одного котика» ©.

Эдриан — хороший популяризатор. Возможно он даже знает как делать машинное зрение. Но 95% его примеров — это пример использования готовой библиотеки. А готовая библиотека почти всегда бесконечно далека от прода.
Разберём что может пойти не так (специально записал!):
- Похожие объекты, оптический трекинг не учитывает направление и скорость, он выбирает оптимальный минимум ближе всего:

- Неадекватный детектор потери. Например человек входит в дверь. Оптический трекер это не любит:

- Неадекватная реакция на сильно изменение формы. Резкий разворот/поворот убивает трекеры:

- Перепады яркости…
Есть и другие, менее значительные причины, которые тоже могут проявится. Это приводит к нескольким утверждениям:
- Если у вас более-менее стабильная детекция — оптический трекер нет смысла использовать
- Если у вас нет опыта тонкого тюнинга таких алгоритмов — то тоже не надо брать такое
- Если у вас есть несколько независимых алгоритмов, а их результаты вы планируете склеивать в ручную — то лучше не надо использовать оптический трекер. Только при автоматической склейке где какой-то ML алгоритм выберет параметры склейки сам.
Это не значит, что оптический трекер не имеет смысла вообще. Есть небольшой процент ситуаций когда его использование может быть оправданно. Какие? Апологеты этого подхода выделяют два типа ситуаций:
- Оптимизация скорости работы. Запускать детектор пореже, а трекинг меньше ест.
- Универсальность работы на любом железе.
Но по мне оба аргумента очень сомнительны при современном уровне развития технологий.
Единственное место, наверное, где трекинг имеет смысл — вы не можете набрать базу для детекции. Вот пример как можно трекать вот через классические, встроенные в OpenCV алгоритмы (реинициализирую руками после разрыва):
И вот что выдаст обычный YOLOv4 (детекции клею через SORT, про который будет ниже):
Понятно, что YOLO можно дообучить, и всё будет сильно лучше. Но, наверное, когда нет таких сил — можно и через трекинг прототип сделать.
А вот что будет оптическим трекером из OpenCV (GOTURN, каждый раз когда разрыв реинициализирую заново):
И да, ниже по тексту мы столкнёмся с алгоритмами которые включают в себя оптический трекер по умолчанию.
Как всё это завязать.
Нагенерили детекций. Возможно нагенерили каких-то метрик близости между ними. Как всё это завязать друг с другом?
Есть много подходов. Проблемы есть почти везде. Начнём с «простого».
Классическая математика
Самым классическим и стабильным подходом является «модель движения» + «алгоритм целераспределения». Собственно, все эти алгоритмы целераспределения и родились в 60–70 годах для слежения за целями в воздухе и космосе.
Как ни странно, один из самых классических подходов, где в качестве модели был взят фильтр Калмана, а в качестве целераспределения — венгерский алгоритм — выстрелил в 2016, взяв первое место в MOT соревновании (SORT). И если по точности он был плюс-минус сравним с другими решениями, то по скорости бил в 20 раз. А по понятности в 100.
Почему этого не произошло раньше? Не знаю. Подход настолько классический и дубовый, что для определения параметров спутников нам его ещё году в 2008 на кафедре МФТИ преподавали. И эта программа, как я понимаю, лет 20–30 не менялась.
Скорее всего так вышло потому, что не было ни одной opensource реализации нормальной. Всё пряталось в глубинах продуктового софта.
В целом, фильтра Калмана — достаточно универсален, но местами перебор. В реальных задачах мы очень часто пользовались более простыми моделями, где в качестве модели движения использовали какие-нибудь аппроксимации, либо более простые методы линейной комбинации.
Такие аппроксимации могут быть очень крутым способом «насадить детекции на один трек».
На базу такого алгоритма можно насадить любые другие метрики близости. Например близость по позе. Или близость точек между результатами оптического трекинга.
Или в конце концов близость между ReID описаниями. Именно так делает, например DeepSORT.
Сравните качество работы SORT против Deep SORT:
И то и то собрано на базе детекции из Yolov4 которая выглядиттак.
Надо сказать что данный подход до сих пор в топе.
На сегодняшний день самый топовый из трекеров с открытым кодом по MOT конкурсу — FairMOT. И, как ни странно, он реализует ту же самую логику, только более хитро обученную.
А вот так будет выглядеть то же самое видео что и выше (правда я запустил не самую мощную сетку, как я понял):
На более мощной чуть лучше детекция работает. Тут явно завалена ближняя часть.
Только вот не везде этот подход будет работать. ReID — нестабилен в большом временном окне. ReID не будет работать по одинаковым вещам как машины, или олени. Или, например, работники в униформе.
Мы наталкивались на задачи когда ReID был самой плохой метрикой для людей, из всех перечисленных.
Нейронончки везде
Не смотря на то, что подход «развернуть всё через Калмана и функцию потерь» работает хорошо и часто выигрывает — люди не перестают затаскивать больше факторов в эту задачу. Например заставать нейронку самой решить как она хочет использовать информацию с прошлого кадра:
К этому подходу будет относится и упомянутые уже LSTM сети трекинга:

И так же упомянутые сети трекинга скелетов:


Казалось бы. Раз можно достичь высокие результаты — так и надо делать всегда! Но, как ни странно, нет.
Предположим вы решили обучить трекер по головам. Подошли серьёзно. И LSTM-сеть с пачкой кадров взяли. И ReID добавили, и детектор переобучили.
Только вот есть одна проблема. Обучать по видео — это огромные объемы датасетов. Длительная разметка, не понятен профит от обучения относительно того же SORT. Даже FairMot надо переобучать. И куда сложнее переобучать, чем отдельно YOLO.
И самое плохое. Если вы сегодня обучаете по головам, а завтра люди с наклоном (или объектив поменяли) — то это разные датасеты. И если для детекции это сделать несложно (у нас сейчас на такую итерацию уходит в среднем 3–4 дня), то собрать датасет треков — это огромная задача.
Как в реальности
Мы затронули интересный вопрос. «А как всё устроено на практике?». Тут всё интересно. По сути, как мне кажется: «на практике всё либо очень сложно, либо очень просто».
Очень сложно — когда надо получить какой-то качественно новый результат. Например водить автомобиль. Тогда рождаются вот такие химеры:

Бывает и сложнее. Я почти уверен, что если у любой Tesla или Yandex-машинке разрисовать схему обучения алгоритмов трекинга — то там сума сойдёт даже адекватный человек.
По тому что видел лично я:
- В двух стартапа видел схему с уже упомянутого pyimagesearch. Когда происходила детекция, а для связывания детекций использовался оптический трекер. В одном стартапе работало на гране допустимого качества. Во втором не работало.
- В одном стартапе разрабатывали детектор + аналог МНК для слежения. Но там трекались точки на человеке. Работало хорошо.
- Сами участвовали/разрабатывали несколько систем трекинга авто. И везде трекинг был через какого-нибудь Калмана/аналог с МНК. Видел несколько фирм где в целом было так же. Работало у всех хорошо.
- Видел 3 фирмы где в качестве трекинга использовался SORT. Одной из них разрабатывали процесс обучения детектора, который подавался в SORT. У всех всё было классно, всё работало.
- Участвовали/до сих пор участвуем в разработке стартапа где трекаются люди в помещениях. Используются почти все техники которые тут упомянуты. Но вес каких-то очень мал. Работает в целом неплохо. Но, конечно, хуже того что человек глазом может.
Что посоветую использовать
Я всегда считаю что простота залог успеха. Мне больше всего нравится SORT. Пока писал статью — написал простой пример того как можно SORT использовать, строчек на 20. Вот тут описание того как оно работает.
Это сработает и для трекинга людей, и для машин, и для котиков.
Если вы хотите залезть в ReID — то проще всего это будет сделать через DeepSort. Но надо понимать, что ReID это огромный мир, вариантов использования масса. Многие из них напрямую не связаны с «трекингом».
Если вам нужно трекать людей очень долго — то советую использовать FaceID-сети, и хорошо ставить камер. Без этого вы обречены на мучения.
Вообще, правильно помнить, что без правильного оборудования трекинг это всегда мучение. Хорошая и правильно поставленная камера >> алгоритма трекинга.
Если вы решили трекать что-то сложное или нестандартное, или захотели сильно повысить точность того что у вас есть — вам придётся использовать большинство описанных техник!
P.S.
Тема трекинга очень большая. Я наверняка что-то забыл. Что-то, может, неправильно написал. Да и примеров не много. Но это всё можно поправить в комментариях! Особенно последний пункт.
