Managing PostgreSQL at Gitlab.com. Jose Cores Finotto
Managing PostgreSQL at Gitlab.com. Jose Cores Finotto.

Большое спасибо! Добро пожаловать на наш разговор о PostgreSQL в Gitlab. Мы поговорим только об основных моментах. И более подробно вы можете узнать на сайте Gitlab.com.

Меня зовут Jose Cores Finotto. Я работаю с командой по инфраструктуре. Я присоединился к команде в сентябре 2018-го года. Сейчас у нас более 45 человек в команде. И Gitlab очень сильно изменился. В мои времена было около 300 сотрудников. Сейчас уже больше 1 000.
Расскажу немного о себе. У меня довольно много опыта в больших компаниях. Всегда работал в инфраструктуре и в реляционных базах данных. И работаю уже больше 10 лет с Postgres.

О чем мы сегодня поговорим?
- Я немного расскажу про Gitlab, про инфраструктуру и сценарии.
- О команде, которая со мной работает.
- Об архитектуре, которая у нас есть.
- Расскажу, что было в начале года и с чем мы заканчиваем этот год. Достаточно много изменений.
- Расскажу о проектах, которые у нас планируются. Расскажу о PgBouncer.
- О Postgres Checkup.
- И о других решения, которые мы внедряем для повышения производительности. Мы рассмотрим их более подробно позже.
Поговорим немного о Gitlab. Кто здесь знает о Gitlab? Кто использует Gitlab? Отлично, очень много людей, я доволен.
Gitlab — это компания, которая разрабатывает решения для того, чтобы облегчить жизнь при разработке программного обеспечения.
У нас есть большое количество фичей, которые очень полезны. Например, CI/CD. У нас есть резервное копирование и еще есть большое количество функций.
В Gitlab у нас есть определенные ценности. И это была одна из причин, по которой я выбрал эту компанию.
Во-первых, мы работаем синхронно. У нас большое количество сотрудников, которые распределены по всему земному шару в разных часовых зонах. И мы редко встречаемся. Но как мы работаем? Мы оставляем на платформе комментарии. И коллеги из других частей мира работают с нами, отвечают нам, добавляют задачи и т. д. И мы таким образом взаимодействуем достаточно эффективно.
В Gitlab мне нравятся совещания. У нас есть всегда Jenda, где каждый записывает свои идеи, о чем мы будем говорить. И если вы не можете принять участие в совещании или вы не можете туда зайти, то необходимо учесть мнение всех.
Касательно результатов, то мы отслеживаем не часы, мы отслеживаем ВМ результат. Т. е. не так важно, во сколько вы закончили работать. У нас есть определенные задачи и необходимо их достичь. У нас достаточно гибкий рабочий график.
Далее. Мы ищем решения и пытаемся найти наиболее простые решения для наших задач. Мы не ищем какие-то решения, которые поставят под угрозу производительность или доступность.
Мы работаем с людьми из разных стран, работаем с различными идеями достаточно успешно.
Еще один пункт — мы стараемся не разрабатывать целый проект сразу. Мы работаем медленно, постепенно и пытаемся интегрировать продукты в наш проект. Мы пытаемся интегрировать изменения и далее двигаться вперед.
Следующий пункт — это прозрачность. В Gitlab у нас есть handbook, guideline компании, где это достаточно хорошо расписано. И все дорожные карты компании, все цели и задачи компании, все, что мы делаем в производстве — все это достаточно прозрачно. Какие-то вещи мы также записываем в Twitter.
И также мы обсуждаем, какова была причина какого-то сбоя. Обсуждаем, что мы можем сделать, чтобы это решить и что можно сделать, чтобы избежать этой ситуации в будущем.

В Gitlab есть две версии. Одна из них самоуправляемая. И для клиентов это open source проект. А также есть поддерживаемые клиенты.
Вторая часть — это Gitlab.com. Это версия для клиентов. И там у нас есть определенная инфраструктура. И, как вы можете видеть, у нас большое количество клиентов, большое количество загрузок.
И, соответственно, это такой вызов для базы данных. У нас 25 миллионов операций (git pull) в день. Больше 3 000 запросов в секунду.
И что мы видим внутри базы данных? У нас порядка 46 000 транзакций в секунду. У нас есть 8 реплик базы данных. И мы работаем с Postgres версии 9.6. Скоро мы проапгрейдимся.
И база данных наша занимает порядка 5 терабайтов.

Теперь я хотел бы поговорить о нашей команде. Я работаю с двумя компаниями, которые много знают о Postgres.
Одна из компаний это https://ongres.com/, которая основана Alvaro. Они работают с нами в production и в проектах, которые мы переводим в production. Это такая операционная работа. И также они участвуют в тюнинге, в настройке производительности и т. д.
Другая компания — https://postgres.ai/. Это Николай Самохвалов. Мы работаем над настройками, над производительностью в целом, над инструментами. И о некоторых инструментах мы поговорим здесь. Эти инструменты для нас очень интересны.
И также мы поддерживаем SRE team. Они поддерживают нас с изменениями. Некоторые из них достаточно сложные. Мы работаем с ними. И у нас очень позитивные результаты от нашего сотрудничества.

О каких проектах я хочу сегодня рассказать? Во-первых, это PgBouncer Saturation. У нас возникали такие проблемы при чтении и записи. Я покажу вам некоторые предложения, которые у нас есть для решения определенных проблем. Например, задержки реплики. Некоторые решения являются очень полезными. Они являются нашими активами.
И также установка Consul. Это DCS, который мы используем для Patroni.
А также инструменты, которые мы разработали для поддержки производительности и доступности базы данных — Postgres-Checkup и Joe bot, например.
Таким образом мы тестируем базу данных и убеждаемся, что производительность будет достаточно высокая при публикации продукта.
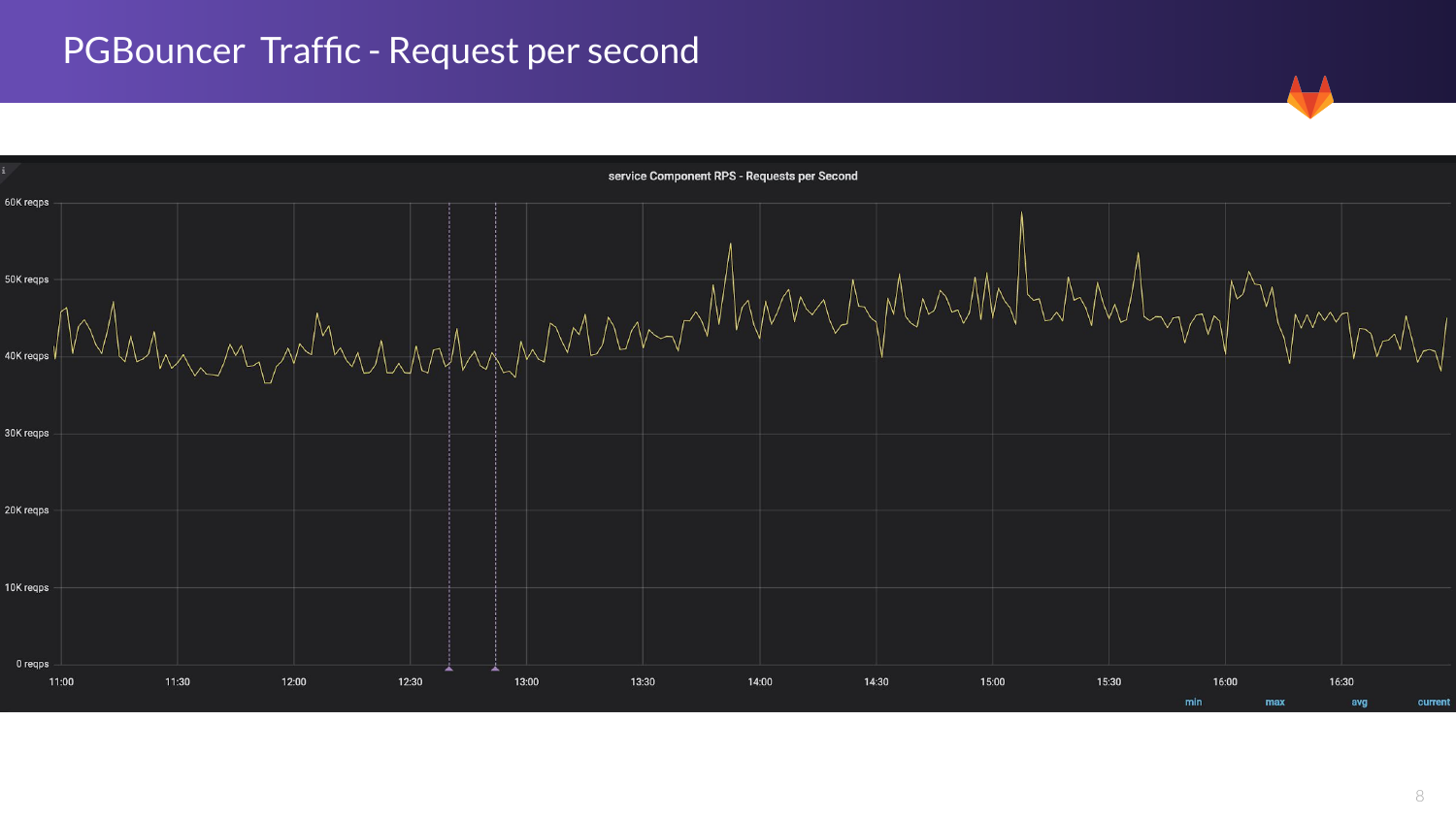
Здесь показан приблизительный трафик, который у нас в базе данных PgBouncer. Я говорю только об основной базе данных. У нас от 40 000 до 60 000. При пике это может быть даже выше, особенно в начале дня в Америке. Это основной пиковый момент, который у нас возникает.
И в нашей загрузке также существует окно для технической поддержки. Это с полуночи до 6 часов утра. Трафик в это время у нас снижается. Также мы иногда это делаем по выходным дням.
С понедельника по четверг у нас есть всегда кто-то в наличии в случае каких-то побочных эффектов. У нас есть много людей, которые могут проверить, в чем дело и посмотреть, что происходит. Миграцию мы также в основном выполняем во время уикенда.
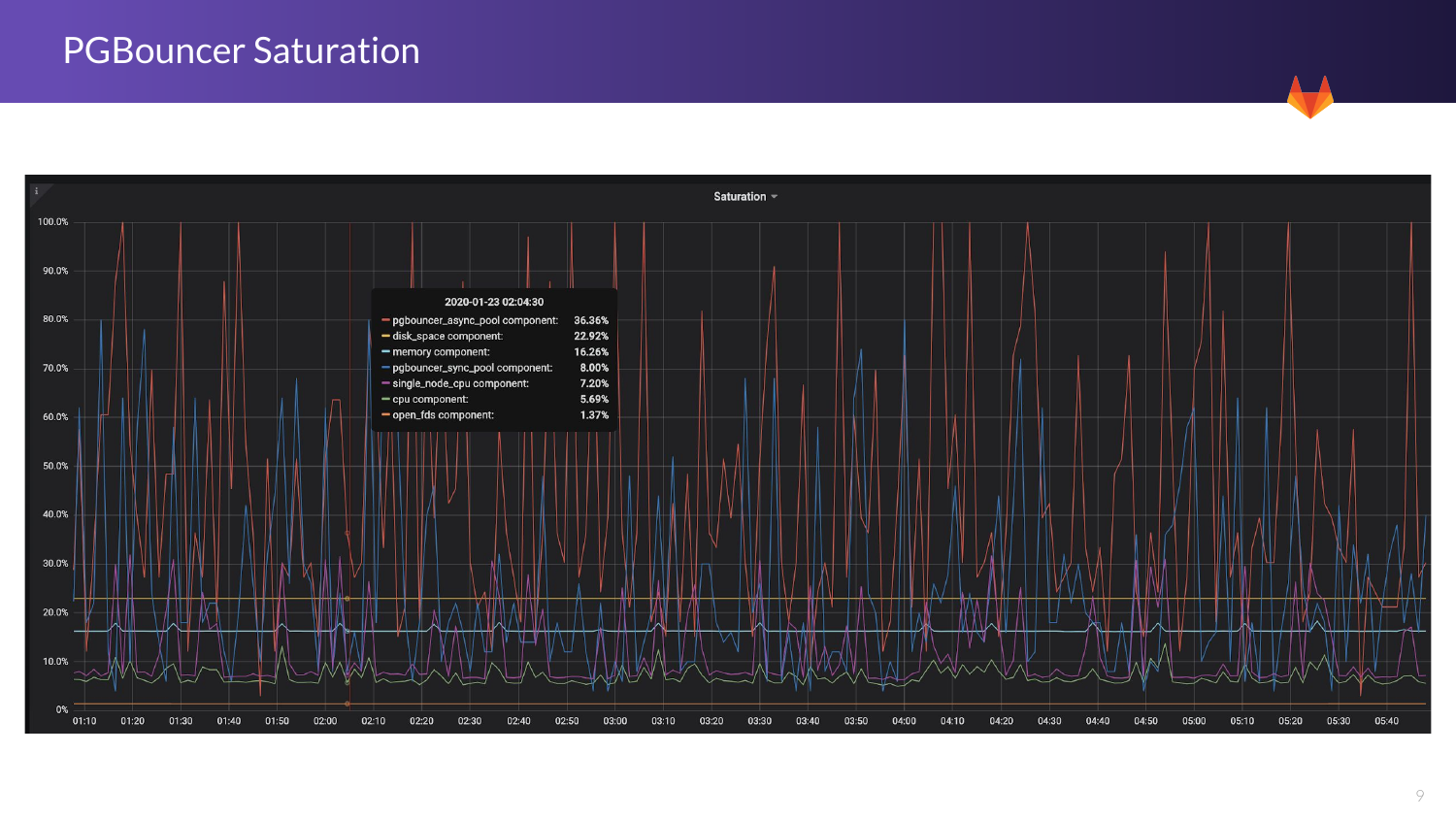
Вот интересный график. Как мы знаем, PgBouncer — это приложение, у которого есть один поток. И при переполнении, когда слишком много на одно ядро запросов приходит (PgBouncer однопоточное приложение) и когда мы достигаем 86% насыщенности, то производительность существенно снижается.
Здесь мы можем видеть красные линии. Это PgBouncer синхронизируется. И синий график показывает уже более контролируемую ситуацию.
У нас есть два типа приложений для трафика. Это синхронные и асинхронные. Синхронные — это API. А асинхронные — это сайт kegjob.
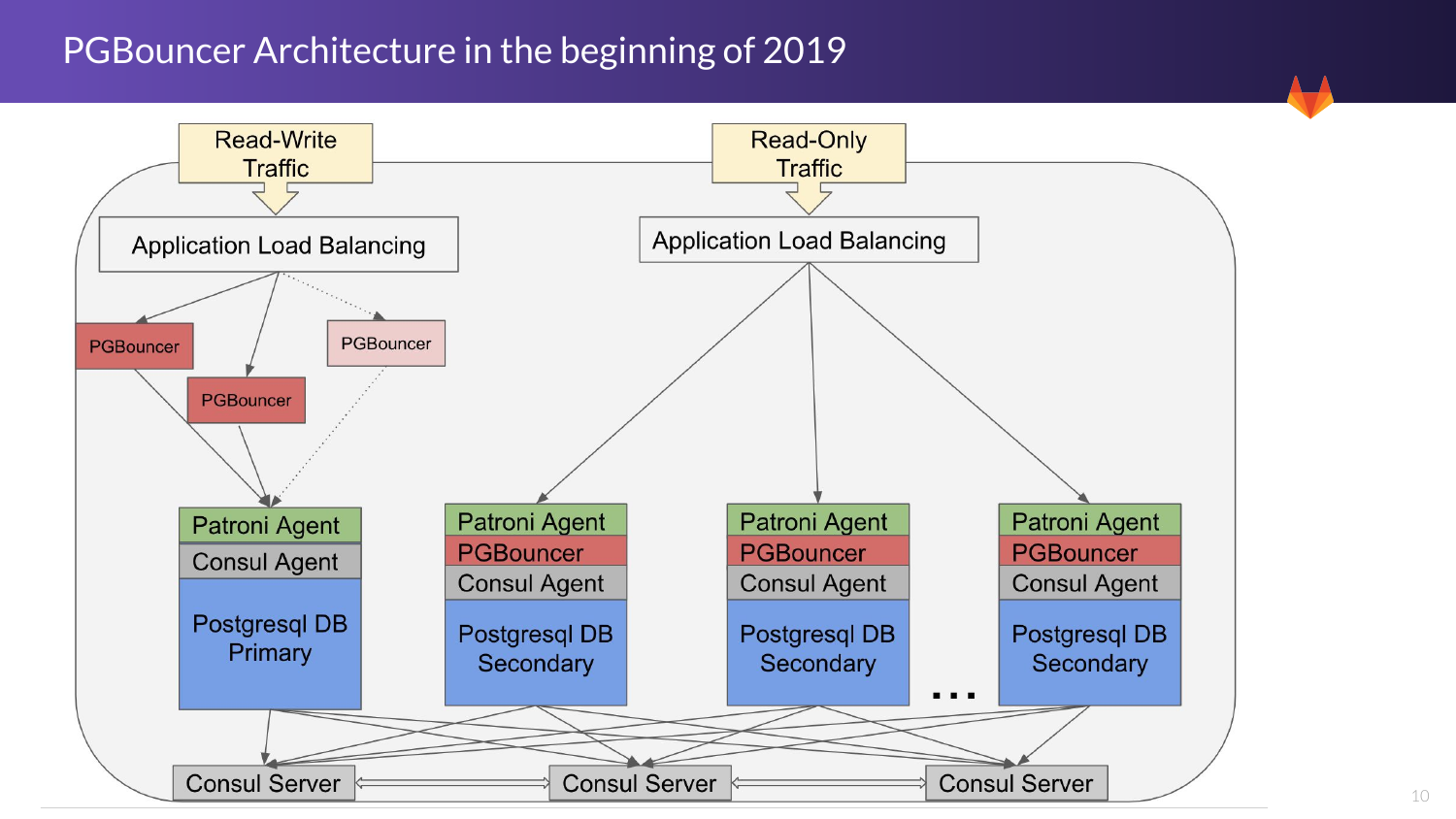
Здесь мы видим архитектуру, которая была в начале года. Начинается только со чтения у PgBouncer. У нас их три для вторичных баз данных. И это неплохо для нас работает пока.
Далее мы переходим к немного другой ситуации. Это механизм archery, т. е. если один из них падает, то другой его подхватит. Это работает также с консолью. И также регистрирует трафик.
Сейчас все пулы работают вместе, они смиксованы. И как только мы обнаружили проблему насыщения, то мы занялись вопросом распределения нагрузки.

И ранее у нас одинаковый пул был везде. А здесь мы видим, что так много соединений в асинхронном режиме нам не нужно. Нам нужно снизить их количество с 80 до 2. И этого будет абсолютно достаточно.
И также у нас есть решения для режима только чтение. Это одно из основных изменений, которые мы сделали для улучшения производительности.
Что касается чтения записи, то у нас есть другой подход. И числа, которые здесь показаны, демонстрируют, что результат достаточно позитивный для нас.

Итак, для решения только чтения в начале у нас в приложении была проблема на уровне приложения. Он мог читать только один PgBouncer хост и только один порт. И нам нужно было несколько хостов и несколько запусков PgBouncer, поэтому эту проблему необходимо было решить. И нужно было как-то разделить трафик, чтобы избежать проблемы насыщения.
И инженерная команда это для нас сделала. Изначально у нас были две ноды на каждую базу данных. И мы получали гораздо лучшую производительность. И когда мы поменяли порты, то все заработало достаточно неплохо. И потом мы добавили третью ноду, и он стал работать достаточно плавно.
Как мы публикуем продукты? Мы добавили PgBouncer, чтобы приложение могло его видеть, а также добавили сервис Consul. И таким образом мы решили вопрос по производительности при операциях только чтение.

Дальше чтение и запись. Стратегия PgBouncer не работала так, как мы ожидали.
Есть два типа пулов, которые у нас были. Они конкурировали между собой и потребляли ресурсы. И работали в основном при синхронном режиме.
Мы решили их разделить. Как это сделать? Самый прямой путь — это создать второй Bouncer. Например, GCP, тогда у нас будет больше PgBouncers для каждого. И мы решили завести три ноды для каждого типа.
И получился достаточно интересный результат. Мы создали Bouncer для внутренней нагрузки и позже мы пофиксили эту ситуацию. Я покажу потом на графике это. И мы замедлили трафик для новых нодов, которые стали использовать новую структуру и новые ноды для Bouncer. Такое техническое обслуживание необходимо для всех хостов, чтобы перезапустить соединение при данной структуре.

Итак, в итоге у нас получилась вот такая архитектура. У нас есть два разных Bouncers загрузки для чтения и записи, три ноды для каждого. HA нам не нужен, потому что даже при падении PgBouncer приложение остается подключенным к той же ноде.
Мы сделали запрос инженерам, чтобы постоянно проверять подключение и перезапускать его при необходимости.
Но даже при этой системе мы можем выжить, потому что PgBouncer перезапускается достаточно быстро. Как правило, у нас проблемы такой не возникает. И здесь мы также видим три запуска PgBouncer на каждой ноде. И сейчас у нас хорошая достаточно производительность при этом наблюдается.

Здесь задержка реплики. Здесь у нас на кластере не приходит никакой трафик. Он получает WAL«ы с небольшой задержкой. Почему это помогает нам? Все очень просто. Когда кто-то совершает ошибку в production, то иногда возникает ситуация, когда в логике что-то случайно удаляется или, например, в приложении что-то удаляется.
Раньше нам приходилось все восстанавливать из бэкапа. Идти в контрольную точку, чтобы восстановиться оттуда. Нужно было смотреть статус, потом пытаться получить экспорт, чтобы понять, какая строка, какая таблица была удалена.
При данной ситуации мы можем просто подключиться к базе данных и найти нужную нам точку. Таким образом мы сохраняем большое количество усилий. Нет необходимости проводить столько работы, как раньше. И мы можем быстро восстановиться в случае какого-то случайного удаления.

При помощи Patroni у нас есть возможность использовать флаги для конфигурации. Каким образом это нам помогает? Без following означает, что нода никогда не станет основной базой данных и никогда не будет получать трафик.
Почему мы не хотим получать трафик? В зависимости от трафика, который приходит на реплику, это может повлиять на репликацию. И таким образом нода будет не лучшим кандидатом. И следует использовать ее как вторичную с целью обеспечения безопасности.
Например, в прошлом у нас были реплики на трафик только чтение. И у нас возникали отказы. Что нам приходилось делать? Мы создавали новый хост, останавливались. Делали его базой данных только для чтения. И потом мы добавляли обратно этот кластер. И у нас деградация в плане производительности на несколько часов, пока нода не вернется.
И вот при таком подходе нода постоянно доступна. В случае какого-то отказа она буквально в течение несколько минут устраняет все проблемы на платформе или в кластере.

Serf checks — https://www.consul.io/intro/vs/serf.html
This issue — https://github.com/zalando/patroni/pull/1364
Установка Consul. Это очень интересно и касается Patroni. Мы используем Patroni уже примерно полтора года. И для нас он вполне себе неплохо работает. Но иногда мы видим определенные отказы. И пытаемся выяснить, в чем дело, почему это произошло.
Если это какой-то отказ оборудования, то это совершенно понятно. Но иногда возникают какие-то ошибки в сети. И в чем тут может быть причина? Как правило переключение на хост. Или мы теряем связь между мастером и DCS. При загрузке мы пытаемся понять, кто у нас будет следующим мастером. И когда первичная нода возвращается, она работает как основная, как и раньше, и ничего не делает. Просто перезапускает все подключения. И мы видим пик в подключениях, потому что нам нужно перезапуститься.
И для обеспечения максимальной доступности для наших заказчиков, конечно, это плохо. Потому что мы не хотим каких-либо прерываний нашего сервиса. И Patroni делает следующее. Во-первых, он проверяет список, чтобы избежать проверок от сервера на клиент. И также мы решили изменить тайм-аут, чтобы увеличить время, которое необходимо для проверки перед тем, как начать перезапуск. И мы получили достаточно позитивный результат в этом отношении. И с этим также были проблемы, о которых говорили разработчики Patroni.

https://gitlab.com/postgres-ai/postgres-checkup — Это один из инструментов, который мы разработали при помощи Postgres.ai. Мы проверяем базу данных. Мы проводим это дважды в неделю. Это проверка достаточно хорошая для нас.
И есть большое количество предложений для того, как можно улучшить базу данных, ее производительность.
Здесь есть три части. Это наблюдение, заключение и рекомендации.
Когда мы говорим о приложении, то оно очень легкое. Проверки никак не влияют на производительность. Они не генерируют сильную загруженность на нашу базу данных. И оно не требует никакой настройки со стороны хоста.
Здесь мы также анализируем загрузку между мастером, primary и secondary. И это очень хорошо, потому что у нас отличаются паттерные запросы в зависимости от того, какой у нас трафик, т. е. это трафик только на чтение или трафик на чтение и запись.

Итак, в Gitlab мы это делаем дважды в неделю. И какие наши преимущества в связи с этим?
- Мы получаем постепенный анализ работы. Мы понимаем, что происходит, какие приходят запросы. Понимаем, какие запросы новые. Иногда разработчики вносят изменения. И иногда разработчики будут использовать ORM. И иногда эти ORM генерируют запросы, у которых не очень хорошая производительность. И мы тогда говорим с ними для того, чтобы это улучшить.
- У нас также есть index bloat. Здесь мы можем еженедельно мониторить то, как это происходит.
- У нас также есть проверка на систему индексов на предмет дубликатов или нерабочих линий.
- И также мы можем анализировать рост наших таблиц. У нас есть некоторые таблицы, которые просто гигантские. И мы смотрим на партиционирование или шардирование.
- И когда мы еще были молодой компанией, мы использовали raw тип даты для тех данных, которые у нас были. И мы дошли до предела. До максимальных данных, возможных на этой базе данных. И поэтому здесь у нас есть очень хорошая подсказка того, сколько времени у нас осталось. И мы постараемся это решить в ближайшие месяцы. Но сначала мы убедимся в том, что наша основная версия Postgres мигрировала, чтобы у нас был минимальный down time.
- Мы можем посмотреть в истории, что произошло месяц назад или 6 недель назад. И мы можем увидеть есть ли у нас паттерны по запросам, которые повторяются или какой именно фикс был применен здесь.
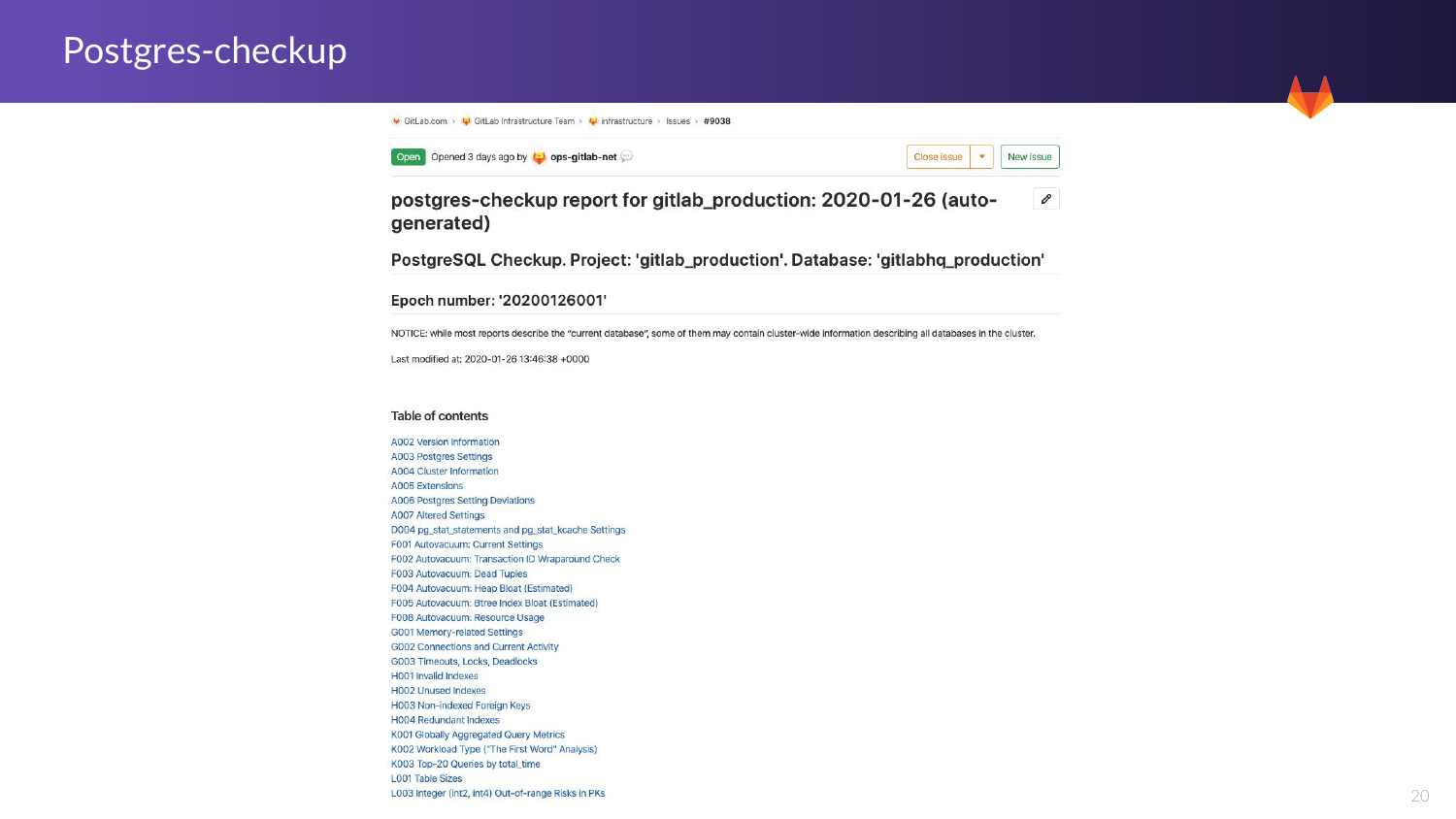
И здесь я бы хотел показать, как мы видим эту проблему в отчетах, которые формируются. И вот здесь вы видите базовый отчет, который был сгенерирован недавно, а именно 26 января. Это настройки и автовакуум с очень детальным объяснением. Вы можете увидеть статистическое заявление, которое я люблю просматривать. Здесь и индексы, и топ-20 запросов за все время. Мне кажется, что это очень круто. Я бы хотел остановиться на этом более детально, потому что мы используем это постоянно с нашими программными разработчиками и инженерами, чтобы показать им, что именно происходит и что мы хотим улучшить.
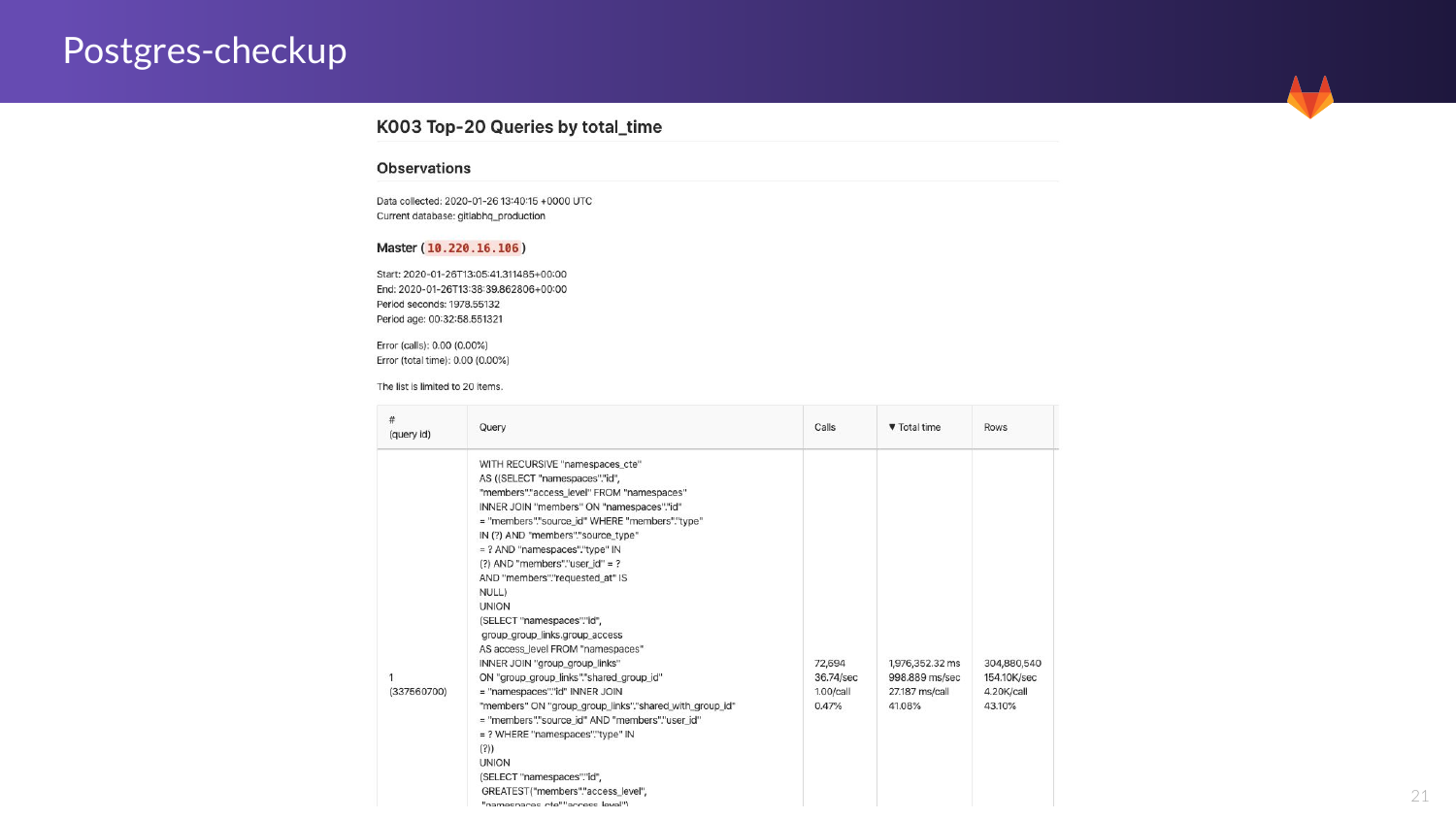
И вот один из примеров. Здесь мы можем видеть запрос. Мы видим общее количество запросов, которые у нас были. Мы это видим в изначальной базе данных. И также видим общее время. Мы видим, что иногда некоторые запросы могут быть очень энергозатратными на своих хостах.
А сейчас я расскажу о двух инструментах, которые мы используем для того, чтобы это собирать. Это Database Lab и Joe bot.

https://gitlab.com/postgres-ai/database-lab
Для чего мы его используем? Мы его используем для того, чтобы создавать реплику из живого environment. Мы используем его для того, чтобы сгенерировать копию и воспроизвести очень похожую среду, которая у нас есть на production.
Мы все знаем, что если вы выполните запрос с двумя таблицами, и если вы сделаете что-то с двумя рядами, то результаты будут отличаться. Поэтому иногда разработчики создают фичу и проверяют ее только в каких-то маленьких условиях. Но когда мы тестируем это на больших массах, то мы обнаруживаем, что там могут быть проблемы с тем, как она будет расширяться.
И что мы делаем при помощи Database Lab? Он генерирует реплику примерно за 2 секунды. И нас получается уже нормальная выборка данных, чтобы мы могли проводить тестирование. И здесь у каждого разработчика или инженера может быть своя собственная, т. е. получается, что у каждого человека может быть своя проба с запросами, даже если он генерирует lock«и или делает сканы, то он не влияет на других пользователей. И мы думаем, что это очень хороший подход.

У нас есть Joe bot — https://gitlab.com/postgres-ai/joe. Это решение, которое у нас есть. У нас есть канал, который внедряет эту базу данных, которую мы создаем с Database Lab и с Joe bot. Я сейчас постараюсь это объяснить. Это достаточно широко распространено среди наших разработчиков. У нас более 17 разработчиков, инженеров, которые это используют. И это позволяет нам устранять проблемы, проводить оптимизацию и делать предложение о том, как лучше это оптимизировать.
И давайте я дам вам общее представление о том, как это работает и о том, как мы это используем.

Все достаточно просто:
- Инженеры дают нам SQL.
- Joe запускает сессию внутри базы данных, которая специально была для него создана.
- И вы дальше включаете это приложение с буфером, который анализирует.
- А потом получаете это всё со всеми рекомендациями.
И это часть магии, которую Joe выполняет за нас.
Давайте я вам покажу более практический обзор того, как это работает. Но сначала я хотел бы поделиться документацией всего этого проекта.
https://about.gitlab.com/handbook/engineering/infrastructure/library/database/postgres/query-optimization-bot/design/
https://about.gitlab.com/handbook/engineering/infrastructure/library/database/postgres/query-optimization-bot/blueprint/
У нас есть design и есть blueprint. И в blueprint мы определили в чем заключается идея и что мы хотим разработать. И это распространенная практика в Gitlab. А в design мы уже в деталях рассматриваем каждую идею того, как мы внедряем и почему мы сделали так, а не иначе.
И здесь мы это сделали в обоих документах. И мы показываем, как мы стараемся помочь разработчикам иметь пространство для того, чтобы они имели возможности тестировать свои наработки перед тем, как пускать их в production.
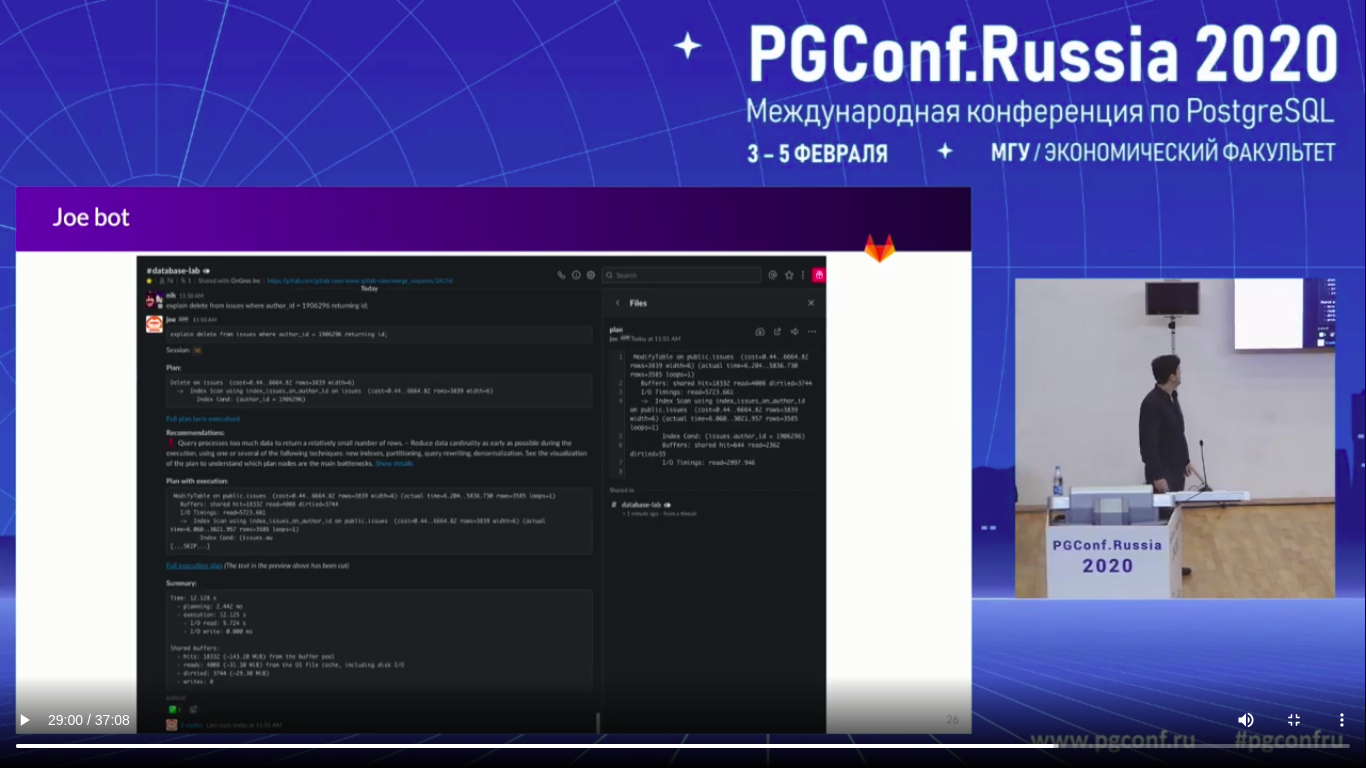
(Слайда нет, поэтому скриншот)
И вот здесь очень явный пример того, как это работает. Вы ставите объяснение, потом рекомендации. И если вы нажмете на план с большими деталями, то их вы увидите. Это прошлый случай, один из кейсов, который у нас был. И также есть коротка сводка. И также там есть информация о shared buffers.
Для нас это достаточно полезно, потому что мы используем это. И с тем пор, как мы это используем, у нас стало меньше проблем с выкатами на уровне инжиниринга.
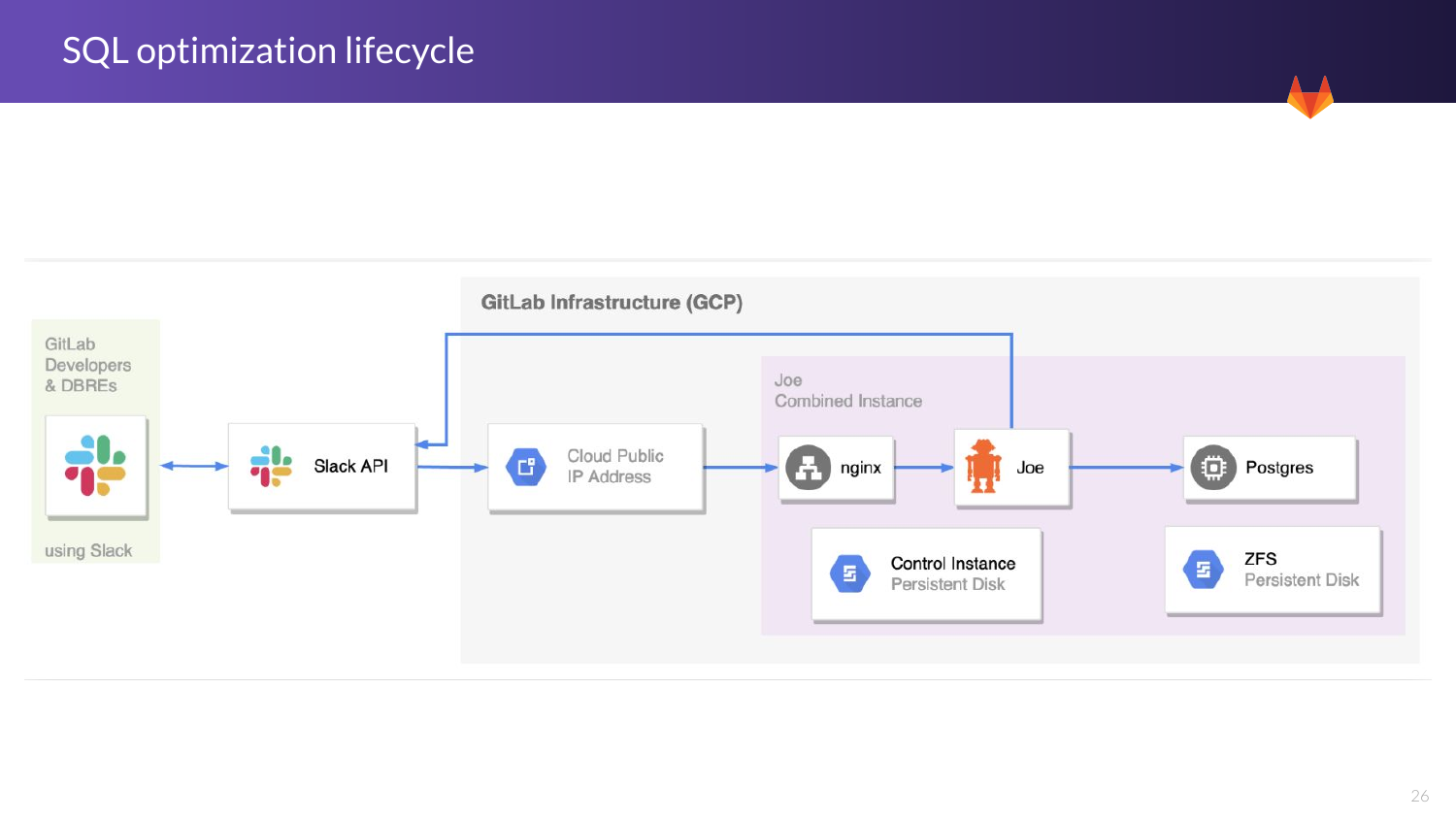
И здесь вы видите цикл оптимизации жизненного цикла. Это небольшой график того, что мы делаем в Gitlub. Мы используем Joe bot, мы используем ZFS, мы используем Postgres. И также интеграция с API, которая есть между разработчиками. Мы используем Joe bot, а те в свою очередь используют Database Lab. И мы видим весь жизненный цикл. И это доступно, это open source.
Вопросы:
Я задам вопрос. Мой первый вопрос. Почему вы выбрали использовать ZFS вместо, например, каких-нибудь нативных решений, например, ORM?
Мы ZFS используем для генерирования Database Lab, потому что это просто быстрее.
Мы можете сказать, насколько это быстрее, чем LVM? Поделитесь числами.
Да, я, по-моему, упоминал уже. Мы способны восстановить базу данных за 2 секунды в 5 терабайтов. А когда мы использовали LVM, надо было гораздо больше времени, когда мы тестировали.
Спасибо за ваше выступление! И я хочу спросить вас о Postgres.ai. Хотели бы вы немного рассказать о том, как 5 терабайт базы данных могли быть сканированы за 2 секунды?
Мы говорим, что у нас есть снапшоты. И мы их способны восстановить за 2 секунды. Так что мы можем сгенерировать нашу среду. У нас есть снапшот нашей базы данных. И в том случае, о котором мы говорим, у вас может быть готовый environment, и вы уже можете синхронизировано ее восстановлять. И потом у вас это будет доступно достаточно быстро. Это одна из причин, по которой мы используем ZFS снапшот для этого.
У меня есть вопрос о безопасности тех ваших клиентов, которые пользуются Gitlab, когда вы добавляете снапшоты в ваши эксперименты.
Если говорить по поводу безопасности, то у нас есть протокол безопасности. Т. е. мы не оставляем никаких данных о клиентах или о самом проекте. Это внутренний процесс, который проходит. Это то, как мы решаем проблему с безопасностью.
Могли бы вы пару слов сказать, в чем слабые стороны того, когда проводите переменные в Consul? Т. е. когда вы убираете чеки и когда вы повышаете тайм-аут до 60. А что, если Consul-агент не будет иметь соединения с кластером?
Да, хороший вопрос. Если мы уменьшаем тайм-аут, то у нас начнется failover и нам придется ждать TTL. И это самая слабая сторона, потому что у вас есть 90 секунд, и если мы туда продвинем, то у нас получится failover. И здесь выбирать: либо то, что есть сейчас, либо нам нужно перезапустить все наши read only, или нам нужно убедиться, что мы уважаем наш TTL и вместо того, чтобы у нас failover был через 30 секунд, я буду увеличивать это на 60 или даже на 90 секунд. И только затем я включу failover. И учитывать, какое количество раз мы видели failover. Мы увидели только один раз и нам тогда больше внимания надо было на TTL. Но мы выбрали, чтобы у нас оставались такие настройки для того, чтобы мы могли избегать как можно больше glitch.
А второе — это про проверки. Обратная сторона — это то, что мы не проводим проверки со стороны Consul сервера в клиенте. И поэтому мы используем DCS — как наше решение.
Большое спасибо за вашу презентацию! Исследовали ли вы причину, почему PgBouncer плохо работает?
Дело не в том, что он плохо работает. А просто у PgBouncer«а есть единый поток, поэтому он достиг своего потолка. И, возможно, это можно было улучшить, если мы улучшили производительность ядер, которые есть. Это одно из того, что мы используем. Но в DCP у нас ограниченные возможности того, что мы можем использовать. И это ограничение железа. Это не производительность PgBouncer«а. Но в последней версии PgBouncer«а мы думали о том, что мы можем использовать больше количество интернет-процессов, больше портов. Поэтому вы могли бы использовать большое внутренних процессов PgBouncer«а.
Если мы начали говорить о PgBouncer«е, то я бы тоже хотел задать один вопрос. Я смотрел на эту ужасную map PgBouncer«а. Рассматриваете ли вы возможность для того, чтобы провести тест, используя Odyssey, как замену?
Да, мы проводим тест уже некоторое время. И мы находимся с ними на постоянной связи. И мы встречаем некоторое неожиданное поведение. И мы сейчас решаем проблемы.

