Сага о SEO, часть 1: серверный рендеринг
Наверняка хотя бы раз в жизни вы или ваши знакомые в поисках приятного досуга на вечер обращались к Яндексу или Гуглу с запросами вроде «кино онлайн бесплатно» или «смотреть сериалы 2021». Если так, не стоит стесняться, вы такой не один, с подобными запросами в Яндекс, например, обращаются несколько миллионов человек в месяц. При этом, скорее всего, как и большинство пользователей с таким запросом, вы не имеете преференций относительно того, где вам этот контент покажут, и перебираете ссылки в выдаче сверху вниз, пока не найдете устраивающий вас ресурс. А значит, владельцы этих ресурсов максимально заинтересованы в том, чтобы
быть как можно выше в выдаче по релевантным запросам
можно иметь более высококачественный продукт, чтобы пользовательский «перебор», дойдя до их ресурса, на нём же и остановился
Второй пункт, очевидно, очень сложный, и зависит от многих факторов, о нем мы поговорим в третьей части статьи. А комплекс мер, направленных на достижение первой задачи, традиционно называется SEO (Search Engine Optimization), и это — относительно древнее уже по современным меркам знание. Причем знание это близко к оккультному, преисполнено мифами и легендами, поскольку ни один поисковый движок никогда не раскрывает алгоритмов и принципов своей работы, ограничиваясь лишь общими рекомендациями. Однако, те, кто занимаются этим самым SEO, эмпирическим методом обнаруживают факторы влияния на поисковую выдачу. И, если лет 10 назад наиболее значимым фактором была цитируемость (ссылки на сайт на других ресурсах, особенно — популярных и объемистых), то за последние годы практически все крупные игроки поискового рынка сошлись на том, что сайт хорош для поисковой системы, если он хорош для пользователей.
Меня зовут Александр Усков, я ведущий разработчик more.tv, в этом посте я расскажу, как мы в НМГ работаем с SEO. Возможно, ряд советов пригодится и вам, вне зависимости от тематики вашего ресурса.
Итак, введя в Яндекс или Google вышеупомянутые запросы, вы с большой вероятностью обнаружите в выдаче (скорее всего, даже на первой странице) некоторые ресурсы активов НМГ, например more.tv и ctc.ru. На данный момент до 90% трафика на этих сайтах приходит из поисковых систем, и суммарно речь идет об аудитории порядка 100 млн уникальных пользователей в год, причем за последний год это число увеличилось практически вдвое. 80% страниц сайта more.tv находится в топ-10 результатов выдачи Яндекса по релевантным запросам, а около 40% — в топ-3. Наша техническая команда проделала огромную работу, чтобы этого добиться, и мы хотим поделиться некоторыми наблюдениями, которые мы извлекли в процессе развития данных продуктов.
Предыстория и решаемые задачи
Сайт more.tv является правопреемником почившего OTT-сервиса videomore.ru, который на момент своего закрытия в 2019 году существовал в интернете более 10 лет, накопил огромную пользовательскую базу, заработал «авторитет» у поисковых систем и занимал лидирующие позиции в поиске. На запуске more.tv мы хотели максимально сохранить и то и другое, хотя было понятно, что на 100% это сделать не удастся — для ПС слишком большой «стресс», когда один сайт целиком превращается в другой, и есть масса причин понизить его в выдаче:
вместо старого домена с историей и кучей ссылок в интернете появляется новый, не имеющей практически никакой ссылочной массы
в значительной степени меняется содержимое страниц, включая даже саму структуру разметки
скорее всего, меняется большая часть URL
какие-то разделы сайта вообще не появятся в обновленной версии.
Для постоянных пользователей сервиса этот процесс тоже доставляет некоторые неудобства, так как у кого-то из них сохранены в закладках адреса их любимого контента, кто-то заходит по ссылкам из истории браузера или мессенджеров, ну и просто люди, понятное дело, привыкли к продукту в том виде, в каком он существует. Мы поставили себе задачу сделать переход с videomore на more.tv максимально комфортным для пользовательской базы, чтобы вызвать минимальный эффект «шока» у тех, кто в один прекрасный день зайдет на свой любимый видеосервис, а окажется, как ему может показаться, на совершенно другом сайте.
Немного теории
Поисковая система (ПС) ставит своей целью показать пользователю наиболее релевантный контент по его запросу, поскольку это повышает лояльность пользователя к поисковой системе со всеми вытекающими последствиями. Но что значит «релевантный» — вопрос очень неоднозначный. Изначально (и по сей день) поисковые системы анализируют, в первую очередь, содержимое сайта, чтобы понять, о чем он вообще и по каким запросам он будет актуален. Но со временем, как и в остальном мире, аналитический подход уступает место феноменологическому, — вместо того, чтобы проводить машинный анализ текста, куда полезнее для оценки этой самой «релевантности» проанализировать поведение пользователей. Ведь достаточно очевидно, что если пользователь, введя поисковый запрос и перейдя по ссылке на некий ресурс из поиска, сразу же закрыл страницу и ушел с сайта, — скорее всего, он не нашел того, что хотел, а, значит, поисковая система должна считать данный ресурс менее релевантным данному поисковому запросу.
И наоборот, чем активнее и чаще пользователи, перешедшие из поиска, пользуются сайтом, тем он полезнее для этих пользователей. На самом деле, разработчики ПС всегда к этому стремились, но у них не было достаточно инструментов для сбора этих данных. Теперь же, когда у Яндекса и Гугла свои сверх-популярные браузеры (суммарно 60% рынка РФ, например), системы мониторинга (Метрика и Analytics) и рекламные сети (AdSense и Директ), которые стоят практически на каждом сайте в интернете, — можете не сомневаться, эти компании знают о вашем поведении в Сети все, что нужно знать.
Таким образом, команды разработки сайтов, которые заинтересованы в привлечении поискового трафика, вынуждены постоянно держать в фокусе внимания те аспекты работы их приложения, которые могут повлиять на пользовательский опыт, на вовлеченность пользователей и, например, на быстродействие самих сайтов, поскольку медленная загрузка страниц является одним из самых значительных драйверов отказов, которые не только негативно влияют на продуктовые метрики, но и пессимизируют сайт в выдаче ПС. Но никуда не делась и контентная часть поисковой оптимизации, поэтому не менее важно и обеспечить ПС возможность быстро, корректно и постоянно индексировать сайт, а также корректно его интерпретировать.
Несмотря на развитие новых технологий, вроде машинного зрения и интеллектуальных систем NLP, главным источником информации для ПС о содержимом сайта все еще является его HTML-код. О том, что можно сделать с HTML-кодом, чтобы польстить поисковым системам, мы поговорим во второй части этой статьи. Пока же обсудим, как решаются более фундаментальные проблемы, вроде безошибочной индексации сайта и скорости загрузки страниц.
Поисковики обходят сайты по-разному, у них есть несколько разных краулеров, некоторые из которых явно дают понять, что они пришли из той или иной ПС, а некоторые — наоборот, притворяются «настоящими» пользователями с полноценным браузером, в том числе и мобильным. Иногда они заходят всего на несколько страниц, иногда — пакетно загружают целый фрагмент сайта, иногда — сканируют его медленно, но непрерывно, по кругу обходя все имеющиеся URL. Но во всех случаях они пользуются стандартными механизмами работы интернета, в частности, протоколом HTTP. Поисковик выполняет GET-запрос на целевой адрес, получает в ответ «что-то» и пытается на основании этого принять какие-то решения. В первую очередь, имеет значение код ответа, семантика которого позволяет определить текущее состояние запрошенного URL — есть ли он вообще, какая у него функция, добавлять ли его в индекс или нет. Яндекс и Google немного по-разному обрабатывают статусы, но есть и общие принципы:
у «здоровых» страниц код ответа должен быть 200 или хотя бы 2xx
время ответа сервиса не должно превышать некую достаточно консервативную величину, порядка 5 секунд, чтобы Яндекс посчитал страницу живой и достойной индексации
постоянные редиректы с кодом 301 «передают» свой вес (скорее всего, с понижающим коэффициентом) в алгоритме поисковых систем тому URL, в адрес которого идет редирект
страницы с кодами ответа 4xx и 5xx (за некоторым исключением) удаляются из индекса
Последнее особенно неприятно; представьте себе: на видеосервисе выходит новый хитовый проект, на него ожидается высокий трафик, сервис находится под нагрузкой, и в этот момент на страницу этого проекта решит заглянуть Яндекс. Если он получит, например, классический 504 (Gateway Timeout), не говоря уже про таймаут запроса, то он выкинет эту страницу из индекса, и в последующие несколько дней количество людей, которые смогут найти этот контент на сервисе, значительно сократится.
Предполагаемый великий успех может легко обернуться эпическим провалом на ровном, казалось бы, месте. Такой же результат будет, если по каким-то причинам сервис при запросе Яндекса сломается и вернет 500. Однако, в ходе наших исследований мы обнаружили, что Яндекс толерантен к коду 503 (Service Unavailable), и, если сервис не возвращает его для одного и того же URL регулярно, то за «разовые» отказы в обслуживании штраф в виде исключения из индекса не полагается. Таким образом, во всех сценариях, когда невозможно предоставить контент ПС, наиболее благоприятным из возможных вариантов выглядит вернуть им именно этот код ответа.
Если же код ответа сервера 200, то поисковая система парсит содержимое ответа и каким-то, известным только ей образом, помещает страницу в индекс и ранжирует ее по тем или иным запросам. И это все прекрасно работало во времена Web 1.0, когда запрос каждой страницы возвращал «финальный» вид страницы целиком, ее полный HTML код, и, по сути, поисковая система получала ровно тот же контент от сайта, что и пользовательский браузер. Но в наши дни в интернете безраздельно властвуют frontend-фреймворки React, Vue и Angular, а сам способ наполнения сайта контентом изменился радикально.
Специфика SPA
До 50% всех веб-приложений на настоящий момент представляют из себя Single Page Application, то есть содержимое такого сайта формируется непосредственно на клиенте при помощи Javascript, а без него страница представляет из себя «шаблон», в котором практически нет ценной для пользователя и ПС информации, и который, в большинстве случаев, у всех страниц сайта одинаков.
Таким же приложением был и сайт more.tv на момент своего рождения, и нас (как и практических всех SEOшников в рунете) очень волновал вопрос, может ли ПС исполнять Javascript и насколько успешно. Смогут ли Яндекс и Google корректно проиндексировать страницы сайта, построенного таким образом?
Изучение предыдущих кейсов дало противоречивые данные: у каких-то сайтов это работает лучше, у каких-то хуже, но практически никогда — правильно, и от чего зависит — непонятно. Поэтому мы провели свой эксперимент, «скормив» Яндексу и Гуглу несколько не особо значительных страниц будущего сайта (куда мы добавили уникальную тарабарщину для последующего поиска) и понаблюдав пару недель, как они отображаются в индексе. Результаты были неутешительны — в то время, как Google, по всей видимости, не испытывал никаких проблем и находил наши экспериментальные страницы по заданной нами тарабарщине, Яндекс отображал эти страницы как пустые, — в том виде, в котором их отдает сервер. Из этого явным образом вытекала необходимость SSR — серверного рендеринга страниц, чтобы отдавать Яндексу уже готовый HTML-код в том виде, в каком его, в конце концов, видит пользователь сайта.
Особую пикантность ситуации придавал тот факт, что, поскольку нам было нужно перенести огромное количество контента (более 50 000 страниц) со старого сайта на новый, это не представлялось возможным сделать в ручном режиме и составить «карту сайта» со списком всех страниц, а схема данных и вытекающая из нее схема роутинга, которую нам нужно было реализовать, весьма сложна и максимально неудобна для поддержки на клиенте, так как требует обращения к большому количеству источников данных, в том числе — недоступных публично. Для понимания сложности этого процесса можно просто оценить блок-схему генерации URL на more.tv для всего лишь одной (хоть и, по сути, самой главной) сущности в модели данных сайта — видеотрека:

Кроме того, контент постоянно публикуется или депубликуется (например, из-за истечения прав на показ), и список фактических доступных страниц сайта пришлось бы обновлять практически непрерывно, если бы мы захотели собрать его целиком. А это значит, что предоставлять контент и поисковым системам, и людям мы должны в реальном времени, в зависимости от текущего состояния того URL, который они запрашивают. Поэтому роутинг сайта more.tv с самого начала и по сей день является серверным, то есть сайт при запросе любого URL обращается в особый сервис (в more.tv он исторически называется PageData), который в реальном времени предоставляет декларативную информацию об URL, его ключевом содержимом, топологии страниц и и наиболее критичной для ПС мета-информации страницы — title, description, keywords и h1, а само веб-приложение more.tv — это «тонкий клиент», который всего лишь отрисовывает страницу на основе этой информации. Конечно, за прошедшие с запуска сервиса 3 года, многое изменилось, и сейчас more.tv уже не совсем «одностраничное» приложение, но на тот момент оно работало по такой схеме.

Об SSR в интернете написано немало, но недостаточно :) Его реализация сильно зависит от используемого стека технологий, имеет ряд ограничений, а заявления о том, что это безусловно ускоряет время загрузки страниц сайта для пользователя, на наш взгляд, несколько наивны и идеалистичны. Процесс загрузки веб-приложения весьма неоднороден и извилист, и есть масса нюансов, которые могут повлиять на скорость загрузки в ту или иную сторону.
Вы наверняка обратили внимание на цифры 1–2–3 на диаграмме выше, пришло время разобраться, что они символизируют. Если посмотреть на waterfall-диаграмму загрузки любой страницы в отладчике Chrome, в разделе Network, можно увидеть, что даже процесс доставки контента от сервера до браузера состоит из нескольких этапов

Все то время, что клиент ждет данных с сервера (Waiting for server response), называется Time To First Byte (TTFB), и на диаграмме этап загрузки, соответствующий этому времени, обозначен цифрой 1. Цифрой 2 обозначено время, в течение которого загружаются и выполняются вторичные ресурсы, на которые ссылается страница, прежде всего — клиентский javascript-код и точечные запросы в API за данными, без которых javascript не может сгенерировать HTML код текущей страницы. В сумме с TTFB это время образует еще одну метрику — First Contentful Paint (FCP). На этом этапе страница уже пригодна для потребления поисковым роботом, так как все ссылки, вставленные непосредственно в HTML, робот уже вполне может обработать и пропарсить самостоятельно, в отличие от выполнения кода, который этот HTML формирует.
И, наконец, когда HTML страницы сформирован клиентским кодом, загружаются CSS и мультимедийные ресурсы (на схеме — цифра 3), после отображения которых страница начинает выглядеть «понятно» для человекоподобного пользователя. В сумме с предыдущими двумя временными отметками образуется метрика Largest Contentful Paint (LCP), и это одна из ключевых метрик Core Web Vitals, придуманных Google для оценки производительности страниц, которая, как уже было упомянуто, напрямую влияет и на поисковые позиции, не только в Google. Все эти метрики можно пронаблюдать в отладчике Chrome в разделе Performance, или в специальном сервисе для анализа показателей загрузки страницы — Google Lighthouse или Google PageSpeed.
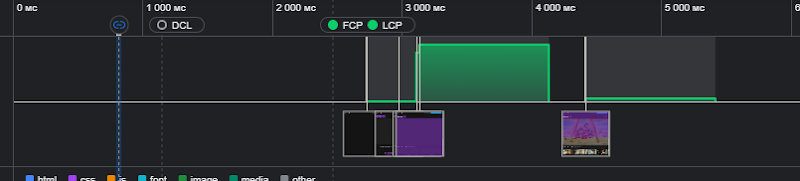
Что происходит, если в схему загрузки добавляется механизм SSR? По сути, какая-то часть клиентского кода (или его аналог) выполняется на сервере, вместо клиента, и в ответ на запрос выдается уже готовый, понятный поисковикам, HTML код, который, однако, обогащен дополнительной информацией, которая нужна клиентскому SPA-коду, чтобы запуститься с «промежуточного» состояния, вместо того, чтобы рисовать всю страницу с нуля. При этом клиентский код все еще должен выполниться для корректной работы приложения, но пользователь уже увидит какую-то разметку, его браузер начнет загружать мультимедиа и зависимые источники, и в итоге время той самой заветной метрики LCP, в теории, сокращается. На практике же в этом процессе есть ряд условий, которые могут оказать решающее влияние на то, будет ли SSR действительно выигрышным с точки зрения временных метрик по сравнению с рендерингом на клиенте.
Независимо от выбранного решения, достаточно очевидно, что процесс SSR занимает некоторое время и некоторый ресурс кластера, и это дополнительное время, как было сказано выше, может вылиться в пользовательский отказ, а ресурс кластера, само собой, повлечет дополнительные расходы на инфраструктуру. Первая проблема, казалось бы, должна решаться кешированием, но кеширование, как известно, — одна из двух самых сложных вещей в программировании, наряду с именованием переменных. Например, требуемая страница может содержать некий контент, который уникален для пользователя, который ее запрашивает, и подходящего кеша может просто не найтись, а будет ли выполнение кода на сервере быстрее, чем на клиенте — вопрос неоднозначный, ибо зависит и от клиентского оборудования, и от серверного, и от загрузки сервиса в момент запроса, и от эффективности утилизации ресурсов браузером, и еще от ряда конъюнктурных обстоятельств. С точки зрения временных метрик, SSR — это перенос вычислительной сложности с участка FCP (цифра 2 на схеме) на участок TTFB (цифра 1 на схеме), и, по большому счету, только наличие серверных кешей может сделать эту операцию действительно целесообразной, — если результат SSR закеширован, то TTFB не должен отличаться в обоих случаях в рамках одной и той же инфраструктуры, а FCP и LCP радикально сокращаются. Будет ли это работать точно так же, если кеша нет совсем — в общем случае ответ «нет». А истина, как обычно, где-то посередине.
Кроме того, если серверный рендеринг и клиентский отличаются кодовой базой (а как правило, в классическом SSR так и есть, хотя некоторые решения за счет предоставляемых абстракций создают иллюзию, что это не так), то они в принципе могут работать совершенно не эквивалентно ни по времени, ни по результату, ни по количеству и характеру ошибок. Есть ряд фреймворков для Javascript, которые эту проблему во многом решают, но, чаще всего, они должны быть внедрены в стек разработки с самого начала, чтобы быть эффективными. С недавних пор сам React, который является основным фреймворком, используемым в наших решениях, умеет делать серверный рендеринг, но на тот момент такой роскоши у нас не было.
Добавим к этому «шкурный» аспект: наши продукты — это сервисы с миллионной аудиторией, и даже копеечная экономия ресурсов кластера, помноженная на миллионы хитов в сутки, превращается в весьма солидные суммы, увеличивающие ROI продукта, в то время как за процессорное время пользователя мы не платим :) Звучит, возможно, цинично, но это, на скромный взгляд автора, — одна из главных причин, почему расцвет Frontend-технологий случился примерно одновременно с популяризацией коммерческих облачных решений, где надо платить практически за каждый лишний такт процессора и килобайт трафика — выносить максимум логики на клиент стало коммерчески оправдано, а производительность пользовательского оборудования стала позволять делать в браузере то, о чем раньше даже и помыслить было нельзя. К сожалению, плохой код и медленные сайты от этого никуда не делись, но это, как говорится, совсем другая история.
Агностический SSR
Одновременно с запуском more.tv шел процесс разработки нового сайта телеканала СТС, который тоже переезжал с монолита на современный стек, включая React, и стало понятно, что мы столкнемся, как минимум, с теми же проблемами с Яндексом, что и в случае с Морем, — он не сможет пропарсить содержимое страниц, если мы их не отрендерим для него на сервере. При этом у ctc.ru совершенно другая кодовая база, принципиально иная архитектура и инфраструктура, хотя на клиенте тоже используется React. Внедрить какое-либо из существующих SSR решений для Javascript туда было бы совсем сложно, и мы пошли путем, который позволяет решить эту проблему раз и навсегда, — сделать серверный рендеринг, который не зависит от стека и кодовой базы приложения. Помог нам в этом терминальный (headless) браузер Chrome, а точнее, — его контейнеризованная версия от Google под названием Rendertron. По сути, это самый «честный» способ получить отрендеренную версию страницы, потому что, по факту, он запускает абсолютно то же приложение, которым пользуются живые посетители сайта, и ему абсолютно все равно, на чем это приложение написано. Если ваш код корректно работает в браузерах на основе Chromium, — этого достаточно, а представить себе сайт, который не оптимизирован под самый популярный браузерный движок на планете, довольно тяжело.
Сложность, однако, таится в другом месте — рендеринг страницы в headless chrome занимает некоторое время, а именно, — не меньше того времени, которое обозначается метрикой LCP. При этом рендеринг страницы — процесс неатомарный, разные ее части могут отрисоваться в разное время и в произвольном порядке, так как данные грузятся с различных источников. Поскольку под капотом rendertron использует Mutation Observer, чтобы определить, «готова» ли страница, то по факту он ждет еще чуть дольше, пока загружаются совсем уж малозначимые для конечного пользователя ресурсы где-то там, за пределом видимой области экрана, например. Поэтому, отдавать страницы «на лету» с использованием такого инструмента не представляется возможным, а значит, надо использовать классическую технику оптимизации и готовить сохраненные копии страниц заранее, мы называем это пререндеринг. Вот только как определить, когда это «заранее» наступает?
В первом приближении, мы решили готовить кеш отрендеренной страницы сразу после ее публикации или редактирования зависимой сущности. Это не идеальное решение, потому что на странице могут использоваться виджеты, которые зависят от других сущностей: например, на сайте добавился новый сериал, и этот сериал должен появиться в подборках, которые раскиданы по сайту нетривиальным образом, и в разделе со всеми сериалами, который еще и побит на страницы. Или, например, если редакция по каким-то причинам решила поменять название сериального проекта после его публикации, то это изменение повлечет за собой необходимость обновить страницы всех серий, сезонов, рецензий и съемочной группы этого сериала. Но такое решение закрывает наиболее болезненные кейсы:
При публикации нового проекта или видео, ПС должна как можно быстрее получить актуальные изменения в содержимом сайта
При депубликации существующего проекта, ПС должна как можно быстрее выкинуть из индекса его страницы
Так появился один из микросервисов в экосистеме more.tv, — Leviathan.
прим.: в команде разработки Моря принята конвенция именования микросервисов именами мифических существ или локаций, предпочтительно — морских :)

Сервис написан на nodejs, что позволяет ему переиспользовать часть имеющейся кодовой базы сайта, а механизм его работы, в целом, достаточно прост:
Редакция того или иного сайта редактирует какой-либо контент через доступную им CMS (систему управления содержимым)
CMS публикует сообщение в брокер очередей RabbitMQ с указанием операции (update / delete) и URL страницы, которую необходимо обновить, а также, в простых случаях, генерирует аналогичные сообщения для наиболее критичных страниц, которые зависят от этого контента
Leviathan забирает сообщения из очереди, готовит отрендеренную копию страницы при помощи Rendertron и кладет ее в MongoDB (изначально мы использовали Ceph, но он оказался недостаточно быстрым)
На фронт-сервере настроен роутинг, который, в зависимости от заголовка User-Agent, направляет запрос либо на наш обычный SPA (для «настоящих» пользователей), либо на Leviathan, для поисковых роботов
Leviathan отдает сохраненную копию страницы, если она есть, либо рендерит ее на «лету» (пессимистичный сценарий, но рабочий) и сохраняет, если ее не было
Как видите, на схеме присутствует и more.tv, и ctc.ru — мы запустили этот сервис сразу для двух продуктов, и минимальными усилиями можно расширить его функционал на произвольное количество сайтов, независимо от их технологической платформы. В идеальном сценарии, при пустой очереди, время «готовности» сохраненной копии страницы — не более 10 секунд, это вполне приемлемо для задач SEO, так как шансы, что именно в эти 10 секунд Яндекс придет за ссылкой, которую только что опубликовали где-то, например, ВКонтакте, — минимален.
Кроме того, появляется дополнительная неочевидная точка оптимизации: поскольку Rendertron буквально рисует страницу тем же образом, что и пользователь, то чем быстрее работает клиентское приложение, тем выше пропускная способность очереди пререндеринга. Оптимизация React-приложений стала важна как никогда (об этом — в третьей части статьи). Особенно забавный нюанс — поскольку контейнер с Rendertron работает постоянно, по принципу API-сервиса, то браузер там тоже висит в памяти и работает «вкладками». Соответственно, если React-приложение, которое он рендерит, имеет утечки памяти, то и сам сервис начинает «течь». Собственно, мы это регулярно наблюдали в мониторинге, — pod с Rendertron за сутки работы мог поглотить 60–70 гигабайт памяти, и для нас это стало еще одним критерием качества нашего клиентского кода. Сам Rendertron, впрочем, мы просто рестартим раз в сутки :)
В деталях, конечно, все несколько сложнее, и есть ряд эджкейсов, которые надо так или иначе решать:
Что делать, если готового кеша нет, а Rendertron не уложился в временной бюджет (5 секунд)?
Что делать в случае массовых публикаций, когда очередь достаточно плотно загружена, как обеспечить доступность контента? На more.tv есть сериалы, в которых под тысячу серий, соответственно, при обновлении какой-либо метаинформации этого сериала нужно обновить сразу тысячу страниц
Как мониторить и отслеживать все эти операции, чтобы локализовать проблемы, в случае их появления, ведь поисковые системы очень небыстро и неявно реагируют на какие-либо изменения в семантике сайта, и время мониторинга практически любых SEO-операций — это минимум 2 недели
Последний пункт был особенно критичен именно на фазе запуска, так как нам нужно было резко перенести более чем 50000 URL, и, хоть существенное падение SEO-показателей ожидалось в любом случае, как оценить, где это «естественное» для процесса миграции сайтов явление, а где — наша недоработка.
Не вдаваясь глубоко в детали, все эти вопросы мы за прошедшие годы эксплуатации сервиса решили, попутно «обмазавшись» трассировкой запросов, логами, метриками Prometheus, управляемым скейлингом сервисов и управляемым троттлингом очереди.
Оптимизация пользовательских метрик
Раз уж у нас есть сохраненные копии страниц, почему бы нам не отдавать их и пользователям тоже? Проблема лишь в том, что это просто HTML, без дополнительной информации для клиентского кода о том, как ему с этим HTML взаимодействовать. На самом деле, стоит задаться вопросом, а как именно наличие пререндеринга может улучшить пользовательский опыт, ведь, как было показано выше, далеко не всегда это напрямую влияет на скорость загрузки страниц, а, тем более, в содержимом more.tv очень много контента, зависимого от пользователя: от персонализированных подборок контента до истории просмотров, а мы храним только отрендеренную копию страницы для неавторизованного пользователя, — так, как сайт должен увидеть Яндекс. Однако, в этом есть огромный плюс — такую страницу можно совершенно невозбранно кешировать на nginx, что значительным образом сокращает время ответа. В итоге мы пришли к такому решению:
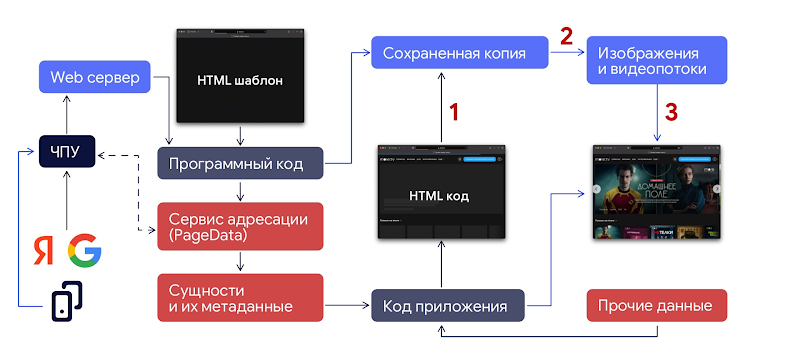
Как видно на схеме, путь загрузки поисковых роботов и для пользователя различается: робот загружает сохраненную копию страницу напрямую по адресу, а пользователь загружает частично заполненный шаблон страницы, в котором уже заполнена часть данных:
Всю метаинформация страницы в теге
, что позволяет вставлять ссылку на сайт в любой мессенджер или соцсеть в виде красивого информативного сниппетаУказания браузеру предзагрузить некоторые ресурсы: css, медиафайлы, шрифты Google Fonts, что немного ускоряет загрузку страницы для новых пользователей
Информацию, необходимую для отрисовки неперсонализированного контента страницы, полученную из сервиса роутинга (aka PageData), что позволяет не ходить на клиенте лишний раз в этот API, и это экономит еще некоторое количество времени на отрисовку содержимого
При этом весь персонализированный контент все еще отрисовывается на клиенте тем же способом, что и раньше
В случае, если сохраненной копии вдруг не нашлось, пользователь попадает на старую логику и получает пустой шаблон страницы, который с нуля заполняется клиентским кодом. Судя по нашим системам мониторинга, это практически вырожденный кейс, <0.01% всех сессий.
Как видно из схемы, критический путь загрузки стал существенно короче, и процессы, которые формируют критические временные метрики, — TTFB, FCP, LCP, — стали «ближе» друг к другу. А поскольку сайт очень посещаемый, и многие пользователи, само собой, смотрят одно и то же, то значительная часть страниц с этой информацией постоянно лежит в кеше nginx и отдается за доли секунды, не вызывая нагрузки на микросервисы. Если вы все еще сомневаетесь в адекватности такого подхода, позвольте поделиться с вами некоторыми метриками, которые мы собирали после релиза всей этой схемы:
TTFB (средний по сайту за сутки) не изменился, что и следовало ожидать
FCP (средний по сайту за сутки) уменьшился практически втрое — с 1050 до 380 миллисекунд
LCP (средний по сайту за сутки) уменьшился вдвое — с 1750 до 900 миллисекунд
Показатель отказов упал с 50% до 30% (иным маркетологам цифры покажутся страшными, но такова специфика сегмента)
Средняя глубина просмотра сайта увеличилась с 2.7 до 5 страниц
Таким образом, как и было предсказано множеством авторов и UX-специалистов, временные показатели работы страницы напрямую повлияли на продуктовые метрики положительным образом. Что касается SEO-трафика и позиций, тут делать выводы чуть сложнее, так как ПС достаточно инертны и не слишком резко реагируют на такие изменения, но по сей день эта схема работает, и наше присутствие в выдаче неуклонно растет.
Конечно, стоит оговориться, что эти метрики засекались в 2019 году, и, если вы зайдете на more.tv сейчас, там все несколько менее радужно, так как за прошедшие годы сайт оброс функционалом, контентом, неизбежно став тяжелее и медленнее, да и конкретные показатели все таки будут зависеть от производительности вашего оборудования: на телефонах, само собой, сайт грузится ощутимо медленнее, чем на стационарных ПК с Core i7 (как, впрочем, и любой другой сайт). Однако, мы непрерывно работаем над этими метриками и над качеством кода, чтобы оставаться в рамках рекомендуемых ПС величин (LCP < 2.5 секунд), а также применяем иные техники оптимизации, о которых мы расскажем в следующих статьях.
Автор статьи:
 Усков Александр
Усков АлександрВедущий разработчик more.tv
