Шаг влево, шаг вправо — шкала. Или от абсолюта к простому порядку

Для применения классических процедур обработки сигналов требуется выполнение операций сложения и умножения, следовательно, требуется представление отсчетов в абсолютной шкале. А могут ли для обработки сигналов применяться другие шкалы, в каких случаях и что это дает? Об этом рассказывается в данной статье.
Заранее авторы извиняются за приличный объем, но это служит для максимально ясного освещения вопроса. И немного о применении шкального кодирования для оценки энтропии мы уже говорили вот тут
Классическое аналого-цифровое преобразование каждому отсчету входного сигнала ставит в соответствие номер интервала на шкале амплитуд, в который этот отсчет попадает (рис. 1).
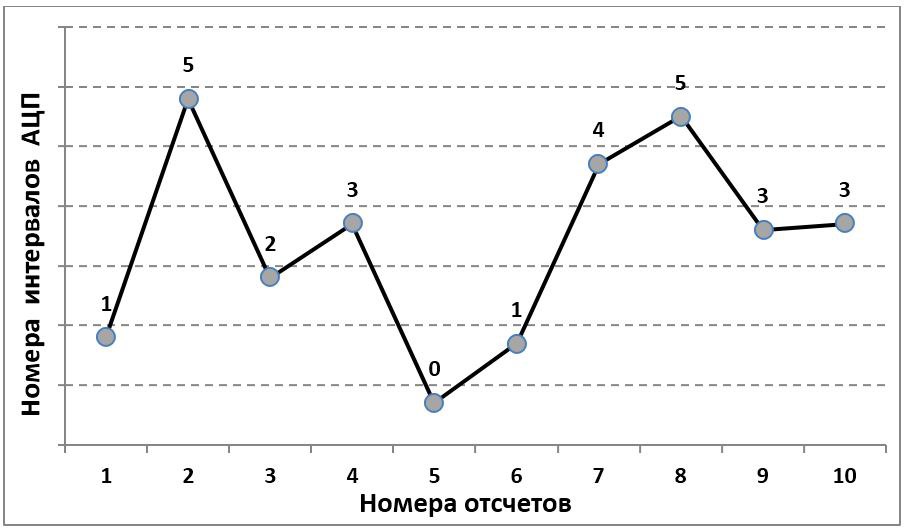
Рис. 1. Принцип аналого-цифрового преобразования
Данную процедуру в отношении каждого отсчета можно рассматривать как единичное измерение. Ширина интервала АЦП определяет максимальную погрешность такого измерения. В теории измерений (см., например, [1]), вводится понятие измерительных шкал (шкал сравнения). Упомянем некоторые из них.
- а) Абсолютная шкала.Это обычная шкала, в которой измерение производится путем сравнения с эталоном (метр, кг и т.п.). Именно эта шкала соответствует классическому АЦП. Результаты измерений в этой шкале можно складывать и умножать.
- б) Шкала интервалов. В этой шкале измерения производятся при выбранной точке начала отсчета и заданном масштабе. Примером является измерение температуры в шкалах Цельсия и Фаренгейта. Результаты измерений в шкале интервалов нельзя складывать и умножать.
- в) Порядковая шкала. Эта шкала определяет только отношения между двумя значениями (больше, меньше или равно), при этом невозможно определить, насколько одно значение больше другого. Примером такой шкалы является замена отсчета его рангом в выборке. К данным в этой шкале неприменимы любые арифметические операции, зато они инвариантны к монотонным преобразованиям исходных сигналов.
2. Шальные Шкальные представления числовых временных рядов
Относительные шкалы находят естественное применение при оцифровке данных качественного характера. Например, когда измеряемые характеристики принимают значения из множества {плохой, хороший, очень хороший}. Но если исходные данные представляют собой числа, то какой смысл представлять их в относительной шкале? И как с ними потом работать? Рассмотрим ответы на эти два вопроса.
Сначала определимся с мотивацией для представления числовых данных в относительных шкалах. В обычном аналого-цифровом преобразовании, принцип которого представлен на рис. 1, соотношение уровней входного сигнала и значений выходных данных фиксировано и не зависит от времени. Отсюда следуют, что любые два отсчета в выборке сравнимы между собой, то есть мы можем определить, какой из них больше и насколько. Всегда ли эти утверждения оправданы с точки зрения природы входных данных? Допустим, мы оцениваем скорость ветра по углу отклонения вершин деревьев (например, обрабатывая записи с камер видеонаблюдения). Можно ли утверждать, что вдвое больший угол отклонения соответствует вдвое большей скорости ветра? Очевидно, нет, связь здесь нелинейная и ее параметры нам точно неизвестны.
Однако мы можем по углам наклона деревьев сравнить скорости ветра в два произвольных момента времени и определить, какая из них больше. Таким образом, абсолютная шкала здесь избыточна, ее использование не только приводит к неэффективному кодированию, но и создает почву для необоснованных суждений (что в науке чревато). В то же время, для представления этих данных достаточно порядковой (ранговой) шкалы, которая порождает код меньшей длины, чем абсолютная, и кодирует только достоверную информацию.
Рассмотрим следующий пример. Зададимся вопросом: «Насколько простой карандаш сегодня стоит больше, чем в 1970 году?». Формально ответить на вопрос несложно, так как цены известны. Но этот ответ не будет иметь никакого смысла, так как 1 рубль 1970 года и 1 рубль 2016 года — несравнимы (в смысле реального наполнения). Следовательно, мы вообще не можем определить, больше или меньше он стоит сегодня по сравнению с 1970 годом. Однако и в 1970 году и в 2016 мы можем сравнить его стоимость со стоимостями других товаров, либо сравнить его стоимости по месяцам тех же лет. Таким образом, для некоторых числовых рядов значения сравнимы только в пределах определённого временного интервала. Для таких рядов ранговое кодирование не подходит, так как оно предполагает сравнимость всех отсчетов временного ряда. В этом случае следует применять другой тип порядковой шкалы, описанный ниже (локально-ранговое кодирование).
Прежде чем перейти к рассмотрению непосредственно процедур рангового и локально-рангового кодирования, несколько слов о практическом значении всех этих рассуждений. Как уже понятно из сказанного, использование абсолютной шкалы там, где она не соответствует природе данных, приводит к двум негативным последствиям:
- неэффективное увеличение объема данных;
- создание предпосылок для ложных суждений о соотношении отсчетов.
С объемом данных все понятно, что касается второй проблемы, то отметим, что к таковым суждениям относятся, например, оценки параметров формы сигнала. Так, в результате монотонных преобразований синусоидальный сигнал можно превратить в пилообразный, и наоборот. Это приведет к некорректности применения, например, процедур спектрального анализа.
Насколько распространены подобные данные? В экономике — почти все, связанные с ценами и различными курсами. В социологии и статистике, например, данные о заболеваемости населения за разные периоды. Их нельзя сравнивать, так как изменялось качество медицинской диагностики. В анализе статистических рядов — когда мы имеем дело с индексами, отражающими интересующий нас показатель, но, возможно, нелинейным образом. В электронике и радиотехнике подобные ситуации возникают там, где имеют место некомпенсируемые нелинейные преобразования и неконтролируемые (паразитные и пр.) модуляции сигнала. Пример — измерение потенциала в электроэнцефалографии, результат, как правило, промодулирован переменным подэлектродным сопротивлением, так что сравнивать можно только близлежащие во времени отсчеты.
Насколько значимы выявленные нами проблемы? Ведь стоимость хранения данных с развитием технологий падает, а от некорректных суждений можно просто воздержаться. Дело в том, что сегодня человечество порождает значительно больше данных, чем может обработать, и этот разрыв растет. Для его преодоления создаются т.н. системы и технологии больших данных (Big Data). Применение шкального кодирования данных в соответствии с их природой может существенно повысить эффективность технологий их автоматической обработки. Во-первых, на этой основе значительно снизится скорость входного потока. Во-вторых, процедуры машинного обучения, автоматического выявления закономерностей и т.п. будут работать более корректно, опираясь только на значимые свойства исходных данных. Вообще, процедура подготовки данных для автоматизированного анализа имеет огромное значение, и шкальное кодирование здесь может сыграть свою роль.
Теперь рассмотрим конкретные методы шкального кодирования данных.
3. Ранговое кодирование числовых рядовРанговое кодирование известно давно и применяется, в частности, в статистике для непараметрической проверки гипотез. Для сигнала, приведенного на рис. 1, соответствующий ранговый код приведен на рис. 2. Он получается заменой отсчета его рангом, то есть порядковым номером в отсортированной по возрастанию выборке.
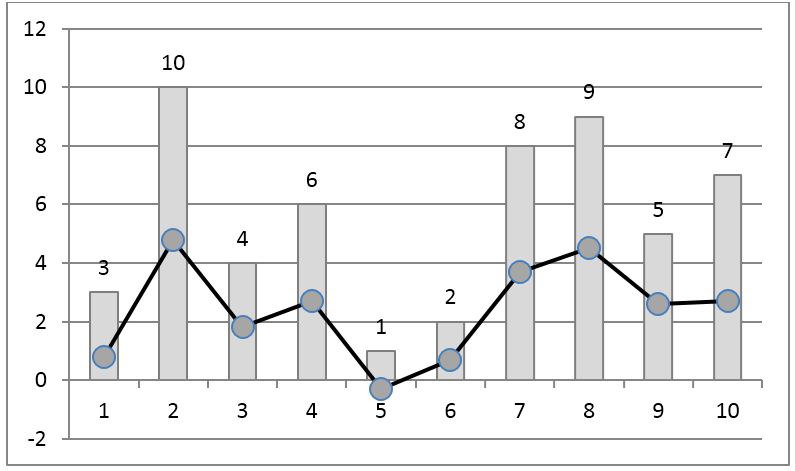
Рис. 2. Ранговое кодирование временного ряда. Линия с маркерами — исходный сигнал, столбики — ранги отсчетов.
Недостатком такого кодирования является его нелокальность в том смысле, что добавление новых элементов к выборке изменяет ранги всех отсчетов. В частности, ранг максимального по значению отсчета всегда равен количеству отсчетов в выборке. Помпе с соавторами [2] предложили делить значения рангов на число элементов в выборке. В результате полученный код всегда находится в интервале [0,1] и влияние новых отсчетов на ранги остальных значительно снижается (рис. 3).
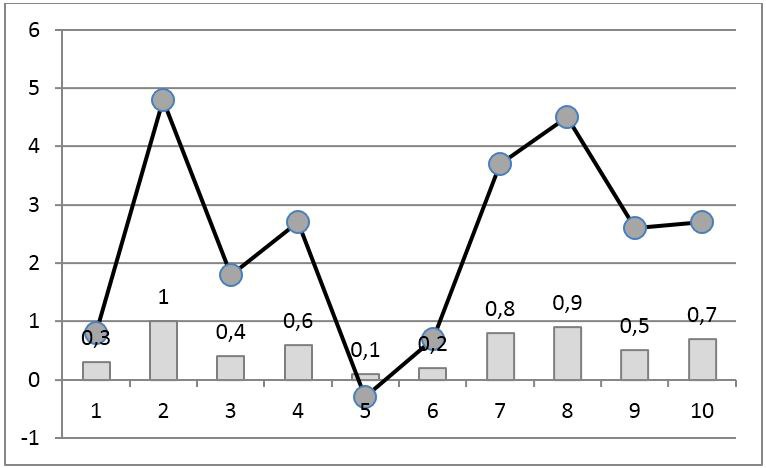
Рис. 3. Ранговое кодирование временного ряда по алгоритму Помпе с соавт. [2]. Линия с маркерами — исходный сигнал, столбики — ранги отсчетов. 4. Локально-ранговое кодирование числовых рядов
Проблема нелокальности рангового кода решается и другим методом — с использованием локально-рангового кодирования. Для этого мы должны задать интервал сравнимости, в пределах которого соотношения отсчетов выборки считаются значимыми и должны быть сохранены. Соотношения отсчетов, отстоящих друг от друга более, чем на интервал сравнимости, при кодировании не учитываются.
В процессе локально-рангового кодирования подбирается такой код, элементы которого повторяют соотношения между отсчетами исходного ряда, отстоящими друг от друга не более, чем на интервал сравнимости. Для примера на рис. 3 приведен такой код с интервалом сравнимости в 2 отсчета. Это означает, что для каждого отсчета сохранены соотношения с ближайшими двумя отсчетами слева и справа.
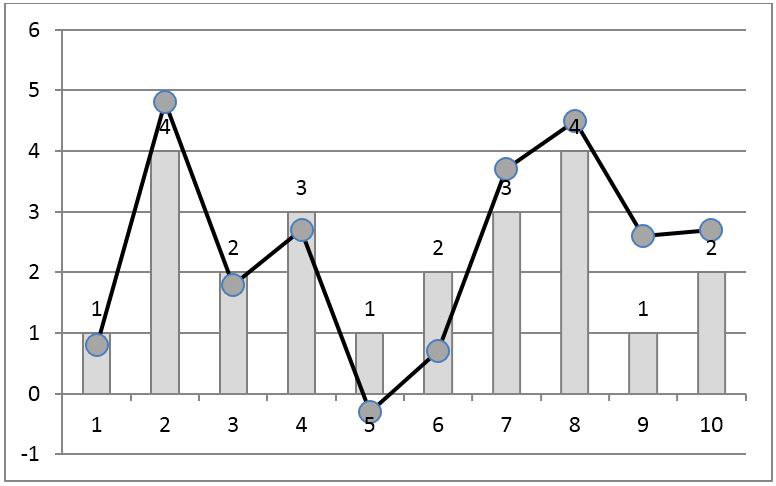
Рис. 4. Локально-ранговое кодирование временного ряда. Линия с маркерами — исходный сигнал, столбики — локальные ранги отсчетов. 5. Символьное представление временных рядов
Ранги отсчетов (глобальные, нормированные, локальные) представлены числами. На самом деле числами они не являются, так как операции сложения и вычитания рангов смысла не имеют. Ранги отражают только знак разности между двумя отсчетами, но не ее величину. Таким образом, ранги представляют собой множество, элементы которого упорядочены отношением ≤. Такое множество всегда можно отобразить на некоторый алфавит, так как символы алфавита упорядочены отношением следования, а сумма и разность для них не определены.
На рис. 5. представлен пример символьного локально-рангового кода для временного ряда. Несложно убедиться, что в пределах двух позиций слева и справа для каждого отсчета выборки символьная последовательность имеет те же соотношения, что и исходная. Для отсчетов, отстоящих более чем на 2 позиции, соотношения не выдерживаются (например, отсчеты с номерами 1 и 5), так как такие отсчеты полагаются несравнимыми.
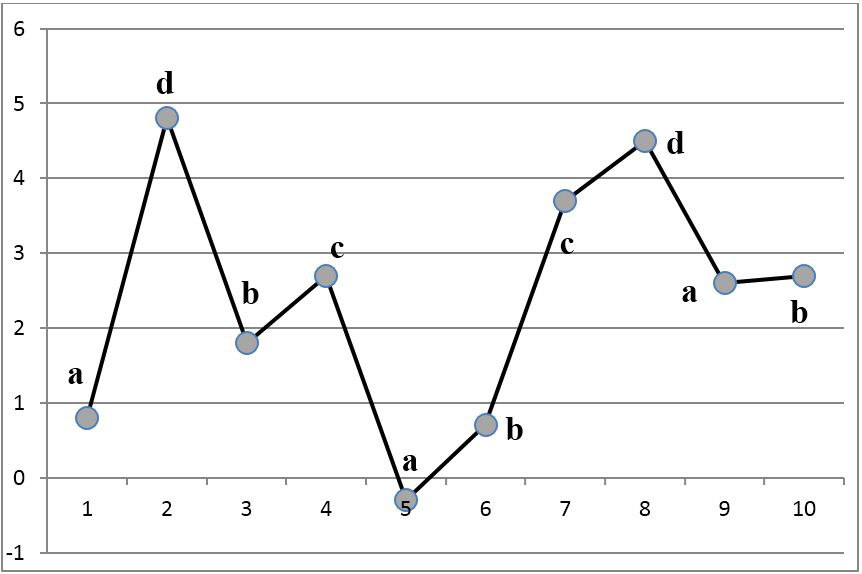
Рис. 5. Символьное локально-ранговое кодирование.
Метод символьного локально-рангового кодирования был предложен в [3], а алгоритм его вычисления приведен в [4]. Вопросы локально рангового кодирования и его применения для оценивания энтропии сигналов подробно рассмотрены в монографии [5].
6. Работа с ранговыми даннымиКак уже было сказано, над данными, представленными в ранговой шкале, арифметические операции не определены. Это, однако, не означает, что над этими данными совершенно запрещены такие операции, в определенных случаях их можно применить. Например, выполнить спектральный анализ для поиска скрытых периодичностей. Однако, так как информация о форме сигнала при кодировании потеряна, доверять можно только выявленной первой гармонике, вторая и последующие гармоники могут появиться вследствие нелинейности кодирования. Также возможно применение к ранговым данным корреляционного анализа.
Однако, так как ранговые данные являются, по существу, символьными к ним возможно абсолютно корректно применять следующие виды анализа:
- статистический анализ символьных рядов (Марковские модели и др.);
- поиск закономерностей с использованием регулярных выражений, прогнозирование временных рядов на этой основе;
- теоретико-информационный анализ (энтропия, взаимная информация и т.п.)
Эти виды анализа данных могут давать новые результаты и в применении к классическим задачам анализа и распознавания сигналов, идентификации моделей и др. По этой причине представление сигналов в ранговых шкалах представляет интерес и в тех случаях, когда данные вполне представимы в абсолютной шкале. В частности, при оценивании энтропии временных рядов целесообразно переходить к ранговой шкале (см. [2,3,5]).7. Немного теории (и совсем скоро конец)
Ранговые коды обладают рядом интересных свойств, например, инвариантностью к непрерывным взаимно-однозначным преобразованиям. Так, ряды: x (n) и e^(x (n)) будут иметь совпадающие ранговые коды. Это делает их привлекательными, в частности, для решения задач оценивания энтропии временных рядов, поскольку оценки энтропии рядов типа x (n) и e^(x (n)) должны совпадать.
Но нам представляется, что шкальное кодирование найдет свое применение и в других областях, в частности Big Data. Обработка символьных последовательностей представляет собой хорошо разработанную область знаний и технологий, так что переход от числовых последовательностей к символьным позволяет расширить арсенал применяемых моделей и алгоритмов обработки.
Теоретические основы шкального кодирования данных вообще и временных рядов, в частности, должны лежать где-то в алгебре данных (вопрос авторами пока не проработан). Основная идея в том, что если мы исключаем из рассмотрения какие-либо свойства входных данных, полагая их незначимыми вследствие их природы либо особенностей процедуры измерения, то мы должны от представления числами переходить к представлению элементами множества с определенными на нем операциями и отношениями, соответствующими тем, которые допустимы для данных. Так, если мы говорим, что абсолютные значения разностей между отсчетами незначимы, и доверять можно только знакам этих разностей, то мы сразу получаем множество, изоморфное некоторому алфавиту символов.
Отказ от сравнимости удаленных друг от друга отсчетов приводит к частично упорядоченному множеству, в котором не все элементы сравнимы. Так что, строго говоря, для локально-рангового кода необходимо выбирать не алфавит (так как в нем все элементы сравнимы), а множество другого типа. Такими свойствами обладает, например, множество слов, упорядоченных отношением ≤, заданным таким образом, что слово А меньше слова Б в том и только том случае, если все буквы, входящие в А меньше, чем соответствующие буквы слова Б. Так слово cbg будет меньше, чем dhr (c Концептуально все это относится к теории информации, а именно к вопросам определения количества информации, содержащейся в данных. Из сказанного понятно, что простое числовое представление данных, включая сигналы, в определенных случаях обладает большой избыточностью, так как кодирует отношения, не являющиеся достоверными. Это, по –видимому, представляет собой новый тип избыточности, отличающийся от широко известной статистической или менее известной алгоритмической. При определённых ограничениях можно ставить и решать задачи по поиску минимального алфавита, позволяющего закодировать нужные отношения в сигнале. Для локально-рангового кода данный вопрос частично рассмотрен в [3]. Можно также предположить, что алгебраические модели данных и сигналов, адаптированные к технологиям Big Data, станут предметом активных исследований, и поводом для этих исследований послужат не только рассмотренные нами проблемы. Так что, заканчивая эту статью, отметим, что вопросы цифрового представления сигналов по-прежнему актуальны и выходят далеко за рамки теоремы Котельникова (время крушить-ломать стереотипы) и других классических результатов теории цифровой обработки сигналов. Литература П.С. Авторы будут рады вашим комментариям, а так же мыслям на тему применения локально-рангового кодирования в ваших предметных областях.1. Саати Томас Л. Принятие решений при зависимостях и обратных связях: Аналитические сети. Пер. с англ. / Науч. ред. А.В. Андрейчиков, О.Н. Андрейчикова. Изд. 4-е. — М.: ЛЕНАНД, 2015. -360 с.
2. Pompe B. Ranking and entropy estimation in nonlinear time series analysis // Nonlinear analysis of physiological data. Springer Berlin Heidelberg, 1998. — P. 67–90.
3. Цветков О.В. Вычисление оценки энтропии биосигнала, инвари¬антной к изменению его амплитуды, с использованием рангового ядра // Изв. вузов. Радиоэлектроника. — 1991. — № 8. — С. 108–110.
4. Цветков О.В. Оценка близости числовых последовательностей на основе сопоставления их ранговых ядер // Изв. вузов. Радиоэлектроника. — 1992. — № 8. — С. 28–33.
5. Цветков О.В. Энтропийный анализ данных в физике, биологии и технике. СПб.: Изд-во СПбГЭТУ «ЛЭТИ», 2015. 202 с.
Автор текста: Цветков О.В.
Хабра-редактор: YuliyaCl
Комментарии (1)
21 сентября 2016 в 12:35
0↑
↓
Спасибо за статью, помню в колледже подобную тему проходили, но тут более развернуто написано :)
