С-вызовы в Go: принцип работы и производительность
Язык Go в последнее время неоднократно обсуждался на хабре — его и критиковали , и хвалили. Мы в Intel любим Go и участвуем в open-source разработке этого проекта. Если вы тоже используете Go, интересуетесь его внутренним строением и вопросами наиболее эффективного программирования на этом замечательном языке, то добро пожаловать под кат. Статья будет о том, каким образом в Go реализован механизм внешних вызовов, и насколько быстро он работает.
Главный принцип, которым руководствуются создатели Go при проектировании языка — максимальная простота организации этого проекта. Создатели сознательно избегают «перегрузки» и излишней функциональности доступной «по умолчанию», поэтому вся дополнительная функциональность вынесена в утилиты, которые пользователи языка могут устанавливать по своему желанию. Таким образом, Go — это не просто платформа, это ещё и набор полезных стандартных утилит. В сам Go включен лишь необходимый их минимум, но всегда доступно великое множество дополнительных полезных инструментов, предусмотренных создателями языка или созданных сообществом. Например, среди стандартных утилит есть go vet, которая помогает отловить подозрительные конструкции в коде (а дополнительно можно поставить go lint, errcheck, structcheck и другие). Утилита test автоматизирует тестирование пакетов, fix — поможет при переходе к новой версии Go и измененным API и сделает необходимые изменения в уже существующем коде. Создатели Go позаботились об удобстве и простоте использования этих инструментов, написание кода благодаря им становится легким и приятным занятием.
Кроме всего прочего, создателями также предусмотрена возможность использования в Go-программах С-библиотек. Это очень важно, поскольку на данный момент Go-шные пакеты существуют далеко не на все случаи жизни, в то время как на С реализовано практически всё. Чтобы всё это богатство С-библиотек применять в Go, создана утилита cgo. Она анализирует Go-код и при компиляции Go-программы, если нужно, вызывает С-компилятор для подключаемого С-кода с указанными флагами, а также формирует из С и Go-файлов один пакет. С её помощью С-код очень легко интегрировать в Go (см., например, тут)
Но неизбежно возникает вопрос, насколько эффективно будет работать Go код, активно использующий С-вызовы? Для того, чтобы разобраться в этом, необходимо узнать чуть больше о внутреннем механизме работы среды исполнения Go. Забегая вперед, скажу, что эти знания нам необходимы, потому что они позволят усомниться в эффективности работы С-вызовов, и заняться дальнейшим анализом… Но обо всем по порядку.
В Go есть go-рутины — это такие «потоки исполнения» пользовательского уровня — go-рутины переключаются в рамках одного системного треда, у каждой из них есть свой стек. Нужно отметить, что организация модели многопоточности в Go имеет под собой строгую теорию, а именно — теорию взаимодействующих последовательных процессов Хоара (CSP), применяемую для формального описания функционирования параллельных систем.
Go известен своей возможностью создавать огромное количество (десятки и сотни тысяч) go-рутин. Это возможно благодаря тому, что изначально все go-рутины требуют для своего создания совсем немного ресурсов –, а именно, все они создаются с небольшим размером стека (2K стека против 2M в случае стандартного потока на Linux/x86–32), а в процессе работы их стек переаллоцируется по мере необходимости. Средством взаимодействия go-рутин является канал.
Здесь возникает вопрос: как в эту систему впишутся С-вызовы? Будет ли увеличиваться стек для нужд С-функции так же, как это происходит для go-рутин? Как будет осуществляться планирование go-рутины, когда она делает внешний вызов? Сперва всё это достаточно неочевидно.
Давайте сначала разберемся в общем механизме работы go-рутин, без внешних вызовов. Чтобы понять, как всё устроено, рассмотрим внутренние сущности Go, которые принято обозначать буквами g, m и p. Кто-то, вероятно, знаком с ними по статье об устройстве go-планировщика, перевод которой также доступен.
g — структура-дескриптор go-рутины. Она содержит всю специфическую для одной go-рутины информацию, в том числе данные о текущих границах её стека, program counter, и указатель на дескриптор текущего системного потока, в котором данная go-рутина исполняется (он обозначается m, и о нем чуть ниже). Go-рутины ставятся на исполнение планировщиком, который вызывается в подходящий для этого момент — например когда исполняемая go-рутина делает системный вызов или операцию ввода-вывода.
Каждый системный поток, созданный средой исполнения Go, в свою очередь, описываются структурой m. В m содержится внутренние данные потока: его идентификатор, текущая исполняющаяся в нем go-рутина, есть поля описания состояния (spinning, blocked, dying) и прочие специфические для Go поля. Но в числе всего прочего там лежат данные, которые будут нас интересовать дальше — это границы выделенного потоку стека, а также указатель на нечто, что называется «контекст исполнения».
Контекст исполнения p — это тоже специальная структура. Контекст нужен системному потоку m для того, чтобы выполнять go-рутины. Внутри себя p хранит локальную очередь go-рутин, готовых к исполнению. Как только m заполучил некоторый контекст p, то он может исполнять go-рутины из локальной очереди, принадлежащей этому контексту. Если локальная очередь опустела, то будет происходить work-stealing из очередей других p. Также существует и глобальная очередь, которую все p периодически проверяют.
Важно понимать, что системных потоков m обычно одновременно существует много — часто их больше, чем контекстов. Но заниматься выполнением go-рутин могут лишь те потоки, которые имеют контекст. Количество контекстов может быть задано переменной окружения GOMAXPROCS, а по умолчанию оно равно количеству ядер процессора. За счет того, что число контекстов — фиксированное, происходит мультиплексирование всего множества go-рутин на заданное число ОС-потоков.
Смысл введения контекста в том, что его можно передавать между разными ОС-потоками, и обычные go-рутины из локальной очереди контекста не заметят разницы. Когда это может понадобиться? Тогда, когда нужно освободить текущий поток для какой-то блокирующей задачи. Давайте представим, что передача контекста невозможна. Тогда если какая-то одна go-рутина делает системный вызов, то для оставшихся в локальной очереди это будет означать простаивание. А поскольку системный вызов может оказаться блокирующим, то и go-рутины могут оставаться заблокированными неопределенное время, а этого нельзя допустить. Передача контекста решает эту пробему и позволяет go-рутинам из очереди продолжать исполняться даже в таких случаях. Именно поэтому перед тем, как совершить системный вызов, контекст передается какому-нибудь другому свободному системному потоку m, и на этом новом потоке очередь продложает беспрепятственно работать. Cистемный вызов же будет осуществлен на исходном потоке, но уже без контекста исполнения.
Итак, мы рассмотрели базовые сущности g, m, p и немного затронули системные вызовы. Теперь мы подошли к вопросу внешних вызовов в Go.
Как вы видите, в Go модель исполнения совсем не свойственная для С-функций. Поэтому внешние вызовы должны обрабатываться особым образом, вне механизма go-рутин. Но мы уже начали говорить об обработке системных вызов в Go –, а что, если системные вызовы также будут и внутри С-функции? Поскольку этого нельзя заведомо знать, то любая произвольная С-функция с точки зрения Go должна обрабатываться так, чтобы правильно работали системные вызовы внутри неё. Следовательно, в обработке Go С-вызовов и системных вызовов должны быть общие моменты. Давайте рассмотрим их подробнее, но по ходу будем отмечать и различия.И syscall, и произвольный С-вызов выполняются в отдельном системном потоке.
Мы не можем заранее знать, сколько времени потребуется на выполнение С-вызова. Точно так же, как и системный вызов, он может оказаться блокирующим, и другие go-рутины не должны от этого страдать. Поэтому С-вызов так же, как и системный, всегда выполняется в отдельном потоке, предварительно передав контекст другому m. Если в момент вызова свободных m в пуле не оказалось, то m создается на ходу. Важное замечание: поскольку и С-функции, и системный вызовы выполняются без контекста, то они не попадают под ограничение GOMAXPROCS, а это означает, что они будут выполняться в отдельном потоке даже при GOMAXPROCS=1. Таким вот образом гарантируется, что исполнение go-рутин не сможет никем быть заблокировано.
Ещё подчеркнем, что созданные системные потоки остаются жить после завершения системного вызова или С-функции и могут быть переиспользованы, а новые m всегда будут создаваться лишь при отсутствии свободных.
И тем, и другим требуется «переключение» стека
Как вы догадываетесь, стек go-рутины и стек ОС-потока — это не одно и то же. Это ясно уже из тех соображений, что go-рутин во много раз больше, чем тредов, плюс ко всему размер стека каждой go-рутины меняется динамически в процессе работы программы.
Действительно, стеки go-рутин выделены в куче и поддерживаются средой исполнения, независимо от стеков ОС-потоков. Изначально все go-рутины стартуют с небольшим стеком 2К, далее стек может расти и уменьшаться. В то время как системные стеки — это самые обычные стеки системных потоков m. Для того, чтобы хранить границы системного стека, в структуре m есть особая go-рутина g0: она особая, потому что в качестве её стека хранятся границы системного стека. Отсюда и принятое обозначение для системного стека в Go: m→g0 стек.
Системные вызовы и С-функции работают на m→g0 стеке. Вот почему перед их запуском потребуется «переключение стека». В случае С-функции это будет сделано внутри функции runtime.asmcgocall (). Там происходит буквально следующее:
- Текущий SP go-рутины сохраняется в спец. поле m структуры.
- SP go-рутины := SP данного системного треда.
В случае системного вызова отличие заключается в том, что в целях оптимизации на системном стеке будет выполняться не всё, а лишь отдельные внутренние функции, для которых это явно прописано (и переключение делается внутри функции systemstack ()).В обоих случаях нужна привязка вызывающей go-рутины к текущему потоку m
Итак, чтобы С-функции исполнялись правильно, им необходимо быть запущенными на системном
стеке. Но есть и ещё один момент: перед тем, как управление перешло в C-код, нужно сообщить среде исполнения о том, что поток становится «сишным», и он не может быть использован для планирования новых go-рутин. Это делается при помощи функции runtime.LockOSThread (). Таким образом гарантируется, что на данный m не будет назначена никакая другая go-рутина, пока не завершится текущая, или же пока текущая go-рутина не вызовет runtime.UnlockOSThread ().При возврате из системного вызова или из С-функции есть некоторая задержка
После завершения работы С-функции или системного вызова go-рутина не всегда сразу может продолжить исполняться. Помните, перед выполнением самой С-функции контекст p был передан другому потоку m? Теперь же мы снова возвращаемся к исполнению Go-кода, а значит для продолжения исполнения нужно снова заполучить контекст (тот же или другой).
В текущей реализации планировщика go-рутина сначала пытается получить тот самый контекст исполнения p, который был ею отдан. Если это удается (например, если тот p никем не используется и находится в состоянии idle), то в этом случае работа продолжается (и задержка минимальна).
Если же получить p сразу невозможно, и все прочие p также заняты, то go-рутина блокируется. Причина этого — существующее ограничение GOMAXPROCS: одновременно могут выполняться не более чем $GOMAXPROCS go-рутин (то есть не больше, чем существует контекстов), а новая go-рутина назначается на выполнение только тогда, когда одна из исполняющихся готова свой контекст «уступить», т.е. будет делать какую-то блокирующую операцию. Получается, что, вернувшись из С-вызова, go-рутина должна будет ждать, пока кто-то не «уступит» контекст по своей воле. Если внешние вызовы происходят часто, то такое ожидание освобождения p по возвращении из С-вызова может всё подпортить.
Это нетрудно увидеть, если написать следующий код:
package main
import (
"fmt"
"sync"
"runtime"
)
func main() {
runtime.GOMAXPROCS(5)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
work()
}()
for i := 0; i < 10; i++ {
go spinlock()
}
wg.Wait()
}
func spinlock() {
for {
}
}
func work() {
fmt.Println("I am working!")
}
Здесь при заданном ограничении GOMAXPROCS=5 создаются 10 go-рутин, которые работают в бесконечных циклах, а затем — ещё одна go-рутина, выводящая что-нибудь на экран. После того, как все они созданы, некоторые 5 из них получают контексты и выполняются. Если запустить этот пример несколько раз, то можно поймать ситуацию, когда work успеет получить контекст в начале и отработать. Но если окажется, что начали исполняться 5 «бесконечных» go-рутин, то контекст они не уступят, и work () уже никогда не сможет выполниться.
Давайте ещё раз проследим ход событий, происходящих при С-вызове. Пусть вызывается некоторая С-функция f (). Это разворачивается в следующую последовательность вызовов, изображенную на рисунке. Сплошной стрелкой обозначен вызов функции, пунктиром — возврат управления.

Посмотрим, что будет происходить на каждом шаге:
Шаг 1. Закрепление Go-рутины за текущим m (вызов lockOSThread ())
Шаг 2. Выбор m из пула системных потоков (если нет свободных m — создание нового потока) и передача контекста выбранному m
Шаг 3. Переключение стека Go-рутины на m→g0 стек потока операционной системы
Шаг 4. Подготовка вызова C-функции f и непосредственно вызов самой функции. Под подготовкой понимается приведение к соглашению о вызовах, соответствующему конкретной архитектуре (к примеру, на x86_64 аргументы функций будут положены в соответствующие регистры). Возврат значения С-функцией также происходит по соглашению, поэтому при необходимости будет сделано обратное приведение (на x86_64 возвращаемое значение из регистра будет перемещено на стек)
Шаг 5. Обратное переключение cо стека ОС-потока на стек текущей go-рутины (m→curg стек)
Шаг 6. Exitsyscall () — внутри него функция блокируется до тех пор, пока не будет возможности исполнять Go-код, не нарушая $GOMAXPROCS ограничение
Шаг 7. Как только исполнение стало возможно — открепление go-рутины от m (unlockOSThread ())
Здесь нужно отметить, что создателями Go предусмотрена также возможность делать callback-и. Callback происходит так: из Go-кода делается вызов некоторой С-функции, которой в качестве аргумента передан указатель на какую-то Go-функцию. Эта С-функция в процессе работы вызывает Go-функцию по переданному ей указателю.
Как минимум рассмотренный в предыдущей части случай говорит о том, что задержки ожидания p существенно скажутся на эффективности callback-a. Давайте рассмотрим немного подробнее, почему это так. С происходящим при С-вызове мы разобрались, а вот чтобы исполнить внутренний Go-код из С, будут выполнены следующие действия:
- Будет создана новая go-рутина
- Затем будет выполнено обратное переключение стека (с системного — на стек новой go-рутины)
- Новой go-рутине для исполнения нужен p. Поэтому она заблокируется и так же, как и при возврате из внешнего вызова, будет ждать, пока не освободится какой-нибудь p.
Таким образом, в случае callback-а помимо уже рассмотренной задержки возврата из С-вызова (обусловленной ожиданием свободного p), здесь присутствует ещё одна задержка той же природы. Получаем, что время ожидания p вносит двойной вклад в накладные расходы.
Итак, давайте ещё раз обозначим природу издержек, возникающих при внешних вызовах из go-рутин:
Ситуация 1. Go-рутина ожидает освобождения p после возврата из С-функции.
В этой ситуации, казалось бы, ничего страшного нет. Но представим, что go-рутин у нас очень много и С-вызовы из них происходят достаточно часто (к примеру, пусть мы таки написали обёртку к любимой библиотеке и пользуемся ей по всем канонам Go, через множество go-рутин). При многочисленных С-вызовах эти задержки станут, во-первых, более вероятны, а во-вторых, более продолжительны.
Ситуация 2. При очередном внешнем вызове не хватило свободного потока для исполнения оставшихся go-рутин.
В этом случае произойдет вынужденное создание нового потока и контекст исполнения будет передан ему. Из-за этого даже самая простая С-функция будет выполнена с существенной задержкой, равной оверхеду создания ОС-потока. Задержку такого рода нельзя предсказать в процессе работы программы, поскольку потоки, как мы выяснили, создаются по необходимости.
Чтобы оценить эти издержки, можно замерить время, затрачиваемое на вызов пустой С-функции из go-рутины в двух возможных ситуациях:
1) В ситуации, когда создается новый поток.
2) В случае, когда переиспользуется существующий поток.
Это и было нами проделано. Ниже приведена простая программа, с помощью которой были получены данные.
package main
// Run program as ./program pb=
// where pb means P_blocked - number of Ps to be in a spinlock.
// Program prints to console time (in nanoseconds) elapsed by one C call that is done in goroutine
import "fmt"
import "time"
import "flag"
import "sync"
// int empty_c_foo() {} // Объявляем пустую функцию
import "C"
func spin_lock() {
for {
}
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
pb_ptr := flag.Int("pb", 3, "number of Ps that will be in spinlock")
flag.Parse()
P_blocked := *pb_ptr
for i := 0; i < P_blocked; i++ { // «нагрузка» среды исполнения
go spin_lock()
}
go func() {
// C.empty_c_foo() // для случая 2
defer wg.Done()
time1 := time.Now()
C.empty_c_foo()
time2 := time.Now()
fmt.Println(int64(time2.Sub(time1)))
}()
wg.Wait()
}
В пункте 1 достаточно измерить время на одну пустую С-функцию, вызванную первой — поскольку это будет самый первый внешний вызов, то на момент, когда он происходит, гарантированно нет свободных m в пуле, а значит, произойдет создание потока, которое нам нужно. В случае 2 программа аналогична, но измерения проводятся уже для повторного С-вызова, ожидается, что издержки станут значительно меньше, так как m уже будет создан при первом вызове.
Для имитации «нагруженной» среды исполнения создавалось некоторое количество go-рутин, занятых в бесконечных циклах: их число обозначено P_spinlocked = 5, 10, 15, …, 35 и для каждого такого значения было сделано 100000 запусков программы и измерений. Программа запускалась на Intel® Xeon® CPU E5–2697 v2 @ 2.70GHz. На машине 48 ядер, параметр GOMAXPROCS=40, машина находилась в монопольном использовании.
Результаты экспериментов для С-вызова в случае, когда создается новый поток
| Количество P_spinlocked = | 5 | 10 | 15 | 20 | 25 | 30 | 35 |
|---|---|---|---|---|---|---|---|
| % выбросов > среднее + 3 ст.отклонения | 0,28% | 0,36% | 0,31% | 0,31% | 0,30% | 0,27% | 0,28% |
| Среднее | 2537 | 2438 | 2518 | 2534 | 2626 | 2686 | 2719 |
| Стандартное отклонение | 201 | 470 | 200 | 224 | 346 | 369 | 393 |
| Медиана | 2512 | 2523 | 2493 | 2500 | 2540 | 2590 | 2613 |
| Максимум | 58182 | 65798 | 59543 | 58243 | 55700 | 66620 | 59600 |
| Минимум | 972 | 870 | 1011 | 909 | 1005 | 975 | 937 |
Результаты экспериментов для С-вызова в случае, когда поток уже создан
| Количество P_spinlocked = | 5 | 10 | 15 | 20 | 25 | 30 | 35 |
|---|---|---|---|---|---|---|---|
| % выбросов > среднее + 3 ст.отклонения | 0,06% | 0,09% | 0,10% | 0,12% | 0,13% | 0,15% | 0,16% |
| Среднее | 1123 | 1126 | 1137 | 1172 | 1250 | 1283 | 1313 |
| Стандартное отклонение | 183 | 212 | 226 | 300 | 433 | 456 | 492 |
| Медиана | 1086 | 1076 | 1080 | 1086 | 1099 | 1117 | 1123 |
| Максимум | 68461 | 73383 | 53756 | 49751 | 50581 | 47844 | 86258 |
| Минимум | 391 | 354 | 364 | 348 | 313 | 340 | 351 |
Для начала сравним распределение длительностей С-вызовов в 1 и 2 случае (при одинаковой загруженности рантайма P_spinlocked = 35). Здесь видим ожидаемый результат — в случае с созданием нового потока время больше. Средние значения отличаются приблизительно в 2 раза и составляют ~2600 нс и ~ 1200 нс соответственно для 1 и 2 случая.

На рисунках ниже для каждого случая в отдельности представлено распределение длительностей при слабой загрузке (P_spinlocked = 5) и при высокой загрузке (P_spinlocked = 35) (без учета выбросов).
Постепенное увеличение загрузки рантайма позволило увидеть, как растут издержки, относящиеся к работе самой среды исполнения — с ростом загрузки наблюдается плавный сдвиг среднего значения. Это хорошо видно также из гистограмм, приведенных ниже: для загруженного рантайма (P_spinlocked = 35) гистрограмма «размывается» в сторону больших значений по сравнению с незагруженным (P_spinlocked = 5), что говорит о том, что сложность работы среды исполнения не константна по отношению к числу go-рутин.


Также нужно отметить, что в обоих случаях присутствует доля процента значительных по величине выбросов (~50000 нс и более). (Это странно. Казалось бы, во втором случае поток уже создан и существенных задержек быть не должно, но тем не менее выбросы одного порядка с первым случаем есть. По всей видимости, причина кроется в особенностях работы операционной системы, не связанных с созданием потоков)
На гистограмме ниже (в логарифмическом масштабе по оси y) представлены все точки, включая выбросы, для обоих случаев при равной загрузке рантайма P_spinlocked = 10. Здесь можно оценить долю выбросов среди всех полученных значений.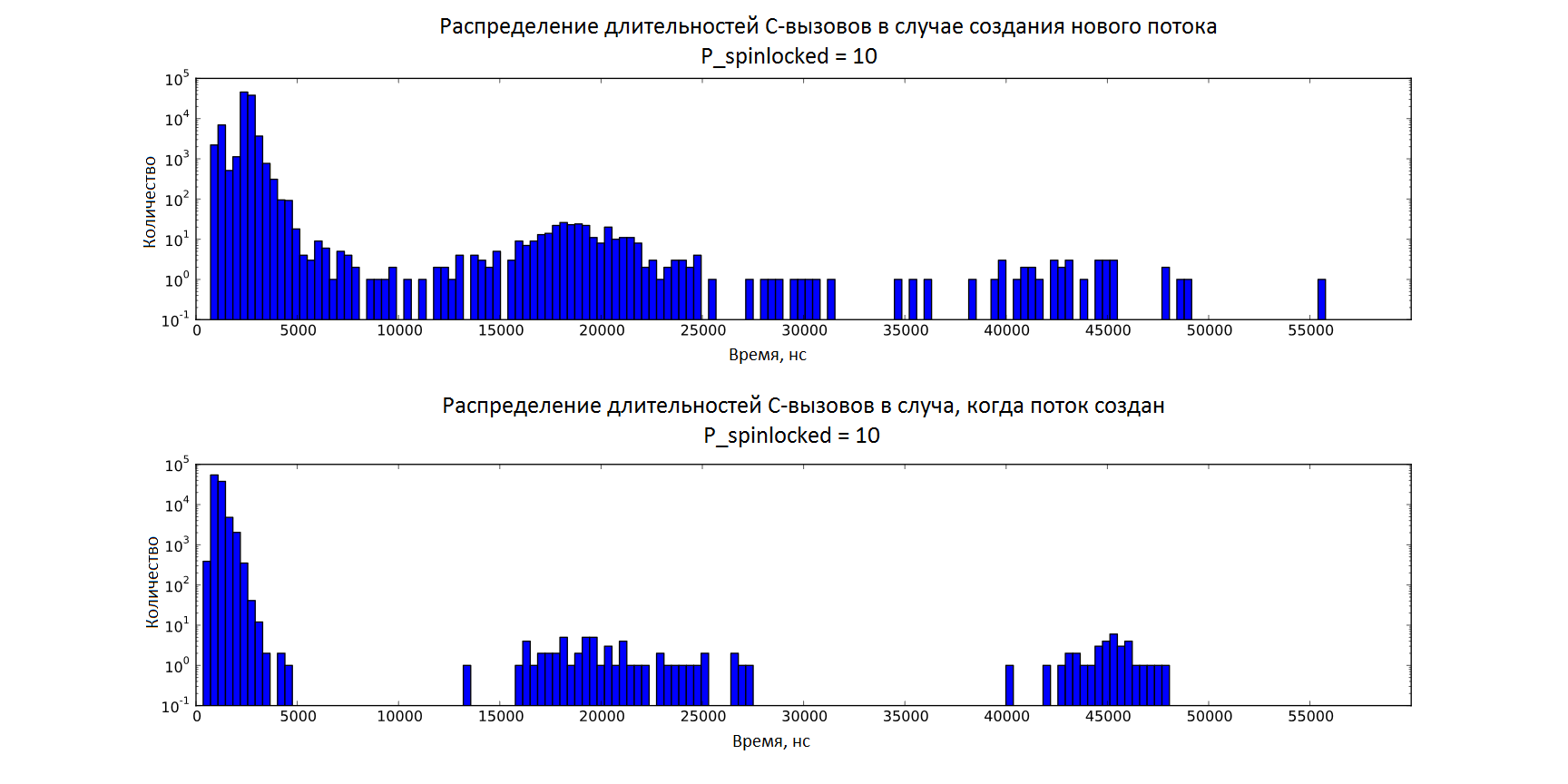
За рамками экспериментов остается вклад сборщика мусора. Для нашего эксперимента он был принудительно выключен. В реальных условиях он вносит долю недетерминированности, периодически полностью останавливая исполнение программы (так называемая стадия Stop-the-world). Разработчики Go уделяют большое внимание улучшению его работы и минимизации связанных с ним пауз в работе программ. В Go 1.5 работа сборщика существенно оптимизирована — гарантируется, что время полной остановки не превышает 10 мс, что очень даже неплохо.
Внешние вызовы являются весьма дорогостоящим мероприятием. К тому же рантайм может сам по себе давать значительные непредвиденные задержки исполнения внешних вызовов даже в нашей искусственной ситуации, когда сборщик мусора отключен, go-рутины, создающие «нагрузку», не работают с памятью, а следовательно не провоцируют добавления стека, а также эти «нагрузочные» go-рутины не делают никаких дорогостоящих операций, которые могли стать причиной вызова планировщика —, а значит, они ещё и не перепланируются. В реальности с настоящими загруженными go-рутинами разброс значений серьёзно увеличится в большую сторону.
Задержку из-за создания потоков можно избежать, например, организовав создание некоторого их количества на старте программы. Но время ожидания свободного контекста по-прежнему останется непредсказуемым, а при частых внешних вызовах будет только возрастать, поэтому приходится признать печальный факт — активное использование cgo из go-рутин плохо скажется на общей эффективности программы и прибегать к нему стоит лишь время от времени. Вероятность больших задержек, конечно, очень мала, но их возможность ставит под вопрос использование внешних вызовов в Go даже для систем мягкого реального времени.
