С нуля до 700 гигабит в секунду — как отгружает видео один из крупнейших видеохостингов России
Мы долго писали код, читали вас и, наконец, решили выйти из тени, чтобы заняться корпоративным блогом и рассказать о том, как одна из крупнейших видеоплатформ рунета доставляет видео до конечного пользователя.
Мы раскроем принципы нашей инфраструктуры и архитектуры, расскажем про используемые решения, поделимся опытом решения рутинных и совершенно нестандартных проблем и, конечно же, выслушаем все претензии и предложения.
Перед тем как рассказать о том, что представляет собой Rutube сегодня, хотелось бы провести небольшой экскурс в историю.
Видеоплатформа и сайт («Зеленый» RuTube, на корпоративном сленге) были придуманы и разработаны в городе Орёл, компанией Inventos.
В 2008-ом году проект приобрёл «Газпром-Медиа Холдинг», и начался набор новой команды в Москве, но до конца 2009-го года поддержка осуществлялась орловскими разработчиками.
Заметки на полях: несмотря на то, что московская команда была собрана из специалистов, в целом имеющих опыт работы с высоконагруженными системами, опыта работы с видео у них было мало — поэтому идеи и наработки, с которыми был куплен проект, пришлось постигать и переосмыслять практически с нуля.
Признаемся — некоторые решения, используемые в переработанном виде и по сей день, были оценены по достоинству далеко не сразу.
Интересно, что значительная часть команды сейчас — из этого, первого, московского «призыва».
Вот как выглядела архитектура проекта осенью 2008 года, в момент приобретения Газпром-Медиа Холдингом.
Язык разработки — Perl. Данные хранились в MySQL, для работы с которой был написан свой ORM. В качестве кэша использовали memcached. Для хранения видеофайлов использовалось несколько 4-х юнитовых серверов SuperMicro, с 16-ю дисками по 1 Тб каждый, объединённых в RAID-5 массив. У каждого сервера был свой дублёр, на котором содержалась точная копия данных. Репликация происходила по DRBD (блочное копирование).
Заметки на полях: есть множество примеров успешной эксплуатации подобных решений — схема очень проста, не требует больших вложений и знания каких-то хитрых инструментов, однако обладает рядом недостатков. Выход из строя любого диска приводит к деградации производительности массива, а в случае выхода из строя всего мастер-сервера, нагрузка по обслуживанию клиентского трафика ложится на реплику. После возвращения в строй мастер-сервера, нагрузка увеличивается за счёт реплицирования данных в обратную сторону, что тоже не добавляет радости.
Создание полной реплики 16-ти терабайтного массива в таких условиях занимало примерно месяц. При этом был риск остаться без живой реплики.
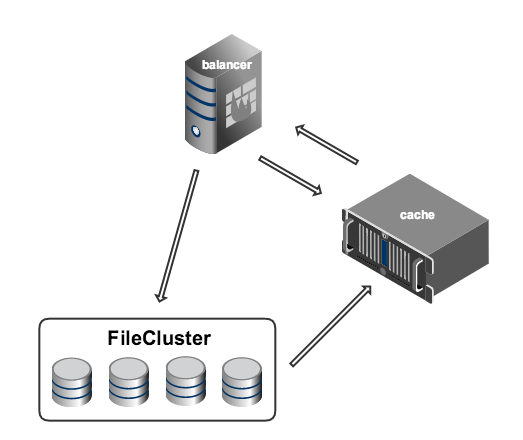
Управлялось всё это хозяйство инструментом, получившим название FileCluster — это была база данных MySQL с интерфейсом на Perl. В базе хранилась вся информация о видеофайлах, а именно, на каких конкретно машинах они лежат. Идея FileCluster заключалась в предоставлении пользователю абстрактного слоя, позволяющего выполнять операции заливки, удаления и чтения файлов из некой сущности, логически объединяющей все физические хранилища.

Всё общение вспомогательных машин (например, энкодеров) с хранилищем происходило через FileCluster.
Файлы между серверами передавались с помощью специальной утилиты, написанной на основе libssh, по, как нетрудно догадаться, ssh.
Заметки на полях: в целом, FileCluster решал множество проблем — позволял уйти от обращения к конкретным физическим хранилищам и избавлял от необходимости плодить на всех машинах большое количество маунт-пойнтов. Однако, имел ряд серьёзных недостатков — например, из-за отсутствия возможности перераспределения контента по хранилищам, после ввода в эксплуатацию новых, на них ложилась повышенная нагрузка.
В качестве протокола для раздачи видео использовался протокол HTTP (progressive download). Надо заметить, что в те времена (2008 год) альтернативой для воспроизведения во flash был только RTMP.
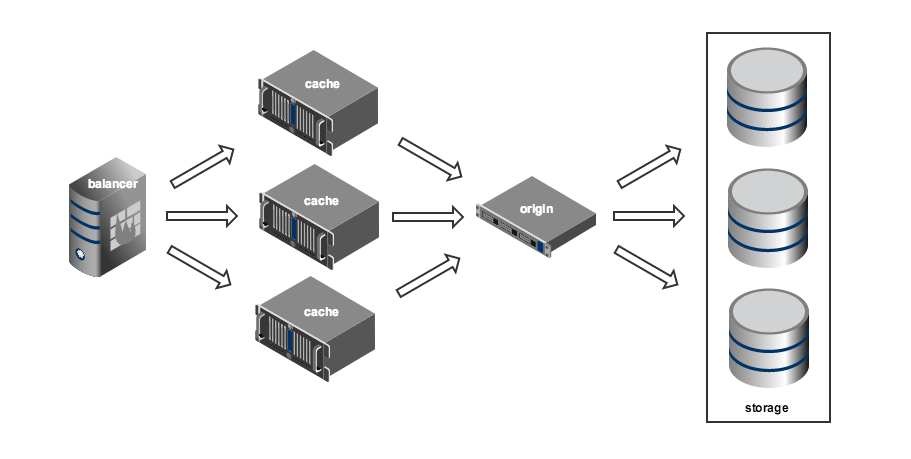
Система видеоотдачи была построена по принципу storage-cache (origin-edge в терминологии Adobe). Клиенты получают видео с кэш-серверов. Если же запрашиваемый файл отсутствует в кэше, отправляется запрос к хранилищу, а ответ кэшируется. Это очень гибкая схема, позволяющая достаточно просто реализовать географически распределённую сеть доставки контента (CDN).
Основой видеоотдачи была ещё одна оригинальная разработка — специальный демон, на основе libevent, получивший название VideoD. Демон написан на C++ с использованием STL.
Старожилы рунета наверняка помнят, что видео RuTube в те времена упаковывалось в свой собственный формат iflv. Формат представлял собой обычный flv-файл, с метаданными о количестве ключевых кадров и их расположении. Такой файл было невозможно воспроизвести стандартными средствами, зато VideoD мог запросить любой фрагмент видео. На фронте проекта располагались несколько серверов с запущенным VideoD. При запросе видео, VideoD обращался к хранилищу, доставал необходимый файл или его фрагмент, и отдавал клиенту.
Для реализации byte range запросов и кэширования, на всех машинах, образующих хранилище, так же были запущены инстансы VideoD, в специальном режиме. Фрагменты файлов, полученные с хранилища таким образом, сохранялись на кэширующих серверах и, при повторных запросах, отдавались уже оттуда.
Заметки на полях: хотя один инстанс VideoD мог обслуживать несколько клиентов, демон был однопоточным, поэтому любая операция чтения с жёсткого диска блокировала все прочие. По этой причине на всех отдающих серверах были установлены сетевые интерфейсы с пропускной способностью 1 гигабит — большего в те времена просто не требовалось.
Гибкость схемы storage-cache достигается за счёт усложнения системы балансировки нагрузки на кэширующие сервера. Для эффективной работы балансера необходимо постоянно отслеживать состояние всей системы, собирая и анализируя большое количество метрик: доступность кэш-серверов, трафик на их сетевых интерфейсах, загрузка дисковой подсистемы, просматриваемые в настоящий момент ролики, частота запроса конкретных роликов (популярность), распределение запросов по регионам и многое другое. Система балансировки образца 2009 года была реализована на базе Perlbal в виде специального плагина и умела отслеживать только одну метрику — популярность роликов.
На основании этой метрики, система балансировки выбирала группу серверов, на которых должен кэшироваться контент. Для получения ссылки на файл, балансер обращался к кэшу (memcached). Если данных в кэше не было, балансер обращался к бэкенду (FileCluster), который обрабатывал запрос и складывал данные в кэш, а затем балансер повторно обращался к кэшу.
Если всё шло хорошо, данные успешно попадали в кэш и, при повторном обращении, балансер их получал. Если возникали какие-то проблемы (обычно очень не вовремя), и при повторном обращении данных в кэше всё ещё не было, пользователь видел печальное сообщение о том, что видео в данный момент недоступно. Стоит отметить, что уже в то время система балансировки представляла собой отдельную сущность, что в дальнейшем позволило нам перестраивать видеоплатформу, не внося серьёзных изменений в бэкенд.
Вся нагрузка распределялась между двумя площадками. В основном ЦОДе было 48 серверов, и ещё 16 в Ростелекоме. Все сервера находились за IPVS, с помощью которой и обеспечивалась отказоустойчивость — «упавшие» машины просто не попадали в выдачу.
Заметки на полях: может показаться, что не всё было сделано оптимально. Но следует принять во внимание тот факт, что Inventos были своего рода первопроходцами, и многие решения, кажущиеся сейчас странными, в далёком 2008 году выглядели оправданными и порой единственно верными. В любом случае, эта архитектура позволяла обслуживать около 20 тысяч одновременных пользователей, при суммарной нагрузке 25 гигабит.
C 2009 года в архитектуре проекта произошли глобальные изменения, основные из которых пришлись на 2012-2014 гг. Были полностью переписаны сайт и сама видеоплатформа.
В качестве основного инструмента разработки используется Python и фреймворк Django. Все независимые задачи (конвертация видео, статистика, поиск дубликатов, сайт) разнесены между самостоятельными сервисами, которые взаимодействуют между собой через RPC на основе Celery. Для организации очередей сообщений был выбран beanstalk, но позже было принято решение отказаться от него в пользу RabbitMQ, который сейчас и обеспечивает большую долю транспорта между сервисами. Взаимодействие с RabbitMQ сделано с помощью Celery. Кэширование организовано через Cacheops + Redis. Для поиска используется Sphinx.
Основная база данных — по-прежнему MySQL, но некоторые проекты усиленно поглядывают «налево» в поисках нового спутника жизни.
Все компоненты платформы дублируются в двух дата-центрах. Организована репликация master — master между основными базами данных, так же подняты отдельные реплики master-slave для всех сервисов, создающих значимую нагрузку на чтение — например, для статистики.
Хранилище
FileCluster был заменён на новый инструмент, который мы назвали FileHeap. FileHeap представляет собой почти классическую реализацию SDS (software defined storage). Написано всё на Python, в качестве базы данных используется MySQL. Для хранения файлов используются недорогие 2-х юнитовые сервера с 16 Гб оперативной памяти, одним 6-ти ядерным процессором и 12-ю дисками по 4 Тб каждый. Также в этой схеме присутствует Царь-Диск — NetApp, доставшийся в наследство от FileCluster. От NetApp мы планируем избавиться в самое ближайшее время, как только нарастим объём недорогих хранилищ до необходимого размера. Все сервера, используемые для хранения файлов, разнесены по двум дата-центрам. На случай ядерной войны, FileHeap всегда создаёт три копии каждого объекта, две из которых обязательно физически находятся в разных дата-центрах.
FileHeap воспринимает каждый жёсткий диск как отдельное хранилище и следит за равномерным заполнением всех доступных ему дисков. Такая схема позволяет нам легко расширять хранилище в соответствие с нашими потребностями, а также без проблем заменять выходящие из строя жёсткие диски.
Загрузка файлов и конвертация
Для загрузки файлов и конвертации существует отдельная группа машин, также равномерно разделённая между двумя дата-центрами. Сервис, отвечающий за конвертацию, разработан на основе библиотеки Celery. Для конвертации используется ffmpeg. Транскодинг каждого качества запускается отдельным процессом и, как правило, на разных серверах, поэтому в случае, если конвертер «умер», существует ненулевая вероятность, что исходник сохранился на другом конвертере, и в итоге задача завершится без ошибок. Передача файлов между конвертерами происходит по WebDAV, в качестве сервера используется nginx.
Для управления группой конвертеров был разработан специальный сервис, который назвали Duck (Download, Upload and Convert King). С его помощью осуществляется мониторинг работы конвертеров, управление очередями задач, удаление и повторная постановка на обработку, а так же ввод в систему новых машин для конвертации.
Балансировка и CDN
Балансировка отдачи видеофайлов реализована на Python c использованием библиотеки Py3 asyncio. На серверах группы балансировки работают несколько демонов, которые занимаются мониторингом работоспособности всех отдающих серверов и состоянием канала. Помимо этого, балансер хранит информацию о просмотрах и популярности роликов. Все эти параметры используются для принятия решения о том, с какого сервера быстрее отдать запрошенный пользователем контент. Обмен данными между серверами балансировки организован через Redis.
При запросе видео, если в кэше нет данных о размещении ролика, балансер обращается к FileHeap и формирует ссылку для кэширующего сервера, по которой можно получить необходимый файл с физического хранилища.
У Rutube есть несколько точек установки кэширующих серверов для видеоотдачи. В Москве они размещены в трёх дата-центрах. Треть серверов предназначена для «горячего» контента (популярные ролики, например — «Интерны»). На «горячих» серверах подняты сетевые интерфейсы с пропускной способностью до 80 гигабит, на «холодных» до 40. Помимо этого, есть несколько точек, обслуживаемых другими операторами связи — одна точка в Красноярске и две в Ереване. Сейчас мы активно работаем в направлении расширения нашей сети доставки.
После инфраструктурного объединения с live-платформой (разработанной компанией ГПМ-Технолоджи) и перехода кинотеатра NOW.ru на платформенный плеер, на начало октября 2015 года платформа Rutube обслуживает до 350 тысяч одновременных просмотров видео по требованию (VOD) и до 65 тысяч одновременных live-потоков, при суммарном трафике 700 гигабит.
Но это далеко не предел: так как админы закупают сервера, Холдинг открывает новые каналы, а разработка пишет код.
