Рубрика «Читаем статьи за вас». Июль — август 2020 года

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- High-Resolution Neural Face Swapping for Visual Effects (Disney Research Studios, ETH Zurich, 2020)
- Beyond Accuracy: Behavioral Testing of NLP Models with CheckList (USA, 2020)
- Thieves on Sesame Street! Model Extraction of BERT-based APIs (UMass & Google Research, ICLR, 2019)
- Time-Aware User Embeddings as a Service (Yahoo! Research, Temple University, 2020)
- Are Labels Necessary for Neural Architecture Search? (Johns Hopkins University, Facebook AI Research, 2020)
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Google, 2020)
- Data Shapley: Equitable Valuation of Data for Machine Learning (USA, 2019)
- Language-agnostic BERT Sentence Embedding (Google AI, 2020)
- Self-Supervised Learning for Large-Scale Unsupervised Image Clustering (Technion, Israel, 2020)
- Batch-Channel Normalization and Weight Standardization (2 papers, Johns HopkinsUniversity, USA, 2019)
- 2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1, ч2, Май ч1, ч2, Июнь
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. High-Resolution Neural Face Swapping for Visual Effects
Авторы статьи: J. Naruniec, L. Helminger, C. Schroers and R.M. Weber (Disney Research Studios, ETH Zurich, 2020)
Оригинал статьи
Автор обзора: Александр Широносов (в слэке shiron8bit, head of ml at Dowell/Everypixel)
Исследователи из disney research предложили ряд улучшений для часто используемого Y-shaped автоэнкодера в задаче замены лиц (face swap), которые позволили им работать с изображениями размером 1024×1024, показывая при этом качество лучше, чем у распространенных в этой области подходов (у deepfacelab [DFL] в частности).
Введение
Авторы четко отделяют задачу face swapping от часто появляющейся рядом задачи face reenactment — в первом случае лицо персоны из source видео мы переносим в визуальные условия персоны на target-видео, ну и собственно все поведение и эмоции задаются target-персоной, а во втором случае по эмоциям из source мы анимируем персону/лицо из target (которое может задаваться как видео, так и фото в случае с one-shot методами). Задача замены лиц периодически возникает в киноиндустрии, когда нужно «оживить» уже мертвого актера, омолодить еще живого, да и в случаях с использованием дублеров/каскадеров, при этом сейчас она решается зачастую при помощи трудозатратного и дорогого cgi (computer-generated imagery), поэтому интерес диснея здесь не случаен.
Пайплайн и архитектура
Авторы, как и в DFL, используют идею из работы YAN, SHUQI, HE, SHAORONG, LEI, XUE, et al. «Video Face Swap Based on Autoencoder Generation Network», в которой была предложена идея Y-shaped архитектуры нейросети, состоящей из одного энкодера, переводящего изображения в некое общее для двух персон латентное пространство, и двух декодеров, каждый из которых умеет генерировать только одну персону. Таким образом, в латентное пространство сетка пытается закодировать множество эмоций, а распутывание (disentanglement) персон происходит физически при помощи разных декодеров. Однако, в отличие от DFL (широко используемой в нем Stylized autoencoder/SAE-архитектуры), авторы текущей работы предлагают использовать comb-подход с более чем двумя декодерами. Конкретно в экспериментах брали 8 декодеров, которые восстанавливали 6 персон (для 2 персон было по 2 декодера для разных target-видео).

При этом сам пайплайн замены лиц стандартный: вырезаем из кадра target-лицо и выравниваем его, подаем на энкодер, получившийся латентный код подаем на декодер той персоны, которую «пересаживаем» на target, получаем соответствующее по эмоции и прочему appearance лицо из source, делаем обратное выравнивание, пересаживаем итоговое лицо (не забывая блендить).
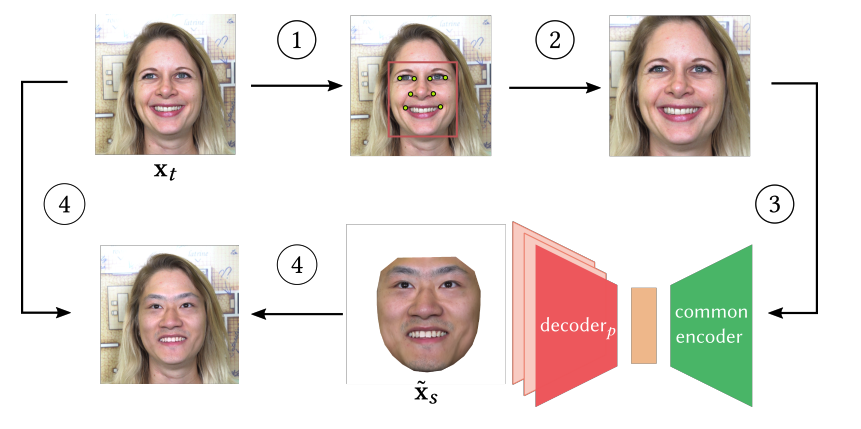
Улучшения и тренировка
Авторами были предложены следующие трюки для улучшения качества работы модели:
- Для обучения автоэнкодеров до разрешения аж 1024 по аналогии с ProGAN/StyleGAN1 используют progressive-обучение, адаптированное под автоэнкодеры: стартуют с разрешения 4×4, на каждом шаге к энкодеру и декодеру добавляют по блоку, работающему с разрешением в два раза большим (с соответствующими энкодеру/декодеру даунсэмплингу и апсэмплингу). Поскольку эти блоки в финальной сетке будут находиться где-то внутри, добавляют еще to_rgb/from_rgb свертки, которые нужны для адаптации инпутов и для подсчета функции потерь на промежуточных этапах. Чтобы не «шокировать» архитектуру новыми блоками с рандомными весами, используют фейдинг, при котором картинка создается из смеси с весами alpha и 1-alpha выхода с нового слоя и увеличенного в 2 раза выхода с предыдущего (уже обученного) слоя. При этом в процессе обучения нового блока коэффициент alpha увеличивается от 0 до 1, а вместе с ним и влияние этого блока.
- При обучении использовали свой датасет из снятых 4K-видео c 9 добровольцами, при обучении каждого нового слоя предъявляли по 10^5 изображений каждой персоны. Само обучение представляет из себя реконструкцию каждым декодером своей персоны, в качестве функции потерь на всех уровнях, кроме двух самых последних/больших, бралась SSIM, а на двух последних — MS-SSIM. При этом подсчет ведется только по маске target-лица, которая получается зачастую небольшим расширением контура, возвращаемого детектором лэндмарок (чтобы брови тоже влезли).
- Большинство детекторов лэндмарок обучалось на не очень больших изображениях, да и точность их проверяется зачастую на отдельных изображениях, что в случае с последовательностью high-res кадров может приводить к скачкам в соседних кадрах и к заметному мерцанию в итоговом видео. Авторы предлагают решить это усреднением предсказаний лэндмарок по n=9 смещенным версиям исходного bounding box«а с лицом (смещения делаются по горизонтальное оси, по сути версия tta).
- Наконец, различия в цвете и освещении между source и target видео может приводить к заметным «швам» (seams) в месте наложения нового лица по маске, не говоря уже о различиях между внутренней частью лица и внешней. Зачастую эту проблему решают применением пуассоновского блендинга (т.н. seamless blending), но он тоже спасает далеко не всегда. Авторы предлагают модифицированный вариант multi-band blending, при котором для смешиваемых изображений строятся пирамиды Гаусса и Лапласа (по сути набор задаунсэмпленных изображений и разниц/граней, по которым можно восстановить исходные изображения). Смешиваем пирамиды по маске (которая тоже даунсэмплится до нужных разрешений) и восстанавливаем итоговое изображение с использованием смешанной пирамиды Лапласа, но для 2 самых ранних и низкочастотных уровней берем оригинальные куски пирамиды от target.
- Помимо этого после такого блендинга считают Global Contrast Factor (глобальная метрика, равная взвешенной сумме локальных контрастов, считаемых через L в Lab), и выход декодера умножают на отношение этого фактора в target и сгенерированном лице.

Результаты
В итоге получаются неплохие визуальные результаты в сравнении с DFL и подходом от Nirkin, основанном на 3dmm. В ablation авторы показывают положительное влияние progressive обучения на детализацию выхода сети, также показывают положительное влияние использования multi-band блендинга и последующего выравнивания контраста (в случае с выравниванием до блендинга получается хуже).
Также авторы говорят о том, что количество декодеров, большее 2, позволяет более адекватно генерировать эмоции для персон в тех случаях, когда в обучающих данных схожих эмоций у персоны не было.
Помимо этого авторы исследовали влияние количества общих слоев у декодеров на качество: важно соблюдать баланс, чтобы, с одной стороны, генерировать нужную эмоцию, а с другой — переносить новое лицо без сохранения черт старого (эта тенденция наблюдается с повышением числа общих слоев); в итоге остановились на 2 общих слоях у всех декодеров.

2. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
Авторы статьи: Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh (USA, 2020)
Оригинал статьи :: GitHub project: (ACL 2020 best paper award)
Автор обзора: Юрий Кашницкий (в слэке yorko, на habr yorko)
Эта работа приоткрывает дверь во взрослое будущее, в котором будет недостаточно выкатить модельку и просто трекать набор метрик. Здесь речь про NLP, но основные тезисы переносятся в целом на весь ML — в ближайшем будущем бизнес заставит нас отвечать за продукт и тестировать его поведение гораздо более системно.

Тут авторы переносят некоторые практики тестирования из SWE на NLP-модельки, в частности black-box testing (только вход-выход, вообще ничего не знаем про саму модель), minimum functionality test (когда на простых примерах проверяется основная функция модели), metamorphic test (небольшие пертурбации, не меняющие разметки, смотрим, как сильно меняется прогноз).
Выкладывают в open source тулзу CheckList, которая помогает автоматизировать и масштабировать создание простых тестов для NLP-моделей. Пример для sentiment analysis: по шаблону «I {negation} {pos_verb} the {thing}» можно наплодить много тест-кейсов с негативным сентиментом (eg. «I don’t like the service»). Прикольно, что они используют RoBerta как MLM, чтоб подсказывать такие слова-вставки, например, для {pos_verb} это like, love, enjoy и т.д. если фантазии не хватает, то тут Роберта подскажет синонимов, причем по контексту.
На примере оценки тональности показывают, что и у коммерческих моделей от гигантов (Google, Amazon, Microsoft) и у SOTA академических моделей (BERT, RoBerta) очень много косяков (но это уже не черри-пикинг примеров, а именно тестирование, a disciplined approach). Интересно, что почти по всем тестам берты лучше коммерческих моделей (исключение — устойчивость к нейтральным фразам, т.к. обучались на датасете SST с бинарными метками тональности).
Пообщались с командой Microsoft Text Analytics, за 5-часовую сессию успели научить их пользоваться тулзой CheckList, провести кучу тестов и найти множество багов в продакшн-системе, которая как-то тестируется внутри самого Microsoft и проходит итерации фидбека кучи пользователей. Если все именно так (а первый автор все же из Microsoft Research), то это просто эпический пример, как лидеров области за бесплатно консультируют и помогают найти кучу проблем в их продукте. Надеюсь, чуваки зарелизили не все, а половину функционала оставили для своего консалтинг-стартапа.
Скорее всего через несколько лет будут выработаны best practices тестирования ML моделей. Осталось самое интересное — понять, как этим ML моделям все же не допускать «детских» ошибок. Систематическое тестирование напрямую с этим не помогает, зато позволяет подебажить модель и обнаружить косяки, неочевидные свойства и т.д., это уже немало.
Предлагают такой системный подход. Есть проверяемые качества (в статье Capabilities), их мы проверяем тестами разных типов. Здесь комментируется на примере анализа тональности, но в статье также анализируются поиск дубликатов (Quora Question Pairs) и Reading comprehension.
Предлагают проверять следующие качества (но можно и многие другие придумать):
словарь + POS — насколько для задачи критичны определенные слова и их формы (например, добавление эмоциональных слов должно соответственно влиять на прогноз);
устойчивость (robustness) к небольшим изменениям, например, к опечаткам (или пример с тональностью: замена одного нейтрального слова на другое не должна особо менять прогноз);
NER — понимание роли именованных сущностей (например, замена одной локации на другую не должна менять прогнозируемую тональность);
отрицание (negation) — вот это вообще боль систем анализа тональности. Пример: «I thought the plane would be awful but it wasn’t»;
и некоторые другие: fairness, temporal, coreference, logic, тут уже от специфики задачи, у того же Reading comprehension будет больше проверяемых качеств.
Теперь 3 типа проверок:
minimum functionality test (навеяно юнит-тестами из разработки) — примеры выше с шаблонами («I {negation} {pos_verb} the {thing}») и отрицанием.
Invariance test — небольшие изменения не должны влиять на прогноз (например, опечатки, добавление рандомных урлов и т.д.).
Directional Expectation test — похоже на предыдущее, только ожидаем, что прогноз определенным образом изменится. Например, добавление «You are lame» должно сделать прогноз более негативным.
Некоторые интересные косяки моделей анализа тональности:
процент фэйлов близок к 100 у всех трех коммерческих моделей в тесте c отрицанием («I thought the plane would be awful, but it wasn«t.»);
коммерческие модели хорошо справляются с шаблонами «I am a {PROTECTED} {NOUN}», где {PROTECTED} — из списка [black, atheist, gay, lesbian, …]- правильно предсказывают нейтральную тональность для фраз типа «I am a lesbian woman». Дрючат их, гигантов, по fairness. BERT, наоборот, почти всегда говорит «negative» в таких случаях;
следует повторить удивительный факт, что почти по всем тестам фаинтюненные на SST модели BERT & RoBerta проявили себя лучше, чем коммерческие.
Авторы статьи: Kalpesh Krishna, Gaurav Singh Tomar, Ankur P. Parikh, Nicolas Papernot, Mohit Iyyer (UMass & Google Research, ICLR, 2019)
Оригинал статьи :: GitHub project: Blog
Автор обзора: Юрий Кашницкий (в слэке yorko, на habr yorko)
TLDR
Забрасывая API с коммерческой BERT-based моделью запросами из почти случайных наборов слов (с лёгкими task-specific эвристиками), можно украсть модель, т.е. воссоздать почти такую же, как и модель-жертва. Рассматриваются способы защиты от такого хулиганства, но в этой борьбе брони и пушки впереди пока пушки.
Как это работает?
Хакер просто файнтюнит свою модель на ответах модели-жертвы (напоминает, кстати, sample-efficient knowledge distillation). И что, все настолько просто? Не совсем, далее идут эвристики. На совсем уж рандомных запросах не сработает, авторы это упоминают.

Для анализа тональности (SST2) эвристики простые — слова берутся из топ-10к (по частотности) wikitext103, остальные заменяются на случайные из этого словаря топ-10к.
В MNLI (natural language inference), вход — это пара предложений: посылка и заключение, предсказывается, как они связаны (entailment, contradiction, neutral). Посылка формируется так же, как для SST2, а заключение просто копирует посылку, и 3 слова заменяются на случайные из все того же словаря топ-10к wikitext103.
Для SQuAD (question answering) параграф и вопрос сэмплируются похожим образом, только к вопросу добавляется вопросительное слово в начало и вопросительный знак — в конец.
И так далее. Не rocket science вроде, но с такими эвристиками работает, а без них — нет.
Идеи двух методов защиты.
Membership classification — выявление выбросов, примеров не из распределения обучающей выборки. API вернет рандомный ответ для таких примеров. Для этого на бэкенде дополнительно строится классификатор real-fake, но и его можно надурить, т.к. классификатор не может предусмотреть произвольное распределение фейка.
Watermarking — для части запросов намеренно выдается неверный ответ, список таких запросов хранится на стороне API. Идея в том, что если атакующая модель обучалась в том числе на таких помеченных запросах, запомнила их и потом была выложена в открытый доступ, то по помеченным запросам в принципе можно установить, что это не оригинальная модель. Большой минус — предположение, что модель будет выложена в открытый доступ. Да и такую легко обойти — надо всего лишь для запросов, полностью совпадающих с украденными, выдавать шум.
Основные выводы:
рассмотрели 4 NLP задачи (sentiment analysis: SST2, natural language inference: MNLI, question answering: SQuAD 1.1. + BoolQ), в каждой из них удалось с помощью adversarial атаки обучить модель от 10% до 2% по метрикам хуже модели-жертвы;
цена такой атаки зависит от числа запросов и не превысила $400 в их экспериментах (для BoolQ — всего $6);
атаки довольно эффективны и по числу примеров, т.е. хоть что-то осмысленное можно утащить даже с небольшим числом запросов (1к-10к), а с какого-то момента видно насыщение качества атакующей модели;
если выбирать запросы с высокой согласованностью прогнозов моделей жертв (например, если взять ансамбль моделей-жертв, обученных с разными сидами), то атака более эффективна;
аккуратно выбранные из Википедии параграфы улучшают атаку в сравнении рандомными запросами, но не сильно;
если в задаче классификации API выдает не распределение вероятностей, а только наиболее вероятный класс, атака все равно возможна, причём почти так же эффективна;
если взять атакующую модель пожирнее, то атака улучшается даже если архитектура не совпадает с архитектурой модели жертвы. e.g. если за API — BERT-base, то атаковать лучше с BERT-large, чем BERT-base. И далее, если взять XLNet, то атака ещё лучше;
трансфер лернинг критичен (то что атакующие модели из BERT семейства уже видели много данных) — обучиться на ответах модели-жертвы с нуля (без предобучения, т.е. с рандомных весов атакующей модели) вообще не получилось.
Еще одна статья, показывающая, как мало мы знаем про эти блэк-боксы, какая это пока leaky abstraction и как много ещё интересных новостей придет из мира adversarial атак и, шире, информационной безопасности в контексте ML.
4. Time-Aware User Embeddings as a Service
Авторы статьи: Martin Pavlovski et.al. (Yahoo! Research, Temple University, 2020)
Оригинал статьи
Автор обзора: Денис Воротынцев (в слэке tEarth, на habr tEarth)
Авторы исследуют вопрос создания эмбедингов активности юзера в сети для последующего использования в моделях второго уровня (ctr prediction, click-through rate). Предложенный подход лучше по качеству чем предложенные ранее. Авторы предлагают использовать полученные эмбединги в embeddings-as-service для своих внутренних (и возможно в будущем и для внешних) стейкхолдеров.
Предположим решается задача ctr predictions. На каждого пользователя есть информация об его активности в сети и время этой активности. Активность юзера имеет большое количество категорий: тысячи и десятки тысяч действий.
При использовании этой информации «как есть» либо нужно генерировать фичи руками, что практически невозможно ввиду сложности задачи; либо использовать нейронные сети, но тут получатся крайне жирные модели, которые (1) тяжело и долго обучать (2) не факт что пройдут по требованиям скорости инференса.
Можно отказаться от использования этих данных вовсе, и использовать только демографические фичи (пол, возраст и т.п.), при таком подходе модели получаются довольно слабыми. Выход: давайте натренируем эмбединги активности и будем использовать их как инпут для моделей второго уровня.
Авторы предложили следующую архитектуру и подход к обучению. Инпут — sequence действий a1, a2, … aL, aL+1 с временем этого действия t1, t2, … tL, tL+1 (L — длина sequence, aL+1 — EOS токен).
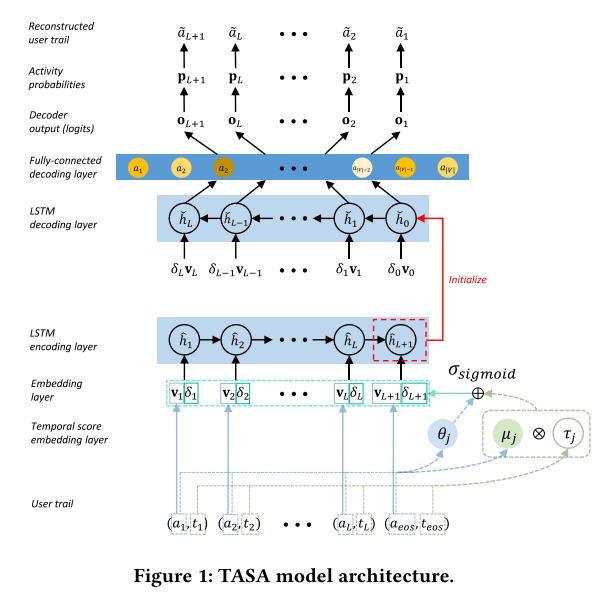
Преобразование входного вектора активности — это, как может оказаться, киллер-фича этой работы. Входной вектор активностей преобразуется в эмбединг активности — aj → vj (эмбединг слой, все стандартно). Затем считается stop feature — текущее время / время последней активности в секвенсе — τj = tj / tL+1. Затем каждая активность мапится в latent space (θj и µj). θj отображает влияние данной активности на секвенс эмбединг, а µj и τj — влияние времени активности на секвенс эмбединг. Считаем temporal score — δj = σ (θj + µjτj) (где σ — сигмоида), на который потом будет домножен секвенс эмбединг — v_hatj = δj*vj. v_hatj подается в следующий слой.
Замечание от автора обзора: В настоящее время есть много подходов по добавлению информации о времени в эмбединг: конкат со временем, конкат с sin/cos времени, positional embeddings и т.п. Не очевидно использование латентных переменных, и преимущества считать именно так. Возможно, это объясняется непостоянностью t, то есть разница между tn, tn+1 очень сильно варьируется, но зачем тогда пихать сюда a_n еще раз.
Затем идет стандартный lstm слой, который кодирует инпут секвенс в эмбединг h (этот эмбединг и будет использоваться как целевой), из которого восстанавливается входной секвенс (стандартная seq2seq lstm модель). Затем идет full connected layer который считает вероятность каждой активности.
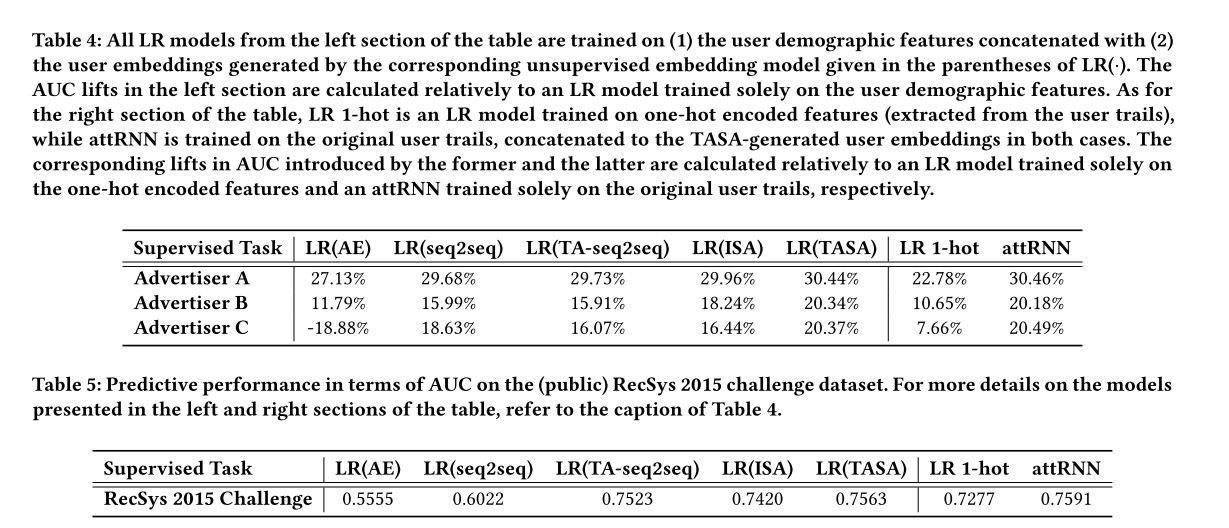
Авторы сравнили свой подход с предыдущими работами: fully-connected AE, seq2seq (lstm), time-aware seq2seq, ISA. Полученный подход лучше реконструирует активность (несколько метрик, два датасета).

Плюс авторы сравнили скоры подхода «эмбединг + LR (Logistic Regression) на целевую задачу» с моделями построенных на сырых данных для решения целевой задачи: LR, attention RNN (attRNN), xgboost. Авторы не могут сообщать скоры на своих датасетах, так что они привели прирост по сравнению с бейзлайном (LR на демографических фичах). Из таблицы 4 видно, что эмбединг + LR сравнялся по качеству с attRNN, обучение которого на порядок дольше.
Авторы в статье также рассказали про подход embedding as service.
5. Are Labels Necessary for Neural Architecture Search?
Авторы статьи: Chenxi Liu, Piotr Dollár, Kaiming He, Ross Girshick, Alan Yuille, Saining Xie (Johns Hopkins University, Facebook AI Research, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Денис Воротынцев (в слэке tEarth, на habr tEarth)
Оказалось, что не особо.
Neural architecture search (NAS) позволяет найти оптимальную архитектуру для выбранной задачи. По сути, NAS — это оптимизация гиперпараметров сети, где у нас есть изменяемые параметры (количество слоев, их тип, дропауты, количество нейронов в слое и т.п.) и метрика качества (здесь и далее — accuracy); мы хотим найти такие параметры, чтобы качество → max. NAS — supervised метод обучения, нам нужны таргеты целевой задачи, чтобы найти оптимальную архитектуру.
К сожалению, это не всегда возможно. Например, в случае если для нашей задачи мало данных. Некоторые работы (Learning transferable architectures for scalable image recognition, CVPR) предлагают очевидный выход: давайте оптимизируем параметры на одном таске, а архитектуру применим на другом. Так, найдя сеть на cifar, можно применить ее к Imagenet.
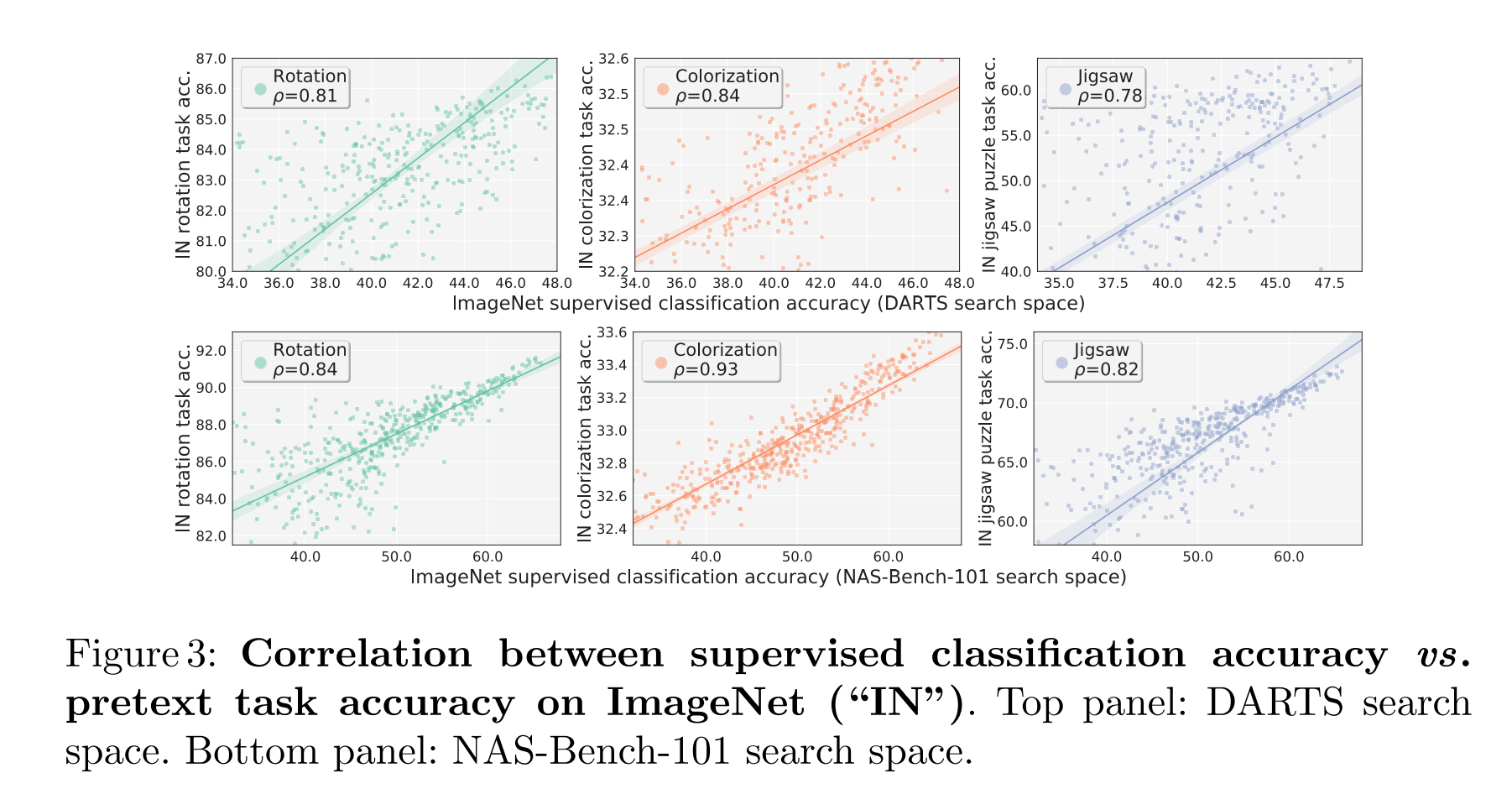
Авторы данной работы решили пойти дальше: давайте вообще откажемся от использования лейблов целевой задачи и придумаем свои. По сути, нам все равно какие веса выучит сеть, нам важна архитектура. Авторы предлагают несколько тасок (прокси-задачи) для использования вместо лейблов: Rotation prediction (классификация, на какой угол повернули картинку), Colorization (pixel-wise classification: gray imgs → colored imgs), Solving jigsaw puzzles (делим картинку на пазл, мешаем, сеть должна предикнуть как перемешали). Авторы прогнали 500 итераций NAS используя несколько методов поиска — DARTS и NAS-Bench-101. Для каждой предложенной NAS архитектуры посчитали качество на прокси-задачу и качество на целевой задаче (переобучили архитектуру с таргетами целевой задачи), между этими метриками посчитали ранговую корреляцию. Оказалось, что корреляция довольно высокая (см. выше), топовые модели на прокси-задаче часто являются топовыми и на целевой задаче.
Довольно простая, но при этом интересная идея. Данный подход, как мне видится, просто киллер фича в задачах с малым количеством лейблов, но большим количеством данных.
6. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Авторы статьи: Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, Zhifeng Chen (Google, 2020)
Оригинал статьи
Автор обзора: Артем Родичев (в слэке fuckai)
TL; DR
- Сделали модуль GShard, который позволяет скейлить нейросетевые модели с помощью нескольких простых функций репликации и шардирования тензоров по нескольким девайсам (TPU/GPU).
- С помощью GShard отскейлили трансформер на основе Mixture-of-Experts. Натренировали несколько моделей варьируя количество трансформер-слоев и экспертов. Тренировали на задаче multilingual machine translation на 100 языковых парах. Самая большая модель — на 600B параметров, тренировали 4 дня на 2048TPU v3.
- Показали что их способ скейлинга трансформера является эффективным — низкий communication cost между девайсами, а training cost растет сублинейно относительно роста размера модели.
Суть
Стало очевидно, что для получения SOTA нужно тренировать большие сети. Они лучше и быстрее сходятся, а также являются более sample efficient, чем аналогичные сети меньшего размера. Однако нет удобных инструментов для скейлинга сетей. Из коробки model parallelism в pytorch или tf работает неэффективно — раздувает вычислительный граф, ведет к большим накладным расходам на коммуникацию между девайсами, добавляет sequential dependency в вычислениях. Если же хочется сделать эффективный скейлинг своей модели, то нужно заниматься инженерией и ручным раскладыванием вычислительного графа по девайсам. Все это плохо, хочется тренировать большие сети удобно и эффективно.
Для этого гугл предложили фреймворк GShard, который включает в себя:
Легковесное API c 3 основными командами:
- replicate (tensor) — реплицировать (копировать) веса на все девайсы (TPU/GPU);
- split (tensor, split_dimension, num_partitions) — делит тензор на num_partitions по заданной размерности split_dimension и раскладывает каждую партицию на соответствующий девайс;
- shard (tensor, device_assignment) — обобщение split (), на какие девайсы нужно шардировать тензор целиком.
Компилятор вычислительного графа, который оптимально строит единый для всех девайсов вычислительный граф и рассылает его на все девайсы. Компилятор реализует эффективное шардирование и реплицирование весов по девайсам. Работает в парадигме SPMD (Single Program Multiple Data), что делает время компиляции вычислительного графа константным, независимым от количества девайсов.
На основе GShard сделали огромный трансформер, который назвали Sparsely-Gated Mixture-of-Experts Transformer. Представляет из себя слегка модифицированный оригинальный трансформер. Обычный трансформер блок (слой) состоит из бутерброда [вход → мультихэд-аттеншн → нормализация → FNN → нормализация → выход] + два res коннекшена (см картинку). Финальный трансформер состоит их N таких слоев. Для скейлинга предлагается в каждом нечетном слое добавить Mixture-of-Experts вместо FNN. Mixture-of-Experts представляет из себя E полносвязных двухслойных FNN сетей + gating механизм, который решает, какому подмножеству экспертов мы передадим на вычисление текущий токен. Аутпут с этого блока считается как усреднение выходов всех FNN, которые участвовали в вычислении для данного входа, умноженные на соответствующие гейтинг веса.

Gating механизм реализуется софтмаксом над количеством экспертов, где i-ый аутпут означает важность/вес i-го эксперта. Хочется, чтобы гейтинг эффективно и равномерно балансировал нагрузку между экспертами и соответственно девайсами. Для этого применим следующие хаки:
- Чтобы не перегружать экспертов, ограничим capacity каждого эксперта как O (N/E), где N — кол-во токенов в батче, E — кол-во экспертов. Введем каунтер, сколько токенов мы обработали данным экспертом, и если превысили его capacity, то не делаем вычисления этим экспертом для очередного токена.
- Добавляем к NLL лоссу дополнительный Auxiliary loss минимизирующий долю токенов на эксперта. Это форсит гейтинг функцию не выбирать каждый раз одних и тех же экспертов, а балансировать между всеми.
- Для каждого токена ограничим вычисления максимум двумя экспертами, которые получили максимальные веса после софтмакса в гейтинг функции. При этом второй эксперт может иметь маленький вес и тогда мы сделаем вычисление, результаты которого почти не повлияют на аутпут. Поэтому будем делать вычисление на втором эксперте с вероятностью пропорциональной его весу.
В итоге получается эффективная схема вычислений, когда для определенных токенов нужно задействовать не больше двух экспертов, а нагрузка между экспертами балансируется с помощью гейтинг-механизма. По сути это можно рассмотреть как единую большую нейросеть, которая для разных входов активирует только некоторую подсеть/подсети и тратит намного меньше вычислительных ресурсов, относительно классического большого трансформера без MoE.
Результаты
Для демонстрации подхода выбрали задачу multilingual machine translation на 100 языковых парах, при этом рассматривали перевод только в одну сторону, НА английский. Языковые пары есть как low-resource на десятки тысяч примеров, так и high-resource на миллиарды сэмплов. Итоговый трейнсет составил 13B сэмлов.
При обучении сетей на задачу multilingual перевода наблюдается два свойства:
- Low-resource языковые пары бенефитят из-за positive transfer. Качество на таких языковых парах улучшается из-за шаринга параметров сети при обучении с другими high-resource языками.
- High-resource языковые пары наоборот деградируют из-за capacity bottleneck. Качество на таких языковых парах ухудшается из-за подмешивания многих других языков. Модели перестает хватать capacity, чтобы хорошо решать задачу перевода для всех языков одновременно.
Первое свойство нам на руку, а второе MoE Transformer исправляет тем, что имеет большое количество параметров и capacity.
Выучили 6 разных моделей, варьируя количество слоев (12 или 36) и кол-во экспертов (128, 512, 2048). Самая большая модель на 36 слоев и 2048 имеет 600B параметров. Интересно, что все модели тренировали в fp32 для стабильности трейна. Пробовали выучить модель на 1T параметров c bfloat16, но она не заработала из-за численной нестабильности. Каждую модель учили показав одинаковое количество токенов. Всего токенов 1T (10^12).
В качестве первого бейзлайна взяли 100 моделей, каждая по 400М параметров, и каждая училась на своей отдельной языковой паре. Второй бейзлайн — 96 слойный обычный трансформер без MoE на 2.3B параметров, его учили одновременно на всех языковых парах, причем учили 40 дней на 2048 TPU (235 TPU лет).
По графикам качества видно, что увеличение глубины модели всегда ведет к значимому увеличению качества как для low-resource, так и для high-resource языковых пар. Также видно, что увеличение количество экспертов при одинаковом количестве слоев тоже бустит качество, особенно для high-resource языках из-за расслабления capacity bottleneck.
Еще показали, что глубокие модели сходятся намного быстрее и являются более sample efficient, чем неглубокие. При этом увеличение количества экспертов при одинаковой глубине не всегда приводит к лучшей сходимости (модель с 512 экспертами сошлась быстрее/также как и модель с 2048 экспертами)

7. Data Shapley: Equitable Valuation of Data for Machine Learning
Авторы статьи: Amirata Ghorbani, James Zou (USA, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Денис Воротынцев (в слэке tEarth, на habr tEarth)
SHAP как алгоритм поиска важных глобальных и локальных фичей — это, пожалуй, сота современного интерпретируемого мл. Подход основан на расчете Shapley values, идея взята из теории игр. Каждая фича принимается как игрок в коалиции, цель которой — максимизация скора. Shapley value фичи при интерпретации одного примера — это вклад данной фичи в финальный предикт по сравнению со средним предиктом. Глобальная важность фичи — это сумма абсолютных значений shapley values каждого примера в данном датасете. Преимущества данного подхода — универсальность, мы можем считать shapley values для любой модели. Недостаток — необходимость большого количества вычислений.
Авторы задались вопросом: что если мы применим shapley values для поиска наиболее важных примеров в обучающей выборке? Известно, что в датасете может быть шум в разметке, некоторые примеры могут просто ухудшать скор и так далее. Идея в том, что мы найдем вклад каждого примера в финальный скор и удалим те примеры, которые ухудшают скор.
Поскольку для точного расчета вклада каждого примера необходимо рассмотреть n! комбинаций (n — количество сэмплов в обучающей выборке, «рассмотреть» — обучить модель и рассчитать скор), авторы предложили использовать Монте-Карло перемешивание для аппроксимации расчетов (TMC-Shapley algorithm):
- Случайно перемешиваем индексы обучающей выборки — idx.
- Проходим по индексам j = 1 до idx: создаем обучающую выборку (сэмплы от 1 до текущего индекса j), обучаем модель на сэмле, считаем лосс. Вклад j примера = текущий лосс минус лосс на прошлой итерации.
- Повторяем пункты 1–2 до сходимости (критерий — приращение shapley values меньше константы), итоговый shapley value примера — среднее по всем итерациям.
Авторы также предложили G-Shapley algorithm, который может применяться при обучении сетей. Отличие по сравнению с TMC-Shapley algorithm состоит в том, что мы не обучаем модель с нуля, а используем bs=1 и смотрим на историю лосса.
Подход был протестирован на двух датасетах: «In this experiment, we use the UK Biobank data set (Sudlow et al., 2015); the task is predicting whether an individual will be diagnosed with Malignant neoplasm of breast and skin (ICD10 codes C50 and C44, binary classification) using 285 features. Balanced binary data sets for each task are created and we use 1000 individuals for the task of training. Logistic regression yields a test accuracy of 68.7% and 56.4% for breast and skin cancer prediction, respectively. Performance is computed as the accuracy of trained model on 1000 separate patients.»
На двух датасетах алгоритм сошелся за 2к итераций, что конечно быстрее чем 1000! итераций (в трейне было 1k примеров), но далеко до идеала: «For all the experiments, calculating data Shapley values took less than 24 hours on four machines running in parallel (each with 4 cpus) except for one of the experiments where the model is a Conv-Net for which 4 GPUs were utilized in parallel for 120 hours.»

Подход сравнивают с leave-one-out подходом. Предложенный подход значительно обходит loo, но требует в 2к раз больше времени на расчет. Авторы также рассмотрели задачу поиска шума в разметке, где продемонстрировали значительные приросты по сравнению с loo. Впрочем, loo — это не сота этой задачи.
В целом приросты метрик выглядят очень сочными, подход выглядит интересным на небольших датасетах или при использовании с какой-либо эвристикой для уменьшения требуемого количества вычислений.
8. Language-agnostic BERT Sentence Embedding
Авторы статьи: Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, Wei Wang (Google AI, 2020)
Оригинал статьи :: GitHub project: Blog
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
Очередная SOTA статья от Google. Они адаптировали мультиязычный BERT для создания эмбеддингов предложени
