RTK query, что мы от него хотим и почему он вам очень нужен
Redux Toolkit Query — это мощный инструмент для взаимодействия с API, который из коробки реализует такие полезные фишки, как отображение состояния загрузки, кэширование, дедупликацию запросов, полинг, ревалидацию при различных условиях, а также весьма удобна в использования за счёт готовых хуков.
Привет, меня зовут Антон Степанов, я — frontend-разработчик в Альфа-Банке. В статье расскажу какие задачи при работе с API frontend-разработчику приходится решать чаще всего, к каким идеям рано или поздно это может привести, и как их можно реализовать в RTK query, собственно.
Об авторе:
 Антон Степанов,
Антон Степанов, Frontend-разработчик в Альфа-Банке и лектор в онлайн-школе. Пришел в профессию ещё в те времена, когда сайты делали на различных CMS. Затем увлёкся JS и так плавно перешёл на React. Работал тимлидом, ещё когда был молод и не знал, какую ошибку совершает.
А что такое фронтенд?
Фронтенд — это про интерфейс.
Почти каждое приложение на фронте, в том числе на React, глобально сводится к одному и тому же: мы получаем данные с бэка, визуализируем их и позволяем пользователю с ними взаимодействовать и иногда менять. Всё.
При этом загрузку данных в React мы можем реализовать множеством способов. Такая гибкость — наше преимущество, но и недостаток.
С одной стороны можно написать покороче/подлиннее/попроще (джунам вообще полезно потренироваться на Vanilla JS)
С другой стороны, каждый раз, когда мы будем оптимизировать наше приложение, то будем сталкиваться с одним и тем же набором вызовов. Из базового, например, мы не хотим повторно запрашивать данные, которые не меняются, хотим отображать лоадер или ошибку, хотим избежать двух одинаковых запросов одновременно.
Но давайте посмотрим, как мог бы выглядеть наш типичный код при базовом подходе средствами React без дополнительных библиотек.
Начинаем с нуля
Представим типичное приложение, которое выводит список пользователей и при клике на каждого открывает страницу с подробной информацией и списком сообщений пользователя.
Начнем с компонента, отображающего подробный профиль пользователя.
export function User({ id }) {
const [user, setUser] = useState();
useEffect(() => {
async function getData() {
try {
const response = await fetch(url + ‘users/${id}’);
let data = await response.json();
setUser(data);
} catch (e) {
}
}
getData();
}, [id]);
if (user) return ;
return null;
}
Примечание. Я намеренно разделил компоненты на осуществляющие логику и вьюхи, чтобы мы могли посмотреть на работу с API не отвлекаясь на интерфейс. Здесь
Дальше к нам приходит заказчик и говорит: «Хочу, чтобы показывался лоадер и отображалась ошибка если пользователя нет». Мы вводим два дополнительных стейта на уровне компонента — кода становится больше.
useEffect(() => {
async function getData() {
setError(false);
setLoading(true);
try {
const response = await fetch(url + ‘users/${id}’);
let data = await response.json();
setUser(data);
setError(false);
} catch (e) {
setError(true);
}
setLoading(false);
}
getData();
}, [id]);
if (isFetching) return ;
return null;
}
Потом заказчик говорит: «У нас регулярно обновляются сообщения: хочу, чтобы пользователь видел всегда свежие». Вводим поллинг.
useEffect(() => {
async function getData() {
setError(false);
setLoading(true);
try {
const response = await fetch(url + ‘users/${id}’);
let data = await response.json();
setUser(data);
setError(false);
} catch (e) {
setError(true);
}
setLoading(false);
}
const interval = setInterval(() => getData(), 1000);
return ()=> clearInterval(interval);
}, [id]);
if (isFetching) return ;|
return null;
}
Кода становится всё больше и больше, и он довольно однотипен. К тому же, его приходится повторять в разных компонентах.
Мы, конечно, можем вынести что-то в кастомные хуки, и это уже будет неплохим решением, но повторяемость всё равно высока. С нашей стороны будет похвально обрабатывать ситуацию, когда компонент размонтирован, а данные только загружаются. Добавим mounted чтобы не делать setState для размонтированного компонента.
useEffect(() => {
let mounted = true;
async function getData() {
setError(false);
setLoading(true);
try {
const response = await fetch(url + ‘users/${id}’);
let data = await response.json();
if (mounted) {
setUser(data);
setError(false);
}
} catch (e) {
setError(true);
}
setLoading(false);
}
const interval = setInterval(() => getData(), 1000);
return () => {
clearInterval(Interval);
mounted = false;
}
}, [id]);
Здесь всё еще не решена проблема отмены fetch с помощью signal при размонтировании, и, несмотря на то, что кода уже много, большинство озвученных в начале проблем ещё не решены. А ещё, полученные данные мы храним в состоянии компонента (внутри кастомного хука). Но если приложение хотя бы чуть сложнее, возникнет момент, когда мы захотим, чтобы наши данные были доступны во всём приложении.
Здесь появляется стэйт менеджмент
Воспользуемся Redux — самой популярной библиотекой для управления глобальным состоянием. Опишем переменные состояния и типичный редьюсер:
const initialState = {
data: undefined,
loading: false,
error: false
}
export default function ServiceListReducer(state = initialState, action) {
switch (action.type) {
case FETCH_SERVICES_REQUEST:
return {...state, loading: true, error: null };
case FETCH_SERVICES_FAILURE:
const { error } = action.payload;
return {...state, loading: false, error };
case FETCH_SERVICES_SUCCESS:
const data = action.payload;
return {...state, data, loading: false, error: null };
default:
return state;
}
}
Примечание. Здесь я специально добавил редьюсер на чистом Redux, как типичный пример того, что часто вижу на курсах, когда люди сдают дипломные проекты и пишут стандартный код, но глубоко во взаимодействие с API не погружаются и не испытывают интерес изучать глубже. Обратите внимание, на обилие кейсов всего лишь для состояния загрузки.
В целом, подход на чистом Redux устарел. Официально рекомендуемый подход (об этом написано на первой странице документации) — это Redux Toolkit. При таком подходе объем бойлерплейт кода будет существенно меньше для каждого эндпойнта. Логика будет вынесена из компонента с использованием санок (саг), но мы опять вынуждены будем повторять код (набор переменных loading, error, data) для каждого слайса (slice — термин Redux Toolkit).
Раз мы повторяем это действие многократно, должен быть способ упростить задачу.
Итак:
Давайте еще раз озвучим, какие проблемы мы хотим решить:
Загрузка данных.
Отображение статуса загрузки и ошибки.
Дедубликация запросов.
Кэширование. Инвалидация.
Загрузка заново в случае ошибки.
Поллинг.
Оптимистичное обновление.
Экономия памяти.
Экономия кода.
Доступ к данным в любом компоненте при этом избежание повторных запросов с одинаковыми параметрами.
А теперь посмотрим, как легко и элегантно это решается и использованием Redux Toolkit Query (RTK Query). Сейчас я сыграю роль «коммивояжера», и буду предлагать вам библиотеку, которая «волшебным образом» решит ваши проблемы.
Сейчас буду убеждать
У нас есть приложение с бэкендом на Koa, достаточно простым: он возвращает данные о пользователях и их сообщениях. При этом иногда выбрасывает ошибку.
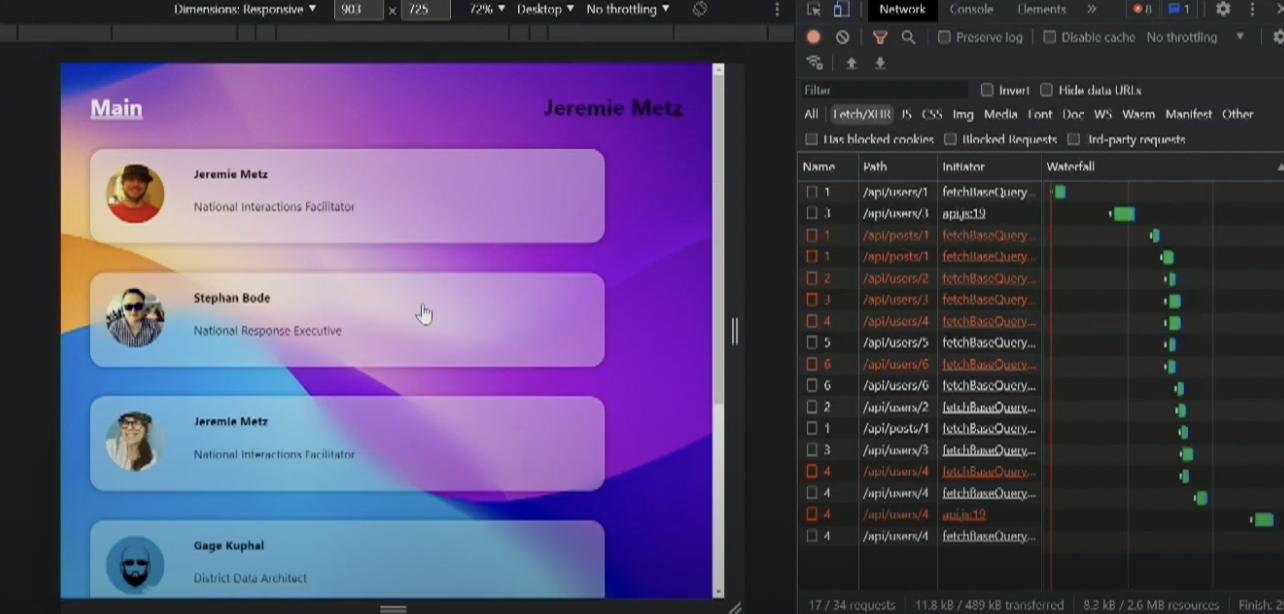
Начнем с того места, на котором остановились, и визуализация нашего кода выглядит так.
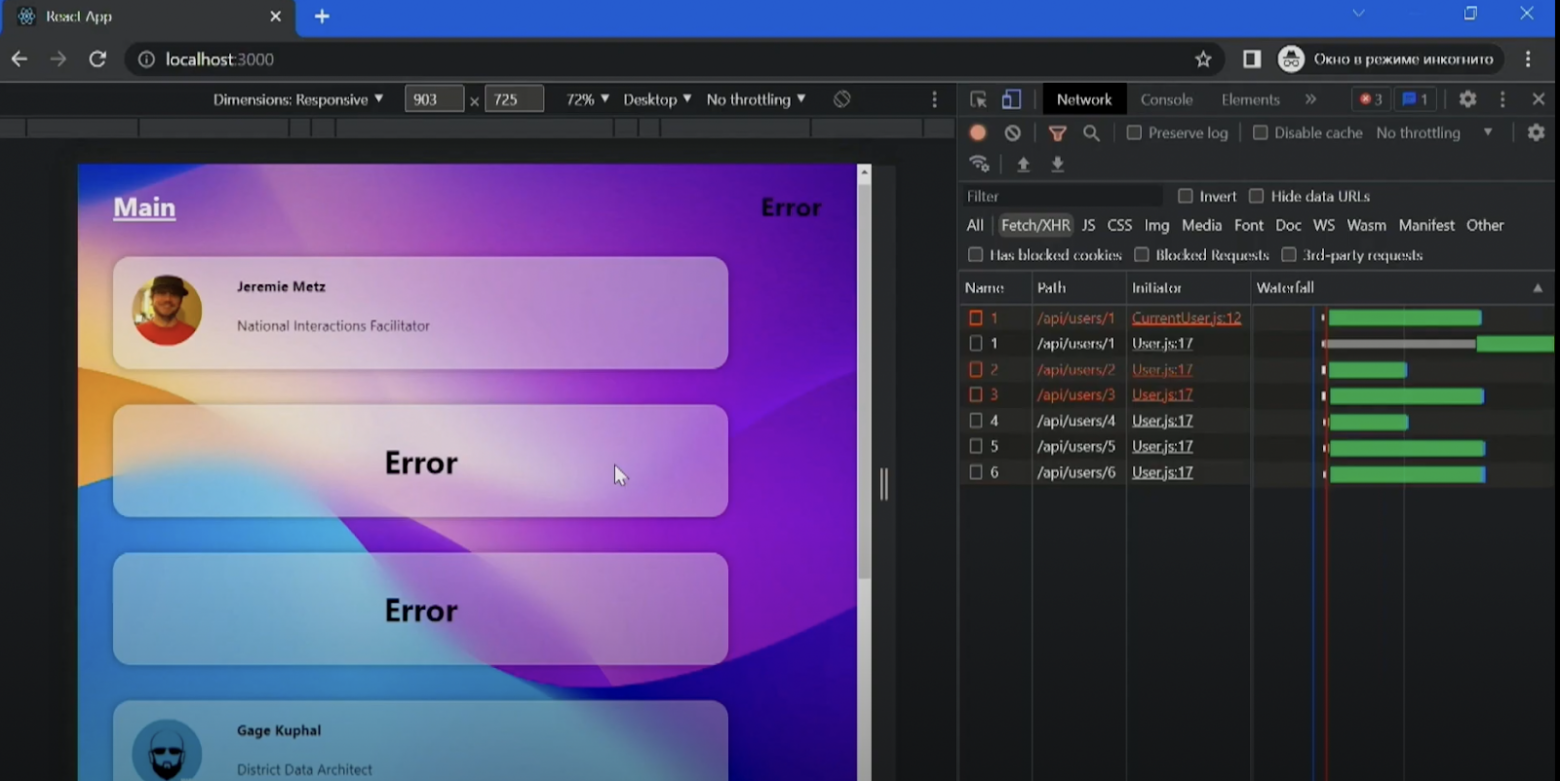
Все данные генерируются с помощью фэйкера. Видно два запроса к api/users/1: загружаются заголовки и сообщения об ошибках.
Ссылки на код фронта и бэка из демонстрации дальше
Код фронта: https://github.com/copperfox777/rtq-alfa-presentation-front
Код бэка: https://github.com/copperfox777/rtq-alfa-presentation-backend
Перейдем к предмету нашего разговора — к внедрению библиотеки.
Библиотека Redux Toolkit Query о которой пойдёт речь уже включена в Redux Toolkit поэтому дополнительно ничего ставить нам не придётся.
Стор. Будем делать стор на redux-toolkit. Создадим отдельный редьюсер для взаимодействия с апи, который затем подключим к стору как обычный редьюсер. Код есть в официальной документации, но всё же приведу его как пример:
store.js:
export const store = configureStore({
reducer: {
// Добавляем редьюсер как слайс
[api.reducerPath]: api.reducer,
someAppSlice: someAppSlice.reducer // какие то другие общие данные
},
// Добавляем апи мидлвар, что даст нам кэширование, инвалидацию, полинг,
// и другие полезные штуки
middleware: (getDefaultMiddleware) =>
getDefaultMiddleware().concat(api.middleware),
})
// Это нужно для refetchOnFocus/refetchOnReconnect о чем далее
setupListeners(store.dispatch)
Подразумевается, что всё приложение у нас будет обернуто в провайдер, как всегда в Redux.
const root = ReactDOM.createRoot(document.getElementById("root”)!);
root.render(
);API. Самая интересная часть — это описание нашего API. Мы описываем эндпойнты — точки, где собираем данные.
myApi.js:
import { createApi, fetchBaseQuery } from "@reduxjs/toolkit/query/react”;
const url = "http://localhost:7070/api/”;
export const api = createApi({
reducerPath: "api”,
endpoints: (builder) => ({
getUsers: (builder.query({
queryFn: async (arg) => {
try {
const response = await fetch(url + ‘users’);
return {data: await response.json() };
} catch (e) {
return { error: e.message };
}
},
}),
}),
});
export const { useGetUsersQuery, useGetUserQuery, useGetPostQuery } = api;Разберём подробнее:
Первый эндпойнт — это getUsers для получения всего списка пользователей. В нём мы описывает queryFn — асинхронную функцию, внутри которой мы выполняем запрос. При этом, в зависимости от результата запроса (success, failure), мы возвращаем объект со свойством data, либо error, соответственно.
Аналогично с небольшими изменениями описаны еще два эндпойнта и экспортированы соответствующие хуки. Названия хуков соответствуют названиям эндпойнтов getUser => useGetUserQuery.
Примечание. Наш пример несколько отличается от документации. Там для загрузки данных используется поставляемый вместе с библиотекой fetchBaseQuery, которая в большинстве случаев весьма удобна. Тогда почему именно такой пример? Во многих компаниях есть свои библиотеки (обёртки), которые используются для получения данных. Поэтому у вас может быть не fetch, а что-то своё хитрое.
Теперь применим экспортируемый хук в нашем компоненте:
function Component() {
const { data: user, isError, isFetching, refetch } = useGetUserQuery(id);
if (isFetching) return Хуки Redux Toolkit Query возвращают не только вышеуказанные переменные, но и несколько весьма полезных других — это error, isUninitialized, isLoading, currentData, isSuccess, refetch. Названия «говорящие»
Примечание. Подробное описание доступно в документации.
Для тех из вас, кто работал с подобными библиотеками, такой подход покажется знакомым.
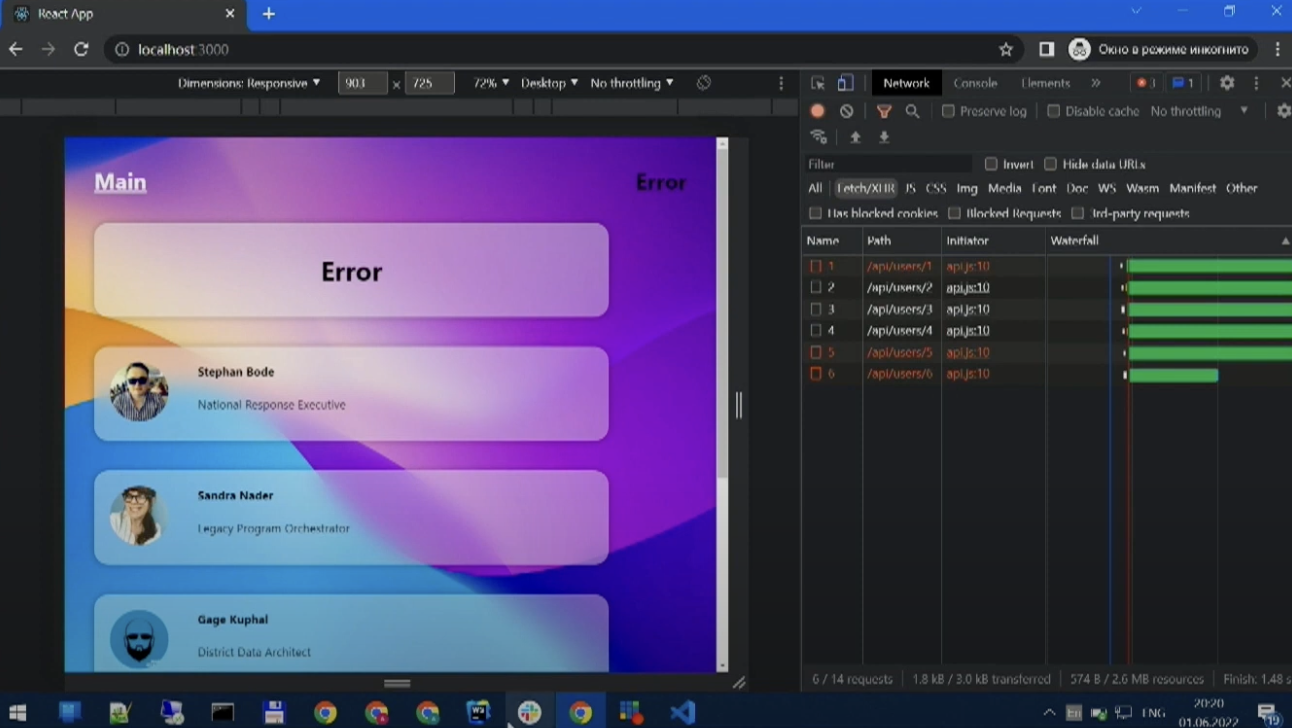
При переходе на карточку пользователя мы заметим, что данные повторно не загружаются. Это из коробки работает кэширование, которое завязано на параметры передаваемые в хук. Также есть регулируемый параметр времени жизни кэша. При превышении времени каш, относящийся к данному параметру, очищается.
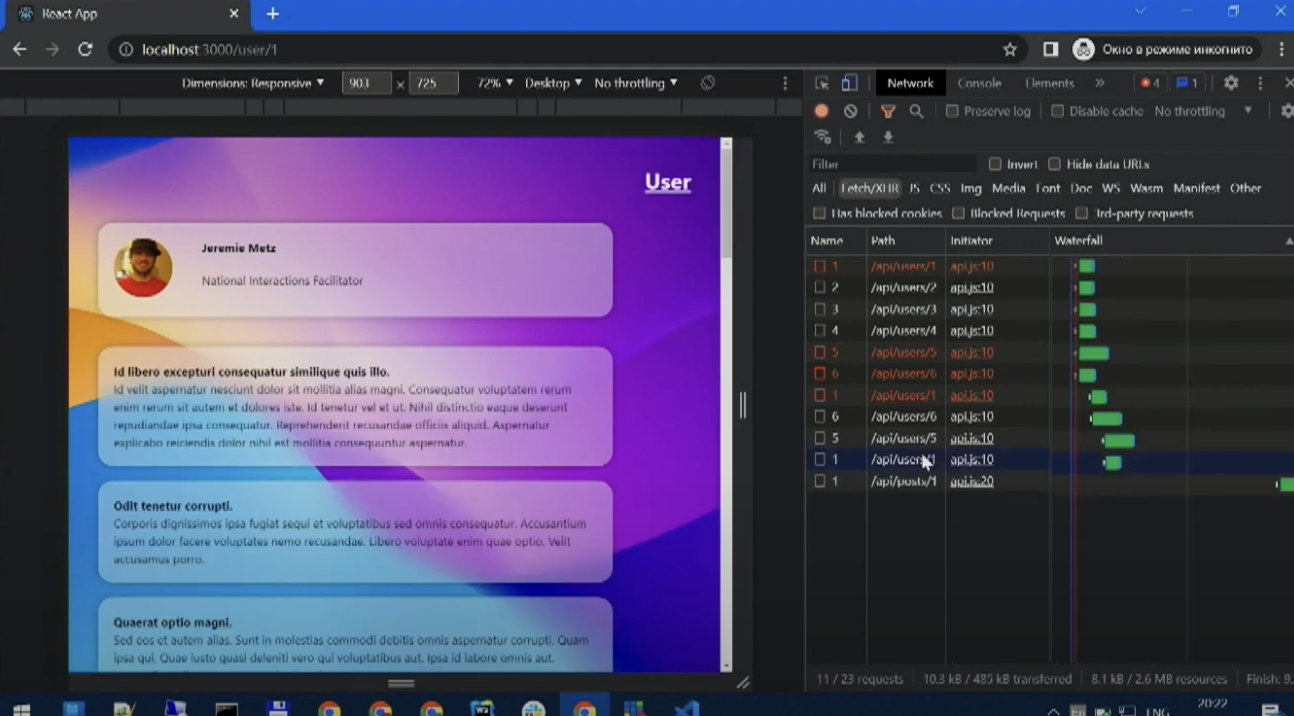
Мы внедрили библиотеку, написали лишь один эндпойнт и решили несколько проблем минимальными усилиями. При этом код наш прост и понятен: он короткий, но не теряет в своем качестве, потому что остается понятным.
Фишки
Добавим пару кнопок на странице пользователя.
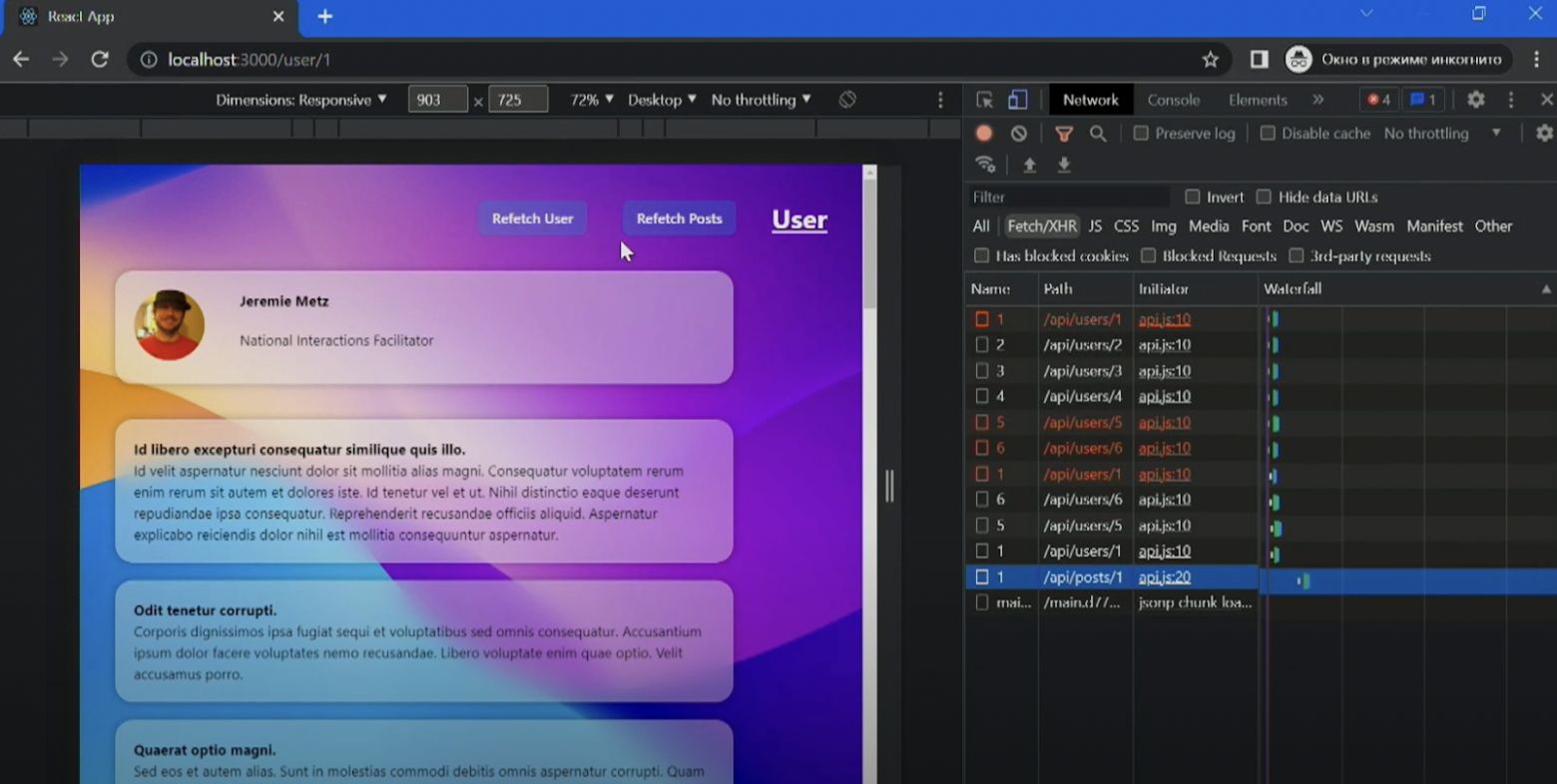
Для принудительного обновления данных (и кэша) добавим кнопки, которые будут вызывать refetch, возвращаемый хуком и обновлять данные и кэш.
Далее рассмотрим сценарий, когда нам нужно обновлять данные, в данном случае сообщения пользователя, которые могут меняться довольно часто.
В этом нам поможет один из дополнительных параметров передаваемых в хук pollingInterval.
export function UserPage() {
const { id } = useParams();
const {
data: posts,
isError,
isLoading,
isFetching,
refetch: refetchPosts,
} = useGetPostsQuery(+id, { pollingInterval: 3000 });
Один параметр и желаемый эффект достигнут. Profit.
Еще один интересный параметр keepUnusedDataFor — определяет, сколько по времени хранить данные в кэше. Отсчёт начнется, когда все компоненты с этим хуком размонтированы.
export function UserPage() {
const { id } = useParams();
const {
data: posts,
isError,
isLoading,
isFetching,
refetch: refetchPosts,
} = useGetPostsQuery(+id, { pollingInterval: 3000,
keepUnusedDataFor: 120 });
Следующая полезная опция — refetchOnReconnect.
export function UserPage() {
const { id } = useParams();
const {
data: posts,
isError,
isLoading,
isFetching,
refetch: refetchPosts,
} = useGetPostsQuery(+id, {
pollingInterval: 3000,
keepUnusedDataFor: 120,
refetchOnReconnect: true
});
Например, пользователь едет в метро и связь теряется. Чтобы пользователь увидел обновлённый контент, когда связь восстановится, ставим refetchOnReconnect: true.
refetchOnFocus — для быстро меняющихся данных. Пользователь ушёл со страницы, вернулся, данные обновились.
refetchOnMountOrArgChange — для случаев, когда необходимо, чтобы данные были максимально «свежими».
Примечание. Подробное описание поведения кэша и дополнительных параметров.
На предыдущем шаге у нас было 2 эндпойнта: один для получения данных пользователей, второй — для получения сообщений.
Вот этот участок кода, в каком-то смысле, однотипный.
…
queryFn: async (arg) => {
try {
const response = await fetch(url + ‘users/${arg}’);
return {data: await response.json() };
} catch (e) {
return { error: e.message };
}
},
…
Чтобы избавится от этого, рекомендую попробовать упомянутый выше fetchBaseQuery. Это простая и удобная обёртка, которая входит в RTK Query. Кода стало меньше, но он не потерял своей функциональности: у нас есть набор аргументов и мы фетчим юзеров по этим аргументам. Добавляем базовый URL.
export const api = createApi({
reducerPath: "api”,
baseQuery: fetchBaseQuery({baseUrl: "http://localhost:7070/api/”}),
endpoints: (builder) => ({
getUser: builder.query({
query: (arg) => ‘users/${arg}’,
}),
getPosts: builder.query({
query: async (arg) => ‘posts/${arg} ,
}),
}),
});
Это простая, но удобная обёртка, которая идёт прямо из RTK. Теперь кода стало меньше, но он не потерял своей функциональности: у нас есть набор аргументов и мы фетчим юзеров по этим аргументам.
Что ещё дает нам эта библиотека из коробки? Есть утилита под названием retry. Это то, что я делал ранее на уровне компонента — ручной refetch.
// useEffect(() => (
// if (isError) refetch();
// }, [isError]);
Но это можно систематизировать — поместить в одно место там, где мы запрашиваем данные. Логично там же и определять, сколько раз мы их будем запрашивать случае ошибки.
import {createApi, fetchBaseQuery, retry} from "@reduxjs/toolkit/query/react”;
export const api = createApi({
reducerPath: "api”,
baseQuery: retry(fetchBaseQuery({baseUrl: "http://localhost:7070/api/”}), {maxRetries:5})
endpoints: (builder) => ({
getUser: builder.query({
query: (arg) => ‘users/${arg}’,
}),
getPosts: builder.query({
query: async (arg) => ‘posts/${arg}’,
extraOptions: {maxRetries: 10}
}),
}),
});
Мы окружаем «ретраем» нашу функцию для загрузки данных, указываем количество попыток. Каждая попытка идёт с увеличенным интервалом времени: сначала 3 секунды, потом 5, потом 9, чтобы не перегружать сеть.
Примечание. Подробное описание алгоритма.
Мутация данных
Задача следующая: мы хотим менять данные (например пользователя), при этом производить обновление кэша. Для этого в RTK Query есть механизм тегов.
В запросе на мутацию мы указываем, какие теги инвалидируются.
Все эндпойнты которые содержат данный тег будут обновлены.
Обратите внимание на строчку providesTagsниже.
import {createApi, fetchBaseQuery, retry} from "@reduxjs/toolkit/query/react”;
export const api = createApi({
reducerPath: "api”,
baseQuery: retry(fetchBaseQuery({baseUrl: "http://localhost:7070/api/”}), {maxRetries:5})
endpoints: (builder) => ({
getUser: builder.query({
query: (arg) => ‘users/${arg}’,
providesTags: (result, error, arg) => [{type: "Users”, id: arg}],
}),
getPosts: builder.query({
query: (arg) => ‘posts/${arg}’,
providesTags: (result, error, arg) => [{type: "Posts”, id: arg}],
}),
updateUser: builder.mutation({
queryFn: async (data) => {
const {id, ...body} = data;
try {
let response = await fetch(‘http://localhost:7070/api/users/${id} , {
method: "post”,
headers: {"Content-Type”: "application/json”},
body: JSON.stringify(body),
});
…
Если мы хотим обновить и валидировать данные всех пользователей сразу, то должны добавить в providesTags {type: "Users”, id: "ALL”} и указывать его при мутации.
getUser: builder.query({
query: (arg) => ‘users/${arg}’,
providesTags: (result, error, arg) => [{type: "Users”, id: arg} , {type: "Users”, id: "ALL”}],
}),
…
Вот как выглядит хук для изменения данных, обратите внимание на параметр invalidatesTags:
…
updateUser: builder.mutation({
query: ({id, … body}) => ({
url: ‘users/${id}’ ,
method: ‘POST’ ,
body,
}),
invalidatesTags: (result, error, {id}) => [{type: "Users”, id}],
}),
}),
});
Это сигнал для нашей программы, чтобы загрузить данные заново. Причем библиотека настолько умна, что загрузит данные не сразу, а ровно в тот момент, когда они нам понадобятся.
Десерт
При базовом использовании описанного выше подхода, после изменения данных и инвалидации тегов, начнется загрузка данных, и некоторое время, до окончания загрузки, пользователь будет видеть устаревшую информацию. Предполагая, что в большинстве случаев запрос завершится успешно, мы можем дополнительно улучшить user experience так, что пользователь увидит обновленные данные сразу. Это называется оптимистичное обновление (optimistic updates).
Для этого нам надо принудительно обновить кэш и отменить обновление если запрос вернул ошибку. Вот как мог бы выглядеть код:
updateUser: builder.mutation({
query: ({id, ...body}) => ({
url: `users/${id}`,
method: 'POST',
body,
}),
// invalidatesTags: (result, error, {id}) => [{type: "Users", id}],
async onQueryStarted({id, ...body}, {dispatch, queryFulfilled}) {
const patchResult = dispatch(
api.util.updateQueryData('getUser', id, (draft) => Object.assign(draft, body)))
try {
await queryFulfilled
} catch {
patchResult.undo()
}
},
})
Код достаточно говорящий и делает ровно то, что описано выше. Обратите внимание на onQueryStarted в котором мы вызываем dispatch на изменение кэша, где указываем название того, что апдейтим getPosts, параметр запроса, и функцию которая меняет draft (предыдущее состояние кэша). Затем ждём завершения запроса await queryFulfilled и возвращаем старые данные при ошибке с помощью patchResult.undo().
Примечание. Подробнее про optimistic updates.
Если вы обнаружите, что хотите обновить данные кеша в другом месте вашего приложения, вы можете сделать это в любом месте, где у вас есть доступ к методу store.dispatch, в том числе в компонентах React с помощью хука useDispatch.
Выводы
RTK Query — это мощный инструмент для получения и кэширования данных. Он предназначен для упрощения распространенных случаев загрузки данных в веб-приложении, избавляя от необходимости вручную писать логику загрузки и кэширования данных.
RTK Query — это дополнительный аддон, включенный в пакет Redux Toolkit, и его функциональность построена поверх других API в Redux Toolkit.
RTK Query из коробки предоставляет все возможности описанные в разделе «ИТАК» данного опуса.
Недостатки:
Я показал использовании библиотеки на примере хуков. Мой пример относительно файла с API достаточно прост: запросы, мутации — всё рядом. В реальном проекте может быть несколько файлов с различными блоками API, и в этом случае возникает вопрос, как связать всё вместе.
Проблема решается тем, что все действия по загрузке, мутированию обновлению кэша, инвалидации в RTQ Query могут быть вызваны с использованием dispatch из любого места приложения.
Система тегов непроста и не так прозрачна, как у альтернатив.
P.S.
Когда мы пишем приложение, то предполагаем, что оно будет функционировать длительное время. В процессе исправления багов и внесение новых фичей его будет смотреть множество людей, которые, если код сложен, потратят на это много времени и сил. Простота кода, его «прозрачность», очевидность и лаконичность (не переходящая в обфускацию) напрямую влияют на качество и итоговую (для заказчика) стоимость продукта, поэтому считаю разумную простоту, при выборе подходов при написании кода, приоритетной.
А вот три любимых цитаты, красочно отражающие эти мысли:
«The ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. So if you want to go fast, if you want to get done quickly, if you want your code to be easy to write, make it easy to read»
Robert C. Martin
«Any fool can write code that a computer can understand. Good programmers write code that humans can understand»
Martin Fowler
«The best code is no code at all. Every new line of code you willingly bring into the world is code that has to be debugged, code that has to be read and understood, code that has to be supported»
Jeff Atwood (react-philosophies)
Также продублирую ссылки на код фронта и бэка из статьи:
Подборка статей из блога:
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
