Ретроспектива автоматизации и изменений в процессах разработки Timeweb
1 ноября 2017 года я стал руководителем рабочей группы разработки в отделе программных разработок Timeweb. А 12 ноября 2018 руководитель отдела спросил, когда же будет готова статья для Хабрахабр, потому что отдел маркетинга спрашивает, добровольцы кончились, а контент-план требует чего-то ещё)
Поэтому хочу дать ретроспективу, как менялись процессы разработки, тестирования и поставки наших продуктов в течение последнего года. Про унаследованные процессы и инструменты, docker, gitlab и то, как идёт у нас разработка.
Хостер Timeweb существует с 2006 года. Всё это время компания вкладывает много сил, чтобы предоставлять клиентам уникальный и удобный сервис, который выделял бы её среди конкурентов. У Timeweb есть свои мобильные приложения, почтовый web-интерфейс, панели управления виртуальным хостингом, VDS, партнёрской программой, свои инструменты поддержки и многое другое.
В нашем gitlab около 250 проектов: это клиентские приложения, внутренние инструменты, библиотеки, хранилища конфигурации. Десятки из них активно развиваются и поддерживаются: в них коммитят на протяжении рабочей недели, тестируют, собирают, релизят.
Помимо большого объёма унаследованного кода, всё это тянет за собой соответствующее количество унаследованных процессов и сопутствующих инструментов. Как и любое наследие, их тоже надо поддерживать, оптимизировать, подвергать рефакторингу, а порой и заменять.
Из всего этого обилия проектов наиболее близки для клиентов хостинга панели управления. И именно в проекте «Панели управления» мы чаще всего обкатываем разные инфраструктурные улучшения и прилагаем немало усилий, чтобы держать связанную инфраструктуру в форме. Распространяя полученный опыт и понравившиеся практики в другие продукты и их команды.
О разных изменениях в инструментах и процессах за минувший год я и расскажу.
Vagrant → docker-compose
Проблема
В первый рабочий день я попробовал поднять локально панели управления. На тот момент это было пять веб-приложений в одном репозитории:
— ПУ виртуального хостинга 3.0,
— ПУ VDS 2.0,
— ПУ вебмастеров,
— STAFF (инструмент поддержек),
— Guidelines (демо стандартизированных фронтовых компонентов).
Для запуска локально использовался Vagrant. В Vagrant запускался ansible. Для запуска и настройки потребовалась помощь коллег и около дня чистого времени. Пришлось ставить особенную версию Virtual Box (на текущей стабильной были проблемы), работа из консоли внутри виртуальной машины здорово нервировала: тривиальные команды вроде npm/composer install ощутимо подтормаживали.
Производительность самих приложений в виртуальной машине была далека от возможной, учитывая используемый стек технологий и мощность машины. Не говоря о том, что виртуальная машина есть виртуальная машина, и она по определению занимает значительную часть ресурсов вашего ПК.
Решение
Окружение для локальной разработки было переписано для запуска в контейнерах docker. Контейнеризация на базе docker — наиболее распространённое решение для изолирования окружения приложений на всех этапах его жизненного цикла. Поэтому особых альтернатив тут нет.
Выводы
Из плюсов:
— локально приложение стало отзывчивее, контейнеры требуют меньше, чем ВМ,
— запуск нового экземпляра, как показала практика, занимает считанные минуты и требует только docker (-compose) не ниже определённых версий. После клонирования достаточно выполнить:
make install-dev
make run-dev
Не обошлось и без компромиссов:
— пришлось написать shell-обвязки для докеризированных команд (composer, npm и т.п.). Они, как и docker-compose.yml, не совсем кроссплатформенны, в сравнении с Vagrant. Например, запуск под Mac требует дополнительных усилий, а под Windows, вероятно, будет проще запустить в виртуалке linux дистрибутив с docker. Но это приемлемый компромисс, т.к. команда использует только debian-based дистрибутивы, это допустимое ограничение для коммерческой разработки,
— для поддержки виртуальных хостов локально запускается контейнер, основанный на github.com/jwilder/nginx-proxy. Не то чтобы костыль, но дополнительное ПО, о котором иногда надо помнить, хотя проблем оно не вызывает.
Да, каждому в команде пришлось хоть немного осознать, что такое docker. Хотя благодаря упомянутым shell-скриптам и Makefile разработчики выполняют 95% своих задач, не задумываясь о контейнерах, зато в гарантированно одинаковом окружении.
newcp-dev → cp-stands
Эти странные словосочетания — имена машин с тестовыми стендами панелей управления, новой и старой соответственно.
Проблема
Рецепты ansible использовались исключительно внутри Vagrant, так что главного преимущества достигнуто не было: версии пакетов в проде и на стендах отличались от того, в чём работали разработчики.
Несоответствие версий пакетов серверного ПО на старых стендах с тем, что было у разработчиков, приводило к проблемам. Синхронизация осложнялась тем, что у системных администраторов используется другая система управления конфигурацией, и интегрировать её с репозиторием разработчиков не представляется возможным.
Решение
После контейнеризации не составило большого труда расширить конфигурацию docker-compose для использования на тестовых стендах. Была создана новая машина, для развёртывания стендов по DOCKER_HOST.
Выводы
Разработчики теперь уверены в актуальности локального и тестовых окружений.
TeamCity → gitlab-ci
Проблемы
Конфигурирование проектов в TeamCity процесс кропотливый и неблагодарный. Конфигурация CI хранилась отдельно от кода, в xml, к которому не применимы нормальное версионирование, и обзор изменений. Также мы испытывали проблемы со стабильностью процесса сборки на агентах TeamCity.
Решение
Поскольку gitlab уже использовался как хранилище для репозиториев, начать использовать его CI было не только логично, но и легко и приятно. Теперь вся конфигурация CI/CD лежит прямо в репозитории.
Результат
За год почти все проекты, собиравшиеся TeamCity, благополучно переехали в gitlab-ci. Мы получили возможность быстро реализовывать самые разные фичи по автоматизации CI/CD процессов.
Нагляднее всего будут скриншоты pipelines:
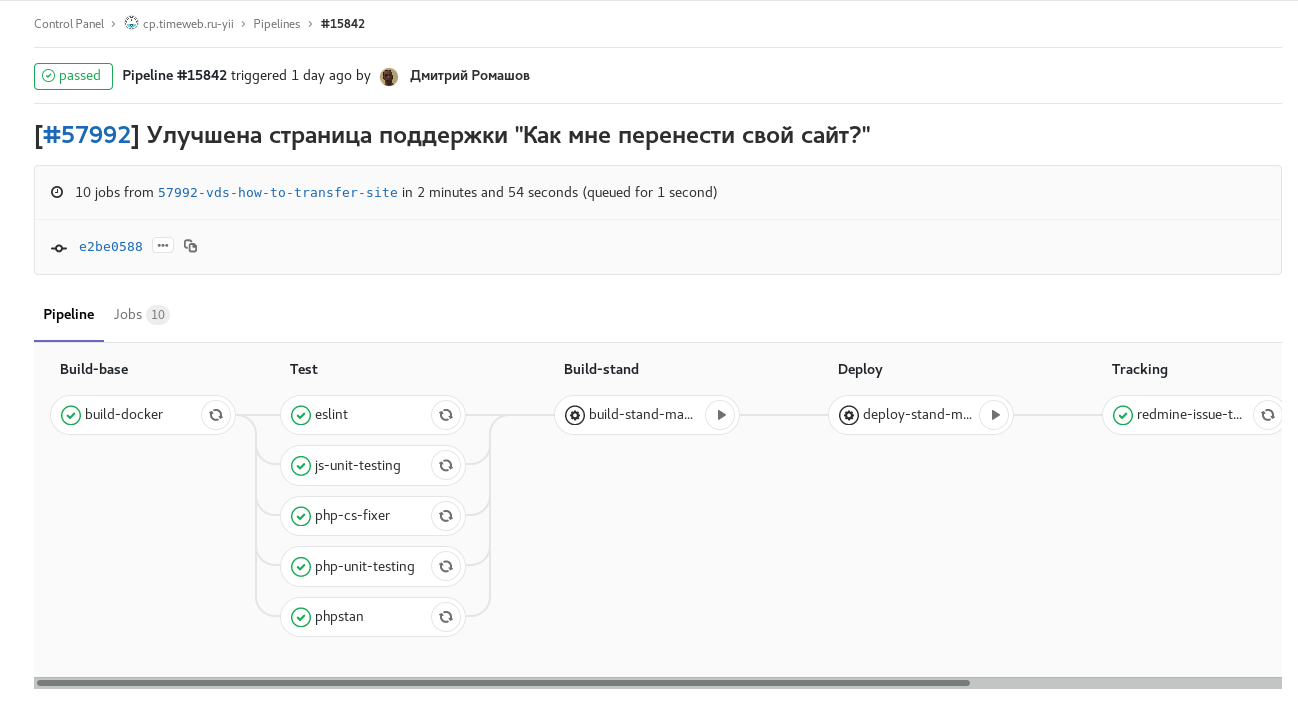
Илл. 1. feature-branch: включены все имеющиеся автоматические проверки и тесты. По завершении отправляет комментарий со ссылкой на pipeline в задачу redmine. Ручные задачи для сборки и запуска стенда с этой веткой.
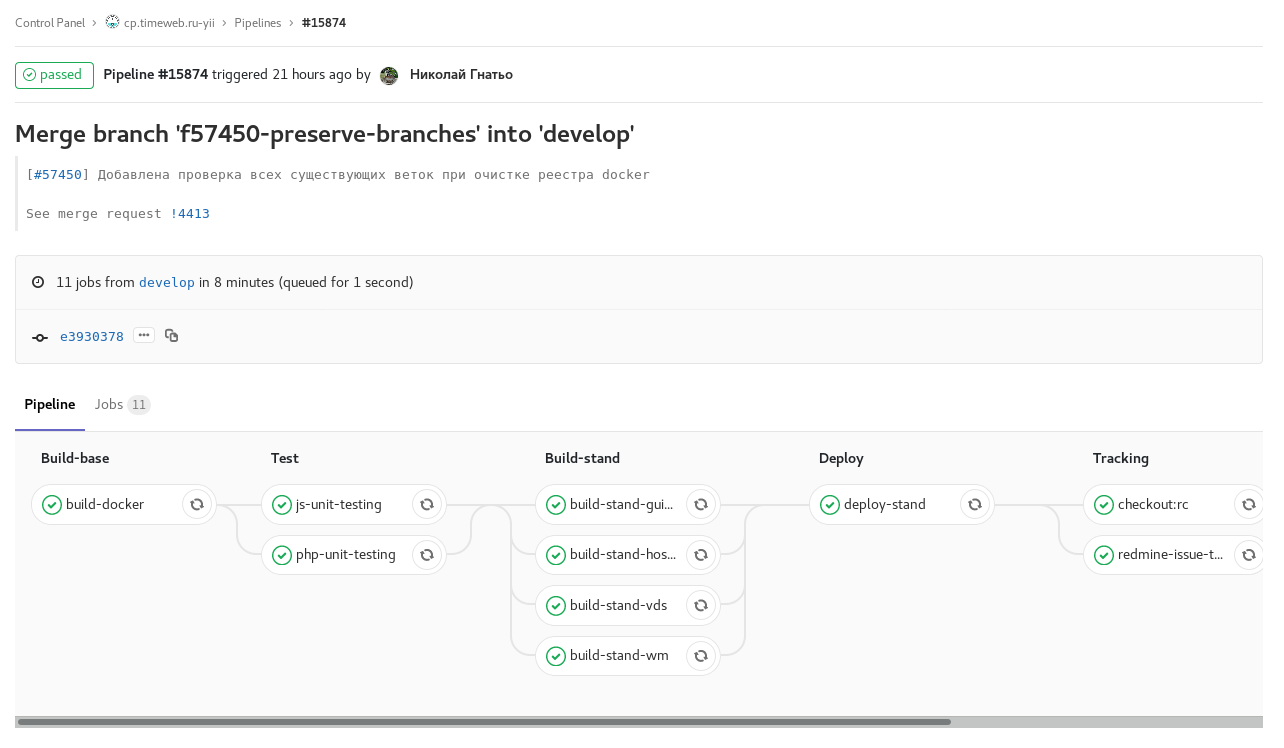
Илл. 2. develop scheduled build with code freeze (checkout: rc): сборка develop по расписанию с code freeze. Сборка образов для стендов отдельных панелей управления происходит параллельно.
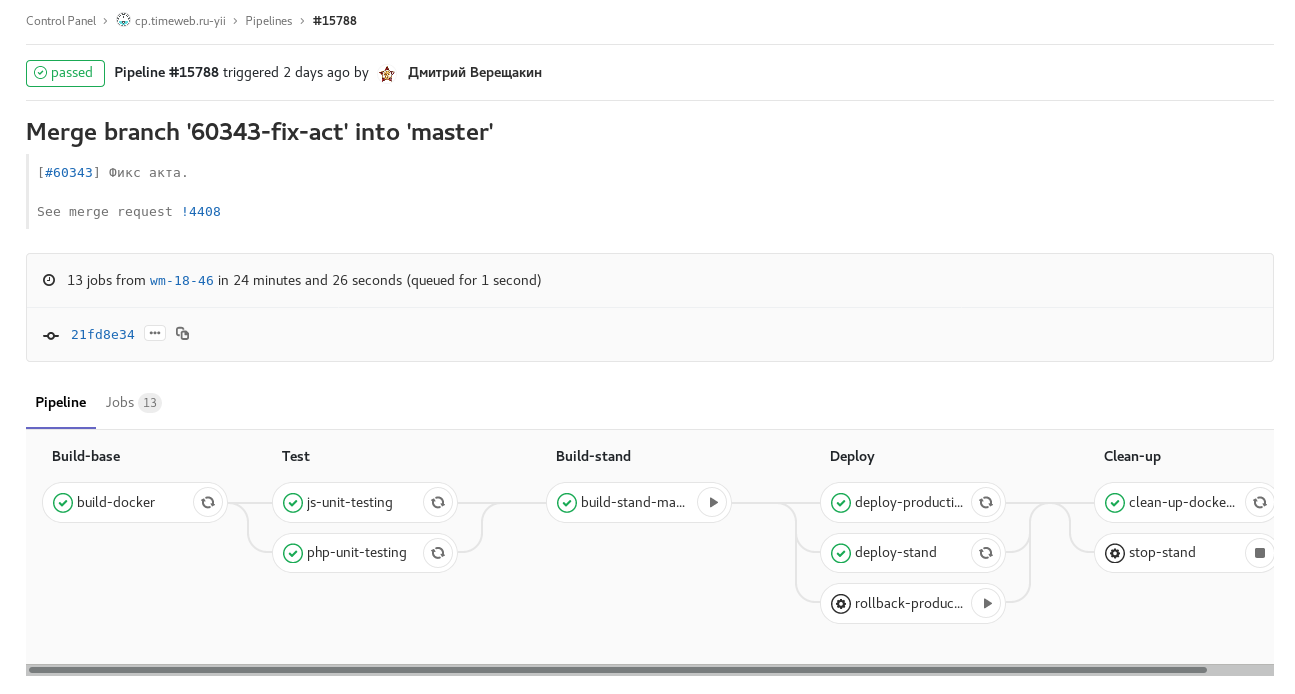
Илл. 3. tag pipeline: релиз одной из панелей управления. Ручная задача для отката релиза.
Кроме этого, из gitlab-ci происходит смена статусов и назначение ответственного в redmine на этапах In Progress → Review → QA, уведомление в Slack о релизах и обновлениях staging и откатах.
Это удобно, но мы не учли один методологический момент. Внедрив подобную автоматизацию в одном проекте, люди быстро привыкают к ней. И в случае переключения на другой проект, где такого ещё нет, либо процесс отличается, можно забыть подвинуть и переназначить задачку в redmine или оставить комментарий со ссылкой на Merge Request (что тоже делает gitlab-ci), заставив, таким образом, ревьюера искать нужный MR самостоятельно. При этом просто копировать куски gitlab-ci.yml и сопутствующего shell-кода между проектами не хочется, ведь придётся поддерживать копипасту.
Вывод: автоматизация хорошо, но когда она одинаковая на уровне всех команд и проектов — ещё лучше. Буду признателен уважаемой публике за идеи, как красиво организовать переиспользование подобной конфигурации.
Pipeline duration: 80 min → 8 min
Постепенно наш CI стал занимать неприлично много времени. Тестировщики от этого сильно страдали: каждое исправление в master к релизу приходилось ждать по часу. Это выглядело вот так: 
Илл. 4. pipeline 80 lvl min duration.
Пришлось на несколько дней погрузиться в анализ медленных мест и поиск путей к ускорению с сохранением функциональности.
Наиболее долгими местами в процессе оказалась установка npm-пакетов. Без особых проблем заменили его на yarn и сэкономили в нескольких местах до 7 минут.
Отказались от автоматического обновления staging, предпочли ручной контроль состояния этого стенда.
Ещё добавили несколько раннеров и разделили в параллельные задания сборку образов приложений и все проверки. После этих оптимизаций pipeline основной ветки с обновлением всех стендов стал занимать в большинстве случаев 7–8 минут.
Capistrano → deployer
Для деплоя в production и на qa-стенд использовался (и продолжает использоваться на момент написания статьи) Capistrano. Основной сценарий у этого инструмента: клонирование репозитория на целевой сервер и выполнение там же всех задач.
Раньше деплой запускался руками QA-инженера, располагающего нужными ssh-ключами, из Vagrant. Затем, по мере отказа от Vagrant, Capistrano переехал в отдельный контейнер. Сейчас деплой производится из контейнера с Capistrano с gitlab-runners, отмеченных специальными тегами и имеющих нужные ключи, автоматически при появлении нужных тегов.
Проблема здесь в том, что весь процесс сборки:
а) заметно потребляет ресурсы боевого сервера (особенно node/gulp),
б) нет возможности держать в актуальном состоянии версии composer, npm. node и т.п.
Логичнее производить сборку на билд-сервере (в нашем случае это gitlab-runner), а на целевой сервер выкладывать готовые артефакты. Это избавит боевой сервер от сборочных утилит и чуждой ему ответственности.
Сейчас мы рассматриваем deployer как замену capistrano (т.к. рубистов у нас нет, как нет и желания работать с его DSL) и планируем перенос сборки на сторону gitlab. В некоторых некритичных проектах мы его уже успели попробовать и пока довольны: выглядит проще, с ограничениями не столкнулись.
Gitflow: rc-branches → tags
Разработка осуществляется недельными циклами. В течение пяти дней идет разработка новой версии: в develop принимаются улучшения и исправления, запланированные к выпуску на следующей неделе. В пятницу вечером автоматически происходит code freeze. В понедельник начинается тестирование новой версии, вносятся доработки, и к середине-концу рабочей недели происходит релиз.
Раньше мы использовали ветки с именами вида rc18–47, что означает релиз кандидат 47-й недели 2018 года. Code freeze заключался в checkout rc-ветки от develop. Но в октябре этого года перешли к тегам. Тэги ставились и раньше, но постфактум, после релиза и слияния rc с master. Теперь появление тега приводит к автоматическому деплою, а заморозка это слияние develop в master.
Так мы избавились от лишних сущностей в git и переменных в процессе.
Сейчас мы «подтягиваем» отстающие по процессу проекты к аналогичному workflow.
Заключение
Автоматизация процессов, их оптимизация, как и разработка, — дело постоянное: пока активно развивается продукт и работает команда, будут и соответствующие задачи. Появляются новые идеи, как избавиться от рутинных действий: реализуются фичи в gitlab-ci.
С ростом приложений процессы CI начинают проходить непозволительно долго — пора работать над их производительностью. Поскольку подходы и инструменты устаревают — надо уделять время рефакторингу, пересматривая их, и обновлять.

