Решение проблемы понимания контекста искусственным интеллектом. Часть 1

Понимание естественного языка является AI полной задачей. Одним из аспектов такого понимания является понимание контекста. В данной статье я объясню, какие виды контекста выделяет наша психика, как она работает с одним из видов контекста, и как мы этот процесс воссоздаем в нашей технологии искусственного интеллекта.
The trophy doesn’t fit into the brown suitcase because it’s too [small/large].
What is too [small/large]?
Answers: The suitcase/the trophy.
The Winograd Schema Challenge
В предыдущей статье описан наш подход к разработке ИИ и то, что нами уже сделано на настоящий момент. Напомню, что мы создаем ИИ путем прямого копирования структур и процессов психики человека.
По комментариям к предыдущей статье мы увидели, что термин «контекст» применяется для описания очень разных ситуаций. Мы рассматриваем этот термин, разделяя его на два вида.
Первый вид контекста — когда речь идет о понимании, вытекающем из прозвучавших в этой фразе понятий. Это ситуации выбора одного из значений омонимов, подбор синонима, выбор одного из нюансов смысла и пр. Например: «Глаза слезились, когда она резала для салата лук» и «Современная стрельба из лука делится на несколько направлений». Человек «на лету» понимает, когда речь идет о луке-растении, а когда о луке — разновидности оружия.
Второй вид контекста — когда для понимания приходится выделять некоторую категорию, зачастую в самом тексте не представленную или особо не выделенную. Именно такая категория позволяет сформулировать некую «идею», обобщенно выражая то, о чем говорится.
Например, если вы в книге Льва Толстого встретите фразу «Он распечатал письмо…», то для правильного понимания текста вы привлекаете категорию »19 век», и делаете вывод, что речь идет не о принтере. Этот вид контекста подразумевает, что для понимания и интерпретации текста может производиться анализ не только всего текста, но и связанных с ним данных.
Решение задач, связанных с разными видами контекста, обслуживаются абсолютно разными процессами психики. Такое же разделение мы повторяем в нашей разработке ИИ. В решении задач первого типа используется метод, основанный на особенности хранения знаний. В решении задач второго типа реализуется более сложный алгоритм, основанный на опыте (в случае искусственного интеллекта речь идет об алгоритмах, компенсирующих отсутствие реального человеческого опыта у системы), и предполагающий больший объем вычислений.
Психика человека чаще всего вначале пытается применить первый метод, т.к. он требует гораздо меньше вычислительных ресурсов. Если же решение не выглядит адекватным, то тогда психика использует второй. Кроме того, чем выше интеллект, тем чаще используется второй метод и большее число возможных контекстов учитывается. Дети, в виду сложности и ресурсоемкости второго метода, а также взрослые, не привыкшие к умственному труду, предпочитают первый.
Мы опишем, как наша технология ИИ работает с первым видом контекста. Как мы работаем со вторым, более сложным, будет описано в следующей статье.
Для иллюстрации возьмем ситуацию диалога:
«Я тут иду по набережной и увидел косу. Интересно, какая коса самая длинная?»
Решение, построенное на нейронных сетях, в силу ограничений, накладываемых самим методом, вероятнее всего не сможет адекватно ответить. Даже если для поиска ответа в НС будет загружено очень много текстов, то, опираясь на вероятность, прозвучит цифра »5.6 метра».
Напомню, что нашу технологию ИИ мы разрабатываем, последовательно копируя психику и ее процессы. Семантическая сеть, которую мы используем для хранения знаний, отражает особенности хранения и обработки информации человеком. Поэтому в рамках нашего подхода задача решается достаточно просто.
В решении, соответствующем семилетнему возрасту, алгоритм обращается к семантической сети и находит вершину, которая расположена в узле, к которому относятся слова, услышанные ранее. В приведенном выше примере необходимо правильно выбрать один из омонимов: коса (прическа) и коса (полоса суши, соединенная с берегом) коса (инструмент). Для этого анализируется, о каком узле семантической сети шла речь ранее. Т.е. выполняется простейшая процедура расчета минимального расстояния до понятий, используемых в тексте ранее. В нашей сети расстояние это функция от количества связей (прямо пропорционально) и их вероятности (обратно пропорционально).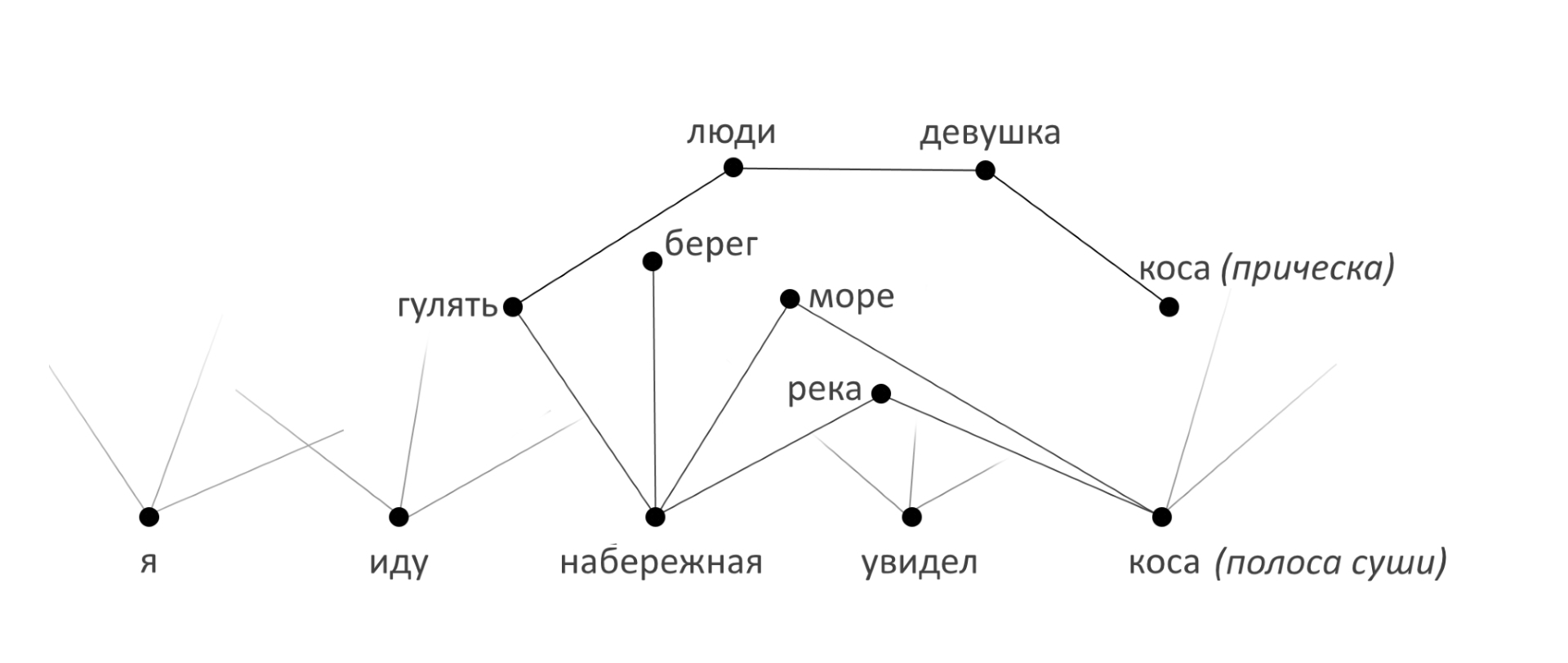
Расстояние от «коса (полоска суши)» до «набережной» будет на два порядка меньше, чем от «коса (прическа)» до любого из этих понятий. ИИ даст ответ »110 км».
Надо отметить, что эта задача решается и вторым способом, с выделением категории, например «река Волга, рядом с которой наш собеседник».
Рассмотрим пример из схемы Винограда, приведенный в начале статьи:
«The trophy doesn’t fit into the brown suitcase because it’s too small. What is too small?»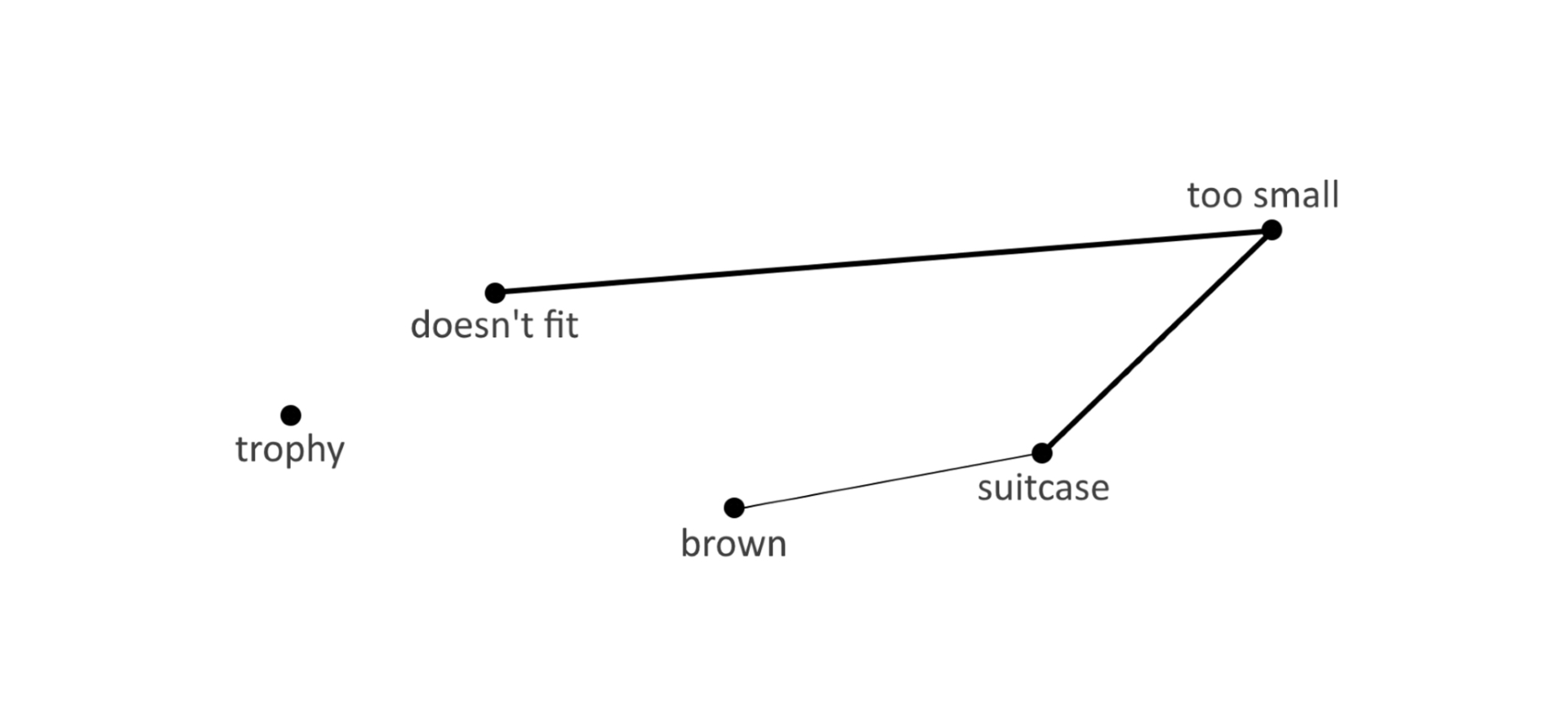
Связь между «doesn’t fit» и сочетанием «too small»-«suitcase» на порядок вероятнее, чем между «doesn’t fit» и «too small»-«trophy». ИИ даст ответ «suitcase».
Наличие высокой вероятности у такой связи, предполагающей на порядок меньшее расстояние в цепочке «doesn’t fit»-«too small»-«suitcase», обусловлено опытом человека. Я, как и большинство, часто сталкивался с ситуацией, когда что-то не влезает в чемодан, так как он слишком мал. Отсюда и такая связь у меня. Такие же связи формируются в процессе обучения ИИ (подробнее о формировании различных видов связей в психике мы опишем в одной из следующих статей о нашей семантической сети).
«The trophy doesn’t fit into the brown suitcase because it’s too large. What is too large?»
Связь между «doesn’t fit» и сочетанием «too big»-«trophy» гораздо вероятнее, чем между «doesn’t fit» и «too big»-«suitcase». ИИ даст ответ «trophy».
Отмечу особенность — у грузчиков, которые часто сталкиваются с ситуацией, когда надо поместить слишком большой чемодан, психика использует второй метод понимания контекста. Т.к. для них связь «too big»-«suitcase» более актуальна. При этом для туристов работает другая система — наряду с нарастанием опыта ситуаций, когда сложно поместить куда-то чемодан, увеличивается невозможность конструкции «не получается что-то положить в чемодан, потому что чемодан слишком большой».
Для решения, соответствующего 12-летнему возрасту, формула несколько сложнее. Причем сформированный к этому возрасту подход реализуется и у взрослого человека — после 12 лет эта часть сети-алгоритмов не усложняется.
Фактически, легкость решения определяется спецификой нашего похода. Все ситуации, связанные с коммуникацией, вся лингвистика, сформированы с участием структур психики человека. Собственно, вся специфика в области языка и определяется этими структурами. Правда, есть и обратный процесс, когда язык определяет структуру. Налицо взаимообуславливание. Не удивительно, что с помощью этих структур (психических) возникающие задачи решаются самым легким образом. Гайку надо откручивать гаечным ключом, они созданы друг для друга. А не ложкой.
Отмечу, что кроме больших преимуществ, наш подход к разработке ИИ привносит и некоторые сложности. Вычислительная архитектура не соответствует физиологической базе, и мы периодически решаем технические задачи по качественному отображению процессов и структур психики в цифре. Также, из-за имеющихся допущений и корректив, какая-то часть ресурсов уходит на обеспечение тождественности семантической сети и алгоритмов ИИ структурам и алгоритмам реальной психики.
Следующая статья будет о втором виде контекста, и она будет, к сожалению, гораздо тяжеловесней. Нам не обойтись без глубокого погружения в психологические процессы при описании алгоритмов работы со вторым видом контекста в нашей технологии.
