Регулярки (regex) — основы для решения кейсов, про которые не пишут в статьях про основы
«Там просто регулярку написать» — говорили они.
Хочу показать вам небольшой кейс/задачу, которую передо мной поставили.
Суть — у нас есть лог (покажу самую интересную часть*), в котором много много разной информации (~100k-700k строк). Из этого лога нам нужно ~3% символов (именно, даже не строк). Затем, сделать таблички по полученным данным и визуализировать это всё. Делал я всё это на python, поэтому и регулярки написаны под python (спойлер: здесь только про регулярки).
Фактически, вся работа с логом сводилась к решению 3-ёх случаев:
Достать строку, в которой есть определенные слова.
Нам нужно найти конкретный реквест и достать данные из его аргументов.
Нам нужно найти конкретный реквест, достать данные из его аргументов, поймать печальку, что в аргументах не вся информация, которая нам нужна и достать еще данные, но по другому условию.
Для проверок наших регулярок, я использовал regex101.com, соответственно, настраиваем его под python.
Итак, часть Лога
 Наш любимый лог
Наш любимый лог
Задача №1:
Нужно достать данные, когда запустилось приложение.
Мы знаем:
1) Строка начинается с даты, то есть с цифры.
2) Из документации (и здравого смысла, после просмотра лога),
что нужная нам строчка, содержит фразу »start_of_app_here».
Я рассчитываю, что вы уже немножко понимаете в регулярках, поэтому не буду расписывать, какой символ за что отвечает.
В итоге получаем такую регулярку: r"^\d.{,1000}start_of_app_here"
Проверяем.
 Итоговая регулярка 1-ой задачи
Итоговая регулярка 1-ой задачи
Всё работает, но стоит добавить:
Лучше не использовать квантификаторы * и +, по моему опыту, они работают гораздо дольше квантификаторов с установленными границами {,}
Не забыть, при использовании метода findall третьим аргументов указать re.M, в противном случае, ^ будет восприниматься как начало текста, а не начало строки.
Пример:re.findall(r"your_reg", data, re.M)
Задача №2:
Достать аргументы запроса Pick_something.
Здесь немного поинтереснее и самое простое было бы достать всё, что начинается с Pick_something. У нас получилось бы что-то вроде: r"Pick_something\(.{,1000}\)"
Но после этого нужно было бы избавляться от самого названия запроса и скобок.
 Первая попытка решения 2-ой задачи
Первая попытка решения 2-ой задачи
Я предлагаю, сразу доставать только то, что внутри скобок. Для этого нам надо узнать, что делают (? <=text) и (?Из этого можем построить шаблон:
(? <=начало_искомого)что_нужно_достать(?
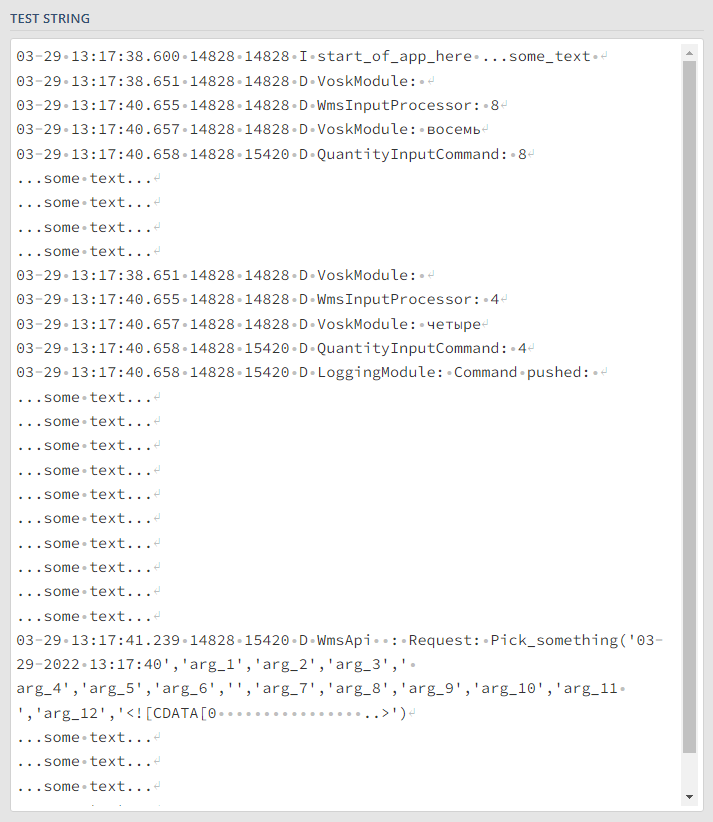
В нашем случае: r"(?<=Pick_something\().{,1000}(?
 Итоговая регулярка 2-ой задачи
Итоговая регулярка 2-ой задачи
Задача №3:
Получаем от коллег по «самой лучшей работе в мире»* новую вводную, что в аргументах не вся информация, что нам нужна.
Обновленная задача звучит как: достать аргументы запроса и циферку команды QuantityInputCommand, которая идёт до запроса.
Первое, что я попробовал, используя прошлые «наработки» достать инфу также, только обернуть нужную мне информацию в группировочные скобки — ()
То есть: r"(?<=QuantityInputCommand:\s)(\d{,10})(?:\s|\S)+Pick_something((.{,200})(?
 Первая попытка решения 3-ей задачи (сильно неудачная)
Первая попытка решения 3-ей задачи (сильно неудачная)
Нам нужна цифра, которая идёт непосредственно перед нашим запросом (Pick_something), то есть такая регулярка не отработала от слова совсем.
Есть вариант доставать всё подряд, и на пост обработке, когда уже будет список всех значений, сделать проверку на последовательность, то есть «если за цифрой из QuantityInputCommand идёт что-то начинающееся с », то оставляем, в противном случае, удаляем».
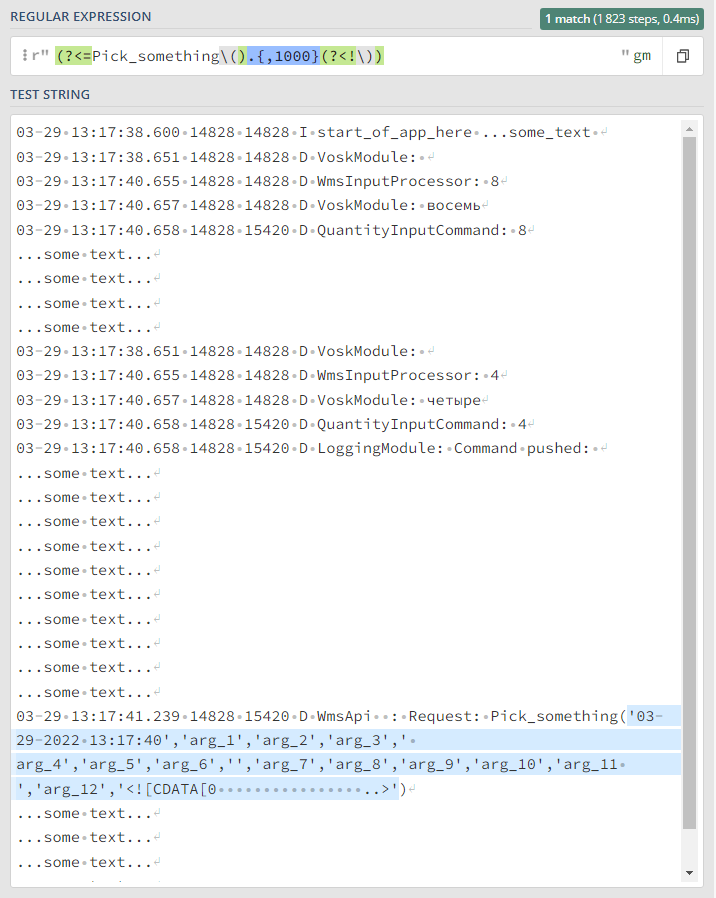
Выглядит примерно так: r"(?<=QuantityInputCommand:\s)\d{,10}|(?<=Pick_something().{,200}(?
 Вторая попытка решения 3 задачи (рабочая, но требует пост обработки)
Вторая попытка решения 3 задачи (рабочая, но требует пост обработки)
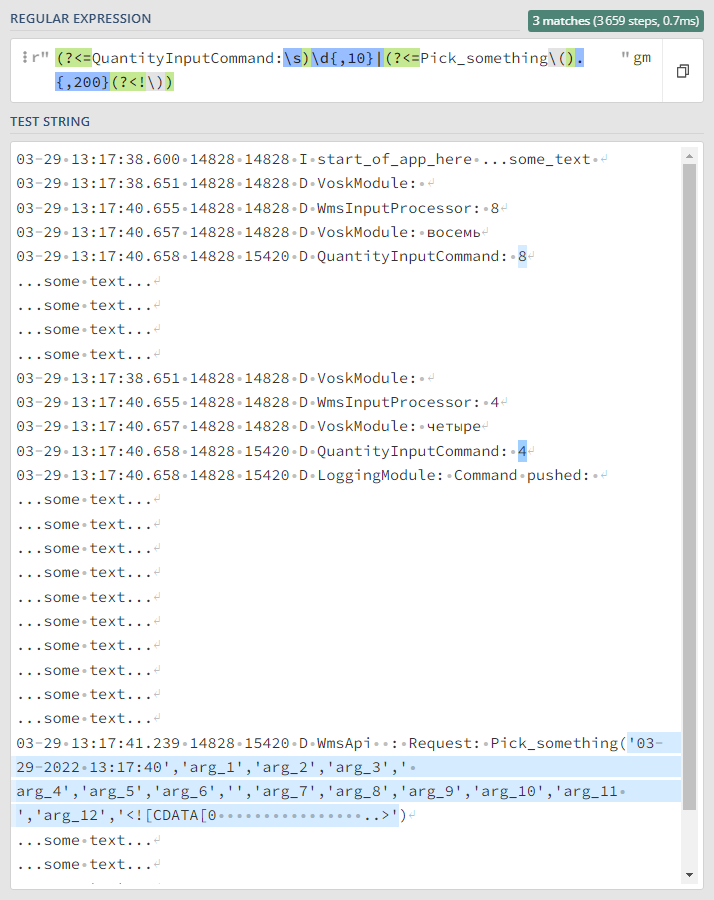
В итоге, мы можем указать на проверку отсутствие повтора, который нам всё ломает. Просто используем (? В нашей задаче решение* выглядит так: r"(?<=QuantityInputCommand:\s)(\d{,10})(?:\s|\S(?
Смотрим, стоит ли слева QuantityInputCommand ((?<=QuantityInputCommand:\s)), забираем цифру и группируем её ((\d{,10})), проверяем, не стоит ли после какого-либо текста (\s|\S) еще одна команда QuantityInputCommand ((?) и дальше, по старой схеме, ищем нужный нам запрос и группируем и забираем его аргументы ((?<=Pick_something()(.{,200})(?)
Получаем:
 Итоговая регулярка 3-ей задачи
Итоговая регулярка 3-ей задачи
Есть немного лишнего текста, но в группах у нас только нужные данные.
Я остановился на этом варианте, данные нужные получены, по скорости меня удовлетворило решение, наверняка, можно придумать что-то поэлегантнее, но в регулярках главное вовремя остановиться, доделывать их можно вечно*.
Итог
Основное, что я хотел показать, это 3-я регулярка, возможно, кому-то поможет и станет неким шаблоном. Довольно долго искал, где бы в лоб сказали: «делай вот так и будут тебе 1) нужные данные 2) по твоему условию 3) без лишних повторов».
Мне показалось, такая потребность может встречаться часто при работе с текстовыми данными, но в статьях про «Основы regex» подобного не нашел, есть подозрения, что такая штука должна в них быть, но мне так и не попалась.
Надеюсь, был кому-то полезен, заранее благодарю за оценку и\или комментарий)
Возможно, напишу небольшое продолжение, по дальнейшей обработке и визуализации в Jupyter Notebook на манер книги «Storytelling with data», если кому-то интересно, дайте знать в комментариях, пожалуйста :-)
P.S. * — по мнению автора.
