Redis для .Net разработчиков

 С 2014 года .net стал совсем другим (не тем, каким мы его знаем). Открытие части .net framework, новый компилятор C#, новый jit компилятор, .net native, активное использование нетипичных для windows технологий в Azure (из-за чего даже переименовали Windows Azure в Microsoft Azure), все большее движение Asp.net в сторону не только windows.
С 2014 года .net стал совсем другим (не тем, каким мы его знаем). Открытие части .net framework, новый компилятор C#, новый jit компилятор, .net native, активное использование нетипичных для windows технологий в Azure (из-за чего даже переименовали Windows Azure в Microsoft Azure), все большее движение Asp.net в сторону не только windows.
На DevCon в 2012 году мы (я) с непониманием, слушал доклады по использованию Redis в .net приложениях. В нынешнем 2015 году не обращать внимания на Redis невозможно, даже живя на другой планете.
Я для себя точкой смены вех вижу 7 октября 2014 года, когда Скотт Гаттри анонсировал общую доступность Redis Cache в Azure.
И последним ударом стало — Microsoft теперь официально рекомендует использовать Redis для кэша — «We recommend all new developments use Azure Redis Cache.» Всю жизнь говорили SQL Server (либо распределенный AppFabric Caching), а теперь Redis.В Asp.Net5 (до декабря 2014 — vnext) появятся возможности:
Команда Entity Framework анонсировала поддержку NoSQL хранилищ в Entity Framework 7 (правда в первом релизе 7.0 будет по старинке только SQL Server). Моя статья об этом.
Xранить Session в Redis 1 и 2.
И кэшировать данные в Redis.
Для SignalR можно использовать Redis в качестве scaleout backplane. Моя статья и официальная
А когда-то не так давно, во времена .net 4.0- 4.5, был только Output cache и умельцы прикручивали Redis сами — автор на хабре недавно писал про использование Redis вместе с CacheDependency.Краткая справка про Redis для .net разработчиков, не следивших за Redis ранее
Изначально Redis писался под nix системы. Через какое-то время Microsoft занялся поддержкой Redis для Windows через Microsoft Open Technologies. И уже потом, от проекта под Windows, Azure форкнула свою версию.Чтобы понимать разницу между проектами: Основную работу по поддержке Windows версии несет команда MS Open Technologies.Она пишет Win32_Interop, для работы Redis под Windows,
 сохраняя все интерфейсы/header файлы для совместимости с не windows версией; при этом ответственность на себя за windows версию берет только в Azure варианте. На локальном сервере/кластере — это на ваш страх и риск.Команде Azure проще всего, т.к.Они не тащат кучу старых веток типа 2.2, 2.4. У них есть prod версия 2.8 и на этом все.
Они не используют 32-битную версию сборки — только 64.
сохраняя все интерфейсы/header файлы для совместимости с не windows версией; при этом ответственность на себя за windows версию берет только в Azure варианте. На локальном сервере/кластере — это на ваш страх и риск.Команде Azure проще всего, т.к.Они не тащат кучу старых веток типа 2.2, 2.4. У них есть prod версия 2.8 и на этом все.
Они не используют 32-битную версию сборки — только 64.
 Им не нужны инструкции инсталляции, т.к. в Azure ты просто берешь инстанс, а не занимаешься сам его настройкой.
Часто задаваемые вопросы
Коллеги, которые очень хорошо/плотно разбирались/ковырялись с SQL Server лет по 10, но вообще не ковырялись с Redis спрашивали: А насколько он быстрый? А выдержит ли он нашу нагрузку, причем с запасом, мы ведь все-таки enterprise, а не детская площадка?
Простой ответ — Redis очень быстрый. На бытовом уровне я бы объяснил так: Использовать данные в памяти сильно быстрее, чем сначала читать их с диска.
Внутри себя Redis хранит данные в разных структурах данных в зависимости от типа. Быстрее чем поиск по hash таблице, тяжело что-то придумать (без углубления в вопросы распределения hash и качества hash функций) => если вы храните данные в ней, у вас все очень хорошо. Если храните данные в списках, то могут быть проблемы.
Т.к. в Redis нет такого сложного конвейера обработки запроса, как в SQL, накладные расходы ниже (план запроса, к примеру, надо составить, если его нет. Он составляется на основе статистики, статистика может быть некорректной и т.д., и т.п.).
В документации есть статья про производительность (очень рекомендую потратить время и прочесть), и сравнение производительности с memcache/ вариант 2. На своих тестах Redis обошел Memcache, что очень хороший критерий производительности.Если коротко, то 100 тысяч запросов в секунду на одном узле — это абсолютно нормальный результат, без какого-то фантастического железа или плясок с бубном при настройке. Мне нравится вот этот график,
Им не нужны инструкции инсталляции, т.к. в Azure ты просто берешь инстанс, а не занимаешься сам его настройкой.
Часто задаваемые вопросы
Коллеги, которые очень хорошо/плотно разбирались/ковырялись с SQL Server лет по 10, но вообще не ковырялись с Redis спрашивали: А насколько он быстрый? А выдержит ли он нашу нагрузку, причем с запасом, мы ведь все-таки enterprise, а не детская площадка?
Простой ответ — Redis очень быстрый. На бытовом уровне я бы объяснил так: Использовать данные в памяти сильно быстрее, чем сначала читать их с диска.
Внутри себя Redis хранит данные в разных структурах данных в зависимости от типа. Быстрее чем поиск по hash таблице, тяжело что-то придумать (без углубления в вопросы распределения hash и качества hash функций) => если вы храните данные в ней, у вас все очень хорошо. Если храните данные в списках, то могут быть проблемы.
Т.к. в Redis нет такого сложного конвейера обработки запроса, как в SQL, накладные расходы ниже (план запроса, к примеру, надо составить, если его нет. Он составляется на основе статистики, статистика может быть некорректной и т.д., и т.п.).
В документации есть статья про производительность (очень рекомендую потратить время и прочесть), и сравнение производительности с memcache/ вариант 2. На своих тестах Redis обошел Memcache, что очень хороший критерий производительности.Если коротко, то 100 тысяч запросов в секунду на одном узле — это абсолютно нормальный результат, без какого-то фантастического железа или плясок с бубном при настройке. Мне нравится вот этот график, 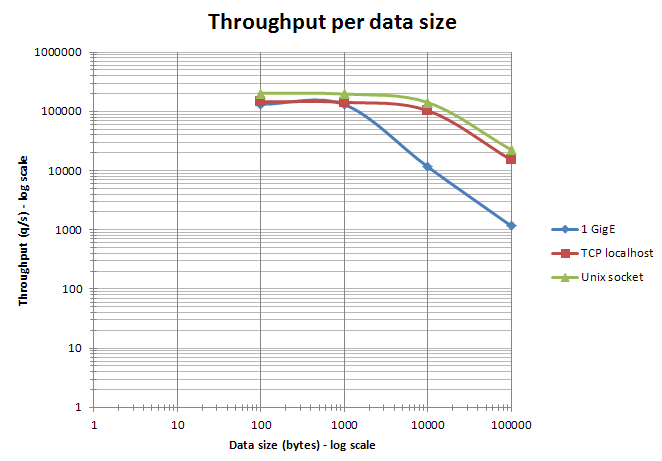 который объясняет большую часть моментов, а именно: что при росте объема данных сеть становится узким местом, а не процессор или память. Сеть — это уже вопрос не к производительности самого Redis.
который объясняет большую часть моментов, а именно: что при росте объема данных сеть становится узким местом, а не процессор или память. Сеть — это уже вопрос не к производительности самого Redis.
Второй вопрос был: кластерную конфигурацию поддерживает? Ответ: да, причем из коробки, и кластер — это практически базовая конфигурация (design for cluster).В этих статьях это описано подробно 1 и 2, и пусть Вас не смущает фразы про альфа/бета — тут как с gmail (которая была beta когда уже сотни миллионов ящиков на ней были по 5–6 лет в эксплуатации). Люди годами работают и не жалуются.Кластеры поддерживают и распределение нагрузки, и отказоустойчивость. Master-узлы разделяют между собой нагрузку (диапазон ключей) + у каждого узла может быть любое число shard-ов (на которых хранится реплика мастера, готовая его заменить в случае недоступности.)А какие хорошие библиотеки доступа из .net есть? Года 2 назад, на devcon 2012, ребята показывали библиотеку, написанную на коленках за неделю. С тех пор мир изменился кардинально. Есть множество библиотек, но для .net де факто стандартом стала stackexchane (те, кто использовал другие библиотеки в своих проектах, все чаще выпиливают и заменяют на эту версию).Чтобы начать пользоваться этой библиотекой, долго вникать в нее не нужно. Принцип ее работы можно разобрать, открыв всего 3 класса.Если данные хранятся в памяти, то как долговременно хранить их? Сервер же перегружается иногда! В определении что такое Redis есть слово, которое всех сбивает с толку — InMemory, но оно не означает In Memory Only. В Redis есть механизм сброса данных на диск, точнее 2 механизма. Инкрементальный — это когда каждые n секунд (можно сделать каждые 5, 30, 600 секунд) идет сброс данных, и Полный — это когда сбрасывается все содержимое на диск. (Как с бэкапами баз данных — инкрементальный и полный бэкап). Эти варианты друг другу не противоречат, можно оба включить. Это не бесплатно в плане производительности, как и любая запись на диск.Вместо заключения .Net сильно меняется, и придется меняться .net разработчикам. Использование Redis — это очередной шаг эволюции платформы, и его надо принять. Это не страшно.Ссылки
