Новые оптимизации для х86 в GCC 5.0: PIC в 32-битном режиме
Данный пост продолжает серию из трех статей об оптимизациях для x86 в GCC 5.0. В предыдущей статье речь шла о векторизации. Напомню, что GCC 5.0 находится сейчас в фазе stage3, то есть внедрение новых оптимизаций уже фактически заверешено и уровень производительности за редким исключением останется прежним и в продуктовом релизе. Сегодня речь пойдет об ускорениях позиционно-независимого кода или position independent code (PIC) в 32-битном режиме для x86.PIC (согласно википедии) — это программа, которая может быть размещена в любой области памяти, так как все ссылки на ячейки памяти в ней относительные. Такой способ компиляции программы используется для Android, библиотек и многих других приложений. Большинство приложений под Android сейчас являются 32-битными, так что производительность GCC для PIC в 32-битном режиме очень важна.Ожидается, что GCC 5.0 существенно (до 30%) разгонит приложения, где производительность сосредоточена в целочисленном цикле, а, именно, такие как криптография, защита данных от помех, сжатие данных, хеширование и другие, особенно те, где векторизация по тем или иным причинам не применилась.
Что же изменилось в GCC 5.0 по сравнению с GCC 4.9?
В GCC 4.9 регистр EBX зарезервирован для адреса глобальной таблицы смещений или global offset table (GOT) и, следовательно, недуступен для распределения. Таким образом, для PIC в 32х битном режиме доступно только 6 регистров (вместо обычных 7): EAX, ECX, EDX, ESI, EDI и EBP. Это приводит к существенным потерям производительности, когда для распределения не хватает регистров.
В GCC 5.0 регистр EBX доступен для распределения. Таким образом, общее количество свободных ригстров для PIC не отличается от абсолютного кода. Ниже приведены результаты для теста с целочисленными вычислениями в цикле с нехваткой регистров.
int i, j, k; uint32 *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < ST; k++) { uint32 s = 0; for (j = 0; j < LD; j++) s += (in[j] * c[j][k] + 1) >> j + 1; out[k] = s; } in += LD; out += ST; } Где: c — это константная матрица: const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1}; Такая матрица используется, чтобы минимизировать вычисления внутри цикла до сравнительно быстрых сложений и вычитаний, но увеличить число зависимостей. in и out — указатели на глобальные массивы «a[1024 * LD]» и «b[1024 * ST]» uint32 — это unsigned int LD и ST — макросы, определяющие длину группы загрузок из памяти и сохранений в память соответственно Опции компиляции »-Ofast -funroll-loops -fno-tree-vectorize --param max-completely-peeled-insns=200» плюс »-march=slm» для Silvermont,»-march=core-avx2» для Haswell,»-fPIC» для PIC и »-DLD={4, 5, 6, 7, 8} -DST=7»-fno-tree-vectorize» — используется, чтобы избежать векторизации и, следовательно, использования xmm регистров (которых всегда доступно одинаковое количество)»--param max-completely-peeled-insns=200» — использутся чтобы GCC 5.0 и 4.9 были в равных условиях, так как для 4.9 этот параметр был равен 100
Прирост производительности GCC 5.0 по сравнению с 4.9 (во сколько раз ускорилось, выше — лучше).По оси Х изменяется количество загрузок в цикле: LD. Большее количество «LD» ведет к большему регистровому давлению.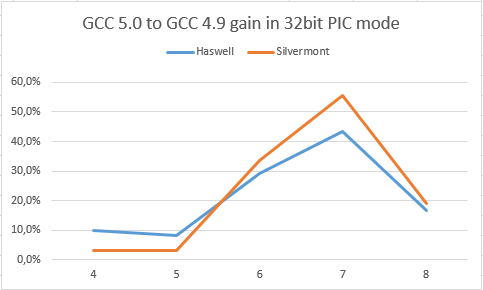
Здесь мы видим, что и Silvermont, и Haswell показывают внушительный прирост. Но чтобы подтвердить, что это произошло именно из-за добавления к распределению EBX регистра следует обратится к 2 чартам ниже:
Эти чарты отображают замедление от перехода к PIC для Haswell и Silvermont на компиляторах GCC 5.0 и GCC 4.9 (выше — лучше)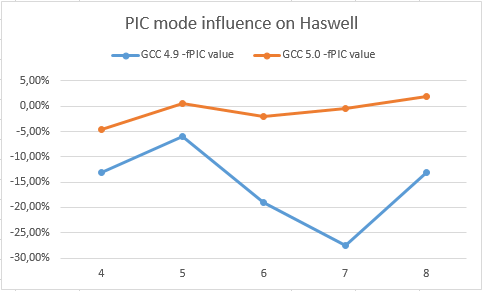
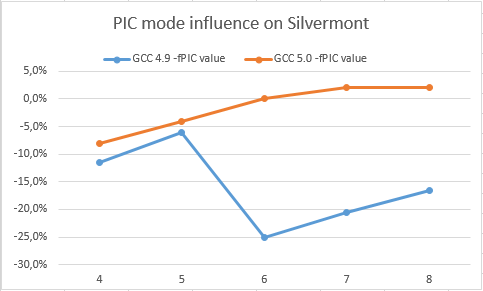
Здесь видно, что GCC 5.0 не сильно проигрывает от перехода к PIC. GCC 4.9 напротив замедляется довольно существенно как на Haswell, так и на Silvermont. Это подтверждает, что GCC 5.0 должен сильно ускорить целочисленные циклы для PIC. Более того разработчики смогут использовать более агрессивные оптимизации (увеличивающие регистровое давление), такие как раскрутка циклов (unroll), подстановка функций (inline), более агрессивный вынос инвариантов…
Попробовать GCC 5.0 можно уже сейчас. Возможно и портирование в Android NDK.
Процессоры использованные в замерах: Silvermont: Intel® Atom™ CPU C2750 @ 2.41GHzHaswell: Intel® Core™ i7–4770K CPU @ 3.50GHz
Компиляторы используемые в замерах:
Скачать пример, на котором производились замеры, можно из оригинального текста статьи на английском.
