RDMA внутри ЦОД в реализации от Huawei
Под катом о том, какой подход предлагает Huawei при организации удаленного прямого доступа к памяти с использованием технологии AI Fabric и чем он отличается от InfiniBand и «чистого» RDMA на базе Ethernet.
Распределенные вычисления применяются в самых разных отраслях. Это и научные исследования, и технические разработки вроде средств распознавания лиц или автопилотов, и промышленность. В целом анализ данных находит все больше сфер применения, и с уверенностью можно сказать, что в ближайшем будущем он не потеряет популярность. Фактически сейчас мы переживаем переход от эры облачных вычислений, где важнейшими факторами были приложения и скорость развертывания сервисов, к эре монетизации данных, в том числе, через использование алгоритмов искусственного интеллекта. По нашим внутренним данным (доклад GIV 2025: Unfolding the Industry Blueprint of an Intelligent World) к 2025 году 86% компаний будут использовать AI в своей работе. Многие из них рассматривают это направление в качестве основного для модернизации деятельности и, возможно, базового инструмента принятия бизнес-решений в будущем. А это значит, что каждой из этих компаний потребуется какая-то обработка сырых данных — скорее всего, посредством распределенных кластеров.
Эволюция архитектуры
С ростом популярности распределенных расчетов увеличивается объем трафика, которым обмениваются отдельные машины ЦОД. Традиционно при обсуждении сетей внимание акцентируется на росте трафика между ЦОД и конечными пользователями в интернете, и он действительно растет. Но рост горизонтального трафика внутри распределенных систем намного превосходит все, что генерят пользователи. По данным Facebook, трафик между их внутренними системами удваивается менее, чем за год.

В попытках справиться с этим трафиком можно увеличивать кластеры, но нельзя это делать бесконечно. Поэтому, прогнозируя рост вычислительной нагрузки на кластеры, необходимо повышать эффективность обработки — в первую очередь, находить и устранять узкие места внутри этих распределенных сетей.
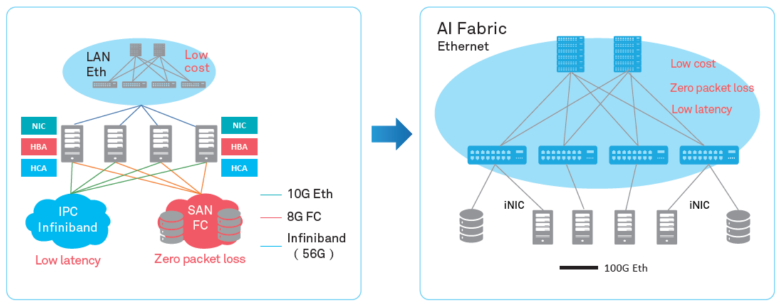
Если раньше «слабым звеном» распределенных систем были ресурсы каждой из этих систем в отдельности, в то время как постоянно развивающиеся сети передачи данных даже обгоняли потребности, то сегодня именно сетевые коммуникации — основной источник проблемы. Привычный стек протоколов TCP/IP и древовидная топология уже не соответствуют поставленным задачам. Поэтому все больше ЦОДов отказываются от централизованной и переходят на новую CLOS-архитектуру, обеспечивающую большую пропускную способность и лучшую масштабируемость кластера, как, например, это сделала компания Facebook несколько лет назад.

Одновременно нужно оптимизировать процесс на другом уровне — на уровне взаимодействия двух отдельных систем. В этой статье мы хотим рассказать о том, какие инструменты оптимизации предоставляет ЦОДу Huawei Ai Fabric. Это наша фирменная технология, ускоряющая обмен данными между узлами.
Изменения сетевого взаимодействия
Главная «фишка» Huawei Ai Fabric — сокращение накладных расходов при передаче пакетов данных между системами внутри кластера за счет реализации RDMA (Remote Direct Memory Access) — прямого доступа к памяти систем, входящих в кластер.
RDMA — путь сокращения задержек передачи
RDMA — идея не новая. Технология обеспечивает прямой обмен данными между памятью и сетевым интерфейсом, сокращая время ожидания и исключая лишние копирования данных в буферы. Ее корни уходят в разработки 1990-х годов компаний Compaq, Intel и Microsoft.
В передаче пакета от одной системы к другой есть три типа задержек:
- из-за процессорной обработки, необходимой, например, для буферизации данных в ОС и подсчета чек-сумм;
- из-за шин и каналов передачи данных (значительно увеличить полосу пропускания технически невозможно);
- из-за сетевого оборудования.

Чтобы сократить потери на всей этой цепочке, еще в 1990-х было предложено использовать прямой доступ к памяти взаимодействующих систем — абстрактную модель Virtual Interface Architecture. Ее основная идея заключается в том, что приложения, запущенные в двух взаимодействующих системах, полностью заполняют их локальную память и устанавливают P2P соединение для передачи данных, не затрагивая ОС. Таким образом можно существенно сократить задержки при передаче пакетов. Кроме того, поскольку модель VIA не подразумевала размещение передаваемых данных в промежуточные буферы, она экономила ресурсы, необходимые на операцию копирования.

Относительно абстрактной модели VIA RDMA, как технология, шагнула дальше в направлении оптимальной утилизации ресурсов. В частности, она не ждет заполнения буфера для установления соединения и допускает соединения одновременно с несколькими компьютерами. За счет этого технология позволяет сократить задержки на передаче до 1 мс, снижая нагрузку на процессор.
InfiniBand vs Ethernet
Две основных реализации RDMA на рынке — проприетарный транспортный протокол InfiniBand и «чистый» RDMA на базе Ethernet, к сожалению, не лишены недостатков.
Транспортный протокол InfiniBand имеет встроенный механизм контроля доставки пакетов (защиту от потери данных), но поддерживается специфическим оборудованием и не совместим с Ethernet. Фактически использование этого протокола замыкает ЦОД на одном поставщике оборудования, что несет в себе определенные риски и обещает сложности с точки зрения обслуживания (поскольку InfiniBand имеет малую рыночную долю, найти специалистов будет не так-то просто). Ну и, естественно, при внедрении протокола нельзя использовать уже существующее оборудование IP-сетей.
RDMA over Ethernet позволяет использовать в сети существующее оборудование, поддерживает сети Ethernet, а значит, будет легче находить специалистов по обслуживанию. На фоне Infiniband это существенно снижает стоимость владения инфраструктурой, упрощает ее развертывание.
Единственный серьезный недостаток, который препятствовал широкому распространению RDMA over Ethernet — отсутствие механизмов защиты от потери пакетов, что ограничивает пропускную способность всей сети. Для сокращения потерь пакетов или предотвращения перегрузки сети необходимо использовать сторонние механизмы. Мы пошли как раз этим путем, предложив собственные интеллектуальные алгоритмы компенсации недостатков RDMA over Ethernet при сохранении его преимуществ в новом инструменте — Huawei Ai Fabric.
Huawei AI Fabric — свой путь
AI Fabric реализует RDMA over Ethernet, дополненный собственным интеллектуальным алгоритмом управления перегрузками сети, что обеспечивает нулевую потерю пакетов, высокую пропускную способность сети и низкую задержку передачи для RDMA-потоков.
Huawei Ai Fabric построен на открытых стандартах и поддерживает целый спектр различного оборудования, что оптимизирует процесс внедрения. Однако некоторые дополнительные инструменты — надстройки над открытыми стандартами, позволяющие повысить эффективность обмена данными, о которых мы расскажем в последующих публикациях — доступны только для устройств производства Huawei. В коммутаторы серии CloudEngine, поддерживающие решение, интегрирован чип, анализирующий характеристики трафика и динамически настраивающий сетевые параметры, что позволяет эффективнее использовать буфер коммутатора. Собранные характеристики также используются для прогнозирования модели трафика в будущем.
Кому это полезно?
Huawei Ai Fabric позволяет получить профит на двух уровнях.
С одной стороны, решение позволяет оптимизировать архитектуру ЦОД — сократить количество узлов (за счет более оптимальной утилизации ресурсов), создать конвергентную среду без традиционного разделения на отдельные подсети, которые сложно и дорого обслуживать по частям. С использованием инструмента не придется под каждый тип сервиса в контроллере домена (со своими требованиями к сети) выделять отдельные подсети. Можно создать единую среду, которая обеспечивает предоставление всех услуг.

С другой стороны, AI Fabric позволяет повысить скорость распределенных вычислений, особенно там, где требуется часто обращаться к памяти удаленных систем. К примеру, внедрение ИИ в любой сфере подразумевает период обучения алгоритма, который может включать миллионы операций, поэтому выигрыш в задержке на каждой такой операции обернется серьезным ускорением процесса.
Эффект от внедрения специализированного инструмента, вроде Huawei Ai Fabric, будет заметен в ЦОД с шестью и более коммутаторами. Но чем больше объем ЦОДа, тем выше профит — за счет оптимальной утилизации ресурсов кластер того же масштаба с Ai Fabric обеспечит более высокую производительность. Для примера кластер из 384 нод может достичь производительности «обычного» кластера в 512 нод. При этом решение не имеет ограничений по количеству физических коммутаторов внутри инфраструктуры. Их могут быть десятки тысяч (если забыть о том, что обычно проекты ограничиваются масштабами административного домена).
