Развитие компилятора C для нового мультиклета-нейропроцессора

На конференции разработчиков системного и инструментального ПО — OS DAY 2016, которая прошла в г. Иннополис 9–10 июня 2016 (Казань) при обсуждении доклада о мультиклеточной архитектуре была высказана мысль, что она будет наиболее эффективной при решении задач искусственного интеллекта. Условия для разработки нового процессора общего назначения, ориентированного на задачи ИИ, сложились в текущем году.
Нейропроцессор Мультиклет S2, проект которого был впервые представлен на Huawei Innovation Forum 2019 является дальнейшим развитием мультиклеточной архитектуры. От ранее созданных мультиклетов он отличается системой команд, а именно вводом новых типов малоразмерных данных (с фиксированной и плавающей запятой) и операций с ними. Увеличено количество клеток — 256 и частота — 2,5 ГГц, что должно обеспечить пиковую производительность 81,9 TФлопс на 16F и, соответственно, сделать его сравнимым, в части нейровычислений, с возможностями современных специализированных ASIC TPU (TPU-3: 90 Тфлопс на 16F).
Так как эффективность использования процессоров в значительной мере зависит от оптимальности компилятора разработана развиваемая схема оптимизации кода.
Рассмотрим ее более подробно.
В предыдущей статье упоминалось об оптимизациях компилятора, которые целесообразно реализовать. Там же вы можете найти материалы о мультиклеточной архитектуре, если вы еще не знакомы с ней.
Генерация двухаргументных команд с двумя константами
С процессором S1 был введен новый формат команд, позволяющий указывать оба аргумента как константное значение. Это позволяет сократить количество команд в коде, избавляясь от лишних команд типа load для загрузки констант в коммутатор.
Например:
load_l func
wr_l @1, #SP
можно заменить на:
wr_l func, #SP
Или даже двух команд сразу:
load_l [foo]
load_l [bar]
add_l @1, @2
Здесь два константных адреса, и чтение из них можно также подставить прямо в аргументы команды:
add_l [foo], [bar]
Данная оптимизация была реализована для всех поддерживающих такой формат. К сожалению, она оказалась очень малоэффективной, по двум причинам:
- Количество ситуаций, где такую оптимизацию можно провести, очень мало. В арбитрарном коде нечасто появляются ситуации, когда нужно как-то обрабатывать два значения, известные заранее. Чаще всего такие вещи решаются на этапе компиляции, и лишь немного остается для выполнения в рантайме. Обычно это некие операции над адресами, опять же, константными.
- Удаление команды загрузки не освобождает процессор от самого процесса генерации константы, а только от выборки отдельной команды load, что дает лишь слабое ускорение, да и то не всегда.
Оптимизация переноса виртуальных регистров между базовыми блоками
В LLVM базовые блоки — это линейные участки, в которых код исполняется без ветвления. Точно такую же функцию выполняют и параграфы в мультиклеточной архитектуре, поэтому чаще всего при генерации код один параграф отражает один базовый блок. В процессоре R1 любая передача виртуальных регистров между параграфами осуществлялась через память путем записи значения нужного регистра на стек и считывания его обратно в параграфе, которому понадобится этот регистр. Этот механизм разделяется на 2 части: передача виртуального регистра в другой параграф для прямого использования и передача виртуального регистра как параметр для phi узла.
Phi узлы — это последствие SSA (Static Single Assignment) формы, в которой представлен язык внутреннего представления LLVM. В этой форме переменную (или, как в случае LLVM IR — виртуальные регистры) можно записать значение только один раз. Например, этот псевдокод:
a = 1;
if (v < 10)
a = 2;
else
a = 3;
b = a;
не представлен в SSA форме, ведь значение переменной а может быть перезаписано. Код можно переписать в этой форме, если использовать phi узел:
a1 = 1;
if (v < 10)
a2 = 2;
else
a3 = 3;
b = phi(a2, a3);
Phi узел выбирает а2 или а3, в зависимости от того, откуда пришел поток управления: 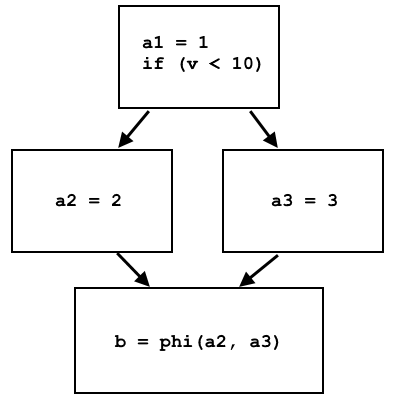
В LLVM IR phi узлы реализованы как отдельная инструкция, которая выбирает разные виртуальные регистры в зависимости от того, из какого базового блока пришло управление. Реализация на процессоре этой инструкции через память довольно проста: разные базовые блоки записывают разные данные в одну и ту же ячейку памяти, а на месте phi узла эта ячейка памяти считывается, и данные будут разные в зависимости от предыдущего базового блока.
SSA форма подразумевает, что когда инициализируется регистр, значение там будет лежать всегда и одно и то же. При прямой передачи виртуальных регистров, когда значение каждого виртуального регистра записывается в свою отдельную ячейку памяти, условие SSA соблюдается без проблем: данные в памяти лежат, пока их не перезапишут. Однако, если мы хотим передавать регистр через коммутатор, необходимо помнить: его размер лишь 63 ячейки, и любое значение пропадает по выполнению любых 63 команд. Поэтому, если виртуальный регистр записывается в каком-нибудь первом параграфе, а используется после выполнения еще сотни других, то передать его через коммутатор невозможно; остается только память.
Реализация данной оптимизация была начата именно с оптимизации phi узлов, потому что, в отличие от прямой передачи виртуальных регистров, значения параметров для phi узла инициализируются всегда непосредственно в предыдущих параграфах (базовых блоках), что позволяет сильно не задумываться о том, хватит ли размера коммутатора, если мы хотим передавать эти параметры через него.
Мультиклеточный ассемблер позволяет присваивать результатам команд имена, и использовать их результаты по этому имени. Вместо того, чтобы программисту каждый высчитывать сколько команд назад этот результат был получен, ассемблер подсчитывает это самостоятельно:
result := add_l [A], [B]
;
; некоторое количество команд
;
wr_l @result, C
Этот механизм прекрасно работает в пределах текущего параграфа, потому что это линейный участок и там известен порядок команд. Это активно используется при генерации кода компилятором: всем командам присваиваются имена и компилятору не нужно заботиться о нумерации команд. Точнее, не нужно было, потому что если мы хотим получить результат команды, выполненный в другом параграфе, то механизм не работает: на этапе ассемблирования невозможно узнать какой параграф реально выполнился предыдущим, если в текущий есть несколько входов. Поэтому единственным вариантом остается обращение к результатам команд через номер. По этой причине нельзя просто выкинуть лишние записи/чтения из памяти в соседних параграфах и заменить ссылки на регистры с команды чтения на команду в предыдущем параграфе.
Здесь стоит обратить внимание на очень важное последствие: если параграф имеет несколько входов, то @1 в первой команде этого параграфа может обращаться к совершенно разным результатам в зависимости от того, какой параграф был предыдущий. Phi узел — это именно такая ситуация. Раньше во всех базовых блоках, инициализирующих phi узел, данные записывались в одну и ту же ячейку памяти, а на месте phi узла было считывание из этой ячейки. Таким образом, абсолютно не важно было место, в котором стояла запись в эту ячейку в предыдущих параграфах, ровно как и место, в котором эта ячейка считывалась. Если избавляться от использования памяти — это меняется.
Чтобы позволить phi узлам использовать коммутатор вместо памяти, было сделано следующее:
- Подсчитываются все phi узлы в текущем базовом блоке (а их может быть несколько), помечаются порядковым номером и выстраиваются в этом порядке
- Для каждого phi узла обходятся инициализирующие его базовые блоки, в них добавляются команды загрузки значения в коммутатор (loadu_q), помеченные порядковым номером соответствующего phi узла
- Сама инструкция phi узла также заменяется на loadu_q с ее порядковым номером
- Все добавленные команды переставляются в заданном порядке
Четверый пункт необходим по уже указанной причине: если бы хотим, чтобы команда loadu_q @3 обращалась к результату именно для своего phi узла, то у всех инициализирующих параграфов команды, загружающие данные в коммутатор, должны стоять в абсолютно одинаковом порядке. Приведем в пример реальный результат компиляции кода, в котором есть два phi узла в одном базовом блоке.
Параграфы с иницализаторами phi узлов:
LBB1_27: LBB1_30:
SR4 := loadu_q @1 setjf_l @0, LBB1_31
setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8]
SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP]
SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff
SR7 := add_l @SR6, [@SR4] loadu_q @SR5
wr_l @SR7, @SR4 loadu_q @SR6
loadu_q @SR6 complete
loadu_q @SR5
complete
Параграф с двумя phi узлами:
LBB1_31:
SR4 := loadu_q @2
SR5 := loadu_q @2
SR6 := loadu_l [#SP + 124]
SR7 := loadu_l [#SP + 120]
setjf_l @0, @SR7
setrg_q #RETV, @SR4
wr_l @SR5, @SR6
setrg_q #SP, #SP + 120
complete
Ранее, вместо команд loadu_q здесь бы стояли записи в память и чтения из нее.
В процессе реализации этой оптимизации также возникли некоторые проблемы, которые не были предвидены заранее:
- Некоторые уже существующие оптимизации кода переставляют команды местами, например вынесение установки адреса следующего параграфа в самое начало текущего, или расположение команд чтения/записи с памятью в начале/конце параграфа соответственно. Эти оптимизации происходят после операций с phi узлами (так называемый lowering LLVM инструкций до процессорных команд), поэтому они зачастую нарушают построенный порядок команд loadu_q. Чтобы не нарушать работу этих оптимизаций пришлось создать отдельный LLVM проход, который расставляет команды для phi узлов в нужном порядке уже после всех остальных манипуляций с командами.
- Оказалось, может возникнуть ситуация, при которой один базовый блок инициализирует phi узлы для двух разных базовых блоках. То есть, следуя указанному алгоритму, эти базовые блоки добавят в инициализирующий по loadu_q команде для каждого phi узла. В этом случае, даже если phi узел у них всего один, в инициализирующем параграфе будет 2 команды loadu_q, которые, по логике, обе должны стоять на последнем месте, что, конечно, невозможно. К счастью, такие ситуации довольно редки, поэтому если встречается такой базовый блок, в котором инициализируются phi узлы для более, чем одного другого базового блока, то только для первого используется коммутатор по алгоритму, для остальных — как раньше, через память.
Всю эту оптимизацию phi узлов можно будет еще немного дополнить. Например, если посмотреть на параграф LBB1_30 выше, то можно увидеть, что команды loadu_q загружают значения, которые больше нигде не используются. То есть, если убрать loadu_q и выставить команды, создающие эти значения, в таком же порядке, то команды loadu_q @2 в следующем параграфе будут также загружать правильные значения.
Бенчмарки
Текущие результаты оптимизации были протестированы на бенчмарках CoreMark и WhetStone, описание которых можно посмотреть в предыдущей статье. Начнем с результатов CoreMark на ядре S2 в сравнении со старыми результатами (предыдущая версия компилятора на ядре S1).
Относительные показатели CoreMark/MHz приведены на гистограмме:

Чтобы получить оценку ускорения только за счет оптимизации phi узлов, можно пересчитать показатель CoreMark на одной мультиклетке на ядрах S1 и S2 для частоты 1600 МГц: они составляют 1147 и 1224 соответственно, что означает прирост на 6.7%.
С WhetStone ситуация несколько иная. Изменения в ядре здесь повлияли на результат, к тому же этот бенчмарк запускается на одном ядре (мультиклетке) и рассчитывается в показателе на мегагерц, поэтому частота процессора не играет никакой роли.
Сравнительная таблица показателей Whetstone:
Сейчас видно, что даже при использовании предыдущей версии компилятора на ядре S1 общий показатель выше, причем в основном из-за тестов с плавающей точкой MFLOPS1–3. Данный недостаток был замечен в ходе тестирования и вызван тем, что внутренний конвейер блока операций с плавающей запятой в S2, по сравнению с S1, больше на один шаг. В результате последовательные цепочки команд, связанных по данным, теряли на каждой команде по одному такту. Необходимость этого шага была вызвана сокращением длительности такта (увеличением частоты работы процессора с 1,6ГГц до 2,5ГГц и увеличением номенклатуры команд, например, появлением команды умножения с накоплением МАС). Это решение — временное. Работа по сокращению длины конвейера проводится, и в будущем это будет исправлено, но тесты проводились на текущей версии S2.
Для оценки ускорения оптимизации компилятора, WhetStone был также скомпилирован на предыдущей версии и запущен на текущей версии S2. Общий показатель составил 0.3068 MWIPS / MHz против 0.3267 MWIPS / MHz на новом компиляторе, т.е. что показывает ускорение на 6.5% за счет вышеописанных оптимизаций.
Разработанная и апробированная система оптимизации позволяет реализовать в дальнейшем очередную оптимизационную схему, а именно, прямую передачу виртуальных регистров через коммутатор. Как уже было сказано, далеко не каждое копирование виртуального регистра можно сделать через коммутатор. Ввиду ограничения по размеру коммутатора и невозможности корректно обращаться к результатам предыдущих параграфов, если точек входа в текущий несколько (это частично решается phi узлами), единственным возможным вариантом остается копирование виртуальных регистров из одного параграфа непосредственно в следующий, но такой, которого есть только один предыдущий. Таких случаев, на самом деле, не так и мало, довольно часто необходимо так напрямую передавать данные, хотя насколько большое ускорение кода это даст сказать заранее, конечно, сложно.
