Развитие инфраструктуры Погоды. Доклад Яндекса
Что делать, если у вас завелись микросервисы, API стало слишком сложно пользоваться и на фронте все чаще мелькает undefined is not a function? На примере Яндекс.Погоды я показал, как мы эволюционировали из REST в GraphQL и почему это сделало жизнь разработчиков фронтенда и приложений мягкой и шелковистой.— Меня зовут Всеволод Струкчинский, я ведущий разработчик Яндекс.Погоды. Доклад будет о том, как мы проектируем свой API, чтобы им было удобно пользоваться и мы от него не страдали.
В докладе четыре части. Сначала — общий обзор, что такое Погода. Потом — как она устроена внутри, какие сервисы используются. Дальше мы погрузимся в наш API, поговорим о том, как и из-за чего мы эволюционировали из Rest API в GraphQL.
Что такое Погода
В первую очередь это наш сайт pogoda.yandex.ru, там самое большое количество наших активных пользователей, на нём вы можете посмотреть погоду, погодные карты, прогноз погоды на сейчас, на 10 дней и так далее. Также вы можете найти погоду на главной странице, yandex.ru. Вторая по значимости причина захода на Яндекс — узнать погоду. У нас есть мобильное приложение. Еще нас показывают по новостям. Очень много и других потребителей — радио, Алиса в Яндекс.Станции, которую вы можете спросить о погоде.
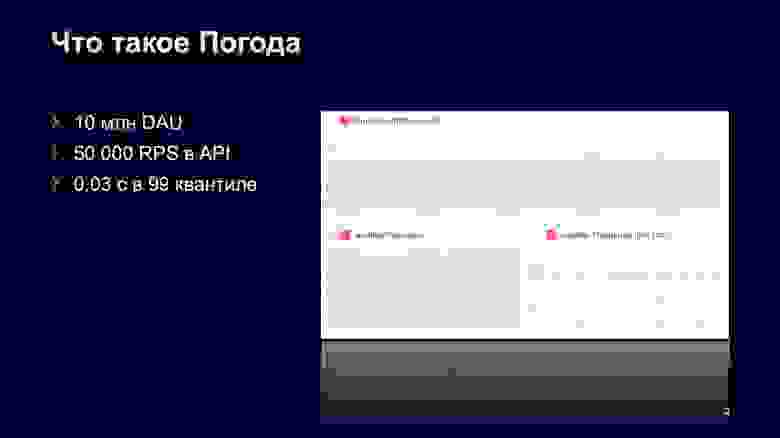
Что это в цифрах? Такое количество платформ дает нам большую нагрузку на API — около 50 тысяч RPS в довольно спокойные дни.
Также это около 10 миллионов пользователей, которые каждый день приходят на Погоду, на наш сайт из разных источников. Весь сервис спроектирован так, что мы обслуживаем эти запросы за 30 миллисекунд в 99-м квантиле. Мы к этому результату очень долго шли, в частности переход на Apphost в этом нам помог.
Чаще всего к Погоде обращаются с вопросом, какая погода сейчас за окном, идет ли сейчас дождь или какая температура, чтобы было понятно, как одеваться. Второй по частотности юз-кейс — почасовой прогноз: люди заходят и смотрят, не начнется ли дождь и когда он закончится. Также мы предоставляем прогноз на 10 дней.
Последняя фишка — наукаст осадков. Мы скачиваем радарные данные о том, где идёт дождь, и показываем прогноз того, где будут осадки в будущем. У нас есть и довольно много побочных данных — климат, температурные карты, но о них мы сегодня не будем говорить.
Как Погода устроена
Как это устроено внутри? Казалось бы, такое количество информации о погоде очень сильно связано между собой, и данных довольно много.
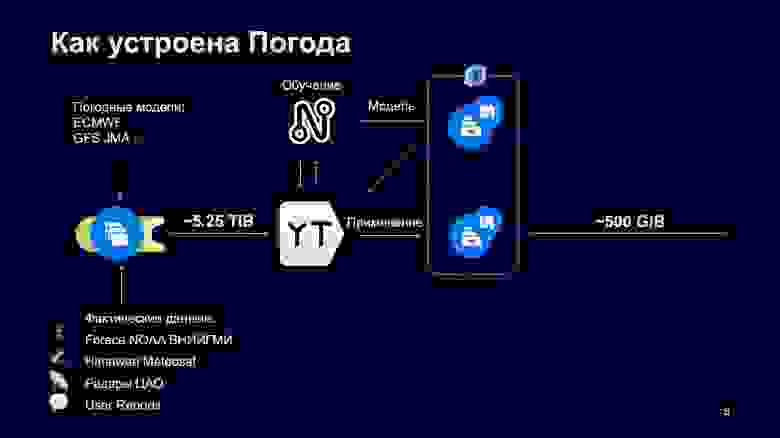
Внутри мы устроены довольно классически. Поставщики присылают нам данные, у нас поднята celery-очередь, к которой подключены обработчики на Python и C++. Эта celery-очередь работает поверх облачного Yandex Message Queue, который предоставляет интерфейс, похожий на Amazon SQS. Дальше эти все данные скачиваются и отправляются в YT. Это MapReduce-система для обработки, мне кажется, сверхбольших данных. Там данные складываются для обучения. Периодически туда приходят графы в Нирване. Про Нирвану вы тоже можете найти статью на Хабре, это система для организации распределенных вычислений. В частности, мы ее очень часто используем для обучения наших формул.
Нирвана по завершении графа сохраняет обычную модель в Yandex Object Storage. Оно очень похоже на S3, даже предоставляет API, совместимый с S3. Над этим облачным хранилищем развернут облачный PostgreSQL, который сохраняет метаинформацию, чтобы ее потом было удобно искать по моделям и сохраненным файлам.
YT запускается и скачивает модель из объектного хранилища, у него уже есть на руках данные, он их применяет и загружает результаты применения обратно в наше облачное хранилище.
Если перейти к цифрам, то от поставщиков в YT у нас скачивается примерно 5,25 терабайта данных. Это довольно много, но данные у нас в большинстве своем распространяются на весь мир. Самые большие по занимаемому месту — погодные модели ECMWF, GFS JMA. Меньше занимают показания со станций, которые предоставляют Foreca, NOAA, ВНИИГМИ.
Данные со спутников, которых у нас два, Himawari и Meteosat, — тоже не очень большие, как и данные с радаров. Последние весят около мегабайта, но радаров порядка 20 и они присылают очень частотные данные. Каждый радар присылает их раз в три-пять минут.
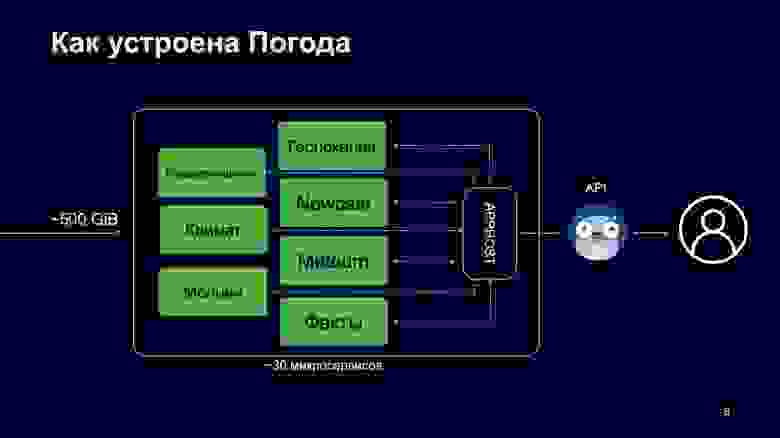
После применения у нас есть на руках около 500 гигабайт данных — температура, скорость ветра, UV-индекс и так далее, более 25 переменных.
Все эти данные скачиваются нашим рантаймом, который обслуживает запросы. Этот рантайм поднят в Apphost, в него входит около 30 микросервисов, каждый из которых отвечает за свою область данных. Микросервис Meteum отвечает за прогнозные данные по температуре, а микросервис Nowcast — за прогнозируемые данные для карты Nowcast. Также есть Молнии, Климат, Предупреждения, Геолокация.
Весь этот зоопарк микросервисов живет исходным кодом в едином репозитории, а рантайм развернут в нашем облаке, про планировку которого вы слышали в докладе Андрея. Над этим всем работает Apphost, про него уже тоже было сказано. Это аналог Service Mash, только он использует архитектуру вида «звезда»: все запросы замыкаются в Apphost, и он решает, в какие микросервисы он пойдет, как сделать запросы, что будет в момент отказа каких-то сервисов, куда пойти или не пойти.
Чтобы общаться с Apphost, нужен интерфейс для клиентов. У нас этот интерфейс предоставляет API, который принимает запросы пользователей по REST и GraphQL и вызывает Apphost, чтобы он выполнил граф.
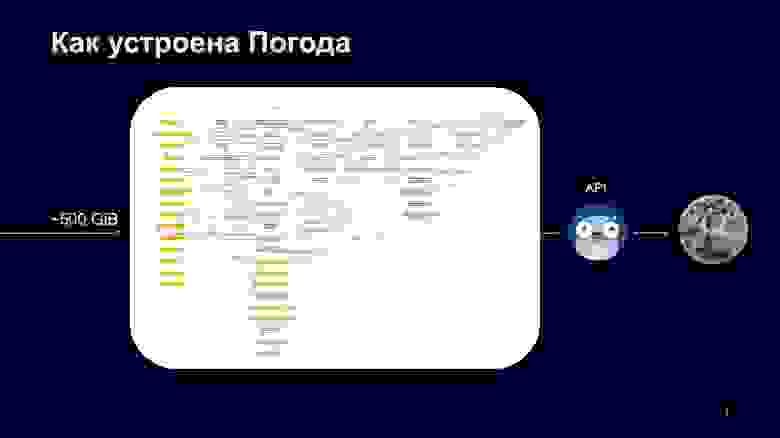
Как это выглядит в продакшене? У нас тоже есть свой большой граф. На слайде его не полная версия, оранжевые квадраты — это подграфы, в которых лежат другие графы. Схема довольно сложная. Глядя на нее, можно увидеть: чтобы получить прогноз или текущую температуру, нам нужно опросить много сервисов, принять из них ответы, нормализовать их и отдать пользователю.
Погружение в погодный API
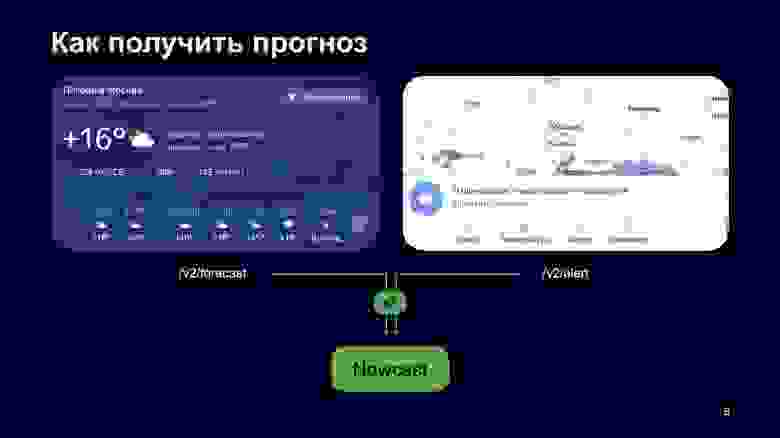
Возьму пример с нашего сайта. Вот два блока. Первый блок — прогноз текущей и почасовой погоды, второй — предупреждения и карта осадков. Как вы можете видеть, и там, и там есть погодная иконка. Она забирается из разных REST-ручек: левый блок забирает из forecast, правый — из alert.
Такие подходы генерируют нам два запроса за одной и той же иконкой в наш сервис Nowcast, и это плохо.
Еще хуже другое: если мы будем показывать здесь две разные иконки, это будет явно бросаться в глаза и пользователи будут репортить: «У вас сломался прогноз, почему вы показываете две разные иконки?»
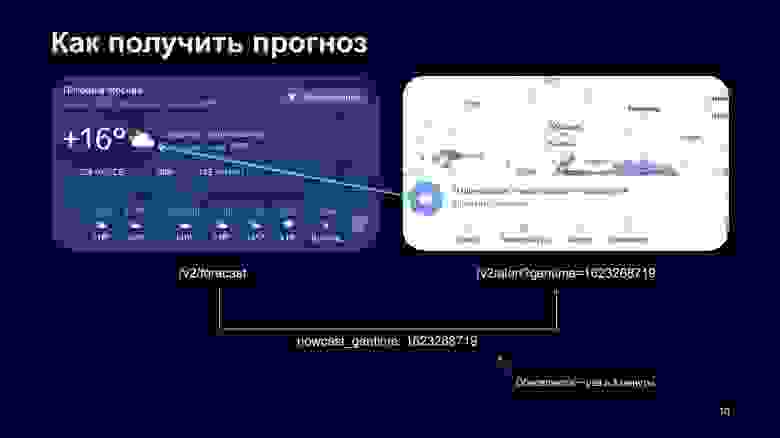
Чтобы решить эту проблему, мы решили в REST API пробрасывать gentime нашего Nowcast, то есть время генерации Nowcast по нашим данным. Когда клиент идет в forecast и получает оттуда данные, ему еще приходит gentime данных Nowcast, которые в нём подмешаны.
Дальше фронтенд берет этот gentime и идет в REST уже с фиксированной версией данных. Так мы избегаем рассинхрона, но это довольно сильно утяжеляет логику клиента, не все клиенты соблюдают правило, что нужно взять число из ответа forecast и передать его в alert.
Есть фактор, который еще сильнее ухудшает ситуацию. Предположим, фронтенд сходил за данными forecast, получил ответ, получил фиксированный gentime, пошел в ручку alert, а она по каким-то причинам сфейлилась, либо сеть моргнула, либо возникли ещё какие-то проблемы, бывает. Что ему тогда делать — непонятно: перезапросить эту ручку он может, но, так как эта ручка обновляется раз в три минуты, он может получить ответ, что такого gentime уже нет, данные устарели.
Тогда ему придется идти и заново получать данные из forecast, заново смотреть на этот gentime, делать всё заново. Это довольно сложная операция.
Вопрос: почему не вернуть все данные в ручке /v2/forecast?
/v2/forecast?
Возьмем и добавим туда флаг — не возвращать гео.
/v2/forecast?no_geo=true
Не возвращать почасовые. Возвращать цвета, переводы, один день, еще какие-то экстра-данные, бриф. Все эти данные — реальные флаги в нашем production API. Добавить туда alert.
/v2/forecast?no_geo=true&hours=false&colors=true&l10n=true&limit=1&extra=true&brief=true&alert=true
Мы на эту идею посмотрели и решили от нее отказаться, потому что такое наращивание флагов ведет к экспоненциальному взрыву бизнес-логики на стороне API. Мы перестаем понимать, какие флаги на какие влияют, что будет, если включить alert и выключить экстра, влияет ли лимит на alert. Разрабатывать и поддерживать это очень неудобно.

Еще неудобнее то, что вся документация на наш REST API ручная, мы ведем ее на вики, и она имеет свойство устаревать. Более того, наш REST API, даже если мы заведем плюс-минус 50 флагов, всё равно будет возвращать лишние данные, которые не всем клиентам нужны. Как и у всех сервисов, у нас уже довольно много endpoint«ов, мы рассмотрели только два, а их около 40. Генерировать разные endpoint’ы вместо query-параметров для клиентов тоже нам не подходило. Протекание сложной логики запросов и перезапросов на клиент — это тоже наша большая боль.
Тогда мы решили посмотреть, что есть вокруг, и сказать: REST in peace. Первое, что попадается, когда вы ищете в Яндексе альтернативу REST — это GraphQL.
GraphQL

Я начну cразу с запроса в GraphQL API. Допустим, нам нужна только температура и иконка. GraphQL предоставляет SDL для запросов, где вы можете описать, что именно вам нужно. В этом запросе мы получаем погоду по координатам. Можно читать слева направо: мы запрашиваем weather by point, передаем координаты, нам нужна текущая температура и иконка, также мы указываем формат иконки. Это позволяет клиенту очень точно описать, что он от нас хочет, и мы не сможем прислать ему лишние данные.
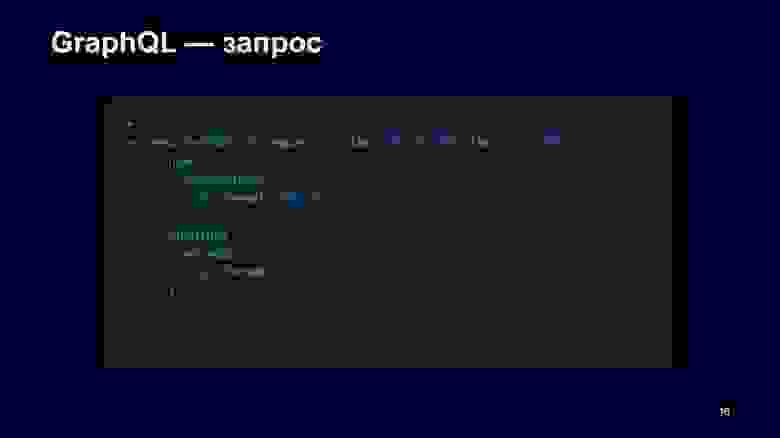
Если клиент эволюционировал и ему нужные дополнительные данные, он может доработать этот запрос, добавить в него, что ему нужные погодные предупреждения, а из них нужны message и иконка. Дальше этот клиент отправляет нам запрос, и мы внутри себя обходим графы, что-то делаем, все это нормализуем и точно убеждаемся, что сейчас иконка в warning соответствует действительности.
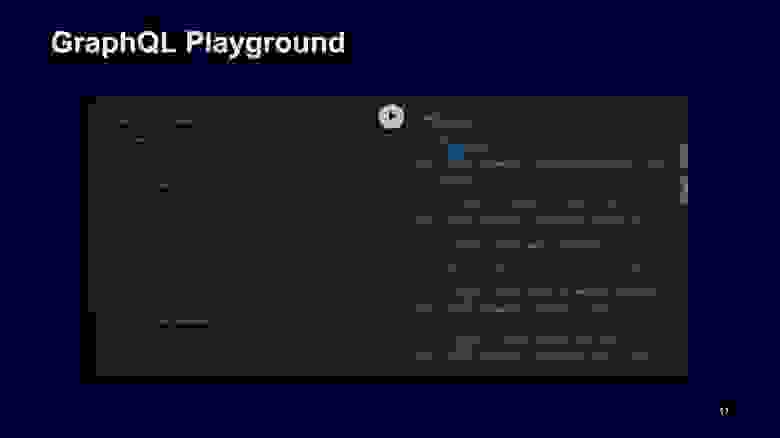
Как оно отвечает? Этот запрос однозначно определяет формат ответа, который приходит от GraphQL API. Справа — примерный запуск этого запроса, он в большинстве случаев повторяет структуру запроса: сначала говорится, что метод ответил «достань погоду по точке» для текущего момента времени, дальше идут предупреждения массивом.
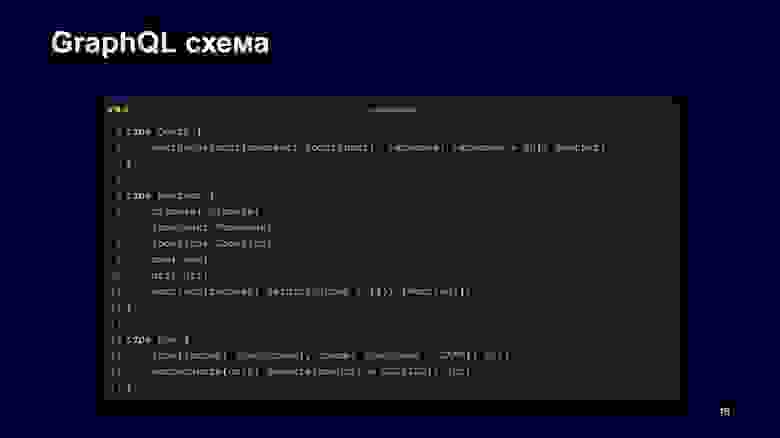
Этот формат жестко определяется схемой, которая в урезанном виде для этого запроса может выглядеть так. У нас есть корневой тип query, у него — функция получения погоды по точке, которая принимает входной тип для точки, язык и возвращает погоду. В погоде вы можете запросить климат, forecast, локацию, текущую погоду, ссылку на сайт и warning. Для текущего момента времени у нас в этом примере только два поля — иконка и температура.
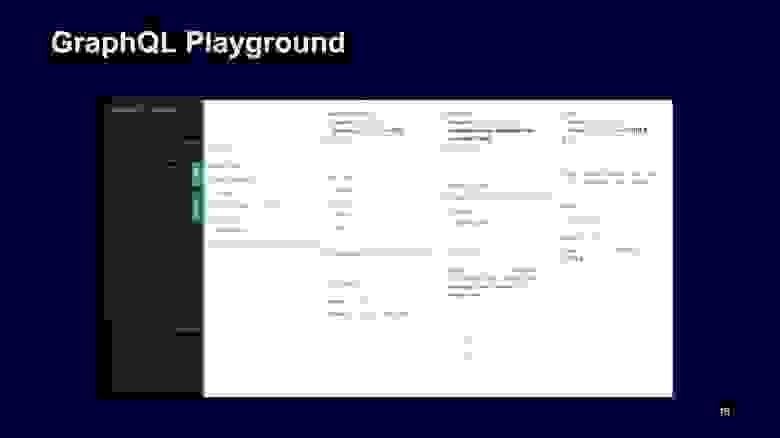
Как клиент может понять, что ему написать? Для этого Playground предоставляет сгенерированную документацию по нашей схеме, вы можете зайти и посмотреть, что и где есть.
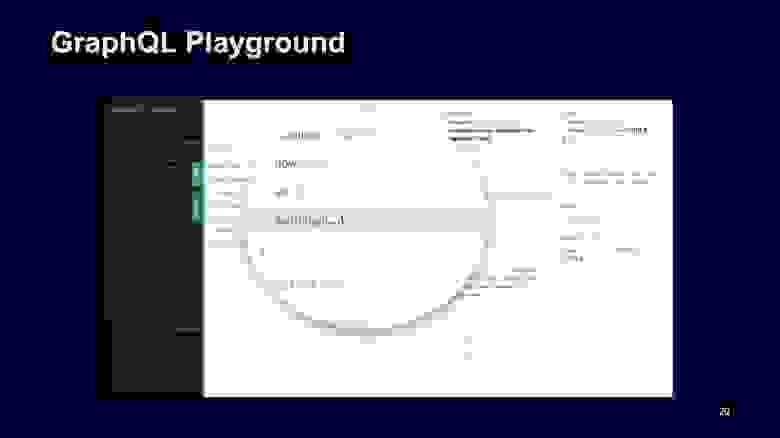
Например, можно убедиться, что для warning включается массив обязательных элементов warning, они не могут быть undefined.
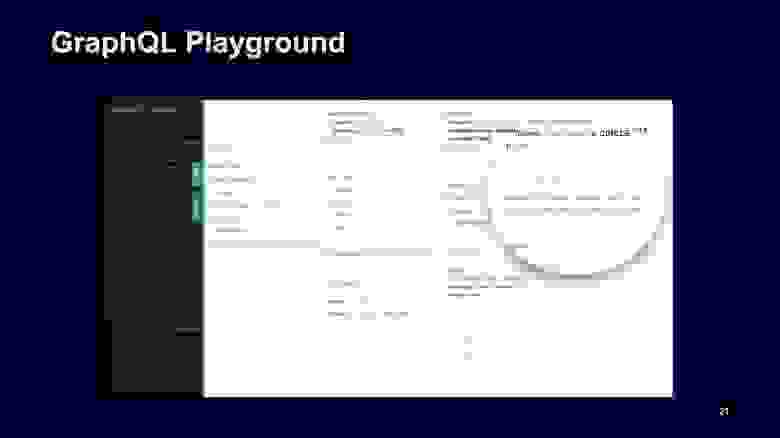
Также он считывает схемы комментария, добавляет их как описание к типам. Это позволяет нам встроить генерацию нашей документации прямо в релизный цикл, мы получаем continuous documentation, это клево. Документация есть, типы есть, но, казалось бы, такая сложная машинерия требует страшных вычислительных ресурсов.
Источник
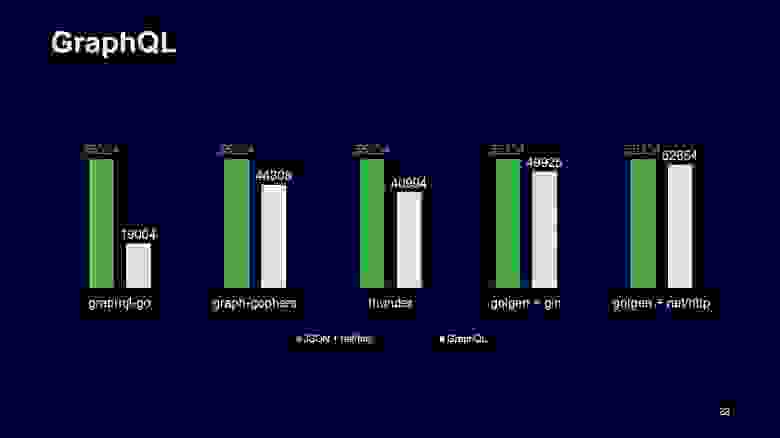
Мы так тоже думали, пока не решили переехать на Go и посмотреть, как с этим обстоят дела в Go. Вот график запросов в секунду разных реализаций Go-серверов для GraphQL. Левый зеленый столбик — это baseline, когда отвечает только JSON и всё жто обрабатывается через NET/http, а правые столбики — результаты обстрелов этих серверов. Левые GraphQl Go показывают не очень хорошие результаты, они более чем в два раза медленнее, чем JSON API, а GQL gen, который использует кодогенерацию, — уже наравне с JSON API и работает очень хорошо.

Мини-итог того, что решает GraphQL. Он сразу решает типизацию ваших запросов и ответов для клиента, у вас уже не будет странных ошибок, что где-то вышел undefined или вы пошли в другое поле. Он организовывает вам continuous documentation, что ускоряет разработку, у вас уже не появляется вопросов, что именно ручка возвращает, какие параметры передать. Вы сами можете попробовать. Клиенты запрашивают только необходимые данные. Это для нас тоже очень важно, потому что опрашивается очень много микросервисов и добавление ненужных переменных о погоде в запрос сильно бьет по нашим ресурсам.
Но почти все базовые реализации GraphQL серверов имеют свои классические боли, про одну из которых я расскажу дальше. Это дедуплицирование запросов в бэкенды или проблема N+1.
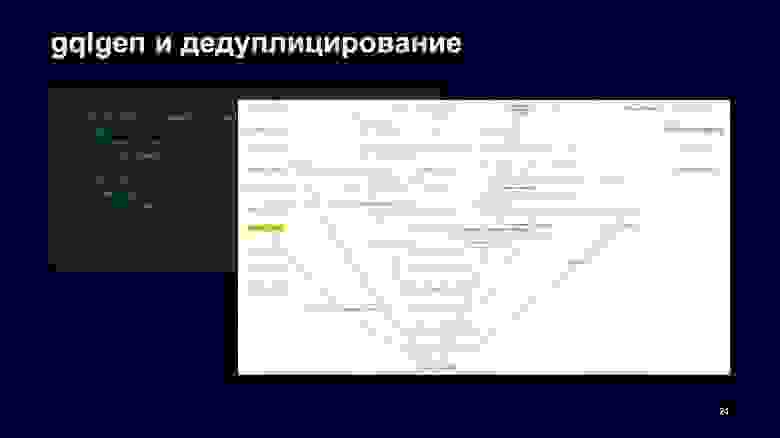
При использовании GraphQL мы по этому запросу сначала заполняем запрос Nowcast в наш граф. Дальше вызывается граф Nowcast, который считывает эти данные. Передает их в Meteum и warning.
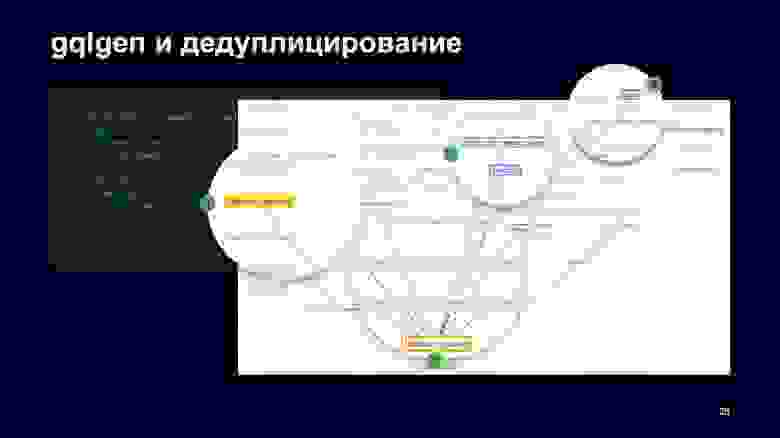
Дальше данные передаются в alert. Как мы видим, дуплицирования запросов в явном виде нет: мы запросили now, warning и, казалось бы, все эти данные прошли один раз до выхода. Но так как в дефолтных реализациях GraphQL-серверов за это отвечают resolver«ы, то вы можете делать два запроса — сначала вы получите данные для now, сформулируете ответ для них, а потом для предупреждений.
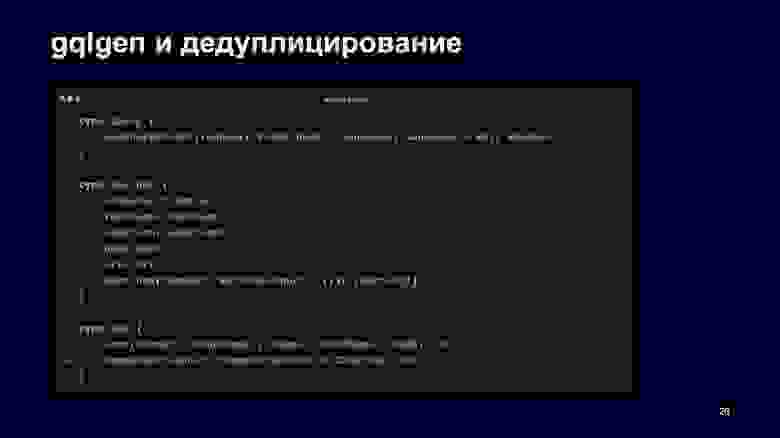
Вернемся к схеме.

Видно, что есть метод weatherByPoint, и gqlgen при запуске кода генерации генерирует функцию, которая обрабатывает этот метод. Она принимает контекст, входные параметры и внутри себя говорит Apphost: «Сформируй, пожалуйста, запрос за погодой по точке для языка, вперед».

Вся магия дедуплицирования происходит внутри метода NewWeatherRequest, в котором мы можем посмотреть, какие поля запрашиваются через NewFieldsCollection. Дальше, если в них есть warning, мы еще добавим входные параметры в граф за warning, и у нас вызовется этот сервис. Если бы в запросе не были запрошены предупреждения, они бы не вызвались.
Как это выглядит на схеме?
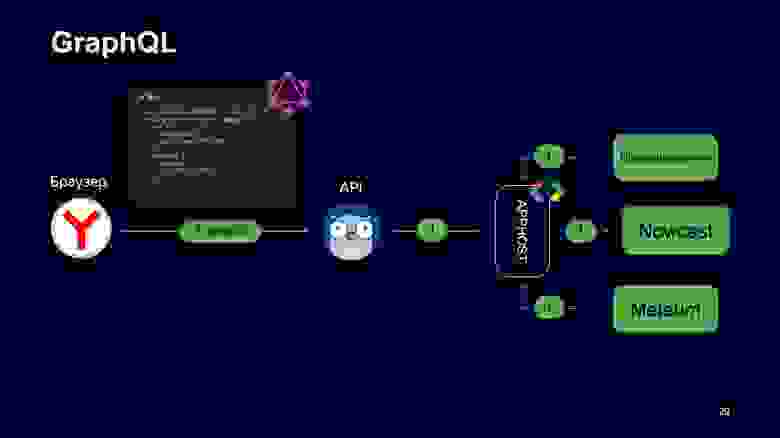
Браузер сейчас делает один GraphQL-запрос за погодой и предупреждениями. API его обрабатывает, смотрит, что ему нужно. Выполняет один запрос в Apphost, который внутри себя общается по Protobuf, и он единожды опрашивает все сервисы, чтобы получить ответ. Казалось бы, история завершена. Но обещание GraphQL про строгую типизацию, которое было дано в начале, реализовано не до конца, потому что браузер может сделать любой запрос, так как он текстовый, и не понять, что схема поменялась или в ней чего-то не было.
Для этого мы взяли Apollo-клиент на нашем фронтенде и генерацию TypeScript-схемы.
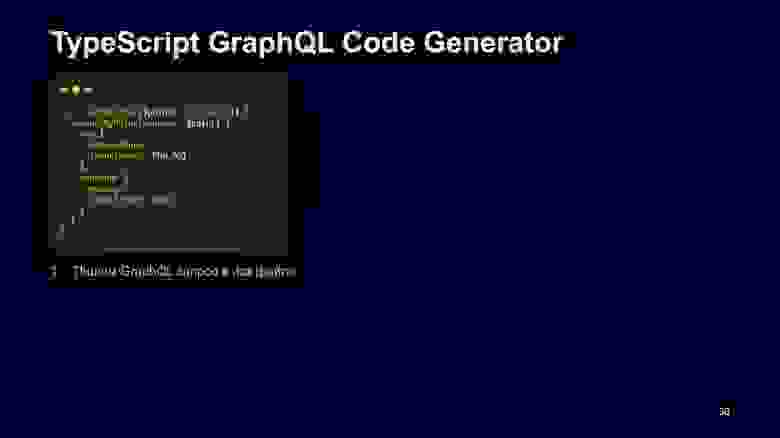
Как это работает в трех шагах? На фронте мы текстом пишем GraphQL-запрос в TypeScript-файле и говорим, что он понимает поинт, именно такие поля мы хотим у него запросить.
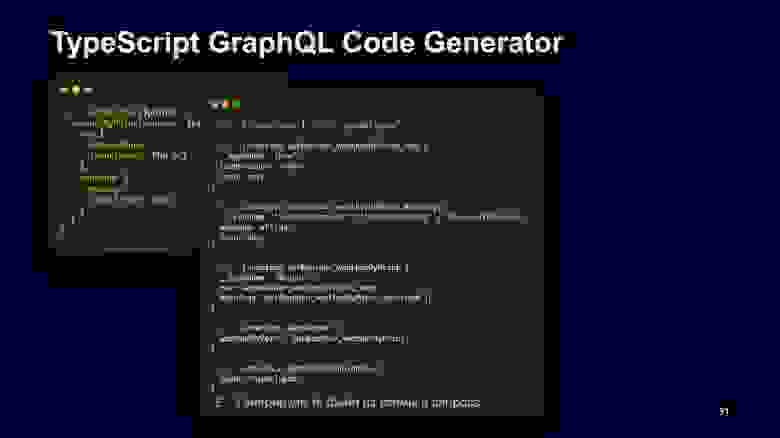
Дальше запускаем утилиту TypeScript GraphQL Code Generator, которая генерирует typescript definition для этого файла. В нём можно видеть, что появились интерфейсы и они могут быть использованы линтерами для подсветки ошибок.

Если вы в клиентском коде портируете, вызываете метод use query, который типизирован get weather, сгенерированном на прошлом шаге, и где-то допускаете ошибку, хотите достать оттуда wanings без r, то TypeScript вежливо вам скажет — извините, такого поля нет.
Заключение
Переход на GraphQL позволил нам добиться уменьшения потребления в два раза на некоторых сервисах, получить больше доступных CPU и железа. Логика клиентов на фронте упростилась, теперь им не надо думать о том, откуда какие цифры передавать. Они запрашивают только то, что им нужно.
Внедрили типизацию: теперь мы не боимся сломать фронт, когда что-то катим, потому что у нас есть continuous integration. Он организовывает проверки, small-тесты, которые запускают линтеры — они подскажут, если мы что-то сломали. Приятным бонусом мы получили автодокументацию на наш API. Фронтенду и клиентам стало проще жить, они могут обращаться к API и проверять свои запросы, смотреть, что приходит в ответ и что этим запросам нужно. Спасибо!
