Разве Tesseract распознаёт медленно?

Работу каждой программы можно ускорить минимум в десять раз
Рабочая установка разработчиков Smart Engines
Мы расскажем о нескольких приемах ускорения распознавания с помощью OCR Tesseract. Всё рассказанное было использовано в реализации проекта, смысл которого состоял в классификации большого числа образов страниц деловых документов (таких документов как паспорт, договор, контракт, доверенность, свидетельство о регистрации и т.п.) и сохранении результатов в электронном архиве. Часть алгоритмов классификации была основана на анализе собственно образов страниц, а часть — на анализе извлечённых из образа текстов. Для извлечения текстов было необходимо распознавание с помощью OCR.
Особенностью любого проекта (заказной работы, предназначенной для создания программного или программно-аппаратного комплекса с установленными заранее свойствами, которые невозможно получить покупкой готового продукта) являются наличие ограничений по срокам и ограничений по ресурсам у исполнителя. Другими словами в проекте исполнитель не всегда имеет возможность решать задачи так, как считает нужным, и вынужден искать компромиссные решения, позволяющие достичь необходимой функциональности при соблюдении сроков и других ограничений. В нашем проекте было необходимо в краткие сроки найти способ распознавания 60000 страниц за 8 часов. По различным причинам мы остановились на бесплатном ПО распознавания текстов и выбрали OCR Tesseract. Основанием для выбора было приемлемое качество распознавания текстов, обеспечивающее качество последующей классификации.
После сборки полнофункционального макета системы (кроме полнотекстового OCR в нём были функции распознавания штрих-кодов, анализа образов страниц документов и функции импорта страниц и экспорта результатов) мы обнаружили, что созданное ПО работает достаточно медленно даже для демонстрации функций системы. Например, оказалось, что обработка 100 страничной тестовой пачки документов занимает более 1 часа, что совершенного не годится для показа заказчику — он просто не дождётся, пока исходные 100 страниц попадут в электронный архив!
Анализ быстродействия показал, что бОльшая часть времени уходит именно на распознавание Tesseract. Поиск информации (как в интернете, так и запросы специалистам) о быстродействии Tesseract показал, что многие пользователи отмечают недостаточное быстродействие этой OCR, а рекомендации по ускорению Tesseract носят частный характер и должны быть проверены экспериментально. Мы проверили несколько способов увеличения скорости распознавания и расскажем о тех из них, которые привели к значительному ускорению работы всей системы.
Способы ускорения произвольной программы можно условно разделить на несколько групп, таких как:
- оптимизация используемого алгоритма;
- выбор параметров используемых алгоритмов;
- оптимизации компиляции с использованием технологий современных процессоров;
- параллелизация алгоримтов обработки.
Начнем с возможности оптимизации собственно Tesseract. Для версии 3.04.00 встроенный для сборки однопоточной системы с помощью Microsoft Visual Studio 2013 с оптимизацией SSE2 профайлер показывает, что 15–25% всего времени исполнения Tesseract заключено в одной единственной функции IntegerMatcher: UpdateTablesForFeature. Теоретически эта функция является кандидатом на оптимизацию алгоритмов, но легко видеть, что код функции IntegerMatcher: UpdateTablesForFeature явно был многократно оптимизирован, по крайней мере, с точки зрения организации данных и минимизации количества операций обработки. Мы пришли к выводу, что возможности такой оптимизации явно требуют расходов времени, которые мы не могли допустить в нашем проекте. Поэтому мы перешли к более простым способам оптимизации.
Опишем используемые нами основные параметры API Tesseract. Инициализация проводилась в режиме fast mode (tesseract: OEM_TESSERACT_ONLY в методе api.Init ()). Распознавалась вся площадь страницы, поскольку для некоторых классов документов недостаточно анализировать заголовок страницы и требует поиск слов в нижней части страницы. Использовался язык распознавания «rus+eng», что выглядит естественным для деловых документов, при печати которых использовались слова как русского, так и английского языка. Страницы были представлены цветными изображениями, хотя в реальности многие страница являлись полутоновыми.
Изменение некоторых из этих параметров позволило существенно ускорить распознавание.
Оценка быстродействия Tesseract проводилась на компьютере Intel® Core™ i7–4790 CPU 3.60 GHz, 16,0 GB, Windows 7 prof 64-bit с 4 физическими ядрами и 8 ядрами HT. Для всех описываемых ниже экспериментов мы использовали один набор данных, состоящий из 300 изображений страниц документов различного типа, различной цветности (полутоновые и цветные), различного разрешения (от 150 до 300 точек на дюйм), различного качества (чистые и зашумленные) и с различным количеством букв на странице. Оценка быстродействия Tesseract проводилась с помощью непосредственных замеров времени распознавания одной страницы.
Распознавание всех 300 страниц с первоначальными параметрами заняло t=4928,53 секунд, при этом среднее время распознавания одной страницы tcp составило 16,43 секунды, минимальное время распознавания одной страницы tmin = 0,99 секунды, а максимальное tmax = 143,21 секунды. Рассмотрим интервалы времени по 10 секунд в диапазоне от 0 до 150. Разброс времени распознавания иллюстрируется гистограммой количества страниц с временем распознавания, попавшим в один из интервалов:

а также графиком суммарного времени, затраченным на распознавание всех страниц из соответствующего интервала:
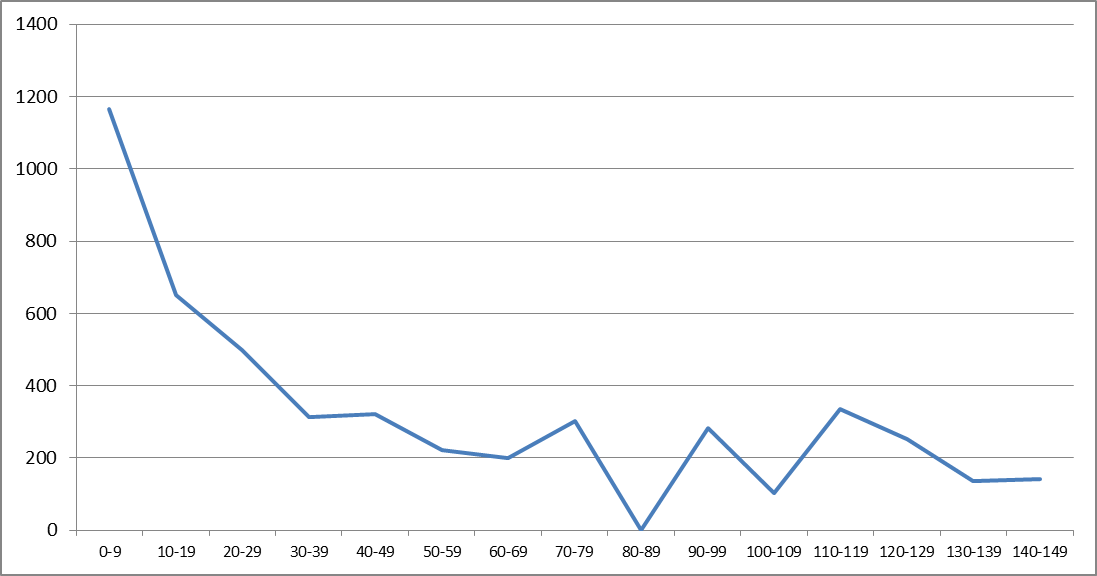
Качественно большой разброс объясняется разнообразием образов страниц в тестовом наборе. В рассмотренном множестве страниц наибольшее время тратится на страницы с большим количеством символов или объектов похожих на символы.
Для ускорения мы, прежде всего, изменили язык распознавания с «rus+eng«на «rus». Это стало возможным из-за внесения изменений в алгоритм дальнейшей классификации, состоящих в анализе только слов, напечатанных кириллицей. Посмотрим, каков оказался выигрыш в быстродействии: суммарное время t=3262,33 сек, среднее время распознавания одной страницы tcp=10,87 секунды, минимальное время распознавания одной страницы tmin=0,99 секунды, максимальное tmax = 83,07.
Результативным оказалось ограничение зоны распознавания в каждой из страниц. Для этого на обучающем множестве из примерно 5000 страниц мы выбрали такое ограничение, чтобы в этой зоне находилось все возможные ключевые слова, необходимые для классификации, и с небольшим запасом выбрали ограничение как 70% по высоте страницы и 90% по ширине. Естественно, что с таким ограничением Tesseract стал распознавать быстрее: суммарное время t=2649,57 сек, среднее время распознавания одной страницы tcp=8,83 секунды, минимальное время распознавания одной страницы tmin=0,83 секунды, максимальное tmax = 77,64.
Отметим, что обе модификации параметров стали возможным только в результате специфики проекта, в других условиях это могло не сработать, например, при наличии во входном потоке англоязычных документов язык распознавания пришлось бы оставить «rus+eng».
Однако после такого «везения» мы продолжили поиск алгоритмов для ускорения обработки страниц. Весьма результативной оказалась процедура бинаризации образов страниц перед распознаванием. Первоначальной целью бинаризации мы считали улучшение собственно точности распознавания благодаря снятию сложного фона и морфологическим операциям. Но бинаризация также дала хорошее ускорение: t=2293,20 сек, tcp=7,64 сек, tmin=0,98 сек, tmax = 59,83 сек. Эти времена были получены для случая распознавания с одним языком «rus », установленной рамкой 0,7×0,9 и с предварительной бинаризацией. Подчеркнем, что приведенные времена включают в себя суммарное время распознавания Tesseract и времени на бинаризацию.
Мы предполагаем, что бинаризация является универсальным приемом, позволяющим одновременно ускорить распознавание и увеличить точность распознавания.
Теперь расскажем об оптимизации с помощью компиляции. Все предыдущие эксперименты проводились с помощью компилятора Visual Studio 13 (version 12.0.40629.00 Update 5). При компиляции с помощью Intel C++ Compiler XE 15.0 мы получили хорошее ускорение по отношению к предыдущему варианту с бинаризацией, рамкой и одним языком: t=2156,00 сек, tcp=7,19 сек, tmin=0,76 сек, tmax=59,66 сек. Для компилятора была указана опция оптимизации для архитектуры AVX2. Для архитектуры SSE4.2 результаты почти такие же, хотя и не превосходящие результаты для архитектуры AVX2. Здесь необходимо упомянуть о том, что компилятор Intel позволяет оптимизировать быстродействие не только для Tesseract, но и для всех других компонент, используемых в системе.
Дополнительно можно было бы воспользоваться установкой таймаута, ограничивающего время распознавания одной страницы, например для метода TessBaseAPI: ProcessPages. Тогда для значения таймаута, равного 30 000 миллисекунд, был бы получен результат: t=2087,10, tcp=6,96, tmin=0,76 сек, tmax=30,00 сек. Однако мы отказались от такого способа оптимизации по двум причине наблюдаемых потерь, связанных с невозможностью классифицировать страницу, забракованную по таймауту.
Для наглядности мы сохранили результаты описанных экспериментов в таблицу:
| № | Способ оптимизации | Суммарное время t (сек) |
Среднее время tcp (сек) |
Минимальное время tmin (сек) |
Максимальное время tmax (сек) |
|---|---|---|---|---|---|
| 1 | Исходный вариант | 4928,53 | 16,43 | 0,99 | 143,21 |
| 2 | Язык «rus» вместо «rus+eng» | 3262,33 | 10,87 | 0,99 | 83,07 |
| 3 | Вариант 2 с ограничением зоны распознавания | 2649,57 | 8,83 | 0,82 | 78,38 |
| 4 | Вариант 3 с предварительной бинаризацией | 2293,20 | 7,64 | 0,98 | 59,83 |
| 5 | Вариант 4 с оптимизацией для AVX2 компилятором | 2156,00 | 7,19 | 0,76 | 59,66 |
Из таблицы следует, что в результате принятых способов оптимизации (вариант 5) суммарное время распознавания всех страниц уменьшилось по отношению к суммарному времени для исходного варианта более, чем в два раза. При этом за счет выбранных алгоритмов бинаризации мы улучшили качество распознавания и последующего анализа содержимого страниц. При такой обработке в течение 8 часов будет распознано примерно следующее количество страниц: 86060/7,19 ≈ 4005.
На следующих рисунках для всех рассмотренных вариантов оптимизации приведены гистограммы количества страниц с временем распознавания, попавшим в один из 10-секундных интервалов и графики суммарного времени, затраченным на распознавание всех страниц из тех же интервалов:
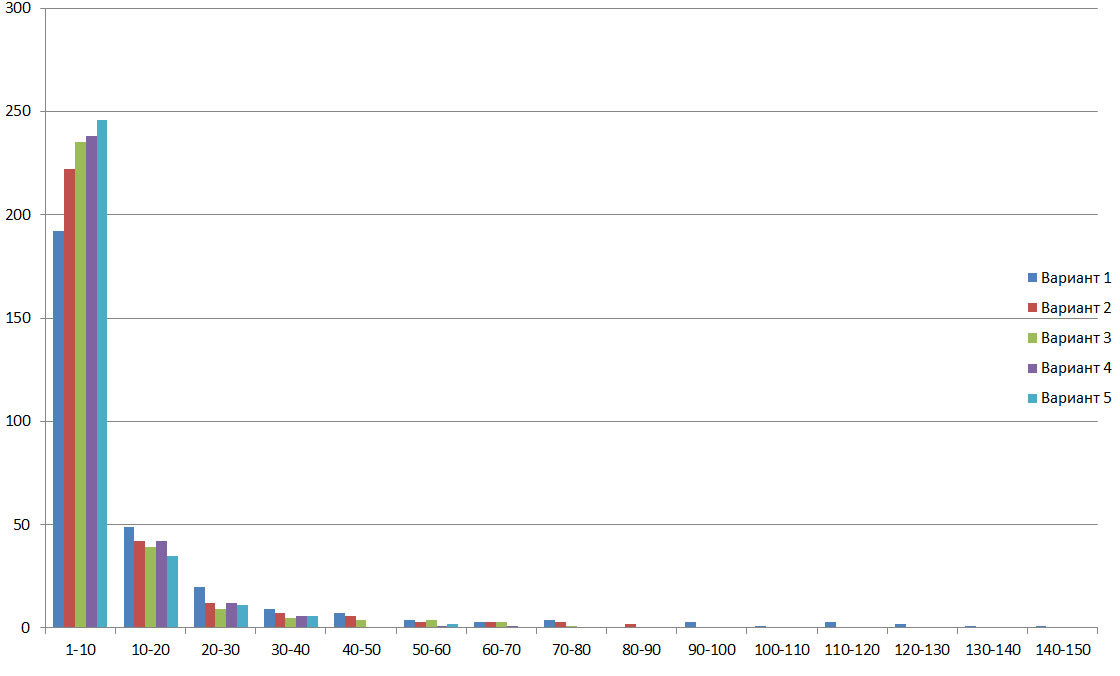
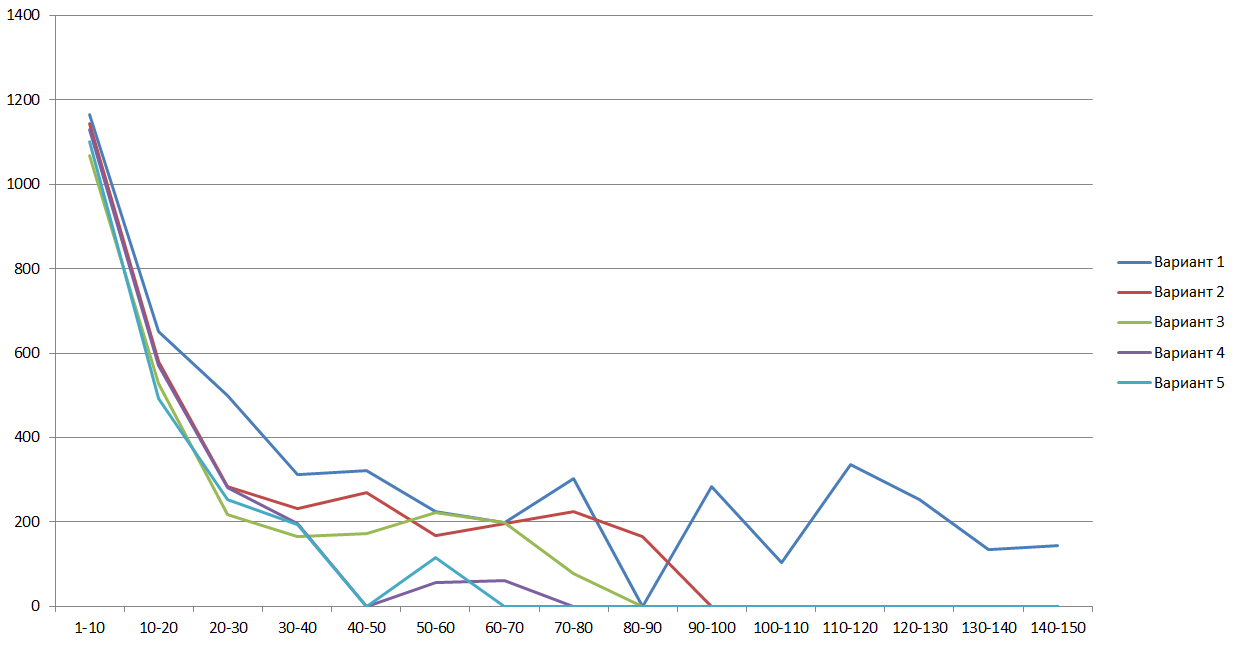
Рассмотрим на графике для вариантов 4 и 5 частоты случившихся времен, попавших в односекундные интервалы. На графике видно, что оптимизация для архитектуры AVX2 уменьшает время распознавания страниц для всех интервалов.
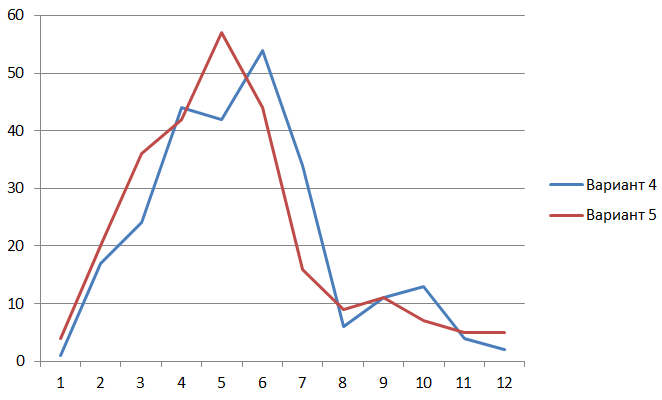
Для вариантов 4 и 5 значения суммарного времени работы Tessract (ранее в таблице были даны значения суммарного времени на распознавание и бинаризацию) составляют 2091,86 и 1993,27 секунд, то есть оптимизация для архитектуры AVX2 позволяет ускорить собственно Tesseract примерно на 5%.
Ясно, что распознавание бОльшого объема страниц нельзя организовать без масштабирования. При масштабировании мы использовали одновременно многопоточность и многопроцессорность. При этом важное внимание было уделено алгоритму балансировки нагрузки на вычислительные модули. Эта система была реализована самостоятельно без применения MPI. Проведем эксперименты обработки (не только распознавания Tesseract, но и всех остальных видов обработки) всех 300 тестовых страниц на одном узле, совпадающем с ранее использованном компьютером, будем оценивать время t обработки всех 300 страниц. Результаты сведены в таблицу:
| Количество процессов | Количество потоков в процессе | Суммарное время t (сек) | Среднее время tcp (сек) |
|---|---|---|---|
| 1 | 1 | 2361 | 7,87 |
| 1 | 2 | 1318 | 4,39 |
| 1 | 3 | 829 | 2,76 |
| 1 | 4 | 649 | 2,16 |
| 2 | 1 | 1298 | 4,33 |
| 2 | 2 | 789 | 2,63 |
| 2 | 4 | 485 | 1,62 |
| 2 | 8 | 500 | 1,67 |
Из таблицы следует, что наилучший результат (1,62 секунд на обработку одной страницы) достигается при запуске 2 приложений, в каждом из которых создано по 4 потока для обработки страниц. Это время соответствует случаю, когда в течение 8 часов будет распознано примерно следующее количество страниц: 86060/1,62=17778. Другими словами мы увеличили скорость обработки страниц примерно в 10 раз. А для обработки заявленного объема в 60000 страниц за 8 часов потребуются 4 аналогичных узла.
Разумеется, можно утверждать, что в аналогичных проектах распараллеливание является наиболее эффективным инструментом увеличения скорости обработки, однако проведенные описанные работы по оптимизации позволили нам ускорить обработку еще в 2 раза, или, что то же самое, позволили уменьшить количество узлов в 2 раза.
В заключение перечислим эксперименты и исследования, которые нам было бы интересно провести «в-принципе», если бы мы имели достаточно свободного времени и достаточные ресурсы:
- исследовать, можно ли вручную оптимизировать быстродействие Tesseract за счет модификации функции IntegerMatcher: UpdateTablesForFeature,
- провести тестирование на архитектуре AVX512 на процессорах Xeon Phi,
- исследовать возможности оптимизации быстродействия Tesseract для GPU.
