Разработка скрипта для сравнения вкусов людей
Приветствую, %username%. Сегодня разработаем скрипт составления рейтинга схожести интересов между людьми.
Заинтересовались? Прошу под кат
Вместо вступления
Хотелось бы заметить, что данный способ работает эффективно только для наибольшего отношения между количеством характеристик набора и числом наборов. Иначе рекомендую использовать данный способ
Теория
Итак, начнем издалека. Представим два некоторых набора данных. Назовем их p и q. Пусть каждый из этих наборов характеризуют два числа. Тогда представим эти наборы, как точки в пространстве L с размерностью dimL = n, где n — количество характеристик. В данном случае 2
p (p1; p2) и q (q1; q2)
Определим некоторую метрику d (p, q) = k, где k — коэф. различия двух наборов. Определим метрику как евклидово расстояние между этими двумя точками, то есть, из курса ангема мы знаем:
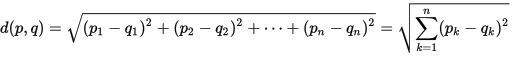
По нашему определению следует, что различие между двумя наборами есть расстояние между точками, которым мы сопоставляем наши наборы. Тогда различие между двумя наборами данных находится по теореме Пифагора, о как!
Тогда для двух идентичных наборов расстояние будет равно нулю.
И что это все значит?
Рассмотрим на примере. Возьмем двух испытуемых, назовем их Вася (В) и Коля (К). Зададим им вопросы:
1) — Оцените по 10 балльной шкале насколько вам нравятся персики
2) — Оцените по 10 балльной шкале насколько вам нравится клубника
Предположим, что Вася и Коля ответили одинаково. Тогда, очевидно, расстояние между точками будет равно нулю, то есть в данных наборах их интересов/вкусов они идентичны. Рассмотрим теперь случай разных ответов.
В: на (1) дал 5, на (2) дал 8
К: на (3) дал 10, на (2) дал 0
Тогда можем представить в двумерном пространстве точки для Коли и Васи:
В (5; 8) и К (10; 0), расстояние между ними, как несложно посчитать 9.4. Это и есть коэф. различия. Но… постойте, как же его интерпретировать?
Давайте посмотрим. Минимальное различие равно нулю при полном совпадении наборов, это понятно. А как же быть с максимальным? Рассмотрим на нашей плоскости некоторую дельта-окрестность. так как максимальное количество баллов 10, то дельта будет равна 10, то есть по теореме Пифагора sqrt (100 + 100) = 14.14 — это и есть максимальное различие, при которым наборы данных можно считать противоположными. Таким образом, у Коли и Васи в данном случае больше различий, нежели сходства.
И зачем это все?
Применения можно найти где угодно. Сайты знакомств, сайты по фрилансу, сайты вакансий и т.д. Создавая опросники можно создать некоторую карту интересов и вкусов по которой можно находить пары для отношений. Любовных, дружеских, трудовых, любых.
Реализуем на примере картографирования интересов людей. И сразу протестируем, на примере моих друзей.
Использовать будем python, так как данный ЯП наиболее подходит для реализации подобных алгоритмов. В первую очередь из-за удобства работы со словарями (хэши/ассоциативные массивы), а также благодаря шикарному встроенному модулю pickle, который позволит нам сохранять словари с вопросами-ответами прямо на диск и потом использовать. По традиции, весь код можно будет посмотреть в конце статьи
Для расчета метрики будем использовать следующий код:
def calc(nPoint):
result = 0.0
print("sqrt(", end="")
for key in Dictionary:
print("(", Points[nPoint[0]][key], " - ", Points[nPoint[1]][key], ")^2 + ", sep="", end="")
result = result + math.pow((Points[nPoint[0]][key] - Points[nPoint[1]][key]),2)
print(")")
result = math.sqrt(result)
return result
Функция принимает кортеж из двух чисел, которые говорят какие наборы данных анализировать (наборы данных хранятся в словаре словаря, где ключи — номер набора), которые находятся в словаре Points.
Функция возвращает коэф. различия двух наборов.
Для того, чтобы «картографировать» интересы нам надо проанализировать каждые наборы, а не только два. Для этого есть функция:
def GenerateMap():
print("~~~~")
for i in range(1, PSize):
for j in range(i + 1, PSize + 1):
print(i, " and ", j, " = ", calc( (i, j) ), sep="")
Функция генерирует карту отношений наборов и выводит в stdout.
Тестирование скрипта на людях
Охохо, как звучит. Теперь поиграемся. Составим данный список вопросов:
1) Насколько вам интересны политические новости в мире? (0-не интересны, 10- интересны)
2) Как сильно вы интересуетесь архитектурой(0-не интересуюсь, 10 сильно интересуюсь)
3) Насколько сильно вам нравятся фильмы ужасов?(0-не нравятся , 10-очень нравятся)
4) Насколько сильно вам нравятся научные статьи?(0-не нравятся , 10-очень нравятся)
5) Ваши интересы к биологическим наукам? (0-не интересуюсь, 10 сильно интересуюсь)
6) Ваши интересы к истории? (0-не интересуюсь, 10 сильно интересуюсь)
7) Ваши интересы к противоположному полу? (0-не интересуюсь, 10 сильно интересуюсь)
8) Ваши интересы к чтению? (0-не интересуюсь, 10 сильно интересуюсь)
9) Ваши интересы к химии? (0, 10)
10) Ваши интересы к психологии? ( 0, 10)
11) К программированию (0, 10)
12) К физике (0, 10)
13) Любите ли вы самообразование(0, 10)
И дадим на них ответить каждому пользователю, создав набор данных. Сразу скажу, в программе набор данных номеруется по мере их загрузки через pickle. Поэтому и выводится, соответственно номера в формате (номер — номер = коэф. различия).
Для удобства чтения я их вручную перепечатал в фамилии, заменив для статьи на рандомные (согласие на обр. данных было получено не от всех).
Запустив картографирование получаем следующее:
Иванов - Семенщенко= 11.83
Иванов - Кириллов= 12.72
Иванов - Козлов = 12.92
Иванов - Азарова = 12.88
Иванов - Петрова = 16.49Семенщенко- Кириллов= 9.59
Семенщенко- Козлов = 8.77
Семенщенко- Азарова = 10
Семенщенко- Петрова = 14.28
Кириллов- Козлов = 10.34
Кириллов- Азарова = 13.85
Кириллов- Петрова = 12.4
Козлов - Азарова = 12.68
Козлов - Петрова = 14.93
Азарова - Петрова = 17.66
Как это интерпретировать? Давайте посмотрим, всего вопросов было у нас 13. Максимальное количество баллов — 10
Тогда по теореме Пифагора найдем наибольшее возможное расстояние в окретности 13-мерного пространства:
sqrt (100×13) = 36,056
Среднее значение = максимальное / 2 = 16.03
Таким образом, мы видим что в основном у нас с друзьями больше общего (это и логично).
И только рейтинг различия между Азаровой и Петровой показывает, что эти два моих друга (подруги) наиболее различны в своих интересах, так как их коэф. равен 17.66, что больше среднего значения.
Вместо заключения
Таким образом, данный способ можно использовать для ранжирования пользователей по их интересам на сайтах знакомств. Мы видим, что чем больше вопросов, тем точнее сравнение личностей. Создав, допустим, при регистрации опросник из 100 вопросов и составив карту для небольшой социальной сети (так как объем памяти для этого метода растет линейно с приростом пользователей) можно рекомендовать людей для общения/знакомства.
#!/usr/bin/python
import sys
import pickle
import math
Dictionary = []
Points = {}
PSize = 0
def DictGen():
print("~~~~")
DictList = []
print("For exit enter a \"0\"")
while True:
s = str(input("> "))
if (s == "0"):
break;
else:
DictList.append(s)
print("Enter a name for new list of keys: ")
fname = str(input("> "))
with open(fname, 'wb') as f:
pickle.dump(DictList, f)
print("Saved with name ", fname, sep = "")
def DictLoad():
print("~~~~")
fname = str(input("Enter a name of list to load\n> "))
with open(fname, 'rb') as f:
Dictionary.clear()
Dictionary.extend(pickle.load(f))
def NewPoint():
print("~~~~")
if (not Dictionary):
print("List of keys not loaded (command 2)")
else:
LocalPoint = {}
for key in Dictionary:
print(key, ": ", sep="", end="")
mark = float(input())
LocalPoint[key] = mark
print("Enter a name for new point: ")
fname = str(input("> "))
with open(fname, 'wb') as f:
pickle.dump(LocalPoint, f)
print("New point saved with name ", fname, sep="")
def LoadPoint():
print("~~~~")
fname = str(input("Enter a name of point to load\n> "))
with open(fname, 'rb') as f:
LocalPoint = pickle.load(f)
Points[PSize] = LocalPoint
def calc(nPoint):
result = 0.0
print("sqrt(", end="")
for key in Dictionary:
print("(", Points[nPoint[0]][key], " - ", Points[nPoint[1]][key], ")^2 + ", sep="", end="")
result = result + math.pow((Points[nPoint[0]][key] - Points[nPoint[1]][key]),2)
print(")")
result = math.sqrt(result)
return result
def GenerateMap():
print("~~~~")
for i in range(1, PSize):
for j in range(i + 1, PSize + 1):
print(i, " and ", j, " = ", calc( (i, j) ), sep="")
while True:
print("0 - exit")
print("1 - generate a list of keys")
print("2 - load a map of marks")
print("3 - add a new point in dimension")
print("4 - load a new point in dimension")
print("5 - calculate distance from two points of dimension")
print("6 - print information")
print("7 - create a map with distance for every point")
i = int(input("#-> "))
if (i == 0):
sys.exit()
elif (i == 1):
DictGen()
elif (i == 2):
DictLoad()
elif (i == 3):
NewPoint()
elif (i == 4):
PSize = PSize + 1
LoadPoint()
elif (i == 5):
print("Enter a two numbers of which points you want to calculate a distance")
nPoint = tuple(int(x.strip()) for x in input().split(' '))
print("Difference: ", calc(nPoint), sep="")
input()
sys.exit()
elif (i == 6):
print("Dictionary", Dictionary, sep = ": ")
print("Points: ", Points, sep = ": ")
print("Total points: ", PSize, sep = "")
elif (i == 7):
GenerateMap()
else:
print("Unknown command")
sys.exit()
