Разработка метамодели с помощью Eclipse Modeling Framework (и немного про моделирование данных)

Это вторая статья цикла, посвященного разработке, управляемой моделями. Сегодня мы создадим метамодель, основанную на метаметамодели Ecore. Вскользь затронем моделирование данных, а именно Anchor, 6НФ и концептуальное моделирование.
Введение
Вы можете пролистать предыдущую статью про OCL и метамоделирование, но это не обязательно. Достаточно только этих тезисов:
- Есть различные объекты реального мира (люди, организации, события, здания, банковские счета, звезды, планеты, деревья, музыкальные произведения и т.д.).
- В некоторой информационной системе мы можем обрабатывать различные сведения об этих объектах.
- Сведения соответствуют некоторой модели. Модель может быть более или менее формализованная, явная или неявная, может описывать различные аспекты объектов реального мира, сама является объектом реального мира. Например, некоторая диаграмма классов UML – это модель.
- Модель строится в соответствии с некоторой метамоделью, языком моделирования (например, UML).
- Метамодели строятся в соответствии с метаметамоделями (например, Ecore, MOF).
Более развернуто эти тезисы описал консорциум OMG (Object Management Group) в архитектуре, управляемой моделями (Model-driven architecture).
После прочтения данной статьи вы научитесь создавать собственные метамодели (языки моделирования).
Выбор метамодели для реализации
Сначала нужно решить какую метамодель мы будем реализовывать.
Искусственные метамодели, созданные исключительно для примера, слишком бесполезные.
Модели сущность-связь, сети Петри и т.п. слишком простые и неинтересные.
Какой-нибудь PMML интересный, но слишком сложный.
Можно было бы реализовать Charity с помощью EMF. Наверное, это было бы очень интересно (представьте себе язык программирования, в котором всё описывается с помощью коммутативных диаграмм), но бесполезно.
На мой взгляд, золотая середина – это Anchor. На примере этого языка мы поймаем сразу множество зайцев:
- Научимся создавать метамодели.
- Познакомимся с одной из альтернатив диаграммам сущность-связь.
- Может быть сломаем некоторые стереотипы о нормализации данных.
- Вскользь затронем концептуальное моделирование.
Отступление про то зачем нужны ещё какие-то языки моделирования данных
Когда я устраивался на последнюю работу, на собеседовании я рассказывал какое замечательное хранилище и кубы я сделал на предыдущей работе, рассказывал, что это практически полностью избавило людей от ручных расчетов. А меня спросили: что будет с этим хранилищем и кубами, если схема данных изменится? Ведь если менять при этом структуру хранилища и кубы, то мы не сможем получать отчеты за прошлые периоды, основанные на старой схеме данных. Я ответил что-то типа того, что мы очень тщательно продумывали схему данных и существенных изменений в ней не будет, максимум в неё что-то добавится, ну, а если будут более серьезные изменения, то с этим ничего не поделать.
Спустя некоторое время я понял, что эта задача безболезненного изменения схемы данных совершенно тривиальна. Достаточно просто выбрать правильную методику моделирования данных. Если строить хранилище на основе 3НФ-5НФ, то, действительно, малейшие изменения в схеме данных всё ломают. Если же нормализовывать данные до 6НФ, то никакие изменения не затронут уже хранящиеся в базе данные.
На идеях нормализации данных до 6НФ в той или иной степени основаны Data Vault и Anchor. Надеюсь, этого отступления достаточно, чтобы заинтересовать вас Anchor.
Примечание
На самом деле, и это не вершина моделирования данных, есть некоторые вещи, которые не учтены в этих подходах. Но учтены, например, в нашей методике моделирования, но об этом вы узнаете, если устроитесь к нам работать ;-)
Отступление про историю моделирования данных
Прежде чем наконец перейти к Anchor немного истории (пожалуйста, отнеситесь к ней критически и с иронией).
В 1970-х было много исследований в области моделирования данных. Один из не плохих подходов, который был придуман в те годы – это объектно-ролевое моделирование. Это была альфа и омега моделирования данных, практически вершина, после которой началась история деградации в этой области. Не буду детально описывать этот подход. В двух словах, данные там описываются в виде фактов, но не «субъект-предикат-объект» как в RDF, а в виде кортежей с произвольным количеством объектов.
К сожалению, не все в те годы осознали гениальность OR-моделирования, поэтому в 1976 Питер Чен опубликовал статью, в которой описал модель сущность-связь. ER-модели отличаются от OR-моделей тем, что в них нет фактов, но есть атрибуты. Это очень существенное отличие.
"ER Diagram MMORPG" by TheMattrix at English Wikipedia. Licensed under CC BY-SA 3.0 via Commons.
В OR-модели набор фактов, относящихся к объекту может быть достаточно произвольным. Например, мы можем сформулировать факты «Сотрудник №1 – имеет имя – Иван» или «Сотрудник №1 – родился в – 1990 год». Или даже более сложные: «Сотрудник №1 – получил степень – доктор наук – в – 2010 год». Но это совершенно не значит, что мы всегда должны для сотрудника указывать имя и год рождения, причем, именно в этом порядке, как и не значит, что мы не можем сформулировать ещё какие-то факты о сотруднике.
В ER-модели при переходе от фактов к атрибутам такая гибкость/открытость модели исчезает, мы начинаем моделировать фиксированные структуры, описывающие фиксированный набор фактов, зашитый в атрибуты, упорядоченные определенным образом.
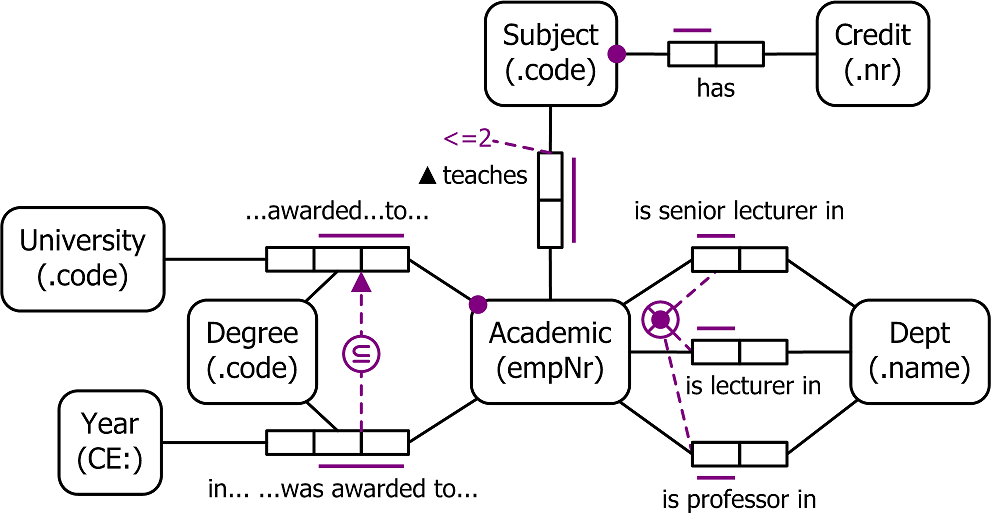
Обратите внимание на то, что в ER-моделях в нотации Питера Чена связи изображаются ромбиками, а атрибуты овалами. Причём, связи могут быть не только бинарными.
В 1981 в рамках предложенной ВВС США программы дальнейшей деградации моделирования данных компьютеризации промышленности (ICAM) был разработан IDEF1, в котором атрибуты перешли внутрь сущностей, а связи из ромбиков превратились просто в линии. Причем, в результате коварного заговора американских военных у многих людей модель сущность-связь ассоциируется именно с IDEF1, а не с ER-моделью Питера Чена.
"B 5 1 IDEF1X Diagram" by itl.nist.gov — Integration Definition for Information Modeling (IDEFIX) — 93 Dec 21. Licensed under Public Domain via Commons.
Позже возникло ещё множество языков и методов, позволяющих моделировать данные, включая UML, RDF, XSD, Anchor, всякие NoSQL. Но чего-то революционно нового во всём этом нет. Это, кстати, хороший пример того, что в ИТ не нужно гоняться за какими-то модными свистелками, большая часть вещей уже давно придумана и просто оборачивается маркетологами в новую обертку.
Отступление про Anchor
Итак, мы дошли до Anchor. Хотя этот язык и отличается от привычного всем IDEF1X или диаграмм классов UML, фактически это просто калька с более древней ER-модели Питера Чена, о которой, возможно, многие уже забыли. Перечислим основные отличия.
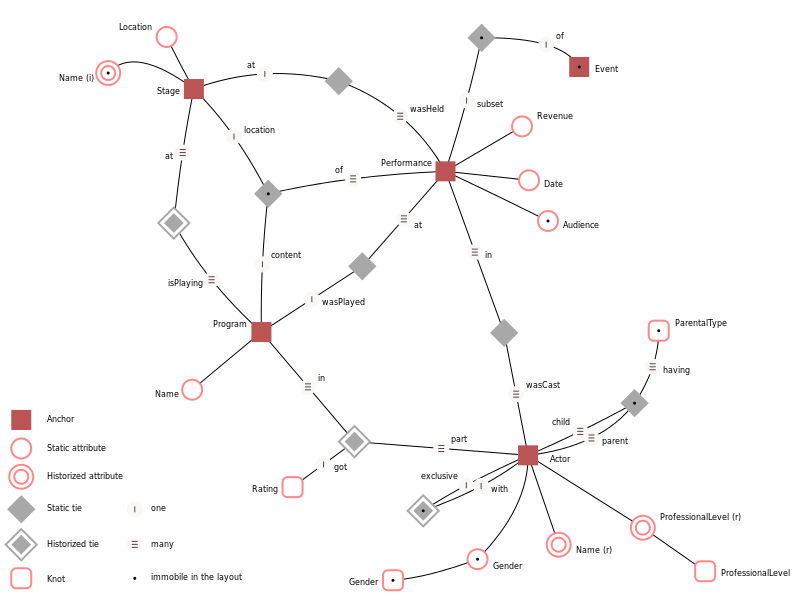
"Anchor Modeling Example" by Lars Rönnbäck — http://www.anchormodeling.com. Licensed under MIT via Commons.
В Anchor сущности (entity) переименованы в якори (anchor), связи (relationship) переименованы в скрепы (tie – наверное их тоже можно называть связями, но слово «скрепа» добавляет этой модели шарма), атрибуты (attribute) оставлены без изменений.
В ER-модели у атрибутов есть представления (representation). В Anchor их называют более привычно – тип данных (data type).
В ER-модели у представлений можно дополнительно ограничивать область допустимых значений (allowable values). В Anchor тоже можно ограничивать область значений, но не произвольным образом, а перечисляя допустимые значения. Такие перечислимые типы в Anchor называют узлами (knot). Забегая вперед, далее мы немного разовьем Anchor в этом плане.
Вряд ли перечисленные отличия между ER-моделью и Anchor можно считать существенными. Пока Anchor напоминает ребрендированную идею 40-летней давности.
Пожалуй, более существенное отличие – это атрибуты и связи с сохранением истории (historized attribute и historized tie). Хотя в ER-модели они отсутствуют, но вообще в них тоже нет чего-то принципиально нового.
Может возникнуть вопрос: если Anchor на столько вторичен, то зачем он вообще нужен, в чём его преимущества по сравнению с другими подходами?
Ответ очень простой. Anchor позволяет немного иначе взглянуть на нормализацию данных. Раньше нормальные формы рассматривались в основном с точки зрения аномалий в данных. При этом 6НФ выглядела каким-то сферическим конём в вакууме, который возможно представляет интерес с теоретической точки зрения, но практически бесполезен. С появлением подходов типа Anchor или Data Vault стало ясно, что нормализация данных важна не только с точки зрения устранения аномалий, но и с точки зрения эволюции схемы данных. В такие схемы проще вносить изменения, ничего при этом не ломая.
Создание проекта
На сайте есть замечательный редактор Anchor-моделей. Мы попробуем сделать аналогичный редактор, основанный на Eclipse Modeling Framework.
Примечание
Точнее, в этой статье мы сделаем упрощенный (древовидный) редактор. В следующей статье сделаем уже полноценный редактор диаграмм. А из совсем следующих статей станет ясно зачем мы всё это делаем. Конечно, чтобы научиться создавать языки моделирования, но не только.
Итак, если хотите попробовать всё на практике, то скачайте и распакуйте Eclipse Modeling Tools.
Создайте новый «Ecore Modeling Project». Назовите его «anchor». На вкладке «Select viewpoints» выберите «Design».
В ecore-файле будет храниться наша метамодель. В aird-файле будет храниться диаграмма для метамодели. Если вы прочитали предыдущую статью, то должны понимать, что модель и диаграмма модели – это разные вещи. Наконец, в genmodel-файле хранится модель генерации исходного кода из нашей метамодели. В ней задаются различные правила генерации кода, в частности, в какую папку его нужно складывать и т.п.
Примечание
Здесь и далее я иногда буду называть метамодель моделью. В этом нет никакого противоречия, метамодель сама является моделью. Равно как и метаклассы являются классами с точки зрения метаметамодели.
Если лень создавать проект, можете взять готовый.
Создание основных метаклассов
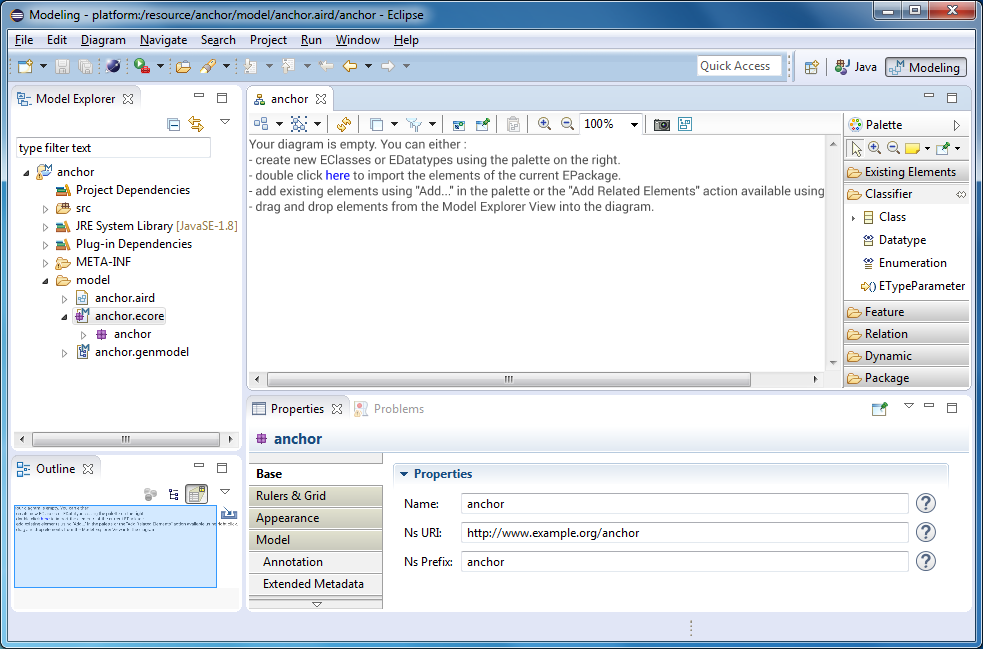
Теперь необходимо описать метаклассы (виды сущностей, которые могут быть в наших Anchor-моделях). Добавьте на диаграмму класс и назовите его Anchor. Добавьте ему атрибут name с типом данных EString. В поле Lower Bound укажите 1.
Добавьте ещё один класс, назовите его Attribute. Скопипастьте ему атрибут name.
В Anchor-моделях якоря и атрибуты можно связывать друг с другом. Поэтому в нашей метамодели мы должны создать связь между якорем и атрибутом. Связь должна быть композицией (composition), потому что атрибуты не могут существовать сами по себе, они всегда принадлежат якорю и причём одному.
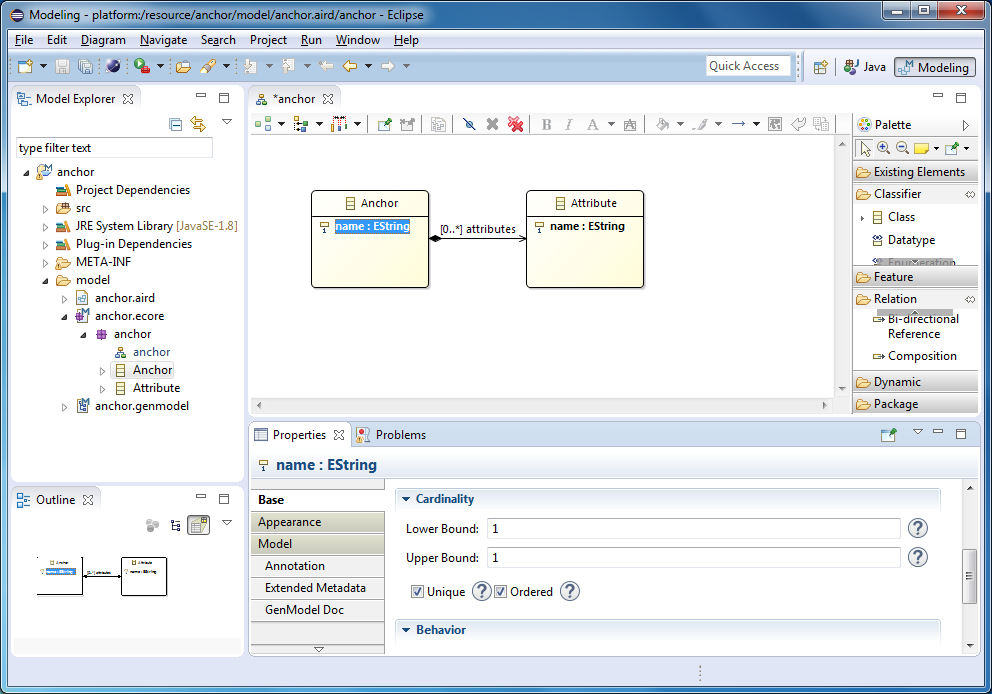
Примечание
Есть разные подходы к именованию отношений. Данное отношение между якорем и атрибутом можно назвать: attribute, attributes, ownedAttribute или ownedAttributes. Отношение один-к-одному нужно однозначно называть в единственном числе. Отношение один-ко-многим иногда называют в единственном, иногда во множественном числе. Если отношение является композицией, то иногда к имени добавляют префикс owned. Это значит, что атрибут принадлежит якорю.
Важно, чтобы в модели использовалась одна схема именования. Я буду использовать вторую.
Генерация редактора модели
Итак, упрощенный набросок метамодели у нас уже есть. Теперь создадим модель в соответствии с этой метамоделью. Для этого необходимо сгенерировать исходный код для плагина, который мы запустим в Eclipse и который позволит нам работать с моделью.
Откройте anchor.genmodel. В свойствах множество разных настроек. Можно оставить их без изменений, но обычно папка для сгенерированного кода изменяется с src на src-gen, чтобы разделять код написанный вручную от сгенерированного. К слову, в нашем проекте вообще не будет кода, написанного вручную.
В контекстном меню выберите «Generate Model Code», после чего в папке src (или src-gen) появится Java API для работы с нашими Anchor-моделями. В рамках данной и последующих статей нам не потребуется ни заглядывать в этот код, ни править его.
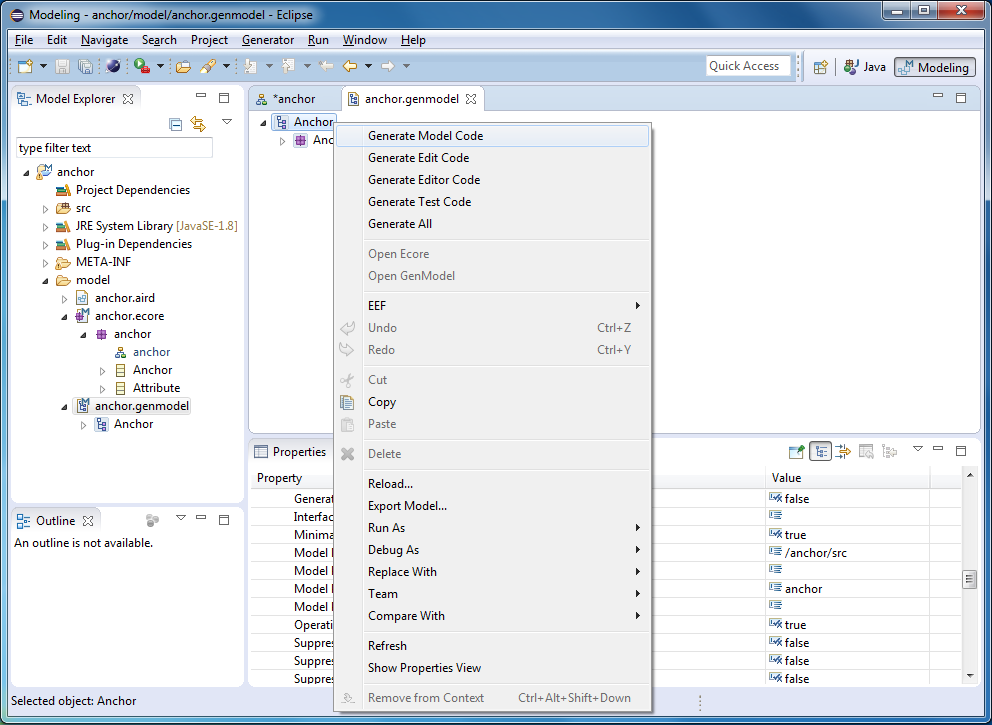
Запустите «Generate Edit Code» и «Generate Editor Code». Таким образом вы создадите два дополнительных проекта: 1) некоторую прослойку между объектной моделью нашего языка моделирования и редактором и 2) древовидный редактор моделей.
До кучи создайте тестовый проект с помощью команды «Generate Test Code». Мы не будем писать модульные тесты, однако в этом проекте вы можете увидеть примеры использования API, сгенерированного для нашей метамодели. Также в этом проекте мы будем создавать тестовые модели.
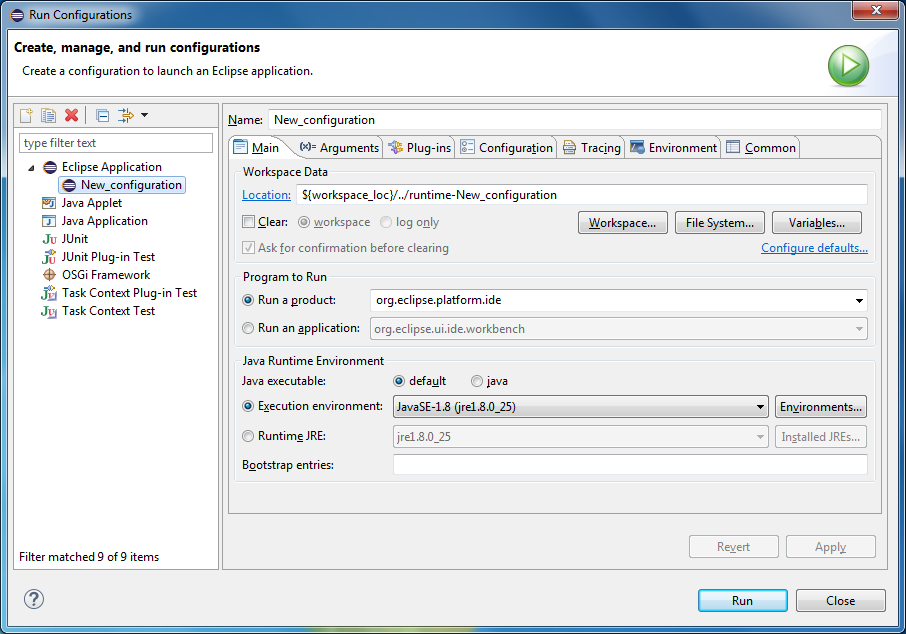
Переключитесь на Java-перспективу (Window -> Perspective -> Open Perspective).
Выберите Run -> Run Configurations… В разделе Eclipse Application создайте новую конфигурацию и запустите её.
Импортируйте в запущенный экземпляр Eclipse проект anchor.tests (File -> Import… -> General -> Existing Projects into Workspace). Откройте перспективу моделирования (Window -> Perspective -> Open Perspective -> Modeling). Создайте в проекте новую папку model (File -> New -> Folder). Создайте в папке Anchor-модель (File -> New -> Other…).

На последней вкладке мастер создания модели спросит какой объект использовать в качестве корневого (поле Model Object). Корневой объект мы пока не создали, поэтому выберите Anchor.
На вкладке свойств укажите какое-нибудь имя якоря, добавьте атрибуты.

Создание корневого объекта модели
Пока наш редактор позволяет описывать только один якорь с атрибутами. Чтобы в модели могло быть несколько якорей, сделайте следующее.
Закройте второй экземпляр Eclipse, в первом экземпляре откройте перспективу Modeling. Откройте файл anchor.ecore. Добавьте в метамодель метакласс Model.

Добавьте созданному метаклассу EReference с именем anchors. В поле EType выберите Anchor. Lower Bound задайте 1, Upper Bound задайте -1 (произвольное количество). В поле Containment укажите истинное значение (это значит, что якори будут принадлежать модели).
Теперь создайте обратную ссылку от якоря к модели. Это не обязательно, но понадобится в следующей статье. Для этого у метакласса Anchor создайте ссылку с именем model и типом Model. В поле EOpposite выберите обратную ссылку anchors. В поле Lower Bound укажите 1.
Примечание
Наверняка вы заметили, что древовидный редактор метамодели очень похож на редактор, который вы только что сгенерировали. Разве что выглядит немного симпатичнее благодаря иконкам. Дефолтные иконки лежат в проекте anchor.edit в папке icons. Другие иконки можно взять отсюда. Они немного кривые, потому что сгенерированы из svg, но идею вы поняли.
Сохраните метамодель. Откройте диаграмму в файле anchor.aird. Добавьте на диаграмму метакласс Model (на палитре инструментов справа в разделе Existing Elements выберите Add). Обратите внимание на то, что на диаграмму также добавилась двунаправленная связь с метаклассом Anchor, которую вы создали в древовидном редакторе.
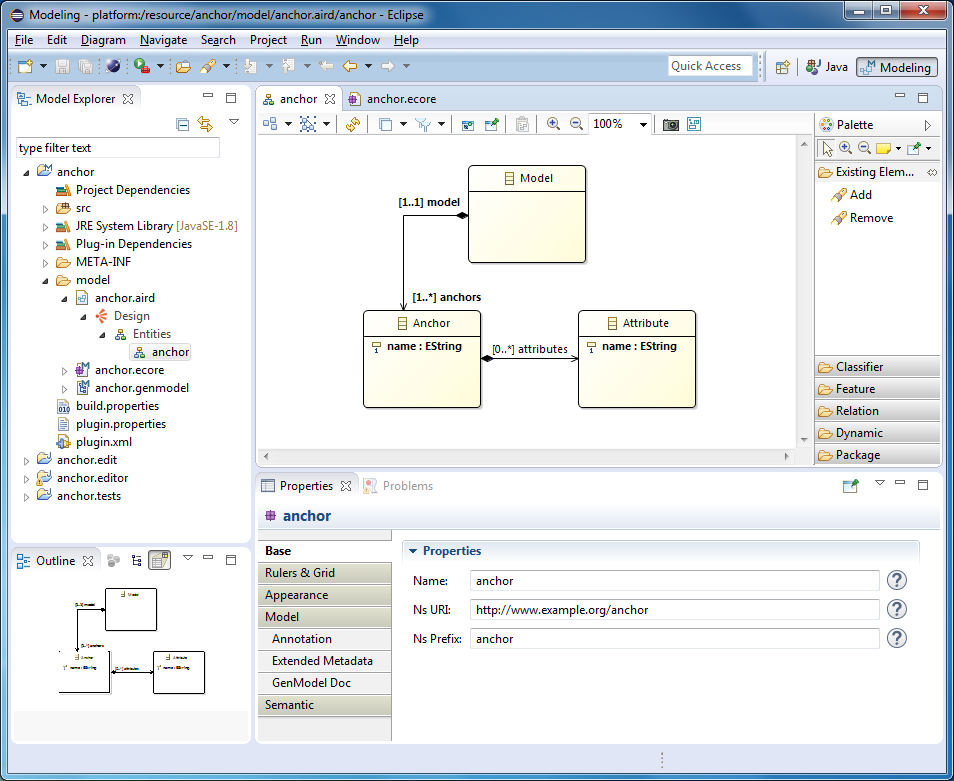
Генерация плагина
После изменения метамодели не забудьте перегенерировать исходные коды во всех проектах. Теперь вместо запуска второго экземпляра Eclipse сделайте следующее. В меню выберите File -> Export… -> Deployable plugin-ins and fragments.
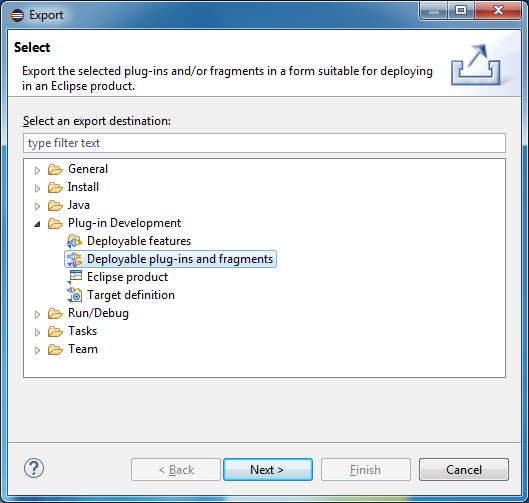
Отметьте все созданные проекты (по крайней мере, все кроме anchor.tests). Выберите Install into host. Repository. После развертывания плагина перезапустите Eclipse. Теперь редактор Anchor-модели будет доступен в этой рабочей области без запуска второго экземпляра Eclipse.
Также вы можете экспортировать плагин в какую-нибудь папку. Затем полученные jar-файлы можно скопировать в папку $ECLIPSE_HOME/dropins. После перезапуска Eclipse, в нём будет доступен ваш плагин.
Завершение создания метамодели
В общем-то, это всё, что необходимо знать о EMF для создания своих метамоделей. Теперь остаётся только добавить недостающие метаклассы.
Узнать какие ещё нужны метаклассы можно либо просто глядя на примеры Anchor-моделей, либо из статьи M. Bergholtz, P. Johannesson, P. Wohed «Anchor Modeling – Agile Information Modeling in Evolving Data Environments».
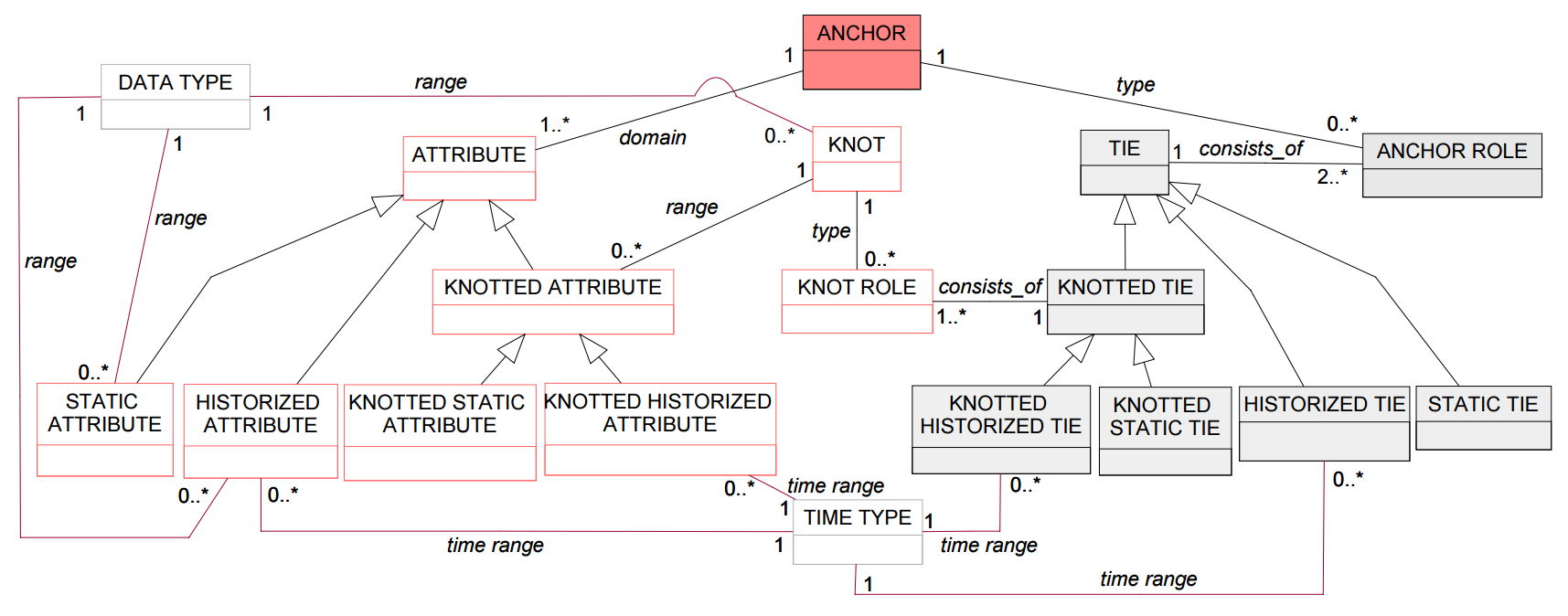
Если вы попробуете реализовать эту метамодель, то увидите, что некоторые вещи в ней можно сделать более оптимально, чем изображено на рисунке. Мы улучшим две вещи:
- Дублирующиеся свойства и отношения вынесем в отдельные классы.
- Немного усовершенствуем систему типов.
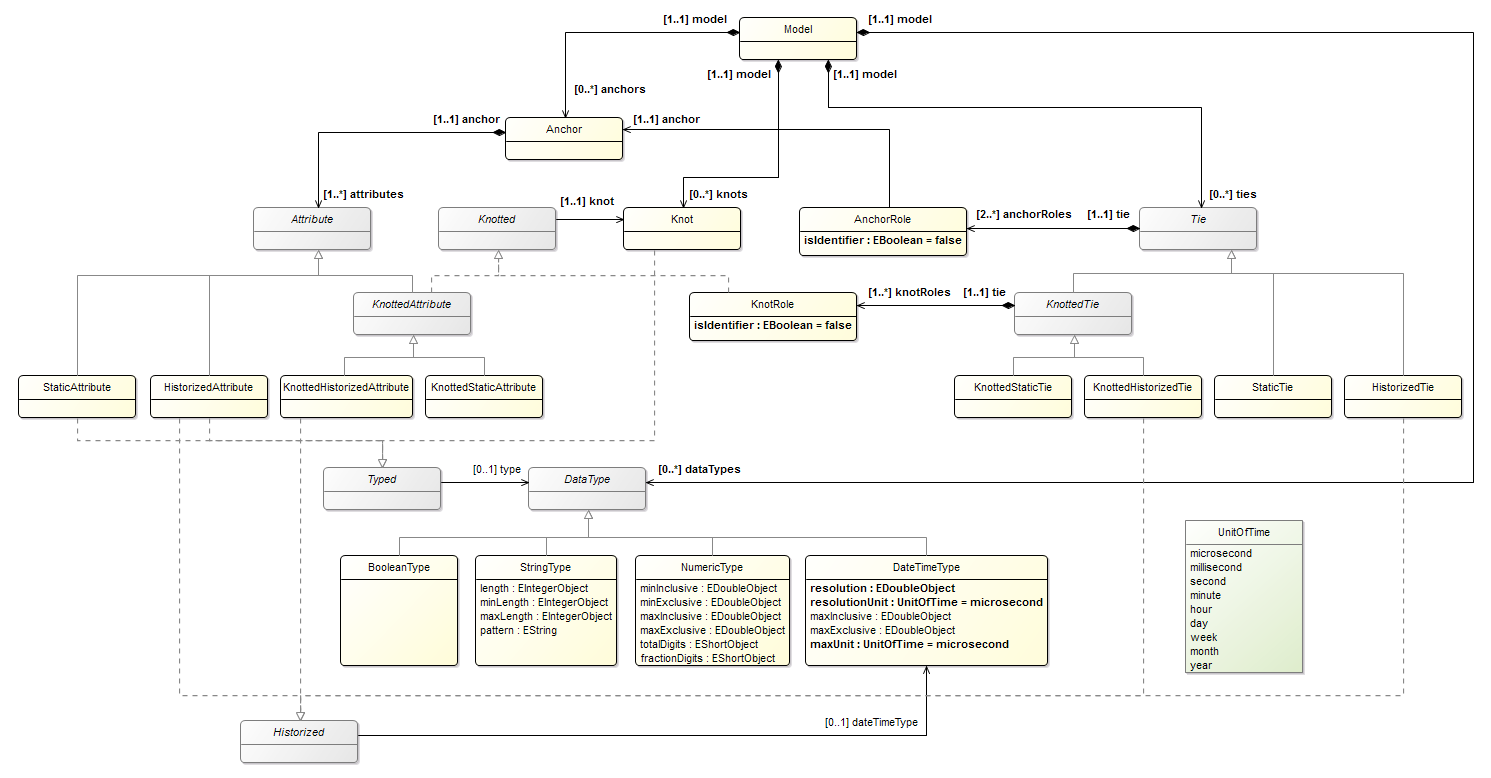
Примечание
На рисунке не изображён интерфейс Named, потому что с ним диаграмма станет совсем нечитаемой.
Для некоторых свойств используется тип EDoubleObject, а не просто EDouble, потому что эти свойства опциональные. Если задать для них тип данных EDouble, то по умолчанию для них будет устанавливаться значение 0, и будет невозможно понять действительно ли они установлены в 0 или они просто не указаны.
Рассмотрим наши усовершенствования подробнее.
Дополнение про абстрактные классы и интерфейсы
На исходной диаграмме классов выше видно, что для всех атрибутов и скреп с сохранением истории определено отношение с метаклассом TIME TYPE. Некоторые метаклассы связаны аналогичным отношением с метаклассом DATA TYPE. Также у многих метакслассов есть атрибут name, хотя он и не показан на рисунке.
Все эти одинаковые свойства и отношения можно вынести в соответствующие метаклассы Historized, Typed, Named и т.д. В Anchor-моделях не могут существовать экземпляры этих метаклассов, поэтому их нужно отметить как абстрактные.
Ecore допускает множественное наследование. И, например, HistorizedAttribute вполне может наследоваться от метаклассов Attribute, Typed и Historized. Однако, если вы загляните в Java API, которое сгенерировано для Ecore-метамодели с использованием множественного наследования, то увидите, что только один из базовых метаклассов будет реализован как Java-класс, а остальные будут реализованы как Java-интерфейсы (т.к. Java не поддерживает множественное наследование). Поэтому для однозначности желательно сразу в Ecore-метамодели отметить некоторые метаклассы как интерфейсы.
Дополнение про типы данных
Если вы посмотрите примеры Anchor-моделей на сайте, то обнаружите там типы данных вида varchar(42), money и т.п. Увидите, что в модели явно заданы типы данных для ключей. Лично меня такая привязка к физике очень удивила. Изначально Anchor производил впечатление достаточно концептуального языка моделирования, а оказалось, что модели привязаны к конкретной СУБД.
Мы устраним эту недоработку, добавив несколько абстрактных типов данных (вы видите их на рисунке выше), которые в последующих статьях будем транслировать в типы данных конкретной СУБД. Ну, в общем-то, забегая вперед, мы и создавали эту метамодель ради того, чтобы в следующих статьях показать возможности преобразования моделей. А то в комментариях на сайте Anchor я даже читал какой-то ад про генерацию SQL-запросов с помощью XSLT – это плохо.
Заключение
После прочтения этой статьи вы должны уметь создавать языки моделирования с помощью Eclipse Modeling Framework. Также, возможно, вы узнали что-то интересное из области моделирование данных.
В следующей статье я опишу как сделать уже не просто древовидный редактор, а редактор диаграмм.
