Разработка и тестирование модуля АСКУЭ
 АСКУЭ — Автоматизированные Системы Контроля и Учета Энергоресурсов. В задачи подобных систем входит сбор данных с приборов учета энергоресурсов (газ, вода, отопление, электричество) и предоставление этих данных в удобном для анализа и контроля виде.
АСКУЭ — Автоматизированные Системы Контроля и Учета Энергоресурсов. В задачи подобных систем входит сбор данных с приборов учета энергоресурсов (газ, вода, отопление, электричество) и предоставление этих данных в удобном для анализа и контроля виде.
Так как такие системы вынуждены иметь дело с множеством самых различных устройств и контроллеров, чаще всего они построены по модульному принципу. Не так давно меня попросили написать модуль для подобной системы, осуществляющий связь с одним из приборов учета (счетчик электрической энергии трехфазный электронный ЦЭ2753).
По ходу повествования Вам будут встречаться выделенные подобным образом комментарии. Единственная их цель — чтобы Вы не заснули в процессе знакомства со статьей.
Давно хотелось применить автоматизированное тестирование. Я посчитал, что сейчас как раз удобный случай. Почему я так решил?
Почему этот случай удобный для того, чтобы попробовать тестирование? Модуль не имел пользовательского интерфейса — только строго заданный API, который очень удобно тестировать. Сроки проекта были не слишком зажатые, поэтому у меня было время для экспериментов. Система АСКУЭ относится к классу промышленных систем и лишняя надежность ей не помешает. Сделав ставку на автоматизированное тестирование, я фактически удвоил количество кода, который требовалось написать. Забегая вперед скажу, что мне пришлось написать эмулятор прибора. Но в конечном итоге, я считаю, что дело того стоило.
Одним из интересных следствий явилось то, что я мог вести разработку без живого прибора — имея на руках только описание его протокола. Живой прибор, конечно, появился, но уже после того, как основной объем кода был создан.
Разработка велась в среде Delphi 7. Для автоматизированного тестирования использовалась библиотека DUnit. Система контроля версий — Mercurial. Репозиторий — BitBucket.
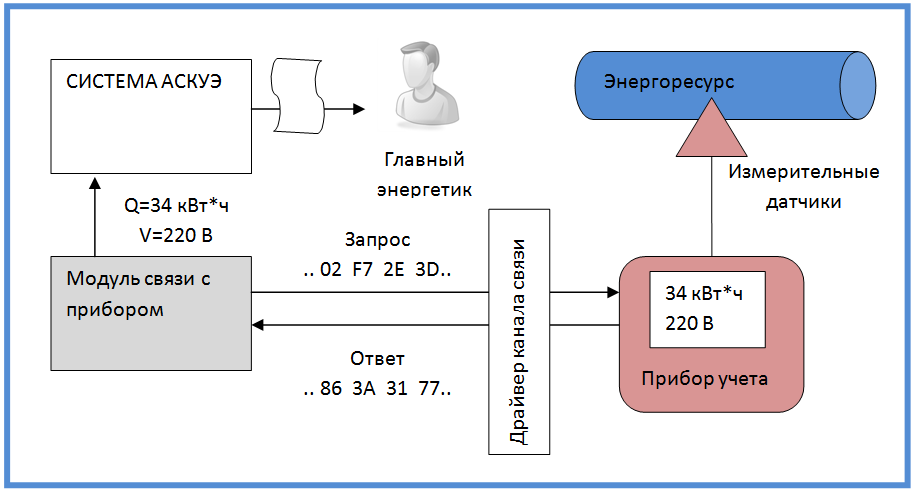
Немного подробнее о месте модуля в системе Основная задача модуля — общение с прибором учета по низкоуровневому протоколу, и предоставление результатов этого общения в виде, понятном системе АСКУЭ. Физическим каналом связи, как правило, является COM-порт с различного рода устройствами раширяющими его функциональность — модемы, преобразователи интрфейсов. Очень распространена связка RS-232/RS-485. Иногда возможен TCP/IP. За нюансы организации канала связи отвечают специальные модули АСКУЭ — драйверы канала.Что же касается самого протокола, то он в общем виде представляет собой последовательность запросов и ответов в виде набора байт. Почти всегда запросы и ответы сопровождаются контрольной суммой. Что-то более определенное сказать трудно. Наиболее характерным представителем подобного способа общения является спецификация MODBUS.
Протокол MODBUS — это удел серых и унылых людей. Если Вы — яркая и творческая личность, Вы, конечно, не воспользуйтесь надежным и проверенным решением, а придумайте свой собственный ни на что не похожий вариант протокола. И в этом случае отдел маркетинга осторожно напишет в рекламной брошюре, чтобы не отпугнуть будущих покупателей прибора, что прибор общается по MODBUS-подобному протоколу. Хотя конечно — ни о какой совместимости с MODBUS речи быть не может.
Внутренняя структура модуля Привожу внутреннюю структуру модуля, которая получилась в результате нескольких итераций разработки и рефакторинга. Можно заметить, что особой оригинальностью она не отличается.Основной объект Device, содержит код, который отвечает за общие действия с прибором, а также за возвращение данных АСКУЭ в нужном формате.
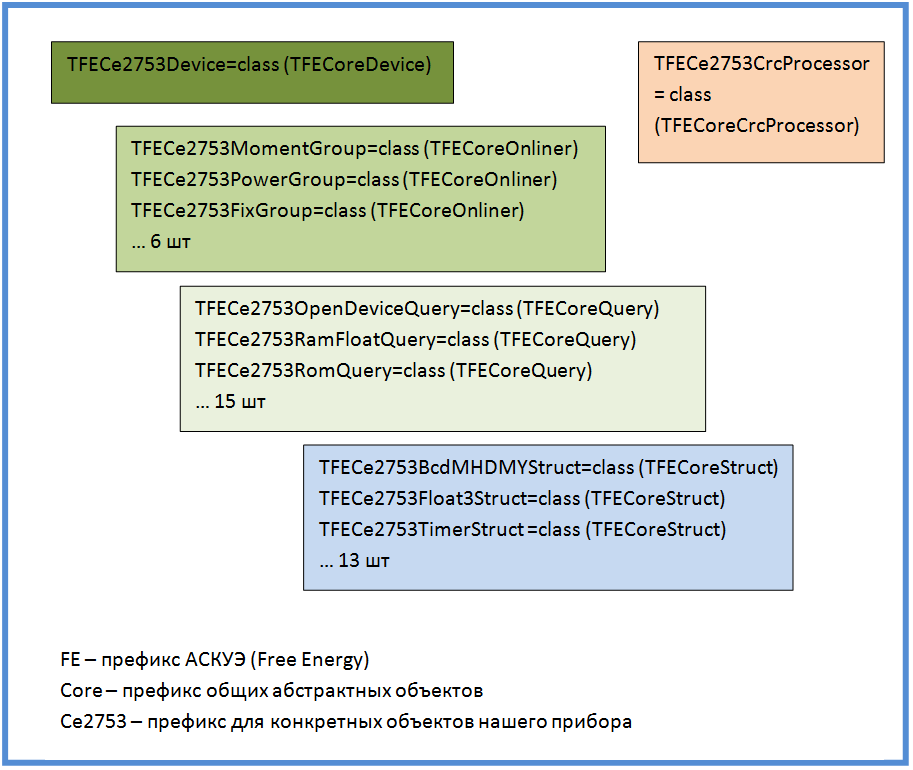
Объект Device владеет несколькими объектами Onliner. Каждый Onliner отвечает за полностью завершенный сеанс общения с прибором. Различные типы онлайнеров отвечают за различные типичные действия с прибором. Самое распространенное — это опрос группы параметров. В случае моего прибора было шесть групп параметров, каждой из них соответствовал свой Onliner.
В своей работе Onliner использует объекты Query. Объект Query отвечает за единичный цикл запроса-ответа. Результатом работы объекта Query является конкретная полученная из прибора порция информации, приведенная к удобному для использования виду. Кроме того, объект Query распознает некорректные и битые ответы прибора, и при необходимости повторяет запрос. Эта логика скрыта на уровне Query и Onliner не беспокоится по этому поводу.
Самый нижний уровень — это объекты Struct. Они отвечают за преобразование различных низкоуровневых байтовых форматов в значения, используемые в языке программирования. На вход объекта Struct подается поток байт — на выходе — значения типа Integer, Float, String. Иногда (можно считать почти всегда) объекту Struct приходится делать нетривиальные вещи. Таким образом на уровне Struct инкапсулирована вся математическая работа по сериализации и десериализации данных. Он скрывает все нюансы этого нелегкого труда от вышестоящих объетов.
На схеме также выделен объект CrcProcessor. В соответствии со своим названием он отвечает за подсчет контрольной суммы. Дело не такое простое, как кажется на первый взгляд.
Ниже я немного подробнее остановлюсь на пребразовании данных (Struct) и подсчете контрольных сумм (CrcProcessor), так как тема интересная и есть о чем поговорить.
Форматы данных в приборах учета Трудно назвать какой-либо способ кодирования информации, который Вам не встретится в запросах и ответах приборов учета.Самый безобидный — целый тип. Целым типом кодируются всевозможные адреса, указатели, счетчики, иногда целевые параметры тоже могут быть целого типа. Конкретный целый тип отличается длиной в байтах и последовательностью передачи этих байт по каналу.
Математика, а точнее ее тщательно разработанный раздел — комбинаторика, задает строгое ограничение количеству перестановок объектов (n!). Например, три байта можно расставить по порядку всего 6-ю способами. Этот непреодолимый (если не обращатся к квантовым вычислениям) теоретический предел очень огорчает создателей протоколов приборов учета. Если бы 3-байта можно было переслать 20-ю различными способами, я думаю рано или поздно Вы столкнулись бы с каждым из них.
Тип с фиксированной точкой — на мой взгляд самый удачный для приборов учета. Идея в том, чтобы передавать по каналу целое значение, с оговоркой, что потом десятичную точку нужно сдвинуть на несколько разрядов влево. Очень хороший и правильно ведущий себя при различных преобразованиях тип. Настолько хороший, что его используют, как стандарт в банковских вычислениях. (Если кто знает есть в VisualBasic тип Currency — он устроен как раз таким образом).
Так как базовый тип — целый, нельзя расслабляться, и забывать про комбинаторику и порядок байт.
Конечно, во всех отношениях, доставляющий массу проблем — тип с плавающей точкой. Рецепт один — досконально разобраться, что в нем что значит, где это расположено, и какие могут быть варианты. И опять же — помните про порядок байт.
Надеяться на то, что тип с плавающей точкой случайно совпадет по внутреннему представлению с одним из стандартных типов Вашей платформы — это верх безалаберности. Если Вас посещают такие мысли, Вам стоит заняться не программированием, а менее рискованным ремеслом — игрой в рулетку, покупке лотерейных билетов, ставками на чемпионат мира по футболу.
Самые интересные варианты возникают при попытке передать по каналу связи метки времени. Различные части даты и времени передаются в самых произвольных форматах.
Порядок следования года, месяца, числа, часа, минуты, секунды уверенно стремится все к тому же теоретическому пределу (n!). Еще можно сказать пару слов про год. Так как проблема 2000 года никого ничему не научила, в большинстве случаев год передается двумя цифрами.
Очень часто поток байт передаваемый по протоколу является прямым дампом внутренней памяти различных микросхем (таймеров, АЦП, портов, регистров).
Ребята, создающие микросхемы, знают толк в рачительном использовании каждого бита. Так что будьте готовы к тому, что Вам придется вырезать и вставлять отдельные биты и наборы бит из произвольных мест, склеивать их, накладывать маски, сдвигать в различных направлениях и делать еще массу вещей, без которых работа настоящего программиста была бы чередой безликих дней, похожих друг на друга.
Большинство форматов я отметил, но это далеко не все тонкости. В любой, самый неожиданный момент, могут быть применены спецприемы, выводящие общение по протоколу на совершенно новый уровень. Например, может быть применена такая экзотика, как BCD (двоично-десятичный формат) или передача чисел ASCII-символами. Бывают случаи, когда части одного значения пересылаются в различных запросах (например для получения целой части значения Вам нужно послать один запрос к прибору, для получения дробной — другой).
Единственное с чем я не встретился — это передачей национальных символов в формате UTF. Но я думаю, тут дело не в доброй воле, а в том, что работа с UTF — дело ресурсоемкое, а ресурсы микроконтроллеров ограничены.
Если Вы думайте, что все вышесказанное — это результат моего огромного опыта работы с несколькими сотнями приборов — то вынужден это опровергнуть. Почти все это мне встретилось в приборе учета, для которого я писал модуль. Тем, кто не верит, я могу выслать паспорт на прибор и описание протокола. Вы убедитесь, что все, что я написал — чистая правда.
Подсчет контрольной суммы С контрольной суммой, как я уже сказал выше, тоже не все так просто, как может показаться на первый взгляд. Несмотря на то, что существуют вполне устоявшееся термины CRC8, CRC16, CRC32, четкого понимания, как должна считаться контрольная сумма они не дают. И поэтому всегда возникают нюансы. Сами создатели протоколов связи это знают и в описании протокола не указывают ссылку на стандарт, а приводят кусок кода (!!!), как правило на Cи, который показывает, как именно должна считаться контрольная сумма.Я бы не рекомендовал выносить расчет CRC в общие библиотеки. Даже если для нескольких случаев алгоритмы совпадут, когда-нибудь Вы встретитесь с вариантом, который полностью перевернет ваши представления о подсчете CRC. Советую для каждого прибора делать свой алгоритм, даже если при этом придется пойти на небольшой Copy-Paste.
В случае моего прибора, почему-то первый байт запроса не должен входить в последовательность для подсчета CRC. Большой удачей я считаю, что обратил внимание, на коротенькое примечание в описании протокола. Потому что иначе мне так и не удалось бы установить связь с прибором. Судя по всему, я столкнулся с деятельностью секты свидетелей непогрешимого первого байта. По-другому я все это объяснить не могу.
Схема тестирования модуля
Внутреннее устройство модуля и некоторые особенности его разработки я описал, теперь привожу схему тестирования модуля. Схема не повторяет структуру объектов, а отражает логическую схему потоков информации и ее верификации. Думаю, что это наиболее важный рисунок в статье и остановлюсь на нем подробнее.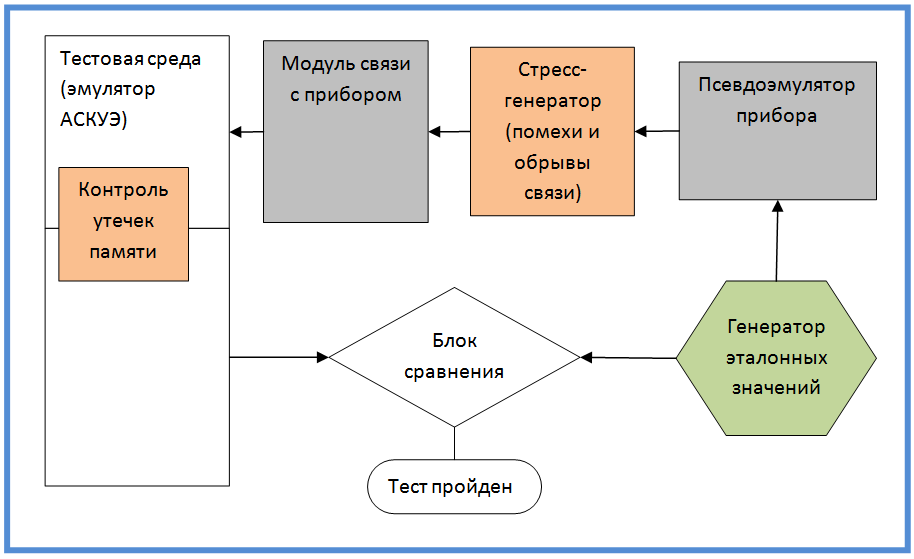
Поначалу мне казалось, что это довольно оригинальная схема, но потом я понял, что она всплыла из моих старых институтских знаний (были некие курсы по теории информации).
Генератор производит и запоминает эталонные значения, их принимает псевдоэмулятор прибора и переводит в низкоуровневый протокол. Протокол воспринимается нашим модулем и из него восстанавливаются эталонные значения. Значения возвращаются в тестовую среду (которая для модуля прибора старается выглядеть как АСКУЭ). Затем тестовая среда сравнивает полученные из модуля значения с эталонными. На основании сравнения делается вывод о работоспособности модуля.
Два модуля, выделенных красным относятся к стресс-тестированию. В частности могут быть воспроизведены ситуации отсутствия связи, обрыва связи, искажения пакетов. Основная задача — проверить механизмы повторных запросов к прибору, а также правильности распределения и освобождения памяти в случае неожиданных ситуаций (за этим следит блок контроля утечек памяти).
Генератор эталонных значений Не очень сложный, но ответственный блок — генератор эталонных значений. Суть генератора в том чтобы получить значение некоторого измеряемого АСКУЭ параметра. Это значение должно с одной стороны быть разнообразным и непредсказуемым (иметь хорошее распределение), а с другой стороны быть детерминированным (то есть воспроизводимым, от теста к тесту, чтобы дать нам возможность эффективно искать ошибки).Даже не слишком раздумывая, становится понятно, что это должна быть некоторая хэш-функция. Немного поэкспериментировав с велосипедами собственных моделей, я в конце концов прикрутил Md5. Претензий к работе у меня не возникло. Ниже привожу код на Delphi.
function TFECoreEmulator.GenNormalValue (const pTag: string): double; var A, B, C, D: longint; begin TFECoreMD5Computer.Compute (A, B, C, D, pTag+FE_CORE_EMULATOR_SECURE_MIX); result:=0; result:=result+Abs (A mod 1000)/1E3; result:=result+Abs (B mod 1000)/1E6; result:=result+Abs (C mod 1000)/1E9; result:=result+Abs (D mod 1000)/1E12; end;
function TFECoreEmulator.ModelValueTag (const pGroupNotation, pParamNotation: string; const pStartTime, pFinishTime: TDateTime): string; begin result:=pGroupNotation+'@'+pParamNotation+'@'+DateTimeToStr (pStartTime)+'@'+DateTimeToStr (pFinishTime); end; В результате несложных преобразований, мы получаем нормальное значение (0…1), которое приводим к требуемому диапазону, и с легким сердцем отправляем в эмулятор. В любой момент значение может быть воспроизведено с абсолютной точностью.
Устройство псевдоэмулятора Основное назначение псевдоэмулятора — генерировать ответы на запросы модуля связи с прибором. «Псевдо» он потому, что о реальной эмуляции речь не идет (это был бы неблагодарный и безполезный труд). Все что он должен сделать — это сформировать конкретные ответы на конкретные запросы. При этом, если нужны значения параметров — он обращается к генератору эталонных значений.Ничего необычного в нем нет, отмечу лишь особенную схему формирования ответа. Первое, что приходит на ум — это некая процедура (как правило с названием Parse) разбора запроса и формирования ответа. Но при практической реализации эта процедура разрастается до невероятных размеров, с постянными сильно вложенными друг в друга case и if.
Поэтому я сделал немного по-другому.
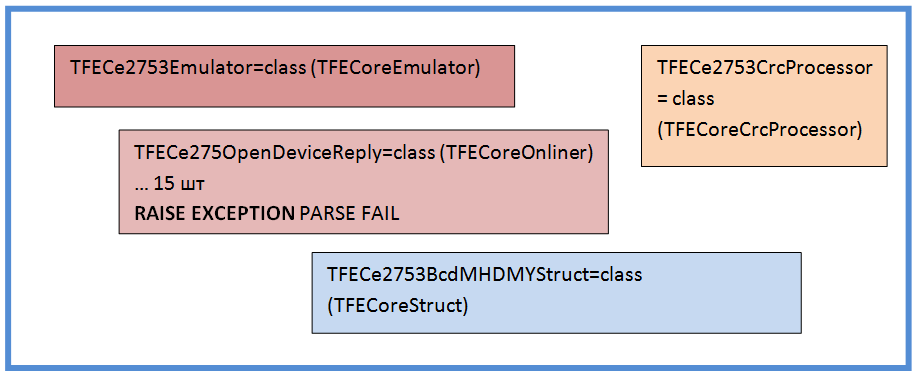
Я снабдил эмулятор набором вспомогательных объектов — я назвал их реплики. Каждая реплика пытается отдельно от других разобрать запрос. Как только она понимает, что запрос к ней не относится, — она бросает исключение, и эмулятор передает запрос для разбора следующей реплике. Таким образом удалось локализовать код для каждого варианта запроса в отдельном объекте. Если ни одна реплика не сработала — значит где-то ошибка, либо в модуле прибора, либо в эмуляторе.
Также можно видеть, что я повторно использовал объекты Struct (я научил структуры как кодировать, так и декодировать информацию) и CrcProcessor. Конечно, с точки зрения надежности такое делать не следует. Но я думаю, Вы мне простите этот компромисс.
С точки зрения надежности в тестируемом объекте и тестовой инфраструктуре не должен использоваться общий код (так как ошибка может взаимно компенсироваться). Желательно, чтобы объекты и их тесты писали вообще разные люди. И желательно, чтобы они ничего не знали друг о друге, а при встрече не здоровались за руку. Как Вы понимаете, я писал все это один и подобная методология мне была недоступна.
Стресс-генератор Стресс-генератор включен в разрыв между модулем и эмулятором прибора. Он может делать следующие вещи: Полностью блокировать ответ эмулятора Оборвать ответ где-то посередине Внести искажение в какой-либо байт ответа В случае обрыва ответа возникла проблема — в каком месте обрывать ответ. Я сделал так, что ответ обрывается в самом критическом месте — когда все заголовки и преамбулы посланы и модуль ждет реальных данных. Он должен уже создать все вспомогательные объекты. Если оборвать передачу в этом месте, то возникает максимальная вероятность утечек памяти.В процессе работы с живым прибором я столкнулся с очень интересной ошибкой: ответ прибора формально соответствует всем правилам, даже совпадает контрольная сумма. Но сами данные не соответствуют запрошенным. Специально для этого случая я ввел еще режим, который назвал внутренней ошибкой прибора.
После длительных размышлений, как такое может быть, я пришел к выводу, что в приборе просто не контролируют целостность запроса. И контрольная сумма, про которую так много написано в руководстве, самим прибором не считается. Поэтому, когда запрос искажается (например меняется адрес запрашиваемой памяти), прибор с чистым сердцем формирует нормальный по форме, но ошибочный ответ.
Контроль за распределением памяти Расскажу немного, как я тестировал модуль на предмет правильного распределения памяти. Многие вещи очевидны и всем известны, но я все-равно расскажу. Может быть что-то из этого покажется интересным. С давних пор программистам по ночам снятся кошмары связанные с распределением памяти. Изобретение Java и DotNet со сборщиками мусора несколько улучшило ситуацию. Но я думаю, что кошмары все равно остались. Просто они стали более изысканными и утонченными.
Современные системы обработки ошибок, которые основаны на механизме исключений — черезвычайно полезная вещь. Но они сильно усложняют процессы выделения и освобождения ресурсов. Это происходит потому, что когда возникает исключение, оно прерывает выполнение процедуры. Исключение легко преодолевает границы условий, циклов, подпрограмм и модулей. И, конечно, код для освобождения ресурсов, который находится в конце процедуры, если не принять специальных мер, выполнен не будет.
Лучшие умы человечества были брошены на решение этой проблемы. В результате была изобретена конструкция try…finally. Эта конструкция также имеет место и в системах со сборщиками мусора, потому что ресурс может быть не только памятью, но и, например, открытым файлом.
Классическая схема применения в случае — если ресурс — объект выглядит так.
myObject:=TVeryUsefulClass.Create; try … VeryEmergenceProcedure; … finally myObject.Free; end; Но мне больше нравится вот такой способ (он позволяет обработать сразу все объекты, задействованные в коде, кроме того, объекты можно создавать где и когда попало).
myObject1:=nil; myObject2:=nil; try … myObject1:=TVeryUsefulClass.Create; … VeryEmergenceProcedure; … myObject2:=TVeryUsefulClass.Create; … VeryVeryEmergenceProcedure; … finally myObject1.Free; myObject2.Free; end; Рецепт правильного управления памятью прост — везде где выделяются ресурсы и есть возможность возникновения исключений — применить схему try…finally. Но по невнимательности легко забыть или сделать что-то не так. Поэтому неплохо было бы протестировать.
Я сделал следующим образом. У всех своих объектах сделал общего предка и при создании заставил их регистрироваться в общем списке, а при уничтожении — удалять себя из списка. В конце список проверяется на неуничтоженные объекты. Эта не очень сложная схема также дополнена некоторыми элементами, которые помогают идентифицировать объект и найти место в коде, где он создается. Для этого объекту присваивается уникальная метка, а моменты создания и удаления выводятся в трассировочный файл.
var ObjectCounter: integer; ObjectList: TObjectList; … TFECoreObject = class (TObject) public ObjectLabel: string; procedure AfterConstruction; override; procedure BeforeDestruction; override; end; …
procedure TFECoreObject.AfterConstruction; begin inc (ObjectCounter); ObjectLabel:=ClassName+'('+IntToStr (ObjectCounter)+')' ObjectList.Add (self); Trace ('Create object '+ObjectLabel) end;
… procedure TFECoreObject.BeforeDestruction; begin ObjectList.Delete (self); Trace ('Free object '+ObjectLabel) end; …
procedure CheckObjects; var i: integer; begin for i:=0 to ObjectList.Count-1 do Trace ('Bad object '+(ObjectList[i] as TFECoreObject).ObjectLabel); end; Наиболее проницательные читатели скажут, что это уже некоторый зачаточный механизм сборщика мусора. Конечно, до сборщика мусора здесь далеко. Думаю — это неплохой компромисс. Какого либо замедления кода я не заметил. Кроме того с помощью директив условной компиляции в рабочей сборке этот механизм может быть отключен.
У механизма есть недостаток — он не позволяет следить за созданием объектов не порожденных от моего общего предка. Как правило — это стандартные библиотечные объекты TStringList, TObjectList и т.д. Я выработал правило, согласно которому создаю их только в конструкторах своих объектов, а уничтожаю — в деструкторах. А за своими объектами уже следит тест. Если делать все аккуратно — вероятность ошибки минимизируется.
Где-то за 3 часа стресс-тестирования мне удалось выявить все критические места и расставить try…finally нужным образом.
Точность воспроизведения эталонных значений Не знаю, как во времена компьютеров, а во времена логарифмических линеек считалось плохим тоном вываливать на человека 14 знаков после запятой, если достоверных из них — всего 3. Поэтому в системе АСКУЭ для каждого параметра можно задать точность. Для всех параметров она разная и определяется модулем связи с прибором. Только он знает как формируются значения и какую допустимую точность можно при этом обеспечить. После того, как основная работа была завершена, я решил поэкспериментировать и выяснить предельные возможности модуля в плане точности. Зачем я этим занялся? Наверное все дело в природном любопытстве. Я видел как на моих глазах происходят волшебный вещи. Эталонные значения запаковываются в хитрые невиданные никем форматы, а затем по мановению волшебной палочки восстанавливаются практически из пепла. А если у тебя есть волшебная палочка всегда хочется ей немного помахать. Думаю, любопытство когда-нибудь меня погубит.
Итак, для каждого типа значения я начал менять допустимую точность. Подробно описывать не буду, расскажу только об одном случае. Я заметил, что тесты стали валится, когда по моим ощущением запаса по точности было еще достаточно.
После небольшого расследования я установил, что в нескольких местах для округления по простоте душевной использовал Trunc. Я заменил на Round и предельная точность сразу повысилась на порядок.
Друзья, для округления чисел, конечно нужно использовать Round и RoundTo. Функция Trunc с математической точки зрения — нелепое, плохо ведущее себя преобразование. Trunc нужно использовать только в одном случае, для которого она и была придумана — отделение целой части от дробной. Во всех остальных случаях — Round. Иначе Вос ждут мелкие, а иногда и крупные неприятности.
Подключение к живому прибору
Как я уже сказал выше, к настоящему прибору я подключился, когда основная часть работы была проделана. Узнав, что прибор нужно подключать по RS-485, я очень обрадовался. Ведь там всего два провода. Имея за плечами пионерский кружок радиоэлектроники я подумал, что с двумя проводами я как-нибудь справлюсь. При попытке соединить преобразователь интерфейсов и прибор, после чтения обозначений контактов, я обнаружил картину, которая ввела меня в длительный ступор: 
Поняв, что с точки зрения формальной логики ситуация решения не имеет, я решил заглянуть в Интернет.
Я — наивный и бесхитростный человек. Каждый новый проект я начинаю с верой в торжество добра и нерушимость стандартов. И всегда меня постигают жестокие разочарования. Хуже всего то, что это повторяется из раза в раз. Жизнь ничему меня не учит.
В Интернете было сказано, что может А подключатся как минус, так и плюс. Все зависит от производителя. Я решил, что если существует такая путаница, то при неправильном подключении по крайней мере сгореть ничего не должно. Я попробовал и так и так. Все заработало.
Конечно, реальный прибор привнес массу доработок в проект. Реальные сеансы связи многое расставили по своим местам. Основные изменения затронули систему обработки ошибок и стресс-тестирования. Особенно, когда я подключался к прибору через беспроводные модемы (почти каждый третий ответ приходил искаженным).
Заключение
 Надеюсь, Вам был интересен мой небольшой рассказ о разработке и тестировании модуля АСКУЭ. Наиболее важным я считаю тестирование. От него напрямую зависит качество продукта. Все изменения, внесенные в проект и не подтвержденные тестированием — напрасная трата сил и времени. Ведь при малейшем изменении кода непротестированная проблема будет возвращатся вновь и вновь.Моя работа была навеяна методологией TDD (Test-Driven-Development разработка через тестирование). Но, конечно, чистого TDD у меня не получилось. Вот что я не делал:
Надеюсь, Вам был интересен мой небольшой рассказ о разработке и тестировании модуля АСКУЭ. Наиболее важным я считаю тестирование. От него напрямую зависит качество продукта. Все изменения, внесенные в проект и не подтвержденные тестированием — напрасная трата сил и времени. Ведь при малейшем изменении кода непротестированная проблема будет возвращатся вновь и вновь.Моя работа была навеяна методологией TDD (Test-Driven-Development разработка через тестирование). Но, конечно, чистого TDD у меня не получилось. Вот что я не делал:
Не писал тесты вперед Не писал тесты на каждый класс Не писал короткие тесты Не знаю к какому типу тестирования отнести то, что происходило в проекте — к модульному или интеграционному. Я бы сказал, что это — приемочное тестирование подсистемы.
Не хочу, чтобы прочитав комментарии Вы подумали, что я жалуюсь на жизнь. Напротив, это — именно то, что делает программирование самым интересным занятием на свете. Прошу также, чтобы создатели приборов учета не принимали все близко к сердцу. Знаю, что по другую сторону интерфейса жизнь тоже интересная. Вся моя ирония направлена, в основном, на меня самого.
Желаю всем приятного программирования.
