Разработка чат-бота с заданной личностью. Лекция в Яндексе
Важная особенность задач по машинному обучению заключается в том, что одинаково хороший результат достижим разными методами. Это и придаёт азарт ML-конкурсам: даже обладая другими компетенциями, чем у заведомо сильного соперника, вы всё равно можете выиграть. Команды Tensorborne и Neurobotics имели практически равные шансы на победу в хакатоне DeepHack и в итоге заняли первые два места. На тренировке Яндекса представители обеих команд выступили с одним объёмным докладом. В расшифровке вас ждут детальные разборы решений и советы начинающим конкурсантам.
И конечно, берите отпуск на хакатон. Когда вы участвуете в недельном хакатоне и одновременно еще и работаете, это плохо. Вы приходите в 7 вечера, немножко поработавший, садитесь и компилите Docker с TensorFlow, Keras, чтобы все это запустилось на каких-то удаленных серверах, к которым у вас даже доступа нет. Где-то в два ночи вы ловите катарсис, и у вас это работает — без Docker, без всего, потому что вы поняли, что можно и так.
Виталий Давыдов:
— Всем привет! У нас должно было быть два доклада, но мы решили их объединить в один большой, потому что рассказываем про первое и второе место в соревновании DeepHack. Мы представляем две команды. Наша команда Tensorborne заняла 2 место, а команда Григория Neurobotics — первое.

Доклад будет состоять из трех основных частей. В интро я расскажу о предыстории DeepHack, о том, чем он является, какие были метрики и т. д. Далее ребята расскажут о решениях, о том, какие были проблемы, примеры и т. д.
Прежде чем говорить про DeepHack, надо отметить, что он является небольшим подмножеством другого очень большого глобального соревнования ConvAI2, который в прошлом году запустил Facebook. В этом году вторая итерация. В какой-то момент Facebook проспонсировал МФТИ, и на базе лаборатории Физтеха создалось соревнование DeepHack.

Подробнее про сам ConvAI. Какую проблему он пытается решить? Он специализируется на диалоговых системах. Проблема диалоговых систем в том, что не существует единой оценочной тулзы, evaluation tool, чтобы понять качество диалогов. Это вещь очень субъективная от человека к человеку: кому-то разговор может понравиться, кому-то нет. Общая глобальная задача ConvAI — придумать общую единую метрику для оценивания диалогов, которой пока нет. Приз — 20 тыс. долларов на AWS Mechanical Turk. Это не кредиты на Amazon, это кредиты только на Mechanical Turk, который по факту является аналогом Яндекс.Толоки. Это краудсорсинговый сервис, который позволяет вам производить разметку на данных.
Задача, которая строится на ConvAI, — построить chit-chat-бота, с которым можно производить какой-то диалог. Они выбрали три метрики: Perplexity, Hits@1 и F1. Дальше я покажу таблицу, которая была на момент нашего сабмита.
Evaluation, по которому они пытались это делать, проходил в три этапа. Первый этап — автоматические метрики, далее — оценка на AWS Mechanical Turk, и дальше живой чат с волонтерами.
Так как ConvAI спонсируется Facebook, он активно продвигает свою библиотеку для создания диалоговых систем ParlAI. Она довольно сложная, но думаю, все участники использовали эту библиотеку. Мы довольно долго с ней разбирались, она не совместима с Python 3.6, например, и с ней есть ряд проблем.
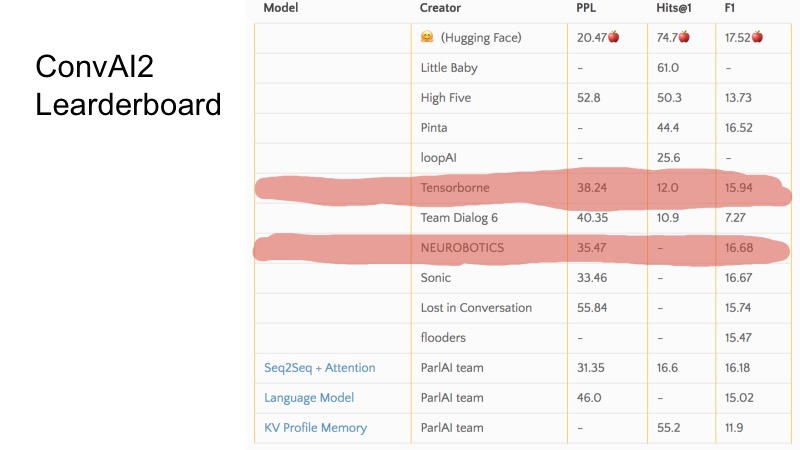
В этих нескольких строчках вы можете видеть, какие позиции мы занимали на момент подачи. Вообще, ConvAI странно организован в том плане, что есть три метрики и не очень понятно, как идет ранжирование по этой таблице. Видно, что по некоторым метрикам некоторые команды выше, по некоторым ниже. Организация всего ConvAI была немного странная.
Но здесь есть три базовых бэйзлайна. Чтобы отобраться на DeepHack, надо было пробить этот бэйзлайн, и топ-10 лучших команд попадали в финал. По секрету скажу, что решения отправили всего 8 команд, и все вышли в финал. Это было не очень сложно.

Задача DeepHack была чуть более понятная и прямолинейная. Нам надо было опять построить робота-болталку, но который будет эмулировать какую-то заданную личность. То есть роботу на вход подавалось описание какой-то личности, и во время разговора с ним он должен был ее раскрыть. Приз был довольно интересный — поездка на NIPS этой осенью, которая полностью спонсируется.
Метрика, в отличие от ConvAI, уже была другой. Было две метрики, и суммарная метрика — взвешенная между этими двумя. Первая метрика — overall quality, оценка того, насколько бот адекватно отвечал, насколько с ним было интересно общаться, не писал ли он какую-то чушь и т. д. Вторая метрика — role-playing, либо 0, либо 1. Она означает, попал ли бот в то описание, которое ему дали. Человек, который общается с ботом, описание не видит. Evaluation происходил в Telegram, то есть был единый Telegram-бот, и когда пользователь начинал с ним общаться, он попадал на какого-то случайного бота из всех сабмитов, чтобы было честно. Яндекс и МФТИ, видимо, налили немного трафика туда, и было в районе 10 тыс. диалогов, насколько помню.
Про квалификационный раунд уже сказал. Финал был очный. Он проходил в течение семи дней работы в МФТИ, был предоставлен какой-то кластер, место, мы там сидели и работали. Evaluation был по факту каждый день, и финальный score, оценка бота в конце, высчитывался таким образом. Соревнование начиналось в понедельник, первый сабмит был во вторник, и evaluation происходил на следующий день. Решение, которое вы отправили во вторник, эвальюировалось в среду с весом 1,5. То, что вы отправили в среду, — с весом 1,4 и т. д.

Про датасет, который Facebook дал для обучения. Он называется Persona-Chat и представляет из себя описание двух личностей и какой-то набор диалогов. Есть описание первой личности и второй. В процессе описания диалога они пытаются друг друга раскрыть. Это все, что было дано. Однако, как всегда, в соревновании не запрещалось пользоваться другими, сторонними датасетами.
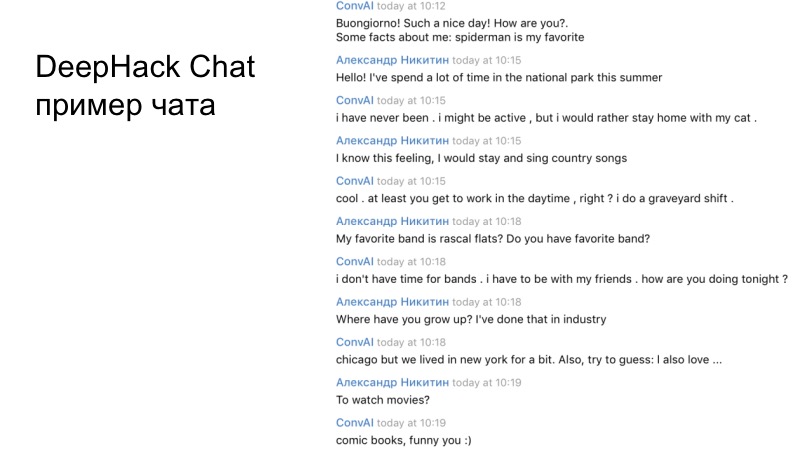
Пример диалога нашей команды. Если вы внимательно почитаете, видно, что получившийся бот работает довольно адекватно и отвечает довольно корректно.
Григорий расскажет про первое место.
Григорий Рашков:
— Я бы хотел рассказать про наш опыт участия в соревновании, нашу стратегию и наше решение.

Во-первых, особенность соревнования в том, что это большая длительность, у нас было не два дня, как на обычном хакатоне, а пять дней, за которые мы могли делать много решений.

Очень субъективные оценки, потому что эвальюировали совершенно разные люди со своими критериями, в частности организатор хакатона Михаил Бубцев говорил, что если он даже догадывался, о каком профиле идет речь, но бот в какой-то момент противоречил своему профилю, отвечал на вопрос не так, как у него написано, то он выбирал другой профиль, даже если догадался, о чем речь.
И третье — отсутствие валидации. Участники не могли внести небольшое изменение и сразу получить фидбек.
Как и во всех фильмах ужасов, наша команда в самом начале решила разделиться. Первая группа занималась нашим основным решением на базе Wasserstein GAN, вторая группа занималась ботом, админкой бота на базе бэйзлайна. Потому что нам уже в первый и второй день нужно было что-то отправить.

Ссылка со слайда
Коротко про бэйзлайн: Seq2Seq плюс attention, который немного адаптирован под данную конкретную задачу. Как именно? На вход подаются фразу, embedding берется из GloVe, но дальше считается представление каждой фразы как взвешенные embedding. Веса выбираются исходя из обратной частоты слова. Чем более редко встречающееся слово попадается, тем больший вес оно вносит.

Ссылка со слайда
Это нужно для отражения уникальности данных характеристик. Это все собиралось в сет, матрицу, на основе этого сета и скрытого состояния строилась маска, потом эта маска накладывалась на сет, получался контекст, и дальше уже он соединялся, через нелинейность подавался на вход декодеров.

За первый день мы еще не написали своего решения, нам нужно было что-то отправлять, поэтому мы написали агента на основе бэйзлайна, но поставили себе задачу как-то выделиться из всей серой массы агентов. Для этого мы воспользовались простой эвристикой, наш бот первым начинал диалог, и он в этой фразе использовал смайл. И это сработало.
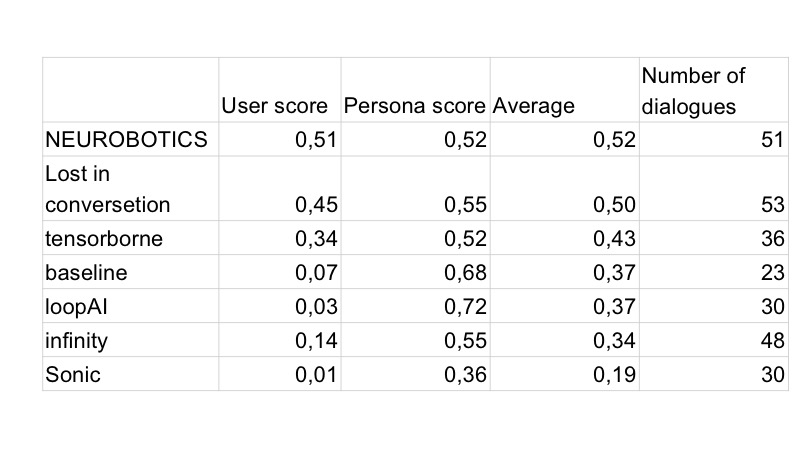
Естественно, на следующий день все боты начинали делать первыми, и у всех были смайлы. За второй день жители Вилабаджо продолжали работать с GAN, жители Виларибо пробовали другие эвристики.
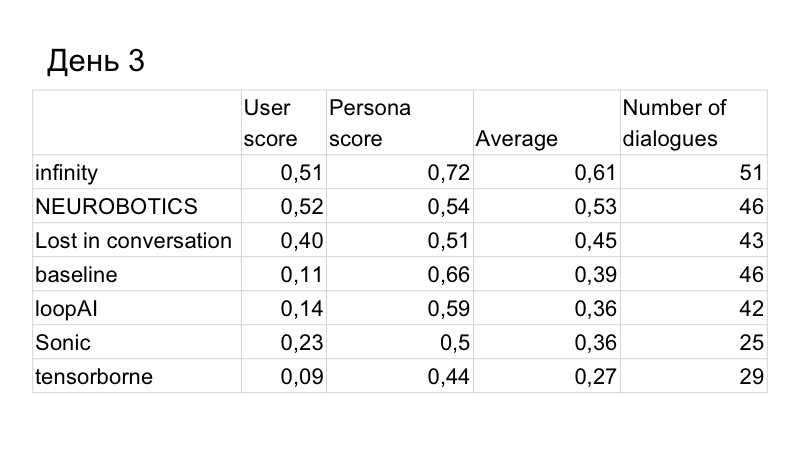
В результате score по качеству диалога у нас чуть улучшился, но нас обошли за счет персоны. Это уже результаты третьего дня, оставалось всего два дня. Мы понимали, что на то, чтобы написать GAN и нормально его протестировать, времени нам не хватит, потому что он учится долго, тяжело, приходится подбирать много гиперпараметров. Поэтому мы решили переключиться на бэйзлайн, потому что он и так хорошо работает.

У нас возникла задача улучшить распознавание профиля пользователя. Мы предложили такую эвристику. В чем была проблема? Пользователь радостно общался с ботом, спрашивал, какая у него работа, хобби, на какой машине он ездит, бот на все это хорошо отвечал, потому что бот вообще хорошо отвечал. В результате по окончании диалога пользователь видел два профиля, которые никак не относились к тому, что было в диалоге, просто потому что там указывались другие вещи, чем те, которые спрашивал пользователь. Поэтому мы решили, что нужно выдавать как-то информацию из профиля.
Как это сделать логичнее всего? Если у человека есть какие-то интересы, наверное, он сам будет о них беседовать, искать общие интересы. Поэтому мы решили, что бот будет в какие-то моменты сам задавать вопросы, исходя из своего профиля. Возник интересный эффект, что генератор, который написали просто по лингвистическим правилам G, использует какой-то факт А из профиля, в результате в диалог заносится G (A), все это отправляется в память боту, и в следующий раз уже модель генерит информацию, исходя и из профиля, и из этого диалога, то есть с большей вероятностью будет говорить что-то, относящееся к профилю.
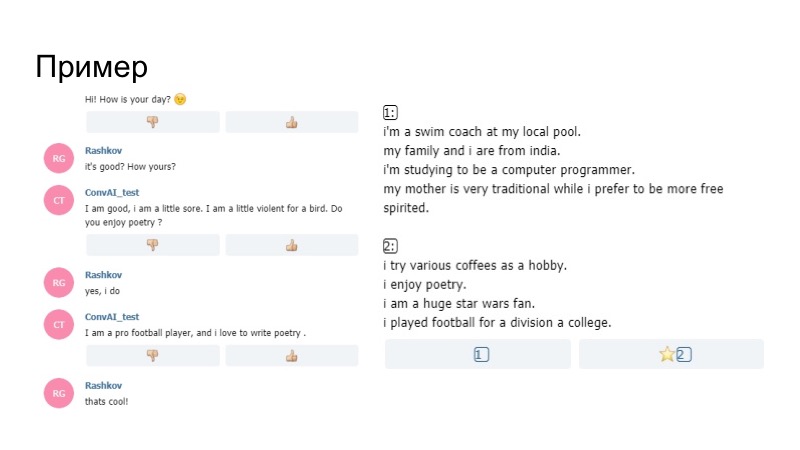
Как это выглядело в реальности? У бота в профиле написано, что он в восторге от поэзии, дальше в ходе разговора он спрашивает, нравится ли мне поэзия. Я говорю, что да, и дальше уже его модель, не генератор, который мы построили по правилам, говорит, что он любит писать стихи. Таким образом бот акцентировал внимание на своем профиле, и это сработало.

Мы снова вернулись на первое место. Оставался последний день. Мы заметили, что тем не менее мы проигрываем в качестве диалога.

Мы воспользовались еще несколькими решениями. Во-первых, использовали paraphrase, проанализировали то, что говорили другие люди, потому что организаторы выложили эту базу, и заметили, что многие общаются с ботом не совсем корректно.
Ссылка со слайда
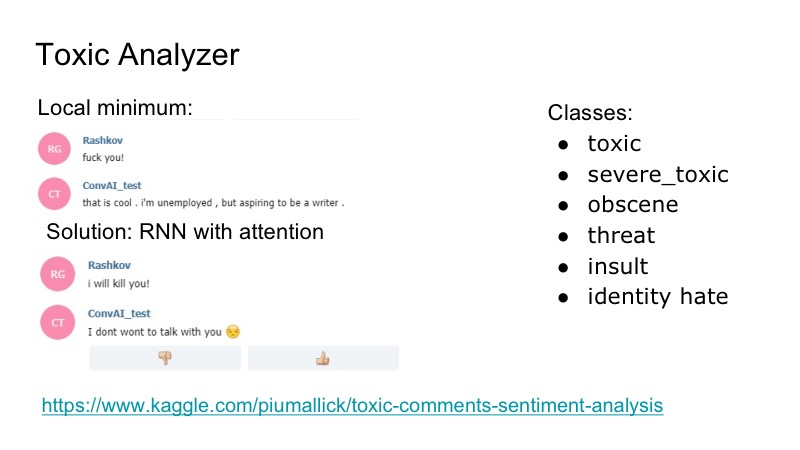
Возникает интересный локальный минимум у бота: он очень хорошо реагирует на любые оскорбления, он с ними соглашается, и чтобы это пофиксить, мы решили воспользоваться имеющимся Kaggle конкурсом на toxic comments analyzer, написали классификатор очень простенький, тоже с RNN вниманием. В том датасете были следующие классы, перекрывающиеся: оскорбления, угрозы… Мы под это решили не учить отдельно модельку, которая будет говорить, потому что такая проблема встречалась, но она была не очень частой. Поэтому мы просто написали какую-то затычку, которую отвечал бот, и все были довольны.

Кроме этого, мы использовали paraphrase, чтобы обогатить речь нашего бота. Сделали это тоже не очень сложно, мы заменяли слова из фразы на синонимы, смотрели получившиеся n-граммы во фразе, чтобы они не сильно отличались от тех, которые были изначально, и дальше выбирали подходящую для фразы комбинацию с наибольшей вероятностью.
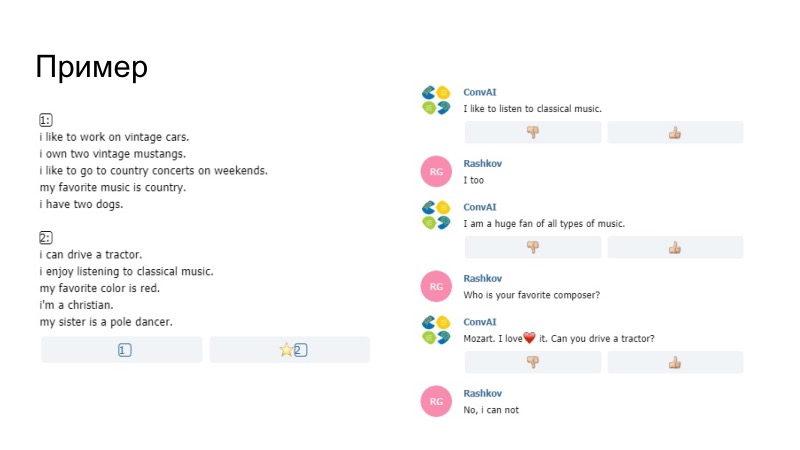
Как пример того, что было, бот здесь говорит, что любит слушать музыку, в профиле у него написано enjoy, у нас это заменилось на like to. Мы не уверены, сгенерировала ли это сама модель или наш Paraphraser, но эта штука прошла. Еще замечание, что нельзя было посылать просто данные из профиля. Там сравнивались пентаграммы. Если пентаграммы совпадали у твоей реплики и твоего профиля, то просто эта фраза не проходила, так устроили организаторы. Дальше кроме всего прочего мы добавили словарь смайлов.

Второй пример, у нас много смайлов. Дальше были эвристики, когда бот реагировал на твое поведение, что ты долго ему не пишешь. Также здесь срабатывал Paraphraser, и это дало хороший результат.
Качество диалога у нас оказалось лучшим, качество отыгрывания роли тоже.
Мы пробовали делать так, чтобы модель генерила набор вариантов, и мы сравнивали их с профилем. Но мне показалось, что в таком случае бот работает хуже, валидацию мы проводить не могли, только субъективные оценки по двум-трем беседам. Поэтому решили такую штуку не ставить, ибо профиль и так хорошо распознавался.
Дальше мы написали решение обратной задачи, вторую модель, которая по диалогу выбирала нужный профиль. Мы планировали ее использовать изначально для обучения, чтобы считать от нее loss-функцию и дальше распространять в сетку. Но это могло ухудшить саму болталку, поэтому решили так не ставить. Также мы думали использовать эту штуку для поведения бота, но оттестировать все не успевали, и решили от этой штуки отказаться. Кроме того мы решили ставить смайлы, исходя из эмоциональной окраски фразы, написали модель, но не нашли подходящего датасета, а те, которые использовали, немножко не про то.

Наша команда.
Даже если ваша основная модель, на которую вы надеетесь, не получается ее написать или она дает плохой результат, не стоит сразу же сдаваться, нужно пробовать какие-то более простые вещи, что довольно естественно. И второе, что иногда стоит смотреть, чего не хватает вашей модели, и думать над конкретными задачами, декомпозировать их и решать конкретные проблемные места, что мы и делали. Спасибо за внимание.
Сергей Колесников:
— Меня зовут Сергей Колесников, я буду представлять решение Tensorborne.

Мы придумали красивое название, прошли на конкурс, придумали много разных штук, чтобы выпустить две статьи после этого, но не выиграли хакатон. Поэтому и называться это будет: «Как не выиграть хакатон, но все-таки опубликовать чертовы две статьи». Академики, сэр.
Особенности конкурса, в котором мы участвовали, превзошли нашу мотивацию. Ввиду того, что оценка производилась ежедневно, то посылки приходилось делать также ежедневно, а конечный reward определялся, как мы любим в RL, дисконтированным суммированием. Все это переросло в то, что нам надо было каждый день отсылать хоть что-то, чтобы она работала, и мы получали хоть какой-то score. В итоге это и вправду переросло в то, что хочешь — не хочешь, а приходилось грести.
Что же у нас было? Превью на всю неделю.
Несмотря на то, что хакатон говорил, что он недельный, все решилось за четыре дня, что кажется для этой задачи ConvAI мало.
Изначально нас собралось пятеро, все хорошие академичные выпускники или около того Физтеха, поэтому в понедельник мы пришли и накидали много предложений, идей, что можно попробовать, какие deep learning модельки попробовать. Мы, правда, не экспериментировали с GAN, потому что уже экспериментировали с ними для текстов и это не работает, поэтому взяли что-то более простое, к тому же были очень похожие конкурсы и у нас были pretrain модельки. Во вторник мы даже смогли запустить что-то на deep learning, ML был везде, где можно, мы запускали замечательные докеры с поддержкой GPU и прочего для Tensorflow и Keras, нам отдельную медаль надо дать за это, ввиду того, что это не так тривиально, как хотелось бы.
По результатам вторника — они были многообещающими, и мы решили немножко улучшить наш ML небольшими эвристиками и прочим, и провалились на седьмое место. Но благодаря нашим товарищам по команде, кто-то нашел ElasticSearch, и попробовали. Был очень неловкий момент, когда ElasticSearch заработал отлично, а DL-модельки и ML, и прочее было немножко не столь робастным. Конец конкурса близился. И как было замечено предыдущим докладчиком, мы решили погрести в ту сторону, что работает. Взяли ElasticSearch, небольшие эвристики и подумали, что good enough, и правда good enough ввиду того, что второе место мы заняли.
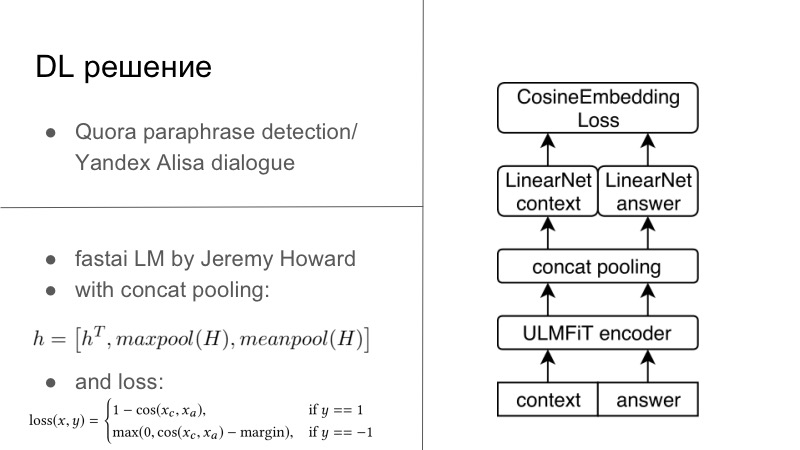
Подробнее. Реально DL-решений было несколько. Первое DL-решение было довольно простым. Кто помнит, в позапрошлом или прошлом году был конкурс Quora paraphrase detection, а в этом году проходил конкурс от Яндекса для Алисы по построению диалогов и прочему. Можно заметить, что задачи там очень близкие. В первом требовалось сказать, парафразы ли эти две фразы, а во втором надо было продолжить диалог. Мы подумали, что раз мы разрабатываем диалоговые системы, то давайте мы тоже просто будем хорошо продолжать диалог. И это отлично работало, диалог с Quora был очень даже ничего.
В основном все это выглядело так, что у нас был некоторый encoder, обычно мы все тренируем на обычных наших RNN, а лучше LSTM с attention и прочим. А дальше мы стандартно использовали либо CosaineEmbedding Loss, представленный ниже на слайде, либо другой embedding loss по типу Tripler Loss или чего-то другого, который эмбеддинги парафраз или ответов на конкретный диалог сближает, а не парафраз наоборот отдаляет, и прочее. Это было первое решение, именно оно было на Tensorflow, Keras, оно готовое, мы попробовали, и было довольно неплохо.
Другое решение было рождено за дня два хакатона по вечерам. Есть замечательный парень Джереми Ховард, он пропагандирует DL и ML для всех, у него есть замечательные два курса, которые вводят вас в курс этого дела и прочего, и под этот курс он написал свою либу FastAI. Все это работает на PyTorch, и во многом даже переписывает PyTorch, это один из минусов этой либы. Но из плюсов, Джереми к НЛП имеет мало отношения, в этом году в марте с еще одним студентом выпустили статью, где они обучили LSTM по всем лучшим практикам в замечательном FastAI, с многими трюками, которые он пропагандирует в своем курсе, и получили SOTA практически для всего.
Так как я являюсь небольшим евангелистом PyTorch, я все-таки смог выкорчевать данную модельку из FastAI, запихнуть, уже можно сказать, в свой фреймворк для PyTorch, и даже обучить все это дело под эту задачу. В основном у нас был некий диалоговый контекст, по сути, это даже если у нас было несколько предложений, вы просто конкатинируете это в одно здоровенное предложение. А дальше у нас был answer, некоторое предложение. Все это можно подать в тот самый кодировщик из FastAI, называется Universal Language Model —, а дальше сложно — Encoder.
После этого мы получаем контекст, который, положим, состоит из 1 до Т таймстепов, как мы любим в seq2seq. Дальше получается после энкодера вырождается Т таких последовательностей. Энкодер энкодит каждое предложение и переводит каждое слово в некий вектор, и дальше используется специальный пулинг, который был предложен в FastAI — Concat poolling. В чем суть? Мы берем последнее представление предложения как в обычных seq2seq, которые даже без attention. Дальше берем maxpool и minpool от всех последовательностей этих векторов, и получаем новый вектор размерностью в три раза больше, который и энкодит все наше предложение.
На самом деле, даже если забыть про этот хакатон, этот замечательный пулинг работает просто на ура, и даже в картиночных конкурсах, если у вас объединен maxpool и minpool, работает просто отлично. После этого мы заэнкодили контекст, и наш возможный ответ — в некоторое представление H, Hc и Ha. Эти вектора передаются на дополнительные линейные модели, обычные типичные feedforward сеточки, и получаются некоторые эмбединги. После того, как мы получили некоторые эмбединги, мы можем учить, по сути, любой metric learning. В нашем случае мы использовали самый простой способ — CosineEmbedding Loss, он доступен в PyTorch.
По окончании этого конкурса я проводил еще небольшие эксперименты и выяснил, что loss можно использовать чуть другой и будет даже еще лучше. Если кому интересно, это contrastive loss, он вне этой презентации, мы его так и не успели использовать. У нас остается два вектора, они нормализуются и дальше считается просто косинусное расстояние.
Это наше DL-решение. ElasticSearch, эвристики и прочее.
Что оказалось более робастным? Было очень обидно, когда в какой-то момент ElasticSearch заработал лучше. Где-то в среду или в четверг нами был распарсен все-таки Persona Dataset ввиду того, что формат данных, которые предоставлял Facebook, скажем так, не очень удобный, но распарсить его все-таки возможно. И мы его перевели во что-то близкое или понятное нам. У нас был диалоговый контекст из массивов предложений, у нас был контекст Персоны, опять же, массив предложений, и у нас был правильный ответ ввиду того, что Persona Dataset содержал как раз эти нужные диалоги, в которых замечательные люди на Amazon Mechanical Turk долго обсуждали и пытались выяснить, кто же кто.
Все эти замечательные вещи можно отлично запихнуть в ElasticSearch, который будет по контексту диалога и контексту Персоны пытаться вернуть правильный ответ, что он и делал. Ввиду того, что сам Persona Dataset содержал в себе порядка, если не ошибаюсь, 10 тыс. диалогов, то за время хакатона этого в принципе хватило. Мы, конечно, думали, как бы улучшить, но не напарсили такой датки.
Однако хотелось чего-то большего. У нас были хорошие показатели по диалоговому скору, однако по скору Persona все было не так гладко, ввиду того, что в нашей обучающей выборке, по сути, не было тех персон, на которых проводился evaluation. Пришло время замечательных heuristic solutions.
Первое, что мы придумали, это задавать вопросы, чтобы наш бот не был пассивным и спрашивал у людей, что вы любите. Разводил вас на диалог. Тогда люди больше отвечали, по сути, выполняли больше работы, нам надо было думать меньше, просто иногда хорошо отвечать, но это вроде мы умели. И это замечательно работало.
Дальше мы придумали небольшую совершенную эвристику — диалоги по некоторому сценарию. На самом деле мы придумали только один сценарий, потому что реально писать эвристики для диалогов — это очень много иф-элсов, а никто не хотел писать иф-элсы, мы же академики, в конце концов.
Также у нас был небольшой dirty hack. Когда пришел последний день, мы решили поставить все на кон и использовать то, что разрешалось рассказывать о своей персоне меньше пентаграмм. Поэтому нашу персону можно было легко понять. Опять же — пришлось использовать много эвристик, чтобы не говорить об этом в лоб.

Какие итоги? Неприятный итог лично для меня состоит в том, что иногда не-DL-решение работает намного робастнее и стабильнее и лучше, чем замечательный DL, который мы попробовали изначально. Дело в том, что вам требуется время, чтобы много чего протюнить, проверить и прочее. А в нашем случае у нас не было никакой валидации. По сути, мы отправляли что-то, обычно часа в два ночи, и надеялись, что это полетит. К сожалению, был один слайд, где наша команда оказалась внизу. Это когда оно не полетело. Мы отправили, оно упало, и мы потеряли день. После этого на DL мы начали смотреть немножко с укором ввиду того, что ElasticSearch объективно работает.
Можно видеть, как эвристики увеличивали именно personality score. Немного магии, немного иф-элсов, и у вас практически 0,25–0,3 улучшения, что дает большой буст на итоговый скор. К нашей печали, это ухудшает диалоговое значение, потому что иф-элсы всегда ухудшают ваше решение.

Примеры. По поводу первой эвристики — в конце первой строки мы нагло и ужасно используем правило организаторов, но черт возьми, вечер пятницы, а ты сидишь и отправляешь в Docker ElasticSearch, с которой ты познакомился на этой неделе. Мы делали все, что могли. Следующая эвристика. Все помнят замечательный сценарий диалог. Мы долго шли к Also, try to guess… Он спрашивает, и ты говоришь — нет, funny you. И замечательно, что эта комбинация настолько general, что работала. Нам было очень хорошо, особенно в два часа ночи, когда мы это отправили.
Также, пользуясь случаем, на камеру хочу сказать спасибо Валентину Малых. В один замечательный четверг в два часа ночи он нам очень помог. Серьезно, если бы все организаторы подходили так ответственно к конкурсам — что два часа ночи, а человек не спит и помогает ребятам выложить решение, консультирует их. Ввиду того, что все происходило в Docker, при отсылке решения было много нюансов.

Что осталось за кадром и что надо бы сделать? ConvAI еще не близко, он будет только к NIPS, и мы даже можем попытаться сделать что-то более приличное.
Во-первых, ElasticSearch действительно хорошо работает. Но, как и любая модель, он имеет гиперпараметры. И мне кажется, что если мы правильно их потюним, то ElasticSearch будет примерно божественным. Надеюсь, не лучше DL.
Во-вторых, надо потюнить все наши DL-решения. Согласитесь: когда у вас четыре дня на то, чтобы вывести это в продакшен, вам немного не до того, чтобы подбирать гиперпараметры и прочее. Вы просто берете то, что работает, и, перекрестив, отправляете это в путь.
И я не знаю, почему мы не взяли бэйзлайн. Это историческая несправедливость, поскольку мы прошли на этот конкурс благодаря бэйзлайну. Никто из нас не знает, почему мы не попробовали его дальше. Просто мы такие — да у нас pre-trained-модельки (неразборчиво — прим. ред.), используем. Много вопросов.
Конечно, в наших proposals лично я говорил, что я сделаю RL bandits и заэнсамблю за два дня. Под это лучше не коммититься, не выйдет. Все это можно улучшить — бот и правда будет намного лучше. И возможно, надо было улучшить эвристики. Кажется, что правильно добавленные эвристики, даже с теми же замечательными смайлами и прочим, и возможно, правильные реакции на всякие toxic-комменты дают еще один небольшой буст. Это кажется логичным.
На хакатон вы должны идти с одной целью — взять и победить. В реальности в нашей команде также был Денис Антюхов, и мы участвовали с ним в DeepHacks еще года два назад. Мы знаем NLP, и на этот DeepHack мы пришли с мыслью, цитирую, «опустить лидерборд». Не опустили, к сожалению. Но цель кажется очень логичной. Если вы хотите участвовать в конкурсах, хакатонах, кегглах, в чем угодно, то вы должны идти с целью не просто поучаствовать, а победить и порвать всех.
Правильная команда — это и вправду самый лучший залог успеха. Наша команда из пяти человек была самой distributed-командой из всех на этом хакатоне ввиду того, что мы так никогда и не встретились. Сегодня первый раз, и мне наконец передали футболку с DeepHack. Но между тем мы все-таки получили неплохой результат. Берите хорошую команду. Сильная команда, если вы знаете друг друга, может дать огромный буст, поскольку вы не потратите дня два на то, чтобы начать понимать друг друга.
Начинайте с бэйзлайнов! Серьезно. Даже не надо использовать свои pre-trained-модельки. Начать с бэйзлайнов, возможно, лучше.
И конечно, берите отпуск на хакатон. Когда вы участвуете в недельном хакатоне и одновременно еще и работаете, это плохо. Вы приходите в 7 вечера, немножко поработавший, садитесь и компилите Docker с TensorFlow, Keras, чтобы все это запустилось на каких-то удаленных серверах, к которым у вас даже доступа нет. Где-то в два ночи вы ловите катарсис, и у вас это работает — без Docker, без всего, потому что вы поняли, что можно и так.
Кажется, что если вы участвуете в большом конкурсе, то все-таки выделите под него чуть больше времени, чем сколько можно не спать в неделю, и участвуйте. Идите и выигрывайте. Спасибо!
