Разработана опенсорсная утилита Depix для восстановления паролей с размытых скриншотов
Разработана опенсорсная утилита Depix для восстановления паролей с размытых скриншотов

Результат работы программы Depix (исходный код)
В голливудских фильмах любят преувеличивать. Они зуммируют фотографии в миллион раз — и выводят цифры из одного пикселя.
Хотя это невероятно, но научные исследования в этой области идут давно. Ещё в 90-е годы были опубликованы теоретические работы и PoC с восстановлением текста из размытых изображений. В 2012 году Владимир Южиков писал на Хабре о своей программе SmartDeblur для восстановления смазанных и расфокусированных снимков.
Несмотря на достаточно хорошее развитии науки в данном направлении, до сих пор не было специализированного инструмента конкретно для восстановления паролей (текста) после пикселизации. Программа Depix — первый такой инструмент.
В 2019 году руководитель видеогруппы Лаборатории компьютерной графики и мультимедиа ВМК МГУ Дмитрий Ватолин рассказывал о современном состоянии науки в части повышения резкости фотографий. Он говорил, что российская полиция постоянно просит его о помощи, хотя и не понимает сложности проблемы:
Вопросы всегда одни и те же. «У нас есть видео с подозреваемым, пожалуйста, помогите восстановить лицо»… «Помогите увеличить номер с видеорегистратора»… «Здесь не видно рук человека, пожалуйста, помогите увеличить»… И так далее в том же духе.Чтобы было понятно о чем речь — вот реальный пример присланного сильно сжатого видео, где просят восстановить размытое лицо (размер которого эквивалентен примерно 8 пикселям).

В общем, проблема повышения резкости действительно актуальна. Все хотят найти в кадре информацию, которой там нет.
Во-первых, что такое пикселизация. Это процесс частичного снижения разрешения изображения для скрытия информации. Используется в разных областях. Многие компании используют пикселизацию для скрытия паролей и других секретных данных во внутренних документах.
Реализация алгоритма Depix атакует (то есть пытается обратить вспять результат работы) общего линейного фильтра для блока пикселей (linear box filter). Этот фильтр берёт блок пикселей и перезаписывает его средним значением всех пикселей в блоке. Реализация простая и быстрая, поскольку можно обрабатывать несколько блоков параллельно.
На рисунке ниже показан пример такого линейного фильтра. Изображение смайлика разделено на четыре блока, для каждого из которых вычисляется средний цвет — и он записывается вместо оригинального цвета пикселей, что приводит к финальной пикселизации. Напрямую реверсировать фильтр невозможно, так как потеряна исходная информация.

Изображения можно размыть множеством способов. Пикселизация линейными фильтрами для блоков пикселей — лишь один из вариантов. Большинство алгоритмов размытия склонны смешивать/растягивать пиксели, поскольку пытаются имитировать естественные размытия, которые вызваны движением камеры или расфокусировкой.
Есть множество инструментов для повышения резкости в обычных задачах, таких как повышение резкости фотографий. К сожалению, именно с паролями нужен другой подход. Здесь высота символов всего в пару блоков, так что нет смысла просто повышать резкость, пишет автор программы Depix.
Выше мы привели ссылки на некоторые инструменты и исследования, опубликованные на Хабре с 2012 года.
Последние разработки в области искусственного интеллекта породили на свет причудливые заголовки в новостях, типа «Исследователи создали инструмент, который идеально повышает резкость лиц». На иллюстрации ниже — примеры из научной статьи с описанием алгоритма PULSE исследователей из университета Дьюка (США).

Работа алгоритма PULSE из университета Дьюка
Но на самом деле здесь ИИ не восстанавливает фотографии, а генерирует новые изображения, которые размываются в такие же пиксели. Фундамент этих работ заложен алгоритмом RAISR от 2016 года. ИИ генерирует лица, которые размываются в картинку, данную на входе. Важно понимать, что сгенерированное лицо не является оригиналом, из которого получено исходное размытое пятно.
Алгоритмы вроде PULSE кажутся новыми, но они ведут очень давнюю историю инструментов для удаления размытия. Ещё в 1994 году (!) Марк Буйе из Юго-западного исследовательского института (США) написал программу для генерации «Плутонов», размытия картинок и их сравнения с настоящими фотографиями, полученными с телескопа «Хаббл».
В широко известной статье от 2006 года Дхира Венкатраман объясняет алгоритм, как восстановить пикселизированный номер кредитной карты. Идея проста: сгенерировать все номера кредитных карт, пикселизировать их — и сравнить результат с пикселизированным числом.
Например, мы видим в интернете фотографию чека или банковской карточки с размытым номером. Как видим, здесь для размытия использовался линейный фильтр для блоков 8×8 пикселей:
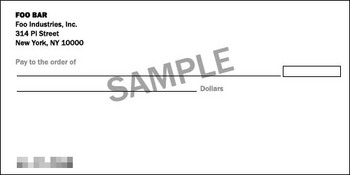
Как восстановить эти цифры?
1. Берём образец чистого бланка.
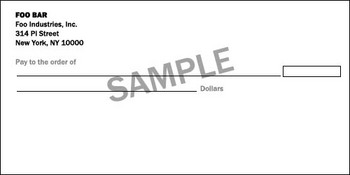
2. Скрипт генерирует картинки для всех номеров.
3. Размываем каждую картинку по образцу исходного изображения.

4. Определяем вектор яркости каждого изображения. Вектор типа ![$a=[a_1,a_2...,a_n]$](https://habrastorage.org/getpro/habr/formulas/8f9/c29/d95/8f9c29d953b95ac996fbcfd3bbc46d01.svg) содержит значения яркости каждого блока.
содержит значения яркости каждого блока.
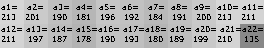
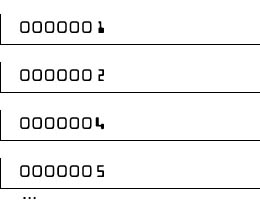
Здесь номер чека 0000001 соответствует вектору a(0000001)=[213,201,190,...].
Также определяем вектор яркости образца ![$z=[z_1,z_2,...z_n]$](https://habrastorage.org/getpro/habr/formulas/102/625/8d7/1026258d70c243c30b9f47475c3a33ab.svg) .
.
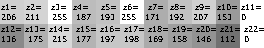
5. Находим вектор с минимальным расстоянием от исходного (после нормализации).
Константы нормализации:


Вычисление расстояния:

Например:
d(0000001) = 1.9363 d(0000002) = 1.9373 ... d(1124587) = 0.12566 d(1124588) = 0.00000
Так находим номер чека: 1124588.
В 2019 году Сомдев Сангван описал интересный метод восстановления размытых лиц в расследованиях OSINT. Метод такой: разрешение фотографии повышается в «Фотошопе». Оно сначала размывается:

А потом запускается поиск по картинкам «Яндекса» (более продвинутый, чем Google Images). В данном случае «Яндекс» выполняет «брутфорс» лица на изображении:

Несложно заметить, что у всех описанных методов есть что-то общее. Если не хватает информации, чтобы правильно восстановить изображение, то мы осуществляем пикселизацию аналогичных данных — и проверяем, совпадают ли они.
Это является основой для нашего алгоритма восстановления паролей со скриншотов.
Линейный фильтр для блоков — это детерминированный алгоритм, то пикселизация одних и тех же значений всегда приводит к одному и тому же блоку. Можно попробовать восстановить текст примерно по такому же принципу, что и цифры в примере выше. Каждый блок или комбинация блоков может рассматриваться как подзадача.
У алгоритма есть определённые ограничения. Он требует одинакового размера и цвета текста на одном и том же фоне. Современные текстовые редакторы также добавляют оттенок и насыщенность, допуская огромное количество возможных вариантов шрифтов на скриншоте.
Здесь довольно простое решение. Берём последовательность де Брёйна для ожидаемых символов, вставляем в тот же редактор и делаем скриншот. Данный скриншот используется в качестве подстановочного изображения для аналогичных блоков:

Эта последовательность включает в себя все двухсимвольные комбинации. Важно использовать именно двухсимвольные комбинации, потому что некоторые пиксельные блоки закрывают больше одного символа.
Чтобы поиск сработал, требуется блок с абсолютно такой же конфигурацией пикселей. Например, в тестовом изображении алгоритм не смог найти часть буквы 'o', потому что в сгенерированном изображении этот блок включал ещё и часть следующей буквы, а в исходном изображении было чисто.
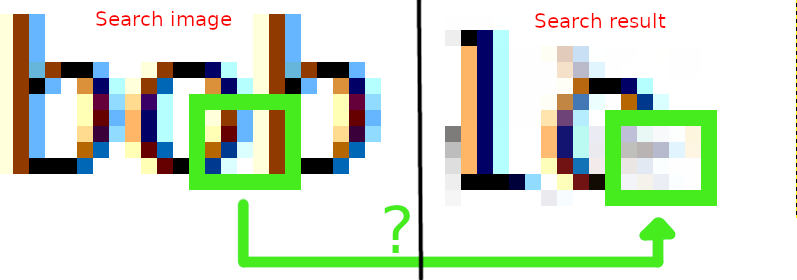
Создание последовательности де Брёйна с пробелами вокруг, очевидно, создаёт ту же проблему, только наоборот: алгоритм не сможет найти правильные блоки, где на край блока попала соседняя буква. Можно сгенерировать изображение со всеми вариантами буквосочетаний, а также с пустыми местами по краям. По такой картинке поиск будет идти дольше, но даст лучшие результаты.
Для большинства размытых изображений инструмент находит результаты одиночного совпадения для блоков. Затем проверяется, что совпадения окружающих блоков находятся на том же геометрическом расстоянии, что и на размытом изображении.
После прохода по всем блокам программа напрямую выводит все правильные блоки, а для блоков с несколькими совпадениями выводит среднее значение. Выдача не идеальна, но работает довольно хорошо. На рисунке показано тестовое изображение со случайными символами. Большинство символов можно прочитать.
Исходный код программы Depix опубликован на Github.
Кстати, описанная техника перекликается с некоторыми известными криптографическими атаками. Например, это похоже на взлом хэшей, напоминает атаку на блочный шифр ECB и атаку на основе открытых текстов (KPA).
Так что если вы хотите удалить информацию со скриншота — удаляйте её полностью, заливая сплошным цветом. Хотя и тут нужно думать головой.

На правах рекламы
Наша компания предлагает безопасные серверы с бесплатной защитой от DDoS-атак. Возможность использовать лицензионный Windows Server на тарифах с 4 ГБ ОЗУ или выше, создание резервных копий сервера автоматически либо в один клик.
Используем исключительно быстрые серверные накопители от Intel и не экономим на железе — только брендовое оборудование и одни из лучших дата-центров в России и ЕС. Поспешите проверить.

