[Перевод] Понимание вертикального автомасштабирования подов в Kubernetes
И почему не стоит его использовать в автоматическом режиме

Вертикальное автомасштабирование подов (Vertical Pod Autoscaling) — одна из крутых функций Kubernetes, которую недостаточно часто используют. И на это есть серьезные причины.
Kubernetes был создан для горизонтального масштабирования, и изначально вертикальное масштабирование подов не казалось очень-то хорошей идеей. Вместо этого более логичным считалось создание копии пода в случае, когда появлялась дополнительная нагрузка.
Однако для этого требовалось серьезно оптимизировать ресурсы, и если вы не настроили под должным образом, установив правильный запрос ресурсов и конфигурацию ограничений, это могло привести либо к слишком частому удалению подов, либо к трате большого количества полезных ресурсов. Если вы назначите своему поду слишком мало ресурсов запроса, ему может не хватить ресурсов для запуска, а если вы назначите слишком много, он будет впустую растрачивать полезные ресурсы, которые могли бы понадобиться другим подам.
Идея использования Kubernetes заключается в том, чтобы упаковать как можно больше контейнеров в максимально маленькую инфраструктуру (очевидно, это требует от вас сохранения буфера на случай сбоя узла, но вы поняли суть). Методом проб и ошибок разработчики и системные администраторы искали оптимальное значение запросов ресурсов и ограничений. Их настройка требовала значительного контроля и понимания, как эффективно их использовать — через сравнительное тестирование или через общее наблюдение за производственным использованием и трафиком.
Все усложняется, когда трафик прерывист, а использование ресурсов не оптимально. С ростом числа контейнеров в микросервисной архитектуре, становится неординарным понимание паттернов утилизации ресурсов, так как системные администраторы сфокусированы на стабильности и в конечном итоге устанавливают запросы ресурсов намного выше того уровня, который реально нужен.
Kubernetes нашел решение этой проблемы в вертикальном автомасштабировании подов. Давайте разберемся, что оно делает и когда его стоит использовать. А затем рассмотрим небольшой пример, чтобы увидеть этот инструмент в действии.
Как работает инструмент вертикального автомасштабирования подов (Vertical Pod Autoscaler, VPA)
VPA использует два основных компонента для того, чтобы автомасштабирование работало. Алгоритм следующий:
- Рекомендательный сервис VPA проверяет историю использования ресурсов и текущий шаблон использования и рекомендует идеальное значение ресурса запросов.
- Если вы установили автоматический режим обновлений, автоматический регулятор VPA исключит работающий под и, основываясь на новом значении ресурса запросов, создаст новый.
- Автоматический регулятор VPA также масштабирует значение предельных ограничений в отношении изначально определенных ограничений (если такие были). Однако он не оставляет рекомендаций по тому, каким должно быть предельно допустимое значение.
Для ограничения ресурсов нет определенного значения — автомасштабирование просто будет его поднимать. И все же, если вы хотите подстраховаться на случай утечки данных, вы можете установить значения максимального ресурса (Max Resource, MR) в Спецификаторе VPA.
Манифест VPA
Давайте взглянем на представленный ниже пример манифеста VPA:
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx
updatePolicy:
updateMode: "On"
resourcePolicy:
containerPolicies:
- containerName: "nginx"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
- containerName: "istio-proxy"
mode: "Off"Как и в любом манифесте, в нем есть поля apiVersion, kind, metadata и spec.
В поле spec мы видим раздел targetRef, который определяет объект, к которому применяется VPA. Раздел updatePolicy определяет, будет ли этот VPA лишь рекомендовать или рекомендовать и автомасштабировать, основываясь на свойстве updateMode. Если updateMode установлен на Auto, он автомасштабирует поды вертикально, если Off, он просто рекомендует идеальные значения запроса ресурсов.
Раздел resourcePolicy позволяет нам задать containerPolicies для каждого контейнера со значениями ресурсов minAllowed и maxAllowed. Это крайне важно, чтобы обезопаситься от утечек памяти. Вы также можете отключить рекомендации по ресурсам и автоматическое масштабирование для определенного контейнера в поде, что обычно встречается в случае сайдкаров Istio или InitContainers.
Ух ты! Это было что-то. В следующей части рассмотрим некоторые ограничения.
Ограничения
Вертикальное автомасштабирование подов, конечно, имеет свои ограничения.
Его нельзя использовать вместе с горизонтальным автомасштабированием подов.
Поскольку вертикальное автомасштабирование подов автоматически изменяет запросы и предельные значения, нельзя использовать его вместе с инструментом горизонтального автомасштабирования (Horizontal Pod Autoscaler, HPA), потому что HPA полагается на CPU и использование памяти, чтобы горизонтально масштабировать поды. Исключением из этого правила может быть ситуация, когда вы используете HPA, который полагается на пользовательские и внешние метрики для масштабирования подов.
Для его работы требуется как минимум две работоспособные реплики подов.
Это ограничение в первую очередь подрывает цель вертикального автомасштабирования и является причиной, по которой оно не часто используется. Поскольку VPA разрушает под и воссоздает его для проведения вертикального автомасштабирования, ему требуется минимум две работоспособные реплики пода, чтобы гарантировать отсутствие перебоев сервиса. Это создает ненужные сложности архитектуры stateful-приложений, и вам придется посмотреть на архитектуру реплики. Для приложений с распределенной структурой использование HPA может быть лучше, чем VPA.
Минимальная выделенная память по умолчанию — 250 MiB.
VPA выделяет минимум 250 MiB памяти вне зависимости от того, что вы указали. И хотя это значение по умолчанию можно исправить на глобальном уровне, VPA становится непрактичным для приложений, которые потребляют меньше памяти.
VPA нельзя использовать с отдельными подами.
VPA работает только с Deployments, StatefulSets, DaemonSets, ReplicaSets и т.д. Его нельзя использовать с изолированным подом, у которого нет владельца. Это не очень существенное ограничение, поскольку большинство разработчиков не используют изолированные поды, но его стоило упомянуть.
Использование VPA в режиме рекомендаций
До сих пор лучший из всех возможных вариантов использования VPA в производственной среде — использование его в режиме рекомендации. Этот режим очень помогает понимать, каковы оптимальные значения запроса ресурсов и как они могут изменяться со временем.
Как только вы это определите, вы сможете собрать эти метрики при помощи оператора Kubernetes или Kubectl и отправить их в инструмент мониторинга и визуализации, как Prometheus, Grafana или стек ELK, чтобы получить важную аналитическую информацию.
Вы можете использовать эту информацию для изменения размеров подов в соответствии с рекомендациями, выбрав часы минимальной нагрузки в течение дня, чтобы ваша работа не повлияла на пользователей и бизнес. И это может также стать частью стратегии непрерывного улучшения.
Я бы не рекомендовал запускать VPA в авторежиме в производственной среде, потому что это относительно новый инструмент, который все еще активно развивается. Меньше всего вам нужен отказ в обслуживании из-за того, что VPA слишком часто удаляет ваши поды. Если вы не знаете наверняка, что делаете, лучше не начинать сразу использовать VPA в производственной среде.
При этом вы всегда можете поэкспериментировать с VPA в среде разработки и проверить, как он ведет себя при возрастающей нагрузке. Вы легко можете выяснить максимальное количество ресурсов, которые может потреблять ваш под, запустив нагрузочный тест, который мы увидим в следующей части.
Практика
Для этого упражнения я бы использовал GKE с включенным VPA. GKE поддерживает VPA только в региональных кластерах.
Убедитесь, пожалуйста, что вы включили VPA в своем кластере либо через контроллер Admission, если вы используете самоуправляемую настройку, либо через настройки вашего облачного провайдера, если используется управляемый кластер.
Итак, начнем. Первым делом создадим deployment Nginx c запросом по умолчанию 250 MiB памяти и 100m CPU.
$ cat <Теперь нам надо представить deployment как сервис LoadBalancer.
kubectl expose deployment nginx --type=LoadBalancer --port 80Подождем, пока облачный провайдер включит балансировщик нагрузки и получит IP балансировщика нагрузки.
$ kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.4.1.4 34.121.204.234 80:30750/TCP 46sТеперь создадим VPA с updateMode: "Off". Это не запустит вертикальное автомасштабирование, но предоставит рекомендации.
$ cat <Теперь проведем некоторые нагрузочные тесты, чтобы проверить, какие рекомендации мы получим с нагрузкой. Для этого теста я воспользуюсь утилитой hey:
hey -z 300s -c 1000 http://34.121.204.234Это запускает запросы в течение 300 секунд с использованием 1000 параллельных потоков — серьезная нагрузка на сервис.
Запустите следующую команду, чтобы получить рекомендации по описанию VPA:
kubectl describe vpa nginx-vpaЕсли мы некоторое время понаблюдаем за VPA, мы увидим, что он будет постепенно рекомендовать увеличивать запросы ресурсов:
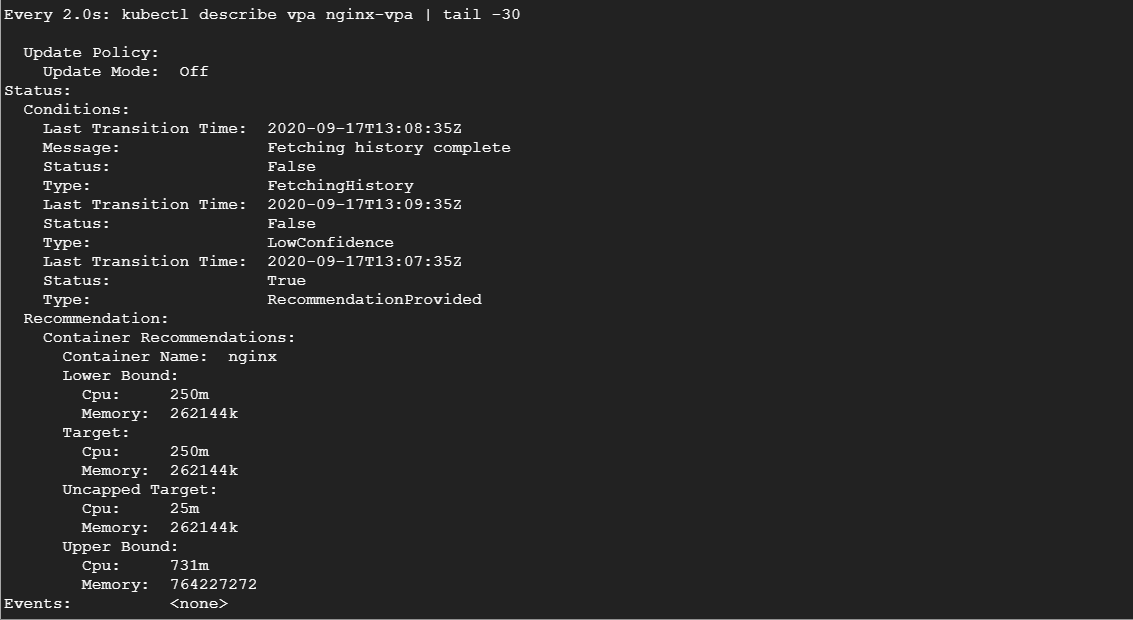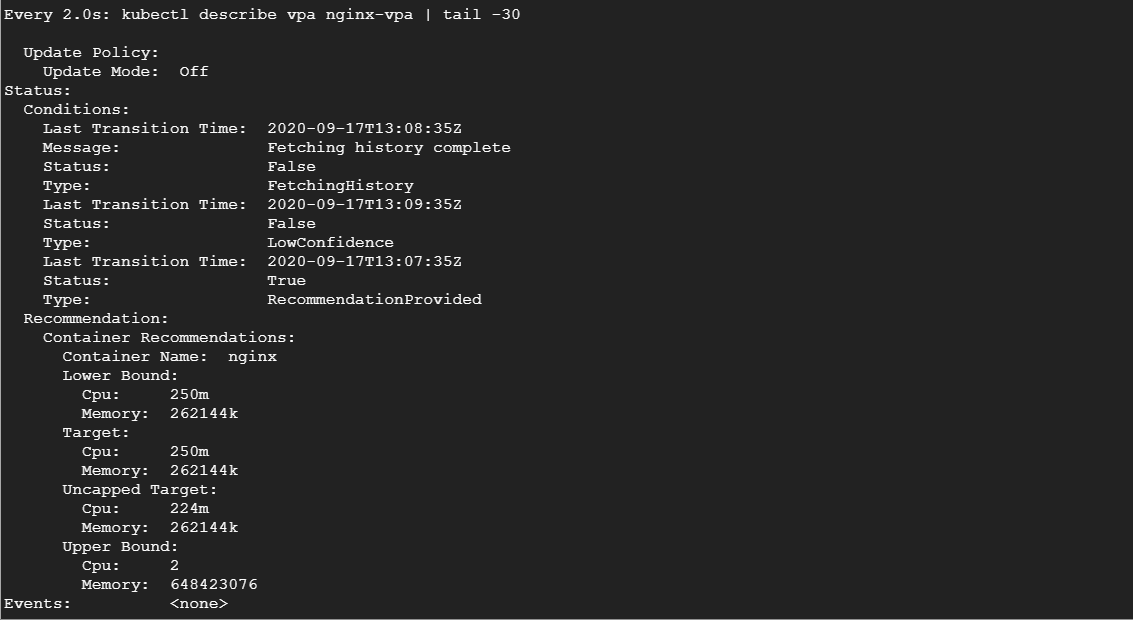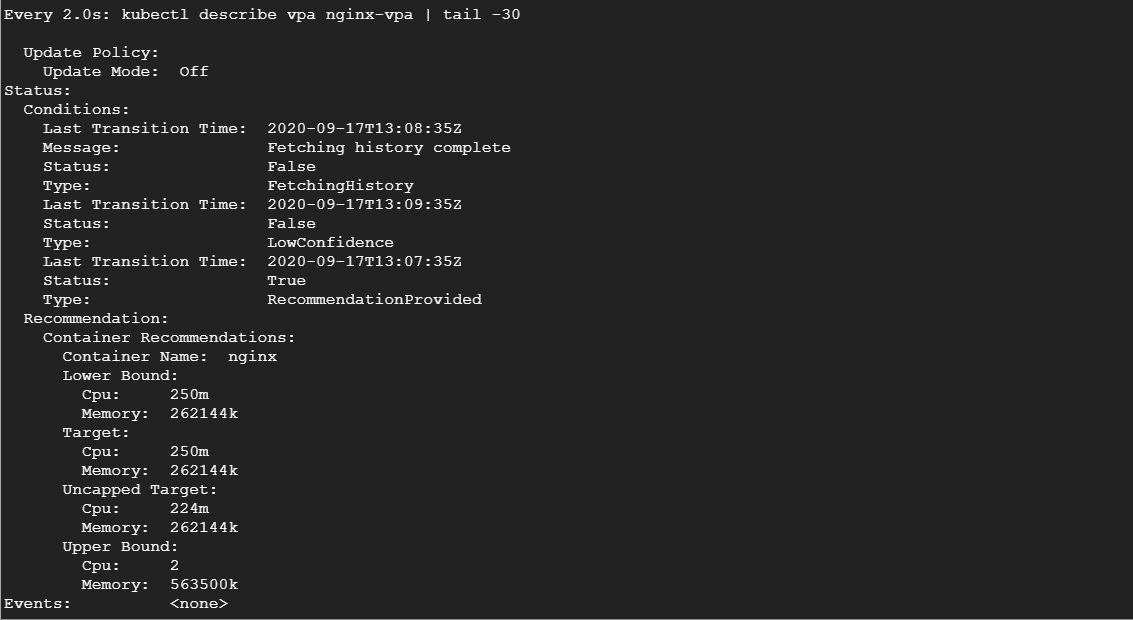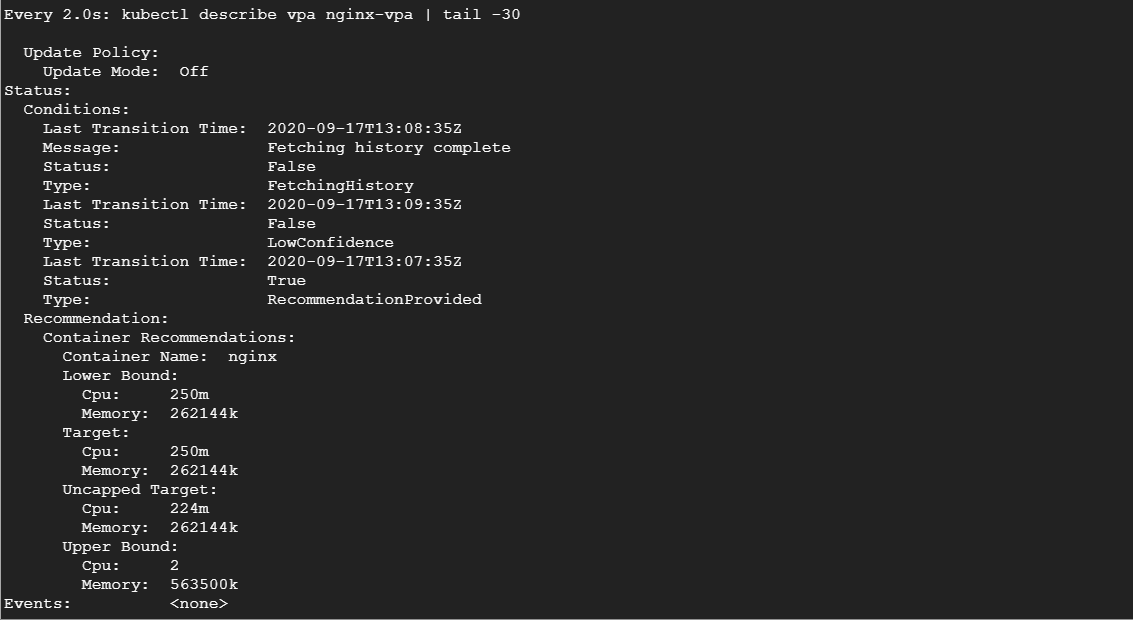
Взглянув на секцию рекомендации, вы увидите несколько предложений.
- Цель (Target): это реальное значение, которое VPA будет использовать, удаляя текущий под и создавая новый. Если вы очищаете эти метрики, всегда надо отслеживать целевое значение.
- Нижняя граница (Lower Bound): отражает нижнюю границу, при которой запускается изменение размера. Если загрузка вашего пода опустится ниже этого показателя, VPA его удалит и создаст меньший.
- Верхняя граница (Upper Bound): определяет верхнюю границу для изменения размера. Если использование пода превышает это значение, VPA удалит его и увеличит.
- Неограниченная цель (Uncapped Target): здесь определяется целевое использование в случае, если вы не задали верхнюю или нижнюю границы для VPA.
Теперь давайте запустим это и посмотрим, что произойдет, если установить updateMode на Auto. Запустим следующее:
$ cat <И затем заново запустим нагрузочный тест. На другом терминале будем наблюдать за подами и увидим, как они удаляются и воссоздаются.
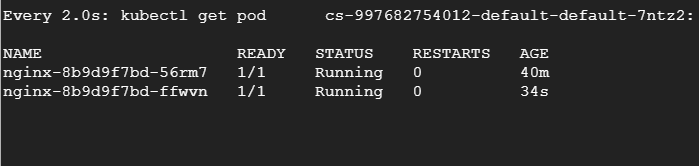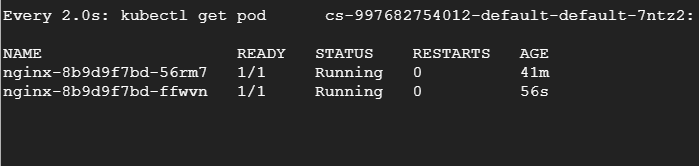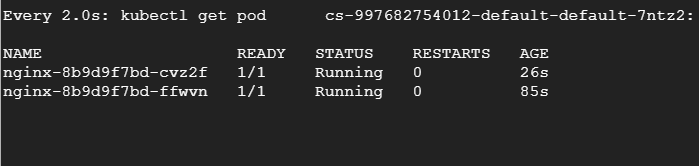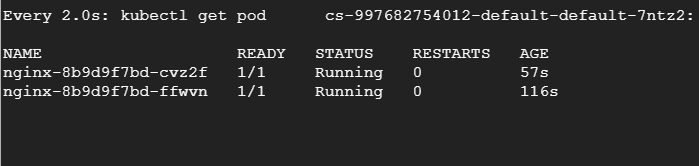
Заключение
Вертикальное автомасштабирование подов — относительно новая концепция автомасштабирования в рамках Kubernetes. Оно больше всего подходит для stateful-приложений или для профилировки использования ресурсов и рекомендаций. В текущей ситуации не рекомендую использовать его в производственной среде в автоматическом режиме, однако режим рекомендаций полезен для получения аналитических данных.
N.B. более подробно о горизонтальном автомасштабировании подов и работе stateful-приложений в кластере можно узнать с помощью видеокурса Kubernetes Мега.
