Разгоняем обработку событий до 1,6 миллионов в секунду
Когда участники HighLoad++ пришли на доклад Александра Крашенинникова, они надеялись услышать про обработку 1 600 000 событий в секунду. Ожидания не оправдались… Потому что во время подготовки к выступлению эта цифра улетела до 1 800 000 — так, на HighLoad++ реальность превосходит ожидания.
3 года назад Александр рассказывал, как в Badoo построили масштабируемую систему near-realtime обработки событий. С тех пор она эволюционировала, в процессе росли объёмы, приходилось решать задачи масштабирования и отказоустойчивости, а в определённый момент потребовались радикальные меры — смена технологического стека.

Из расшифровки вы узнаете, как в Badoo заменили связку Spark + Hadoop на ClickHouse, в 3 раза сэкономили железо и увеличили нагрузку в 6 раз, зачем и какими средствами собирать статистику в проекте, и что с этими данными потом делать.
О спикере: Александр Крашенинников (alexkrash) — Head of Data Engineering в Badoo. Занимается BI-инфраструктурой, масштабированием под нагрузки, руководит командами, которые строят инфраструктуру обработки данных. Обожает всё распределённое: Hadoop, Spark, ClickHouse. Уверен, что классные распределенные системы можно готовить из OpenSource.
Сбор статистики
Если у нас нет данных, мы слепы и не можем управлять своим проектом. Именно поэтому нам нужна статистика — для мониторинга жизнеспособности проекта. Мы, как инженеры, должны стремиться к улучшению наших продуктов, а если хочешь улучшить — измерь. Этого девиза я придерживаюсь в работе. В первую очередь, наша цель — это польза для бизнеса. Статистика дает ответы на вопросы бизнеса. Технические метрики — это технические метрики, но бизнес тоже заинтересован в показателях, и их тоже надо считать.
Жизненный цикл статистики
Жизненный цикл статистики я определяю 4 пунктами, про каждый из которых будем разговаривать отдельно.
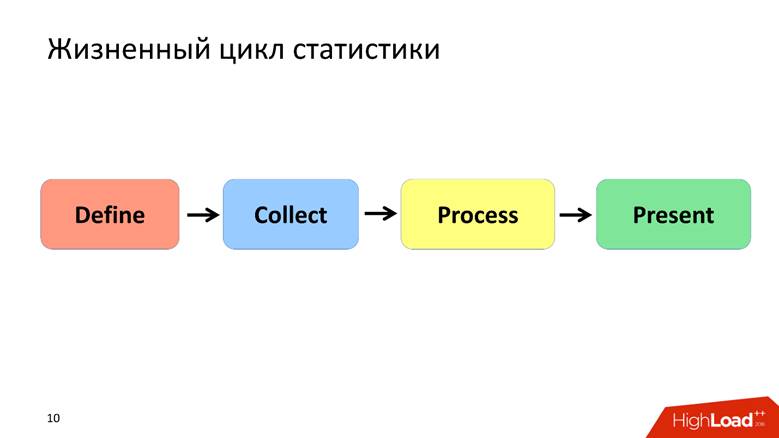
Фаза Define — формализация
В приложении мы собираем несколько метрик. В первую очередь, это бизнес-метрики. Если у вас фото-сервис, например, вам интересно, сколько фотографий заливают в день, в час, в секунду. Следующие метрики — «полутехнические»: отзывчивость мобильного приложения или сайта, работа API, насколько быстро пользователь взаимодействует с сайтом, инсталляции приложений, UX. Трекинг поведения пользователей — третья важная метрика. Это системы типа Google Analytics и Яндекс.Метрики. У нас своя классная система трекинга, в которую мы много инвестируем.
В процессе работы со статистикой задействовано много пользователей — это разработчики и бизнес-аналитики. Важно, чтобы все разговаривали на одном языке, поэтому надо договариваться.
Договариваться можно устно, но гораздо лучше, когда это происходит формально — в четкой структуре событий.
Формализация структуры бизнес-событий — это когда разработчик говорит, сколько у нас регистраций, аналитик понимает, что ему предоставили информацию не только об общем количестве регистраций, но и с разбивкой по странам, полу и другим параметрам. И вся эта информация формализована и находится в открытом доступе для всех пользователей компании. Событие имеет типизированную структуру и формальное описание. Например, мы у себя храним эту информацию в формате Protocol Buffers.
Описание события «Регистрация»:
enum Gender {
FEMALE = 1;
MALE = 2;
}
message Registration {
required int32 userid =1;
required Gender usergender = 2;
required int32 time =3;
required int32 countryid =4;
}
Событие регистрации содержит информацию о пользователе, поле, времени события и стране регистрации пользователя. Эта информация доступна аналитикам, и, в дальнейшем, бизнес понимает, что мы вообще собираем.
Зачем нужно формальное описание?
Формальное описание — это единообразие для разработчиков, аналитиков и продуктового отдела. Потом эта информация красной нитью пронизывает описание бизнес-логики приложения. Например, у нас есть внутренняя система описания бизнес-процессов и в ней скрин, что у нас есть новая фича.
В product requirements document есть секция с инструкцией, что когда пользователь взаимодействует с приложением таким образом, мы должны отправить event с точно такими же параметрами. Впоследствии мы сможем валидировать, насколько наши фичи хорошо работают, и что мы их правильно измерили. Формальное описание позволяет нам в дальнейшем понимать как эти данные сохранить в базе данных: NoSQL, SQL или других. У нас есть схема данных, и это круто.
В некоторых аналитических системах, которые предоставляются как сервис, в подноготной хранилища всего 10–15 событий. У нас это число выросло больше 1000 и не собирается останавливаться — без единого реестра жить невозможно.
Итоги фазы Define
Мы решили, что статистика — это важно и описали некую предметную область — это уже хорошо, можно жить дальше.
Фаза Collect — сбор данных
Мы решили строить систему так, что когда происходит бизнес-событие — регистрация, отправка сообщения, лайк — то одновременно с сохранением этой информации, мы отдельно отправляем некое статистическое событие.
В коде статистика отсылается одновременно с бизнес-событием.
Оно обрабатывается совершенно независимо от хранилищ данных, в которыхработает приложение, потому что поток данных проходит через отдельный конвейер обработки.
Описание через EDL:
enum Gender {
FEMALE = 1;
MALE = 2;
}
message Registration {
required int32 user_id =1;
required Gender user_gender = 2;
required int32 time =3;
required int32 country_id =4;
}
У нас есть описание события регистрации. Автоматически генерируется API, доступный разработчикам из кода, который в 4 строчки позволяет отправить статистику.
API на основании EDL:
\EDL\Event\Regist ration::create()
->setUserId(100500)
->setGender(Gender: :MALE)
->setTime(time())
->send();
Доставка событий
Это наша внешняя система. Мы так делаем потому, что у нас есть невероятные сервисы, которые предоставляют API для работы с данными о фотографиях, о чем-то еще. Они все хранят данные в классных новомодных базах, например, в Aerospike и CockroachDB.
Когда нужно построить какой-то репортинг, не надо ходить и побираться: «Ребята, сколько у вас тут этого и сколько того?» — все данные отправляются отдельным flow. Конвейер обработки — внешняя система. Из контекста приложения мы отвязываем все данные от хранилища бизнес-логики, и отправляем дальше в отдельный pipeline.
Фаза Collect предполагает наличие application серверов. У нас это PHP.
Транспорт
Это подсистема, которая позволяет отправить в другой pipeline то, что мы делали, из контекста приложения. Транспорт выбирается исключительно из ваших требований, в зависимости от ситуации в проекте.
У транспорта есть характеристики, и первая — гарантии доставки. Характеристики транспорта: at-least-once, exactly-once, вы выбираете под ваши задачи статистики, исходя из того, насколько эти данные важны. Например, для биллинговых систем недопустимо, чтобы в статистике отражалось больше транзакций, чем есть — это деньги, так нельзя.
Второй параметр — биндинги для языков программирования. С транспортом надо как-то взаимодействовать, поэтому он выбирается под язык, на котором написан проект.
Третий параметр — масштабируемость. Раз мы говорим о миллионах событий в секунду, то хорошо бы держать в уме задел на дальнейшую масштабируемость.
Вариантов транспорта много: РСУБД приложения, Flume, Kafka или LSD. Мы используем LSD — это наш особый путь.
Live Streaming Daemon
LSD не имеет ничего общего с запрещенными веществами. Это живой, очень быстрый стриминговый демон, который не предоставляет какого-то агента для того, чтобы в него записать. Мы его умеем тюнить, у нас существует интеграция с другими системами: HDFS, Kafka — мы можем отправленные данные перестримливать. У LSD нет сетевого вызова на INSERT, и в нём можно управлять топологией сети.
Самое главное, что это OpenSource от Badoo — нет повода не доверять этому программному обеспечению.
Если бы это был идеальный демон, то вместо Kafka мы бы на каждой конференции обсуждали LSD, но в каждом LSD есть ложка дёгтя. У нас есть свои ограничения, с которыми мы живем, которые нас устраивают: в LSD нет поддержки репликации и гарантия доставки у него at-least once. Также для денежных транзакций это не самый подходящий транспорт, но с деньгами вообще надо общаться исключительно через «кислотные» базы данных — поддерживающие ACID.
Итоги фазы Collect
На основании результатов предыдущей серии мы получили формальное описание данных, сгенерировали из них отличный, удобный для разработчиков API для отправки событий, и придумали, как эти данные транспортировать из контекста приложения в отдельный pipeline. Уже неплохо, и мы подходим к следующей фазе.
Фаза Process — обработка данных
Мы насобирали данные из регистраций, загруженных фотографий, голосований —что со всем этим делать? Из этих данных мы хотим получить графики с длинной историей и сырые данные. Графики все понимают — не надо быть разработчиком, чтобы понять по кривой, что доход компании растет. Сырые данные используем для оперативного репортинга и ad-hoc. Для более сложных случаев наши аналитики хотят выполнять аналитические запросы на этих данных. И тот, и тот функционал нам нужен.
Графики
Графики бывают разных видов.
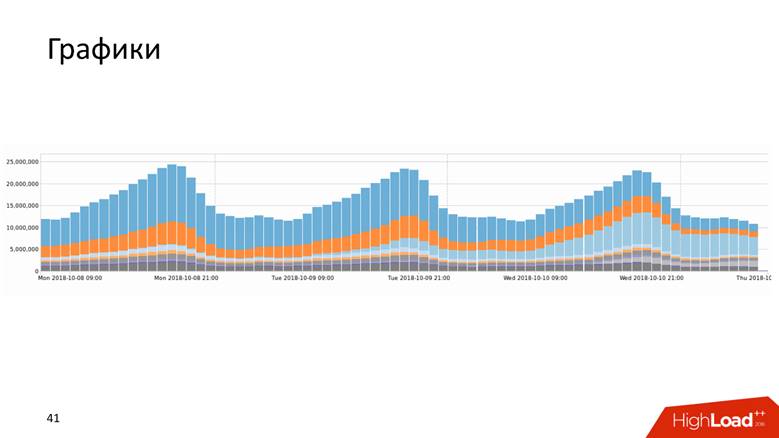
Или, например, график с историей, который показывает данные за 10 лет.
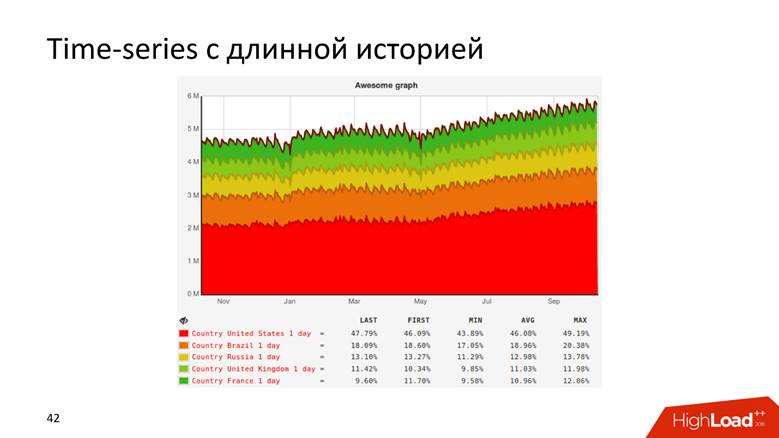
Графики бывают даже такие.
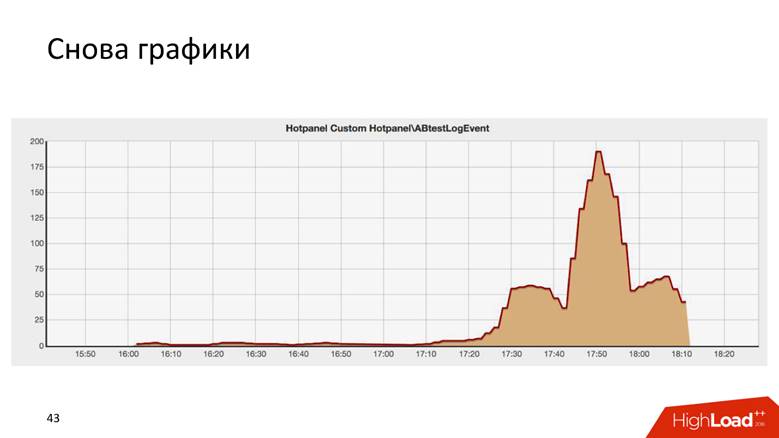
Это результат некоторого AB-теста, и он удивительно похож на здание Крайслера в Нью-Йорке.
Существует два способа нарисовать график: запрос к «сырым» данным и time series. Оба подхода обладают недостатками и достоинствами, на которых мы не будем подробно останавливаться. Мы используем гибридный подход: короткий «хвост» из сырых данных держим для оперативного репортинга, а time series для долгосрочного хранения. Второе вычисляется из первого.
Как мы доросли до 1,8 миллионов событий в секунду
Это долгая история — миллионы RPS не случаются за день. Badoo — это компания с десятилетней историей, и можно сказать, что система обработки данных росла вместе с компанией.
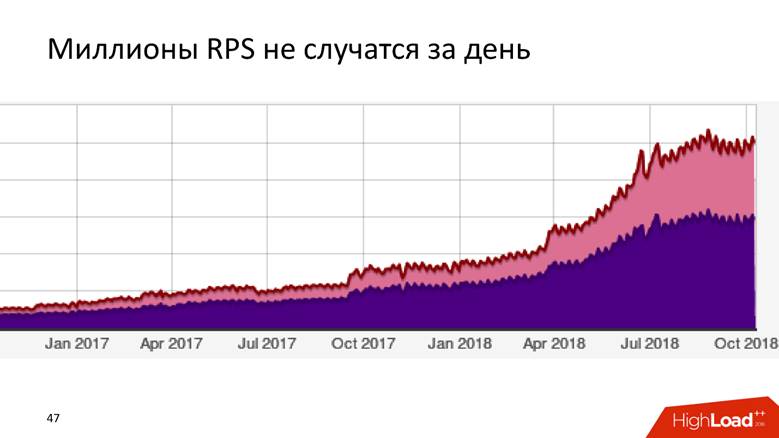
Сначала у нас не было ничего. Мы начали собирать данные — получилось 5 000 событий в секунду. Один хост MySQL и больше ничего! С этой задачей справится любая реляционная СУБД, и с ней будет комфортно: у вас будет транзакционность — кладете данные, получаете по ним запросы — все классно и неплохо работает. Так мы жили некоторое время.
В какой-то момент случился функциональный шардинг: данные о регистрациях -сюда, а о фотографиях — туда. Так мы дожили до 200 000 событий в секунду и начали применять разные комбинированные подходы: хранить не сырые данные, а агрегированные, но пока в пределах реляционной БД. Мы храним счетчики, но суть большинства реляционных БД такая, что на этих данных потом невозможно будет выполнить DISTINCT-запрос — алгебраическая модель счетчиков не позволяет посчитать DISTINCT.
У нас в Badoo есть девиз «Unstoppable force». Мы не собирались останавливаться и росли дальше. В момент, когда перешагнули порог 200 000 событий в секунду, приняли решение о создании формального описания, о котором я говорил выше. До этого был некий хаос, а теперь получили структурированный реестр событий: начали масштабировать систему, подключили Hadoop, все данные легли в Hive-таблицы.
Hadoop — это огромный программный комплекс, файловая система. Для распределенных вычислений Hadoop говорит: «Вот сюда поместите данные, я вам позволю выполнять аналитические запросы на них». Так мы и сделали — написали регулярный расчет всех графиков — получилось отлично. Но графики имеют ценность, когда они оперативно обновляются — раз в день смотреть на обновление графика не так весело. Если мы выкатили на продакшн что-то, приводящее к fatal error, то хотели бы увидеть падение графика сразу, а не через день. Поэтому вся система начала деградировать через какое-то время. Однако мы поняли, что на данном этапе можно придерживаться выбранного стека технологий.
Для нас Java была в новинку, нам понравилось, и мы поняли, что можно сделать по-другому.
На этапе от 400 000 до 800 000 событий в секунду, мы заменили Hadoop в чистом виде и Hive, как исполнителя аналитическихзапросов, на Spark Streaming, написали generic map/reduce и инкрементальный обсчёт метрик. Я еще 3 года назад рассказывал, как мы это сделали. Тогда нам казалось, что Spark будет жить вечно, но жизнь распорядилась иначе — мы упёрлись в ограничения Hadoop. Возможно, если бы у нас были другие условия, то мы бы продолжали жить с Hadoop.
Другой проблемой, помимо вычислений графиков на Hadoop, были неимоверные четырехэтажные SQL-запросы, которые гоняли аналитики, а графики обновляются не быстро. Дело в том, что там довольно хитрая работа с оперативным процессингом данных, чтобы это было реалтайм, быстро и круто.
Badoo обслуживается двумя дата-центрами, расположенными по двум сторонам Атлантического океана — в Европе и в Северной Америке. Чтобы построить единые репортинги, надо данные из Америки прислать в Европу. Именно в европейском дата-центре мы ведем весь учет статистики, потому что там больше вычислительных мощностей. Roundtrip между дата-центрами порядка 200 мс — сеть довольно нежная — сделать запрос в другой ДЦ это не то же самое, что сходить в соседнюю стойку.
Когда мы начали формализовать события и разработчики, и продакт-менеджерывтянулись, всем всё понравилось — случился просто взрывной рост эвентов. В это время пора было покупать железо в кластер, но мы не особо хотели это делать.
Когда мы прошли пик 800 000 событий в секунду, то узнали, что Яндекс выложил в OpenSource ClickHouse, и решили его попробовать. Набили вагон шишек, пока что-то пытались сделать, и в результате, когда все заработало, устроили небольшой фуршет по поводу первого миллиона событий. Наверное, на ClickHouse можно было бы и заканчивать доклад.
Просто возьмите ClickHouse и живите с ним.
Но это неинтересно, поэтому продолжим разговаривать про процессинг данных.
ClickHouse
ClickHouse — это хайп последних двух лет и не нуждается в представлении: только на HighLoad++ в 2018 году я помню порядка пяти докладов о нем, а также семинары и митапы.
Этот инструмент предназначен для решения именно тех задач, которые мы перед собой поставили. Там есть realtime update и фишки, которые мы получили в свое время от Hadoop: репликация, шардинг. Не было повода не попробовать ClickHouse, потому что понимали, что с реализацией на Hadoop мы уже пробили дно. Инструмент классный, а документация вообще огонь — я сам туда писал, все очень нравится, и все здорово. Но нам надо было решить ряд вопросов.
Как весь поток событий переложить в ClickHouse? Как объединять данные из двух дата-центров? От того, что мы пришли к админам и сказали: «Ребята, давайте засетапим ClickHouse», они не сделают сеть в два раза толще, а задержку в два раза меньше. Нет, сеть по-прежнему такая же тонкая, и маленькая, как первая зарплата.
Как хранить результаты? На Hadoop мы понимали, как рисовать графики —, но как это делать наволшебном ClickHouse? Волшебная палочка в комплект не входит. Как доставлять результаты до time series storage?
Как говорил мой лектор в институте, рассмотрим 3 схемы данных: стратегическая, логическая и физическая.
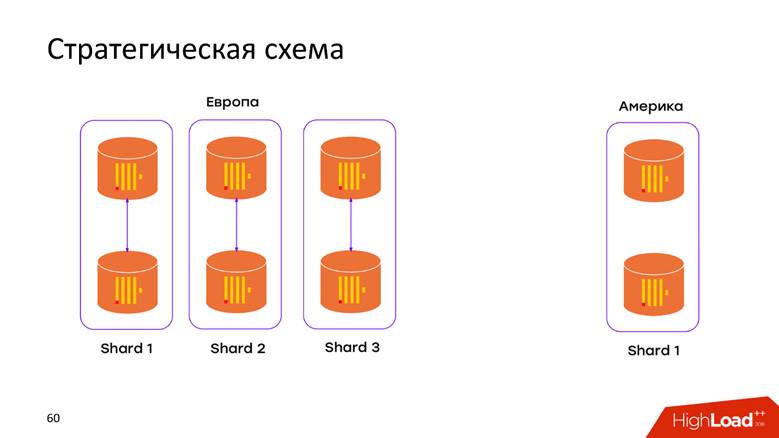
Стратегическая схема хранения
У нас есть 2 дата-центра. Мы узнали, что ClickHouse умеет ничего не знать про ДЦ, и просто засетапили в каждом ДЦ по кластеру. Теперь данные не переезжают через кросс-атлантический кабель — все данные, которые произошли в ДЦ, хранятся локально в своем кластере. Когда хотим произвести запрос над объединенными данными, например, узнать, сколько регистраций в обоих ДЦ, ClickHouse дает нам эту возможность. Низкая задержка и доступность для запроса — просто шедевр!
Физическая схема хранения
Опять вопросы: как наши данные лягут в реляционную модель ClickHouse, что сделать, чтобы не потерять репликацию и шардинг? В документации ClickHouse всё обширно описано, и если у вас больше, чем один сервер, вы наткнетесь на эту статью. Поэтому не будем углубляться в то, что есть в мануале: репликации, шардирование и запросы ко всем данным по шардам.
Логическая схема хранения
Логическая схема — это самое интересное. В одном pipeline мы обрабатываем гетерогенные события. Это означает, что у нас есть поток гетерогенных событий: регистрации, голоса, заливки фотографий, технические метрики, трекинг поведения пользователей — все эти события обладают совершенно разными атрибутами. Например, я посмотрел экран на мобилке — мне нужен id экрана, я за кого-то проголосовал — надо понимать, голос был за или против. Все эти события обладают разными атрибутами, по ним рисуются разные графики, но все это надо обрабатывать в едином pipeline. Как это засунуть в модель ClickHouse?
Подход №1 — per event table. Этотпервый подход, мы экстраполировали с опыта, полученного с MySQL — создавали табличку под каждый эвент в ClickHouse. Звучит довольно логично, но мы натолкнулись на ряд сложностей.
У нас нет ограничения на то, что событие изменит свою структуру, когда выйдет сегодняшний билд. Патчем это может сделать любой разработчик. Схема вообще во все стороны мутабельная. Единственное required-поле — это timestamp-событие и что за событие было. Все остальное меняется на лету, и, соответственно, эти таблички надо модифицировать. В ClickHouse есть возможность выполнять ALTER на кластере, но это деликатная нежная процедура, которую сложно автоматизировать, чтобы она работала безотказно. Поэтому это минус.
У нас больше тысячи различных событий, что дает нам высокий INSERT rate на одну машину — все данные постоянно записываем в тысячу таблиц. Для ClickHouse это анти-паттерн. Если у Пепсислоган — «Живи большими глотками», то у ClickHouse — «Живи большими батчами». Если этого не делать, то захлебывается репликация, ClickHouse отказывается принимать новые вставки — неприятная схема.
Подход №2 — широкая таблица. Сибирские мужики попробовали подсунуть бензопиле рельсу и применить другую модель данных. Мы делаем таблицу с тысячей колонок, где у каждого события зарезервированы колонки под его данные. У нас получается огромная разреженная таблица — к счастью это не ушло дальше разработческой среды, потому что уже с первых вставок стало ясно, что схема абсолютно плохая, и мы так делать не будем.
Но все-таки хочется использовать такой классный программный продукт, чуть-чуть еще допилить — и будет что надо.
Подход №3 — generic таблица. У нас есть одна огромная таблица, в которой мы храним данные в массивах, потому что ClickHouse поддерживает нескалярные типы данных. То есть мы заводим колонку, в которой хранятся названия атрибутов, и отдельно колонку с массивом, в котором хранятся значения атрибутов.
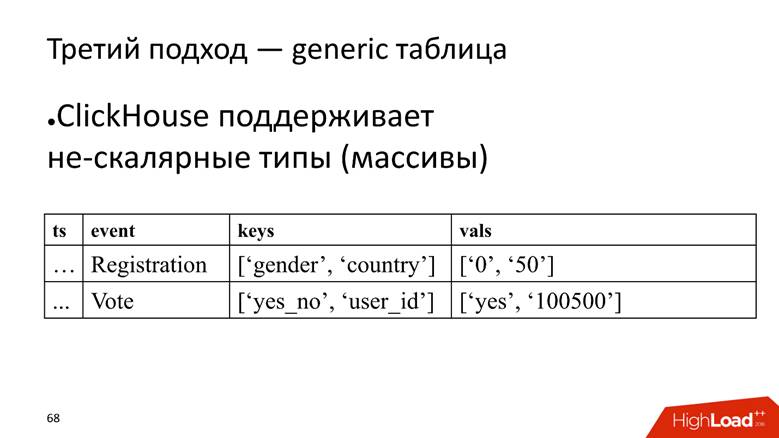
ClickHouse здесь свою задачу выполняет очень хорошо. Если бы нам надо было только вставлять данные, мы бы, наверное, еще раз в 10 больше на текущей инсталляции выжали.
Однако, ложка дегтя в том, что это тоже анти-паттерн для ClickHouse —хранить массивы строк. Это плохо, потому что массивы строк занимают больше места на диске — они хуже жмутся, чем простые колонки, и сложнее в обработке. Но для нашей задачи мы на это закрываем глаза, так как достоинства перевешивают.
Как делать SELECT из такой таблицы? У нас задача — посчитать регистрации, сгруппированные по полу. Надо сначала в одном массиве найти, какая позиция соответствует колонке gender, потом в другую колонку залезть с этим индексом и достать данные.
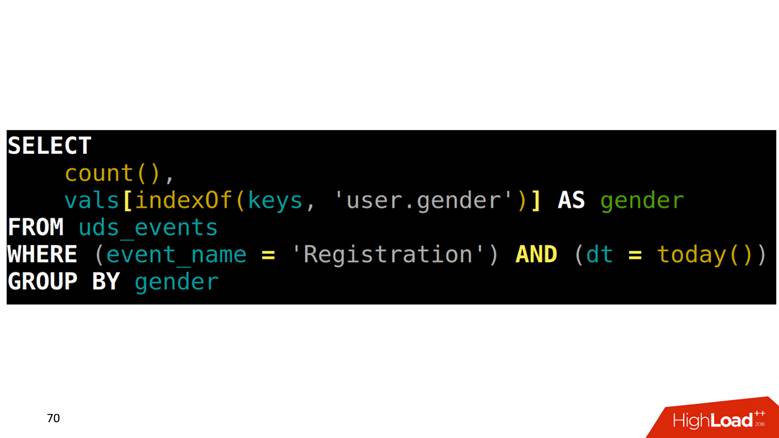
Как рисовать графики на этих данных
Поскольку все эвенты описаны, у них есть строгая структура, каждому типу события мы формируем четырехэтажный SQL-запрос, выполняем его и сохраняем результаты в другую таблицу.
Проблема в том, что для отрисовки двух соседних точек на графике, надо отсканировать всю таблицу. Пример: мы смотрим регистрации за сутки. Это событие от самой верхней строки до предпоследней. Просканировали один раз — отлично. Через 5 минут хотим нарисовать новую точку на графике — опять сканируем диапазон данных, который пересекается с предыдущим сканированием, и так — для каждого события. Звучит логично, но выглядит не здорово.
Вдобавок, когда мы берем какие-то строки, нам надо еще считать результаты под агрегации. Например, есть факт, что раб божий зарегистрировался в Скандинавии и был мужчиной, и нам надо посчитать сводную статистику: сколько всего регистраций, сколько мужчин, сколько из них людей, и сколько из Норвегии. Это называется в терминах аналитических баз данных ROLLUP, CUBE и GROUPING SETS — одну строчку превратить в несколько.
Как лечить
К счастью, в ClickHouse существует инструмент для решения этой проблемы, а именно — сериализованное состояние агрегатных функций. Это означает, что можно какой-то кусочек данных просканировать один раз и сохранить эти результаты. Это прямо киллер-фича. Мы 3 года назад сделали точно такую на Spark и Hadoop, и круто, что параллельно с нами лучшие умы Яндекса реализовали в ClickHouse аналог.
Медленный запрос
У нас есть медленный запрос — посчитать уникальных юзеров за сегодня и вчера.
SELECT uniq(user_id)
FROM table
WHERE dt IN (today(), yesterday())
В физическом плане мы можем сделать SELECT для состояния за вчерашний день, получить его бинарное представление, куда-то сохранить.
SELECT uniq(user_id)
‘xxx’ AS ts,
uniqState(user id) AS state
FROM table
WHERE dt IN (today(), yesterday())
Для сегодняшнего дня у нас просто меняется условие, что это будет сегодня: ‘yyy’ AS ts и WHERE dt = today() и timestamp мы назовем «xxx» и «yyy». Потом из таблицы с этими бинарными данными селектим и получаем в итоге, сколько у нас было людей вчера и сегодня, то есть за 2 дня.
SELECT uniqMerge(state)
FROM ageagate_table
WHERE ts IN (‘xxx’, ‘yyy’)
Инкрементальные вычисления
Тактика такова:
- квантуем время на минуты, над данными за минуту выполняем этот запрос;
- получаем результаты агрегатных функций в сериализованном виде;
- объединяем результаты.
То есть мы за сутки не сканируем все эвенты, а сливаем какое-то количество часовых или минутных промежуточных результатов. Эта техника позволила нам снизить время обработки в разы. Точных цифр не скажу, но она помогла нам выжить, потому что, когда мы сказали, что теперь всё классно считаем в ClickHouse, люди обрадовались: «О, теперь вам можно еще эвентиков налить! Давайте, сейчас посмотрим на вас!»
Как хранить эти результаты
Как мы помним, если у нас будет тысяча таблиц, это не очень хорошо. Поэтому результаты агрегации нужно сливать в одну таблицу, в которой будем хранить имена агрегатных функций и их значения. Это опять два массива. Преимущество этой таблицы — к ней можно написать SQL-запрос, который позволит аналитикам колдовать над этими результатами. Классно, что можно выполнить любые запросы над исходными данными, но результаты агрегаций тоже полезная информация.

Мы не забываем о том, что надо как-то нарисовать time series. Реализуем это посредством функциональности материализованных представлений: как только добавляем данные в таблицу, срабатывает триггер, который делает вставку в другую таблицу, предназначенную только для time series.
Таблица для time series проста как атом водорода: колонка с датой, колонка с именем метрики, колонка с точным timestamp и колонка со значением точки на графике. Когда вставляем результат выполнения агрегации над конкретным событием, у нас срабатывает триггер, который выглядит следующим образом. Нам надо получить имя метрики из таблички с массивами и взять от него хэш. Это важный момент, потому что в отличие от большинства баз данных, мы не храним здесь текстовое представление метрики, а берем от него хэш — это круто, он занимает меньше места. Да, математически у него возможны коллизии, но в ClickHouse существует хэш-функция, которая дает очень крутое распределение, и мы ее радостно используем.
Когда надо получить данные на клиенте, мы не знаем реальное значение этого хэша, и отдаем его на откуп ClickHouse:
— Вот тебе метрика «регистрация мужчин», так она выглядит — поколдуй и сделай из нее хэш.
Это дает нам выборку time series за 2 недели, то есть точки для 20 метрикза 20–80 мс. Это крутой результат. В ClickHouse есть функционал GraphiteMergeTree, который позволяет хранить time series, но наш подход круче и производительнее.
Параметры системы процессинга
8 серверов ClickHouse, из которых 6 в дата-центре в Европе, а 2 в Америке: фактор репликацииравен 2 — в одном шарде два сервера, и нам этого достаточно. В пике 1.8 млн. событий в секунду на вход, а выходнаямощность системы 500 тысяч метрик в секунду. Представляете, нам прилетает 1,8 млн, и мы умудряемся усиливать и выдавать 500 тысяч! Суммарно наша система знает больше миллиарда метрик.
Последствия перехода с Hadoop
Снижение задержки в 2 раза. Мы стали рисовать точки на графиках в два раза чаще. Экономия по памяти в 3 раза, а по CPU — в 4. Я считаю, что это очень внушительные и исключительно позитивные результаты.
Итоги фазы Process
Мы научились поэтапно выбирать технологии под нашу задачу, решили, что будем измерять, собрали данные в кучу и сделали крутейший процессинг. Это не значит, что вы прочитаете доклад, тут же возьмете ClickHouse и начнете писать 3 000 событий в секунду. Да, это возможно, но и возможно, что под вас это будет overkill.
Мы научились выбирать, а вы узнали, как мы проходили этот путь. Мы выбрали ClickHouse, и пока не нащупали его пределов. Уверен, что модель, которую мы используем, позволит масштабироваться и дальше. По моим оценкам, эти 8 серверов позволят пережить пик в 3–4 миллиона событий без добавления железа. Выше — решать проблемы вместе с железом.
Фаза Present — доступ к данным
Что с этими данными произойдет дальше, кто с ними будет работать? Мы нарисуем time series, у нас даже есть дашборды из time series, где разные люди из компании смотрят и пишут друг другу вопросы, почему здесь так, а здесь так.
Drop Detect — поиск отклонений на SQL: нехитрым SQL-запросом к таблице с результатами, которые мы посчитали по эвентам, можно выявить самое необычное поведение метрик.
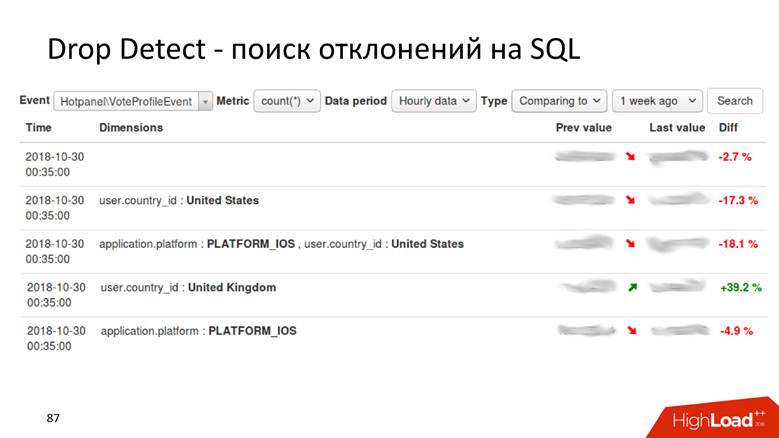
Это пока никакой не Anomaly Detection — простое сравнение нескольких точек на графике. У нас есть инструмент, который рассказывает, что голоса за профили просели на 2% в таком разрезе, а в другом — выросли на 40, и среди всех метрик, которые случились по этому эвенту, а их может быть десятки и сотни тысяч, это наиболее значимое изменение.
Это все здорово — можно построить мониторинг, задать границы, но хочется чего-то большого, поэтому приходит настоящий Anomaly Detection.
Anomaly Detection
Это система, которая берет time series данные. Они у нас иерархические: регистрация, регистрация мужчин, регистрация мужчин в Скандинавии. Для каждого time series графика вычисляются предсказание и границы. В случае, если актуальное поведение метрики выходит за границы, производится алертинг. Мы еще ранжируем примерно, как делает drop detection — когда видим наиболее интересные и значимые аномалии, производим алертинг.
Примерно так выглядит наш UI.
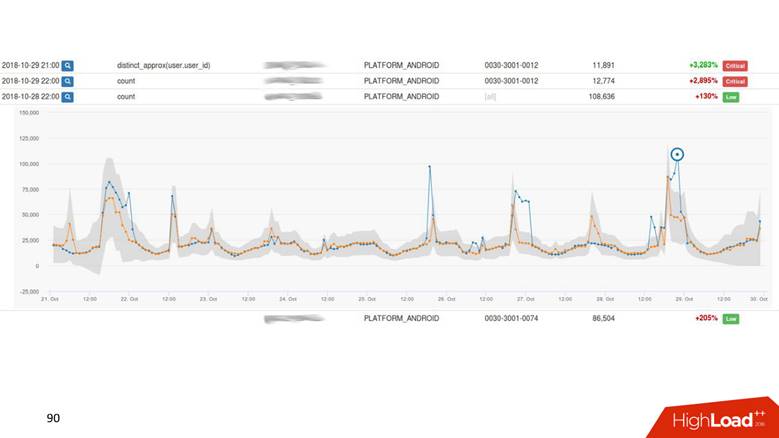
Аномалии отсортированы по весу. Есть какой-то внешний слой, который вылез за ширину доверительного интервала — серой области. Этим пользуются и продакт-менеджеры, и разработчики.
Итоги фазы Present
На основании классных технологий, которые мы применили на прошлом шаге, у нас появилась возможность рисовать графики. Отдел мониторинга теперь может настроить алертинг на основании жестких правил, которые задают разработчики: если метрика падает ниже 1000 — alarm, если метрика отлична от 0 — alarm. БД нам это позволяет.
Прикрутили наш Anomaly Detection со своей структурой данных, с табличками и колонками. Раньше у нас Anomaly Detection жил в аналитической системе Exasol, а теперь его данные также хранятся в ClickHouse. Этот переход позволил нам также ускорить процесс Anomaly Detection в 2 раза, просто сменив базу.
Заключительная фаза
Подытожим всё, что узнали, рассмотрев 4 этапа жизненного цикла статистики.
Мы поняли, зачем собирать статистику в проекте, и познакомились с техниками сбора, которые можно для этого применить. Мы рассмотрели, как поэтапно изменять стек технологий, и какмы прошли это изменение. Узнали, какие инструменты можно построить на базе статистических данных.
До следующего большого московского HighLoad++ еще далеко, но до ноября HighLoad++ успеет побывать в Санкт-Петербурге в апреле и в Новосибирске в июне. Это будут абсолютно самостоятельные конференции сосвоей программой, поэтому если вы хотите быть в курсе всего, вам нужно посетить их все:)
Кроме того, на май намечена PHP Russia и, какое совпадение, Александр Крашенинников входит в её программный комитет. То есть, возможно, именно тот человек, который ускорил обработку событий д 1,8 млн/с, будет помогать вам с докладом, если вы подадите заявку до 1 апреля.
