Разделение звука в видеозаписях
 Кадр из видео Super Mario Theme (Trumpet & Euphonium)
https://youtu.be/o3a6F070Xt0
Кадр из видео Super Mario Theme (Trumpet & Euphonium)
https://youtu.be/o3a6F070Xt0
Введение
Традиционно популярными и активно исследуемыми областями в Deep Learning являются задачи обработки изображений или текстов. Тем не менее, задачи, связанные с обработкой звуков и аудиодорожек, полезны и могут найти практические приложения во многих областях. Вот неполный перечень задач обработки звука, при решении которых используются подходы на основе глубокого обучения:
Классификация звуковых сигналов;
Speech2Text. Перевод речи в текстовое отображение;
Text2Speech. Обратная предыдущей задача. Генерация речи по заданному тексту;
Поиск похожий звуков;
Sound Separation. Разделение звуковой дорожки на составляющие звуки;
Beamforming. Разделение многоканальной звуковой дорожки на возможные составляющие с учетом пространственного расположения звукозаписывающих устройств.
В данной статье я расскажу о решении задачи Sound Separation, но с одним отличием — в качестве входных данных используются видеозаписи.
Для начала разберемся: что такое звук? Звук — это механические колебания, передающиеся в среде. Звуковые колебания характеризуются амплитудой и частотой. В среднем обычный человек может услышать звуки частотой 20Гц — 20000Гц. Для представления аудиоданных в цифровом формате микрофон с определенной частотой регистрирует амплитуду механических колебаний среды, затем полученные замеры преобразуются в цифровой формат. Таким образом, звук в вычислительных устройствах представляется как временной ряд. При этом, чем более высокая частота дискретизации, тем более высокие частоты получается сохранить.
Возможно представление аудио сигнала в виде трехмерной диаграммы, где на оси абсцисс изображено время, на оси ординат — частота звука. Третье измерение с указанием амплитуды на определенной частоте в конкретный момент времени представлено интенсивностью или цветом каждой точки изображения. Такое представление называется спектрограммой. Для получения спектрограммы из исходного аудио сигнала необходимо выполнить оконное преобразование Фурье.
 Пример спектрограммы
Пример спектрограммы
Такое представление позволяет применять двумерные сверточные нейронные сети в задачах обработки звука. Следует помнить, что в таком подходе не учитывается положение на изображении, хотя в случае спектрограмм это может быть важно. Например, в задаче классификации изображений совершенно неважно, находится объект внизу или вверху, при этом положение «внизу» и «вверху» на спектрограмме отвечает разным частотам, а значит разным звукам.
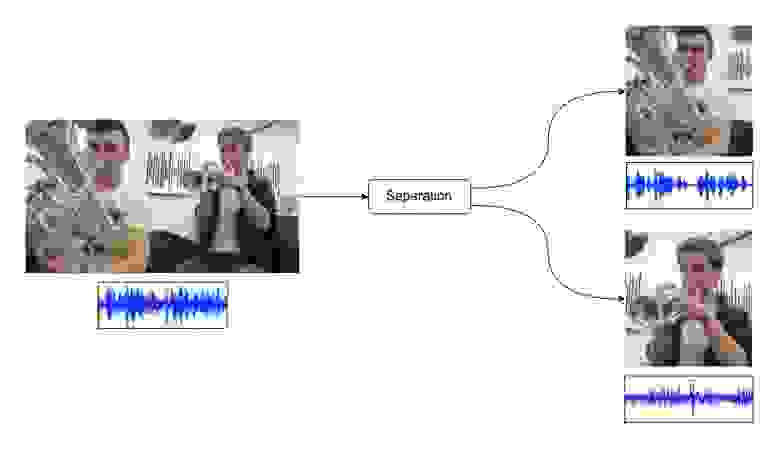
Задача разделения звуков заключается в получении аудиодорожек отдельных источников звука по одной аудиозаписи с несколькими источниками.

 — исходная аудиодорожка, «смесь» отдельных звуков
— исходная аудиодорожка, «смесь» отдельных звуков  — i-тая компонента звука
— i-тая компонента звука  — число компонент звука
— число компонент звука
Разделение звука
Задача локализации — поиск источников звука в кадре и отделение от общей аудиодорожки.
Локализация звуков
Подобрать метрику, которая идеально оценивала качество модели, не так просто. Это связано со сложностью самих звуковых данных, а так же с тем, что восприятие результата может быть субъективно. Несколько человек могут по-разному оценить качество разделения в зависимости от их музыкального слуха и других факторов. Зачастую, в задачах разделения звука используют метрику SDR, дополнительно можно вычислять SIR и SAR.
SDR — source to distortion ratio, общая оценка того, насколько хорошо источник звучит
SIR — source to interference ratio, оценка того, насколько хорошо звук отделен от остальных источников
SAR — source to artifact ratio, оценка того, насколько хорошо звук изолирован от нежелательных артефактов
Теперь, определившись с задачей и метриками, можно посмотреть как решать такую задачу.
Модель
Расскажу про подход, предложенный в статье Sound-of-Pixels. Модель состоит из нескольких частей: визуальная, аудио и синтезатор. Для начала определимся, что передается на вход в модели. Исходными данными для модели являются видеозаписи с источниками звука. Видеозапись можно представить как последовательность кадров и аудиодорожка. Аудиодорожку из одномерного представления можно перевести в спектрограмму. Таким образом, на вход модели будем подавать несколько кадров из видео и спектрограмму аудиодорожки.
Архитектура модели
Для вычисления признаков из кадров видео используется ResNet, для генерации аудио признаков из спектрограммы применяется U-Net подобная архитектура. После вычисления видео и аудио признаков они комбинируются с некоторыми обучаемыми весами и на выходе модели получаются сетка из масок. Маска — это одноканальное изображение с таким же размером, как и у входной спектрограммы, каждый пиксель маски принимает значения от 0 до 1. Впрочем, маска может быть бинарной, тогда значения — это 0 или 1. При поэлементном умножении маски на исходную спектрограмму смеси получается спектрограмма изолированного источника звука, а по спектрограмме можно восстановить аудиодорожку изолированного звука.
При вычисления визуальных признаков пространственные размерности уменьшаются в 16 раз. При использовании кадров размером 224×224 выходная пространственная размерность получается 14×14. И в каждой пространственной точке получается визуальный размер признаков размерности K (гиперпараметр, подбирается в зависимости от датасета). Сеть синтезатор для каждой пространственной точки совмещает визуальные признаки и аудио признаки и предсказывает маску для спектрограммы. Получается маска для звуков, источники которых находятся в соответствующем участке исходных кадров.
Выход модели
Обучить такую модель напрямую проблематично, поэтому авторы предлагают несколько трюков. Обучение проводится по видео с отдельными источниками звука. Если рассматривать музыкальный домен, то подойдут видео с соло исполнениями на музыкальных инструментах. Дополнительной разметки при этом не требуется, но при обучении делается несколько допущений. Во-первых, во время обучения не предсказывается сетка масок, после визуальной сети берется макспулинг по пространственным размерностям и маска вычисляется одна на весь кадр. Во-вторых, звук аддитивен, а это значит, что при сложении двух аудиозаписей в соло исполнении получается запись исполнения в дуете.
Для обучения из выборки семплируется пара видеозаписей, т.е. объект для обучения — это две видеозаписи. Аудиодорожки складываются и получается дорожка с несколькими источниками звука. В аудио часть модели подается смесь, а в по кадрам первого и второго видео вычисляются соответствующие вектора визуальных признаков. Теперь можно применить синтезатор к аудио признакам и видео признакам от первого и второго видео и получить на выходе маску для извлечения исходных аудиодорожек из смеси. Исходные аудиодорожки нам известны, можно посчитать функцию потерь между предсказанными дорожками и исходными и обновить веса модели.
Обучение модели
Остается вопрос — где взять данные для обучения? Для обучения на музыкальных инструментах использовался датасет MUSIC, для обобщения модели на общий звуковой домен использовался датасет VGGSound. Данные собраны из видео на youtube, но сами датасеты — это .csv файлы с id видео. Сбор, загрузку и предобработку записей нужно выполнять своими руками. MUSIC содержит ~600 видеозаписей с соло исполнением на 11 (есть часть с 21) музыкальных инструментах, а также видео с исполнениями в дуете. Все исполнения любительские, произведены в повседневной обстановке без использования профессионального оборудования. VGGSound намного больше, датасет содержит более 200 тысяч видеозаписей, а также разметку на 310 классов звуков (указывается временной отрезок в видео и метка звука, который звучит в этом отрезке)
Результаты
Давайте теперь посмотрим на результаты обученной модели. Сначала я покажу, как работает модель на музыкальных инструментах, затем на общих звуках из VGGSound.
Разберем разделение на этапе валидации на примере двух видео. Возьмем два видео с соло исполнениями, сложим их аудиодорожки и разделим обратно.
Разделение гитары и скрипки
По полученным спектрограммам можно восстановить звук и получить финальный результат
Модель работала в режиме валидации, который приближен к обучению. Визуальные признаки в этом случае считались по всему кадру, разбиения на регионы не было. Теперь можно посмотреть на результаты модели, которая не только разделяет источники, но и ищет их в кадре.
Локализация источников звука
Теперь, если взять полученную модель и обученный детектор объектов в кадре, то можно усреднять маски в предсказанных boundary box детектора и получать звуки, издаваемые объектами в кадре.
Приведу метрики, которые я получал в результате наиболее удачных экспериментов. За baseline я взял метрики, которые авторы указали в своей статье. В приведенных экспериментах я использовал размерность признаков K=16. В других экспериментах пробовал различные значения, но они дают худший результат. В статье же авторы указывают, что по их экспериментам размерность K=32 работает лучше.
SDR | SIR | SAR | |
baseline | 8.87 | 15.02 | 12.28 |
BCE loss, бинарная маска | 10.56 | 21.24 | 13.96 |
BCE loss, регуляризация сценами с тишиной | 8.27 | 17.69 | 12.07 |
L2 loss, непрерывная маска | 5.87 | 15.41 | 15.03 |
Перейдем к датасету VGGSound. Приведу пример разделения детского плача и шума от работы погрузчика.
Разделение общих звуков
По вычисленным спектрограммам можно собрать аудиодорожки.
Локализация работает, но не идеально. Например, в кадре с вертолетом в небе у модели получается выделить звук в центре кадра.
Локализация источника звука (вертолета)
Есть и неудачные примеры.
Локализация источника звука (человек)
Модель определяет источник звука в центре, но по краям кадра также дает ненулевые маски. В целом же, модель, обученная таким способом на звуках из общего домена, работает.
Наилучшая модель на валидации получилась со следующими метриками:
SDR | SIR | SAR | |
K=32, BCE loss | 3.62 | 9.43 | 11.78 |
Сравнивать напрямую метрики на MUSIC и VGGSound, как я считаю, не очень корректно, т.к. датасеты совсем разные, VGGSound гораздо больше и вариативнее. Из-за этого оптимальным значением для размерности вектора признаков оказалось 32.
Трудности
В процессе воспроизведения статьи я столкнулся с рядом трудностей, о которых хотел бы упомянуть.
Сбор данных — довольно трудоемкий процесс. Даже несмотря на то, что есть размеченные датасеты, загрузка данных из источников требует времени и аккуратности. Каждая видеозапись требует времени на скачивание, времени на обработку, а также объем на диске. Уместить весь VGGSound локально я не смог, поэтому после скачивания сразу вырезал из видео нужный участок, раскладывал его на кадры и аудиодорожку, приводил картинки к меньшему размеру и понижал частоту дискретизации аудио дорожки. Стоит также сказать, что youtube не дает открыто массово скачивать контент с ресурса, поэтому пришлось применить некоторые трюки. Помимо этого, нет никаких гарантий, что указанные в датасете видео будут доступны на видеохостинге всегда, и, конечно же, это не так. Некоторые видеозаписи из датасета скрыты, удалены, заблокированы.
Авторы оригинальной работы опубликовали код, но он оказался неполным и немного устаревшим. Потребовалось обновить код для совместимости с современной версией PyTorch, исправить несколько неочевидных нюансов, а также дописать код для выполнения локализации и демо (локализация + детектор)
Архитектура модели довольно сложная, из-за чего появляется много гиперпараметров и похожих решений, которые можно попробовать и улучшить результат. Основной гиперпараметр — размерность вектора признаков K. Это значение крайне желательно подбирать. Сама модель состоит из нескольких, каждая из архитектур обладает своими особенностями и потенциалом для улучшения. Понятно, что посмотреть на все комбинации улучшений для каждой из модели очень трудоемко и можно смотреть на каждую модель по очереди.
Обучение модели занимает довольно много времени. На личном компьютере (Nvidia RTX 2070 Super) обучение на MUSIC занимает 4 суток, на VGGSound 6 суток. Из-за этого каждый эксперимент занимал много времени, по этой причине пункт выше становится еще более актуальным.
Заключение
В статье я рассказал о том, как можно научить модель находить источники звука в видеозаписи без явной разметки. Это отличается от большинства существующих решений, требующих для обучения смесь звуков и разделенные звуки. Такие датасеты есть, но их немного и, что более важно, они небольшие и основаны на музыкальных композициях (MusDB, например). В рассмотренном подходе удалось научить модель разделять звуки из общего домена.
На практике такую модель можно применять, например, для удаления посторонних шумов в кадре, выделения речи людей и другие подобные задачи.
