Рассылка пуш уведомлений на Go31.08.2015 07:18

Жила-была рассылалка пушей на node.js, которая кое-как свою работу по рассылке нескольких миллиардов пушей в сутки на четыре платформы выполняла. Но это «кое-как» никого не устраивало. Да и стабильностью решение в целом не отличалось. Вот и заменили ее на реализацию на Go. Что из этого вышло под катом (в довольно общих словах почти без кода).
Архитектура простая: происходит некоторое событие, нужно о нём уведомить N’ное число получателей, причем содержимое пушей персонализированно. На каждого получателя формируется пачка пушей (для всех привязанных устройств) и складывается в очередь отправки.
Пушилка должна эти пуши оттуда достать, отправить куда надо, да и статистику обновить.
Из очередей доставать можно лишь через внешнее API, отдающее пачки пушей только для затребованных платформ (это ещё понадобится ниже). Все платформы обрабатывает один процесс, распределяя пуши по обработчикам, которые уже знают, что и как нужно сделать со своим типом.
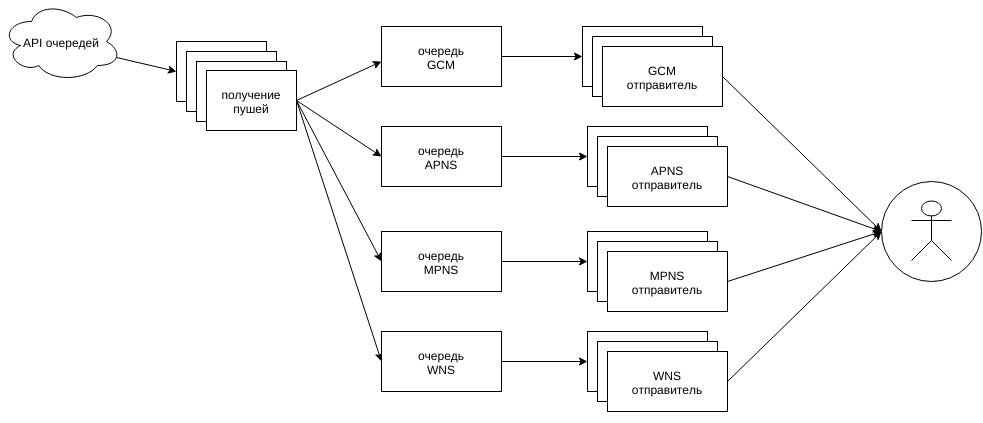
Схема упрощенная: к и от сгруппированных блоков должно идти соответствующее число связей, а не как на схеме по одной.
Получение пушей от API
Так как единственным способом получения пушей является внешнее API с доступом по HTTPS, то получение работает просто через http.Client с увеличенным MaxIdleConnsPerHost для поддержки keep-alive. Несколько горутин, разделяя этот общий http.Client, постоянно стучатся в API за свежей пачкой пушей. Если приходит полная пачка (порядка 1–3к пушей) — следующий запрос уходит сразу же, если сильно меньше, чем хотели — запрос уходит с небольшой паузой.
Тут ловим двух зайцев: даём накопиться очереди, либо, если проблема в начавшем тормозить внешнем узле, снижаем на него нагрузку. Если запросы не проходят вообще, или подвисают, то по истечению некоторого периода (порядка пары минут), закрываем все соединения и создаем новый объект http.Client.
В итоге получаем постоянный поток свежих данных на обработку, распределяемых по целевой платформе в соответствующие очереди (обычные буферизированные каналы).
При этом мониторится заполненность очередей, и, если какая очередь забивается очень сильно (более 50%), то рассылалка перестает запрашивать этот тип у API.
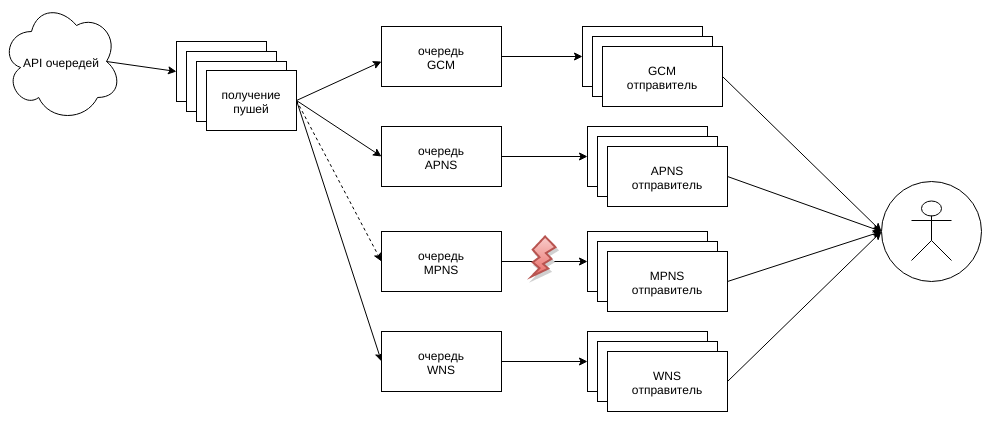
Отправители пушей
Логика рассылки пушей варьируется между платформами, но так или иначе они реализуют общий интерфейс, объединяющий их в пулы воркеров.
Размерами этих пулов управляет общий менеджер соединений, следящий за размерами каналов принятых пушей. При превышении заполненности сверх 10% от вместимости каналов, менеджер расширяет пул в пределах разрешенного в конфиге для конкретной платформы и мобильного приложения, зарегистрировавшегося как получатель пушей.
Чем ценнее приложение — тем больше ему можно :) Такого бы не было, если бы не приходилось рассылать пуши на кучу всевозможных сторонних приложений, даааааалеко не все из которых следят за своими сертификатами и актуальной регистрацией приложений.
Наращивание емкости пулов выполняется шагами (не по одному, а пачками), с минимальным временем между двумя расширениями, чтобы новосозданные успели войти в рабочий ритм. В конфиге максимальные лимиты задраны весьма высоко, на случай массовых проблем (как-то успело сломаться ~80% пушилок, прежде чем начались задержки в доставке, т.к. оставшиеся вытянули на себе больше положенного).
Соединений нужно очень много, и не обошлось без повышения umilit -n до уровня в >10к дескрипторов. Ну и в Go подтягиваем лимиты сразу до позволенного максимума примерно так:
var rLimit syscall.Rlimit
if err := syscall.Getrlimit(syscall.RLIMIT_NOFILE, &rLimit); err != nil {
return nil, err
}
if rLimit.Cur < rLimit.Max {
rLimit.Cur = rLimit.Max
syscall.Setrlimit(syscall.RLIMIT_NOFILE, &rLimit)
}
Общий канал конкретной целевой платформы (gcm и т.п.) разделяется на множество каналов (и пулов воркеров для их обработки) по каждому зарегистрированному у нас приложению. Специальные горутины раскидывают входящий поток пушей по каналам конкретных приложений, пока какой-то из них не начинает забиваться. Здесь в дело вступает масштабирование пулов, досоздающее воркеров для конкретного приложения. Если расти уже некуда, то тут два варианта: проблема с критически важным для нас приложением или нет.
В случае важного приложения просто перестаем разгребать входящий канал пушей, он начинает забиваться, это видят воркеры, получающие пуши от API, и просто убирают конкретную платформу из своих запросов. И пуши или перераспределяются по другим пушилкам, или начинается рост очереди, и это уже видно на мониторинге.
А если приложение не особо важное, и лимиты на него исчерпаны — то увы, пуши будут отбрасываться без обработки (но эти отбрасывания появятся в статистике).
Так же ведется внутренняя статистика (внутри приложения) по числу проблем с конкретными приложениями (кривые сертификаты, обрывы соединения с серверами, таймауты при отправке и т.п.) и при превышении «чаши терпения» такие приложения получают временный бан — все пуши отбрасываются без обработки все время действия бана.
Это очень полезная функция на случай сторонних приложений-однодневок или неожиданно ставших популярными приложений, у которых нет нормальных сертификатов, а пушей они генерят больше лимитов целевых платформ. Были случаи, когда мы сами писали представителям этих приложений и намекали им, что хорошо бы им доделать эту часть у себя, чтобы получать пуши нормально.
Ну и, конечно, нужно идти на всё во имя keep-alive и кеширования сертификатов, иначе приложение мгновенно встанет колом, ибо ошибки взаимодействия будут всегда, и от переподключений никуда не уйти.
Во всех воркерах есть внутренние буферы переотправки на случай сбоя, которые мы считаем не фатальным (таймаут запроса, или 502 код ответа, к примеру). Выглядит примерно так:
for {
select {
case push := <-mainChan:
send(push)
case push := <-resendChan:
send(push)
default:
// ...
}
}
func send(push Push) {
if !doSmth(push) {
resendChan <- push
}
}
Благодаря отсутствию гарантии в порядке выбора из нескольких вариантов в select получаем поочередную выборку из обоих каналов. Сверх этого есть еще лимиты на число переотправок, таймауты до переотправки, но это уже за рамками материала.
APNS

Больше всего (пока что?) по работе отличаются пуши для яблочной продукции, где общение с удаленной стороной происходит через tls соединение с отправкой бинарных пакетов.
По документации, сообщение об ошибке (если такая возникла, например старая авторизация или некорректно сформированный запрос) должно придти по этому же соединению впоследствии.
Т.к. ждать ответа (которого обычно и нет) на каждый запрос слишком медленно, то приходится складывать все отправленные пуши и чуть дополнительной информации в отдельные списки отправленных, но не подтвержденных пушей (используется list.List). И ждать ответа. Сколько ждать, тоже не особо понятно. В данном случае время ожидания выбрано в 2 секунды (меньше, бывало, не хватало).
При получении ответа мы узнаем номер пуша (передается с каждым пакетом), с которым или возникла какая-то ошибка, или все хорошо. Соотвественно, все пуши ДО указанного можно считать подтвержденными в доставке, конкретно этот пуш отбрасываем или отправляем еще раз. Все пуши после указанного остаются в списке до следующего сообщения об ошибке, или по истечению времени ожидания. Пуши, пролежавшие в очереди больше 2 секунд, считаем «отправленными по таймауту».
Плюс, есть еще отдельное соединение с серверами Apple, по которому нам прилетают входящие пакеты с данными по «отписавшимся» приложениям. Его обрабатывает отдельная горутинка, по одной на каждое клиентское приложение.
В итоге получаем бесконечное перекладывание пушей между каналами получения, очередями неподтвержденных и повторной переотправкой (может происходить многократно для каждого пуша).
К этому еще можно добавить, что приходят иногда ошибки, не описанные в документации. Или (самое популярное) соединение рвется без какого-либо уведомления об ошибках. Красота же)
Реализация прокачивает примерно (это лишь число доставленных или отброшенных, не всех) 1.4 миллиарда apns пушей в сутки (~30к-33к в секунду в пики) на ноутбуке с мобильным процессором i7–4500U (во имя тестов, конечно).
Но, как недавно узнал, Apple планирует реализовать схему, как у других — через http запросы. Посмотрим.
GCM
Самая адекватная платформа. Логика воркеров была написана буквально за 1–2 дня и с тех пор просто работает. Создаем http.Client с MaxIdleConnsPerHost побольше (несколько тысяч), и шлем POST запросы. Сервера отвечают быстро, документация хорошая — красота. В пиковое время выходит близко к 100к пушей в секунду.
XMPP вариант не пробовал, но, будет время, попробую. Хотя, «работает — не трожь».
MPNS, WNS

Это худший из всех вариантов, особенно MPNS. Тут тебе и ожидание ответа по 1–2 секунды (просто нет слов!), и получение стектрейсов вместо xml с ошибкой (и это после ожидания тех самых 1–2 секунд).
пример кусков ответа
\r\n\r\n
\r\n
Insufficient memory to continue the execution of the program.<\/title>\r\n<br />…<br />OutOfMemoryException: Insufficient memory to continue the execution of the program.]\r\n System.CodeDom.Compiler.Executor.ExecWaitWithCaptureUnimpersonated (SafeUserTokenHandle userToken, String cmd, String currentDir, TempFileCollection tempFiles, String& outputName, String& errorName, String trueCmdLine) +3231\r\n<br />…<br />This error page might contain sensitive information because ASP.NET is configured to show verbose error messages using <customErrors mode=\«Off\»\/>. Consider using <customErrors mode=\«On\»\/> or <customErrors mode=\«RemoteOnly\»\/> in production environments.<br />…<br /></p>
</div><p>
<br />Хуже всего то, что иногда такой ответ не означает, что пуш не был принят и доставлен. И повторная отправка с нашей стороны приводит к приходу на устройство двух одинаковых пушей. А, как оказывается, людей больше огорчают два пуша, чем их отсутствие в принципе.</p>
<p>Отдельно стоит рассказать про TLS Renegotiation, который требуется для отправки с сертификатом (без него быстро упираешься в лимиты на отправку), но не поддерживается в Go, да и вообще повсеместно выпилен.</p>
<p>Для этого приходится слать пуши через cgo обертку над curl. Но решение выходит так себе по стабильности — каждые несколько миллионов запросов есть вероятность словить sigsegv где-то внутри системных либ. Для временного решения этой проблемы работа с curl через cgo была вынесена в отдельное небольшое (~400 строк) приложение на всё том же Go, работающего по принципу: пушилка => «http сервер => https curl tls renego client» => сервера MS.<br />Таких приложений запускается отдельный небольшой пул со своим менеджером, мониторящим падения. Эти промежуточные прокси отвечают основной пушилке как ответом внешних серверов, так и добавляют в заголовки отсебятину для отладки и статистики: время ответа, код ответа прокси (в дополнение к коду ответа внешнего сервера), и т.п. Все это даёт возможность довольно таки надёжно отправлять пуши в нестабильной обстановке.</p>
<p>Кстати, вместо MaxIdleConnsPerHost не забываем задавать CURLOPT_MAXCONNECTS побольше, иначе опять не взлетим по CPU.</p>
<p><em>А ведь именно в этой платформе текст пуша и badge (число у иконки приложения) необходимо задавать двумя разными независимыми запросами (а в WNS тремя). Смело умножаем вышеприведенные секунды ожидания и глюки на два (три) и идем дальше…</em></p>
<h3>Сбор статистики</h3><p>
<br />Как бы это все вместе ни работало, нужна статистика. Причем чем подробнее, тем лучше.<br />Мониторится как код наполнения очередей (тот, который еще до API), так и работа методов API, и сами приложения рассылки.</p>
<p>Главной характеристикой идет время отправки: сколько времени проходит от момента генерации пуша и до подтвержденной отправки на сервера конкретной площадки. Для быстрых GCM и APNS среднее время выходит порядка 60–100 мс на весь путь обработки, для MPNS/WNS как повезет: быстрее, чем работают сервера MS мы отправить не можем.</p>
<p>Ведется статистика по: <br /></p>
<ul><li>число отправленных, отброшенных, вернувших ошибку при отправке, с просроченными авторизациями (для них нужно еще и сами токены отправить, и отбрасывать их, пока они еще есть в очередях отправки, а не пробовать отправить-снова получать ошибку-переустанавливать соединение); </li>
<li>время обработки: min/max/avg по каждой платформе и каждому приложению отдельно; </li>
<li>uptime процесса, использование cpu (с разделением по user, system, io, idle), число открытых файловых дескрипторов, потребление памяти (rss), время на работу gc суммарно и min/max/avg последних запусков.</li>
</ul>
<p><br />Всё это собирается и отправляется пачками всё в тоже API.</p>
<p>Однако, сохранять статистику по каждому пушу из каждой горутины (а ведь их много тысяч) в единое место крайне накладно. Поэтому, все воркеры собирают свои статистики сначала у себя локально, и лишь время от времени (раз в несколько секунд) сливают ее в общее место. Примерный код: <br /></p>
<pre>
<code class="go">type Stats struct {
sync.RWMutex
ElapsedTime ...
Methods ...
AppID ...
...
}
addStatsTicker := time.Tick(5 * time.Second)
for {
select {
case <-addStatsTicker:
globalStats.Lock()
gcm.stats.Lock()
mergeStatsToGlobal(&gcm.stats)
cleanStats(&gcm.stats)
gcm.stats.Unlock()
globalStats.Unlock()
case push := <-mainChan:
// таких статистик много, это пример одной из них
gcm.stats.Lock()
statsMethodIncr(&gcm.stats, push.Method)
statsAppIDIncr(&gcm.stats, push.AppID)
gcm.stats.Unlock()
send(push)
// ...
}
}
</code>
</pre>
<h3>Выборочное логгирование</h3><p>
<br />В дополнение к общей статистике пушилки позволяют логгировать все ключевые шаги при обработке выборочных пушей.<br /><img src="https://habrastorage.org/files/3be/e80/6df/3bee806df01e4ea7bc598144ec47661e.png" alt="3bee806df01e4ea7bc598144ec47661e.png" /><br />Если из очереди приходит пуш со спец флагами, то все действия по обработке данного пуша отправляются в канал debug логгера, отсылающего эти логи все так же в API. Собираются не только факты успешности/ошибки, но и все важные подробности: ключевые ветвления при выборе, значения переменных и буферов, точное время с миллисекундной точностью. Все это позволяет довольно точно понять, что пошло не так по самим этим логам при проблемах вида «вот кому-то не пришел пуш вчера в такое время», «пришло два одинаковых» и т.п.<br />Это все в дополнение к «локальным» логам, которые в общем случае не покидают пределы машины, на которой запущена пушилка.</p>
<p>Вот как-то так. Все это работает на многих десятках тысяч горутин без каких либо проблем, и это круто)</p>
<p>P.S. Очень многое осталось за кадром, может быть позже…</p>
<p>P.P. S. Картинки гоферов взяты отсюда.
</p>
<p class="copyrights"><span class="source">© <a target="_blank" rel="nofollow" href="http://habrahabr.ru/post/265731/">Habrahabr.ru</a></span></p>
</div>
<br>
<!--<div align="left">
<script type="text/topadvert">
load_event: page_load
feed_id: 12105
pattern_id: 8187
tech_model:
</script><script type="text/javascript" charset="utf-8" defer="defer" async="async" src="//loader.topadvert.ru/load.js"></script>
</div>
<br>-->
<div style="padding-left: 20px;">
<!-- PCNews 336x280 -->
</div>
<!-- comments -->
</div>
<br class="clearer"/>
</div>
<br class="clearer"/>
<div id="footer-2nd"></div>
<div id="footer">
<br/><br/>
<ul class="horz-menu">
<li class="about"><a href="/info/about.html" title="О проекте">О
проекте</a></li>
<li class="additional-menu"><a href="/archive.html" title="Архив материалов">Архив</a>
</li>
<li class="additional-menu"><a href="/info/reklama.html"
title="Реклама" class="menu-item"><strong>Реклама</strong></a>
<a href="/info/partners.html" title="Партнёры"
class="menu-item">Партнёры</a>
<a href="/info/legal.html" title="Правовая информация"
class="menu-item">Правовая информация</a>
<a href="/info/contacts.html" title="Контакты"
class="menu-item">Контакты</a>
<a href="/feedback.html" title="Обратная связь" class="menu-item">Обратная
связь</a></li>
<li class="email"><a href="mailto:pcnews@pcnews.ru" title="Пишите нам на pcnews@pcnews.ru"><img
src="/media/i/email.gif" alt="e-mail"/></a></li>
<li style="visibility: hidden">
<noindex>
<!-- Rating@Mail.ru counter -->
<script type="text/javascript">
var _tmr = window._tmr || (window._tmr = []);
_tmr.push({id: "93125", type: "pageView", start: (new Date()).getTime()});
(function (d, w, id) {
if (d.getElementById(id)) return;
var ts = d.createElement("script");
ts.type = "text/javascript";
ts.async = true;
ts.id = id;
ts.src = (d.location.protocol == "https:" ? "https:" : "http:") + "//top-fwz1.mail.ru/js/code.js";
var f = function () {
var s = d.getElementsByTagName("script")[0];
s.parentNode.insertBefore(ts, s);
};
if (w.opera == "[object Opera]") {
d.addEventListener("DOMContentLoaded", f, false);
} else {
f();
}
})(document, window, "topmailru-code");
</script>
<noscript>
<div style="position:absolute;left:-10000px;">
<img src="//top-fwz1.mail.ru/counter?id=93125;js=na" style="border:0;" height="1"
width="1" alt="Рейтинг@Mail.ru"/>
</div>
</noscript>
<!-- //Rating@Mail.ru counter -->
</noindex>
</li>
</ul>
</div>
<!--[if lte IE 7]>
<iframe id="popup-iframe" frameborder="0" scrolling="no"></iframe>
<![endif]-->
<!--<div id="robot-image"><img class="rbimg" src="i/robot-img.png" alt="" width="182" height="305" /></div>-->
<!--[if IE 6]>
<script>DD_belatedPNG.fix('#robot-image, .rbimg');</script><![endif]-->
</div>
<!--[if lte IE 7]>
<iframe id="ie-popup-iframe" frameborder="0" scrolling="no"></iframe>
<![endif]-->
<div id="footer-adlinks"></div>
<noindex>
<!--LiveInternet counter--><script type="text/javascript">
document.write("<a rel='nofollow' href='//www.liveinternet.ru/click' "+
"target=_blank><img src='//counter.yadro.ru/hit?t45.6;r"+
escape(document.referrer)+((typeof(screen)=="undefined")?"":
";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?
screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+
";"+Math.random()+
"' alt='' title='LiveInternet' "+
"border='0' width='1' height='1'><\/a>")
</script><!--/LiveInternet-->
<!-- Rating@Mail.ru counter -->
<script type="text/javascript">
var _tmr = window._tmr || (window._tmr = []);
_tmr.push({id: "93125", type: "pageView", start: (new Date()).getTime()});
(function (d, w, id) {
if (d.getElementById(id)) return;
var ts = d.createElement("script"); ts.type = "text/javascript"; ts.async = true; ts.id = id;
ts.src = "https://top-fwz1.mail.ru/js/code.js";
var f = function () {var s = d.getElementsByTagName("script")[0]; s.parentNode.insertBefore(ts, s);};
if (w.opera == "[object Opera]") { d.addEventListener("DOMContentLoaded", f, false); } else { f(); }
})(document, window, "topmailru-code");
</script><noscript><div>
<img src="https://top-fwz1.mail.ru/counter?id=93125;js=na" style="border:0;position:absolute;left:-9999px;" alt="Top.Mail.Ru" />
</div></noscript>
<!-- //Rating@Mail.ru counter -->
<!-- Yandex.Metrika counter -->
<script type="text/javascript">
(function (d, w, c) {
(w[c] = w[c] || []).push(function () {
try {
w.yaCounter23235610 = new Ya.Metrika({
id: 23235610,
clickmap: true,
trackLinks: true,
accurateTrackBounce: true,
webvisor: true,
trackHash: true
});
} catch (e) {
}
});
var n = d.getElementsByTagName("script")[0],
s = d.createElement("script"),
f = function () {
n.parentNode.insertBefore(s, n);
};
s.type = "text/javascript";
s.async = true;
s.src = "https://mc.yandex.ru/metrika/watch.js";
if (w.opera == "[object Opera]") {
d.addEventListener("DOMContentLoaded", f, false);
} else {
f();
}
})(document, window, "yandex_metrika_callbacks");
</script>
<noscript>
<div><img src="https://mc.yandex.ru/watch/23235610" style="position:absolute; left:-9999px;" alt=""/>
</div>
</noscript>
<!-- /Yandex.Metrika counter -->
<!-- Default Statcounter code for PCNews.ru https://pcnews.ru-->
<script type="text/javascript">
var sc_project=9446204;
var sc_invisible=1;
var sc_security="14d6509a";
</script>
<script type="text/javascript"
src="https://www.statcounter.com/counter/counter.js"
async></script>
<!-- End of Statcounter Code -->
<script>
(function (i, s, o, g, r, a, m) {
i['GoogleAnalyticsObject'] = r;
i[r] = i[r] || function () {
(i[r].q = i[r].q || []).push(arguments)
}, i[r].l = 1 * new Date();
a = s.createElement(o),
m = s.getElementsByTagName(o)[0];
a.async = 1;
a.src = g;
m.parentNode.insertBefore(a, m)
})(window, document, 'script', '//www.google-analytics.com/analytics.js', 'ga');
ga('create', 'UA-46280051-1', 'pcnews.ru');
ga('send', 'pageview');
</script>
<script async="async" src="/assets/uptolike.js?pid=49295"></script>
</noindex>
<!--<div id="AdwolfBanner40x200_842695" ></div>-->
<!--AdWolf Asynchronous Code Start -->
<script type="text/javascript" src="https://pcnews.ru/js/blockAdblock.js"></script>
<script type="text/javascript" src="/assets/jquery.min.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/jquery/jquery.json.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/jquery/jquery.form.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/jquery/jquery.easing.1.2.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/jquery/effects.core.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/browser-sniff.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/scripts.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/pcnews-utils.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/pcnews-auth.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/pcnews-fiximg.js"></script>
<script type="text/javascript" src="/assets/a70a9c7f/js/pcnews-infobox.js"></script>
</body>
</html>