Рассказываем про библиотеку для Process Mining: теперь SberPM в открытом доступе
В конце 2020 года в открытый доступ вышла разработанная Сбером python-библиотека SberPM — первая в России мультифункциональная библиотека для интеллектуального анализа процессов и клиентских путей. Ниже про то, как она устроена и как ей пользоваться.
DataHolder
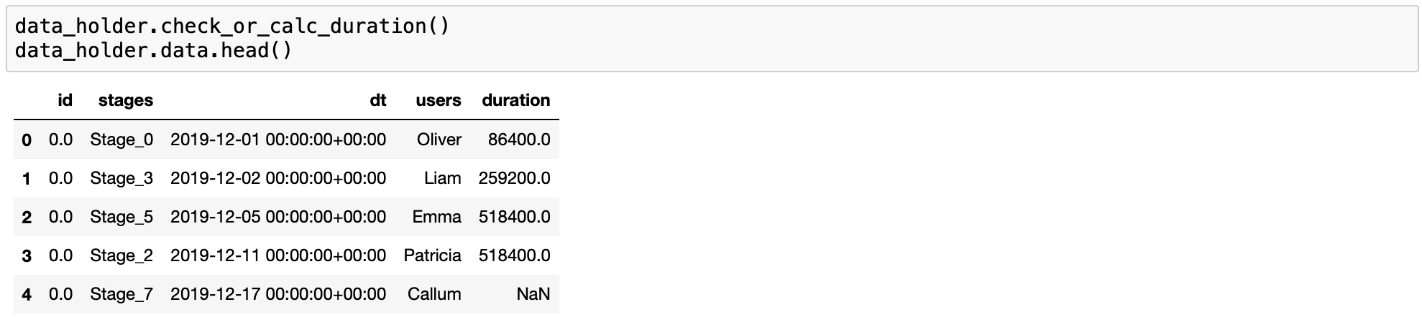
Основу для применения Process Mining формируют данные лог-файла, в котором хранится информация о выполненных в рамках одного процесса действиях. Работа с библиотекой начинается с загрузки лога в DataHolder, под капотом которого производится автоматическая предобработка данных — удаление нулевых значений, сортировка по времени и т.д. Как следует из названия, DataHolder хранит исследуемые данные с указанием ключевых атрибутов, необходимых для анализа — ID (идентификатор события), активности, временные метки начала и/или конца событий. Также для более глубокой и интересной аналитики могут быть добавлены дополнительные атрибуты: ID и роли пользователей, территориальный и продуктовый разрезы, текстовые комментарии и другое.

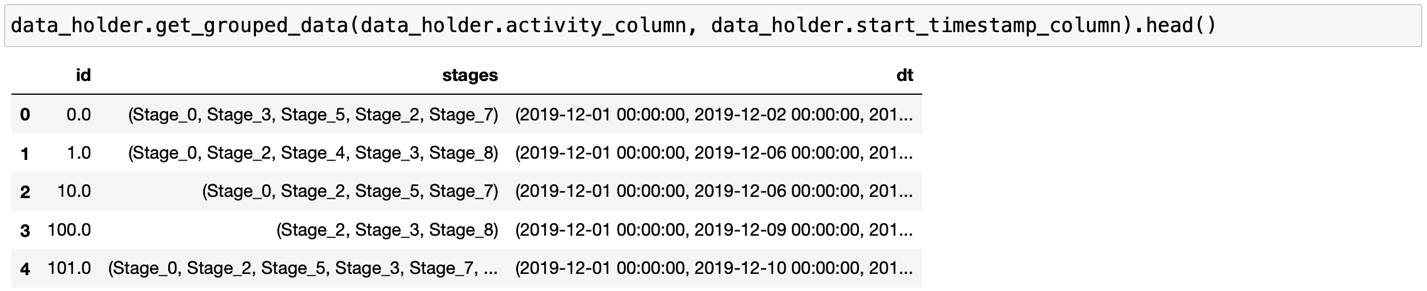
Помимо этого, с помощью методов DataHolder можно быстро выполнить основные операции с лог-файлом, например, рассчитать длительность каждой активности или сгруппировать данные по ID и указанным колонкам.
Понятие DataHolder является базовым, поскольку большинство алгоритмов библиотеки работают с экземпляром именно этого класса.
Майнеры, визуализация и BPMN
Хранящийся в DataHolder лог-файл обеспечивает достоверную и детализированную информацию о ходе исполнения бизнес-процесса. С ее помощью можно реконструировать модель реального, а не предполагаемого процесса. Для построения графа AS-IS процесса в библиотеке реализовано несколько алгоритмов, называемых майнерами:
- SimpleMiner — рисует все ребра, найденные в логе;
- CausalMiner — рисует только прямые связи;
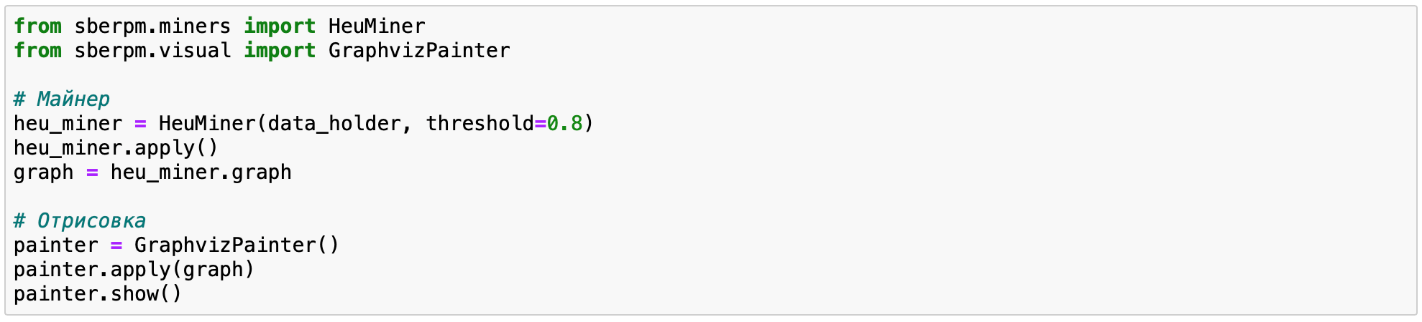
- HeuMiner — удаляет наиболее редкие связи в зависимости от порога (threshold) — чем он больше, тем меньше ребер на графе;
- AlphaMiner — рисует граф в виде сети Петри с учетом прямых, параллельных и независимых связей между активностями;
- AlphaPlusMiner — Alpha Miner, который может работать с одноцикловыми (one-loop) цепочками.
Визуализировать полученный в результате работы майнера граф процесса можно встроенными средствами Graphiz следующим образом:
Можно также сохранить (импорт) или загрузить (экспорт) граф в формате BPMN (Business Process Model Notation):

Визуальная схема позволяет не только получить полное представление о цепочке событий, но и исследовать актуальное состояние процесса на любом уровне детализации. В качестве примера рассмотрим графы, построенные различными майнерами, для одного и того же синтетического процесса:
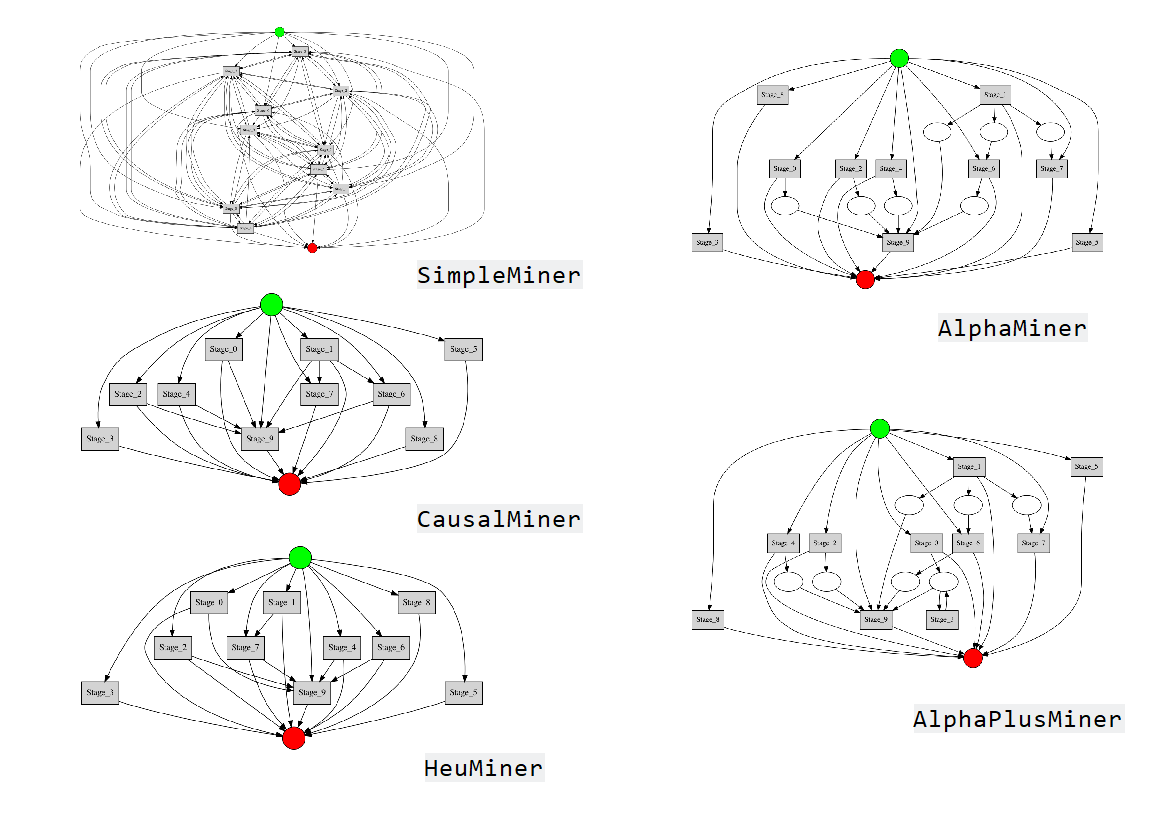
Итак, CausalMiner позволяет отобразить процесс наиболее линейно, HeuMiner показывает самые частотные цепочки, а AlphaMiner наглядно демонстрирует параллельные участки процесса.
Метрики
Process Mining, как известно, не ограничивается восстановлением моделей бизнес-процессов из лог-файлов. Важной составляющей анализа является расчет и мониторинг ключевых индикаторов исполнения процесса. За это в библиотеке отвечает модуль метрик, в котором на данный момент реализованы следующие виды статистик:
- ActivityMetric — метрики по уникальным активностям;
- TransitionMetric — метрики по уникальным переходам;
- IdMetric— метрики по ID;
- TraceMetric — метрики по уникальным цепочкам активностей;
- UserMetric — метрики по уникальным пользователям;
- TokenReplay — fitness, который показывает, насколько хорошо граф описывает бизнес-процесс.
В первых пяти случаях для объекта группировки рассчитываются число появлений, число уникальных ID / активностей / пользователей, процент зацикливаний, временные характеристики (средняя, медианная, максимальная и другие виды длительности) и т. д.
Пример работы класса UserMetric:
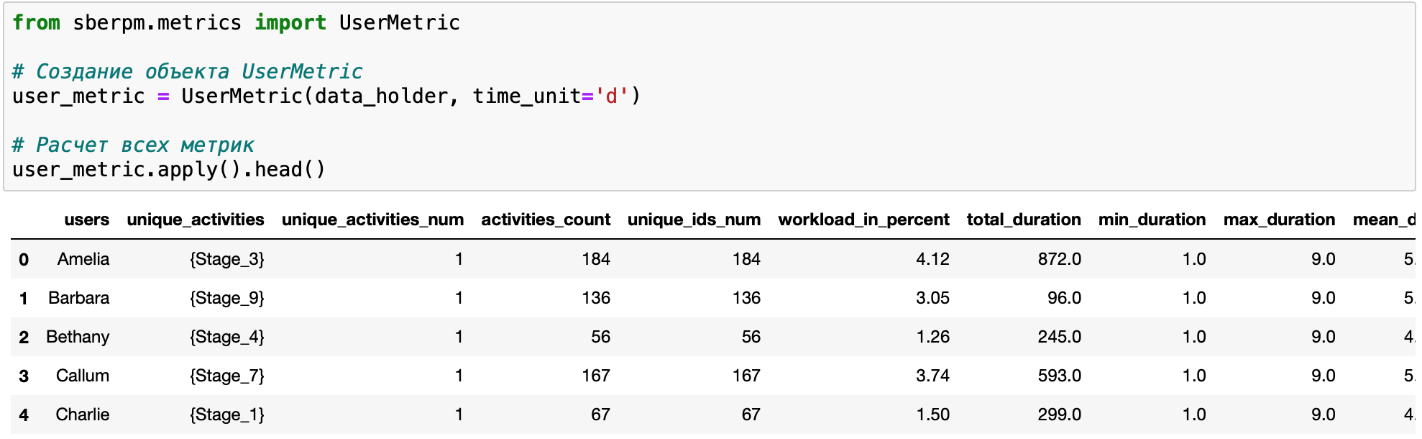
Несомненным преимуществом данного модуля является быстрота расчетов. Допустим, перед аналитиком стоит задача определить среднюю длительность самых частотных цепочек событий процесса. Решение методами pandas займет 5 минут и более 10 строк кода, в то время как решение методами SberPM — 1 минуту и 3 строчки кода.

Помимо этого, в библиотеке реализована возможность добавить метрики на граф процесса. Сделать это можно следующим образом:

В результате на графе можно, например, изменить ширину ребер и цвет нод в зависимости от значений метрик и тем самым отследить самые частотные пути и долгие этапы процесса.
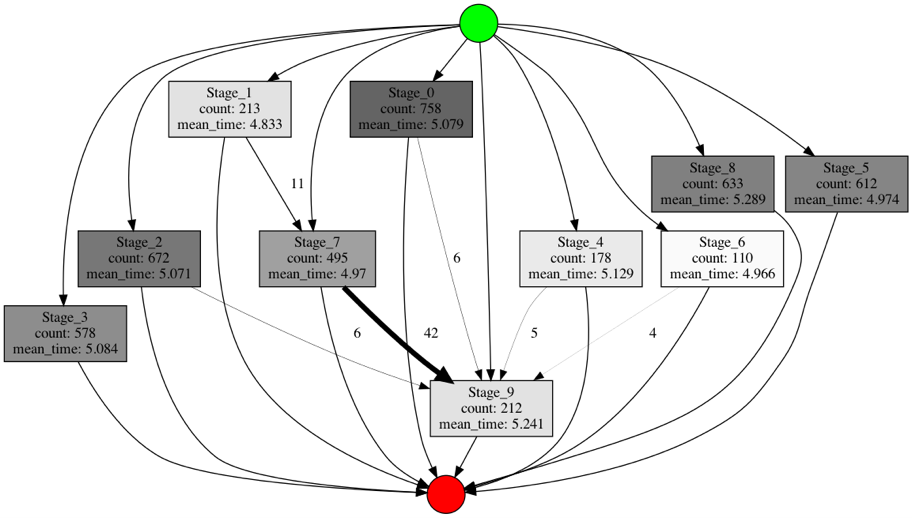
Таким образом, анализируя модель реконструированного процесса вместе с данными о длительности и особенностях его исполнения, можно выявить задержки по времени реализации отдельных действий, взаимосвязи между пользователями, зацикленности в процессе, неэффективных исполнителей, а также скрытые недостатки и проблемы в процессах, из-за которых может существенно снижаться производительность целой организации.
Модуль ML
Помимо классических инструментов Process Mining, SberPM предлагает функционал методов машинного обучения. На данный момент пользователям доступны векторизация и кластеризация процессов, а также модуль автопоиска инсайтов. Расскажем подробнее, для чего это нужно и как этим пользоваться.
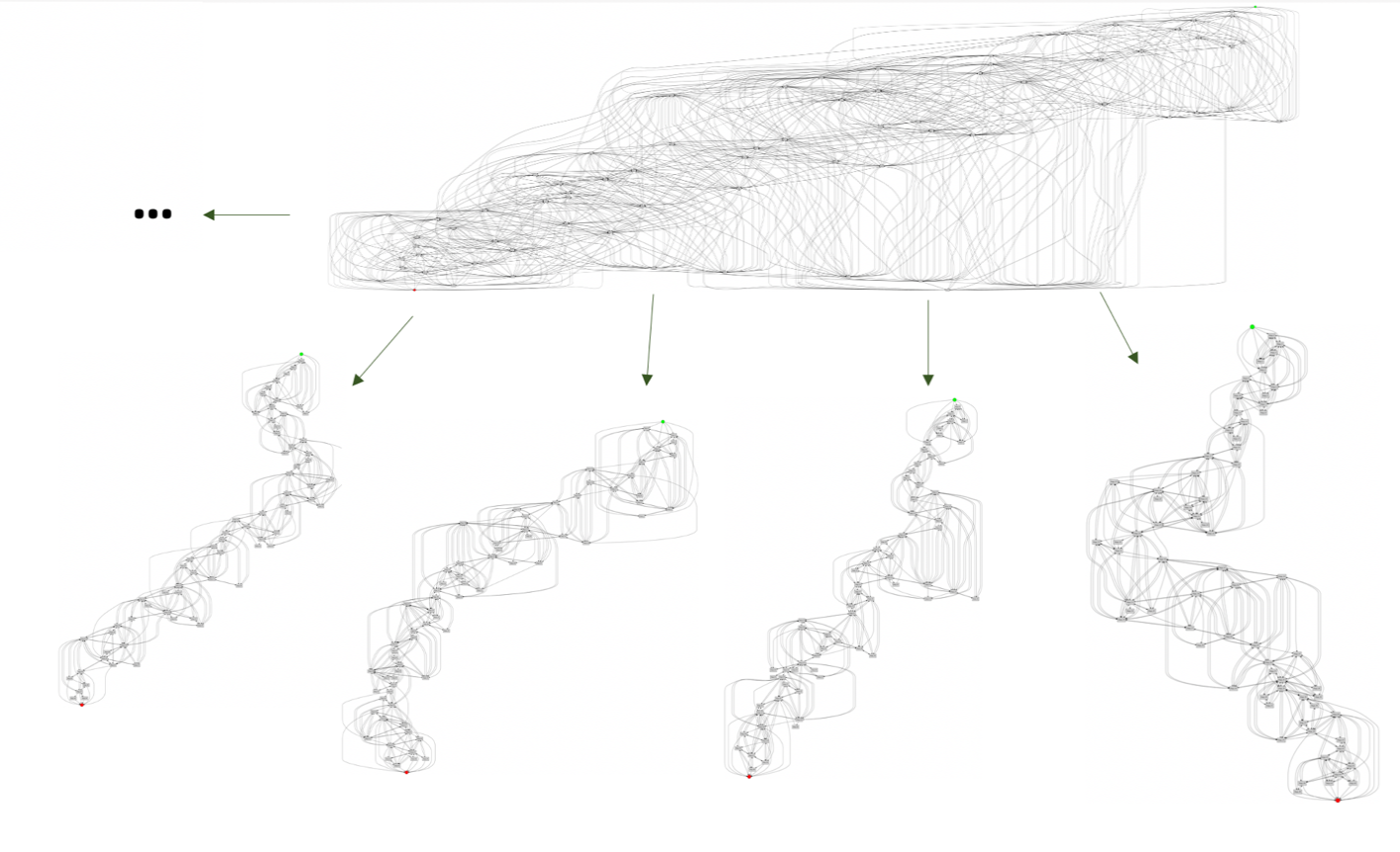
Допустим, необходимо провести анализ крайне загруженного процесса, сложного по структуре и с большим количеством активностей и связей. Например, как этот:
Даже при беглом взгляде на граф понятно, что анализ подобного процесса займет огромное количество времени и не факт, что в итоге удастся найти все узкие места и неэффективности. Но можно облегчить задачу, получив векторные представления каждой цепочки событий (trace), а затем выполнив кластеризацию процесса на его составляющие, схожие по структуре и свойствам. Получение векторных представлений, или эмбеддингов, реализовано в SberPM удобно и логично:

Для кластеризации предназначен класс GraphClustering. Ниже приведен пример работы с ним:

Таким образом, каждому trace из лога будет сопоставлена метка кластера. Объединив цепочки с одинаковыми метками, получим подпроцессы, пригодные для дальнейшего анализа. Для процесса, граф которого изображен выше, это будет выглядеть как-то так:
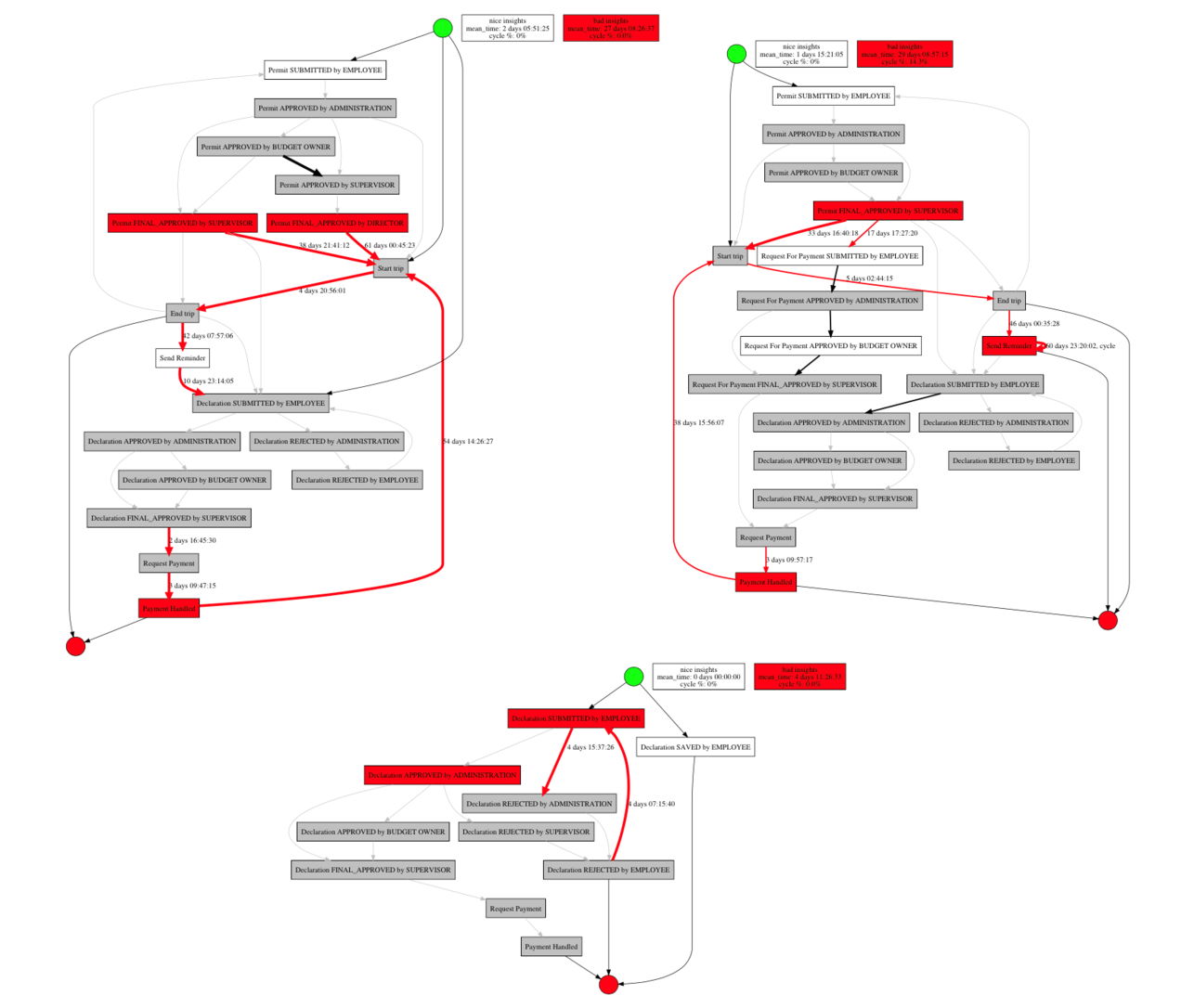
Еще одна полезная «фишка» SberPM — модуль автоматического поиска инсайтов. С его помощью можно проанализировать лог-файл, выявить возможные узкие места процесса «по нажатию кнопки» и визуализировать их на графе. Поддерживается 3 режима работы: анализ по зацикленности, по времени выполнения и комбинированный анализ, где каждой активности и каждому переходу присваивается индекс оптимальности, показывающий, насколько тот или иной объект требует вмешательства.
Ниже приведен пример работы с модулем и результат визуализации инсайтов на графе:

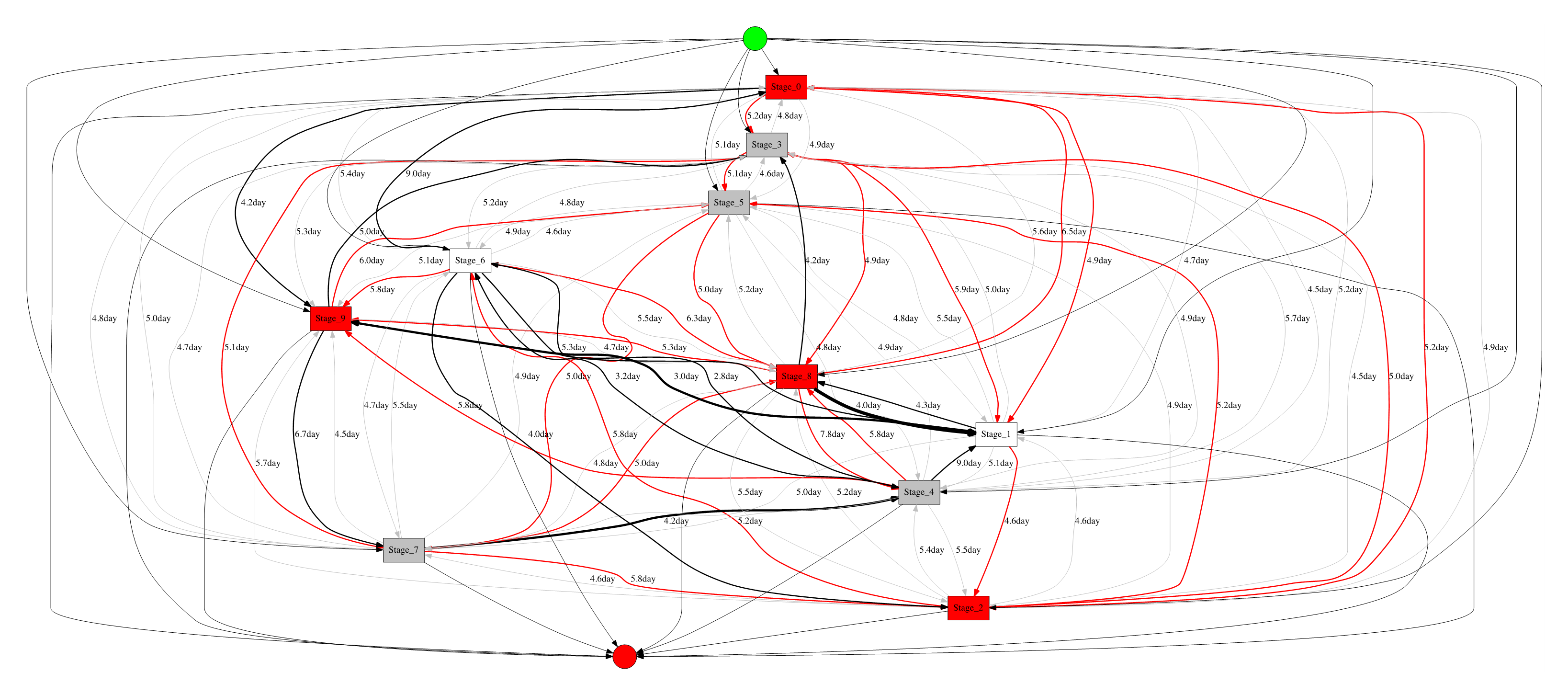
«Плохие» переходы и активности, требующие оптимизации, выделены красным цветом, «хорошие», т.е. не требующие оптимизации — черным, нейтральные — серым. Толщина ребер на графе также меняется в зависимости от оптимальности перехода.
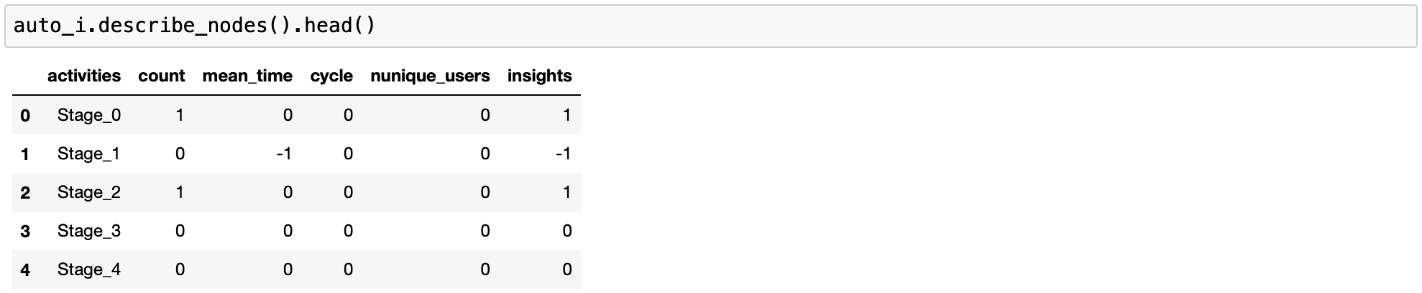
Дополнительно для всех активностей и переходов можно вывести более детальную таблицу, где для каждого элемента отмечается, является ли он инсайтом и, если да, то по какой именно метрике. Так,»1» в графе insights означает, что объект является «хорошим» инсайтом,»-1» — «плохим» инсайтом,»0» — не является инсайтом вовсе.
Более подробное описание всех модулей и классов можно найти в файле tutorial.ipynb, расположенном в репозитории библиотеки SberPM на GitHub.
Мы планируем на постоянной основе улучшать библиотеку и дополнять ее функционал. Запланированы релизы для расширения и масштабирования Open Source решения SberPM. Пожалуйста, пользуйтесь, оставляйте обратную связь, добавляйте коммиты и развивайте библиотеку вместе с нами.
