Расширения в Kotlin. Опасный атавизм или полезный инструмент?

Kotlin — еще молодой язык, но уже стремительно ворвался в нашу жизнь. Из-за этого не всегда понятно, каким образом правильно реализовать тот или иной функционал и какие best practice применять.
Особенно тяжело обстоит дело с возможностями языка, которых нет в Java. Одним из таких камней преткновения оказались расширения.
Это удобный инструмент, который делает код более читаемым, практически ничего не требуя взамен. Но в то же время знаю как минимум одного человека, который если и не считает расширения злом, то точно относится к ним скептически. Ниже я хотел бы обсудить особенности этого механизма, которые могут вызвать споры и недопонимание.
Расширения на DTO — нарушение шаблона Data Transfer Object
Например, есть класс User
class User(val name: String, val age: Int, val sex: String)
Вполне себе DTO! Далее в коде в нескольких местах нужна проверка, является ли пользователь совершеннолетним. Самый простой вариант — во всех местах сделать условие
if (user.age >= 18) { ... }
Но, поскольку таких мест может быть сколь угодно много, разумно вынести эту проверку в метод.
Тут видится три варианта:
- Функция fun isAdult (user: User) — из таких функций обычно состоят утилитные классы.
- Поместить функцию isAdult внутрь класса User
class User(val name: String, val age: Int, val sex: String) { fun isAdult() = age >= 18 } - Написать обертку для User, которая будет содержать в себе подобные функции.
Все три варианта технически имеют право на жизнь. Но первый добавляет неудобство в виде необходимости знать все утилитные функции, хотя это, конечно, не великая проблема.
Второй вариант вроде бы нарушает шаблон Data Transfer Object, так как в классе не только геттеры и сеттеры. А шаблоны нарушать — плохо.
Третий вариант не нарушает ни принципов ООП, ни шаблонов, но приходится каждый раз создавать обертку, если хотим использовать подобные функции. Такой вариант тоже не очень нравится. В итоге получается, что все равно придется идти на жертвы.
На мой взгляд, проще пожертвовать шаблоном DTO. Во-первых, я не нашел ни одного объяснения, почему нельзя делать функции (кроме геттеров и сеттеров) в DTO. А во-вторых, просто по смыслу подобный код удобно иметь рядом с данными, которыми оперируем.
Но не всегда есть возможность поместить такой код внутрь DTO-шек, так как не всегда у разработчика есть возможность редактировать классы, с которыми он работает. Например, это могут быть классы, генерируемые из xsd. К тому же для кого-то может быть непривычно и некомфортно писать подобный код в Data-классах. Kotlin предлагает решение для подобных ситуаций в виде функций и полей расширений:
fun User.isAdult() = age >= 18
Этот код можно использовать так, как если бы он был объявлен внутри класса User:
if(user.isAdult()) {...}
В итоге получается достаточно аккуратное решение, которое с наименьшими компромиссами удовлетворяет нашим потребностям. Если говорить о том, что нарушается шаблон DTO, то хочется напомнить, что в Java это будет обычный статический метод вида:
public static final boolean isAdult(@NotNull User receiver)
Как видим, формально даже шаблон не нарушается. Использование этой функции выглядит так, как если бы она была объявлена в User и Idea будет предлагать ее при автодополнении. Это очень удобно.
Расширения специфичны. Об их существовании можно не знать и путать методы и поля сущности с расширениями
Идея в том, что разработчик пришел на проект, а вокруг код, реализованный в расширениях, и непонятно, какой метод оригинальный, а какой — метод расширения.
Это не проблема, так как Idea помогает разработчику в этом вопросе и подсвечивает такие функции. Хотя справедливости ради надо сказать, что различие лучше заметно при теме Darcula. Если ее сменить на Light, все становится менее очевидно и расширение отличается лишь курсивным шрифтом.
Ниже видим пример вызова двух методов: isAdult — метод расширения, isMale — обычный метод внутри класса User. Скриншот слева — тема Darcula, справа — обычная Light тема.


Несколько хуже дела обстоят с полями. Если, например, решим реализовать isAdult как поле-расширение, то отличить его от обычного поля можно будет только по типу шрифта. В данном примере name — обычное поле. Поле-расширение выдает только курсивный шрифт.
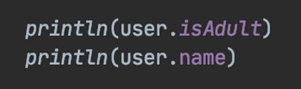

Среда разработки Idea помогает определить, какой метод является расширением, а какой — оригиналом при автодополнении. Это удобно.
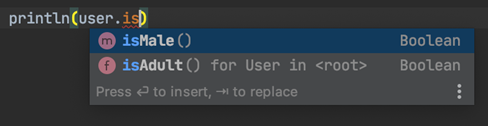
Аналогично обстоят дела с полями.
«for User in
Плюс сам факт, что Idea «привязывает» расширение к расширяемой сущности, очень сильно помогает при разработке, так как методы и поля расширения предлагаются при автодополнении.
Расширения разбросаны по всему проекту, образуя помойку
У нас на проектах такой проблемы нет, так как мы не бросаем расширения на произвол и выносим код с public-расширениями в отдельные файлы или пакеты.
Например, функция isAdult из примера выше могла бы оказаться в файле User пакета extensions. Если пакета недостаточно и хочется точно не путать, где класс, а где файл с функциями, можно его назвать, например, _User.kt. Так сделали разработчики из JetBrains для коллекций. Или, если совесть запрещает начинать файл с подчеркивания, можно назвать user.kt. На самом деле нет разницы, каким из способов пользоваться, главное, чтобы было единообразие, которого придерживалась бы вся команда.
Создатели языка при разработке методов расширений для коллекций поместили их в файл _Collections.kt.
Вообще это вопрос организации кода, а не проблема расширений. Статические функции в Java, да и не только статические, можно разбросать не менее беспорядочно, чем расширения.
Не замокать функции расширения при юнит-тестировании
На мой взгляд, в моканье функций расширений нужды нет, как нет нужды и в моканье статических методов. В функции расширения следует помещать логику работы с уже имеющимися данными. Например, в случае с функцией isAdult для класса User все необходимое есть в isAdult. Ничего мокать не нужно.
Рассмотрим немного более сложный пример. Есть некий компонент, который служит для получения пользователей из внешней системы, — UserComponent. Метод получения пользователей называется getUsers. Предположим, что появилась необходимость получать всех активных пользователей и решили добавить логику фильтрации в виде функции — расширения. В итоге получили функцию:
fun UserComponent.getActiveUsers(): List = this.getUsers().filter{it.status == "Active”}
Может показаться, что вот она — ситуация, когда нужен mock для расширения. Но если вспомнить, что getActiveUsers — просто статический метод, оказывается, что mock не нужен. Мокать следует методы и функции, которые вызываются в расширении, и не более того.
Есть вероятность перекрытия функции расширения одноименной функцией, размещенной внутри расширенного класса
Данный кейс рассмотрим на примере из первого пункта. Допустим, есть функция расширение isAdult, которая проверяет, является ли пользователь совершеннолетним:
fun User.isAdult() = age >= 18
После этого реализуем одноименную функцию внутри User:
class User(val name: String, val age: Int, val sex: String){
fun isAdult() = age >= 21
}
При вызове user.isAdult () будет вызвана функция из класса, несмотря на то что есть одноименная и подходящая функция расширения. Такой кейс может запутать, так как пользователи, не знающие о функции, объявленной внутри класса, будут ожидать выполнения функции расширения. Это неприятная ситуация, которая может иметь крайне серьезные последствия. В данном случае речь идет не о возможных неудобствах ревью или нарушении шаблона, а о потенциально ошибочном поведении кода.
Описанная выше ситуация показывает, что при использовании функций расширений могут возникнуть реальные проблемы.
Чтобы их избежать, следует не забывать максимально покрывать функции расширения юнит-тестами. В самом страшном случае при не упавших тестах окажется две функции, работающие одинаково. Одна — расширение, а другая в самом классе. Если тесты упадут, это привлечет внимание к тому, что одна функция перекрывает другую.
Расширение привязано к классу, а не к объекту, и это может вызвать путаницу
Для примера рассмотрим класс User из первого пункта. Сделаем его open и создадим его наследника Student:
class Student(name: String, age: Int, sex: String): User(name, age, sex)
Определим функцию расширения для Student, которая тоже будет определять, является студент совершеннолетним или нет. Только для студента изменим условие:
fun Student.isAdult() = this.age >= 16
И теперь напишем следующий код:
val user: User = Student("Петя", 17, "M")
Что же вернет user.isAdult ())?
Казалось бы, объект типа Student и функция должна вернуть true. Но все не так просто. Расширения привязаны к классу, а не к объекту, и результат будет false.
В этом нет ничего странного, если вспомнить, что расширения — это статические методы, а расширяемая сущность — первый параметр в этом методе. Это еще один момент, о котором следует помнить при использовании этого механизма. Иначе можно получить неприятный и неожиданный эффект.
Вместо вывода
Эти спорные моменты не кажутся опасными, если помнить, что говорим расширение — подразумеваем статический метод. Плюс покрытие такого функционала юнит-тестами поможет минимизировать возможную путаницу, связанную со статической природой расширений.
На мой взгляд, расширения являются мощным и удобным инструментом, который позволяет улучшить качество и читабельность кода, практически ничего не требуя взамен. Вот почему я их люблю:
- Расширения позволяют писать логику, специфичную для контекста расширяемого класса. Благодаря этому поля и методы расширения читаются так, будто они всегда присутствовали в расширенной сущности, что, в свою очередь, улучшает верхнеуровневое понимание кода. В Java, увы, так сделать нельзя. Причем расширения имеют те же модификаторы доступа, что и обычные функции. Это позволяет писать подобный код с той областью видимости, которая действительно необходима для конкретной функции.
- Удобно использовать функции расширения для маппингов, которых достаточно много приходится видеть при решении повседневных задач. Например, в проекте есть класс UserFromExternalSystem, который используется при вызове внешней системы, и было бы здорово вынести маппинг в функцию расширения, забыть о нем и использовать так, будто он изначально был в User.
callExternalSystem(user.getUserFromExternalSystem())
Конечно, то же самое можно сделать обычным методом, но такой вариант менее читабелен:callExternalSystem(getUserFromExternalSystem(user))
или такой вариант:val externalUser = getUserFromExternalSystem(user) callExternalSystem(externalUser)
По сути, никакой магии не происходит, но благодаря таким мелочам работать с кодом приятнее. - Поддержка Idea и автодополнения. В отличие от методов из утилитных классов, расширения хорошо поддерживаются средой разработки. При автодополнении расширения предлагаются средой как «родные» функции и поля. Это позволяет неплохо повысить эффективность разработчика.
- В пользу расширений говорит тот факт, что огромная часть библиотек Kotlin написана в виде расширений. Много удобных и любимых методов для работы с коллекциями — расширения (Filter, Map и так далее). В этом можно убедиться, изучив файл _Collections.kt.
Плюсы расширений перекрывают возможные минусы. Конечно, велик риск неправильного использования этого механизма и соблазна весь код запихать в расширения. Но тут скорее вопрос об организации кода и грамотном применении инструмента. При правильном использовании расширения станут верным другом и помощником в написании хорошо читаемого и поддерживаемого кода.
Ниже приведены ссылки на материалы, которые использовались для подготовки этой статьи:
- proandroiddev.com/kotlin-extension-functions-more-than-sugar-1f04ca7189ff — отсюда взяты интересные мысли про то, что, используя расширения, мы ближе работаем с контекстом.
- www.nikialeksey.com/2017/11/14/kotlin-is-bad.html — тут автор выступает против расширений и приводит интересный пример, который рассматривается в одном из пунктов выше.
- medium.com/@elizarov/i-do-not-see-much-reason-to-mock-extension-functions-7f24d88a188a — мнение Романа Елизарова насчет моканья методов расширений.
Также хотелось бы сказать спасибо коллегам, которые помогли с интересными кейсами и мыслями относительно этого материала.
