Распространённые ошибки изменения схемы базы данных PostgreSQL (Николай Самохвалов)

Postgres.ai делает возможным работу с полноразмерными базами данных в CI, значительно улучшая качество разработки и тестирования.
Разрабатываемый компанией открытый инструмент, Database Lab Engine, позволяет создавать полноразмерные клоны баз данных любого размера за секунды. Используя такие клоны, вы можете тестировать изменения, оптимизировать SQL-запросы и быстро развёртывать независимые тестовые стенды.
Вебсайт компании — https://Postgres.ai/ — содержит также SaaS-версию Database Lab.
Видео:
Всем добрый вечер! Спасибо, что пришли послушать! Тема очень интересная. Будет тема, которая так или иначе во всех проектах вылезает.

В случае изменении схемы базы, как мы знаем, очень часто бывают проблемы с производительностью и не только. И о том, как сделать так, чтобы этих проблем стало меньше, мы сегодня поговорим.

Меня зовут Николай Самохвалов. За свою карьеру я более тысячи изменений схемы в реляционных базах, прежде всего в Postgres, сделал или заревьювил. У меня есть некоторый опыт, чтобы стоять на этой сцене.

Моя компания довольно молодая. Postgres.ai как раз специализируется на том, чтобы улучшать управление, в том числе изменениями. И делать это автоматически. Об этом мы сегодня тоже будем говорить.
Иногда слышу о том, что в докладе была реклама. Но, во-первых, это реклама открытого продукта, т. е. это open source. Во-вторых, это реклама моего продукта, который я и моя команда делаем. Так что, я считаю, что это меня полностью извиняет.

Это самый главный слайд. Легко запомнить: bit.ly/highload2021. Вы всегда по этой ссылке можете найти данные слайды. Они останутся открытыми. Переходите по этой ссылке, комментарии там открыты.
Я рекомендую смотреть HighLoad-материалы в записи. Очень много выкладывается полезного. И оно довольно медленно устаревает. Я всегда, когда лечу через океан, смотрю материалы с прошлых конференций.

Что сегодня следует ожидать? Доклад называется «Самые популярные ошибки, которые делают люди». Так как я в комитете HighLoad с 2007-го года, я хорошо выучил, что если сделать такой доклад, то это привлечет внимание.

Я собираюсь показать какие-то примеры, но это не главное. Главное, чтобы вы запомнили принципы. Слишком много разных ситуаций бывает, когда у вас что-то ломается. И постепенно надо к ним готовиться. По мере роста проекта вы делаете это все лучше и лучше. Но главное усвоить принципы, как готовиться не только к известным проблемам, но еще и к неизвестным. Это сложно. Сегодня мы поговорим о том, как быть готовым к совершенно неизвестным вещам, чтобы не было downtime при изменениях схемы. А также, чтобы релизы делались чаще и качественнее, как это требует бизнес. И я хочу показать вам конкретный путь, как сделать это в вашей организации.
Поднимите, пожалуйста, руки, кто с Postgres работает. Меньше 10% работают не с Postgres. Удивительная картина, главная сцена HighLoad и большинство работает с Postgres. 10 лет назад такое было сложно представить. Здорово!
Тем, кто работает не с Postgres, я надеюсь, тоже будет интересно. Некоторые вещи общие, но, конечно, некоторые штучки будут чисто postgres«овые. И мы это увидим.

О терминах. DML и DDL, я надеюсь, все понимают.
DML — это database manipulation language. Это SELECT, UPDATE, INSERT, DELETE и еще можно TRUNCATE туда засунуть и … .
DDL — это data definition language. Это CREATE, ALTER, DROP.
Что такое database migrations? Это дурацкое называние. Оно пришло, как я подозреваю, из мира Ruby. Оно прижилось, но на самом деле это слово перегруженное, потому что миграция — это когда мы из Oracle в Postgres мигрируем. Когда мы меняем схему, мы никуда не мигрируем. Мы там колонку добавили.
Некоторые различают database schema migrations и database data migrations отдельно. Но очень часто эти темы переплетены.
Как раз в 2019-ом году доклад назывался «Дорогой DELETE», на котором я больше про изменения данных говорил. Сегодня будем говорить про изменения схемы. Но темы переплетены. И изменяя схему, вы иногда вынуждены и данные менять. Но в целом эта тема называется database migrations.
Еще из Википедии можно увидеть: DB change management, schema versioning, schema evolution.
В целом это планируемые изменения в схемы базы.

Из той же Википедии, читая про schema migrations, видим фразу о том, что изменения — это тот момент, когда система может упасть и это большой риск.
Все мы знаем такое понятие, как code freeze или feature freeze, когда менеджмент говорит, что сегодня никаких изменений, никаких релизов, пожалуйста, потому что у нас маркетинговая кампания и мы не хотим увеличивать риск проблем. Их можно понять.
В целом — это сложная тема, когда приходится менять схему online без downtime, без проблем в реляционной СУБД. И это настолько сложная тема, что даже иногда появляются продукты, которые говорят: «Давайте мы вообще не будем менять схему, а будем все хранить в JSON». Это правда сложная тема.
И в Postgres у нас транзакционное управление схемой. Вы можете открыть транзакцию, поменять несколько вещей и ее закрыть. И у вас будет атомарные изменения. Если у вас будет какая-то ошибка, то у вас вся транзакция не будет применена. Это очень классно.
Но тем не менее огромное количество вещей в Postgres не готовы. И вы должны обкладываться разными алгоритмами, чтобы так или иначе не подвергать систему downtime и деградации.
У нас повышенный риск возникает, когда мы что-то меняем. И это относится не только к IT-системам. Это понятно.

Давайте подумаем, какие бывают разные типы ошибок, когда мы делаем изменения в схеме.
Об этой ошибке даже стыдно говорить, но вы даже не представляете, насколько она часто встречается. Это когда на prod«е другая схема, т. е. не та, которую ждали. Допустим, мы используем какую-то систему версионирования схемы, например, Liquibase, Flyway, Sqitch. Вам нужно держать схему в Git«е и все изменения трекать именно через Git. Это must have в наши дни. И у нас там что-то лежит, а на prod’е что-то немножко другое. Бывает такая ситуация. Кто-то руками построил индекс или триггер навесил. Из-за этого наша миграция может упасть. Это очень частая проблема. Про это стыдно говорить, но она есть.
У нас есть какое-то тяжелое изменение. Например, какое-то изменение схемы подразумевает перезапись всей таблицы. И такая вещь довольно сложная. Там букет проблем.
Мы делаем релиз, хотим что-то поменять, но нам не дают это сделать, потому что какая-то транзакция удерживает какой-то lock, который конфликтует с нашим lock. И вот мы заблокированы.
Или, наоборот, мы — blocker, мы что-то делаем и заблокировали каких-то пользователей, а то и всех. Можно повесить lock на базу и заблокировать всех.
Мы все сделали хорошо, но со временем идет деградация системы, потому что наше изменение, допустим, привело к увеличенному bloat или убили какой-то индекс, который нужен раз в месяц и 1-го числа он понадобился, т. е. у нас какие-то последствия после релиза.
Вот 5 типов ошибок, которые бывают.
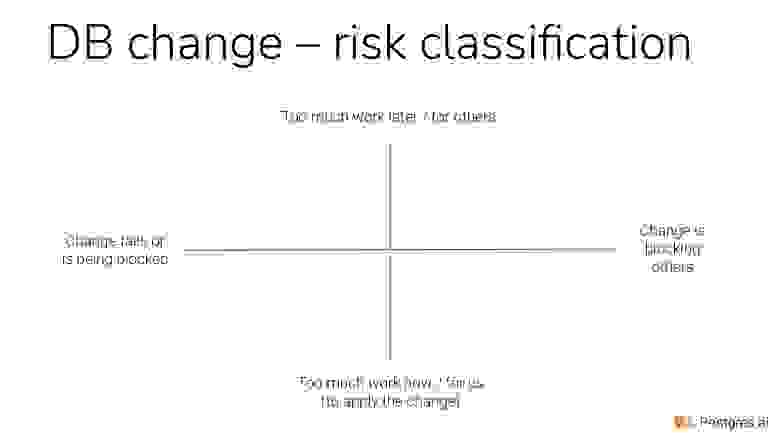
Чтобы почувствовать эти проблемы, сделаем 4 оси. Это 4 характеристики проблемы.
В нижней части — это слишком много работы, которую нужно делать прямо сейчас. Например, мы должны обновить гигабайт данных, миллиард строчек.
В верхней части — это много работы, которой предстоит Postgres или СУБД сделать потом, потому что мы заложили бомбу замедленного действия. Т. е. внизу — это много работы сейчас, вверху — много работы потом. Ясно, что это две разные проблемы.
В левой части — это значит, что мы заблокированы или вообще упали при изменении.
В правой части — это значит, что мы кого-то заблокировали.
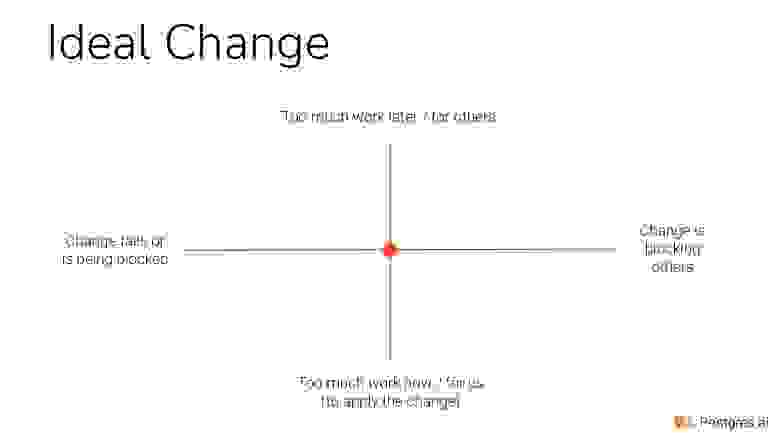
Идеально изменения выглядят вот так. Мы делаем изменения и никакие из этих 4-х характеристик не встречаем.
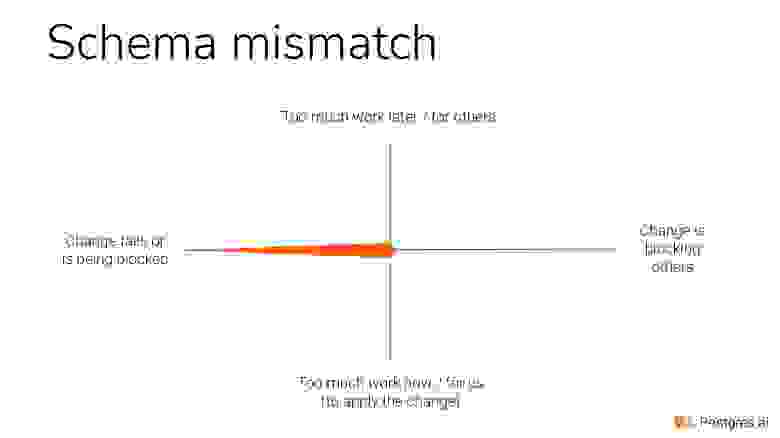
Изменение, которое связано с разъезжанием схемы, выглядит вот так. Мы можем сделать релиз, потому что добавляем колонку, а она там уже есть. Либо мы дропаем индекс, а его там уже нет, т. е. разъехалась схема.
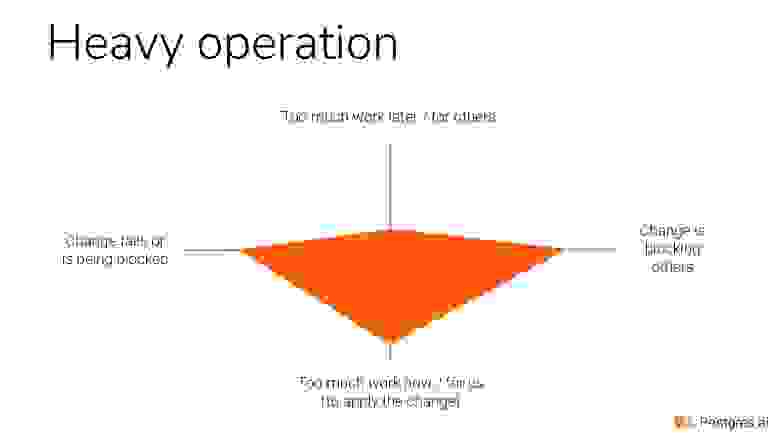
Heavy operation выглядит вот так. Мы не только делаем много работы сейчас, но мы еще и сами может быть заблокированы. Когда мы обновляем много строчек, мы не можем получить эти locks. Или мы блокируем другие изменения в базе, потому изменения конфликтуют. Если мы в одном запросе будем миллиард строчек обновлять, мы захватим lock на все эти миллиард строчек, и пользователи это точно заметят.
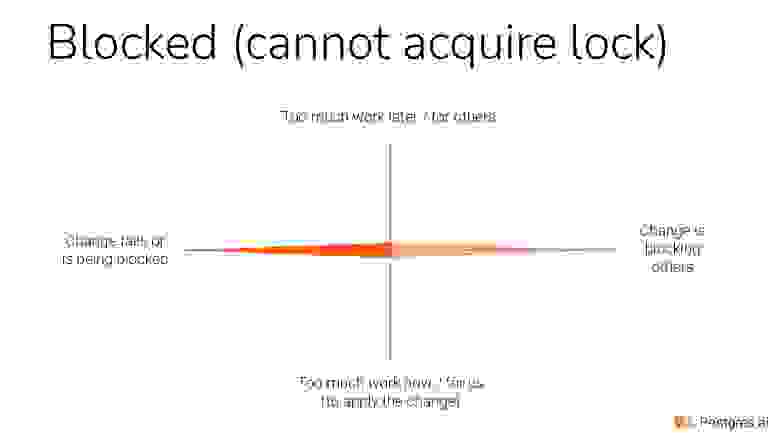
Если мы не можем получить lock, то еще и других начинаем блокировать. Я вам это покажу.
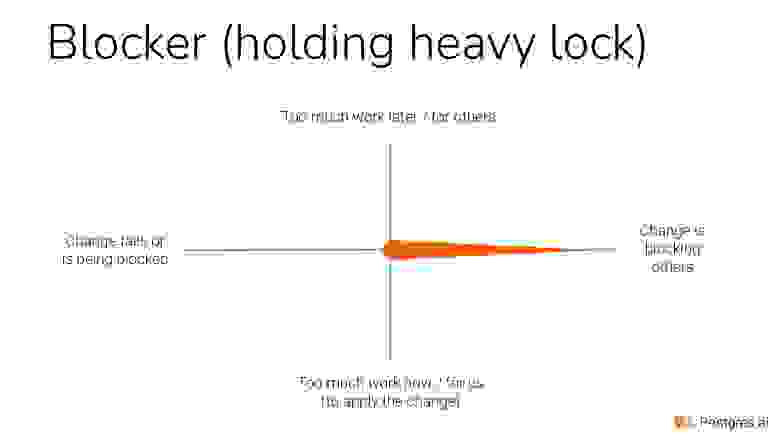
И в конце концов, если мы кого-то блокируем, то это выглядит вот так.

В post-изменениях проблема выглядит вот так, т. е. вот такие характеристики.

Как эти характеристики выглядят с точки зрения бизнеса? Если вниз, то мы делаем много работы. Скорее всего, мы загрузим ресурсы, и может быть какая-то деградация. Но она будет сразу и это хорошо. Я сделал более красным верх, потому что отложенная деградация — это менее приятная вещь, потому что вы ее не видите сразу. Вы не понимаете, в чем причина, поэтому дольше диагностировать и исправлять.
Если мы соломку постелили в виде всяких timeouts и упали, то Ok, мы релиз отменили. Это очень неприятно бывает, но зато пользователи ничего не заметили. Поэтому левая часть наименее красным выделено.
И самое плохое, когда мы начинаем блокировать, и у нас получается либо частичный, либо полный downtime. Если частичный, то у нас какие-то функции отвалились на нашем сервисе. Если полный, то вообще все легло: или весь сервис лег, или все сервисы легли, если у вас монолит.

Начнем с простого примера. Если мы создаем таблицу, на prod«е она есть, то вы увидите такую ошибку. Это всем известная ошибка в Postgres: relation «t1» already exists.
И дальше начинаются разные вариации решения этой проблемы, которые я наблюдал в жизни.
Одна из команд, посмотрев на это, решила: «Ok, у нас Flyway, довольно старая версия и у нас нет никаких UNDO шагов»

Flyway описывает только все время движения вперед. И на каком-то из environment такая проблема.

Что будем делать? Давайте добавим if [not] exists. Кто-то начинает смеяться. И правильно делает. Но не смешно на самом деле. Мне так и не удалось в той команде это выкорчевать. Это распространилось и стало общей практикой. И потом очень сложно от этого избавиться. Эта некоторая травма, которая на всю жизнь. Т. е. люди начинают писать это везде: if exists, not exists. И все время предполагают, что, возможно, наше изменение уже было сделано.
Чем это плохо? Это мы обсудим попозже.
Давайте посмотрим на характеристику. Она очевидная. Я буду показывать вот такие глобусы. Мы видим, что у нас только по одной из этих четырех измерений это как раз вылезло.

Я только что рассказал историю, что Flyway был. Может быть, вообще ничего не было. Такое тоже бывает. Люди говорят: «У нас нет времени внедрять систему управления изменениями схемы, поэтому мы пока написали хорошие скрипты. Они сами все будут делать. Мы все равно в Git«е все держим». Но все это в какой-то момент разъезжается.

Как должно быть по-хорошему? У нас есть система управления контрольной версией одна из этих. И там не просто описывается движение вперед, а, как я уже сказал, движение назад.
Если мы движение вперед и назад можем описать, то это классно по многим причинам.
И Википедия говорит: «Если у вас есть DO, UNDO, то вы можете не в production-environments откатывать изменения назад». Т. е. вы накатили, откатили и можете еще раз повторить. Тестировать становиться немножко легче, хотя есть более хорошие способы тестировать. О них попозже скажу.
В идеале вы должны поместить в CI тестировании ваши DO, UNDO шаги. А совсем в идеале, как я всем рекомендую, надо DO, UNDO, DO. Почему? Потому что повторное DO тестирует это UNDO. Если вы неправильно написали UNDO или вообще его не написали, то у вас второе DO упадет. Т. е. вы создали таблицу, у вас пустое UNDO, вы создаете еще раз, он у вас падает.

Только если у нас не чертов if [not] exists существует. Он как раз такой костыль, который делает возможность игнорировать UNDO шаг. Именно поэтому его не надо использовать. Это плохая практика. Это антипаттерн изменения схемы. Он приводит к запрятыванию потенциальных проблем, которые потом могут дойти до prod.

Соответственно, рекомендация: не используйте if [not] exist направо и налево. Используйте только с умом. Иногда он все-таки нужен, но нужно понимать, когда он нужен. И старайтесь описывать DO, UNDO. И положите их в CI, и тестируйте в такой цепочке: DO-UNDO-DO.
Также, что люди делают? Например, в Ruby On Rails есть возможность переключиться на structure.sql и после каждого изменения не только DDL описанный держать в Git«е, но и всю схему мы дампим. Там рельсы сами это делают, но можно повторить для всего, чего угодно. И в Git«е всегда есть представление о том, какая должна быть вся схема базы. Это легкая операция, т. е. сдампить схему. Таким образом это позволяет нам контролировать и сверяться с prod«ом. Мы можем на prod«е дампить схему. И можно увидеть расхождения. Там версия будет уже pg_dump важна, но это можно игнорировать.
И не игнорируйте ошибки. Не надо заплатки делать, надо их просто решать.

Про тестирование мы поговорили. Как вообще ландшафт тестирования, связанный с разработкой выглядит? Т. е. мы забываем про всякие инфраструктурные задачи, про бэкапы, репликацию. Мы можем тестировать и схему, и данные. Данные тоже можем тестировать. Мы можем делать статический анализ.
Например, мы не хотим, чтобы в поле, в котором есть название ML, были данные типа текст и у него не было индекса, потому что мы хотим игнорировать кейс. И давайте мы будем использовать CI-текст либо у нас будет функциональный индекс от ML. Такие тесты можно писать.
Например, Sqitch позволяет описывать тест, у него есть DO-UNDO deploy revert. И еще у него есть verify. В verify вы можете на языке SQL или PSQL описывать тесты. И каждый раз их в CI гонять.
А можете тестировать данные. Например, ради производительности вы выключили внешние ключи. Так иногда бывает, но не всегда, конечно. И это хорошо, что не всегда. У вас нет внешних ключей, вы можете данные всякими SELECTs протестировать и убедиться, что нет строчек, которым не на что ссылаться, чтобы внешний ключ нельзя было навесить.
Можно динамически тестировать. Это как раз тема сегодняшняя. Мы можем изменение DDL тестировать, либо DML тестировать. И я предлагаю делать это на полноразмерных базах. И я расскажу сейчас, как это делать.
Мы делаем это не только на пустышке или на какой-то маленькой тестовой базе, мы это делаем на копии production, который развернули быстро за счет тонкого клонирования.
И так же можно тестировать разные запросы, делать benchmarks, но это уже другая тема.

Если мы говорим конкретно про тестирование изменений и о том, как делать их надежно, то есть известная пирамида Маслоу. Это пирамида Маслоу для changes management в реляционной базе.
На самом нижнем уровне система контроля версии, которая у вас обязательно должна быть. Это Liquibase, Sqitch, Flyway встроенные в ваш framework.
Вы все трекаете через Git.
Следующий уровень — у вас есть тестирование DO, UNDO. Желательно даже DO, UNDO, DO в CI.
Третий уровень — у вас есть процесс review. Если у вас нет процесс review, то это очень плохо. Это еще хуже, чем в коде не иметь процесс review. Изменения — это то, что приводит к проблемам, они повышают риск проблем. Соответственно, если нет процесс review, то нет вторых глаз, которые посмотрели бы на это изменение. И тогда у вас еще больше рисков возникает.
Вам очень нужно найти вторую пару глаз, чтобы человек посмотрел. Но опыт показывает, что если процесс review ручной, то дальше все зависит от культуры, опыта и усталости человека, который делает review. Иногда мы все этим грешим. Мы очень бегло посмотрели и нажали апрув. И вроде бы сначала нормально было, а потом downtime, потому что мы там что-то просмотрели. И чтобы не было этого, нам нужно каждое изменение прогнать сначала до deploy на полноразмерной базе. Т. е. вы прогнали автоматически, потому что если вручную, то будут скипать. А если автоматически оно прогоняется в CI, то это наша гарантия, т. к. изменения мы прогнали на копии prod«а. Собрали диагностику, как оно себя вело, где-то там сохранили. И после этого мы можем говорить, что это изменение можем апрувить. Оранжевый уровень — это самый классный уровень. Но очень мало компаний до него дошли.
Например, некоторые наши клиенты, такие как GitLab, дошли до этого. У них, если создается merging west и в нем есть database migration, то в этом случае автоматически происходит проверка всех изменений на тонком клоне.

На самом деле видно, что оранжевый уровень тоже не полностью защищает. Это очень хороший уровень и мало, кто до него дошел. Но я считаю, что до него дойти нужно всем, поэтому наш продукт Database Lab — open source. Но есть еще, конечно, что-то дальше.
Например, вы делаете изменение, и тут неожиданно пришел autovacuum, который не уступает вам дорогу. Как известно, autovacuum блокирует нас. Если мы хотим сделать ALTER, autovacuum нас блокирует. Но обычный autovacuum уступает дорогу автоматически, потому что он видит через секунду, что он кого-то блокирует и он автоубивается сам. Но бывает такой autovacuum, который в режиме force Transaction ID WrapAround prevention делает freeze. Он перелопачивает таблицу. Из-за того, что у нас 4-байтные айдишники он фризит tuples (картежи). Соответственно, он нам дорогу не уступит в этом режиме.
И, к сожалению, иногда бывают такие ситуации, что было изменение, которое было протестировано миллион раз, но именно на prod«е в 3 часа ночи мы сталкиваемся с тем, что autovacuum не уступает дорогу. Такие проблемы требуют действительно большого опыта и дополнительных соломок. Вы делая большое изменение, заранее делаете freeze сами. Контролируете, когда autovacuum будет в таком режиме запускаться к конкретным таблицам. Это только одна из возможных проблем.
И оранжевый уровень позволяет уменьшить эту вишенку. Без оранжевого уровня у вас огромная вишенка. И вы не знаете, что там происходит.

Вот пример 2. Database Lab — это штука, которая позволяет делать тонкие клоны для любых баз, конечно, только для Postgres пока что. Они могут быть под вашим управлением, они могут быть в облаке.
По сути, вы разворачиваете специализированную реплику для вашей базы. И на одной машинке вы можете держать сразу 20–30 клонов. И каждый клон полноразмерный и независимый. Можно гонять все ALTER, СREATE INDEX в своей базе. Это может делать разработчик, тестировщик. Можно развернуть такой полноразмерный клон чисто для тестирования, т. е. у вас появляются полноразмерные среды, разворачиваемые за 10 секунд. У вас 10 терабайт база, а клон разворачивается за 10 секунд. Это тема отдельного выступления. И они были и на HighLoad тоже. Зайдите на postgres.ai и посмотрите, как это работает, попробуйте установите у себя.
В целом здесь мы говорим про изменения, поэтому я демонстрирую изменения с помощью бота, который поверх этих тонких клонов работает. И мне так удобнее, он дополнительные штуки привозит.
Здесь видно, что создается таблица в 10 миллионов строчек. Строчки от 1 до 10 миллионов int4, плюс какой-то рандомный текст. И потом внешний ключ на айдишник повесили.
Joe делает некоторую диагностику о том, как изменение происходило, т. е. чем мы там занимались. Видим, что IO некоторое было. И это изменение выполнялось 14 секунд. За 14 секунд мы создали таблицу.

Допустим, дальше мы хотим обновить что-то. И мы говорим, что хотим заменить 0159 на OiSg. Если мы делает вот такое изменение, то случится следующее: в Postgres будут все 10 миллионов строчек обновляться. Т. е. если даже replace не случится, он все равно обновит.
А когда у нас апдейт в Postgres происходит, то строчка физически помечается мертвой, создается новая строчка. И таблица физически у вас увеличится в 2 раза, хотя, может быть, этот replace никакую строчку не задействовал. Это очень неприятная проблема.
Я специально поставил: set statement_timeout to 15s, чтобы показать, что так мы можем упасть. Этот тайм-аут нам нужен. Он должен быть на production. Он нас защищает от того, чтобы мы не делали каких-то тяжелых действий.
Но у нас случилась проблема, мы не смогли зарелизиться. Мы делаем такое изменение, а оно не выкладывается. Если мы тестируем на полноразмерной базе, то мы увидим, что есть проблема. На маленькой базе у нас может за 100 миллисекунд все выполниться, и мы думаем, что все хорошо. Но нет, на большой базе мы как раз увидим, что проблема именно в этом.

И это очень неприятное изменение, потому что оно всю таблицу обновляет. Это тяжелая операция прямо сейчас. Мы можем упасть из-за statement_timeout, если он есть. Либо мы можем быть заблокированы, потому что кто-то с этой таблицей что-то делает, какие-то строчки сейчас обновляет и не отпускает, поэтому мы будем ждать этот lock. А еще мы блокируем другие изменения с этой базой. Это точно заметят пользователи. Вот так делать нельзя.

Если мы этот тайм-аут уберем, то мы выполним это изменение. Здесь видно, что оно было 44 секунды. И эти 44 секунды мы будем блокировать записи в этой таблице на изменения. Такое пользователи точно могут заметить.

Сместился акцент. Здесь я нарисовал череп, потому что это реально очень плохая ситуация. Мы блокируем всех. Плюс еще по оси Y вверх у нас появилась проблема. Почему? Потому что, если мы меняем всю таблицу апдейтом, то мы создаем 10 миллионов мертвых картежей. Даже если придет autovacuum и всех пометит, у нас будет свободное пространство в физическом layout. Это так называемый bloat. Именно так он появляется. Массивная операция приводит к bloat. Т. е. таблица раздулась, и нам потом там нужно repack запускать и т. д.
Именно вот так делать нельзя. У нас по Y вверх появилось изменение, которое приводит к тому, что больше тяжелой работы будет в будущем. Какие-нибудь сканы замедляться, т. е. мы ухудшили работу на будущее. Мы это можем не сразу заметить. Через неделю, например, пойдет деградация, потому что мы на ровном месте сами себе bloat устроили.

Если посмотреть под микроскопом, то как раз этот бот приводит этот план точно так же. Мы поняли, что обязательно надо buffers включать, когда вы explain analyze гоняете, чтобы видеть, сколько данных не только в логическом уровне rows, а еще сколько физически данных мы потрогали. Т. е. это hit, read, dirtied, written. Чтобы мы видели эти числа и чувствовали, как операция работает на физическом уровне.
И мы также заметили, что хорошо бы это еще в байты переводить. Обычно страница по умолчанию в Postgres 8kb. Умножаем эти числа на 8kb и переводим гигабайты, мегабайты.
Так мы видим, что в этот апдейт было 459 гигабайтов хитов. Конечно, там многие страницы хитились много раз. Это понятно. Но мы 716 мегабайт читали, скорее всего, с диска. И видно, что это очень тяжелая операция. И это не то, что вы хотите получить при релизе.

Как раз здесь я демонстрирую, что если мы возьмем строчку, то сначала наш кортеж лежал по адресу 0,1, т. е. это на нулевой странице первый tuple. А когда мы сделали апдейт, причем мы ничего логически не поменяли, то видим, что адрес изменился. Потому что тот tuple был помечен мертвым, и родился новый живой tuple. Именно вот так проблема возникает, даже если мы ничего не меняем.

Это был очень тривиальный пример. Давайте подумаем, что здесь можно делать.
Конечно, прежде всего надо сократить количество работы в одном шаге. Нужно разбить на батчи такую ситуацию. И, возможно, вам потребуется временный индекс для того, чтобы по этим батчам быстро находить следующий батч. Например, по id найти или еще как-то. Если индекса у нас нет, то мы должны его сделать.
И возвращаясь к replace, очевидная оптимизация, т. е. если этих символов нет в значении, то не нужно эту строчку трогать, потому что апдейт приведет к новому мертвому кортежу.
А дальше есть интересный момент. Мы разбиваем на батчи и там с какой-то скоростью движемся. Во-первых, моя рекомендация — не думать про параллельную обработку вообще. Вы можете миллиард строчек в день обрабатывать на фоне и не сильно мешать пользователям, если у вас мощная машина. Конечно, это зависит от конкретной ситуации, нагрузки, ресурсов и т. д. Если вы будете использовать параллельную обработку, то вы будете рубить сук, на котором вы сидите. Вы сами с собой будете конкурировать и убивать производительность. Лучше в один поток все делать.
Но еще важный момент в том, какой размер батча подобрать. Если у вас мобильный сайт, либо веб-сайт, то секунда — это уже медленно. Т. е. ваш апдейт залочит определенное количество строчек. Пользователи могут это заметить. Если это будет длиться несколько секунд, то очень большая вероятность, что они будут недовольны. 100 миллисекунд — это еще более-менее быстро, хотя уже заметно. 1 секунда — это уже медленно. А 10 секунд — это недопустимо, пользователи посчитают, что ничего не работает, тормозит и т. д. Поэтому батчи надо так подбирать, чтобы было меньше секунды.
Слишком дробить тоже плохо, потому что есть транзакционный overhead. Если вы раздробите и будете по одной строчке обрабатывать все 10 миллионов, вы увидите, как у вас общее время увеличивается и есть транзакционный overhead. В целом это нехорошо. Одна секунда — это золотое число для обновлений.
И есть еще хорошая практика контролировать количество tuples, bloat с помощью дополнительного анализа. И иногда сделать паузу, чтобы autovacuum отработал, либо даже вакуумом пройтись автоматизировано, если у вас очень много строчек обновляется.

Допустим, у нас есть айдишник. Я как раз в табличку сделал 4-байтный айдишник. Многие, наверное, с этой проблемой уже сталкивались. Вы хотите вставить 2^31–1 и видите вот такую ошибку.
Хорошо, если вы эту ошибку видите где-то в не production-окружении, потому что если вы ее увидели в production-окружении, то это очень неприятная проблема. Не такая неприятная, как transaction id wraparound, конечно, т. е. касается только одной таблицы. Но если эта таблица центральная в вашем сервисе, то очень нехорошо. У меня были ситуации, когда это приводило к downtime этого сервиса до нескольких часов. Слава богу, это было в 2008-ом году. Очень неприятно было с этим дело иметь.
Вы знаете об этой проблеме заранее и хотите поменять на 8-байтный int этот первичный ключ.

Как это можно сделать? Вот так это можно сделать. И для нашей 10 миллионной таблицы это заняло 4,5 минуты. Это самый-самый плохой пример. Он по всем осям плохой. Очень много работы сейчас. Мы раздули таблицу, много работы на потом. Мы, скорее всего, будем долго пытаться получить lock. Мы будем блокировать всех. Это отвратительная вещь. Вы так можете сделать только, если разрешаете себе downtime maintenance window. Обновили, дальше поехали. Но в целом это очень неприятно.

У меня сейчас нет времени, чтобы окунаться в это. На самом деле на это нужен час времени минимум, чтобы всякие детали рассказать в решении этой проблемы. Я могу рассказать в кулуарах или смотрите на канале https://www.youtube.com/RuPostgres.
Есть два пути:
Можно перестать туда писать, конечно. А многие подумают, что могут использовать там негативные значения. Почему там 2^31–1, а не в 32? Потому что у него есть негативное значение. Но там не всегда это возможно, потому что либо у вас в коде что-то не то выйдет, либо в url. Это не очень хорошая идея, хотя она имеет право на жизнь. Но это все уход от решения проблемы.
Нормальное решение проблемы — это либо новая колонка, либо новая таблица.

Вы создаете новую колонку, делаете триггер, чтобы трекать все новые строчки. Вы погружаете старые данные. И, по сути, вы уже синхронизировали новую колонку со старой.
И дальше возникает проблема, которая до 11-го Postgres нормально не решается. Чтобы первичный ключ на новой колонке объявить, вам нужен уникальный индекс создать. Если вы просто дропнете первичный ключ, создадите первичный ключ, вы получите блокировку, скан полной таблицы. И будет то же самое. Это неприятно.
Поэтому вы должны заранее создать уникальный индекс, на основе которого будет работать первичный ключ. Но это еще не все. Вам нужно NOT NULL, потому что просто уникальный индекс разрешает NULL, а первичному ключу нужно, чтобы NOT NULL был.
Нам нужно заботиться еще об внешних ключах, но не будем уже этих мелочей касаться, хотя они тоже могут отъесть кучу времени.

Индекс вы будете использовать со словом «concurrently». Concurrently — очень важно. Если вы пользуетесь автоматизированным средством тестирования и забудете concurrently, то это будет отловлено и на production не пойдет, потому что без него мы блокируемся.

До 11-го Postgres у нас не было никаких возможностей сделать NOT NULL без скана всей таблицы. Соответственно, добавление Not NULL приводило к скану всей таблицы. Это была тяжелая ситуация. И это никак не обходиться, к сожалению.
В 11-ом Postgres сделали неблокирующий дефолт. Вы можете добавлять новую колонку и говорить: «default что-нибудь» и это не приводит к перезаписи всей таблицы. Т. е. дефолт виртуальный, все старые строчки получают этот дефолт виртуально.
В какой-то момент меня осенило, что мы можем еще и NOT NULL сказать. И старые строчки уже виртуально заполнены этим -1. И поэтому NOT NULL не будет приводить к скану. Он будет очень быстрый.
И таким образом мы можем сказать: «NOT NULL DEFAULT -1» для новой колонки, которая 8-байтная. И это будет очень быстро. Это с 11-го Postgres доступно. Этим надо пользоваться.
Когда мы заполняем все старые строчки, -1 превращается в уже настоящее старое значение, которое меньше, чем 2^31–1 или равно этому значению. И дальше DEFAULT -1 свое дело отслужил, можем его дропнуть. И у нас состояние колонки готово к тому, чтобы первичный ключ навешивать. Это как раз такой трюк, который очень помогает таким сложным операциям.

На это надо минимум полчаса, чтобы рассказать об алгоритме. Поймайте меня в кулуарах, расскажу с удовольствием.
И там возникают разные интересные проблемы, которые могут стрельнуть. Я помню, как мы для одной крупной американской компании порешали все проблемы. И в 3 часа ночи force autovacuum не позволил зарелизить, хотя все проблемы были решены.

Chain of blockers — это очень интересная вещь. Допустим, вы хотите ALTER TABLE ADD COLUMN, т. е. добавить колонку любую. Вы знаете, что это очень простая операция для Postgres, но так получается, что вы почему-то не можете ее добавить, либо вы начинаете ее добавлять и видите, что все ложиться. Такие ситуации бывают.
Почему? Это старые слайды. Я специально сделал первую сессию. Там был SELECT. Просто SELECT из этой таблицы, транзакция еще не завершилась.
Какая-то транзакция поработала с этой таблицей, сделала SELECT, Sherlock на какую-то строчку. Мы делаем ALTER и не можем ALTER сделать, потому что мы ждем, когда та транзакция закончится. Это еще не самое плохое. Было бы Ok, если бы мы просто не могли получить lock и упали.
Самая гла
