Распознавание русской речи для колл-центров и параноиков
Когда вы звоните в колл-центр, вас внимательно слушает, а иногда и отвечает, не только оператор и товарищ майор, но и робот-аналитик. Этот хитрый робот умеет распознавать нужные ключевые слова в вашей речи, но и производить полнотекстовое распознавание речи, и на основании этого всего, делать далеко идущие выводы.
Анализировать записи можно как «на лету» (что делается редко), так и постфактум, например, разыскивая конкретные звонки для анализа живым человеком. Я работал с несколькими программно-аппаратными решениями для этого, и сейчас поделюсь опытом.
 Автоматическое распознавание уже начинает справляться с русским языком, за исключением некоторых особо сложных случаев
Автоматическое распознавание уже начинает справляться с русским языком, за исключением некоторых особо сложных случаев
Сразу отмечу — да, эти решения могут сочетаться с определением конкретного человека по «голосовому отпечатку пальца», но это немного другая история и подробно останавливаться на этом здесь я не буду.
4 основных направленияЕсть 4 вектора, по которым сейчас развивается распознавание речи: Естественное распознавание для систем голосового обслуживания (IVR) — это почти как голосовые помощники iOS и «Андроид». С той же примерно точностью. Аналитика переговоров (анализ тысяч звонков в поисках каких-то трендов). Распознавание и идентификация по голосу (тот самый «голосовой отпечаток пальца», который вы оставляете почти в каждом банке). И анализ эмоций, позволяющий понять, что что-то не так. Обычно сейчас анализ эмоций происходит так же постфактум и работает в сумме с остальными движками разпознавания. Но некоторые вендоры (не ведущие) предлагают вариант «на лету», правда, обычно это отдельная технология не особо завязанная с остальными бизнес-процессами. IVR Здесь всё достаточно знакомо. Вы звоните авиаперевозчику. Там женщину вынули, автомат засунули. Автомат спрашивает вас, из какого вы города. Вы отвечаете, софт пробует сделать транскрипцию по звукам и по морфемам. И сравнивает результат с базой возможных ответов.Успешный случай:
Робот: Скажите, в каком городе вы находитесь? Пользователь: Москва.//Что распознал робот: маасква.//В базе есть голосовой синоним: Масква.//Результат «маасква» по расстоянию Дамерау-Левенштейна наиболее близок к синониму «Масква». Расширение выборки не требуется.//В базе город, соответствующий этому синониму: Москва.Робот, радостно: Вы в Москве!
Неуспешный случай:
Робот: Скажите, в каком городе вы находитесь? Пользователь: Пошёл-ка.//Что распознал робот: пшолка.//В базе есть голосовые синонимы к городам Пушкин и Пущино.//Результат «пшолка» далёк ото всех вариантов. Выборка расширяется до расширенных топонимов.//Выборка расширяется до стандартных вопросов автоответчику независимо от вопроса.//В расширенной выборке нет варианта под такое слово.//История общения пока пустая.Робот, грустно: Пожалуйста, повторите город, где вы находитесь.
Сложный случай:
Робот: Скажите, в каком городе вы находитесь? Пользователь: На Урале.//Что распознал робот: нау рале.//В базе стандартной выборки подходящих вариантов нет.//Первая часть похожа на предлог или междометие, в работу параллельно запускается синоним «у рале» и его производные.//В базе стандартной выборки подходящих вариантов нет.//Выборка расширяется до топонимов.//В расширенной выборке есть «Урал» и его производные голосовые синонимы.Робот, грустно: Пожалуйста, повторите город, где вы находитесь.Пользователь: Завьялиха, брат.//Робот разбивает длинное сообщение на части и начинает искать каждую.//Находятся города: Завьялиха, Братск, Брат-Ньиве.//Робот заглядывает в историю: там есть Урал. Делается предположение, что один топоним соответствует расположению другого. Урал сравнивается с каждым городом, ближе всего — Завьялиха. Теория отмечается как наиболее вероятная.Робот, озадаченно: Вы в Завьялихе? Пользователь: Однозначно!//Это разделительный вопрос. Мы ищем синонимы к «да» и «нет». Затем каждое слово-синоним оценивается по своим голосовым синонимам вроде «адназдачна». Поиск по выборке показывает, что клиент согласен с теорией робота.Робот, удовлетворённо: В какой город вы направляетесь? Пользователь: А куда сегодня можно улететь?
Итак, как вы видите, в основе — система синонимов к основным словам-ответам, а также некий набор мета-слов, которые отвечают за управление диалогом. Каждое слово имеет множество голосовых синонимов: «ага», «ога», «аха» и так далее. В зависимости от конкретной используемой системы логики (их несколько различных) робот так или иначе оценивает контекст, делает оценку правдоподобности ответа из базовой выборки, при необходимости расширяет выборку и пробует строить гипотезы на основании истории общения. В более сложном случае используется анализ предложений, чтобы определить, какие слова что означают. Например, на вопрос, куда летим, пользователь может ответить: «Из Москвы в солнечный Магадан». Здесь найдётся минимум три города — Москва, Солнечный и Магадан. Разбор предложения на основе распознанных предлогов поможет предсказать, что Солнечный и Магадан важнее. Дальше робот может, например, сделать запрос во внешнюю базу и попробовать дополниться контекстом: если нет прямых рейсов Москва — Солнечный, то будет выбран Магадан. Но учитывая погрешности всех этих методов, робот всё-таки переспросит, точно ли туда.
Наиболее успешно такие IVR используются банками. Например, возможен подобный диалог:
Робот: Чем могу помочь? Пользователь: Здравствуйте. А где тут у вас ближайший банкомат к озеру Смолино? Робот: Уточните, пожалуйста, вы находитесь в Челябинске? Пользователь: Ага, на Новороссийской.Робот: Ближайший к вам банкомат находится на улице такой-то, дом такой-то.
Идентификация по голосу За примерно минуту записи вашего голоса можно составить уникальный «отпечаток», соответствующий вашему ID в базе данных. Распознавание выполняется по первой-второй фразе, около 8–15 секунд вашей речи. Кроме верификации того факта, что вы — это вы, также может выполняться поиск по базе отпечатков.Крупные банки почти поголовно используют этот метод и как средство дополнительной идентификации пользователя для некритичных операций, и как фильтр фродеров. По хорошему у банка должны быть записи фрод-звонков, и если звонит один из известных злоумышленников, оператор видит специальное предупреждение на основе сопоставления его голоса с отметками в базе. Возможен ретроспективный анализ всех записей колл-центра для поиска записей конкретного человека (точность, правда, невысокая, в базе из 1000 звонков придётся слушать около 30, чтобы найти нужный). Все детали есть вот здесь.
Аналитика эмоций
В зависимости от вашего эмоционального состояния меняется фактически частота тех или иных звуков в речи (ударных, носовых и так далее), а также высота произнесения некоторых гласных. По большей части алгоритмы определения эмоционального состояния закрыты. Точность у них не очень высокая, поэтому, повторюсь, одно из немногих практических применений — это знать, в каком состоянии клиент звонил 10 раз до этого. На российском рынке анализ эмоций используют в дополнение к аналитике речи, для более точного определения эмоциональных — «плохих» или «хороших» вызовов.Аналитика речи
Первая задача — разбить диалог на два канала: входящий и исходящий. Это может решаться средствами колл-центра (писать из двух разных источников) или же постобработкой, например, по технологии Speaker Separation. После такой подготовки уже можно рассматривать каждую из частей отдельно.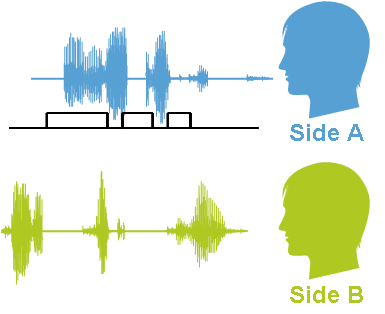
Допустим, на входе — 400 тысяч записей звонков за этот месяц. До этого руками оценивалось менее 1% звонков.
У вас стоят следующие задачи:
Некоторые операторы говорят «форточки» вместо «Windows». Такой жаргонизм вас не устраивает: нужно понять, кто это, и ещё раз объяснить. Хорошо бы постоянно следить за использованием слов-паразитов со стороны операторов и автоматически считать их в звонках. Была рекламная акция — нужно понять, сколько раз люди упоминали новый товар, сотовый тариф или другой продукт при звонках. Робот их подсчитывает, маркетологи оргазмируют. Выявляется тишина. Тишина больше 5 секунд — это признак какого-то затруднения в процессе (например, оператор что-то загружает у себя). В данном случае можно проверять потом, что за сервис так тормозит. Хорошо бы оценивать уровень удовлетворённости клиента. Замечательно бы научиться считать FCR (показатель, оценивающий количество обращений, решенных с первого обращения в КЦ). А также увеличить эффективность работы операторов — с помощью аналитики речи можно автоматизированно обучать операторов, имеющих пробелы по конкретным темам. Итак, для первого случая достаточно просто занести «форточки» во всех вариациях произношения в базу поиска. Робот будет разбирать речь и искать такие вхождения. Точно так же решается задача слов-паразитов, ищем и считаем. Аналогично — новый счётчик на название товара, уровень вопросов по которому нам нужно оценить. Выявление тишины — базовый функционал, тут даже настраивать почти ничего не нужно.
Уровень удовлетворённости клиента — чуть более сложная тема. Есть словарь на примерно 500 «плохих» и столько же хороших слов. Бывают слова, которые могут попасть в обе категории в зависимости от контекста, к примеру — русский мат и производные. Им можно как восторженно похвалить, так и поругать, при этом слова будут одинаковые. В зависимости от системы робот начинает оценивать контекст разными способами. Например, если рядом было слово «спасибо», скорее всего, будет присвоена общая положительная оценка. Даже если это был сарказм.
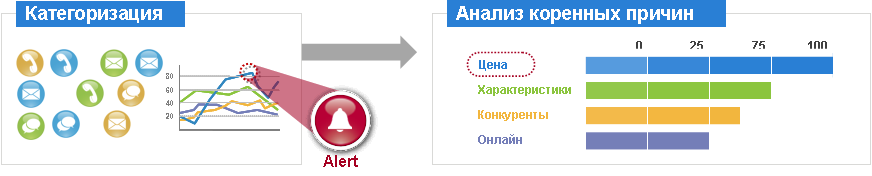
Примерно похожим образом работает выявление трендов. Робот может искать те или иные формализуемые закономерности на основе аналитики речи.
 Иллюстрация того, как может руководитель видеть звонки по типам. Синий — стандартные звонки. Жёлтый — проблемы с качеством работы сотрудника. Красный — упущенная продажа. Зелёный — позитивный отзыв. Фиолетовый — клиент в зоне риска.
Иллюстрация того, как может руководитель видеть звонки по типам. Синий — стандартные звонки. Жёлтый — проблемы с качеством работы сотрудника. Красный — упущенная продажа. Зелёный — позитивный отзыв. Фиолетовый — клиент в зоне риска.
Что касается последнего пункта, то операторам настраиваются индивидуальные KPI, по которым производится контроль. В случае если значение одного из таких показателей отклоняется в «плохую» сторону или зону, то это может служить индикатором того, что оператор плохо разбирается в одной из тематик. Или, например, можно выявлять лучшие практики и методики (например, по продаже или коллекторской деятельности). А на основании этой информации корректировать существующие механизмы обучения. При грамотно выстроенной работе с KPI, операторы могут «соревноваться» в продуктивности (как с другими операторами, так и с самим собой). По моему опыту, операторы, которые видят свою работу в цифрах, стремятся работать лучше.
Погрешности Если 75% звонков с оценкой уровня удовлетворённости клиента были отобраны правильно при не более чем 5% ложных срабатываний, это считается за большой успех в ряде категорий, например, когда нужно выявить какие-то сложные эмоциональные задачи. На некоторых сегментах вроде поиска одного конкретного слова точность будет 85%-95% при минимуме ложных. В условиях зашумлённых линий статистика может быть и такой: около 60% истинных звонков попадает в выборку, из них около 5–10% ложных срабатываний. Но с учётом, что у вас 400 000 звонков, для статистики это всё равно достаточно точно. Собственно, даже если система будет отбирать всего 30% интересующих вас звонков и пропускать остальные 70%, вы получите возможность и найти оператора с любовью к жаргону, и составить соотношение негативных-позитивных отзывов по конкретным товарам.Конкретная погрешность зависит от оборудования колл-центра, точности постановки задач для нечёткого поиска, класса системы распознавания и аудитории звонящих.
Почему такая большая погрешность?
Потому что помехи на линии.
Ветер и другие фоновые звуки очень затрудняют распознавание. Если составить голосовой отпечаток для идентификации можно и при орущем ребёнке на фоне, то вот разобрать слова уже не так просто.
При узкой полосе, характерной для некоторых АТС и старых сотовых кодеков, различить «С» и «Ф» почти нереально. Приходится подключать морфемный анализ, что рождает ещё больше гипотез на низком уровне.
Русский язык очень слабо типизирован. Опираться на состав предложения для построения гипотез довольно тяжело.
Смысл часто сильно зависит от интонации. Словарное слово-подтверждение «Ага» и «Конечно» — это может быть и «Ага, конечно!», являющееся отрицанием. Не все умеют разговаривать с роботами.
В случае с IVR не всегда пользователь сразу понимает, что говорит с автоответчиком. Отсюда — разные сложные конструкции и объяснения на пару минут.
А ещё бывают разные ударения и произношения.
Разработчикам систем распознавания пока никто не ставил задачу профильно работать с дагестанским или финским акцентом.
При сжатии файлов на запись в самом колл-центре также возможно внесение новых искажений (это касается пост-аналитики).
Реальное применение
Одним из производителей систем заявлено вот что: • Автоматизация процесса поиска обращения по заданным параметрам и ключевым словам.• Воспроизведение обращения с возможностью перехода к моменту ключевой фразы.• Выявление причин обращений и жалоб клиентов.• Выявление операторов, требующих дополнительного обучения.• Выявление лучших практик, используемых операторами.• Получение оповещений в случае появления обращений с заданными условиями отбора.
В моей практике были следующие задачи:
Нужно было выявить результат рекламной акции в духе «Принеси пять крышек». Увеличение звонков в колл-центр нужно было сопоставить с количеством упоминаний акции в свободной форме. Около 60% звонков было отобрано верно, что, зная погрешности, позволило сделать оценку.
В одной компании было изменено название. Некоторые операторы использовали старое по привычке, надо было отучать. Нашли и отучили. В рамках этой же задачи проверялось, что оператор здоровается с каждым клиентом и представляется. Робот проверял наличие нечёткого шаблона приветствия в начале разговора.
У оператора банка был скрипт предложения трёх новых услуг. Интерес к ним надо было взвесить для разных групп клиентов и оставить в итоге для каждой группы только одно оптимальное предложение. Достаточно сложная задача, в которой использовался механизм оценки удовлетворённости, описанный выше. Погрешность, естественно, высокая, но для статистического анализа с последующим прослушиванием нескольких сотен звонков вполне хватило. Заказчик доволен, раньше приходилось слушать 4–5 тысяч звонков.
Нужно было раскидать звонки по направлениям, чтобы оценить загрузку операторов. Грубо говоря, претензии, сравнения товаров, вакансии и так далее. Словарь под каждую тему, общие контекстные правила — и вперёд. Точность около 65%, что достаточно для статистики.
Нужно было выявить задержки в бизнес-процессах госкомпании. 37% звонков были с длительной тишиной. После этого мы начали разбирать лингвистические гнёзда до тишины и сразу после, составлялся рейтинг наиболее важных ключевых слов. Каждое гнездо сводилось к какому-нибудь тренду, связанному с процессом или продуктом. Из-за широких рамок задачи мы акцентировались на минимальных ложных срабатываниях, и в выборку попало только около 30% звонков, где удалось распознать всё точно. Абсолютное количество звонков было неважно, нужно было найти причину. Выяснилось, что задержки были в блоке «операции с картой», «кредит», «досрочное погашение». Нашлась проблема и в процессе (не было быстрого способа сделать эту операцию) и в сервисе (он загружался около 9 секунд вместо положенных 3 секунд). Исправили. Продолжили мониторить тишину для улучшения сервиса. Конкретная бизнес-задача — сократить время обслуживания клиента за счёт поиска и оптимизации самых долгих процессов.
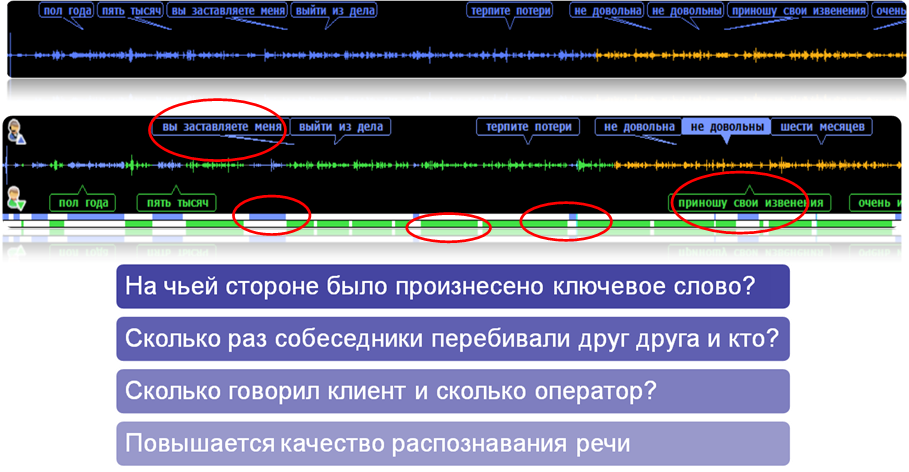
 Общий принцип поиска ключевых слов
Общий принцип поиска ключевых слов
 И категоризация по ним
И категоризация по ним
Когда имеет смысл внедрять такие системы? Когда колл-центр не менее чем на 100 операторов — иначе проще перебирать звонки руками.При этом пост-аналитика не требовательна к инфраструктуре — можно хоть на FTP выкладывать, откуда робот будет забирать записи для анализа и выдавать результат в веб-интерфейсе. Тем не менее есть ряд требований к кодекам и качеству сохранения записей.
Оценку окупаемости дать не могу, потому что задачи у всех разные и разнесены по разным направлениям от безопасности до маркетинга. По отзывам заказчиков и оценкам некоторых вендоров для сферического КЦ в вакууме — от года до двух.
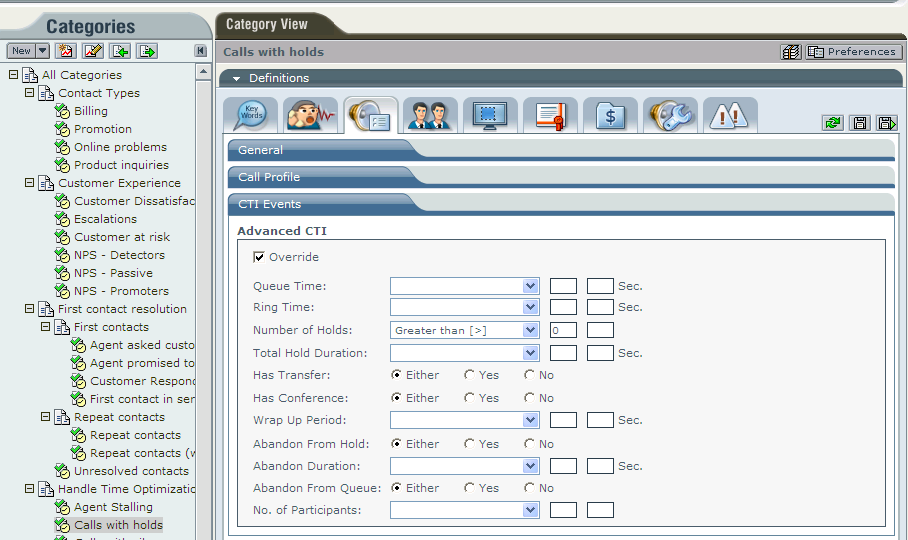 Тонкая настройка одной из систем
Тонкая настройка одной из систем
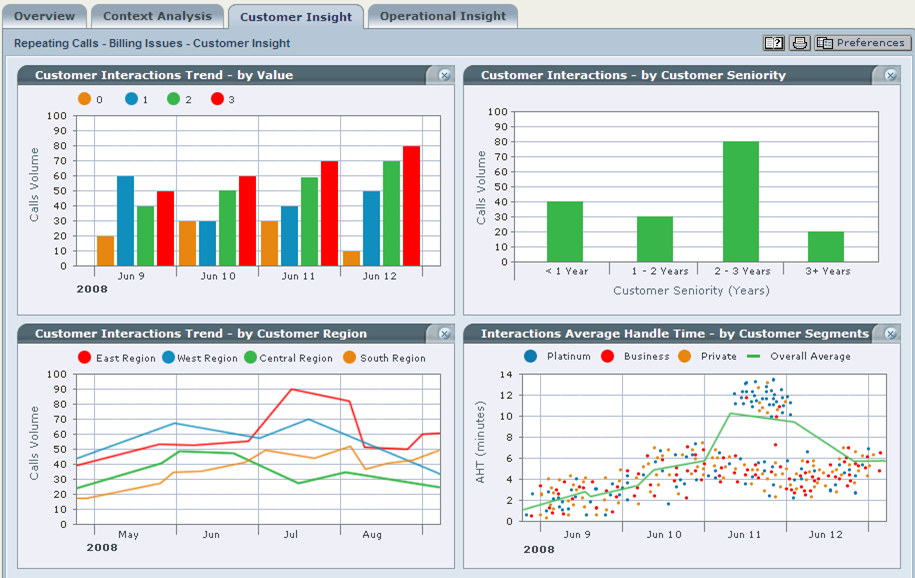 Пример результата по ретроспективному анализу звонков 2008 года
Пример результата по ретроспективному анализу звонков 2008 года
Инструментарий систем аналитики речи (всех известных мне вендоров) позволяет выделять слова и фразы, которые чаще всего употребляются в рассматриваемом срезе звонков. Напомню, используя подобные системы, у нас есть возможность рассматривать весь объем звонков под разными углами: сделать выборку по группе операторов, по длительности звонков, по теме звонка, по количеству тишины, по объему речи клиента и многим другим разрезам данных. Таким образом, мы можем выделять существенные тренды в различных областях работы КЦ.
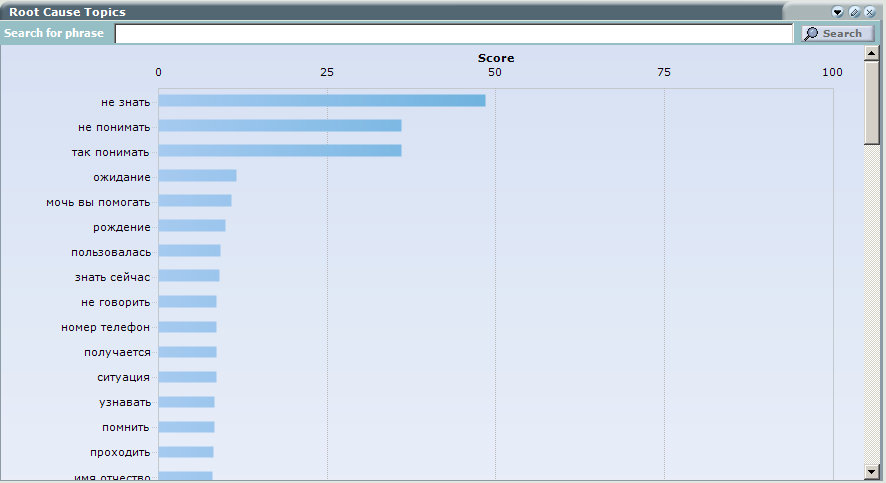
При этом есть дополнительные инструменты, позволяющие понять причины звонков и разобраться, что к чему — это инструменты выстраивающие корреляцию между словами. Проще говоря, я выбираю интересующее меня слово, а система мне показывает, с какими другими словами и фразами оно чаще всего употребляется. В отдельных случаях система ищет не только статистические совпадения, но и старается, и, соответственно, можно понимать причины обращений в КЦ и сортировать по ним подобрать правильный смысл, то есть выстроить внятные предложения. А пользователь системы может легко определять причины обращений в КЦ и осуществлять дальнейший анализ (Root Cause Analysis).
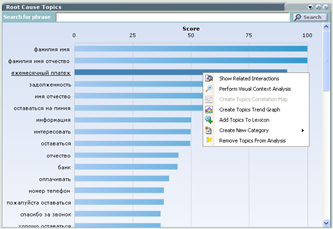
Пример определения причины звонков для уточнения ежемесячного платежа по кредиту:
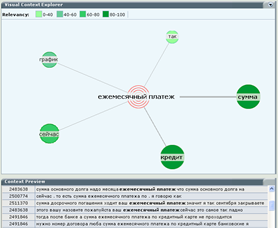
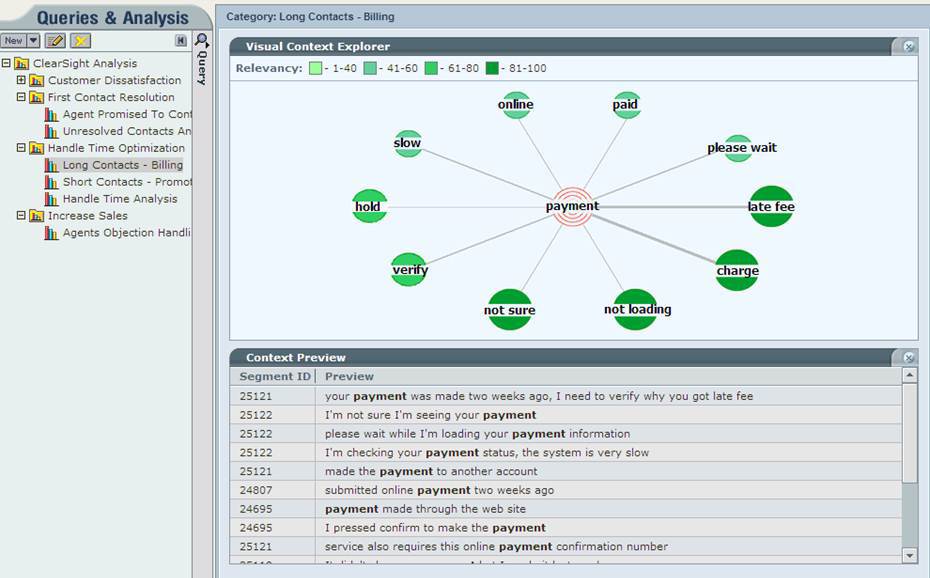
Или вот тут видно, что у пользователей какие-то проблемы с осуществлением платежей:
Внедрение Для IVR и аналитики речи в большинстве случаев требуется установка ПАК на месте. Железо и софт настраиваются в среднем за 2 недели. Ещё около месяца-двух подписываются документы, формулируются правила, согласовываются юридические моменты обработки голоса, интегрируются системы — например, с CRM и так далее.Этот же сервис для пост-аналитики доступен в нашей облачной среде. Можно загружать записи в наш ЦОД, где робот будет их обрабатывать и выдавать отчёты. Сроки те же, только минус две недели на железо. Новые задачи (с уже решёнными организационными вопросами) обычно загоняются в аналитику за день-два.
По языкам — в среднем современными системами поддерживаются около 10 самых популярных языков мира, плюс основные европейские языки не вошедшие в этот список. Русский, естественно, тоже.
Если есть вопросы по конкретным площадкам, готов отвечать в комментариях или по почте DVelikanov@croc.ru.
Резюме Слава роботам!
