Распознавание эмоций в записях телефонных разговоров

Технология распознавания эмоций в речи может может найти применение в огромном количестве задач. В частности, это позволит автоматизировать процесс мониторинга качества обслуживания клиентов call-центров.
Определение эмоций человека по его речи — уже относительно насыщенный рынок. Я рассмотрела несколько решений от компаний российского и международного рынков. Попробуем разобраться, в чем их преимущества и недостатки.
1) Empath

В 2017 году был основан японский стартап Empath. Он создал платформу Web Empath, основанную на алгоритмах, обученных на десятках тысяч голосовых образцов японской медицинской технологической компании Smartmedical. Недостатком платформы является то, что она анализирует только голос и не пытается распознать речь.
Эмоции, передаваемые человеком по текстовому и голосовому каналу, часто не совпадают. Поэтому анализ тональности лишь по одному из каналов недостаточен. Деловым разговорам, особенно, присуща сдержанность в проявлении эмоций, поэтому, как правило, позитивные и негативные фразы произносятся абсолютно безэмоциональным голосом. Однако бывают и противоположные ситуации, когда слова не имеют эмоционального окраса, а голос ярко показывает настроение человека.
Также важное влияние на форму проявления эмоционального состояния оказывают культурные и языковые особенности. И попытки многоязычной классификации эмоций демонстрируют значительное снижение эффективности их распознавания [1]. Тем не менее, такое решение имеет место быть, а компания имеет возможность предлагать свое решение клиентам по всему миру.
2) Центр речевых технологий

В составе программного продукта Smart Logger II компании ЦРТ есть модуль речевой аналитики QM Analyzer, позволяющий в автоматическом режиме отслеживать события на телефонной линии, речевую активность дикторов, распознавать речь и анализировать эмоции. Для анализа эмоционального состояния QM Analyzer измеряет физические характеристики речевого сигнала: амплитуда, частотные и временные параметры, ищет ключевые слова и выражения, характеризующие отношение говорящего к теме [2]. При анализе голоса первые несколько секунд система накапливает данные и оценивает, какой тон разговора был нормальным, и далее, отталкиваясь от него, фиксирует изменения тона в положительную или отрицательную сторону [3].
Недостатком такого подхода является неверное определение нормального тона в случае, когда уже в начале записи речь имеет позитивный или негативный эмоциональный окрас. В таком случае оценки на всей записи будут некорректными.
3) Neurodata Lab

Компания Neurodata Lab разрабатывает решения, которые охватывают широкий спектр направлений в области исследований эмоций и их распознавания по аудио и видео, в том числе технологии по разделению голосов, послойного анализа и идентификации голоса в аудиопотоке, комплексного трекинга движений тела и рук, а также детекции и распознавания ключевых точек и движений мышц лица в видеопотоке в режиме реального времени. В качестве одного из своих первых проектов команда Neurodata Lab собрала русскоязычную мультимодальную базу данных RAMAS — комплексный набор данных об испытываемых эмоциях, включающий параллельную запись 12 каналов: аудио, видео, окулографию, носимые датчики движения и другие — о каждой из ситуаций межличностного взаимодействия. В создании базы данных приняли участие актеры, воссоздающие различные ситуации повседневного общения [4].
На основе RAMAS с помощью нейросетевой технологии компания Neurodata Lab создала решение для контакт-центров, позволяющее распознавать эмоции в голосе клиентов и рассчитывать индекс удовлетворенности обслуживанием непосредственно во время разговора с оператором. При этом анализ осуществляется как на голосовом уровне, так и на семантическом, при переводе речи в текст. Система также учитывает дополнительные параметры: количество пауз в речи оператора, изменение громкости голоса и общее время разговора.
Однако стоит заметить, что база данных для обучения нейронной сети в данном решении была подготовлена специально с участием актеров. А, согласно исследованиям, переход от модельных эмоциональных баз к распознаванию эмоций в спонтанной речи ведет к заметному снижению эффективности работы алгоритмов [1].
Как видим, у каждого решения есть свои плюсы и минусы. Попробуем взять от аналогов все самое лучшее и реализовать собственный сервис для анализа телефонных звонков.
Empath | ЦРТ | Neurodata Lab | Разрабатываемый сервис | |
семантический анализ | - | + | + | + |
русский дата-сет | - | нет | + | + |
дата-сет спонтанных эмоций | + | - | + |
В качестве материалов для создания русскоязычного эмоционального дата-сета со спонтанной речью мне была предоставлена база записей телефонных разговоров от IT-компании Эм Си Арт.
Общий алгоритм работы разрабатываемого сервиса выглядит следующим образом.
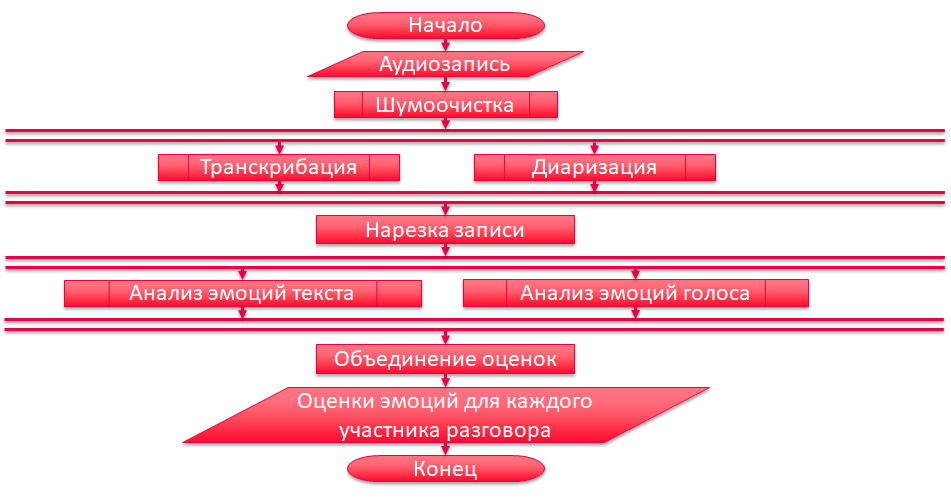 Блок-схема алгоритма обработки звонка
Блок-схема алгоритма обработки звонкаПри реализации были использованы следующие инструменты:
Шумоочистка — RNNoise_Wrapper
Диаризация — pyAudioAnalysis
Транскрибация — vosk-api
Анализ эмоций текста — dostoevsky
Для распознавания эмоций по голосу не нашлось подходящей библиотеки с открытым исходным кодом, поэтому модель для решения данной задачи будем создавать сами.
Для работы со звуковой волной нужно сначала преобразовать ее в цифровой вид. Для этого выполняется процедура дискретизации, после которой будет получен массив чисел, каждое из которых представляет амплитуду звуковой волны через фиксированные промежутки времени. Обучение нейронной сети на этих данных было бы неэффективно, так как их объем очень большой. Чтобы решить данную проблему, можно выполнить преобразование сигнала в набор акустических характеристик. Для этого я использовала библиотеку Librosa.
Я выбрала пять наиболее часто используемых признаков:
мел-частотные кепстральные коэффициенты (MFCC)

вектор цветности

мел-спектрограмма

спектральный контраст

тональный центроид (Tonnetz)

На основе выделенных из записей телефонных разговоров отрезков я составила 3 варианта дата-сетов с различным количеством выделяемых классов эмоций. Также для сравнения результатов обучения была взята берлинская база эмоциональной речи Emo-DB, созданная с привлечением профессиональных актеров.

Сначала я попробовала обучить простые классификаторы библиотеки scikit-learn:
SVC
RandomForestClassifier
GradientBoostingClassifier
KNeighborsClassifier
MLPClassifier
BaggingClassifier
В результате обучения на дата-сете Emo-DB получилось достичь точности распознавания 79%. Однако при тестировании полученной модели на размеченных мной записях телефонных разговоров, точность оказалась равной всего 23%. Это подтверждает тезисы о том, что при многоязычной классификации и переходе от модельных эмоций к спонтанным точность распознавания значительно снижается.
На составленных мной дата-сетах получилось достичь точности 55%.
База данных | Количество классов | Количество записей | Модель | Точность |
Emo-DB | 4 | 408 | MLPClassifier | 79.268%/22.983% |
MCartEmo-admntlf | 7 | 324 | KNeighborsClassifier | 49.231% |
MCartEmo-asnef | 5 | 373 | GradientBoostingClassifier | 49.333% |
MCartEmo-pnn | 3 | 421 | BaggingClassifier | 55.294% |
При увеличении количества выделяемых классов эмоций точность распознавания падала. Это так же может быть связано с уменьшением выборки ввиду сложности разметки по большому количеству классов.
Далее я попробовала обучить сверточную нейронную сеть на дата-сете MCartEmo-pnn. Оптимальной архитектурой оказалась следующая.

Точность распознавания такой сети составила 62.352%.
Далее я провела работу по расширению и фильтрации дата-сета, в результате чего количество записей увеличилось до 566. Модель заново была обучена на этих данных. По итогу точность распознавания увеличилась до 66.666%. Это говорит о необходимости дальнейшего расширения набора данных, что приведет к увеличению точности распознавания эмоций по голосу.
 График истории обучения и матрица ошибок полученной CNN
График истории обучения и матрица ошибок полученной CNNПри проектировании сервиса была выбрана микросервисная архитектура, в рамках которой создается несколько независимых друг от друга узко сфокусированных сервисов, решающих только одну задачу. Любой такой микросервис можно отделить от системы, и дописав некоторую логику, использовать как отдельный продукт.

Сервис Gateway API производит аутентификацию пользователей по стандарту JSON Web Token и выполнять роль прокси-сервера, направляя запросы к функциональным микросервисам, находящимся в закрытом контуре.
Разработанный сервис был проинтегрирован с Битрикс24. Для этого было создано приложение Аналитика речи. В понятиях Битрикс24 это серверное приложение или приложение второго типа. Такие приложения могут обращаться к REST API Битрикс24, используя протокол OAuth 2.0, а также регистрировать свои обработчики событий. Поэтому достаточно было в сервере добавить роуты для установки приложения (по сути регистрация пользователя), удаления приложения (удаление аккаунта пользователя) и обработчик события OnVoximplantCallEnd, который сохраняет результаты анализа записей в карточках связанных со звонками CRM-сущностей. В качестве результатов приложение добавляет расшифровку записи к звонку и комментарий с оценкой успешности разговора по пятибалльной шкале с прикреплением графика изменения эмоционального состояния по каждому участнику разговора.

Заключение
В работе представлен результат исследования на тему распознавания эмоций в речи, в ходе которой на основе русскоязычных записей телефонных разговоров был создан дата-сет эмоциональной речи, на котором была обучена CNN. Точность распознавания составила 66.66%.
Был реализован веб-сервис, с помощью которого можно выполнять очистку аудиозаписей от шума, диаризацию, транскрибацию и анализ эмоций в аудиозаписи или текстовых сообщениях.
Сервис был доработан, чтобы его также можно было использовать как приложение Битрикс24.
Данная работа выполнялась по заказу компании Эм Си Арт в рамках ВКР бакалавра образовательной программы «Нейротехнологии и программирование» университета ИТМО. Также по этой теме у меня был доклад на X КМУ и была принята на публикацию в «Сборнике трудов Конгресса» статья.
В ближайшее время планируется работа по улучшению точности распознавания эмоций по голосу через расширение набора данных для обучения нейросети, а также замена инструмента диаризации, так как качество его работы на практике оказалось недостаточно хорошим.
Список источников
Давыдов, А. Классификация эмоционального состояния диктора по голосу: проблемы и решения / А. Давыдов, В. Киселёв, Д. Кочетков // Труды международной конференции «Диалог 2011.». — 2011. — С. 178–185.
Smart Logger II. Эволюция систем многоканальной записи. От регистрации вызовов к речевой аналитике [Электронный ресурс]. — Режим доступа: http://www.myshared.ru/slide/312083/.
«Smart logger-2» не дремлет. Эмоции операторов call-центров и клиентов под контролем [Электронный ресурс]. — Режим доступа: https://piter.tv/event/_Smart_logger_2_ne_drem/.
Perepelkina, O. RAMAS: Russian Multimodal Corpus of Dyadic Interaction for Studying Emotion Recognition / O. Perepelkina, E. Kazimirova, M. Konstantinova // PeerJ Preprints 6: e26688v1. — 2018.
