Распознавание чеков в Google Docs с помощью ABBYY OCR SDK
Так как песочницей для наших планов выступили Google Docs, а конкретнее Таблицы, то мне захотелось разместить фото всех чеков на отдельном листе. Первая попытка вставить картинку в таблицу через привычный пункт меню «Вставка → Изображение» привела к тому что чек оказался поверх ячеек таблицы и моим друзьям IT-шникам такое оформление точно бы не приглянулось:
«Должен же быть способ вставить картинку в ячейку…», — подумал я. Google нашел этот способ с первого запроса: функция IMAGE (URL), как значение ячейки. Ну что ж, дело сделано:
Можно дальше идти смотреть лыжные уроки. Хотя…
…Google моментально среагировал на мой запрос «Online FineReader API» и выдал несколько статей с хабра о ABBYY Cloud OCR SDK. Быстрый просмотр доступных методов платформы подтвердил мои надежды и желанный ocrsdk.com/documentation/apireference/processReceipt был найден. Для осуществления задуманного недоставало понимания как вставить в ячейку таблицы пользовательскую функцию, которая будет вызывать методы обработки чека. Но и тут поиск меня не подвел и был найден Редактор скриптов Google.
Теперь дело за малым. Первым делом необходимо создать приложение ocrsdk. Делается это в процессе регистрации нового пользователя, так что с этим проблем не возникло. Письмо с паролем приложения, который необходим для аутентификации запросов, было отправлено сразу после завершения регистрации.
Далее в нашей Таблице выбираем пункт меню «Инструменты → Редактор скриптов» и создаем функцию processReceipt (imageUrl):
function processReceipt(imageUrl) {
// Загружаем картинку чека
var image = UrlFetchApp.fetch(imageUrl);
// Формируем заголовок авторизации, который состоит из имени приложения и пароля
var pass = "GoogleDriveTest" + ":" + "********************"
// Формируем POST запрос на обработку чека
var url = "http://cloud.ocrsdk.com/processReceipt";
var headers = {
"Content-Type":"image/png",
"Authorization" : "Basic " + Utilities.base64Encode(pass)
};
var options = {
"method":"POST",
"headers": headers,
"payload" : image.getContent()
};
var response = UrlFetchApp.fetch(url, options);
// Парсим XML ответа и находим в нем ID задачи по обработке нашего чека (больше деталей тут http://ocrsdk.com/documentation/apireference/processReceipt/)
var document = XmlService.parse(response.getContentText())
var id = document.getRootElement().getChildren()[0].getAttribute('id').getValue()
var resultUrl
// Ждем успешного завершения задачи и получаем url по которому можно получить результат обработки чека
do {
Utilities.sleep(3000)
url = "http://cloud.ocrsdk.com/getTaskStatus" + "?taskId=" + id;
headers = {
"Authorization" : "Basic " + Utilities.base64Encode(pass)
};
options = {
"method":"GET",
"headers": headers,
};
response = UrlFetchApp.fetch(url, options);
document = XmlService.parse(response.getContentText());
if (document.getRootElement().getChildren()[0].getAttribute('status').getValue() == 'Completed') {
resultUrl = document.getRootElement().getChildren()[0].getAttribute('resultUrl').getValue()
break
}
} while(true)
// Получаем результат обработки чека
options = {
"method":"GET",
};
response = UrlFetchApp.fetch(resultUrl, options);
document = XmlService.parse(response.getContentText());
// document содаржит XML нашего чека. Из-за моральных принципов реализацию функции findTotalPriceInReceiptXML я скрыл :)
result = findTotalPriceInReceiptXML(document)
return result
}
Всё сохраняем и идем обратно в таблицу. Чтоб сие чудо заработало, пришлось вынести в отдельную ячейку таблицы URL картинки чека. Наша функция теперь доступна как =processReceipt (ячейка с URL).
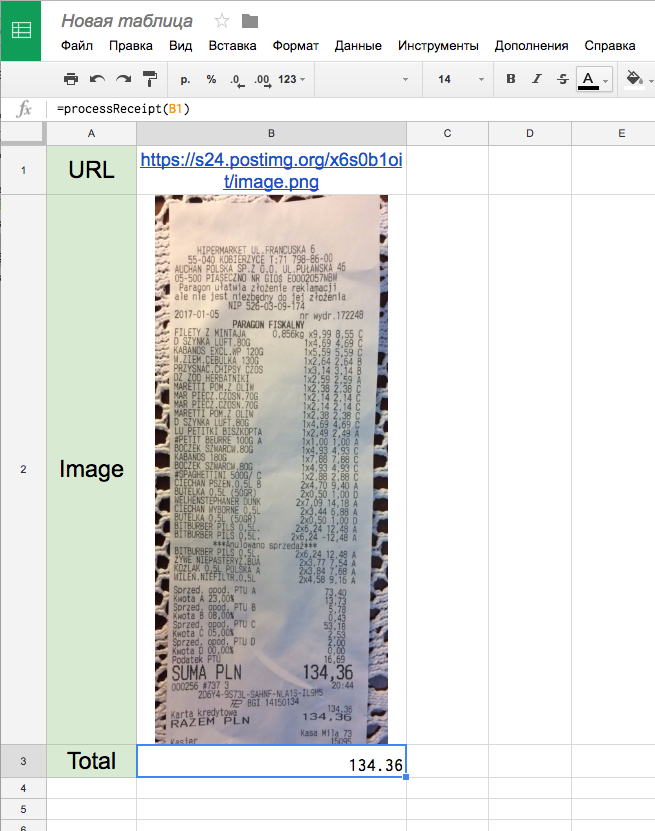
Всем хорошей зимней погоды и удачи на лыжных склонах!
Комментарии (4)
 and7ey
and7ey
6 января 2017 в 18:52
0↑
↓
After the registration Customer will automatically receive a Free Test Set through his account. This test set consists of Free 50 Customer«s A4 Images — any 50 images which are valid for 90 days after the registration has been completed.
…
Receipt is considered to be an image processed with processReceipt method. Every Receipt recognition is charged as a recognition of two A4 pages.
Т.е. лишь 25 чеков можно распознать бесплатно. Печально.-
and7ey
6 января 2017 в 19:00
+1↑
↓
Хотя можно 100 страниц в месяц получить бесплатно — http://blog.ocrsdk.com/get-the-best-ocr-technology-for-free. Уже лучше:).
6 января 2017 в 19:30
+1↑
↓
Что-то мне подсказывает, что просто вбить »134.36» руками было бы быстрее, чем фотографировать чек, вставлять его в документ и распознавать. Здесь нужно писать приложение для телефона, которое само фотографирует чек и распознаёт его.6 января 2017 в 20:06
0↑
↓
Вы правы в том что приложение решит задачу организации базы фотографий чеков с их распознаванием более качественно. Более того, таких приложений написано предостаточно. А вот метод продемонстрированный в статье, хоть и не оптимален, но достаточно оригинален. Его плюс в том, что всё что вам надо сделать — написать логику по обработке изображения, а вот о визуальной составляющей уже позаботились инженеры google.
