Raft (не)всемогущий: какие надстройки повышают надёжность алгоритма
Все любят Raft. Существует устойчивое мнение, что присутствие этого алгоритма в какой-нибудь распределённой системе означает, что всё с этой системой будет хорошо. А именно:
До тех пор, пока большинство узлов в кластере живо и подключено друг к другу, кластер будет доступен на запись (с перерывами на выборы лидера).
Если лидер работоспособен и связан с большинством, то кластер будет постоянно доступен на запись.
Если лидер откажет, то новый лидер будет выбран «быстро» (что бы это ни значило).
На самом деле, одного лишь следования спецификации Raft (https://raft.github.io/raft.pdf или варианту из кандидатской Диего Онгаро) недостаточно для того, чтобы добиться всего вышеперечисленного. На этом в своё время погорели даже etcd, что привело к инциденту с недоступностью кластера на запись в Cloudflare в 2020 году.
Меня зовут Сергей Петренко, вот уже четыре года я работаю над репликацией в Tarantool, и сегодня хочу рассказать про слабые места алгоритма Raft и способы их преодоления. Эта статья — вольный пересказ нашего с Борисом Степаненко доклада на Hydra 2022. Если читатель не знаком с Raft, то предлагаю ознакомиться с моей статьёй о нём.

Начну немного издалека. Предположим, у вас есть система с Raft и вы хотите использовать её в проде. Все мы не раз слышали, что Raft гарантирует наличие не более чем одного лидера в каждом терме, а также способен пережить потерю чуть менее половины узлов в кластере, не потеряв работоспособности. То есть, если лидер жив, он сможет обрабатывать записи, а если лидера нет, то новый будет найден. Казалось бы, кроме этих гарантий для долгой эксплуатации системы нам ничего больше и не нужно. Так ли это на самом деле? Сейчас и узнаем.
Во-первых, давайте посмотрим повнимательнее на гарантию того, что кластер останется работоспособным до тех пор, пока большинство серверов работоспособны и связаны друг с другом. Неправильное понимание этой гарантии и привело в итоге к инциденту в Cloudflare.
Pre-Vote
Начнём с примера. Давайте посмотрим, как будет себя вести кластер Raft в случае частичной потери связности.

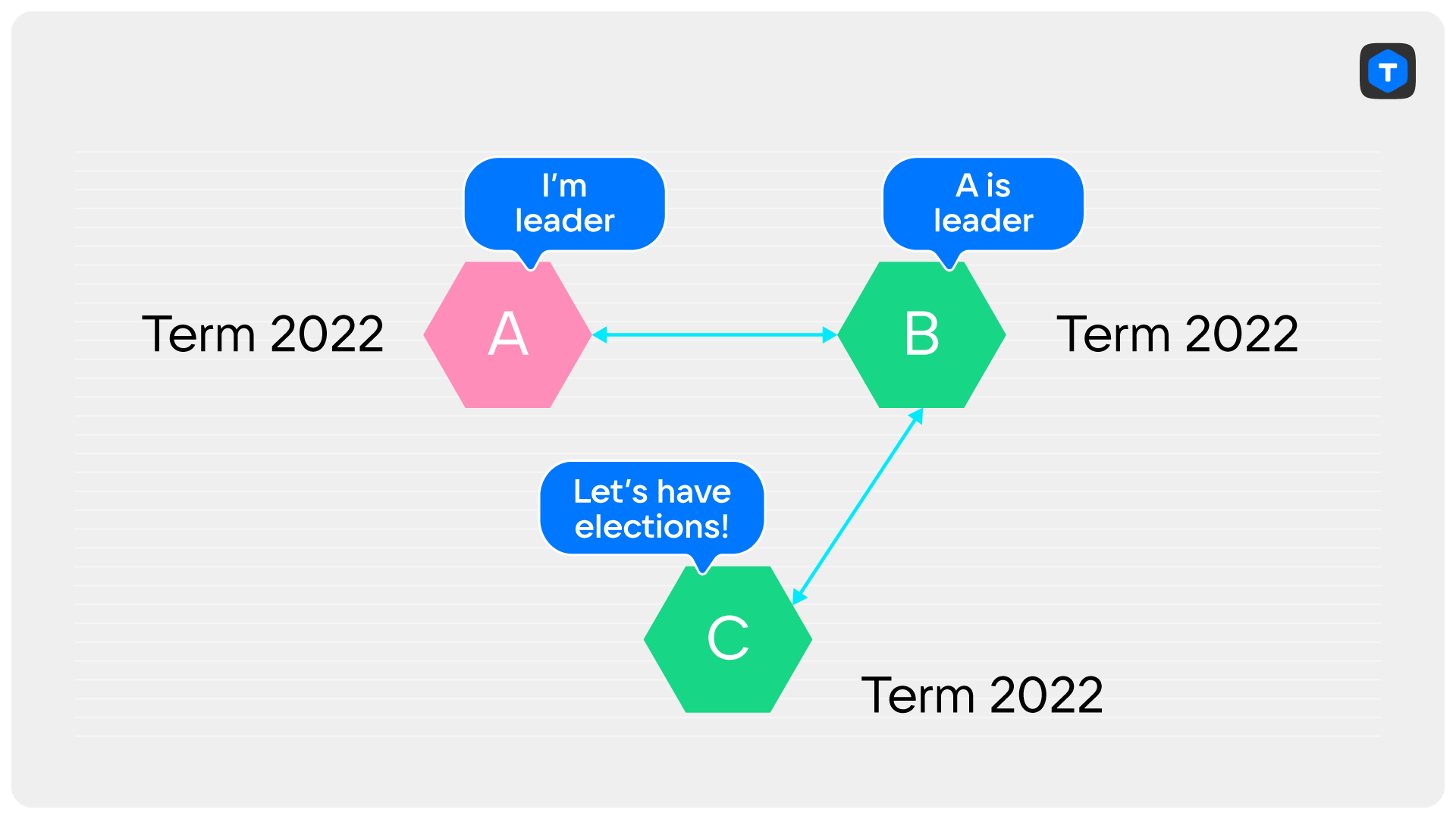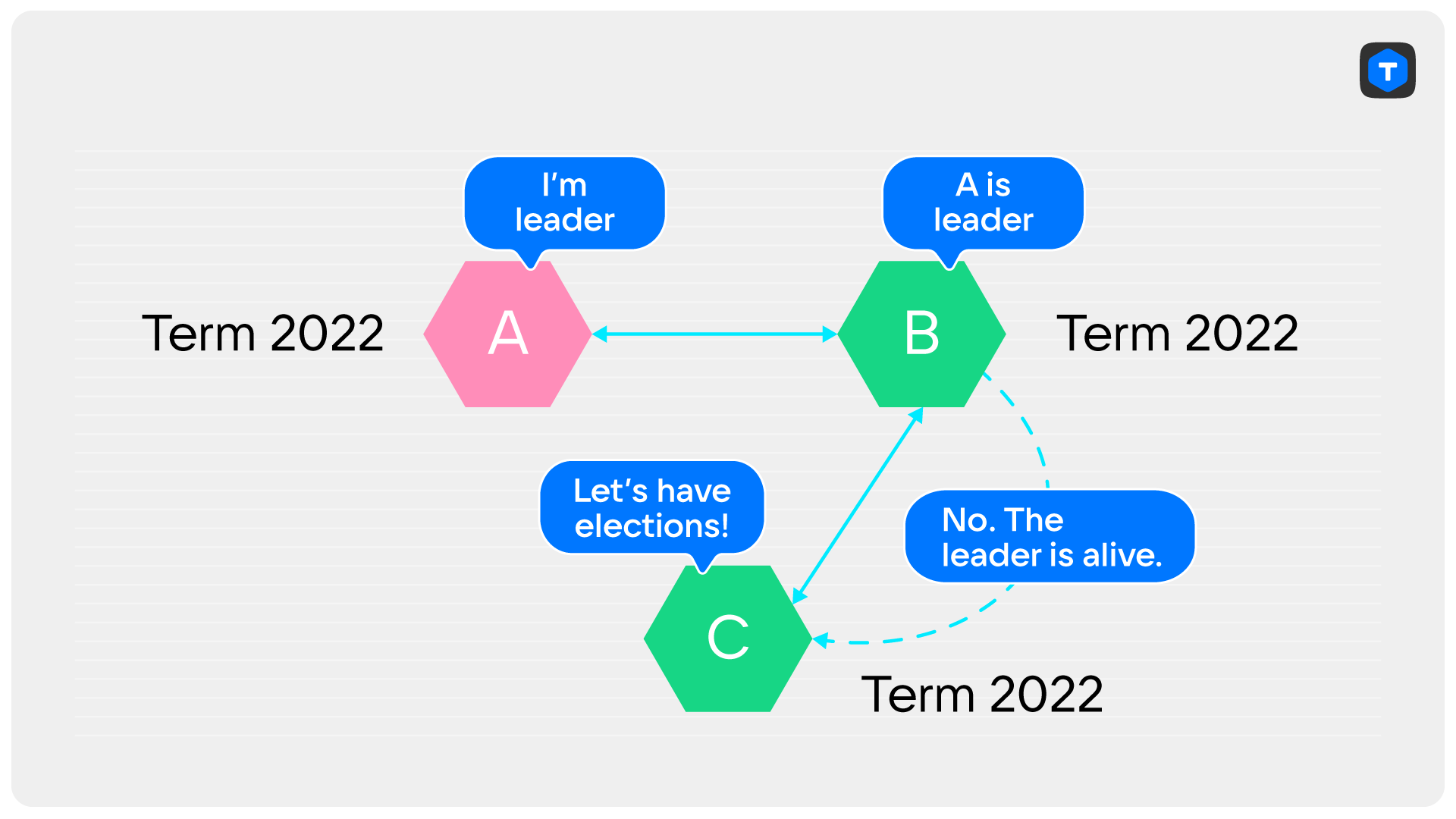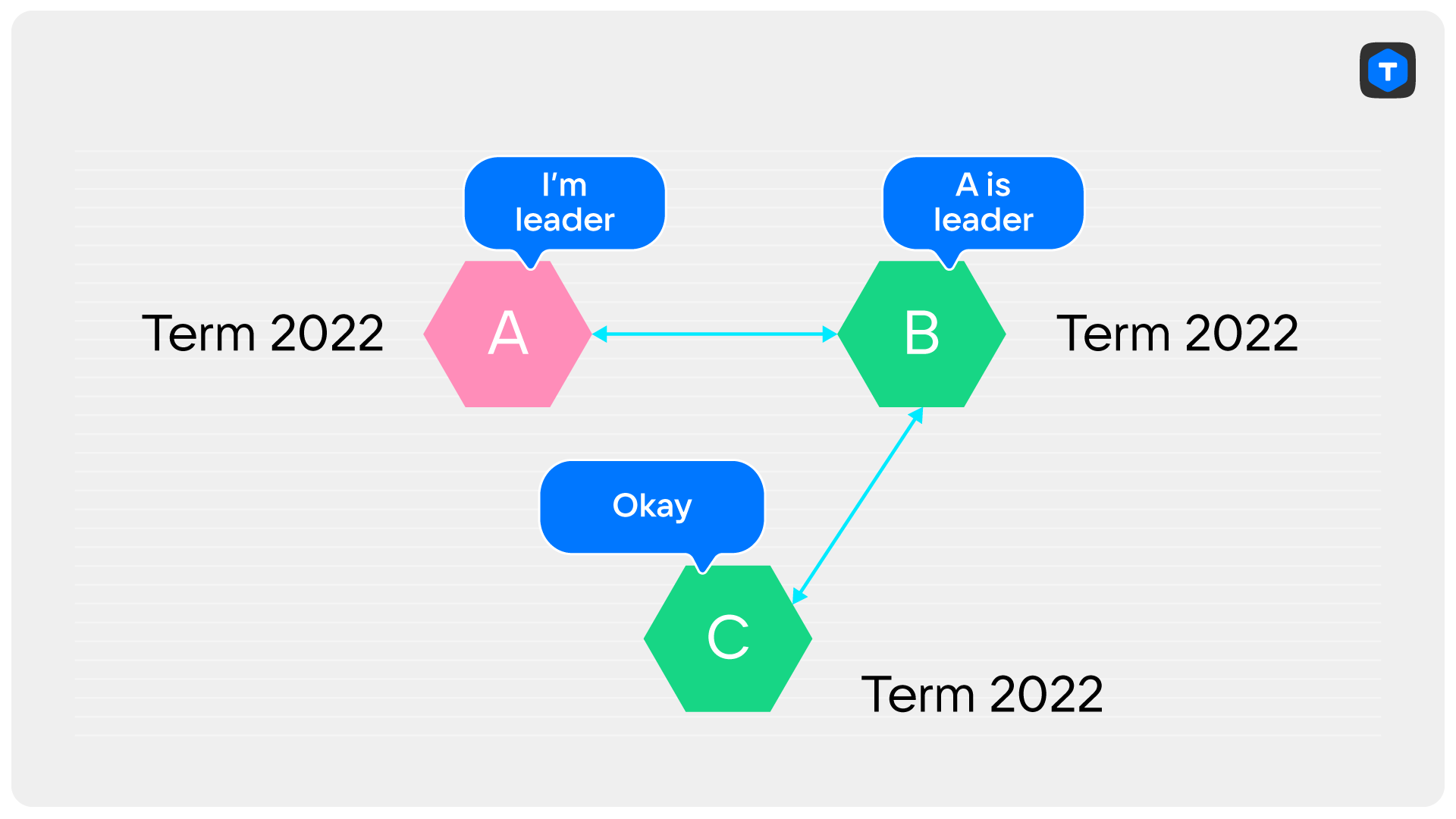
Предположим, наш кластер состоит из трёх узлов, A, B и C. A — лидер. B и C — его реплики, на дворе 2022 терм. К чему приводит обрыв связи между A и C? Не получив от лидера ни одного heart beat«а за election_timeout, сервер C решит, что лидер пропал, и начнёт выборы в терме 2023.
Единственный, кому сервер C может послать RequestVote — сервер B.
Получив запрос с бóльшим термом, сервер B повысит и свой терм. При этом он не обязательно проголосует за C, ведь у B могут быть более свежие данные, если лидер что-то записал с момента потери связи.
В ответ на очередное сообщение от лидера (напомню, пока ещё это сервер A), сервер B сообщит, что терм вырос, чем вынудит сервер A сложить полномочия. Кластер остаётся без лидера, идут выборы. Пока лидер не появится, кластер недоступен на запись.
Если же так получилось, что с момента обрыва соединения новых записей не было, то сервер B проголосует за сервер C сразу же по получении RequestVote.

Если такое произошло, мы попадем в вечный цикл:
Сервер C не видит лидера.
По истечении election_timeout сервер C начинает выборы.
Повышение терма достигает сервера A через сервер B.
Сервер B голосует за C.
Сервер A складывает полномочия.
A и C меняются местами, и всё повторяется с пункта 1, но уже в новом терме.
Клиент, подключённый к такому кластеру с мигающим лидером, скорее всего не сможет ничего записать. Стоит ему обнаружить действующего лидера и попытаться сделать запись, как тот уже складывает полномочия и даже не знает, кому переслать запрос на запись (так как не видит нового лидера напрямую). Всё это будет продолжаться до тех пор, пока чудом не получится сделать хотя бы одну запись или пока не восстановится связь между A и C. Именно это и произошло в Cloudflare с etcd. А внешняя система совершенно справедливо решила, что раз не выходит что-нибудь записать в кластер etcd, значит в нём отказало большинство узлов и нужно применять экстренные меры. Всего 6 минут недоступности etcd на запись привели к аварии продолжительностью более 6 часов.
Тут читателю может показаться, что какая-то из гарантий Raft нарушена. На самом деле нет.
В каждый момент времени лидер связан с большинством (включая себя), сам лидер не отказывает. И тем не менее наши ожидания рушатся. Кластер неработоспособен.
Но дело в том, что Raft никогда и не обещал работоспособности в такой ситуации. Было обещано лишь, что «лидер будет найден, если большинство узлов работоспособно и связано друг с другом». Речи о том, что лидер будет постоянен, вообще не идёт. А гарантия того, что лидер будет найден, не нарушается. Он в примере выше становится «найден» приблизительно раз в election_timeout. Выясняется, что на практике гарантий Raft недостаточно.
Но это только полбеды.
Вернёмся назад в терм 2022 и представим, что в нашем кластере из узлов A, B и C узел C полностью потерял связь с остальными. Сервер A — лидер, он связан с сервером B и может обрабатывать запросы на запись. Пока всё хорошо.

Сервер C, как и в примере выше, будет начинать новые выборы раз в election_timeout. Выиграть ни одни из них сервер C не сможет. Он просто не наберёт большинство голосов. Однако его терм будет неограниченно расти, и в момент восстановления связности сервер A опять сложит полномочия, увидев больший терм. Кластер опять перешёл в read-only как минимум на один раунд выборов без видимых на то причин.
Решение Raft
О проблеме таких «мешающих» (disruptive) серверов говорит и автор Raft, Диего Онгаро, в своей диссертации. Он, правда, упоминает их в связи с изменениями конфигурации.
Решение, предложенное автором Raft — новая стадия выборов, называемая Pre-Vote. Идея заключается в том, что каждый сервер перед началом выборов рассылает всем запрос на голос «понарошку», который тоже называется PreVote. Этот запрос содержит те же поля, что и обычный RequestVote, и голосующий отвечает на него по тем же правилам, что и на RequestVote. Разница только в том, что голосующий не повышает терм при получении этого запроса, а также отвечает отрицательно либо просто игнорирует запрос, если ещё видит лидера в текущем терме.
Кандидат повышает терм и начинает настоящие выборы только после того, как получит подтверждение, что большинство голосующих готово проголосовать за него.
Давайте убедимся, что PreVote спас бы Cloudflare от инцидента. Посмотрим на ту же ситуацию, где С потерял связь с лидером, но не с другой репликой. Хотя C и может послать B запрос PreVote, B на него ответит отрицательно, поскольку сам видит лидера. C не сможет набрать большинство, то есть два ответа на PreVote.
При полной потере и последующем восстановлении связности PreVote тоже поможет. Действительно, сервер C не сможет получить ни одного ответа на запрос PreVote, а значит и не будет начинать выборы.

Единственный недостаток оригинального решения для нас — нарушение обратной совместимости. Raft уже какое-то время работает в Tarantool, и в протоколе нет запроса PreVote. Его, конечно, можно добавить, но старые серверы не умеют обрабатывать новые запросы. Пришлось бы вводить дополнительную логику на стороне отправителя: если сервер старый, не отправляем ему запрос PreVote и по умолчанию считаем, что он ответил на него положительно. Мы такое не любим и стараемся избавляться от уже существующих мест, в которых есть дополнительный код для поддержки старых версий. Нам бы больше подошло решение, расширяющее один из существующих запросов. Старые серверы просто игнорируют новые поля в существующем запросе, а значит дополнительная логика не нужна. Мы пошли именно по этому пути.
Наше решение
«В Tarantool сервер знает достаточно, чтобы не начинать выборы, когда это не нужно», — подумали мы, и сделали Pre-Vote по-своему. Мы заставили все реплики сообщать окружающим о том, видят ли они лидера. Собрав информацию о том, кто видит лидера, а кто — нет, можно решать, начинать ли выборы. Если хоть кто-то видит лидера, или если нет связи с большинством, то выборы начинать не будем.
Преимущество нашего решения в обратной совместимости. Не потребовалось вводить новый запрос и специальным образом обрабатывать его отправку на старые серверы, если в кластере присутствуют серверы с разными версиями Tarantool.
Недостаток в том, что мы не сравниваем журналы лидера и голосующих, а значит начинаем выборы, даже если журналы голосующих содержат более свежие данные. Это не плохо: до тех пор, пока кто-то видит лидера, выборов не будет. А когда все перестанут его видеть, выборы в любом случае начнутся. Закончатся они за один или несколько раундов — уже не так важно благодаря другой нашей модификации, Split-Vote detection. О ней сейчас и поговорим.
Split-Vote detection
На этот раз у меня нет для вас страшилки с Cloudflare или другой известной компанией, но, надеюсь, и без этого будет интересно.
Как известно, не каждый раунд выборов заканчивается появлением лидера. Например, если в кластере сразу несколько узлов заметят его пропажу, то они начнут выборы независимо, до того, как получат друг от друга запросы RequestVote. Голоса оставшихся реплик вполне могут разделиться между несколькими кандидатами так, что ни один из кандидатов не наберёт большинство голосов. Эту ситуацию будем называть split-vote.
В Raft с этим борются с помощью рандомизации election_timeout. На каждом сервере и в каждом раунде выбирается новое случайное значение, немного отличающееся от сконфигурированного. Таким образом повышаются шансы того, что очередные выборы успеет начать только один кандидат, а остальные получат от него RequestVote до истечения их собственного election_timeout. Если бы в Raft это не было сделано, то выборы могли никогда не закончиться: все серверы перезапускали бы их синхронно, отдавая голос за себя. Однако у нас всё ещё есть место для оптимизации: каждый лишний раунд выборов — это election_timeout простоя кластера в read-only.
Наше решение
На самом деле раунды, в которых произошла ничья, тратят время впустую. Если бы лидер был избран, это, скорее всего, произошло бы в начале раунда (приблизительно через время обмена пакетами между самыми далёкими серверами). При этом election_timeout много больше этого времени согласно требованиям Raft.
Кроме того, в Tarantool, в отличие от канонического Raft, сервер рассылает информацию об отданном голосе не только кандидату, за которого проголосовал, а вообще всем членам кластера. Это значит, что каждый из серверов может следить за тем, сколько голосов набрал каждый из кандидатов. Увидев, что ни один из кандидатов уже не может выиграть в текущем раунде, сервер ускоряет начало нового раунда. С момента обнаружения ничьей до начала нового раунда проходит в среднем 0.05 * election_timeout. Дело в том, что в пределах одной десятой от election_timeout мы выбираем случайную задержку перезапуска выборов. Ровно с той же целью, что и Raft: чтобы избежать новой ничьей. Таким образом, в лучшем случае мы экономим приблизительно 0.9 * election_timeout на каждом раунде с ничьей. Это очень заметно: в оригинальном Raft найти лидера за два раунда означает потратить порядка election_timeout + какая-то доля election_timeout. У нас же два таких раунда займут долю election_timeout. Быстрее, чем оригинальный Raft поймёт, что случилась ничья.
В худшем случае, когда ничья случается два или более раз подряд, мы ускоряемся ещё значительнее. Каждый раунд с ничьей для нас практически ничего не стоит. При этом мы никак не повышаем вероятность повторной ничьей: случайную задержку на перезапуск выборов в этом случае мы генерируем в тех же пределах, что и в обычной ситуации.
CheckQuorum
Raft гарантирует, что в одном терме не может быть двух лидеров. Однако ничего не говорится про существование двух лидеров в один момент времени (в старом терме и в новом). Нам бы хотелось избежать таких ситуаций. Причина в том, что клиенты, подключённые к старому лидеру, могут и не заметить, что появился новый. У них просто не будет причин это проверять до тех пор, пока старый лидер не сложил полномочия. Он будет доступен на запись, а синхронные транзакции будут откатываться после того, как не наберут ACK-ов от большинства реплик.

Для нас наличие двух лидеров в один момент времени критично, потому что Tarantool поддерживает не только синхронную, но и асинхронную репликацию. Каждый из лидеров доступен на запись, и если писать на старом лидере асинхронные транзакции, то клиент может вообще не заметить, что произошла смена лидера. Это приведёт к тому, что часть клиентов будет обращаться к новому лидеру, часть — к старому. Получим split-brain. Чтобы такого избежать, необходимо, чтобы старый лидер складывал полномочия и переходил в read-only, как только появляется вероятность, что его кто-то сместил.
Ситуация с двумя лидерами возможна только в случае, когда старый потерял связь с большинством серверов в кластере. Действительно, раз для победы на выборах нужно получить большинство голосов, то единственный вариант, при котором старый лидер не узнает о выборах — отсутствие у него связи с большинством. Если бы он был соединён хотя бы с одним сервером, проголосовавшим за нового лидера, он бы сразу же сложил полномочия. А такого, чтобы старый лидер был соединён с большинством, среди которого никто не голосовал, а одновременно новый — с проголосовавшим большинством, быть не может.
Итак, мы хотим добиться того, чтобы лидер складывал полномочия сразу же, как только потерял связь с большинством кластера. Если связность потеряна, то, скорее всего, большинство уже выбрало другого лидера.
Есть еще одна причина, по который CheckQuorum необходим: без него наличие одного лишь PreVote может привести к тому, что кластер окажется «заблокирован»: текущий лидер не сможет ничего писать, а ни одна из реплик не сможет начать выборы. Давайте посмотрим на пример: пусть у нас был кластер из пяти серверов. Один из них — D — был лидером. Дальше произошла невероятная череда событий: сперва отказал сервер E, затем по какой-то причине порвалась связь между A и D, и, наконец, по какой-нибудь новой причине пропала связь между C и D.
В результате, хоть сервер D и остаётся лидером, он не может коммитить синхронные транзакции, поскольку не набирает три подтверждения. Сервер B не начинает выборы, так как видит лидера — D, а серверы A и C не начинают выборы, потому что сервер B сказал им, что лидер жив.

CheckQuorum спасает от этой ситуации, поскольку лидер, потерявший связь с большинством, сложит полномочия, что позволит одной из его реплик баллотироваться.
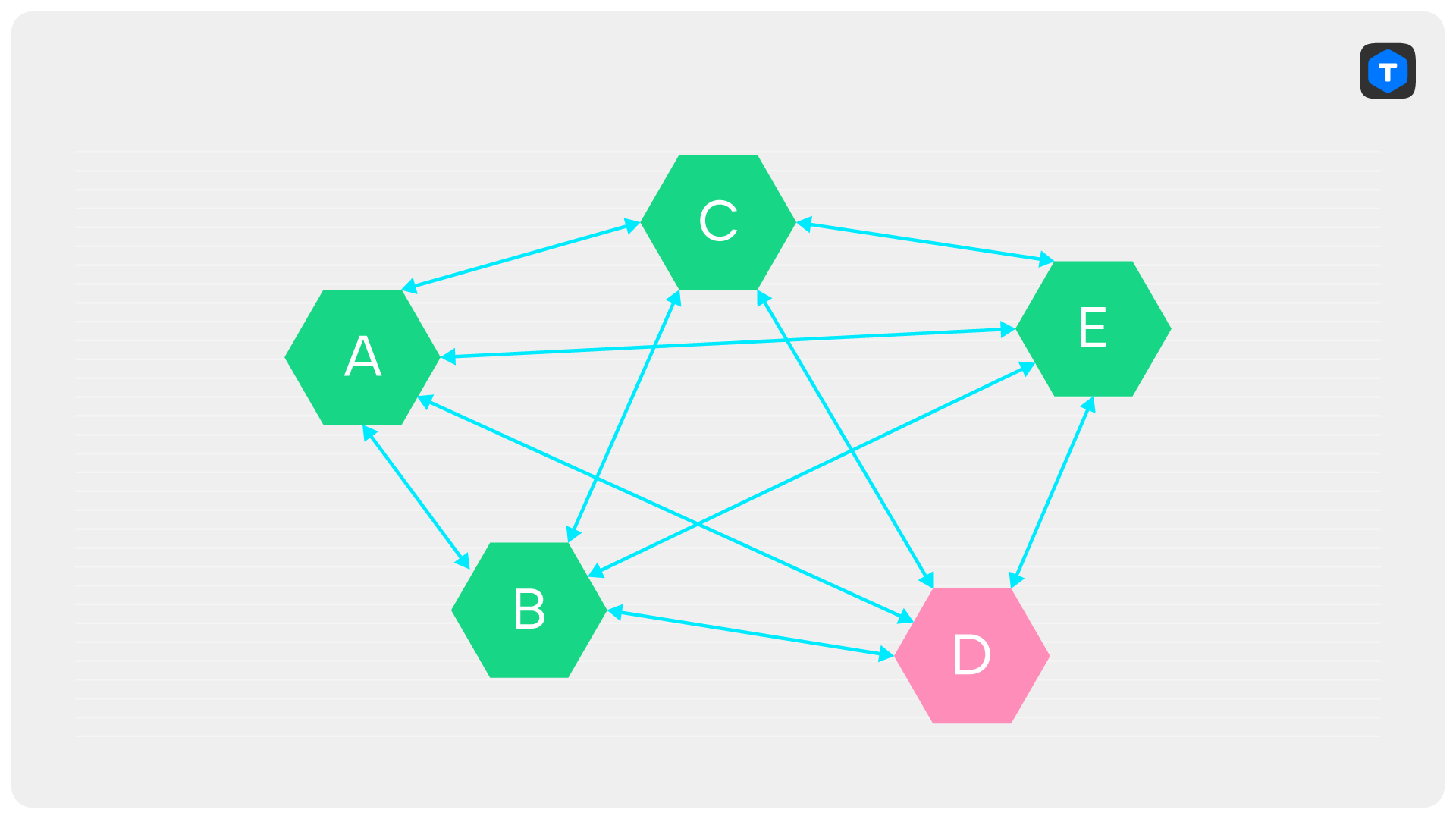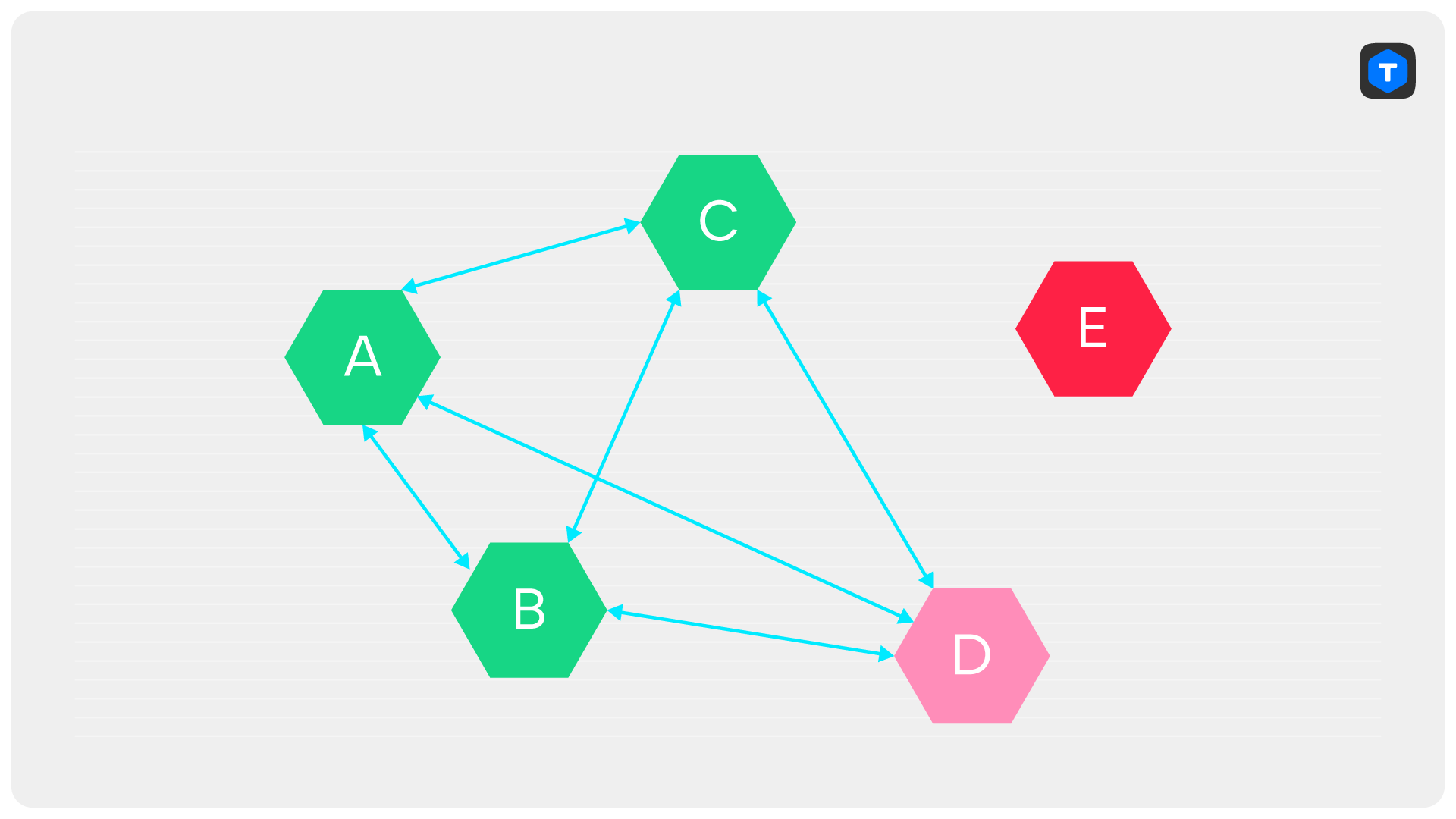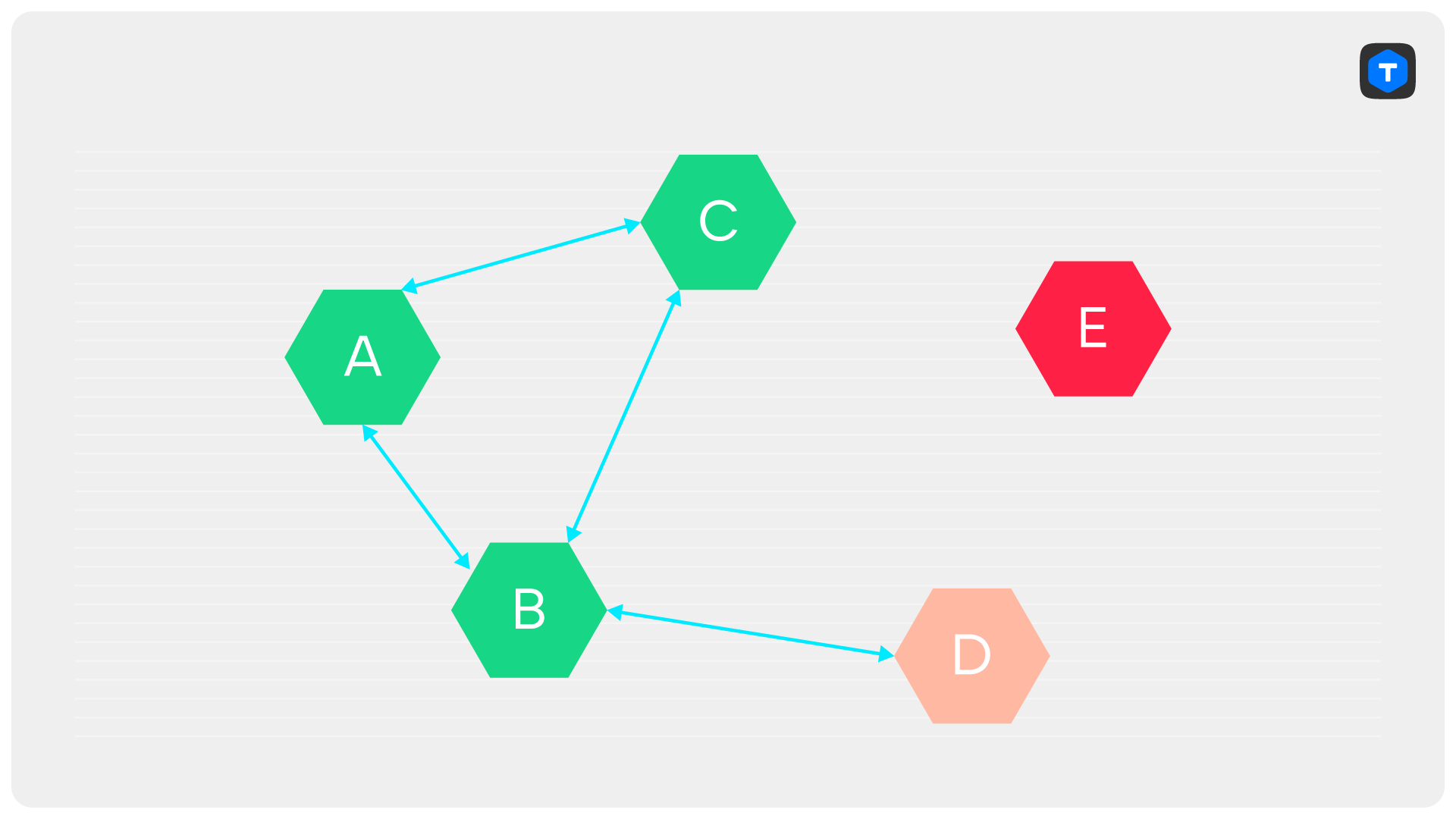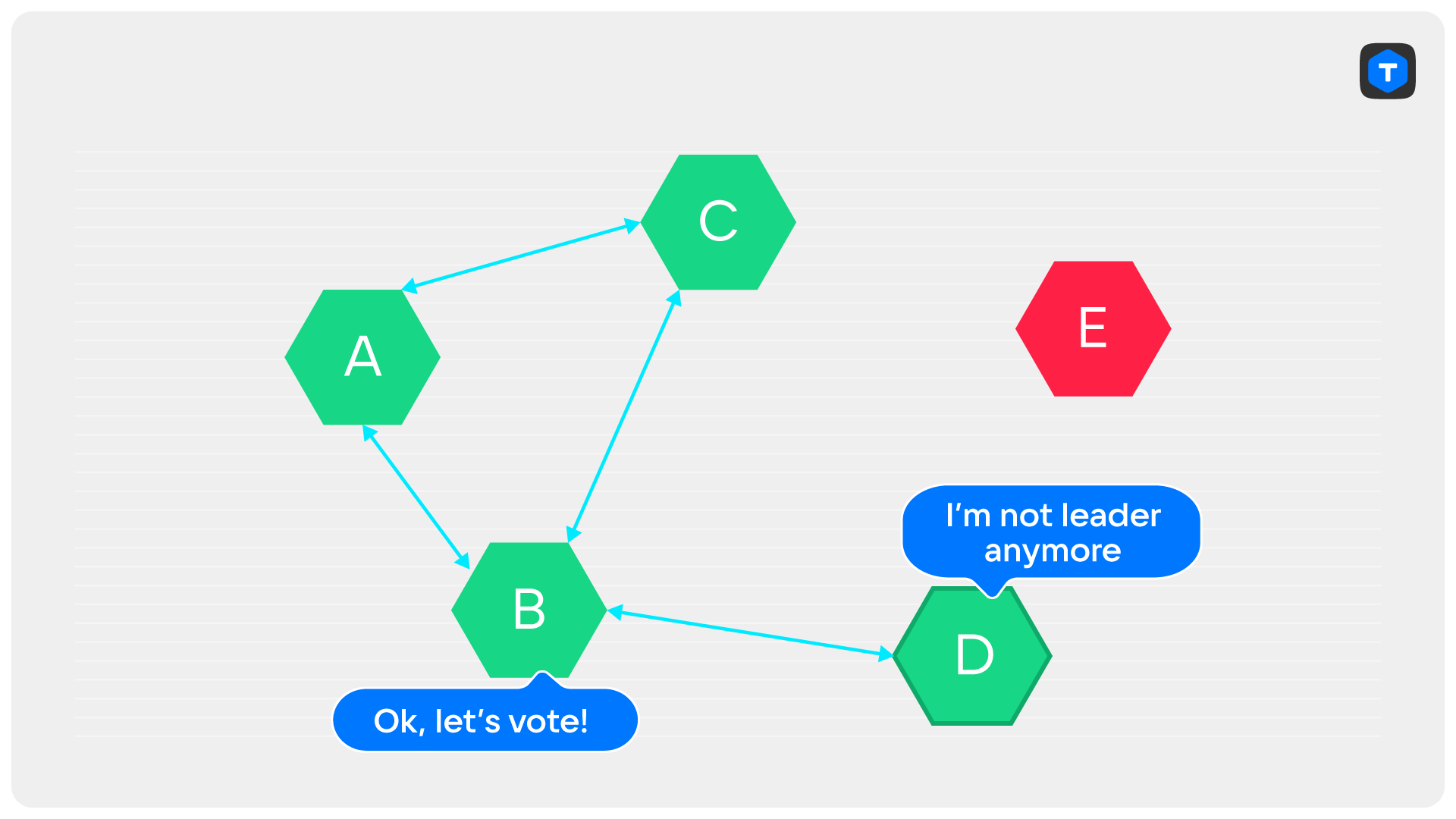
Остаётся понять, в какой именно момент лидер должен сложить полномочия. Для примера с заблокированным кластером это не важно. Важно, чтобы лидер рано или поздно это сделал, тем самым позволив репликам начать выборы.
Если используется только синхронная репликация, то всё легко и просто. Скорость складывания полномочий тоже не важна. Старый лидер всё равно не сможет подтвердить ни одну из синхронных транзакций, пришедших после обрыва связи.
Если же используются асинхронные транзакции, то для обеспечения консистентности придётся произвести сразу несколько действий.
Программа минимум: старый лидер должен сложить полномочия строго до того, как реплики смогут выбрать нового лидера. Это нужно, чтобы в кластере не было двух writeable-узлов в один момент времени. Такой режим будем называть строгим CheckQuorum.
Но этого недостаточно. Мы не можем гарантировать, что ни одна асинхронная транзакция не будет записана после обрыва связи. В любом случае перед обнаружением потери связи пройдёт какое-то, пусть и небольшое, время. Это значит, что старый лидер запишет транзакцию, которой не будет на новом. Когда связь, наконец, восстановится, транзакция попадёт на остальные узлы, и консистентность всего, что писал новый лидер, может быть нарушена. Отсюда следует и программа максимум.
Программа максимум: после восстановления связности новый лидер и все его реплики не должны применять транзакции, записанные старым лидером. Это мы обсудим в следующей главе, а пока поговорим о том, как же добиться программы минимум.
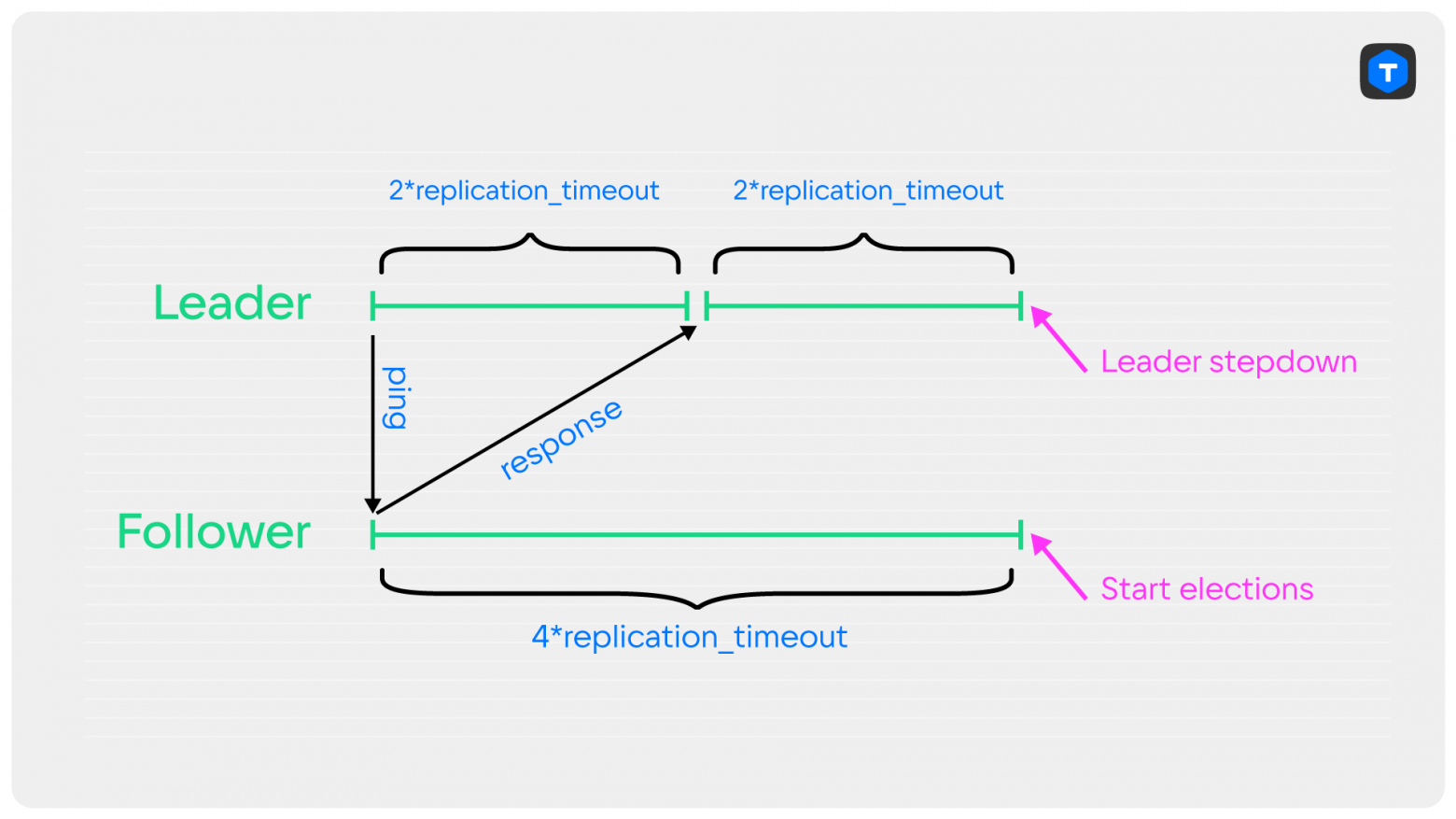
Итак, и лидер, и реплики, следят за состоянием подключения с помощью heart beat«ов. Если от сервера в течение 4 * replication_timeoutне приходят heart beat«ы, то соединение считается порванным. Heart beat реплики является ответом на heart beat мастера, и посылается только после получения heart beat«а от мастера.

Как видно, после последнего обмена heart beat«ами лидер перезапускает таймер на обрыв соединения позже, чем это делает реплика. В самом худшем случае последний heart beat от реплики придёт лидеру ровно в момент истечения таймаута. Лидер не знает, в какой момент реплика отправила heart beat, с тех пор на ней мог уже истечь таймаут.
Если же реплика ещё и успеет быстро провести выборы, то старый лидер сложит полномочия слишком поздно.

Итак, в худшем случае лидер заметит обрыв соединения вдвое позже, чем реплика. Значит, чтобы гарантировать сложение полномочий лидером строго до того, как большинство начнёт выборы, необходимо, чтобы таймаут на лидере был вдвое меньше, чем на репликах. Так и поступим.
Split-Brain detection
Tarantool позволяет конфигурировать кворум. Это удобно: можно, например, экстренно разблокировать кластер, в котором отказала большая часть узлов. Но это и опасно: с кворумом ниже, чем N / 2 + 1, может возникнуть два не связанных друг с другом лидера. Либо в одном и том же терме, либо в разных. Оба лидера при этом могут независимо подтверждать синхронные транзакции и писать асинхронные. Если восстановить связность после того, как в кластере какое-то время работало два лидера, то изменения одного перезапишут изменения другого. Чтобы этого не допустить, необходимо обнаруживать в потоке репликации транзакции от конкурирующего лидера, и, не применяя их, разрывать соединение с узлом, который их прислал.
Запись PROMOTE
Маркером появления нового лидера является запись PROMOTE. Она содержит терм, в котором лидер был избран, ID этого лидера, ID предыдущего и последний полученный лидером LSN предыдущего лидера. Этой информации достаточно, чтобы выстроить линейную историю лидерства с самого первого терма и до конца. Когда кластер работает штатно, каждый приходящий PROMOTE согласован с известной узлу информацией: терм — наибольший из всех, приходивших до сих пор, ID предыдущего лидера верно указывает на ID в предыдущем PROMOTE, LSN предыдущего лидера совпадает с LSN последней подтвержденной предыдущим лидером транзакции.

Если хотя бы одно из условий не выполнено, значит, произошёл split-brain.

Также нужно обнаруживать случаи, когда старый лидер продолжал подтверждать транзакции уже после того, как в кластере появился новый лидер. Фактически, приход любой транзакции от узла, не приславшего последний PROMOTE, это показатель split-brain«а.

Последний пример решает и нашу проблему со строгим CheckQuorum: теперь любая транзакция (и синхронная, и асинхронная), пришедшая от старого лидера, ведёт к обрыву связи с ним и не применяется, тем самым сохраняя консистентность данных на новом лидере и его репликах. А значит старый лидер не может повлиять на состояние нового лидера и его реплик.
Уроки из сказанного
Канонический Raft не обеспечивает работоспособность кластера в случае частичной потери связности. Чтобы справиться с этим, применяются две модификации: PreVote и CheckQuorum.
Наше отклонение от канонической реализации позволило ускорить выборы с помощью обнаружения ничьей, и в то же время потребовало дополнительных модификаций для обеспечения консисентости: (строгий CheckQuorum и Split-Brain detection).
