RAD с помощью многомерного табличного процессора
Хочу поделиться с хабрсообществом проектом из области business intelligence, которым я занимаюсь в свободное время последние полтора года.
Многие используют табличные процессоры (Excel, OpenOffice Calc и т.д.) для быстрого создания приложений, которые выполняют простые вычисления, помогают при создании отчётов или облегчают планирование. Несмотря на то, что возможности таких приложений, как правило, очень ограничены, простота табличных процессоров делает такой подход очень популярным. Речь в этой статье пойдёт о попытке расширить возможности табличных процессоров с помощью многомерной модели данных (обычно ассоциируемой с понятием OLAP), стараясь при этом не слишком усложнить работу с новым инструментом. Кому интересно читаем дальше.
Проблема
Последние пять лет я работаю IT консультантом и занимаюсь .NET-разработкой в основном в области контроллинга и планирования в крупных предприятиях. За это время мне уже несколько раз попадались проекты, когда клиент показывал сложный excel-документ с множеством формул и парой скриптов и говорил, что хочет приложение с такой же функциональностью плюс пара дополнительных фич. Эти проекты объединял похожий сценарий использования документа, состоящий из трёх шагов:
- Собрать данные от множества (5–1000) пользователей. Данные представляли собой цифры, привязанные к нескольким атрибутам, как например: продажи в определённой точке, за определённое время, определённого продукта или расходы на проект, категорию, отдел. Документ обычно либо находился в сетевой папке, либо копии посылались пользователям по мэйлу, а ответ вручную переносился в один документ.
- Посчитать статистику/результат. Excel усложнялся в течении нескольких лет и кроме множества формул его использование подразумевало несколько шагов которые выполнялись вручную. Также возможны симуляции вычислений с разными входными данными. Например: что бы было, если бы курс доллара вырос на 10%.
- Показать результат в виде таблицы. Обычно эта таблица впоследствии использовалась в печатных отчётах или в слайдах презентаций.
Решения на базе табличных процессоров, с которыми я имел дело, как правило, использовались с одной из двух целей:
- планирование, когда планы и прогнозы на будущее находятся не в транзакционных базах компании, а в головах экспертов
- специальные отчёты, исходные данные которых не ведутся в транзакционных системах
Со временем количество ручной работы, связанной с использованием табличных процессоров сильно росло, и организация решалась оплатить разработку специального ПО с возможностью параллельной работы множества пользователей и надёжного хранения данных в базе.
Пример
Вот выдуманный и очень сильно упрощённый пример такой электронной таблицы, который, тем не менее, иллюстрирует сложности связанные с «плоской» моделью данных.
Представим компанию по продажи лимонада. У нас 3 сотрудника, которые продают лимонад в разных местах города. Компания решает планировать продажи на каждый день, для того чтобы:
- примерно знать, сколько лимонов покупать по утрам
- платить бонусы сотрудникам, которые стараются повысить продажи (например, зазывая людей, а не играя на телефоне за прилавком)
Поскольку в компании 3 сотрудника, 1 продукт и пока нет особой потребности вести долговременную статистику, она решает использовать электронные таблицы. Вот так выглядит наш документ: 
В строках дни, а в столбцах количество проданных стаканчиков лимонада, выручка и процент выполнения плана. Для того чтобы сравнивать планы с реальностью, мы будем вести данные в двух вариантах: запланированные и действительные. Мы создали по рабочему листу на каждого сотрудника, и считаем по ним сумму исходя из того, что в каждом листе строка Total имеет номер 33. Каждый месяц мы копируем листок, стираем данные и заполняем снова.
Вопрос: Что делать, если у нас появится несколько продуктов (свежевыжатый апельсиновый сок?), мы захотим статистику по месяцам или за год, расширится штаб продавцов и мы захотим видеть данные по районам города (например, чтобы видеть эффект рекламы)? Что если мы захотим усложнить формулы и добавить планирование расходов? Мы, конечно, можем ещё немного помучиться с таблицами: наплодить рабочих листов на каждый продукт и продавца (к примеру, всего 5 продуктов и 10 продавцов = 50 листов), исправлять скопированные формулы, писать скрипты, чтобы сгруппировать продавцов и так далее. А что если…
Идея
Вспомнив университетский курс по базам данных, я сразу заметил, что многомерная модель данных очень хорошо подходит для описания таких систем.
Моим первым решением было создание фреймворка на .NET, который хранил данные в базе в виде многомерного куба, занимался контролем доступа к данным и позволял описывать вычисления в виде скриптов на IronPython. Хотя кода на каждый новый проект требовалось значительно меньше, использование этого фреймворка требовало знания C# и баз данных.
Через какое-то время появилась идея создать похожую на табличные процессоры многомерную систему, работа с которой не требовала бы умения программировать.
Рынок
Дальше речь пойдёт про OLAP и многомерный анализ данных. Так как на хабре эта тема уже обсуждалась (например, Введение в многомерный анализ), я не буду повторяться и исхожу из того, что читатель примерно знает, о чем идёт речь.
Поиск в интернете показал, что идея не нова. Мне попались две категории похожих продуктов:
Многомерные табличные процессоры (Multi-dimensional spreadsheets)
В 1991 году компания Lotus Development Corporation выпустила продукт Lotus Improv, который является типичным представителем этого типа программ. Несмотря на то, что этот продукт послужил примером для целого класса похожих систем, он не был очень удачным, и его разработка была прекращена в 1996 году. Насколько я понял из статей в интернете, продукт был рассчитан на одного пользователя. Для себя я сделал следующие выводы:
- Многомерная модель данных — слишком сложный концепт для большинства рядовых пользователей.
- Использовать многомерный куб в одиночку редко имеет смысл. Данные, которые вводит один человек, чаще всего прекрасно поместятся в двухмерную табличку. Многомерная модель данных имеет смысл в многопользовательском сценарии.
Полноценные Business Intelligence системы с функцией планирования
Несколько крупных (или даже очень крупных) компаний уже предлагают серверные системы подобного типа.
В описании таких систем обычно присутствует слово OLAP, но в их работе есть несколько отличий от классических OLAP систем, которые обычно предназначены для анализа уже существующих данных из транзакционных систем. В моем понимании, системы планирования с многомерной моделью данных отличаются тем, что позволяют удобный многопользовательский ввод данных в многомерный куб. Это значит, что база данных стоящая за такой системой должна одновременно поддерживать и транзакционный (сохранить ввод пользователя) и аналитический (агрегация данных) режим работы.
Оказалось, что некоторые из моих клиентов уже пробовали использовать одну или другую систему планирования с многомерной моделью данных и столкнулись со следующими трудностями:
- Использование большинства таких систем требует присутствия высокооплачиваемых специалистов, так как: необходимо умение программировать на специальных скриптовых языках; чтобы правильно установить или администрировать систему часто необходимо прочитать несколько сотен страниц документации.
- Относительно дорогие и сложные лицензии.
- В то же время функциональность таких систем ограничена и использование конечного продукта, созданного на основе системы, обычно сложнее, чем использование специально написанного приложения.
С последним пунктом сложно что-либо сделать. Идея создавать софт без навыков программирования не нова, но пока не изобретён искусственный интеллект, возможности таких программ будут ограничены. Первые два пункта я решил исправить.
Решение
Написать систему, работа с которой будет такой же простой, как и использование табличных процессоров, обладающую следующими свойствами:
- Многомерная и иерархическая модель данных
- Формулы, максимально приближенные к уже знакомым формулам табличных процессоров
- Возможность работать параллельно через веб
- Контроль доступа к данным и формулам
- Простая инсталляция, возможность начать работать за пару минут, используя бесплатную версию
- Простота в обслуживании (без необходимости работать в облаке)
- Только несколько человек, которые создают модель приложения, должны понимать концепты OLAP. Пользователь, который вводит данные, просто заполняет таблицу.
- Способность хранить и быстро просчитывать большие объёмы данных (до миллиарда значений)
Дизайн
Общая архитектура
Система (кодовое название Egeria) рассчитана на многопользовательскую работу через Web и состоит из сервера, написанного на .NET/C# и веб-клиента. Для работы «в домашних условиях» есть простое приложение (Launcher), которое позволяет выбрать папку с данными, запускает локальный сервер и открывает браузер с нужным адресом.
Измерения и их элементы
В отличие от табличных процессоров, где строки и столбцы пронумерованы цифрами и буквами соответственно, члены/элементы измерения (dimension members) в кубах обычно создаются из элементов прикладной области (в нашем случае это продавцы, продукты, дни и так далее). Часто для описания элементов каждого измерения используются таблицы баз данных. Поскольку я не хотел усложнять жизнь пользователей изучением SQL, я решил создать визуальный концепт для репрезентации метаданных.
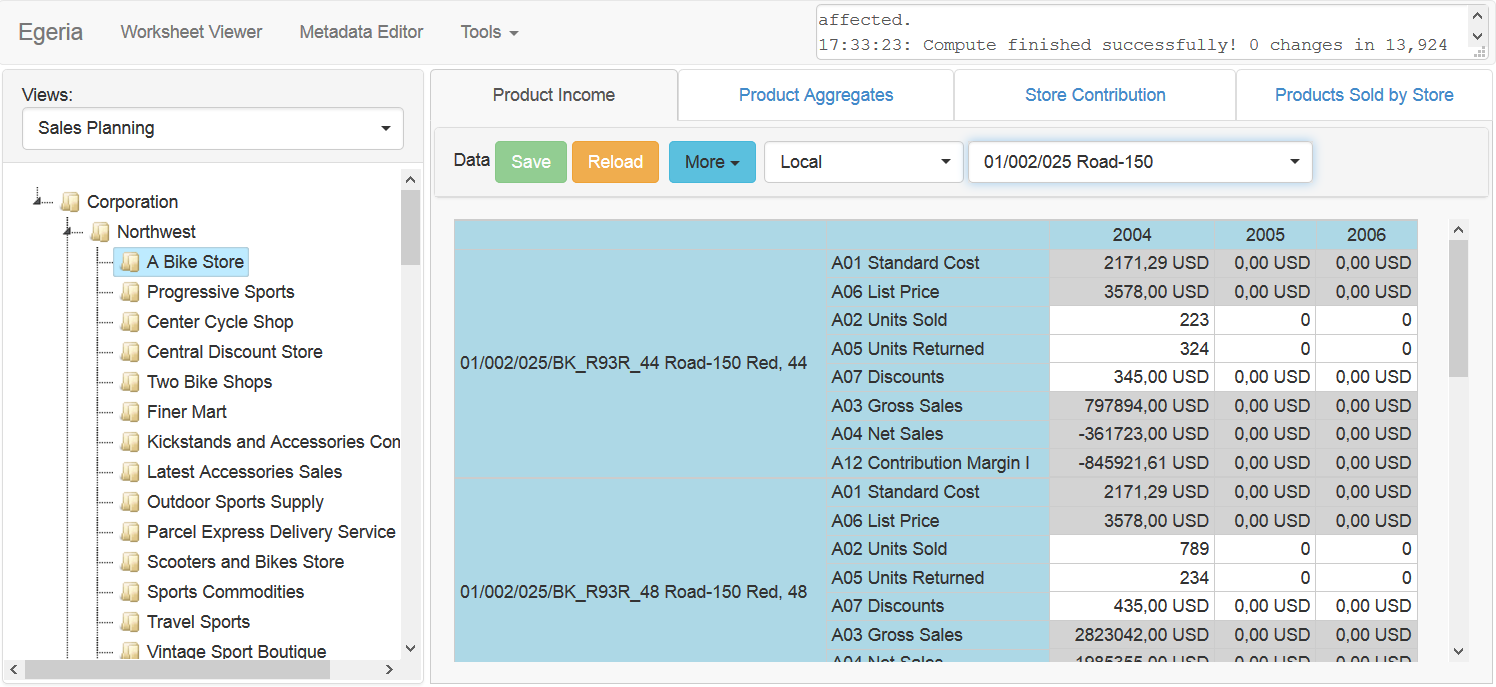
То, что получилось, я назвал визуальный документ. Все метаданные в системе, включая системные объекты (такие как куб или измерение), описываются визуальным документом. Пример такого документа, который описывает форматирование позиции отчёта, виден на следующем изображении: 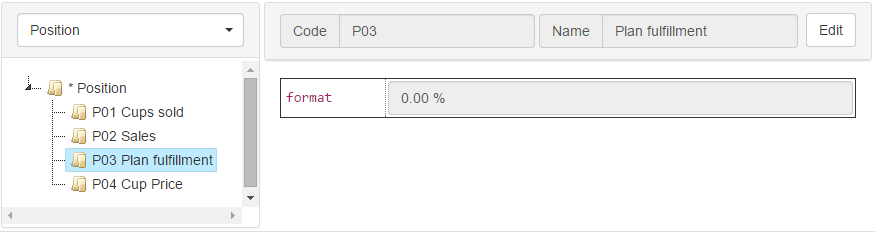
Каждый документ имеет два поля: код (Code) для ссылок на документ из формул и имя (Name) для отображения на экране. Сам визуальный документ имеет иерархическую структуру и состоит из обычных элементов ввода, как например: поле для ввода текста, списки выбора, чекбокс или список элементов. Структура визуального документа описывается визуальной схемой, которая в свою очередь является визуальным документом (структуру визуальной схемы можно описать визуальной схемой так же, как структуру XML Schema можно описать с помощью инстанции XML Schema). Схема, которая описывает документ с предыдущего изображения, определяет поле «format». Эту схему видно в разделе «Level data type» следующего изображения: 
На этой картинке показано описание измерения «позиция отчёта» (Position). В Egeria все измерения иерархические (даже если определён всего один уровень иерархии). Это означает, что каждое измерение можно представить в виде дерева. Как уже было сказано, элементы этого дерева — визуальные документы. Документы каждого уровня иерархии имеют свою схему, описанную в Dimension model. Измерение Position имеет один уровень иерархии, который называется position. Так же в каждое измерение добавляется нулевой элемент с кодом звёздочка (*). Этот элемент не содержит данных и находится на самом верхнем уровне иерархии, который тоже имеет идентификатор звезда (*). На первой картинке слева мы видим, что измерение Position состоит из 5 элементов: *, P01, P02, P03, P04.
Кубы
Численные данные хранятся в так называемых кубах. Куб описывается входящими в него измерениями и представляет собой что-то вроде многомерного листа Excel. В каждую ячейку куба можно сохранить одно число.
Представление данных: рабочий лист
Современные экраны показывают не более двух измерений, что вынуждает нас проектировать данные на строчки и столбцы двухмерной таблицы. Это преобразование и выбор участка куба, доступного для пользователя, описывается с помощью концепта рабочего листа (worksheet).
В Egeria, в отличие от табличных процессоров, рабочий лист не содержит данных (они хранятся в кубе), а просто отображает данные части куба. Два листа могут показывать один и тот же регион куба.
Работает все так же, как сводная таблица (pivot table) в табличных процессорах. Пользователь выбирает, какие измерения будут столбцами, какие строками и какие фильтрами с помощью drag&drop. После этого для каждого измерения выбираются элементы, которые будут отображаться в рабочем листе. После того как рабочий лист сохранен, можно вводить данные в куб и создавать формулы.
Вычисления
Простая, но гибкая система обработки вычислений в кубе — главное преимущество Egeria. Все вычисления производятся на сервере. Формулы компилируются в машинный код и поэтому выполняются очень быстро. На среднем ноутбуке за 10–20 секунд полностью просчитывается куб с пятью миллионами значений (количество не заполненных клеток в кубе не играет роли). Система трекинга зависимостей в кубе позволяет просчитывать изменение одной ячейки куба мгновенно (если, конечно, от этой ячейки не зависят ещё 5 миллионов ячеек).
Хотелось сделать формулы Egeria максимально похожими на формулы обычных табличных процессоров. Вот 3 основных отличия, которых я не смог избежать:
- Egeria немного расширяет стандартный язык формул, чтобы дать возможность использовать метаданные в формулах. Выражение pos.format, например, вернёт содержимое поля format элемента измерения pos текущей ячейки.
- Добавлена пара новых функций, позволяющих работать с метаданными и форматировать ячейки. Более подробно о них можно прочитать в документации системы.
- Важное нововведение — это система адресации в кубе:
Адресация в кубе
Адреса в табличных процессорах выглядят так: B3 или $C$4 (первый относительный, второй абсолютный). Писать каждое измерение в каждый адрес было бы слишком сложно (у нас может быть 10–15 измерений). К тому же Egeria отказывается от копирования формул из соображений быстродействия и понятности получившейся модели вычислений (для каждой формулы мы описываем пространство, в котором она действует).
Адресация в системе происходит всегда относительно ячейки, которая считается в данный момент.
Каждое обращение в куб заключается в квадратные скобки. В скобках через запятую перечисляются адреса по каждому измерению, которое нужно изменить, чтобы добраться до нужной ячейки. Выражение [] вернёт ячейку, которая обрабатывается в данный момент. Выражение [dim1: a1] вернёт ячейку с кодом a1 в измерении dim1, оставив остаток адреса не измененным. Так же есть специальные функции, которые позволяют обращаться к элементам иерархических измерений. [dim1: children ()], например, вернёт по одной ячейке для каждого элемента под текущим элементом в измерении dim1. Таким образом можно агрегировать данные.
Как будет выглядеть наш пример в Egeria?
У нас получится примерно вот это:
Выбрав слева в дереве продавца, а сверху через списки выбора месяц и продукт, мы увидим продажи в таблице справа.
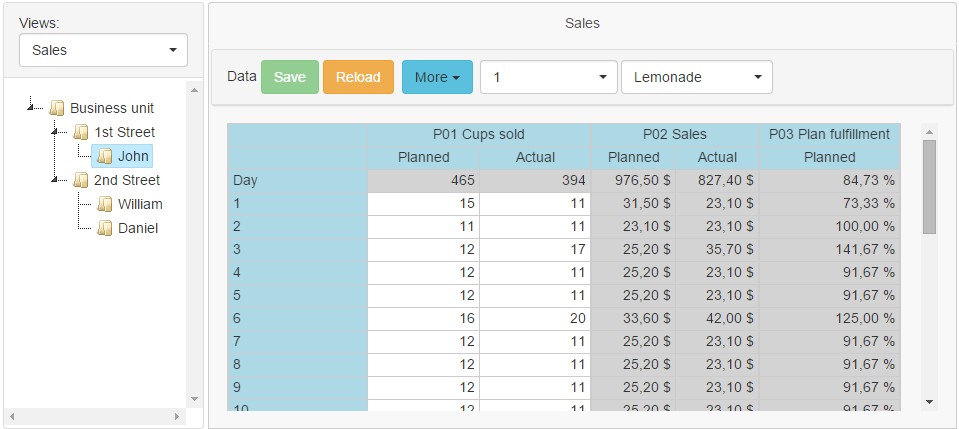
Если в дереве выбрать улицу, то справа увидим продажи по этой улице:
Это приложение можно создать за 20 минут (включая ввод данных), выполнив следующие шаги:
- Открываем редактор метаданных и создаём следующие измерения (в скобках указан код измерения, используемый в формулах):
- Day (day) — День продажи с элементами от 1 до 31.
- Month (mon) — Месяц продажи с элементами от 1 до 12.
- Data type (dty) — Тип данных с элементами: запланированные (Planned) и действительные (Actual)
- Position (pos) — Позиция отчёта/формы ввода с элементами: количество проданных стаканчиков лимонада (Cups sold), выручка (Sales), процент выполнения плана (Plan fulfillment) и цена за стакан (Cup price).
- Business unit (bu) — Наши сотрудники, сгруппированные по улицам, на которых они работают.
- Product (prod) — Продукты, которые продают наши сотрудники.
- Создаём следующие worksheets (рабочие листы или формы ввода):
- Prices: Ввод цен по улицам.
- Sales: Ввод проданных стаканчиков и подсчёт выручки.
- Sales by month: Агрегация данных по месяцам.
- Добавляем формулы.
Формула для подсчёта продаж, например, выглядит так:[day:*,dty:*,mon:*,pos:P04,bu:parent()] * [pos:P01]
pos: P01 это код элемента измерения «позиция отчёта» который называется «количество проданных стаканчиков» (Cups sold), pos: Р04 — «цена стакана». Поскольку цена стакана зависит только от улицы и продукта, мы храним её на нулевом (*) элементе в измерениях день (day), тип данных (dty), и месяц (mon).
Выражение bu: parent () выходит с уровня иерархии «продавец» (измерения business unit) на уровень иерархии «улица».
Подробное видео с пошаговым созданием этой системы можно найти в разделе скринкасты на сайте системы.
Хотите узнать больше?
На сайте http://egeria.rocks вы найдёте:
- документацию и скринкасты к проекту (к сожалению, пока только на английском)
- бесплатную предварительную версию системы
- пару примеров приложений, созданных с помощью Egeria
Кроме приведённого здесь примера, там есть:
- система для планирования продаж, которая автоматически просчитывает доходы компании из продаж и расходов, производя при этом конвертацию валют
- система для планирования инвестиций на примере парка развлечений
- система для оценки недвижимости
- система учёта времени по проектам с возможностью вводить отпуска
и это только небольшая часть того, для чего можно использовать систему Egeria.
Тех-данные
Для тех, кому интересно, как это все работает:
Front-end
В связи с недавним ростом популярности и возможностей веб приложений выбор пал на JavaScript/HTML5 (Single Page Application) в качестве клиента. В этом случае роль сервера ограничивается предоставлением REST API.
Клиент использует AngularJS, который имплементирует MVVM pattern. Наличие большого количества бесплатных компонентов для этой платформы и её продуманная архитектура значительно упростили разработку клиента.
Back-end
Сервер написан на C#. В качестве серверного фреймворка используется Nancy FX.
ASP.NET показался мне слишком тяжёлым для того чтобы просто создать REST API. К тому же простота Nancy и использование шаблона «фасад» (facade pattern) позволят при необходимости заменить web framework в течение одного или двух дней.
Хотелось так же, чтобы пользователь мог просто скачать и запустить приложение, получив, таким образом, локальный веб сервер. Это отлично поддерживает self-host сценарий использования Nancy.
Для парсинга формул использован Sprache Framework, который позволяет создать парсер за несколько часов. После парсинга из синтаксического дерева генерятся Expression Trees, которые .NET runtime превращает в нативный код.
База данных
Поскольку под капотом визуальный документ сериализируется в JSON документ, Egeria может хранить данные в любой JSON базе данных. В данный момент существует адаптер для MongoDB. Для хранения данных в локальных файлах используется самописное copy-on-write хранилище «ключ-значение» (key-value-store) и сериализация данных с помощью protobuf-net. К сожалению, я не смог найти хорошо поддерживаемое хранилище «ключ-значение», написанное полностью в управляемом коде (managed code). Для работы с JSON объектами используется JSON.NET.
Данные куба хранятся в сжатом двоичном представлении (примерно 30 байт на точку с точностью .NET-овского decimal), что позволяет экономить память и быстро перемещать данные из key-value-store в память и обратно. Система построена по принципу in-memory processing и исходит из того, что все данные поместятся в память. Куб загружается асинхронно и система доступна почти сразу после старта.
Обратная связь
Был бы очень рад узнать ваше мнение о системе.
- Очередной велосипед или что-то новое?
- Есть идея применения системы?
- Я думаю о том, чтобы, после приведения кода в читабельный вид, выложить его на Github. Хотелось ли бы вам, чтобы код системы был открытым или здесь всё же важнее качественная техническая поддержка?
- Нашли ошибку или хотите предложить новую функцию?
Пишите комментарии.
Особенно интересно мнение людей, которые уже занимались системами планирования с многомерной моделью данных.
